In computer science, a priority queue is an abstract data type which is like a regular queue or stack data structure, but where additionally each element has a "priority" associated with it. In a priority queue, an element with high priority is served before an element with low priority. If two elements have the same priority, they are served according to their order in the queue.
stack — elements are pulled in last-in first-out-order (e.g. a stack of papers)
queue — elements are pulled in first-in first-out-order (e.g. a line in a cafeteria)
It is a common misconception that a priority queue is a heap. A priority queue is an abstract concept like "a list" or "a map"; just as a list can be implemented with a linked list or an array, a priority queue can be implemented with a heap or a variety of other methods.
This is also known as "pop_element(Off)", "get_maximum_element", or "get_front(most)_element".
Some conventions reverse the order of priorities, considering lower values to be higher priority, so this may also be known as "get_minimum_element", and is often referred to as "get-min" in the literature.
This may instead be specified as separate "peek_at_highest_priority_element" and "delete_element" functions, which can be combined to produce "pull_highest_priority_element".
In addition, peek (in this context often called find-max or find-min), which returns the highest priority element but does not modify the queue, is very frequently implemented, and nearly always executes in O(1) time. This operation and its O(1) performance is crucial to many applications of priority queues.
Using a priority queue to sort
he semantics of priority queues naturally suggest a sorting method: insert all the elements to be sorted into a priority queue, and sequentially remove them; they will come out in sorted order. This is actually the procedure used by several sorting algorithms, once the layer of abstraction provided by the priority queue is removed
Heapsort if the priority queue is implemented with a heap.
Smoothsort if the priority queue is implemented with a Leonardo heap.
Selection sort if the priority queue is implemented with an unordered array.
Insertion sort if the priority queue is implemented with an ordered array.
Tree sort if the priority queue is implemented with a self-balancing binary search tree.
Applications
Bandwidth management
Priority queuing can be used to manage limited resources such as bandwidth on a transmission line from a network router.
Dijkstra's algorithm
When the graph is stored in the form of adjacency list or matrix, priority queue can be used to extract minimum efficiently when implementing Dijkstra's algorithm, although one also needs the ability to alter the priority of a particular vertex in the priority queue efficiently.
Huffman coding
Huffman coding requires one to repeatedly obtain the two lowest-frequency trees. A priority queue makes this efficient.
3. A bit stream 10011101 is transmitted using the standard CRC method. The generator polynomial is x3+1. Show the actual bit string transmitted. Suppose the third bit from the left is inverted during
transmission. Show that this error is detected at the receiver’s end.
Solution:
Message M (x) = 10011101 = x7+x4+ x3+ x2+ 1
CRC Polynomial C (x) = x3+ 1 = 1001
Multiply the message with x3 since the divisor polynomial is of degree 3.
Since T (x) minus the remainder would be exactly divisible by C (x), we subtract the remainder from T (x) as shown below:
Note: The minus operation in polynomial arithmetic is the logical XOR operation.
T (x): 10011101000
Remainder: 100
-------------------
10011101100 ? This turns out to be the original message with
------------------- the remainder appended to it.
If the third bit form the left is inverted during transmission, the bit stream would be: 10111101100. Dividing this by 1001 we get:
10101
---------------------------------------------
1001 | 10111101100 ? Message
| 1001
-----------------
1011
1001
---------
1001
1001
------------
0100 ? Remainder
------------
Since the remainder is 100, which is different form 0, the receiver detects the error and can ask for retransmission.
