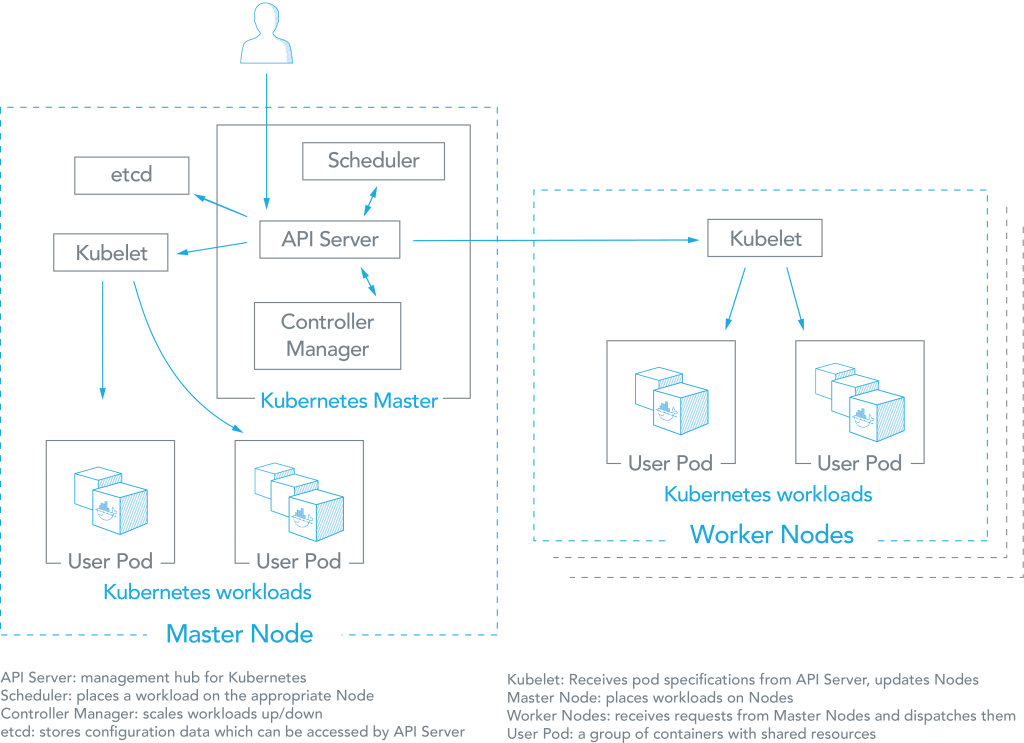
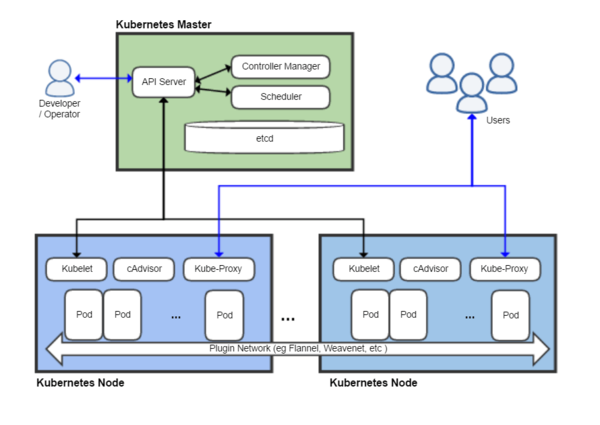
- Use the Kubernetes command-line tool,
kubectl , to deploy and manage applications on Kubernetes. Usingkubectl , you can inspect cluster resources; create, delete, and update components; and look at your new cluster and bring up example app
- Disable the swap file
This is now a mandatory step forKubernetes . The easiest way to do this is to edit /etc/fstab and to comment out the line referring to swap.
To save a reboot then type insudo swapoff -a.
https://blog.alexellis.io/your-instant-kubernetes-cluster
- Swap disabled. You MUST disable swap in order for the
kubelet to work properly.
https://kubernetes.io/docs/setup/independent/install-kubeadm/
- This document shows you how to perform setup tasks that
kubeadm doesn’t perform: provision hardware; configure multiple systems; and load balancing.
-
kubeadm : the command to bootstrap the cluster. kubelet : the component that runs onall of the machines in your cluster and does thingslike starting pods and containers.-
kubectl : the command lineutil to talk to your cluster.
The network must be deployed kube -dns , an internal helper service, will not start up before a networkis installed .kubeadm only supports Container Network Interface (CNI) based networks (and does not supportkubenet ).
