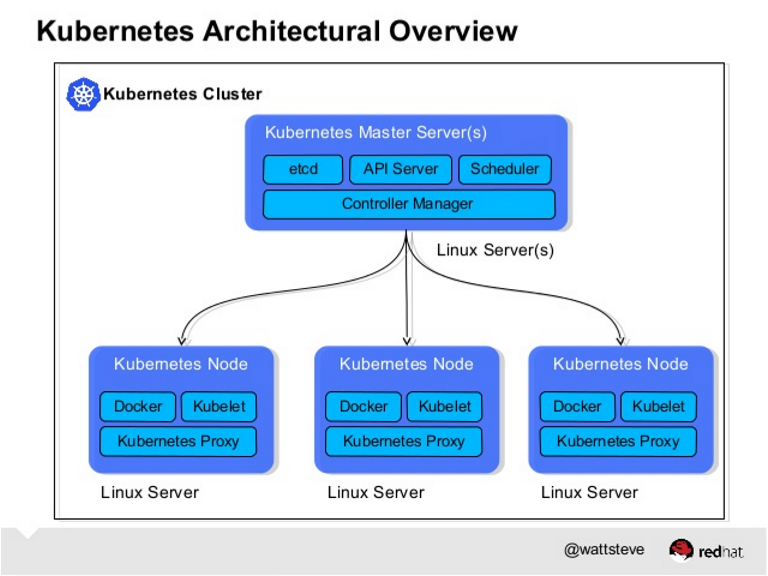
Kubernetes is an orchestration framework for Docker containers which helps expose containers as services to the outside world. The minion is the node on which all the services run.Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications
https://www.tutorialspoint.com/docker/docker_kubernetes_architecture.htm
The kubelet is responsible for running containers on your hosts.
CNI stands for Container Networking Interface which is a spec that defines how network drivers should interact with Kubernetes
Docker Swarm provides an overlay networking driver by default — but with kubeadm this decision is left to us.
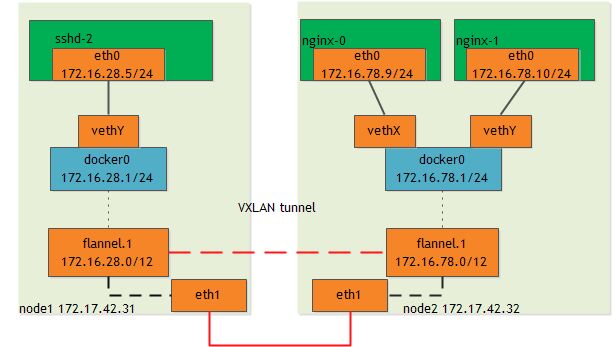
how to use the most similar driver to Docker's overlay driver (flannel by CoreOS)
Flannel provides a software defined network (SDN) using the Linux kernel’s overlay and ipvlan modules.
https://medium.com/@Grigorkh/install-kubernetes-on-ubuntu-1ac2ef522a36






- I now believe containers are the deployment format of the future. They make it much easier to package an application with its required infrastructure. While tools such as Docker provide the actual containers, we also need tools to take care of things such as replication and
failovers ,as well as APIs to automate deployments to multiple machines.
Load balancing with
When working with
It’s possible to expose a service directly on a host machine port—and this is how
A two-step load-balancer setup
We found that a much better approach is to configure a load balancer such as
The Kubernetes community is
Blue-green deployments in
A blue-green deployment is one
Logging
There are plenty of open-source tools available for logging. We
Monitoring
Our application components post metrics to an InfluxDB time-series store. We also use
Data stores and
Besides data stores and our
https://techbeacon.com/one-year-using-kubernetes-production-lessons-learned
- A pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), with shared storage/network, and a specification for how to run the containers. A pod’s contents are always co-located and co-
scheduled, and run in a shared context.
Minikube starts a single nodekubernetes cluster locally forpurposes of development and testing.Minikube packages and configures a Linux VM, Docker and allKubernetes components, optimized for local development
The latest
The latest version of
https://kubernetes-v1-4.github.io/docs/getting-started-guides/minikube/
- the many benefits it provides, including:
Portability:
Open-source:
Install
The two all-in-one deployment options described below install
. Using
Installer-based
This method usually deploys
CoreOS Tectonic
Everything from scratch
Platform9 Managed
Kube2Go
Install
If placing all of your data and workloads in a public cloud is acceptable, the easiest way to deploy and consume
https://platform9.com/docs/install-kubernetes-the-ultimate-guide/
- abbreviating the words based on their first letter, last letter, and
number of letters in between.This is why you’ll sometimes see i18n for internationalization and l10n for localization. of course our favoritekubernetes (k8s).