Goal Maximize protection, Minimize extra bits Idea Add k bits of redundant data to an n-bit message N-bit message is represented as a n-degree polynomial with each bit in the message being the corresponding coefficient in the polynomial Example Message = 10011010 Polynomial = 1 ?x7 ? 0 ?x6 ? 0 ?x5 ? 1 ?x4 ? 1 ?x3 ? 0 ?x2 ? 1 ?x ? 0 = x7 ? x4 ? x3 ? x
Cyclic Redundancy Check
Error Detection Checked at many layers ? Physical (e.g. modulation) ? Datalink (e.g. cyclic redundancy check) ? Network/Transport (e.g. IP Checksum) ? Application (e.g. MD5 hash)
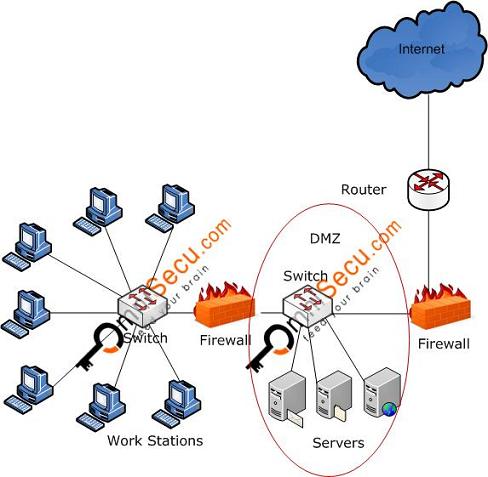
In computer security, a DMZ (sometimes referred to as a perimeter network) is a physical or logical subnetwork that contains and exposes an organization's external-facing services to a larger untrusted network, usually the Internet. The purpose of a DMZ is to add an additional layer of security to an organization's local area network (LAN); an external attacker only has access to equipment in the DMZ, rather than any other part of the network. The name is derived from the term "demilitarized zone", an area between nation states in which military action is not permitted.
Services in the DMZ
Any service that is being provided to users on the external network can be placed in the DMZ. The most common of these services are:
Web servers
Mail servers
FTP servers
VoIP servers
Web servers that communicate with an internal database require access to a database server, which may not be publicly accessible and may contain sensitive information. The web servers can communicate with database servers either directly or through an application firewall for security reasons.
E-mail messages and particularly the user database are confidential information, so they are typically stored on servers that cannot be accessed from the Internet (at least not in an insecure manner), but can be accessed from the SMTP[clarify] servers that are exposed to the Internet.
The mail server inside the DMZ passes incoming mail to the secured/internal mail servers. It also handles outgoing mail.
For security, legal compliance[clarify] and monitoring reasons, in a business environment, some enterprises install a proxy server within the DMZ. This has the following consequences:
Obliges the internal users (usually employees) to use the proxy to get Internet access.
Allows the company to reduce Internet access bandwidth requirements because some of the web content may be cached by the proxy server.
Simplifies the recording and monitoring of user activities and block content violating acceptable use policies.
A reverse proxy server, like a proxy server, is an intermediary, but is used the other way around. Instead of providing a service to internal users wanting to access an external network, it provides indirect access for an external network (usually the Internet) to internal resources. For example, a back office application access, such as an email system, could be provided to external users (to read emails while outside the company) but the remote user would not have direct access to their email server. Only the reverse proxy server can physically access the internal email server. This is an extra layer of security, which is particularly recommended when internal resources need to be accessed from the outside. Usually such a reverse proxy mechanism is provided by using an application layer firewall as they focus on the specific shape of the traffic rather than controlling access to specific TCP and UDP ports as a packet filter firewall does.
Architecture
There are many different ways to design a network with a DMZ. Two of the most basic methods are with a single firewall, also known as the three legged model, and with dual firewalls.
Single firewall A single firewall with at least 3 network interfaces can be used to create a network architecture containing a DMZ. The external network is formed from the ISP to the firewall on the first network interface, the internal network is formed from the second network interface, and the DMZ is formed from the third network interface. The firewall becomes a single point of failure for the network and must be able to handle all of the traffic going to the DMZ as well as the internal network. The zones are usually marked with colors -for example, purple for LAN, green for DMZ, red for Internet (with often another color used for wireless zones).