Kubernetes DNS schedules a DNS Pod and Service on thecluster, and configures thekubelets to tell individual containers to use the DNS Service’s IP to resolve DNS names
https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/
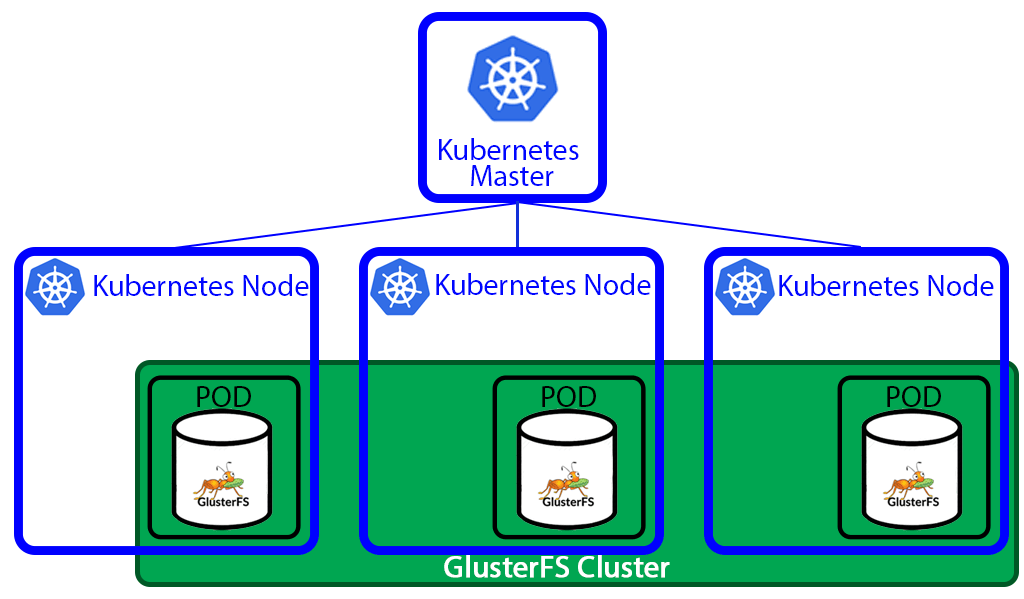
- Container visibility requires context.



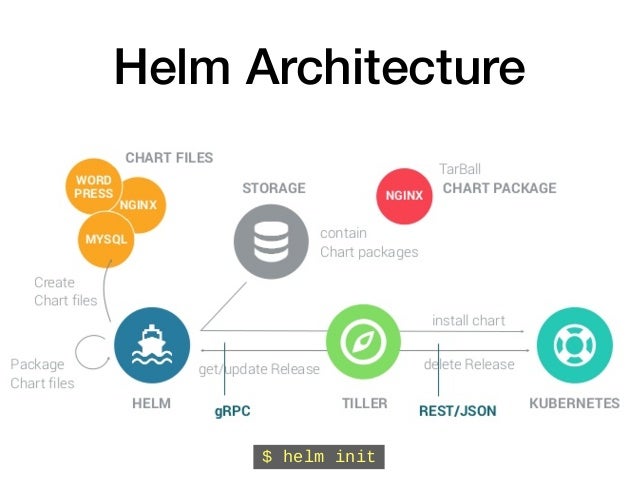
- Helm is a Kubernetes-based package installer. It manages Kubernetes “charts”, which are “
preconfigured packages of Kubernetes resources.” Helm enables youto easily install packages, make revisions, and even roll back complex changes
- Deploying an application using containers can be much easier than trying to manage deployments of a traditional application over different environments, but trying to manage and scale multiple containers manually is much more difficult than orchestrating them using Kubernetes. But even managing Kubernetes applications looks difficult compared to, say, “apt-get install
mysql ”.
https://www.mirantis.com/blog/install-kubernetes-apps-helm/
- Three Big Concepts
A Chart is a Helm package. It contains all of the resource definitions necessary to run an application, tool, or service inside of a Kubernetes cluster. Think of it like the Kubernetes equivalent of a Homebrew formula, an Apt dpkg, or a Yum RPM file.
A Repository is the place where charts can be collected and shared. It's like Perl's CPAN archive or the Fedora Package Database, but for Kubernetes packages.
A Release is an instance of a chart running in a Kubernetes cluster. One chart can often be installed many times into the same cluster. And each time it is installed, a new release is created. Consider a MySQL chart. If you want two databases running in your cluster, you can install that chart twice. Each one will have its own release, which will in turn have its own release name.
https://helm.sh/docs/intro/using_helm/
- You could avoid this by writing an automation script, but if you change the filenames or paths of your
Kubernetes resources, then you need to update the script too.
Helm is a tool for managing Kubernetes charts. Charts are packages of pre-configured Kubernetes resources.
Helm allows us to work from the mental model of managing our “application” on our cluster, instead of individual
https://medium.com/ingeniouslysimple/deploying-kubernetes-applications-with-helm-81c9c931f9d3
- A Chart is a Helm package. It contains
all of the resource definitions necessary to run an application, tool, or service inside of a Kubernetes cluster. Think of it like the Kubernetes equivalent of a Homebrew formula, an Aptdpkg , or a Yum RPM file.
