http://en.wikipedia.org/wiki/Continuous_integration
- Continuous integration attempts to automate building and testing of source code at regular intervals
in order to alert a team as early as possible about problems and merging issues
From Wikipedia: Continuous Integration, "In software engineering, continuous integration (CI) implements continuous processes of applying quality control — small pieces of effort, applied frequently. Continuous integration aims to improve the quality of software, and to reduce the time taken to deliver it, by replacing the traditional practice of applying quality control after completing all development."
From Martin Fowler: "Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily - leading to multiple integrations per day. Each integration
http://obscuredclarity.blogspot.com/2012/04/continuous-integration-using-jenkins.html
- the goal of CD is
validation of every change, preferably in an automated way, sothat it is potentially shippable.
Keep everything under version control
Automate the build
Run unit test in the build
Commit early and often
Build each change
Fix build errors immediately
Keep the build fast
Test in a clone of the production environment
Make it easy to get the latest build results
Ensure that the build process is transparent to everyone
Automate the deployment
Continuous Delivery (CD) adds the following aspect to the Continuous Integration practices:
Any change passing the tests is immediately ready to
This means that the most current version of the product
With a press of a button
Continuous Deployment,
https://www.sap.com/developer/tutorials/ci-best-practices-ci-cd.html
- What is the difference between Continuous Integration, Continuous Deployment & Continuous Delivery?
Continuous Deployment
Continuous Delivery
is the practice of keeping your
https://codeship.com/continuous-integration-essentials
- Continuous Integration Vs Continuous Delivery Vs Continuous Deployment
Continuous delivery is an extension of CI. In this process, developed code is continuously delivered as soon as the developer deems it ready for being shipped.
Continuous Deployment
Continuous Deployment (CD) is the next logical step after continuous delivery. It is the process of deploying the code directly to the production stage as soon as it is developed
Continuous Integration
Continuous Integration (CI) involves building and unit-testing the code changes immediately after the developer checks it in, thus enabling the newly incorporated changes to be continually tested .
http://www.saviantconsulting.com/blog/difference-between-continuous-integration-continuous-delivery-and-continuous-deployment.aspx
- Continuous Delivery is about keeping your application in a state where it
is always able to deploy into production. Continuous Deployment isactually deploying every change into production, every day or more frequently.
https://www.todaysoftmag.com/article/1068/continuous-delivery
- Continuous integration with Maven 2,
Archiva and Hudson
The term 'Continuous integration' originates from the Extreme Programming development process, where it is one of the 12 practices.
http://www.extremeprogramming.org/
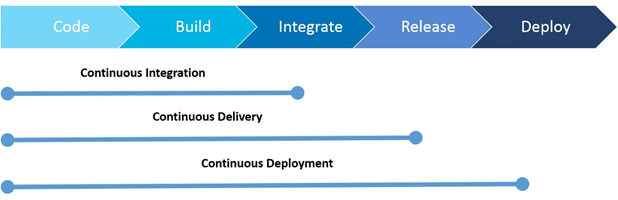
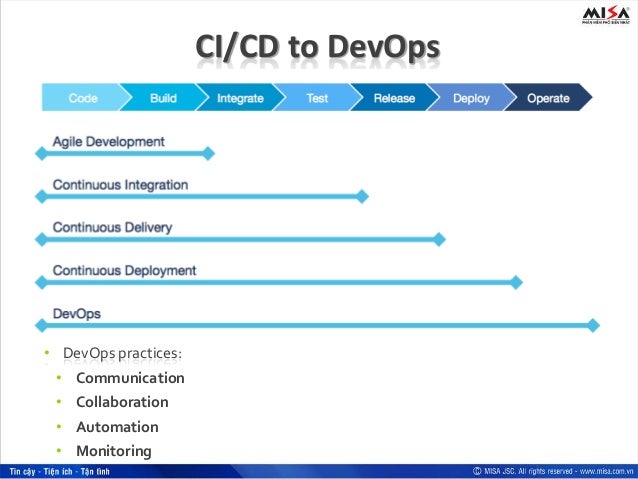
- Continuous Integration (CI) Best Practices with SAP
– Pipeline Suggestions
CI/CD pipeline
The recommended process flow starts with the change by a developer
As a precondition for a merge, applying a 4-eyes principle by doing code reviews is a common practice. Gerrit for, example collects, feedback of human code reviewers together with voter build and test results in one common place as a prerequisite for the merge
When running a Continuous Delivery scenario, the requirements are much higher. The single change does not only have to be successfully integrated into the main line. After the qualification of every single change the product must still have a quality such that it could be released and deployed to production. T
To reach this, the change has to be deployed to an acceptance test system that by any means should correspond to the productive runtime system.
https://www.sap.com/developer/tutorials/ci-best-practices-pipelines.html
- Jenkins vs Travis CI vs Circle CI vs
TeamCity vsCodeship vs GitLab CI vs Bamboo
Travis CI is one of the more common names in the CI/CD ecosystem, created for open source projects
It’s focused on the CI level, improving the performance of the build process with automated testing and an alert system.
