- The Open Science Grid (OSG) provides common service and support for resource providers and scientific institutions (i.e., "sites") using a distributed fabric of high throughput computational services.This documentation aims to provide HTC/HPC system administrators with the necessary information to contribute resources to the OSG.An existing compute cluster running on a supported operating system with a supported batch system: Grid Engine, HTCondor, LSF, PBS Pro/Torque, or Slurm.
- WekaIO Matrix and Univa Grid Engine – Extending your On-Premise HPC Cluster to the Cloud
The capacity of the file system will depend on the number of cluster hosts, and the size and number of SSDs on each host. For example, if I need 100TB of shared usable storage, I can accomplish this by using a cluster of 12 x i3.16xlarge storage dense instances on AWS where each instance has 8 x 1,900GB NVMe SSDs for a total of 15.2 TB of SSD storage per instance. A twelve node cluster, in theory, would have 182.4 TB of capacity, but if we deploy a stripe size of eight (6N + 2P) approximately 25% of our capacity will be dedicated to storing parity. 10% of the Matrix file system is recommended to be held in reserve for internal housekeeping and caching so the usable capacity of the twelve node cluster is ~123 TB (aGridFTPssuming no backing store).
https://blogs.univa.com/2019/06/wekaio-matrix-and-univa-gridgridftp-engine-extending-your-on-premise-hpc-cluster-to-the-cloud/
- What Is High-Performance Computing?
High-performance computing (HPC) is the ability to process data and perform complex calculations at high speeds.
One of the best-known types of HPC solutions is the supercomputer. A supercomputer contains thousands of compute nodes that work together to complete one or more tasks. This is called parallel processing. It’s similar to having thousands of PCs networked together, combining compute power to complete tasks faster.
https://www.netapp.com/us/info/what-is-high-performance-computing.aspx
- Open Source High-Performance Computing
The Open MPI Project is an open source Message Passing Interface implementation thatis developed and maintained by a consortium of academic, research, and industry partners. Open MPI is, therefore, able to combine the expertise, technologies, and resources from all across the High-Performance Computing communityin order to build the best MPI library available. Open MPI offers advantages for system and software vendors, application developers and computer science researchers.
https://www.open-mpi.org/
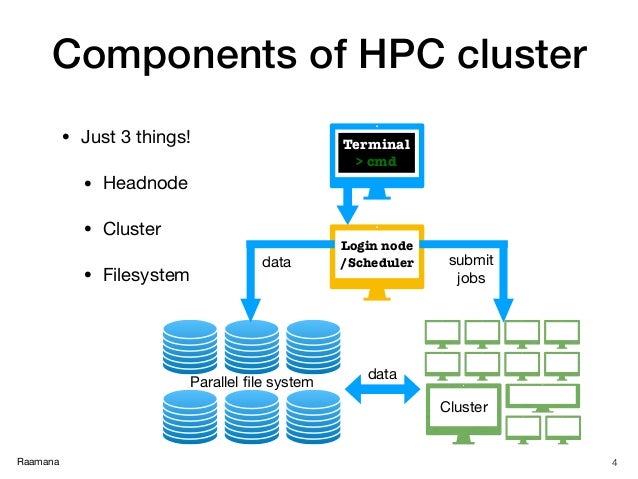
- Introduction to high performance computing, what is it, how to use it and when
Improves the scale & size of processing
With raw power & parallelization
Thanks to rapid advances in
https://www.slideshare.net/raamana/high-performance-computing-with-checklist-and-tips-optimal-cluster-usage
- Some workloads have very high I/O
throughput , so to make surethese requirements are met , the kernel uses schedulers.
http://www.admin-magazine.com/HPC/Articles/Linux-I-O-Schedulers?utm_source=ADMIN+Newsletter&utm_campaign=HPC_Update_110_2018-03-22_Linux_I%2FO_Schedulers&utm_medium=email
- The general goal of HPC is
either to run applications faster or to run problems that can’t or won’t run on a single server. To do this, you need to run parallel applications across separate nodes. If you are interested in parallel computing using multiplenodes, you need at least two separate systems (nodes), each with its own operating system (OS). To keep things running smoothly, the OS on both nodes should be identical. (Strictlyspeaking , it doesn’t have to be this way, but otherwise, it is very difficult to run and maintain.) If you install a package on node 1, then it needs tobe installed on node 2as well . This lessens a source ofpossible problems when you have to debug the system.
- OFED (
OpenFabrics Enterprise Distribution) is a package that developed and released by the OpenFabrics Alliance (OFA), as a joint effort of many companies that are part of the RDMA scene. It contains the latest upstream software packages (both kernel modules anduserspace code) to work with RDMA. It supportsInfiniBand , Ethernet andRoCE transport.
- I explained how to install the RDMA stack in several ways (inbox, OFED and manually).
- Installation of RDMA stack manually
http://www.rdmamojo.com/2014/12/27/installation-rdma-stack-manually/
- OFED (
OpenFabrics Enterprise Distribution) is a package that developed and released by the OpenFabrics Alliance (OFA), as a joint effort of many companies that are part of the RDMA scene.
http://www.rdmamojo.com/2014/11/30/working-rdma-using-ofed/
- What is
RoCE ?
RDMA over Converged Ethernet (
What are the differences between RoCE v1 and RoCE v2?
As originally implemented and standardized by the InfiniBand Trade Association (IBTA)
These limitations have driven the demand for RoCE to operate in layer 3 (
https://community.mellanox.com/docs/DOC-1451
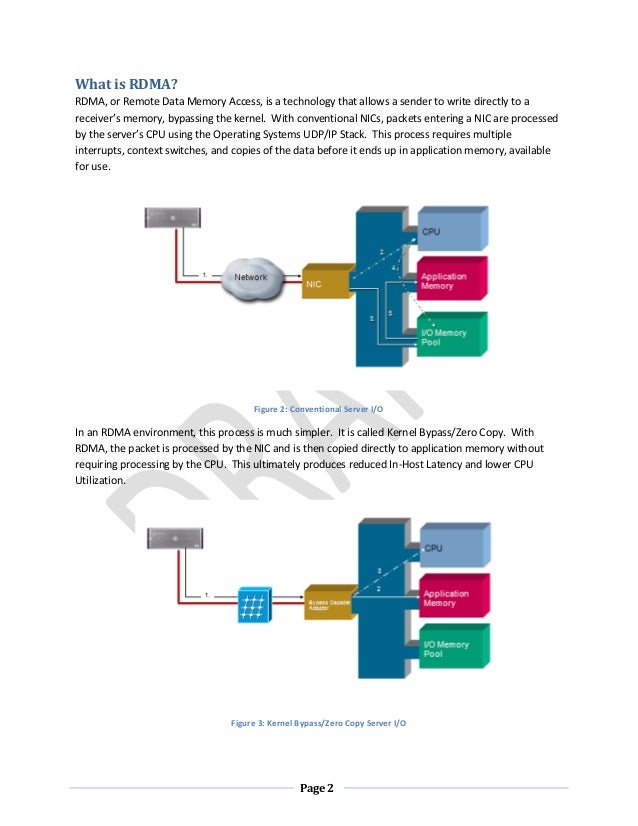
- Remote Direct Memory Access (RDMA) provides direct memory access from the memory of one host (storage or
compute ) to the memory of another host without involving the remote Operating System and CPU, boosting network and host performance with lower latency, lower CPU load and higher bandwidth.
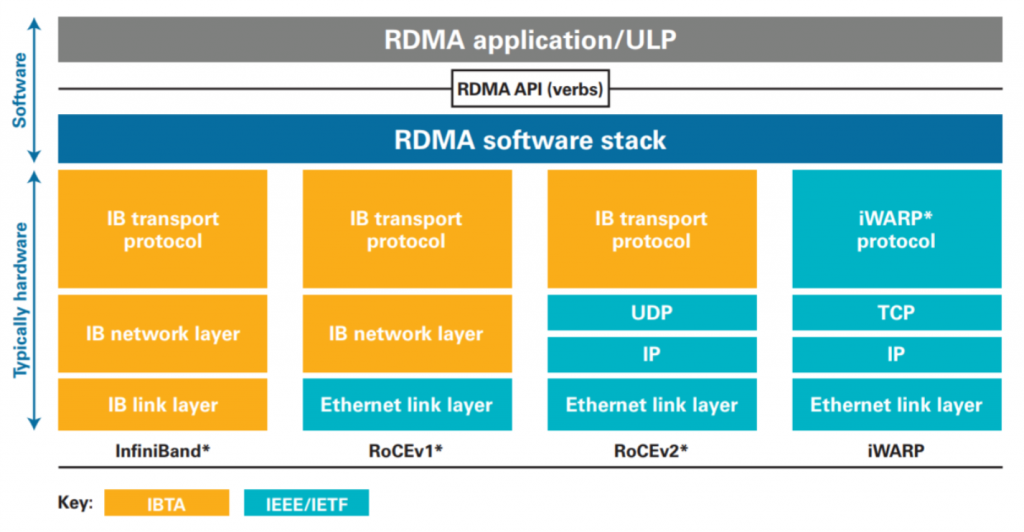
- RDMA over Converged Ethernet (RoCE) is a network protocol that allows remote direct memory access (RDMA) over an Ethernet network. There are two RoCE versions, RoCE v1 and RoCE v2. RoCE v1 is an Ethernet link layer protocol and hence allows communication between any two hosts in the same Ethernet broadcast domain. RoCE v2 is an internet layer protocol
which means that RoCE v2packets can be routed .
RoCE versusInfiniBand
While the RoCE protocols define how to perform RDMA using Ethernet and UDP/IP frames, the
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
- RDMA or Remote Direct Memory Access, communications using Send/Receive
permit high through-put and low-latency networking.
The set of standards, defined by the Data Center Bridging (DCB) task group within
IEEE 802.1
target of CEE is the convergence of Inter Process Communication (IPC), networking
and storage traffic in the data center. the lossless CEE functionality is conceptually
similar to the features offered by the
per port (analogous to
The CEE new standards include: 802.1Qbb
control, 802.1Qau
Transmission Selection and Data
The lossless delivery features in CEE enables a natural choice for
building RDMA, SEND/RECEIVE and kernel bypass services over CE
E is to apply RDMA transport services over CEE or
ROCE
software stack (similar to
Many Linux distributions, which include OFED, support a wide and rich range of middleware and
application solutions such as IPC, sockets, messaging, virtualization, SAN, NAS, file systems and databases, which enable
three dimensions of unified networking on Ethernet
delivering the lowest latency and jitter characteristics and enabling simpler
software and hardware implementations
multiple ISV applications, both in the HPC and EDC sectors
http://www.itc23.com/fileadmin/ITC23_files/papers/DC-CaVES-PID2019735.pdf
- Network-intensive applications like networked storage or cluster computing need a network infrastructure with a high bandwidth and low latency. The advantages of RDMA over other network application programming interfaces such as Berkeley sockets are lower latency, lower CPU load and higher bandwidth.
[ 5] The RoCE protocol allows lower latencies than its predecessor, theiWARP protocol.[ 6] Thereexist RoCE HCAs (Host Channel Adapter) with a latency as low as 1.3 microseconds[ 7][ 8] while the lowest knowniWARP HCA latency in 2011 was 3 microseconds
The RoCE v1 protocol is an Ethernet link layer protocol with
The RoCEv2 protocol exists on top of either the UDP/
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
RoCE versusInfiniBand
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
RoCE is a standard protocol defined in the InfiniBand Trade Association (IBTA) standard.RoCE makes use of UDP encapsulation allowing it to transcend Layer 3 networks. RDMA is a key capability natively used by the InfiniBand interconnect technology. Both InfiniBand and EthernetRoCE share a common user API but have different physical and link layers.
- Why
RoCE ?
networks. With
companies massive amounts of capital expenditures. There is no difference to an application between
using RDMA over
Ethernet environment
http://www.mellanox.com/related-docs/whitepapers/roce_in_the_data_center.pdf
- Remote Direct Memory Access (RDMA) provides direct access from the memory of one computer to
high-throughput, low-latency networking with low CPU utilization, which is especially useful in massively
parallel compute clusters
http://www.mellanox.com/related-docs/whitepapers/WP_RoCE_vs_iWARP.pdf
- There are two different RDMA performance testing packages included with Red Hat Enterprise Linux,
qperf andperftest .Either of these may be used to further test the performance of an RDMA network.
- InfiniBand is a great networking protocol that has many features and provides great performance. However, unlike
RoCE andiWARP , which are running over an Ethernet infrastructure (NIC, switches and routers) and support legacy (IP-based) applications, by design. InfiniBand, as acompletely different protocol, uses a different addressing mechanism, which isn't IP, and doesn't support sockets - therefore it doesn't support legacy applications. This means that in some clusters InfiniBand can'tbe used as the only interconnect since many management systems are IP-based. The result of this could have been that clusters that use InfiniBand for the data traffic may deploy an Ethernet infrastructure in the cluster as well (for the management). This increases the price and complexity of cluster deployment.
IP over
The
The traffic that
kernel bypass
reliability
zero
splitting and assembly of messages to packets, and more.
SM/SA must always be available in order for
The MAC address of an
The MAC address of the
Configuring VLANs in an
Non-standard interface for managing VLANs.
http://www.rdmamojo.com/2015/02/16/ip-infiniband-ipoib-architecture/
- RDMA support for
Infiniband ,RoCE (RDMA over Converged Ethernet), and Omni-Path inBeeGFS is based on the Open Fabrics Enterprise Distributionibverbs API (http://www.openfabrics.org).
- Competing networks
High-performance network with RDMA (e.g.
http://www.cs.cmu.edu/~
- In our test environment we used two 240GB Micron M500DC SSDs in RAID0 in each of our two nodes. We connected the two peers using Infiniband
ConnectX -4 10Gbe. We then ran a series of tests to compare the performance of DRBD disconnected (not-replicating), DRBD connected using TCP over Infiniband, and DRBD connected using RDMA over Infiniband, all againstthe performance of the backing disks without DRBD.
For testing random read/write IOPs we used
direct IO
https://www.linbit.com/en/drbd-9-over-rdma-with-micron-ssds/
- Ethernet and
Infiniband are common network connections used in thesupercomputing world.Infiniband was introduced in 2000 to tie memory and the processes of multiple servers together, so communication speeds would be as fast as if they were on the same PCB
- the value of Infiniband as a storage protocol to replace
FibreChannel with several SSD vendors offering Infiniband options. Most likely this is necessary to allow servers to get enough network speed but mostly to reduce latency and CPU consumption. Good Infiniband networks have latency measured in hundreds of nanoseconds andmuch lower impact on system CPU because Infiniband uses RDMA to transfer data. RDMA
- Soft RoCE is a software implementation that allows RoCE to run on any Ethernet network adapter
whether it offers hardware acceleration or not . It leverages the same efficiency characteristics as RoCE, providing a complete RDMA stack implementation over any NIC. SoftRoCE driver implements theInfiniBand RDMA transport over the Linux network stack. It enables a system with standard Ethernetadapter to inter-operate with hardware RoCE adapter or with another system running Soft-RoCE.
- Starting the RDMA services
[
2. RDMA needs to work with pinned memory, i.e. memory which cannot
* soft
* hard
http://www.rdmamojo.com/2014/11/22/working-rdma-using-mellanox-ofed/
- Native
Infiniband /RoCE / Omni-Path Support (RDMA)
https://www.beegfs.io/wiki/NativeInfinibandSupport