Dual firewall
A more secure approach is to use two firewalls to create a DMZ. The first firewall (also called the "front-end" firewall) must be configured to allow traffic destined to the DMZ only. The second firewall (also called "back-end" firewall) allows only traffic from the DMZ to the internal network. This setup is considered more secure since two devices would need to be compromised. There is even more protection if the two firewalls are provided by two different vendors, because it makes it less likely that both devices suffer from the same security vulnerabilities.
In a typical DMZ configuration for a small company, a separate computer (or host in network terms) receives requests from users within the private network for access to Web sites or other companies accessible on the public network. The DMZ host then initiates sessions for these requests on the public network. However, the DMZ host is not able toinitiate a session back into the private network. It can only forward packets that have already been requested
One of the longstanding problems with the SELinux network access controls was that they lacked any ability to control packets at the network interface level, limiting our ability to provide access control based on the physical network and making it impossible to provide access control for forwarded packets
The network ingress/egress controls were designed to solve these problems by placing SELinux network access controls at the network interface level.
The new ingress/egress controls are fairly simple: each packet entering the system must pass an ingress access control and each packet leaving the system must pass an egress access control. Forwarded packets must also pass an additional forwarding access control
https://paulmoore.livejournal.com/2128.html
What are Access Control Lists?
ACLs are a network filter utilized by routers and some switches to permit and restrict data flows into and out of network interfaces. When an ACL is configured on an interface, the network device analyzes data passing through the interface, compares it to the criteria described in the ACL, and either permits the data to flow or prohibits it.
Why Do We Use Access Control Lists?
The primary reason is to provide a basic level of security for the network.
ACLs are not as complex and in depth of protection as stateful firewalls, but they do provide protection on higher speed interfaces where line rate speed is important and firewalls may be restrictive ACLs are also used to restrict updates for routing from network peers and can be instrumental in defining flow control for network traffic
When do we use Access Control Lists?
they do offer a significant amount of firewall capability
ACLs should be placed on external routers to filter traffic against less desirable networks and known vulnerable protocols.
One of the most common methods in this case is to setup a DMZ, or de-militarized buffer zone in your network. This architecture is normally implemented with two separate network devices.
The most exterior router provides access to all outside network connections. This router usually has less restrictive ACLs, but provides larger protection access blocks to areas of the global routing tables that you wish to restrict.
This router should also protect against well known protocols that you absolutely do not plan to allow access into or out of your network
ACLs here should be configured to restrict network peer access and can be usedin conjunction with the routing protocols to restrict updates and the extent of routes received from or sent to network peers.
The DMZ is where most IT professionals place systems which need access from the outside. The most common examples of these are web servers, DNS servers, and remote access or VPN systems.
The internal router of a DMZ contains more restrictive ACLs designed to protect the internal network from more defined threats.
ACLs here are often configured with explicit permit and deny statements for specific addresses and protocol services.
As you can see from this diagram, ingress traffic flows from the network into the interface and egress flows from the interface to the network.
ACLs start with a source address first in their configuration and destination second
As you configure an ACL on the ingress of a network interface it is important to recognize that all local network or hosts should be seen as sources here, and the exact opposite for the egress interface.
the implementation of ACLs on the interface of a router that faces an external network
the ingress side is coming from the outside network and those addresses are consideredto be sources, while all internal network addresses are destinations
the egress side, your internal network addresses are now source addresses and the external addresses are now destinations.
Honeypots, the simplest technology, work by tricking a hacker into thinking that they succeeded in infiltrating a system, when in reality the perpetrator reached the 'honeypot', which mimics the target server and provides the hacker with fake 'trophy' information while at the same time studying the behavior of the hacker and logging its IP address for law enforcement authorities to persecute
Honeyd, for instance, can create multiple different honeypots, called virtual honeypots.