Developers can use Travis CI to watch the tests as they run, run a number of tests in parallel, and integrate the tool with Slack, HipChat, Email and so on to get notified of issues or unsuccessful builds.
It has a limited list of third-party integrations, but since the focus is on CI rather than CD
Price: While Travis CI offers free support for open source projects
Circle CI
Circle CI is a cloud-based tool that automates the integration and deployment process.
The tool supports containers, OSX, Linux and can run within a private cloud or your own data center
For Linux users, the first container is free
Circle CI can auto-cancel redundant builds on GitHub.
https://blog.takipi.com/jenkins-vs-travis-ci-vs-circle-ci-vs-teamcity-vs-codeship-vs-gitlab-ci-vs-bamboo/
- Continuous Delivery Part 1: The Deployment Pipeline
Continuous Delivery defines a set of Patterns to implement a rapid, reliable and stress-free process of Software delivery.
This
» Every check in Leads to a Potential Release
» This is very different to the Maven Snapshot-Release process of delivering Software
» Create a Repeatable, Reliable Process for Releasing Software
» Automate almost Everything
» Keep Everything in Version Control
» This includes code, test scripts, configuration, etc
» If It Hurts, Do It More Frequently, and Bring the Pain Forward
» Use the same release process and scripts for each environment
» Build Quality In
» Continuous Integration, Automated Functional Testing, Automated Deployment
» Everyone is Responsible for the Delivery Process
» DevOps
» Continuous Improvement
» Refine and evolve your delivery platform
The most central pattern for achieving the above is creating a Deployment Pipeline.
This pipeline models the steps from committing a change, through
The first step usually builds the module and creates the project artifacts, these artifacts then pass along the pipeline, each step providing more confidence that the release will be successful.
If
» Build Pipeline
» Groovy Builder
»
And the following plug-ins could be useful when building your pipeline:
» HTML Publisher
» Sonar
» Join plugin
» Performance plugin
Build Process
Configuration management
Artifact management
Automated Functional Testing
Automated Deployment
Build Process
When using the Maven release plugin we
Using the Maven release plugin this requires 3 builds, 2 POM transformations and 3 SCM revisions.
Versions are usually hard coded directly into the pom.
When following Continuous Delivery every CI build leads to a potential release meaning there is no concept of snapshots and we must provide a unique version number for each build.
To set the release version of the
Configuration management
Using a declarative configuration management tool such as puppet can ease this concern.
By storing the puppet manifests/modules in version control along with the artifact we can always match up releases with configuration and test them together.
Artifact management
The artifact should be
An artifact repository such as Nexus/
It is often preferable to set up
This way we can grant permission to promote an artifact for an environment to one set of users (e.g. to signify UAT is complete) and then a different set can initialize the release.
We can also regularly clear out repositories used earlier in the pipeline (e.g. remove test artifacts older than 2 weeks, UAT artifacts older than 2 months).
Automated Functional Testing
Functional testing tools such as
Automated Deployment
this generally requires some kind of orchestration server (Possibly a Jenkins slave).
The responsibilities for this server may include updating puppet configs, deploying multiple artifacts to multiple servers in order, running database migrations (Liquibase is often useful for this task), running smoke tests to validate the deployment or performing automated rollback if something goes wrong.
Extra consideration is needed if zero-downtime deployments are required, for example data migrations will need to be forward/backward compatible.
Tools such as Control Tier, Rundeck and Capistrano can be used to help this process.
Continuous Delivery Part 2: Implementing a Deployment Pipeline with Jenkins
This basic pipeline will consist of a number of jobs:
1.Build the artifact
2.Acceptance testing
3.Deploy to Staging
4.Deploy to live
1.Build the artifact Job
The first job in your pipeline is usually responsible for setting the version number, building the artifact and deploying the artifact to an artifact repo. The build task may also include running unit tests, reporting code coverage and code analytics.
2.Acceptance testing Job
The next job is responsible deploying the artifact from the artifact repo into a test environment and then running a suite of automated acceptance tests against the deployment.
We will now add a trigger from the Build job to the Acceptance Test job. From within the Build Job configuration add a “Trigger parameterized buid on other projects” post-build action. In “Projects to Build” specify “Acceptance Test”. Finally Click on “Add Parameters” and select “Current build parameters” to pass our release number to the next job.
3.Deploy to Staging Job
Create a new free-style project job to named “Deploy to Staging”.
This job will be responsible for running the automated deployment and smoke test scripts against the staging environment.
This job should be a manually triggered gate in the pipeline.
To do this open the Acceptance Test job configuration and create a new “Build Pipeline Plugin -> Manually Execute Downstream Project” Post-build action.
4.Deploy to live
You can repeat the process with the “Deploy to Live” Job just like deploy to staging job?
Create the Pipeline
The final task is to create the pipeline. From the Jenkins homepage create a new view by clicking on the “+” tab next to “All”. Give the view a name and specify a “Build Pipeline View”.
http://www.agitech.co.uk/category/continuousdelivery/
- How to Build True Pipelines with Jenkins and Maven
The essence of creating a pipeline is breaking up a single build process in smaller steps, each having its own responsibility
Lets define a true pipeline as being a pipeline that is strictly associated with a single revision within a version control system
This makes sense as ideally we want the build server to return full and accurate feedback for each single revision
As new revisions can be committed any time it is natural that multiple pipelines actually get executed next to each other.