The absolute lowest latency
The highest throughput
To make use of
We call this an HCA (Host Channel Adapter). The adapter creates a channel from
In RDMA we setup data channels using a kernel driver. We call this the command channel.
We use the command channel to establish data channels which will allow us to move data bypassing the kernel entirely
Once we have established these data
The verbs API is a maintained in an open source
There is an equivalent project for Windows
Queue Pairs
RDMA operations start by “pinning” memory. When you pin
RDMA is an asynchronous transport mechanism.
https://zcopy.
- The following configurations need to
be modified after the installation is complete:
/etc/
/etc/
/etc/security/limits
The
turn various drivers on or off. The
their default names (such as ib0 and ib1) to more descriptive names. You should edit this file to change how your devices
RDMA communications require that physical memory in the computer
overall computer
applications, it will
/etc/security/limits
Because RDMA applications are so different from Berkeley Sockets-based applications and from normal IP networking,
directly on an RDMA network.
https://lenovopress.com/lp0823.pdf
- Dramatically improves the performance of socket-based applications
VMA is an Open Source library project that exposes standard socket APIs with kernel-bypass architecture, enabling user-space networking for
http://www.mellanox.com/page/software_vma?mtag=vma
- Using RDMA has the following major advantages:
Zero-copy - applications can perform data transfer without the network software stack involvement and data is being sent received directly to the buffers without being copied between the network layers.
Kernel bypass - applications can perform data transfer directly from
No CPU involvement - applications can access remote memory
Message-based transactions - the data
Scatter/gather entries support - RDMA supports natively working with multiple scatter/gather entries i.e. reading multiple memory buffers and sending them as one stream or getting one stream and writing it to multiple memory buffers
You can find RDMA in industries that need at least one
Low latency - For example HPC, financial services, web 2.0
High Bandwidth - For example HPC, medical appliances, storage, and backup systems, cloud computing
Small CPU footprint - For example HPC, cloud computing
there are several network protocols which support RDMA:
RDMA Over Converged Ethernet (RoCE) - a network protocol which allows performing RDMA over Ethernet network. Its lower network headers are Ethernet headers and its upper network headers (including the data) are
Internet Wide Area RDMA Protocol (
http://www.rdmamojo.com/2014/03/31/remote-direct-memory-access-rdma/
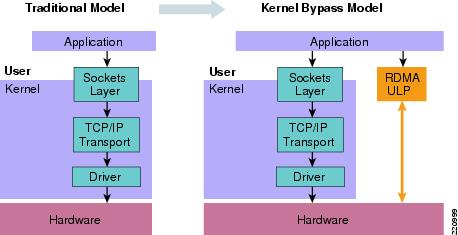
- kernel bypass