Traditionally, a honeypot was a physical computer which simulated the operating system of the real server, but which was actually safely positioned outside the firewall Honeyd's invention of the virtual honeypot was a huge advancement because as a result, a company could have multiple honeypot traps covering all unused or unauthorized IP addresses, and not just one, which they hoped the attacker would choose
When a hacker attempts to connect to an IP address that a company doesn't authorize, Honeyd "takes over" that IP address using ARP spoofing (modifying the source IP address number in the communications packet) and assigns a virtual honeypot for the hacker to interact with. If the hacker probed a different unused IP, Honeyd would assign a different virtual honeypot with perhaps a different operating system or applications to remain realistic
Heat seeking honeypots will contain a module identifying web pages that hackers find "trendy", and which are commonly attacked
This module uses a series of algorithms to "search logs of the Bing search engine to identify queries used by attackers"
The program then mimics the web page at a location near the target server, interacts with the hacker "without manually setting up the actual software that is targeted"
In some versions of this technology, the program "trains" itself to act like the targeted website by employing natural language processing to "generate responses to attacker requests"
Researchers at the Pacific Northwest National Laboratory are building a reasoning framework called CHAMPION, which acts within a network and identifies potential attackers. The laboratory employs behavioral psychologists to determine which factors are most likely to prompt an employee to launch an attack against his own company
Then, CHAMPION combines data such as email traffic, calendars, and evaluation reports into a set of observations falling into four categories: employee role patterns, psychosocial patterns, policy violation patterns, and web access patterns
It then compares these observations to a database of indicators, and it labels individuals that fit the description of an attacker as dangerous
One of the most recurring themes in the field of decoy-based cyber security is targeting human error, rather than computer error, which occurs much less often.
http://www.pitt.edu/~cdv16/trends.htm
The DMZ or the Demilitarized Zone in a network refers to a segment of a network in which we place all the servers that need to be accessible from the internet
In either of these scenarios, whether we have only one firewall in a three-legged design or we have two back-to-back firewalls in the other design, our DMZ is going tobe placed behind only one firewall
But the question is what if there was a pretty critical server placed in the DMZ and we needed more than one layer of security in order to protect it? What if one of our firewalls which is placed in the front is a pretty old one and not capable of doing a very good logging and auditing of the kind of attacks on the DMZ?
In such cases, we need to come up with another design and combine the back-to-back and three-legged firewall designs to create something that satisfies our needs for better security of DMZ
In this scenario let’s say both of our firewalls are Forefront TMG 2010 and one of them acts as the front-end firewall connecting from one side to the Internet and from the other side to the back-end TMG.
The back-end firewall is going to be a three-legged firewall with:
One leg connecting to the LAN
One leg connecting to the DMZ
One leg leg connecting to the front-end TMG
The DMZ is placed behind two firewalls: The front-end TMG and the back-end TMG and if the user is going to reach the DMZ from the internet, he will have to pass through two firewalls
The LAN is also behind two firewalls and therefor better protected
Do you want to consider putting honeypots in your network? The network segment between the firewalls is the best place… The hackers expect the DMZ servers to be there
Specifically, we present heat-seeking honeypots that actively attract attackers, dynamically generate and deploy honeypot pages, then analyze logs to identify attack patterns.
In our design, the heat-seeking honeypots have four components. The first component is to identify which types of Web services the attackers are actively targeting. The second component is to automatically set up Web pages that match attackers’ interests. The third component advertises
honeypot pages to the attackers. When the honeypot receives traffic from attackers, it uses a sandboxed environment to log all accesses. Finally, the fourth component embodies methods to distinguish attacks from normal users and crawler visits, and to perform attack study
Comparing honeypots
we look at how effective different honeypot
setups are in terms of attracting attackers.
1.Web server:
Here, we have just a Web server (in
our case, Apache) running on a machine that can be
publicly accessed on the Internet. The machine has no
hostname, so the only way to access the machine is by
its IP address. There are no hyperlinks pointing to the
server, so it is not in the index of any search engine or
crawler.
2.Vulnerable software:
We install four commonly targeted Web applications, as described in Section 3.2 (a).
The application pages are accessible on the Internet,
and there are links to them on public Web sites. There-
fore, they are crawled and indexed by the search engines.