- However, if you have specific
IaaS , networking, configuration management, or operating system requirements not met by any of those guides, then this guide will provide an outline of the steps you need to take
Cloud Provider
Nodes
You can use virtual or physical machines.
While you can build a cluster with 1 machine,
Many Getting-started-guides
Other nodes can have any reasonable amount of memory and
Network Connectivity
When creating a cluster, you need to allocate a block of IPs for
The simplest approach is to allocate a different block of IPs to each node in the cluster as
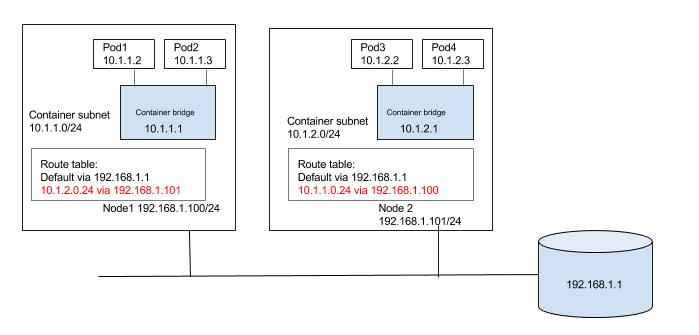
A process in one pod should be able to communicate with another pod using the IP of the second pod.
Using an overlay network
An overlay network obscures the underlying network architecture from the pod network through traffic encapsulation (for example
Encapsulation reduces performance, though exactly how much depends on your solution.
Without an overlay network
Configure the underlying network fabric (switches, routers, etc.) to
This does not require the encapsulation provided by an overlay, and so can achieve better performance.
Software Binaries
You will need binaries for:
A container runner, one of:
docker
Selecting Images
You will run
Build your own images.
Useful if you are using a private registry.
The release contains files such as
You can verify if the image
Security Models
There are two main options for security:
Access the
Use a firewall for security.
This is easier
Access the
Use
This is the recommended approach.
Configuring certs can be tricky.
All nodes should run
Using Configuration Management
The previous steps all involved “conventional” system administration techniques for setting up machines.
There are examples of
The
https://kubernetes.io/docs/getting-started-guides/scratch/
The problem was divided Kubernetes and Application.
it has a very similar modus operandi to Terraform, which helps to reduce cognitive load
it is
with the combination of the -C flag (check mode) and -D flag (diff mode)
formatting the ephemeral disks that come with our VMs and mounting them in a place where we
The rest of the
A common question I get is “Why not just use Terraform for the whole thing (config files, packages etc?
https://www.weave.works/blog/provisioning-lifecycle-production-ready-kubernetes-cluster/
- with the combination of the -C flag (check mode) and -D flag (diff mode)
ansible will show us where the live system differs from the checked in config.
We use this (and prom-run) to build an
formatting the ephemeral disks that come with our VMs and mounting them in a place where we
https://docs.ansible.com/ansible/latest/user_guide/playbooks_checkmode.html
Kubernetes
Does not provide application-level services, such as middleware (e.g., message buses), data-processing frameworks (for example, Spark), databases (e.g.,
https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
- Docker Swarm is a clustering and scheduling tool for Docker containers. With Swarm, IT administrators and developers can establish and manage a cluster of Docker nodes as a single virtual system.
A swarm is made up of multiple nodes, which can beeither physical or virtual machines. The basic concept is simple enough: rundocker swarm init to enable swarm mode and make your current machine aswarm manager, then run docker swarm join on other machines to have them join the swarm as workers.