nvme over fabrics (NVMe-OF)NVMe basics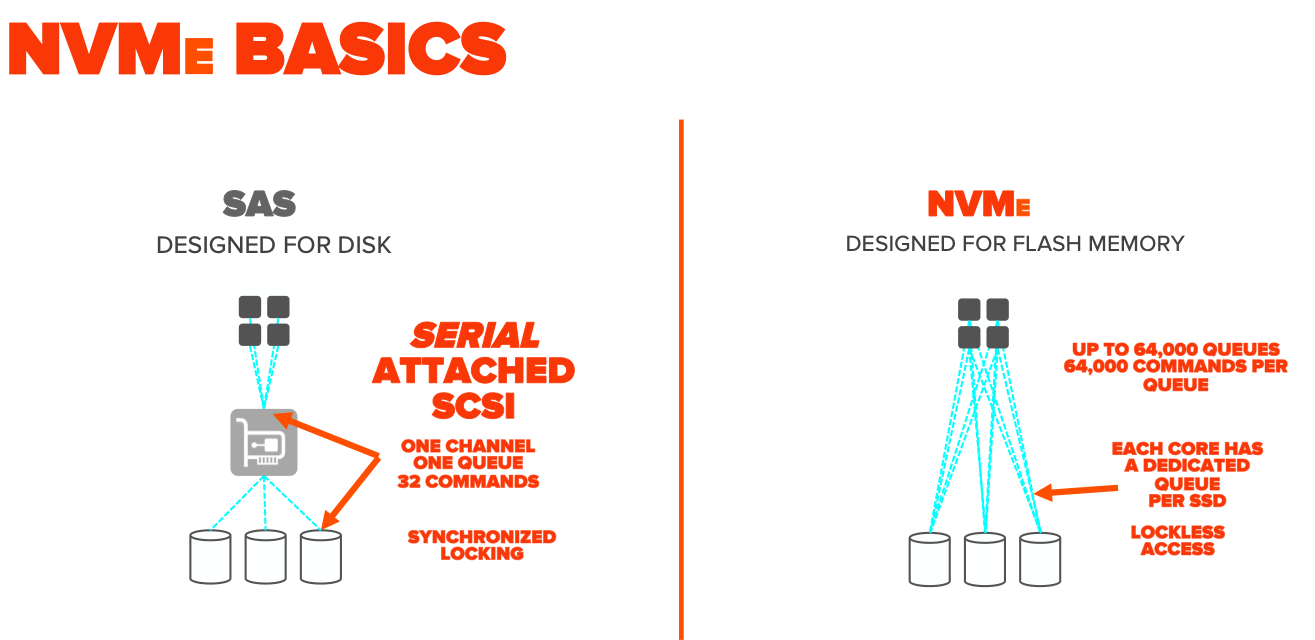
- open fabric alliance
- Facebook Introduces A Flexible
NVMe JBOF - The HPC Project
is focused on developing a fully open heterogeneous computing, networking and fabric platform Optimized for a multi-node processorthat is agnostic to any computing group using x86, ARM, Open Power, FPGA, ASICs, DSP, and GPU silicon onan hardware platform NVMe Over Fabrics-NVMe -OF- Energy efficiency for green HPC
.jpg)


