- How To use an SPF Record to Prevent Spoofing & Improve E-mail Reliability
A carefully tailored SPF record will reduce the likelihood of your domain name getting fraudulently spoofed and keep your messages from getting flagged as spam before they reach your recipients.
Email spoofing is the creation of email messages with a forged sender address; something
that is simple to do because many mail servers do not perform authentication
Spam and phishing emails typically use such spoofing to mislead the recipient about the origin of the message.
A number of measures to address spoofing, however, have developed over the years:
SPF,
Sender ID,
DKIM,
and DMARC.
Sender Policy Framework (SPF) is an email validation system designed to prevent spam by detecting email spoofing.
Today, nearly all abusive e-mail messages carry fake sender addresses. The victims whose addresses are being abused often suffer from the consequences, because their reputation gets diminished, they have to waste their time sorting out misdirected bounce messages, or (worse) their IP addresses get blacklisted.
The SPF is an open standard specifying a technical method to prevent sender-address forgery.
SPF allows administrators to specify
which hosts are allowed to send mail on behalf of a
given domain by creating a specific SPF record (or TXT record) in the Domain Name System (DNS). Mail exchangers use DNS records to check that mail from a
given domain is being sent by a host sanctioned by that domain's administrators.
Benefits
Adding an SPF record to your DNS zone file is the best way to stop spammers from spoofing your domain. In addition, an SPF Record will reduce the number of legitimate e-mail messages that
are flagged as spam or bounced back by your recipients' mail servers
The SPF record is not 100% effective, unfortunately, because not all mail providers check for it
Although you do not need an SPF record on your DNS server to
evaluate incoming email against SPF policies published on other DNS servers, the best practice is to set up an SPF record on your DNS server. Setting up an SPF record lets other email servers use SPF filtering (if the feature is available on the mail server) to protect against incoming email from spoofed, or forged, email addresses that may
be associated with your domain.
https://www.digitalocean.com/community/tutorials/how-to-use-an-spf-record-to-prevent-spoofing-improve-e-mail-reliability
SPF is an email authentication mechanism which allows only
authorized senders to send on behalf of a
domain, and prevents all unauthorized users from doing so.
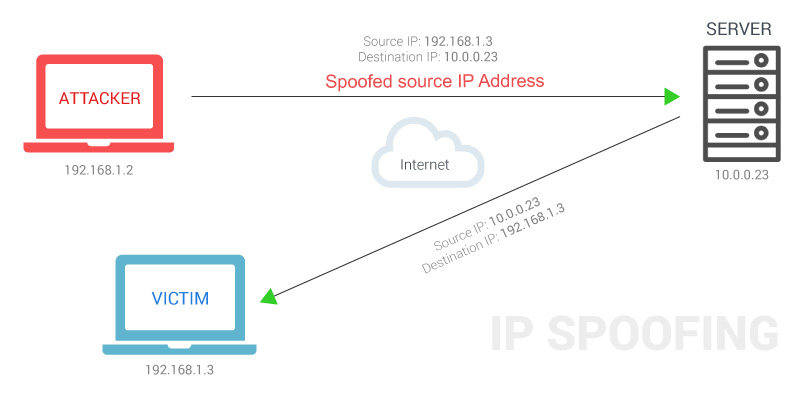
your business domain is
business.com; you will send emails to your employees and customers from support@business.com;
your email delivery server, which
sends the email for you, has an IP address of 192.168.0.1;
some attacker uses a scam email server at IP address 1.2.3.4 to
try to send spoofed emails.
When an email delivery service connects to the email server serving up the recipient's mailbox:
the email server extracts the domain name from the envelope from address;
in this case, it's
business.com;
the email server checks the connecting host's IP address to see if it's listed in
business.com's SPF record published in the DNS. If
the IP address is listed, the SPF check passes, otherwise not
For example, let's say your SPF record looks like this:
v=spf1 ip4:192.168.0.1 -all
it means only emails from IP address 192.168.0.1 can pass SPF check, while all emails from any IP address other than 192.168.0.1 will fail. Therefore, no email from the
scam server at IP address of 1.2.3.4 will ever pass SPF check.
What is DKIM?