3.Heat-seeking honeypot pages:
These pages are generated by option (b) as described in Section 3.2. They
are simple HTML pages, wrapped in a small PHP
script which performs logging. Similar to software
pages, the honeypot pages are also crawled and indexed by search engines
the release of Symantec Decoy Server, a "honeypot" intrusion detection system (IDS) that detects, contains and monitors unauthorized access and system misuse as it happens. As a complement to host- and network-based IDS, Symantec Decoy Server diverts attacks from key resources while also providing early detection of internal and external attacks.
"Honeypots supplement security solutions such as firewalls and other intrusion detection systems, providing advanced decoy technology and early detection sensors. In addition to the forensic elements, honeypots can be used as a tool for reducing false positives,"
Symantec Decoy Server is not signature-based, so it automatically detects unknown attacks without any need for security signature updates or dynamic policy configurations. It also detects both host- and network-based attacks, unauthorized use of passwords and server access for increased network protection.
Once a decoy server has been attacked, it covertly monitors the activities of an attacker in real-time using Session Replay, a live session analysis tool. Sessions may be recorded and played back for further analysis to help organizations understand the tools and tactics used against them.
Symantec Decoy Server provides early detection of threats and enables attack diversion and confinement by actually becoming the target of the attack. The decoy sensor acts like a fully functioning server and can simulate email traffic between users in the organization to mirror the appearance of a live mail server.
http://www.symantec.com/region/au_nz/press/au_030701c.html
A honeypot is a system that's put on a network so it can be probed and attacked.
There are two types of honeypots:
Research: For example, the Honeynet Project is a volunteer, nonprofit security research organization that uses honeypots to collect information on cyberthreats.
Production: production honeypots are being recognized for the detection capabilities they can provide and for the ways they can supplement both network- and host-based intrusion protection.
A low-interaction system offers limited activity; in most cases, it works by emulating services and operating systems.
high-interaction honeypots involve real operating systems and applications, and nothing is emulated
Advantages of honeypots
Too much data: One of the common problems with the traditional IDS is that it generates a huge amount of alerts. In contrast, honeypots collect data only when someone is interacting with them.
False positives: Perhaps the biggest drawback of an IDS is that so many of the alerts generated are false.Honeypots sidestep this problem because any activity with them is, by definition, unauthorized.
False negatives: IDS technologies can also have difficulty identifying unknown attacks or behavior. Again, any activity with a honeypot is anomalous, making new or previously unknown attacks stand out
Resources: An IDS requires resource-intensive hardware to keep up with an organization's network traffic. According to Lance Spitzner, founder of the Honeynet Project, a single Pentium computer with 128MB of RAM can be used to monitor millions of IP addresses.
Encryption: more and more attackers are using encryption as well. That blinds an IDS's ability to monitor the network traffic. With a honeypot, it doesn't matter if an attacker is using encryption; the activity will still be captured
The functionality of honeypots is so diverse that it has been a challenge to define exactly what a honeypot is: honeypots serve many different purposes for different organizations. Generally, a honeypot is an information system resource whose value lies in unauthorized or illicit use of that resource.
In fact, its value lies in its being misused.
A dedicated server
A simulated system or state machine like deception tool kit[4] or KFSsensor[5]
A service on a selected host, like Tiny Honeypot that listens to ports not in legitimate use[6]
A virtual server, such as the original honeynet[7] and most other honeypots
A single file with special attributes which is sometimes called a honeytoken[8] or any number of other possibilities
The value in a honeypot is derived from the lack of any authorized activity to the resource. A honeypot resource is never meant for legitimate use; therefore, any use of the honeypot resource is illegitimate and accidental, or hostile in nature.
In the field of computer security, honeytokens are honeypots that are not computer systems.
Honeytokens are fictitious words or records that are added to legitimate databases.