The OpenFabrics Enterprise Distribution (OFED™)/OpenFabrics Software is open -source software for RDMA and kernel bypass applications. OFS is used in business, research and scientific environments that require highly efficient networks, storage connectivity, and parallel computing.
OFS includes kernel-level drivers, channel-oriented RDMA and send/receive operations, kernel bypasses of the operating system, both kernel and user-level application programming interface (API) and services for parallel message passing (MPI), sockets data exchange (e.g., RDS, SDP), NAS and SAN storage (e.g. iSER, NFS-RDMA, SRP) and file system/database systems.The network and fabric technologies that provide RDMA performance with OFS include legacy 10 Gigabit Ethernet, iWARP for Ethernet, RDMA over Converged Ethernet (RoCE), and 10/20/40 Gigabit InfiniBand.
OFS is used in high-performance computing for breakthrough applications that require high-efficiency computing, wire-speed messaging, microsecond latencies and fast I/O for storage and file systems.
OFS delivers valuable benefits to end-user organizations, including high CPU efficiency, reduced energy consumption, and reduced rack-space requirements. OFS offers these benefits on commodity servers for academic, engineering, enterprise, research and cloud applications. OFS also provides investment protection as parallel computing and storage evolve toward exascale computing, and as networking speeds move toward 10 Gigabit Ethernet and 40 Gigabit InfiniBand in the enterprise data center.
https://www.openfabrics.org/index.php/openfabrics-software.html
At the Open Compute Project Summit today Facebook is announcing its flexible NVMe JBOF (just a bunch of flash), Lightning.
Facebook is contributing this new JBOF to the Open Compute Project.Benefits include:
Lightning can support a variety of SSD form factors, including 2.5", M.2, and 3.5" SSDs.
Lightning will support surprise hot-add and surprise hot-removal of SSDs to make field replacements as simple and transparent as SAS JBODs.
Lightning will use an ASPEED AST2400 BMC chip running OpenBMC.
Lightning will support multiple switch configurations, which allows us to support different SSD configurations (for example, 15x x4 SSDs vs. 30x x2 SSDs) or different head node to SSD mappings without changing HW in any way.
Lightning will be capable of supporting up to four head nodes. By supporting multiple head nodes per tray, we can adjust the compute-to-storage ratio as needed simply by changing the switch configuration.
http://www.storagereview.com/facebook_introduces_a_flexible_nvme_jbof
http://www.opencompute.org/projects/high-performance-computing-hpc/
Benefits of NVMe over Fabrics for disaggregation
https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2015/20150811_FA11_Burstein.pdf
https://www.eurotech.com/en/hpc/hpcomputing/energy+efficient+hpc
- PUE for a dedicated building is the total facility energy divided by the IT equipment energy. PUE is an end-user metric used to help improve energy
efficiency in data center operations.
https://eehpcwg.llnl.gov/documents/infra/09_pue_past-tue_future.pdf
- green HPC

- The OpenFabrics Enterprise Distribution (OFED™)/OpenFabrics Software is
open -source software for RDMA and kernel bypass applications.OFS is used in business, research and scientific environments that require highly efficient networks, storage connectivity, and parallel computing. The software provides high-performance computing sites and enterprise data centers with flexibility and investment protection as computing evolves towards applications that require extreme speeds, massive scalability, and utility-class reliability.
The network and fabric technologies that provide RDMA performance with OFS include legacy 10 Gigabit Ethernet,
OFS is available for
OFS for High-Performance Computing.
OFS for Enterprise Data Centers
OFS delivers valuable benefits to end-user organizations, including high CPU efficiency, reduced energy consumption, and reduced rack-space requirements.
https://www.openfabrics.org/index.php/openfabrics-software.html
EasyBuild is a software build and installation framework that allows you to manage (scientific) software on High-Performance Computing (HPC) systemsin an efficient way .
- Using the Open Build Service (OBS) to manage build process
- Welcome to the OpenHPC site. OpenHPC is a collaborative, community effort that
initiated from a desire to aggregatea number of common ingredients required to deploy and manage High-Performance Computing (HPC) Linux clusters including provisioning tools, resource management, I/O clients, development tools, and a variety of scientific libraries.Packages provided by OpenHPC have been pre -built with HPC integration in mind with a goal to provide re-usable building blocks for the HPC community
- This stack provides a variety of common, pre-built ingredients required to deploy and manage an HPC Linux cluster including provisioning tools, resource management, I/O clients, runtimes, development tools, and a variety of scientific libraries.
OpenHPC containers