A Release is an instance of a chart running in a
Helm installs charts into
https://docs.helm.sh/using_helm/#quickstart
Helm is made of two components:
tiller server. Runs inside the
https://docs.helm.sh/using_helm/#installation-






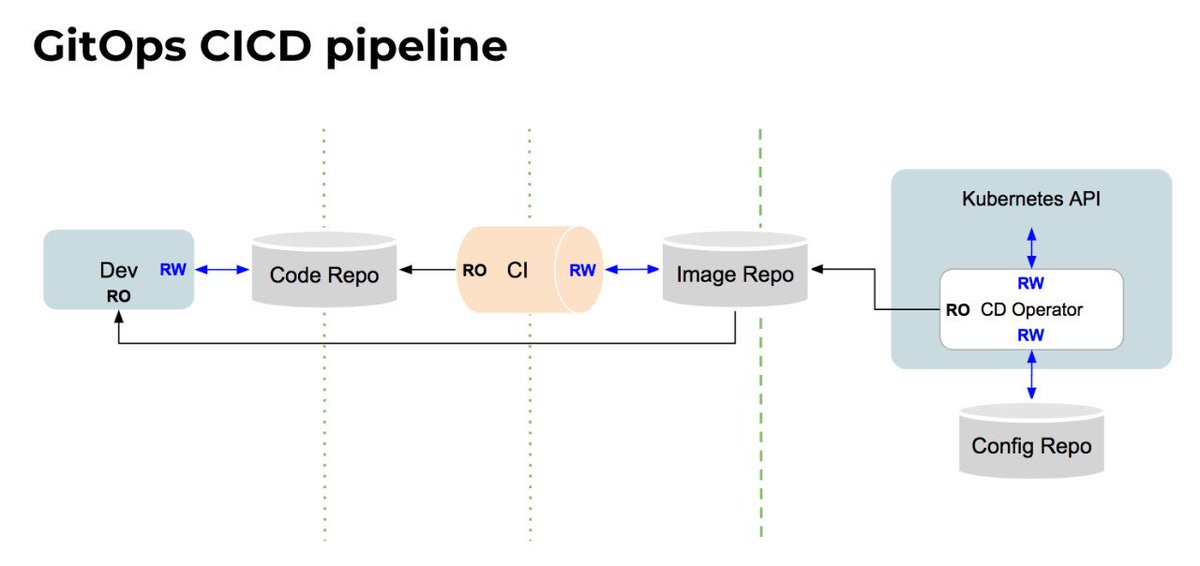
- our developers operate
Kubernetes via Git
By using Git as our source of truth, we can operate almost everything
For example, version control, history, peer review, and rollback happen through Git
Our provisioning of AWS resources and deployment of k8s is declarative
Our entire system state is under version control and described in a single Git repository
Operational changes
Diff tools detect any divergence and notify us via Slack alerts; and sync tools enable convergence
Let’s say a new team member deploys a new version of a service to prod without telling the on-call team. Our diff tools detect that what is running does not match
By using declarative tools, the entire set of configuration files can
We also use Terraform and Ansible to provision
Tools like Chef, Puppet and Ansible support features like “diff alerts”
These help operators to understand when action may need to
best practice is to deploy immutable images (
we have 3 main 'diff' tools:
https://www.weave.works/blog/gitops-operations-by-pull-request


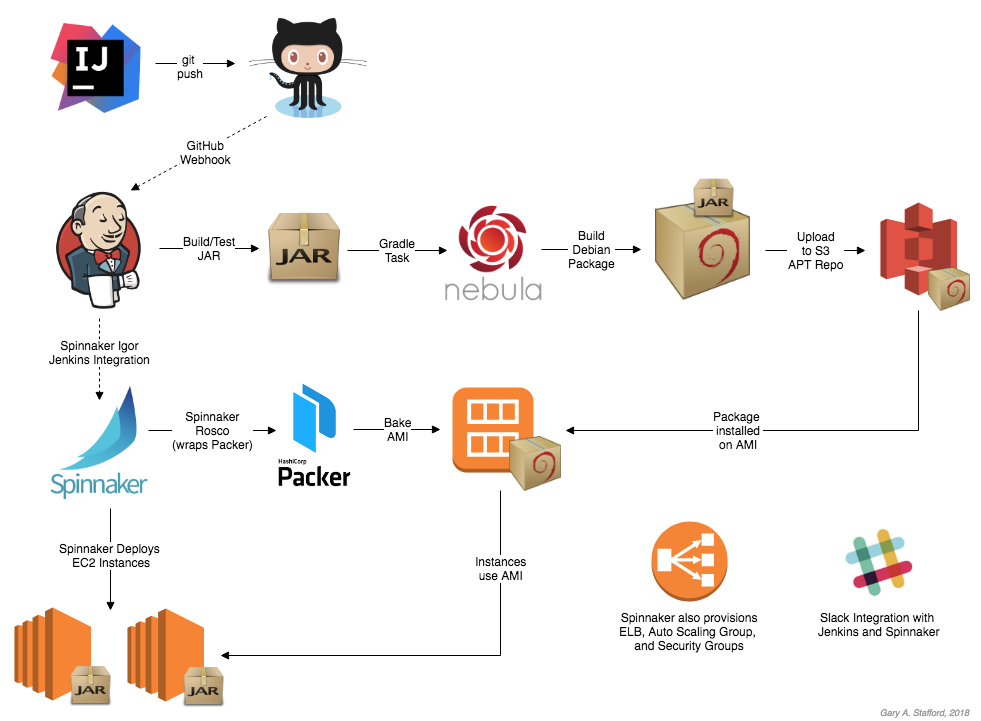

- Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence
https://www.spinnaker.io/


- By running an active-active architecture across Google Cloud Platform (GCP) and AWS, we’re in a better position to survive a DNS DDOS attack, a regional failure — even a global failure of an entire cloud provider.