If needed it is even possible to allow concurrent executions of the same build step for different pipelines.
Now lets say we have a continuous build for a multi-module top-level Maven project that we want to break up in the following steps, each step being executed by a separate Jenkins job.
1.create – checkout the head revision, compile and unit-test the code, build and archive the artifacts
2.integration test – run integration tests for these artifacts
3.live deploy – deploy artifacts to a live server
4.smoke test – run smoke tests for these deployed artifacts
For efficiency it is recommended to prevent doing work multiple times within the same pipeline, such as doing a full checkout, compiling code, testing code, building artifacts and archiving artifacts.
The different steps in a pipeline can typically be executed by activating different Maven profiles which actually reuse artifacts that have been created and archived in an upstream build within the same pipeline. The built-in automatic artifact archiving feature is enabled by default in Jenkins. This feature can often be disabled for downstream jobs as these jobs typically do not produce any artifact that need to be reused.
The Maven 2 Project Plugin sets the local maven repository by default to ~/.m2/repository.
Especially when implementing pipelines it is necessary to change this setting to local to the executor in order to prevent interference between concurrent pipeline builds.
if Jenkins nodes are running with multiple executors it is recommended to change the generic local maven repository setting anyway, as the local Maven repositories are not safe for concurrent access by different executors.
With the executors having each there own private local Maven repository, it is no longer needed to let a Maven build actually install the generated artifacts into the local repository, as there are no guarantees that the consecutive steps of the same pipeline are executed by the same executor. Furthermore, as we will see below, the artifacts that are needed in downstream builds will be downloaded into the local repository of the assigned executor anyway.
As every pipeline creates unique artifact versions the size of the executor local Maven repositories can grow very quickly.
Because every pipeline build only needs one specific version of the generated artifacts, there is no point to keep the older versions.
So it is a good idea to cleanup the local Maven repositories on all nodes regularly, at least for the artifacts that are generated by the pipelines.
This can be done by creating a cleanup job for each node executing a simple shell script.
http://java.dzone.com/articles/how-build-true-pipelines
- Creating a build pipeline using Maven, Jenkins, Subversion and Nexus
Builds were typically done straight from the developer’s IDE and manually deployed to one of our app servers.
We had a manual process in place, where the developer would do the following steps.
•Check all project code into Subversion and tag
•Build the application.
•Archive the application binary to a network drive
•Deploy to production
•Update our deployment wiki with the date and version number of the app that was just deployed.
The problem is that there were occasionally times where one of these steps were missed, and it always seemed to be at a time when we needed to either rollback to the previous version, or branch from the tag to do a bugfix.
Sometimes the previous version had not been archived to the network, or the developer forgot to tag SVN.
The Maven release plug-in provides a number of useful goals.
•release:clean – Cleans the workspace in the event the last release process was not successful.
•release: prepare – Performs a number of operations
?Checks to make sure that there are no uncommitted changes.
?Ensures that there are no SNAPSHOT dependencies in the POM file,
?Changes the version of the application and removes SNAPSHOT from the version. ie 1.0.3-SNAPSHOT becomes 1.0.3
?Run project tests against modified POMs
?Commit the modified POM
?Tag the code in Subersion
?Increment the version number and append SNAPSHOT. ie 1.0.3 becomes 1.0.4-SNAPSHOT
?Commit modified POM
•release: perform – Performs the release process
?Checks out the code using the previously defined tag
?Runs the deploy Maven goal to move the resulting binary to the repository.
http://java.dzone.com/articles/creating-build-pipeline-using
- Maven Release Plugin and Continuous Delivery
The idea behind my Continuous Delivery system was this:
•Every check-in runs a load of unit tests
•If they pass it runs a load of acceptance tests
•If they pass we run more tests – Integration, scenario and performance tests
•If they all pass we run a bunch of static analysis and produce pretty reports and eventually deploy the candidate to a “Release Candidate” repository where QA and other like-minded people can look at it, prod it, and eventually give it a seal of approval.
As you can see, there’s no room for the notion of “snapshot” and “release” builds being separate here. Every build is a potential release build
http://devopsnet.com/2011/06/15/maven-release-plugin-and-continuous-delivery/
- Jenkins Pipeline (or simply "Pipeline") is a suite of plugins which supports implementing and integrating continuous delivery pipelines into Jenkins.
Jenkins Pipeline provides an extensible set of tools for modeling simple-to-complex delivery pipelines "as code"
The definition of a Jenkins Pipeline is typically written into a text file (called a Jenkinsfile) which in turn is checked into a project’s source control repository.
https://jenkins.io/doc/pipeline/tour/hello-world/
- Defining a Pipeline
A Pipeline can be created in one of the following ways:
Through Blue Ocean - after setting up a Pipeline project in Blue Ocean, the Blue Ocean UI helps you write your Pipeline’s Jenkinsfile and commit it to source control.
Through the classic UI - you can enter a basic Pipeline directly in Jenkins through the classic UI.