OpenHPC software stack

OpenHPC v1.3 software components
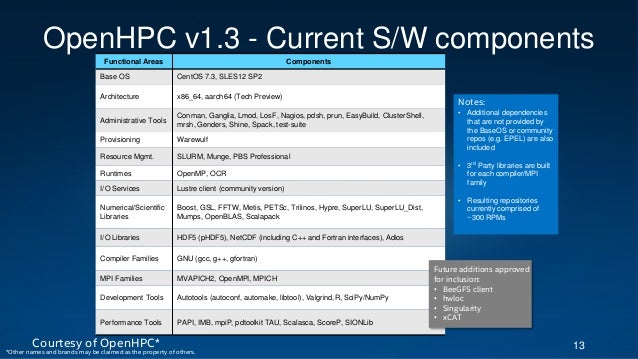
OpenHPC (v1.3.4)
Cluster Building Recipes
CentOS7.4 Base OS
This guide presents a simple cluster installation procedure using components from the
stack.
provisioning tools,
resource management,
I/O clients,
development tools,
and a variety of scientific libraries
software package management, system networking, and PXE booting
Unless specified otherwise,
The examples also presume the use of the BASH login shell
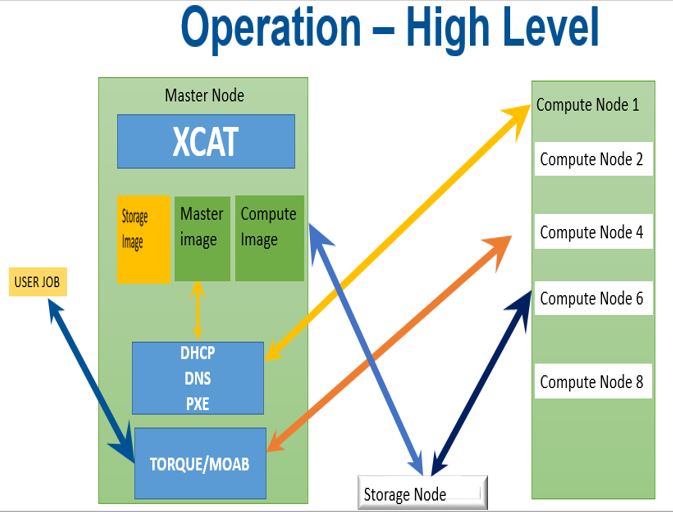
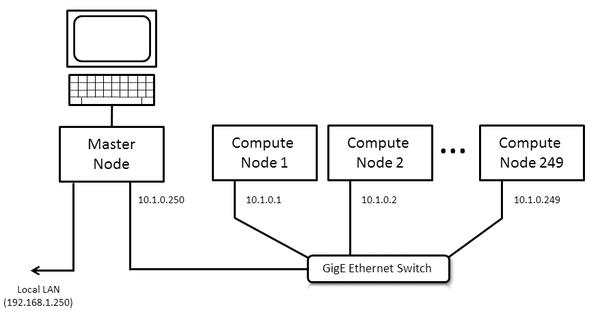
This installation recipe assumes the availability of a single head node master, and four compute nodes.
4-node stateless cluster installation
The master node serves as the overall system management server (SMS) and
subsequently configured to provision the remaining
the
host.
For file systems, we assume that the chosen master server will host an NFS file system that
available to the
The master host requires at least two Ethernet interfaces with eth0 connected to
the local data center network and eth1 used to provision and manage the cluster backend
will
and
and
IP networks
management packets between the host and BMC
in this recipe
message passing and optionally for parallel file system connectivity as well
storage targets
In an external setting, installing the desired BOS on a master SMS host typically involves booting from a
DVD ISO image on a new server. With this approach, insert the CentOS7.4 DVD, power cycle the host, and
follow the distro provided directions to install the BOS on your chosen master host
- http://openhpc.community/downloads/
xCAT offers complete management for HPC clusters,RenderFarms , Grids,WebFarms , Online Gaming Infrastructure, Clouds, Datacenters etc.xCAT provides an extensible framework that is base
https://xcat.org/
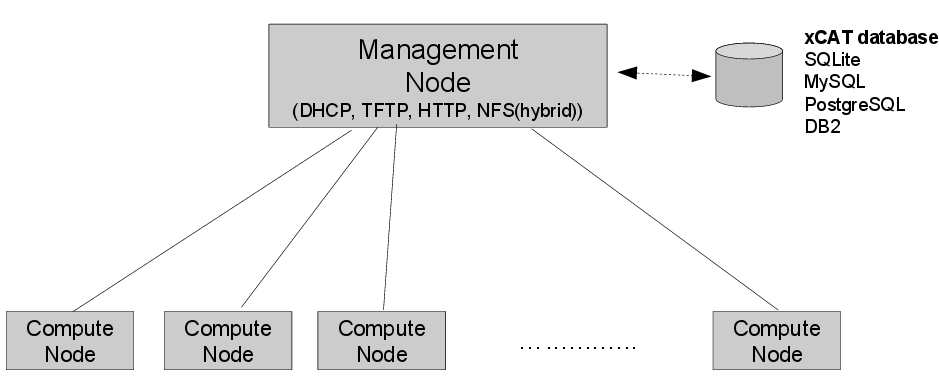
XCAT CLUSTER MANAGEMENT
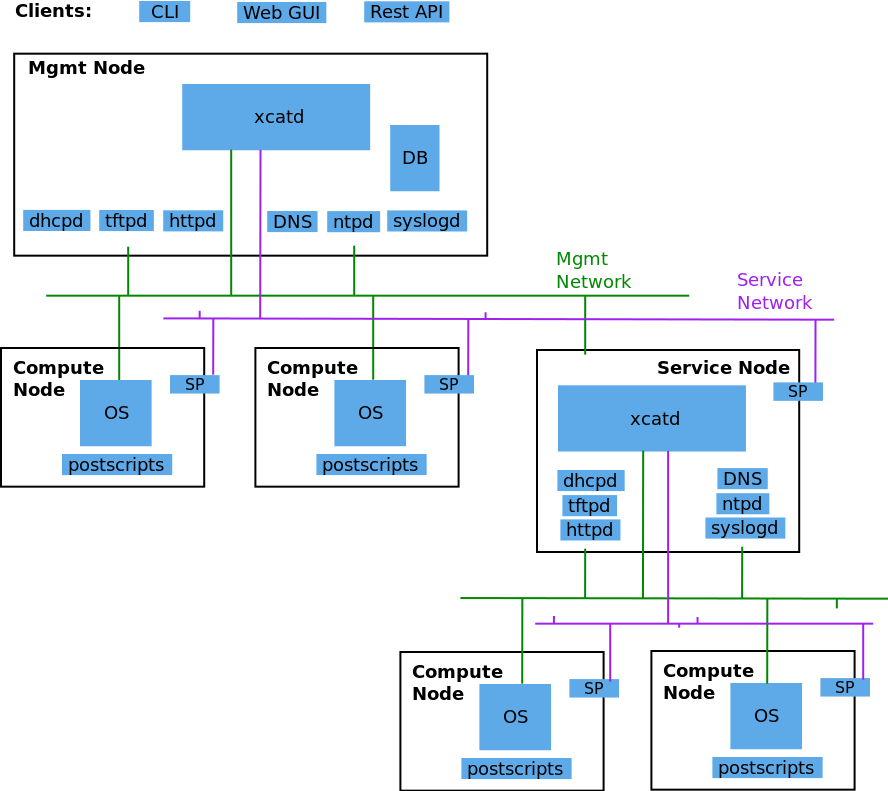
The following diagram shows the basic structure of xCAT
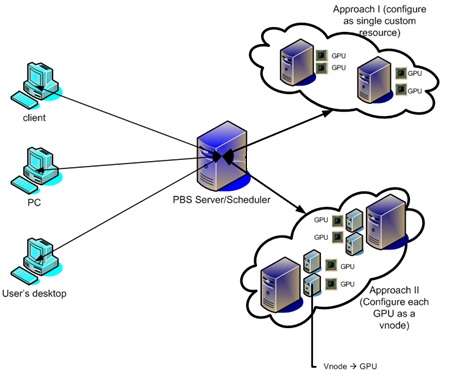
- PBS Professional software optimizes job scheduling and workload management in high-performance computing (HPC) environments
https://www.pbspro.org/

Warewulf is a scalable systems management suite originally developed to manage large high-performance Linux clusters.
http://warewulf.lbl.gov/