They allow administrators to track data in situations they wouldn't normally be able to track, such as cloud-based networks. If data is stolen, honeytokens allow administrators to identify who it was stolen from or how it was leaked. If there are three locations for medical records, different honey tokens in the form of fake medical records could be added to each location. Different honeytoken would be in each set of records.
https://en.wikipedia.org/wiki/Honeytoken
A honeytoken is a data or a computing resource that exists for the purpose of alerting you when someone accesses it. This type of a honeypot could take many forms, such as a user account that no one should use, a file that no one should access and a link on which no one should click.
While partitioning chops single drives into smaller logical volumes, JBOD combines drives into larger logical volumes.
https://blog.storagecraft.com/jbod-care/
JBOD
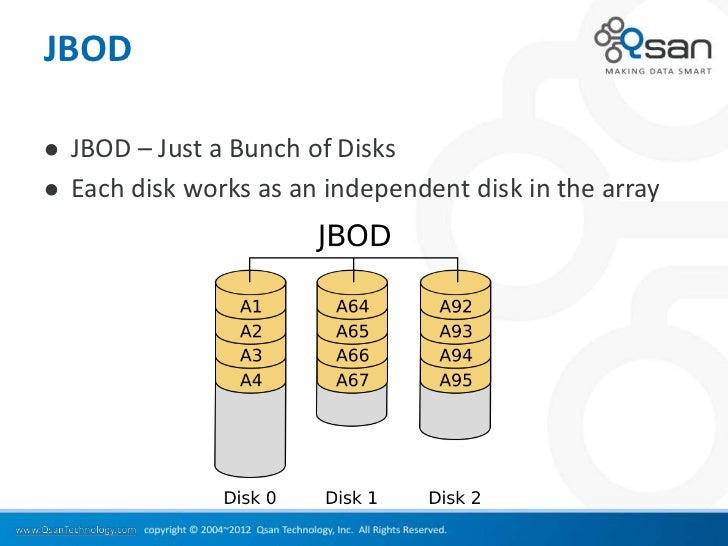
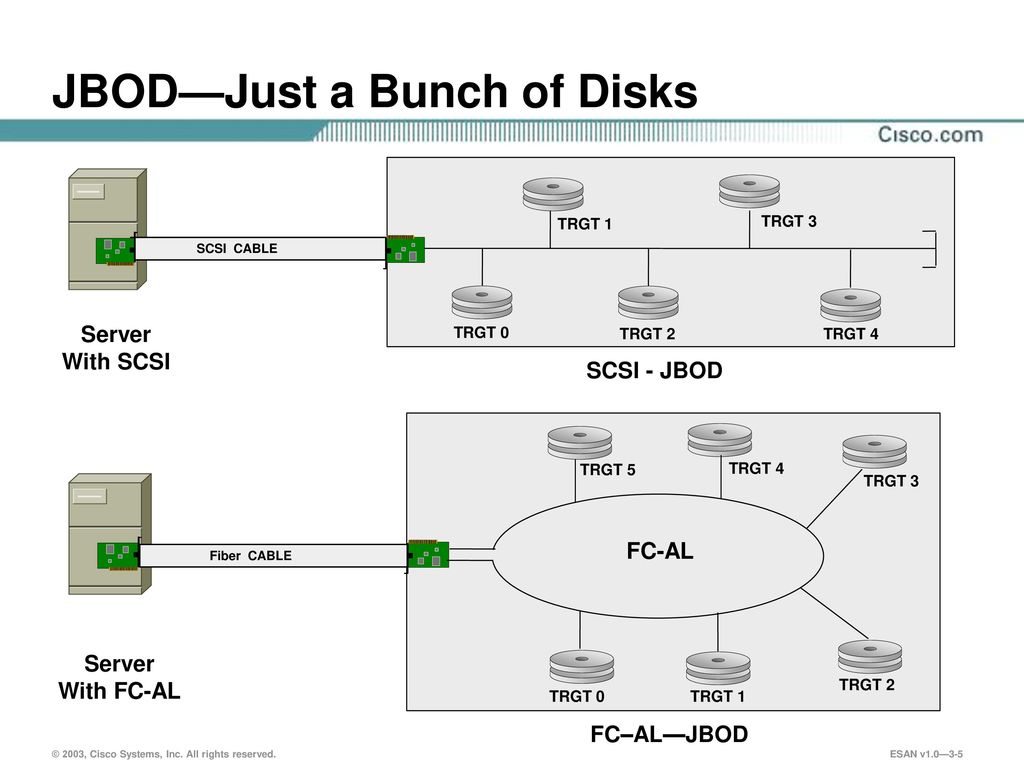
JBOD (Just a bunch of disks or Just a bunch of drives) is when a number of drives are used, but are not in a RAID configuration.