One important aspect of email security is the authenticity of the message. An email message usually goes through multiple
serversbefore it reaches the destination. How do you know the email message you got
is not tampered with somewhere in the journey
DKIM, which stands for
DomainKeys Identified Mail, is an email authentication method designed to detect forged header fields and content in emails.
DKIM enables the receiver to check if email headers and content have
been altered in transit.
Asymmetric cryptography
DKIM is based on asymmetric cryptography, which uses pairs of keys: private keys
which are known only to the owner, and public keys which may
be distributed widely.
One of the best-known uses of asymmetric cryptography is digital signatures, in which a message
is signed with the sender's private key and can
be verified by anyone who has access to the sender's public key.
How DKIM works
On a high level, DKIM authentication
consists of 2 components: signing and verification. A DKIM-enabled email server (signing server) signs an email message on its way out, using a private key which is part of a generated
keypair. When the message arrives, the receiving server (verification server) checks if a DKIM-Signature field exists in the header, and if so, uses the DKIM public key in the DNS to validate the signature
In short, in order for DKIM to work:
create a
keypair containing both the private key and the public key;
keep the private key with the signing server;
publish the public key to the DNS in a DKIM record, so that the verification server has access to it.
What is DMARC?
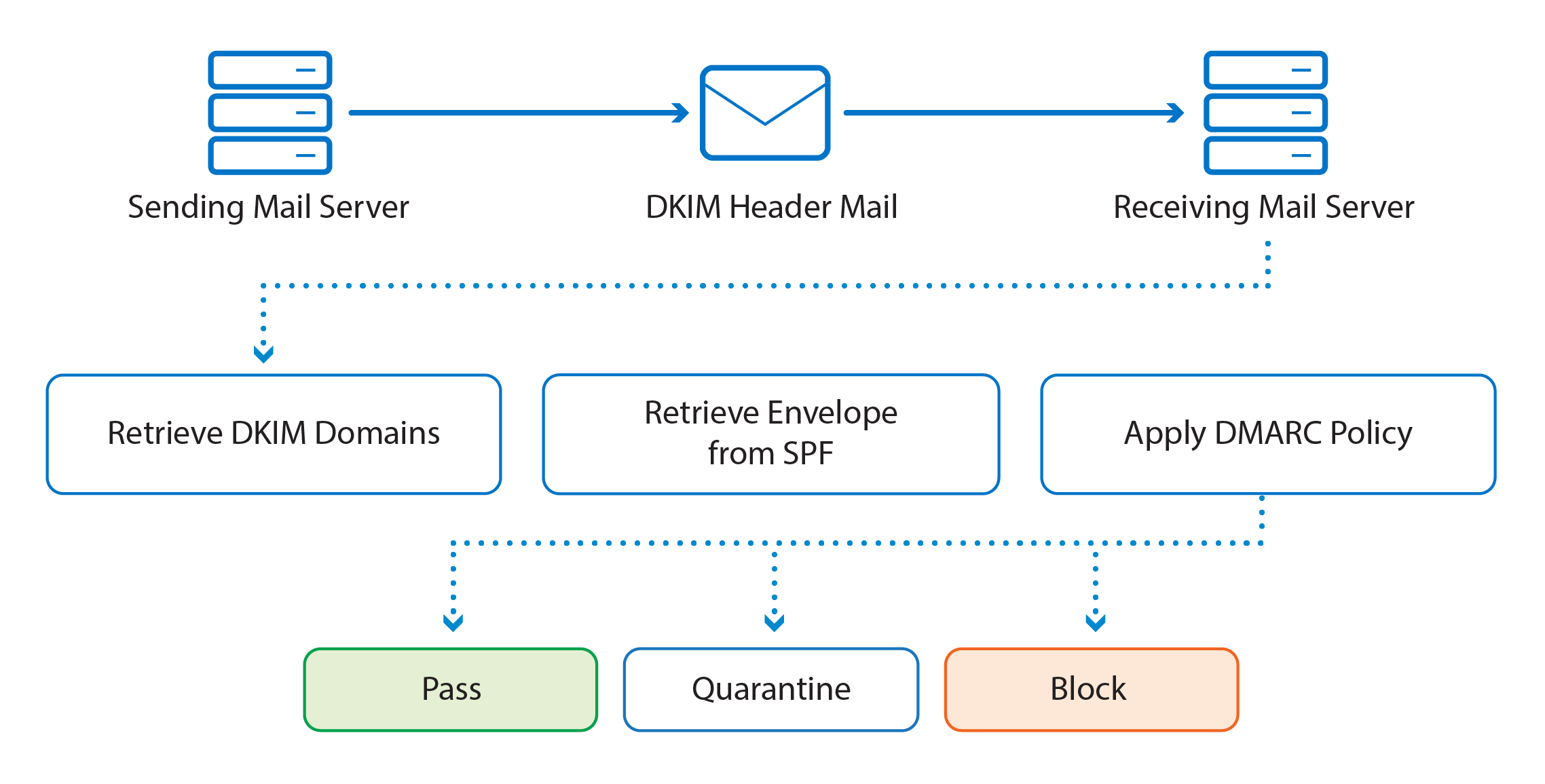
DMARC, which stands for Domain-based Message Authentication, Reporting & Conformance, is a way to determine whether an email message is actually from the sender or not. It builds on the widely deployed SPF and DKIM protocols, and adds domain alignment checking and reporting capabilities to designated recipients, to improve and monitor the protection of the domain against nefarious spoofing attempts
How DMARC works
On a high level,
DMARC is based on SPF and DKIM. Together the SPF/DKIM/DMARC trio can stop the long-standing email address spoofing problem.
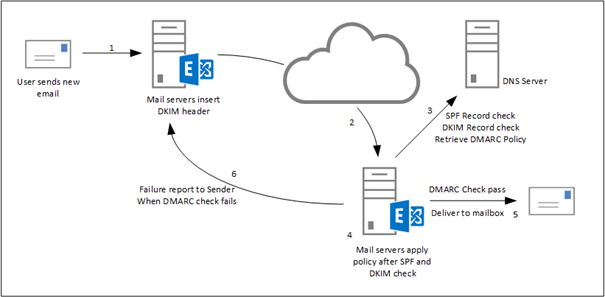
Here is how DMARC works: first you publish a DMARC record for your email domain in the DNS; whenever an email that claims to have originated from your domain