In SCM - you can write a Jenkinsfile manually, which you can commit to your project’s source control repository
it is generally considered best practice to define the Pipeline in a Jenkinsfile which Jenkins will then load directly from source control.
https://jenkins.io/doc/book/pipeline/getting-started/
- Staging is an environment for final testing immediately prior to deploying to production. In software deployment, an environment or tier is a computer system in which a computer program or software component is deployed and executed
https://en.wikipedia.org/wiki/Deployment_environment

- Jenkins
http://jenkins-ci.org/
- Jenkins Backup and copying files
To create a backup of your Jenkins setup, just copy this directory.
The jobs directory contains the individual jobs configured in the Jenkins install. You can move a job from one Jenkins installation to another by copying the corresponding job directory. You can also copy a job directory to clone a job or rename the directory.
Click reload config button in the Jenkins web user interface to force Jenkins to reload configuration from the disk.
http://www.vogella.com/articles/Jenkins/article.html#jenkins_filesystem
- how to configure a simple Continuous Delivery pipeline using Git, Docker, Maven and Jenkins.
Traditional Release Cycle
We have to package the release, test it, set up or update the necessary infrastructure and finally deploy it on the server.
Continuous Delivery
we have to automate the whole release process (including package release, set up/update infrastructure, deploy, final tests) and eliminate all manual steps. This way we can increase the release frequency.
Continuous Delivery is about
reduced risks,
increased reliability,
faster feedback,
accelerated release speed and time-to-market.
Fortunately, Docker is great at creating reproducible infrastructures.
Using Docker we create an image that contains our application and the necessary infrastructure (for instance the application server, JRE, VM arguments, files, permissions).
The only thing we have to do is to execute the image in every stage of the delivery pipeline and our application will be up and running.
Docker is a (lightweight) virtualization, so we can easily clean up old versions of the application and its infrastructure just by stopping the Docker container.
https://blog.philipphauer.de/tutorial-continuous-delivery-with-docker-jenkins/
- We are using a separate parameterized build for doing exactly the same thing. There two ways of doing it.
1) Use "copy artifact" built step together with a "build selector" Parameter to get the right version, then deploy
2) Use a "run parameter" to get the artifact URL, download (ie. with wget) and deploy
The build selector offer three options
- latest
- last stable (works only with "delete old builds" option)
- specific build
Build selector parameter should work very well
you can enter the
particular build# or use other availabe selectors
I added this idea at http://wiki.hudson-ci.org/display/HUDSON/Deploy+Plugin
http://jenkins-ci.361315.n4.nabble.com/How-to-revert-to-a-build-with-artifacts-td2330574.html
- We have a number of libraries that are shared across multiple projects and we wanted this build to run every night and use the latest versions of those libraries even if our applications had a specific release version defined in their Maven pom file
In this way we would be alerted early if someone added a change to one of the dependency libraries that could potentially break an application when the developer upgraded the dependent library in a future version of the application.
We also wanted the nightly build to tag a subversion with the build date as well as upload the artifact to our Nexus “Nightly Build” repository.
The first problem to tackle was getting the current date into the project’s version number
For this I started with the Jenkins Zentimestamp plugin. With this plugin the format of Jenkin’s BUILD_ID timestamp can be changed.
I used this to specify using the format of yyyyMMdd for the timestamp.
The next step was to get the timestamp into the version number of the project.
I was able to accomplish this by using the Maven Versions plugin.
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>versions-maven-plugin</artifactId>
<version>1.3.1</version>
</plugin>
At this point the Jenkins job can be configured to invoke the “versions;set” goal, passing in the new version string to use. The ${BUILD_ID} Jenkins variable will have the newly formatted date string.
This will produce an artifact with the name SiestaFramework-NIGHTLY-20120720.jar
Uploading Artifacts to a Nightly Repository
Since this job needed to upload the artifact to a different repository from our Release repository that's defined in our project pom files, the “altDeploymentRepository” property was used to pass in the location of the nightly repository.
${LYNDEN_NIGHTLY_REPO} is a Jenkins variable containing the nightly repo URL.
Tagging Subversion
Finally, the Jenkins Subversion Tagging Plugin was used to tag SVN if the project was successfully built. The plugin provides a Post-build Action for the job with the configuration section shown below.
So now that the main project is set up, the dependent projects are set up in a similar way, but need to be configured to use the SiestaFramework-NIGHTLY-20120720 of the dependency rather than whatever version they currently have specified in their pom file
This version can then be overriden by the Jenkins job. The example below shows the Jenkins configuration for the Crossdock-shared build.
Enforcing Build Order
the Crossdock-Shared and the Messaging-Shared jobs are “downstream” from the SiestaFramework job. Once both of these jobs complete, a Join trigger can be used to start other jobs.
http://java.dzone.com/articles/setting-nightly-build-process
- A "master" operating by itself is the basic installation of Jenkins and in this configuration the master handles all tasks for your build system
If you start to use Jenkins a lot with just a master you will most likely find that you will run out of resources (memory, CPU, etc.).
At this point you can either upgrade your master or you can setup agents to pick up the load.
As mentioned above you might also need several different environments to test your builds. In this case using an agent to represent each of your required environments is almost a must.