https://searchitoperations.techtarget.com/definition/Docker-Swarm
https://docs.docker.com/get-started/part4/#set-up-your-swarm
- Easily Deploy Applications at Any Scale
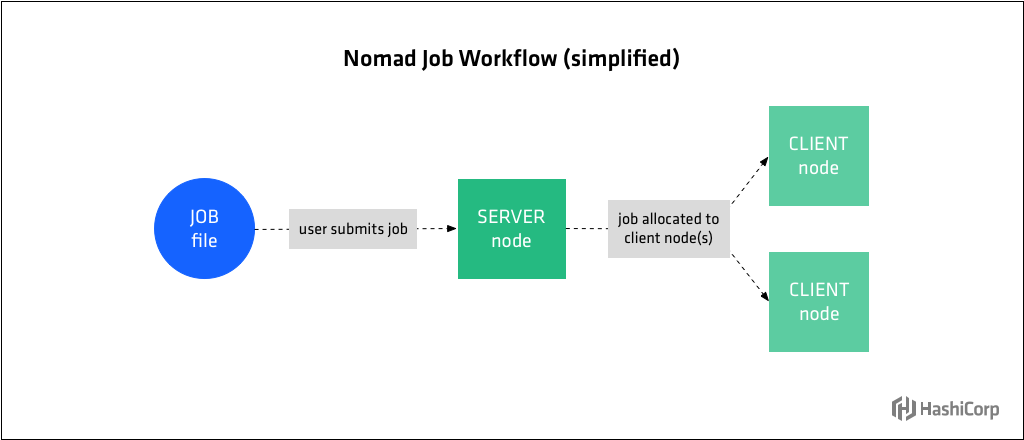
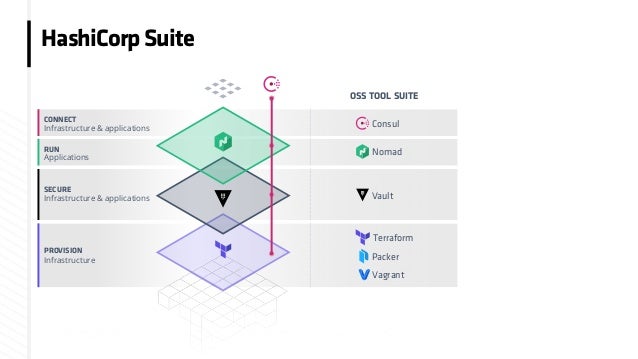
HashiCorp Nomad is a single binary that schedules applications and services on Linux, Windows, and Mac. It is an open source scheduler that uses a declarative job file for scheduling virtualized, containerized, and standalone applications.
https://www.nomadproject.io/
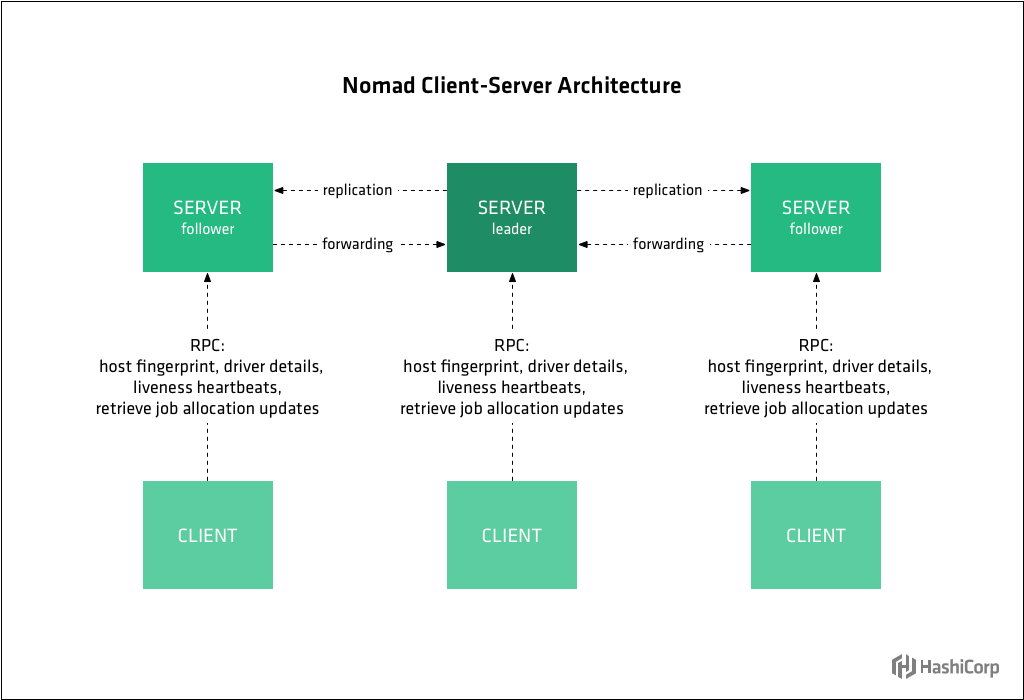
- The agent is also running in server mode, which means it is part of the gossip protocol used to connect all the server instances together.
Nomad servers are part of an auto scaling group where new servers
https://www.nomadproject.io/intro/getting-started/running.html
- To automatically bootstrap a Nomad cluster, we must leverage another HashiCorp open source tool, Consul.
https://www.nomadproject.io/guides/operations/cluster/automatic.html

I have read this post. collection of post is a nice one..!!
ReplyDeleteDocker and Kubernetes Training
Docker Training
Docker Online Training
Docker Training in Hyderabad
Kubernetes Online Training