is received, the email service provider fetches the DMARC record and checks the email message accordingly;
depending on the outcome, the email is
either delivered, quarantined, or rejected.
Email delivery reports are sent to the email addresses specified in the DMARC record periodically, by email service providers
DMARC implements identifier alignment to eliminate the discrepancy between envelope from/header from addresses in SPF, and that between d= value and header from
address in DKIM;
DMARC adds reporting capabilities to enable email domain owners to gain visibility into email
deliverability, and ultimately implement full email protection against email spoofing/phishing.
DMARC alignment: authentication hardened
When either of the following is true of an email message, we say the email is DMARC aligned:
it passes SPF authentication, and SPF has identifier alignment;
it passes DKIM authentication, and DKIM has identifier alignment.
https://dmarcly.com/blog/home/how-to-implement-dmarc-dkim-spf-to-stop-email-spoofing-phishing-the-definitive-guide#introduction-to-spf
- SPF is using an SPF record in public DNS where all legitimate outbound SMTP servers for a domain are listed. A receiving SMTP server can check this DNS record to make sure the sending mail server is allowed to send email messages on behalf of the user or his organization
DKIM is about signing and verifying header information in email messages. A sending mail server can digitally sign messages, using a private key that’s only available to the sending mail server. The receiving mail server checks the public key in DNS to verify the signed information in the email message. Since the private key is only available to the sending organization’s mail servers, the receiving mail server knows that it’s a legitimate mail server, and thus a legitimate email message.
DMARC or Domain-based Message Authentication, Reporting & Conformance
DMARC which stands for Domain-based Message Authentication, Reporting & Conformance is an email validation mechanism, built on top of SPF and DKIM. DMARC is using a policy
which is published in DNS. This policy
indicates if the sending mail server is using SPF and/or
DKIM, and tells the receiving mail server what to do if SPF and/or DKIM does not pass their respective checks.
https://jaapwesselius.com/2016/08/23/senderid-spf-dkim-and-dmarc-in-exchange-2016-part-iii/