An agent is a computer that is set up to offload build projects from the master and once setup this distribution of tasks is fairly automatic.
The exact delegation behavior depends on the configuration of each project; some projects may choose to "stick" to a particular machine for a build, while others may choose to roam freely between agents.
For people accessing your Jenkins system via the integrated website (http://yourjenkinsmaster:8080), things work mostly transparently. You can still browse javadoc, see test results, download build results from a master, without ever noticing that builds were done by agents. In other words, the master becomes a sort of "portal" to the entire build farm.
Since each agent runs a separate program called an "agent" there is no need to install the full Jenkins (package or compiled binaries) on an agent.
https://wiki.jenkins.io/display/JENKINS/Distributed+builds
- Bamboo vs Jenkins
It’s used for continuous build environments and to keep an eye on jobs running externally from an environment to report on outputs from those jobs. This can be frustrating for developers who would like to use Jenkins for its automation facility but are also looking for the application to assist with the security testing of their code.
It’s OK. Jenkins does support static code analysis from other packages. A plugin is used to capture the results and to parse them. Once these results are passed to Jenkins, the application enables the results to be visually represented in a consistent manner. Jenkins can report on the warnings generated by a build, deliver trend reporting that shows the level of warnings generated by subsequent builds, granular reporting (module, type, package, etc.) for warnings, severity reports, an HTML comparison of source and warnings, stability reporting, project health reporting, scoring for builds that are “warning free”, e-mail reports, etc.
https://www.checkmarx.com/2017/03/12/bamboo-vs-jenkins/
- Bamboo Server vs. Jenkins
Automatically detect, build, test, and merge branches to deploy code continuously to production or staging servers based on the branch name.
Built-in deployment support
Send a continuous flow of builds to test environments and automatically release builds to customers when they're ready – all while maintaining links to issues and commits behind them.
https://www.atlassian.com/software/bamboo/comparison/bamboo-vs-jenkins
- We use Jenkins to organize the following jobs:
- commit (with the maven goal "clean test" to check if the commit broke a unit test)
- integration (with the maven goal "clean integration-test" to check if the commit broke an integration test)
- deploy to nexus (with the maven goal "clean deploy -Dmaven.test.skip=true" to deploy the package in the remote nexus repository)
- inspect on sonar (with the maven goal "sonar:sonar" to inspect the code quality)
- release (with maven goal "mvn --batch-mode clean release:clean release:prepare release:perform -DreleaseVersion=${versions.release} -DdevelopmentVersion=${versions.development}" - we used some groovy to execute this since we had some custom version requirements, but if you could use a maven plugin for incrementing versions all the better. We also trigger this manually.)
- deploy to a server (through ssh - a script is available on the server and gets executed to deploy the latest version to the server)
- selenium (with the maven goal "clean test" - using appropriate profile to execute the selenium tests)
Usually all of these execute serially. But there are cases when you might want to make this parallel. For instance if you have multiple servers, you don't need to wait for the artifact to deploy to one server. You could do that in parallel. You might want maybe the inspect and release to go in parallel if you don't mind the code quality in the current release.
For more on the maven goals/ lifecycle check https://maven.apache.org/guides/introduction/introduction-to-the-lifecycle.html
- CruiseControl
CruiseControl is both a continuous integration tool and an extensible framework for creating a custom continuous build process
http://cruisecontrol.sourceforge.net
- Teamcity
http://www.jetbrains.com/teamcity/index.html?gclid=CK-Tm8L93asCFQJUgwodP2YPSQ
- Apache Continuum
Continuous Integration and Build Server
Apache Continuum™ is an enterprise-ready continuous integration server with features such as automated builds, release management, role-based security, and integration with popular build tools and source control management systems. Whether you have a centralized build team or want to put control of releases in the hands of developers, Continuum can help you improve quality and maintain a consistent build environment.
http://continuum.apache.org/
- Drone is an open source Continuous Delivery platform that automates your testing and release workflows.
https://drone.io/
http://www.atlassian.com/software/bamboo/overview
https://www.gocd.org/
http://hudson-ci.org/
- Zuul-ci
- Keep your builds evergreen by automatically merging changes only if they pass tests.
- CI/CD with Ansible
- Use the same Ansible playbooks to deploy your system and run your tests
- Bamboo
http://www.atlassian.com/software/bamboo/overview
- GoCD is an open source build and release tool from ThoughtWorks. GoCD is an open source tool which is used in software development to help teams and organizations automate the continuous delivery of software.
https://www.gocd.org/
- Hudson
http://hudson-ci.org/
Hudson Continuous Integration quick start
- Using snapshots for components that are under development is required for the automated continuous integration system to work properly. Note that a fixed version, non-snapshot versioned artifact should not be modified and replaced. The best practice is that you should not update artifacts after they are released. This is a core assumption of the Maven approach
this assumption is not correct in enterprise software development, where vendors and end users do sometimes update "finished" artifacts without changing the version number, for example through patching them in place. Even though it is possible to violate this rule, every attempt should be made to comply to ensure integration stability.