The drives may be handled as separate logical volumes, or they may be combined into a single logical volume using a system like LVM.
http://en.wikipedia.org/wiki/Non-RAID_drive_architectures
Use Disk Utility to Create a JBOD RAID Array
A JBOD RAID set or array, also known as a concatenated or spanning RAID, is one of the many RAID levels supported by OS X and Disk Utility. JBOD (Just a Bunch Of Disks) is not actually a recognized RAID level, but Apple and most other vendors who create RAID-related products have chosen to include JBOD support with their RAID tools.
JBOD allows you to create a large virtual disk drive by concatenating two or more smaller drives together. The individual hard drives that make up a JBOD RAID can be of different sizes and manufacturers. The total size of the JBOD RAID is the combined total of all the individual drives in the set.
There are many uses for JBOD RAID, but it’s most often used to expand the effective size of a hard drive, just the thing if you find yourself with a file or folder that is getting too large for the current drive. You can also use JBOD to combine smaller drives to serve as a slice for a RAID 1 (Mirror) set.
No matter what you call it - JBOD, concatenated or spanning - this RAID type is all about creating larger virtual disks
A JBOD (Just a Bunch of Drives) is a drive enclosure that accommodates multiple disk drives. These drives are interfaced through a common backplane and are accessed through JBOD controllers that provide either the Fiber Channel bypass or SAS expander functionality. The JBOD enclosures attach to a managing RAID system, thus providing an easy means to quickly expand array capacity to many folds.
http://www.surveon.com/support/RAID.asp
JBOD means the individual disks are presented (to a server) with no amalgamation, pooling or structure applied. The term is in widespread use, especially in the context of computers that have software volume management, such as LVM (AIX, HP-UX, Linux), DiskSuite (Solaris), ZFS (Solaris), Veritas Volume Manager (UNIXes), Windows, and so-on.
Spanning or concatenation is an additional configuration that can be applied by volume managers to combine JBODs into larger logical volumes or LUNs (logical unit numbers
http://searchstorage.techtarget.com/definition/JBOD
JBOD (Just a Bunch of Disks)
JBOD is not one of the numbered RAID levels. Unlike a concatenated array, the disks of JBOD appear as individual hard disks, instead of one single large disk. JBOD accurately describes the underlying physical structure that all RAID structures rely upon. When a hardware RAID controller is used, it normally defaults to JBOD configuration for attached disks.
http://www.sansdigital.com/raid-diagrams.html
RAID JBOD
JBOD RAID description
JBOD (Just a bundle of disks) is a tie of hard drives, strictly speaking, it is not a RAID array. Though some disks can be united in one logical section with help of OS or with hardware using RAID controller which supports the function of JBOD array build. Usually files are recorded sequentially to the end of the disk, then writing goes on to next HHD. Such data organization does not require any special equipment, as it was said above, and it can be implementedby means of OS or third-party software. Although, when one of the drivesfails system is breaking down and data recovery from JBOD array in necessary.
JBOD Recovery
In case of JBOD disk array failure we should detect sequence of drives. This is not hard if JBOD array has just two storages, but task becomes more complicated if the array has three or more drives. In this case it is necessary to analyze file allocation table to determine the addressing of the file or directory, and then performing necessary calculations we can quite easily prioritize disks in the array. In addition, we should mention that in some cases when one or several drives of JBOD array failed and could not be recovered, the information from damaged JBOD was still available, though partially.