- Hence the emergence of the tangible need for supercomputers, able to perform
a large number of checks required inan extremely short time.
The nowadays security solutions require a mix of software and hardware to boost the power of security algorithms, analyze enormous data quantities in real time, rapidly crypt and decrypt data, identify abnormal patterns, check identities, simulate attacks, validate software security proof, petrol systems, analyze video material and many more additional actions
The Aurora on-node FPGAs allow for secure encryption/decryption to coexist with the fastest processors in the market. The Aurora Dura Mater rugged HPC, an outdoor portable highly robust system, can
https://www.eurotech.com/en/hpc/industry+solutions/cyber+security
- This is
particularly truewith respect to operational cybersecurity that, at best, is seen as a necessary evil, and considered asgenerally restrictive of performance and/or functionality. As a representative high-performance open-computing site, NERSC hasdecided to place as few roadblocks as possible for access to site computational and networking resources
- Activate tools such as
SELinux that will control the access throughpredefined roles, but most HPC centers do not activate it as it breaks down the normal operation of the Linux clusters and it becomes harder to debug when applications don’t work as expected
- The traffic among HPC systems connected through public or private network now is
exclusively through encrypted protocols using OpenSSL such as ssh,sftp ,https etc
access to service ports from
https://idre.ucla.edu/sites/default/files/cybersecurity_hpc.pdf?x83242
Some of the HPC centers do not rely on users in protecting their password. So they implementedwhat is called One Time Password (OTP) where usersare given small calculator-like devices to generate a random key to login to the system. However, that is inconvenient for users, as they have to carry this device all the time with them and also add to the operating cost of HPC systems
- Protecting a High-Performance Computing (HPC) cluster against real-world cyber threats is a critical task nowadays, with the increasing trend to open and share computing resources.
- Security of the clusters accesses usually relies on Discretionary Access Control (DAC) and
sandboxing such aschroot , BSD Jail [1] orVserver [2]. The DAC model has proven to be fragile [3].Moreover, virtual containers do not protect against privilege escalation where users can get administration privilegesin order to compromise data
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5633784
GridFTP is a high-performance, secure, reliable data transfer protocol optimized for high-bandwidth wide-area networks. TheGridFTP protocol is based on FTP, thehighly-popular Internet file transfer protocol.
http://toolkit.globus.org/toolkit/docs/latest-stable/gridftp/
- What is GridFTP? •A protocol for efficient file transfer •An extension of FTP •Currently the de facto standard for moving large files across the Internet
Using GridFTP: Some background •You move files between “endpoints” identified by a URI •One of these endpoints is often your local machine, but GridFTP can also be used to move data between two remote endpoints •X.509 (“grid”) certificates are used for authentication to a particular end-point –Usually you’ll have one certificate that you use at both end-points, but this need not be the case
Features of GridFTP•Security with GSI, The Grid Security Infrastructure •Third party transfers •Parallel and striped transfer•Partial file transfer•Fault tolerance and restart •Automatic TCP optimisation
https://www.eudat.eu/sites/default/files/GridFTP-Intro-Rome.pdf
- This paper describes FLEXBUS, a flexible, high-performance
onchip communication architecture featuring a dynamically configurable topology. FLEXBUSis designed to detect run-time variations in communication traffic characteristics, and efficiently adapt the topology of the communication architecture, both at the system-level, through dynamic bridge by-pass,as well as at the component-level, using component re-mapping.
https://www10.edacafe.com/nbc/articles/1/212767/FLEXBUS-High-Performance-System-on-Chip-Communication-Architecture-with-Dynamically-Configurable-Topology-Technical-Paper
- High Performance Computing (HPC) Fabric Builders
Intel® Omni-Path Fabric (Intel® OP Fabric) has a robust architecture and feature set to meet the current and future demands of high performance computing (HPC) at a cost-competitive price to today's fabric. Fabric builders members are working to enable world-class solutions based on the Intel® Omni-Path Architecture (Intel® OPA) with a goal of helping end users build the best environment to meet their HPC needs.
https://www.intel.com/content/www/us/en/products/network-io/high-performance-fabrics.html
- High-Performance Computing Solutions
In-memory high performance computing
Build an HPE and Intel® OPA foundation
Solve
https://www.hpe.com/us/en/solutions/hpc-high-performance-computing.html
Memory-Driven Computing: the ultimate composable infrastructure
RoCE vs.iWARP Q&A
two commonly known remote direct memory access (RDMA) protocols that run over Ethernet: RDMA over Converged Ethernet (
Q. Does RDMA use the TCP/UDP/IP protocol stack?
A.
Q. Can Software Defined Networking features like
A. Yes, most RNICs can also support VxLAN. An RNIC combined all the functionality of a regular NIC (like VxLAN offloads, checksum offloads etc.) along with RDMA functionality.
Q. What layers in the OSI model would the RDMAP, DDP, and MPA map to for
A. RDMAP/DDP/MPA
Q. Are there any best practices identified for running
A. Congestion caused by dropped packets and retransmissions can degrade performance for higher-level storage protocols whether using RDMA or regular TCP/IP. To prevent this from happening a best practice would be to use explicit congestion notification (ECN), or better yet, data center bridging (DCB) to minimize congestion and ensure the best performance. Likewise, designing a fully non-blocking network fabric will also
Q. Is
A.
http://sniaesfblog.org/roce-vs-iwarp-qa/
- A Brief about RDMA, RoCE v1 vs RoCE v2 vs
iWARP
For those who are wondering what these words are, this is a post about Networking and an overview can be, how to increase your network speed without adding new servers or IB over your network, wherein IB stands for
DBC
Data-Center Bridging (DCB) is an extension to the Ethernet protocol that makes dedicated traffic flows possible in a converged network scenario. DCB distinguishes traffic flows by tagging the traffic with a specific value (0-7) called a “CoS” value which stands for Class of Service. CoS values can also
PFC
In standard Ethernet, we
ETS
With DCB in-place the traffic flows
The purpose of Enhanced Transmission Selection (ETS) is to allocate bandwidth based on the different priority settings of the traffic flows, this way the network components share the same physical pipe but ETS makes sure that everyone gets the share of the pipe specified and prevent the “noisy neighbor” effect
Data Center Bridging Exchange Protocol
This protocol is better known as DCBX as in also an extension on the DCB protocol, where the “X” stands for
http://innovativebit.blogspot.com/2018/06/a-brief-about-rdma-roce-v1-vs-roce-v2.html
File Storage Types and Protocols for Beginners
DAS SCSI
FC SAN
NAS
- SMB Multichannel and SMB Direct
SMB Multichannel is the feature responsible for detecting the RDMA capabilities of network adapters to enable SMB Direct. Without SMB Multichannel, SMB uses regular TCP/IP with the RDMA-capable network adapters (all network adapters provide a TCP/IP stack along with the new RDMA stack).
https://docs.microsoft.com/en-us/windows-server/storage/file-server/smb-direct
- What is SMB Direct?
SMB Direct is SMB 3 traffic over RDMA. So, what is RDMA? DMA stands for Direct Memory Access. This means that an application has access (read/write) to a hosts memory directly with CPU intervention. If you do this between hosts it becomes Remote Direct Memory Access (RDMA).
https://www.starwindsoftware.com/blog/smb-direct-the-state-of-rdma-for-use-with-smb-3-traffic-part-i

High-end GPFS HPC box gets turbo-charged
DDN's GRIDScaler gets bigger scale-up and scale-out muscles
- MPICH is a high performance and widely portable implementation of the Message Passing Interface (MPI) standard
https://www.mpich.org/

Catalyst UK Program successfully drives development of Arm-based HPC systems
- The Open MPI Project is an open source Message Passing Interface implementation that
is developed and maintained by a consortium of academic, research, and industry partners. Open MPIis therefore able to combine the expertise, technologies, and resources from all across the High Performance Computing communityin order to build the best MPI library available. Open MPI offers advantages for system and software vendors, application developers and computer science researchers.
https://www.open-mpi.org/


Best Practice Guide – Parallel I/O
Can (HPC) Clouds supersede traditional High Performance Computing?
- The MVAPICH2 software, based on MPI 3.1 standard, delivers the best performance, scalability and fault tolerance for high-end computing systems and servers using
InfiniBand , Omni-Path, Ethernet/iWARP , andRoCE networking technologies.
http://mvapich.cse.ohio-state.edu/