Every project that is part of continuous integration must specify a distributionManagement section in its POM
This section tells Maven where the artifacts are going to be deployed at the end of the build process, that is, which repository (local or remote).
this would be the Archiva repository. Deploying artifacts to a repository makes them available for other projects to use as dependencies.
You must define a distributionManagement section that describes to which repository to deploy snapshots and releases. It is recommended that the distributionManagement configuration be placed at a common inherited POM that is shared among all projects
There are some important settings that govern how and when Maven will access repositories:
Update Policy: This controls how often Maven will check with a remote repository for updates to an artifact that it already has in its local repository. Configure your snapshot repository in your settings.xml in Hudson to use updatePolicy as always. The effect of updatePolicy is on your development systems. The default value is daily. If you want to integrate the changes as they occur in Hudson, you should change their updatePolicy accordingly.
Server credentials: This tells Maven the credentials that are needed to access a remote repository; typically Maven repositories will require you to authenticate before you are allowed to make changes to the repository, for example, publishing a new artifact). Unless you have given the Archiva guest user global upload privileges, which is not recommended, you must specify correct credentials for the snapshot repository in the servers section. You should have a unique Hudson user with snapshot repository upload permissions
Hudson provides a number of ways to manage a continuous integration build's triggers in Hudson. These include manual and automated triggers. The option to manually start a build is always available for any job. When choosing an automated trigger, you may consider factors like the structure of the project, the location of the source code, the presence of any branches, and so on
This type of build trigger is vital to establishing a healthy continuous integration build. As changes are committed to project source, Hudson triggers the builds of the associated Hudson jobs. The trigger does this by periodically checking the associated Subversion URL for changes.
To enable this trigger, select the Poll SCM option. You must then provide a cron expression to determine the schedule Hudson uses to poll the repository.
you can use the SNAPSHOT dependency trigger to monitor the Maven repository for changes in such dependencies. When an updated SNAPSHOT dependency has been detected, the build will trigger and download the new dependency for integration.
Hudson should be configured to send notifications to the correct parties when the build breaks
Hudson should have each user registered as a unique user. The Hudson username must match the Subversion username that they ordinarily commit under. Hudson relies on this name to look up the proper contact email to send a notification to.
http://docs.oracle.com/middleware/1212/core/MAVEN/ci_environmement_hudson.htm
- There are certainly other CI engines out there, such as the primary open source rivals to Hudson: Apache Continuum and CruiseControl
We've worked with both Continuum and CruiseControl in the past, and consider them to be functional – in an adequate sort of way. Continuum's web-based front-end isn't bad, and for the most part it does what it's designed to do. We've found CruiseControl to be more competent than Continuum when it comes to stability, although we must admit that we have not tried any of Continuum's newer builds. But when it comes to ease of configuration Hudson wins, hands down. If, like us, you're visually-oriented, and if you find it painful to edit an XML file to configure CI (as is the case with CruiseControl), Hudson's graphical user interface just makes perfect sense
configure Hudson to access the Subversion repository, and perform continuous integration builds from there.
Let's go ahead and set up the post-commit hook now. But first, go back into the testWebapp Hudson job configuration and uncheck the "Poll SCM" checkbox. Then click "Save". Now we're ready to configure the post commit hook. Our repository resides in /var/lib/svn/repositories/testWebApp (see above):
http://www.openlogic.com/wazi/bid/188149/Creating-a-Continuous-Integration-Server-for-Java-Projects-Using-Hudson
- Loose coupling of components of the application, which reduces the impact of change
In this new paradigm, many development organizations are also adopting iterative development methodologies to replace the older waterfall-style methodologies. Iterative, agile development methodologies focus on delivering smaller increments of functionality more often than traditional waterfall approaches.
Continuous integration is a software engineering practice that attempts to improve quality and reduce the time taken to deliver software by applying small and frequent quality control efforts. It is characterized by these key practices:
Use of a version control system to track changes.
All developers commit to the main code line, head and trunk, every day.
The product is built on every commit operation.
The build must be automated and fast.
There should be automated deployment to a production-like environment.
Automated testing should be enabled.
Results of all builds are published, so that everyone can see if anyone breaks a build.
Deliverables are easily available for developers, testers, and other stakeholders
Repository Management with Archiva
A typical Maven environment consists of Maven installation on each developer's local machine, a shared Maven repository manager within the enterprise, and one or more public Maven repositories where dependencies are stored.
internal Maven repository for two purposes:
To act as a proxy or cache for external Binary repositories, like Maven's central repository, so that dependencies are downloaded only once and cached locally so that all developers can use them.
To store artifacts that are built by the developers so that they can be shared with other developers or projects.
In a typical enterprise that use Archiva, Archiva is set up on a server that is accessible to developers and build machines. The enterprise defines the following repositories on this server:
A mirror of Maven's central repository
An internal repository to store internally developed artifacts that are completed or published
A snapshot repository to store internally developed artifacts that are under development and not completed yet.
Archiva also provides the ability to manage expiration of artifacts from your snapshot repository. Each time that you execute a build, artifacts are created and stored in the snapshot repository. If you are using continuous integration, you may want to execute builds several times each day. The best practice is to configure Archiva to remove these stored artifacts after a certain amount of time (for example, one week).