Concatenation may be thought of as the reverse of partitioning. Whereas partitioning takes one physical drive and creates two or more logical drives, JBOD uses two or more physical drives to create one logical drive.
Concatenation is sometimes used to turn several odd-sized drives into one larger useful drive, which cannot be done with RAID 0. For example, JBOD could combine 3 GB, 15 GB, 5.5 GB, and 12 GB drives into a logical drive at 35.5 GB, which is often more useful than the individual drives separately.
In the diagram to the right, data are concatenated from the end of disk 0 (block A63) to the beginning of disk 1 (block A64); end of disk 1 (block A91) to the beginning of disk 2 (block A92). If RAID 0 were used, then disk 0 and disk 2 would be truncated to 28 blocks, the size of the smallest disk in the array (disk 1) for a total size of 84 blocks.
Concatenation is one of the uses of the Logical Volume Manager in Linux, which can be used to create virtual drives spanning multiple physical drives and/or partitions.
http://www.raidrecoverylabs.com/standard_raid_levels/
JBOD RAID Explained
Unlike raid, JBOD takes a bunch of drives or disks and turns them into one large partition. Also, there is no redundancy offered by JBOD. Thus, the disadvantage is that unlike RAID arrays, the whole JBOD arrays fails if there is a failure of one disk in the array. In simple words, JBOD can be thought of as the opposite of partitioning. In case you are using JBOD you will find that there is no fault tolerance, no improvement in performance unlike the raid technology.
What are the advantages of JBOD over RAID?
There is no wastage of data in the drive. There is no loss in the capacity as JBOD array lets you to combine the individual disks into one single large unit. For instance, a 10GB drive and a 40GB drive would add up to form a 50 GB volume of JBOD while only 30GB of RAID zero array. The advantage however is relatively smaller these days since drives are cheap in cost.
There is easier recovery during disaster. In a RAID volume, data on each disk is destroyed since all the files are striped in it, but if the same drive in the JBOD set of array dies then there is easier recovery of files on the other drives. Thus, JBOD recovery in such instances is better than RAID data recovery.
JBOD and RAID levels:
There are several disadvantages of JBOD though as compared to the RAID levels. It is hence consideredto be a cheaper option for a RAID system.
JBOD does not offer redundancy unlike the raid technology.
There is no increase in the performance of the system using JBOD array unlike RAID which betters the performance and offers higher reliability.
JBOD lacks fault tolerance.
Unlike RAID recovery, JBOD recovery can be a bit tougher.
JBOD-RAID recovery:
There are various categories of software available to recover your JBOD. You can get file recovery after a virus attack or a sudden shut down of the system, system crash, etc. In case of accidental deletion of files on your file system, you can use utilities that are available over the Internet. You can easily obtain a quick and an effective solution to restore all the files that you have lost.
http://www.raidrecoveryonline.com/jbod_raid/
the differences between four types of disk storage: Just a Bunch of Disks (JBOD), Direct Attached Storage (DAS), Network Attached Storage (NAS), and Storage Area Networks (SANs).
JBOD is a collection of disks in a box presented to the OS either as a single volume or a combination of drives as larger logical volumes. However, there’s no support for RAID fault tolerance or performance optimization.
https://www.petri.com/storage-tip-understanding-difference-jbod-das-nas-sans
Non-RAID drive architectures
JBOD: Just a bunch of disks; an array of drives, each of which is accessed directly as an independent drive.
SPAN or BIG: a simple concatenation of multiple drives. Such a concatenation is sometimes also called JBOD, but this usage is proscribed in careful use due to ambiguity with the alternative meaning just cited
MAID: a system using hundreds to thousands of hard drives for nearline storage
http://en.wikipedia.org/wiki/Non-RAID_drive_architectures