Building HPC Cloud with InfiniBand : Efficient Support in MVAPICH2, Xiaoyi Lu

MVAPICH2 over OpenStack with SR-IOV: An Efficient Approach to Build HPC Clouds

Keynote: Designing HPC, BigD & DeepL MWare for Exascale - DK Panda, The Ohio State University
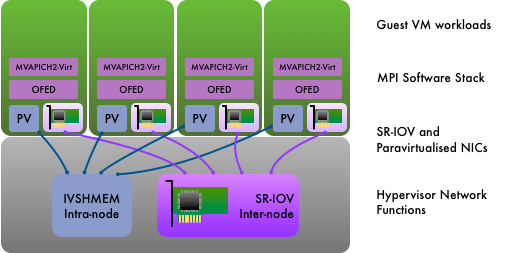
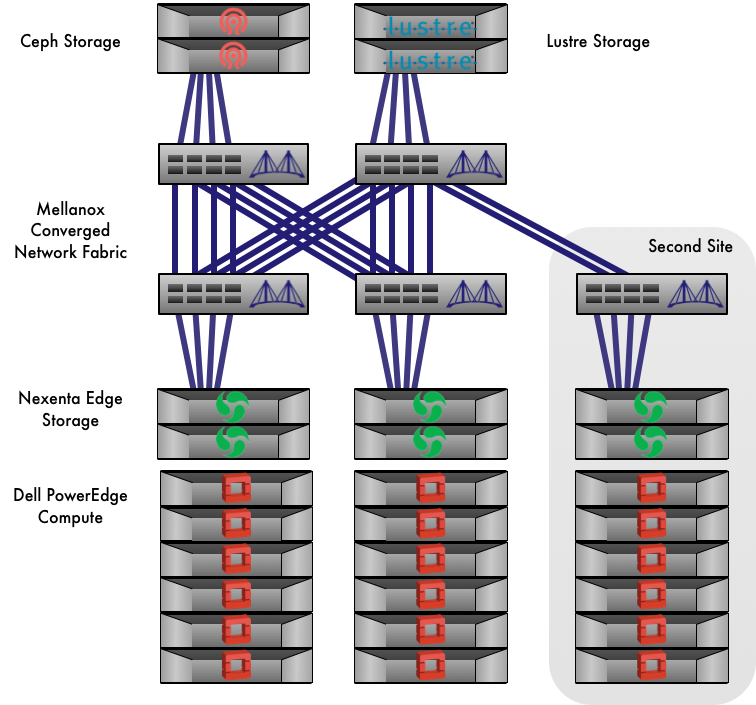
OpenStack and HPC Network Fabrics
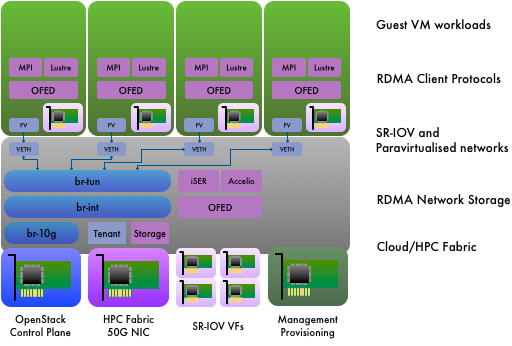
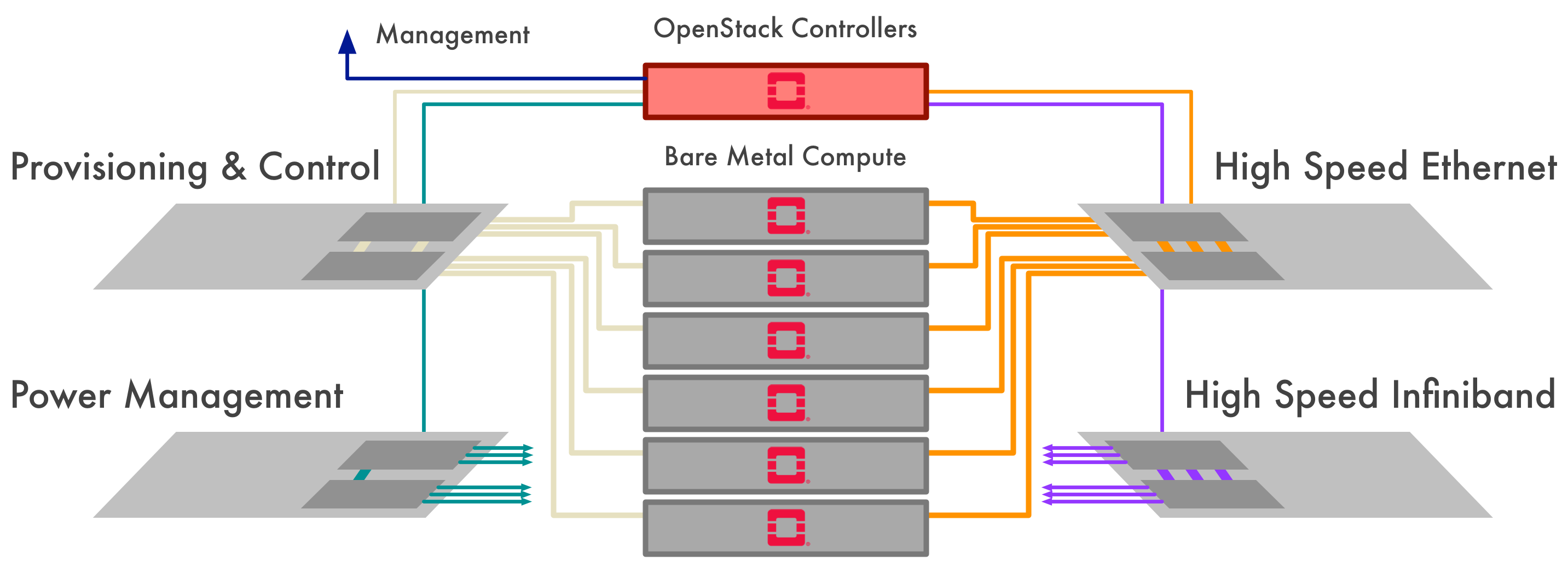
HPC Networking in OpenStack: Part 1
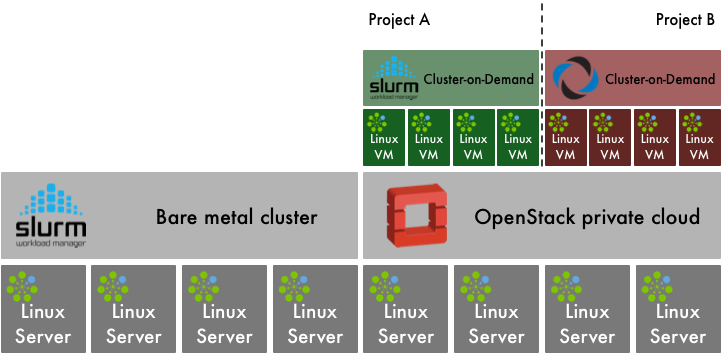
OpenStack and HPC Workload Management