Alternatively, you can configure Archiva to keep just the last n versions of each artifact. Either approach helps to automatically manage the expiration and deletion of your snapshot artifacts.
Continuous Integration with Hudson
typically this automation include steps such as:
Initiating a build whenever a developer commits to the version control system
Checking out the code from the version control system
Compiling the code
Running unit tests and collating results (often through JUnit)
Packaging the code into a deployment archive format
Deploying the package to a runtime environment
Running integration tests and collating results
Triggering the build to the Maven snapshot repository
Alerting developers through email of any problems
However, it is also possible to use the build system to enforce compliance with corporate standards and best practices. For example, enterprises can include the following steps in the build process:
Running code coverage checks to ensure that an appropriate number of unit tests exist and are executed
Running code quality checks to look for common problems
Running checks to ensure compliance with naming conventions, namespaces, and so on
Running checks to ensure that documentation is included in the code
Running checks to ensure that the approved versions of dependencies are used and that no other dependencies are introduced without approval
http://docs.oracle.com/middleware/1212/core/MAVEN/introduction.htm#BABIBEIJ
- Committed change sets tend to be smaller and occur more frequently than in a noncontinuous integration process.
You must commit the active trunk or branch code for the target release so that the continuous integration system can perform an integration build
http://docs.oracle.com/middleware/1212/core/MAVEN/config_svn.htm
- everything has to be changed in a XML configuration file making it error prone and a pain in the boat to change. Although CruiseControl comes with a web application that can be deployed to any kind of Servlet container jobs can’t be easily configured, monitoring is basic and extensibility would take a lot of effort. Version 2.7 comes with a dashboard trying to fix these shortcomings. Frankly, it doesn’t convince me as an easy-to-use user interface which would even allow beginners to Continuous Integration to get an easy access. Once you were in Hudson-land you never want to go back.
- 12.2.1 Distribution Management
Every project that is part of continuous integration must specify a distributionManagement section in its POM. This section tells Maven where the artifacts are going to be deployed at the end of the build process, that is, which repository (local or remote)
Deploying artifacts to a repository makes them available for other projects to use as dependencies.
You must define a distributionManagement section that describes which repository to deploy snapshots and releases to
It is recommended that the distributionManagement configuration be placed at a common inherited POM that is shared among all projects such as the oracle-common POM
http://docs.oracle.com/middleware/1212/core/MAVEN/ci_environmement_hudson.htm#A999401
- Backup Plugin - hudson - Hudson Wiki
wiki.hudson-ci.org › Dashboard › hudson › Plugins?
- We use groovy scripts/dsl(s) to generate all of the above jobs - great when you have multiple projects and takes least time when you start a new project.
My best experience with CI was when on top of all this we used Gerrit ( https://code.google.com/p/gerrit/ ) to keep the trunk branch clean. No person was allowed to commit crappy code (at least not if at least one person gave a -. If you had 2 pluses and no minuses, your commit was free to go). Not only that the trunk stayed clean, but after 2/3 weeks of arguing (constructively) the whole team managed to absorb the level of knowledge of the most experienced in different areas. We also agreed easier on different conventions. Although people's will and professionalism should do this, this tool forces you constantly to think about such things.
Another way would be to directly comment in git-hub although it doesn't allow rules as much as I know. Or you might use some plugins for reviewing.
Good practice when using git is also to commit in a separate branch (separate branch for each story) so that if something is not proper, it is patched in a separate branch and it gets fixed before it gets to the trunk.
I might be missing something, but I hope al least the above gonna be help
We'll geek out in a minute to help you get Hudson up and running. But first, we'd like to outline how we are currently integrating Hudson into our development workflow, as well as how we hope to take advantage of Hudson in the near future. As of right now, we've setup Hudson to begin the build and testing process every time that we commit upstream to a master code repository on GitHub. By configuring a post-receive hook, GitHub fires off a simple HTTP request to our Hudson server to begin the build process. Hudson clones our Drupal code repository and then executes a short Bash script that uses Drush to install, configure, and test our Drupal distribution. Once the build process is complete, this same Bash script triggers Drupal to run our test scripts (in our case, SimpleTest). Upon completion of the tests, Hudson emails us with the results of our automated tests.
Admittedly, the percentage of automated test coverage of our distros is not high at this point. Since a lot of the user stories that we want to test in our distros revolve around basic content management tasks, writing automated tests often takes considerably more time than configuring the features themselves. We're playing around with using Selenium so that our project and product managers can record tests the first time they click through a site to review features - and then including these tests in our Hudson workflow. This would be a far cry from test-driven development, but it's a start.
For our work with Meedan.net, we are also toying around with the idea of integrating GitHub's Jekyll-based wiki with our project management tool, Pivotal Tracker (PT). Leveraging Pivotal Tracker's API, in theory, we could write out the associated user stories to a GitHub wiki page every time that we close a release in PT. If a GitHub push is tagged with that release, we would then have a wiki page write-up of all the user stories that should be tested with a given Hudson build. That wiki page would then become the test script for repeatable manual testing by our product team.
http://thinkshout.com/blog/2010/09/sean/beginners-guide-using-hudson-continuous-integration-drupal
You can think of a pipeline as a distributed, higher-level, continuously-running Makefile.
Each entry under resources is a dependency, and each entry under jobs describes a plan to run when the job is triggered (either manually or by a get step).
Jobs can depend on resources that have passed through prior jobs. The resulting sequence of jobs and resources is a dependency graph that continuously pushes your project forward, from source code to production.
https://concourse-ci.org/
Adoptinga Jobs -as-Code approach can transform your business for agile application delivery and processes by avoiding rework and headaches related to your application delivery.
Jobs-as-Code allows your business to reap the benefits of a truly automated and continuous delivery pipeline while ensuring the highest levels of availability and reliability.
The term “jobs” in Jobs-as-Code refers to the automation rules that define how batch applications are run.
These rules define what to run, when to run it, how to identify success or failure, and what action needs tobe taken .
Traditionally, Operations defined these rules only at the end of software developmentlifecycle , which meant these jobs were not tested at the same time that the rest of the application was built .
This approach often led to wasted time in production, hard-to-fix errors and unplanned work,as a result of poor communication and manual intervention.
with the Jobs-as-Code approach, developers can now include jobs as artifacts in the continuous DevOps delivery pipeline the same waythe Java or Python code is managed through the entire software development process today.
https://www.bmc.com/blogs/what-is-jobs-as-code/
- Concourse is an open-source continuous thing-doer.
You can think of a pipeline as a distributed, higher-level, continuously-running Makefile.
Each entry under resources is a dependency, and each entry under jobs describes a plan to run when the job is triggered (either manually or by a get step).
Jobs can depend on resources that have passed through prior jobs. The resulting sequence of jobs and resources is a dependency graph that continuously pushes your project forward, from source code to production.
https://concourse-ci.org/
- What Is “Jobs-as-Code
” ?
Adopting
Jobs-as-Code allows your business to reap the benefits of a truly automated and continuous delivery pipeline while ensuring the highest levels of availability and reliability.
The term “jobs” in Jobs-as-Code refers to the automation rules that define how batch applications are run.
These rules define what to run, when to run it, how to identify success or failure, and what action needs to
Traditionally, Operations defined these rules only at the end of software development
This approach often led to wasted time in production, hard-to-fix errors and unplanned work,
with the Jobs-as-Code approach, developers can now include jobs as artifacts in the continuous DevOps delivery pipeline the same way
https://www.bmc.com/blogs/what-is-jobs-as-code/
- Integrating Ansible with Jenkins in a CI/CD process
The purpose of using Ansible in the pipeline flow is to reuse roles and Playbooks for provisioning, leaving Jenkins only as a process orchestrator instead of a shell script executor
Example Pipeline Flow
The process starts by pulling the application source code from Github.
The next thing to do is to update the project version according to the build number
After updating the project’s version, Jenkins starts building the source code using Maven.
After a successful compilation, the pipeline will perform unit tests.
If nothing goes wrong during the unit tests, the pipeline flow initiates the integration tests.
The output from unit and integration tests is a coverage report, which will be one of the artifacts used by Sonar server to generate quality metrics.
The other one is the application source code.
The Jenkins server provides an interface for someone with the right permissions to manually promote the build.
After the approval, the pipeline continues to execute the flow and goes on to the next step, which is to upload the compiled artifact to the Nexus repository.
Then we have a new application snapshot ready to be deployed.
The pipeline flow just sets the required parameters like the compiled artifact URL and the target host to execute the Ansible Playbook afterward.
The Playbook is used to automate all target host configuration.
After the Ansible Playbook execution, the last step could be to send a notification to every stakeholder regarding the results of the new deployment via email or slack.
Ansible Playbooks
Ansible played a fundamental role twice in this lab. First, it automated all the infrastructure for this lab, then we used it as a tool to deploy our application through Jenkins pipeline.
Application deployment
The pipeline has been designed to prepare the application binaries, now called “artifact”, and to upload them in Nexus.
https://www.redhat.com/en/blog/integrating-ansible-jenkins-cicd-process
- Jenkins pipeline as code is a concept of defining Jenkins build pipeline in Jenkins DSL/Groovy format.
There are two types of Jenkins pipeline code.
Declarative Pipeline
Scripted Pipeline
https://devopscube.com/jenkins-pipeline-as-code/
Thank you for sharing wonderful information with us to get some idea about it.
ReplyDeleteDocker Training in Hyderabad
Kubernetes Training in Hyderabad
Docker and Kubernetes Training
Docker and Kubernetes Online Training
Nice Post. Keep updating more and more DevOps Online Training
ReplyDeleteThank you for sharing valuable information.This article is very useful for me valuable info about fakecineaste DevOps Training in Bangalore | Certification | Online Training Course institute | DevOps Training in Hyderabad | Certification | Online Training Course institute | DevOps Training in Coimbatore | Certification | Online Training Course institute | DevOps Online Training | Certification | Devops Training Online
ReplyDeleteThanks for sharing. Keep updating more and more SEO Training
ReplyDeleteJava Training
python Training
Salesforce Training
Tableau Training
AWS training
Dot Net Training
DevOps Training
Selenium Training