A Self-Adaptive Network for HPC Clouds: Architecture, Framework, and Implementation
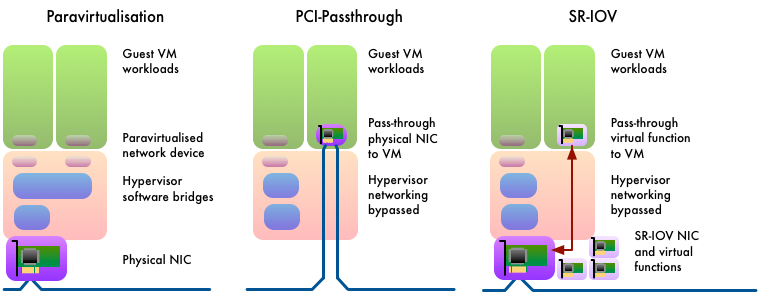
OpenStack and Virtualised HPC
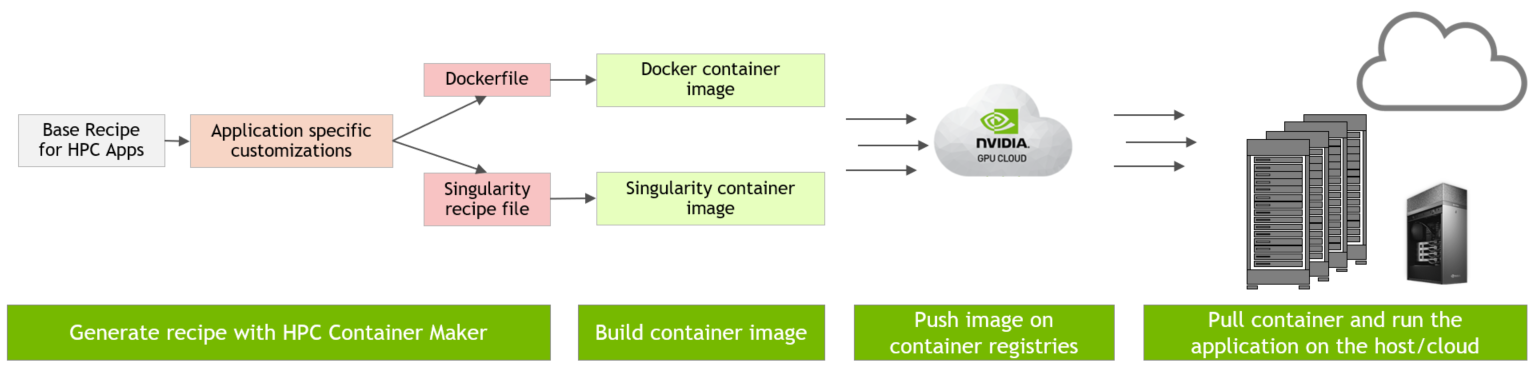
Making Containers Easier with HPC Container Maker

SUSE Linux Enterprise High Performance Computing
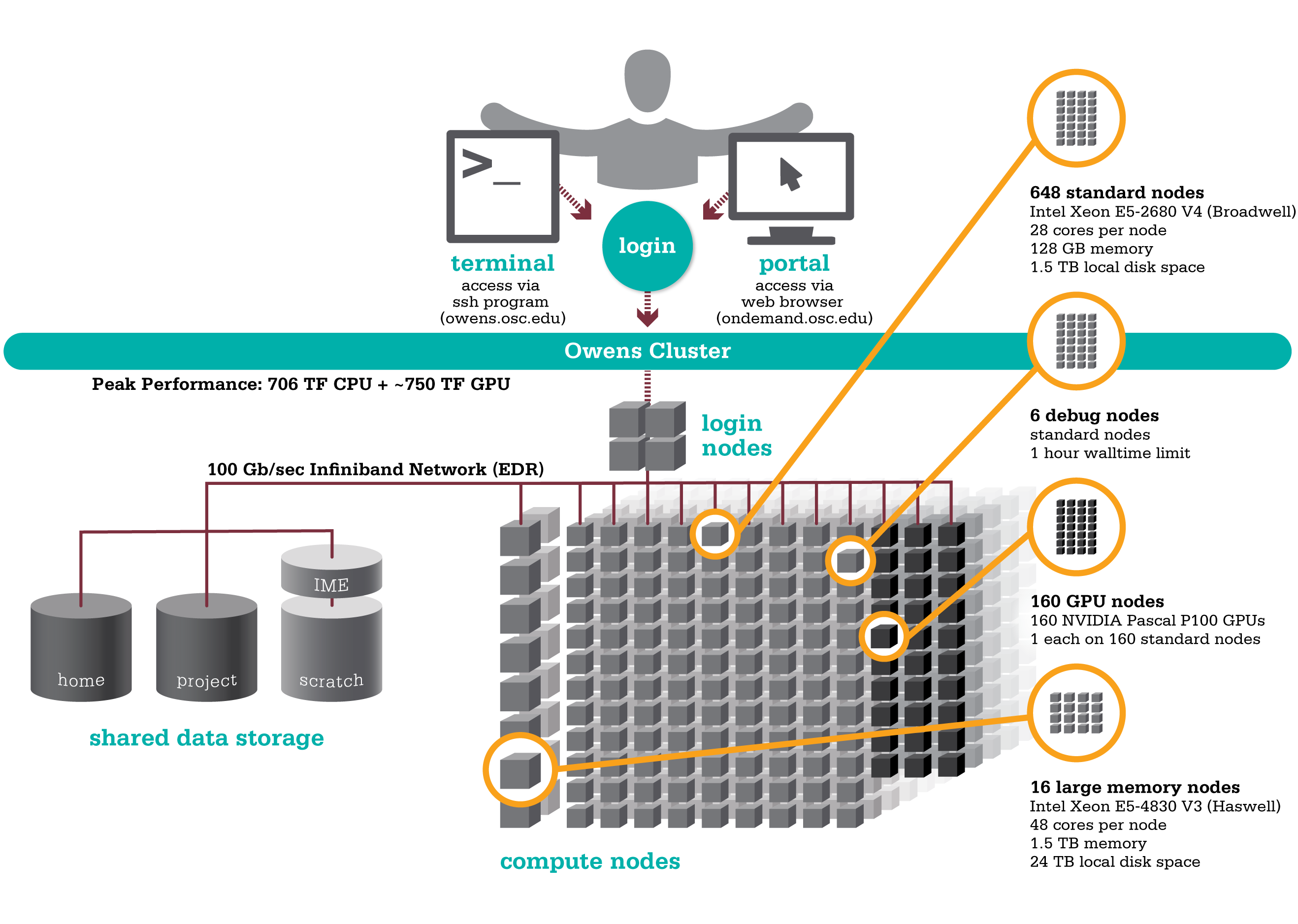

Introduction to Linux & HPC
One Library with Multiple Fabric Support- Intel® MPI Library is a
multifabric message-passing library that implements the open-source MPICH specification. Use the library to create, maintain, and test advanced, complex applications that perform better on HPC clusters based on Intel® processors.
https://software.intel.com/en-us/mpi-library

Supermicro High Performance Computing (HPC) Solutions

PDC Center for High Performance Computing
No comments:
Post a Comment