This is where continuous delivery helps out . Specifically, we use Spinnaker, an open source, continuous delivery platform for releasing software changes with high velocity and confidence. Spinnaker has handled 100% of our production deployments for the past year, regardless of target platform.
Spinnaker abstracts many of the particulars of each cloud provider.
we’re able to maintain important continuous delivery concepts like canaries, immutable infrastructure and fast rollbacks.
once code is committed to git and Jenkins builds a package, that same package triggers the main deployment pipeline for that particular microservice .
That pipeline bakes the package into an immutable machine image on multiple cloud providers in parallel and continues to run any automated testing stages.
The deployment proceeds to staging using blue/green deployment strategy, and finally to production without having to get deep into the details of each platform
Support for tools like canary analysis and fast rollbacks allows developers to make informed decisions about the state of their deployment.
http://www.googblogs.com/guest-post-multi-cloud-continuous-delivery-using-spinnaker-at-waze/

- Automatic pipelines: Upgrade the binary and config in both AWS and GCP with one click
Cross-Cloud Canary & Rollback: Each pipeline has canary testing and fast rollback if there's a problem with the canary.
Multi-Cloud Redundancy: "If one goes down [Spinnaker] just launches instances in the next one."
https://blog.armory.io/spinnaker-enables-multi-cloud-deployments-for-waze-and-saved-1-000-people/
Multi-Cloud Deployments with Spinnaker
Discussing Terraform and Spinnaker
- The Benefits of Immutable Infrastructure
Immutable Infrastructure: The practice of replacing your infrastructure with new instances each time you deploy new code to ensure mutated code does not carry forward.
a short list of benefits immutable infrastructure may provide you:
Your company is preparing to run cloud-native applications
You are trying to automate the scaling of your infrastructure in the cloud
You want simple and infinitely repeatable deployments
Continuous deployments safely and quickly
The operations become more automated and responsibility falls on the developers
Server and node failures do not result in your service going down for long if at all
https://blog.armory.io/spinnaker-feature-immutable-infrastructure/
- The Benefits of Multi-Cloud Deployments
The main purpose of multi-cloud deployments is to mitigate against disasters
Spinnaker allows for easy configurations of a pipeline to execute a multi-cloud deployment
https://blog.armory.io/the-benefits-of-multi-cloud-deployments/
- Spinnaker Feature - Blue/Green (AKA Red/Black) Deployments
Blue/Green Deployments: A deployment
Internally, you can treat one production environment as a testing environment while the other is live and being used. When satisfied with the test environment’s viability, the team can
https://blog.armory.io/spinnaker-feature-blue-green-aka-red-black-deployments-2/
- Spinnaker Feature - Canary Deployments
Canary Deployments: For monitoring test deployments on a small percentage of servers before scaling the changes to the rest.
When testing a new batch of code or deployments that may or may not break your servers, it should be good practice for developers to push the code to a small subset of canary servers for monitoring. When satisfied with the code’s viability, developers can then deploy the code to the rest of the servers. In contrast, if the deployments break the canary servers only those servers
After you successfully deploy to canary servers, you can then run automated or manual tests
https://blog.armory.io/spinnaker-feature-canary-deployments/
- Chaos Monkey is a resiliency tool that helps applications tolerate random instance failures.
Chaos Monkey should work with any back-end that Spinnaker supports (AWS, Google Compute Engine, Azure, Kubernetes, Cloud Foundry).
https://github.com/Netflix/chaosmonkey
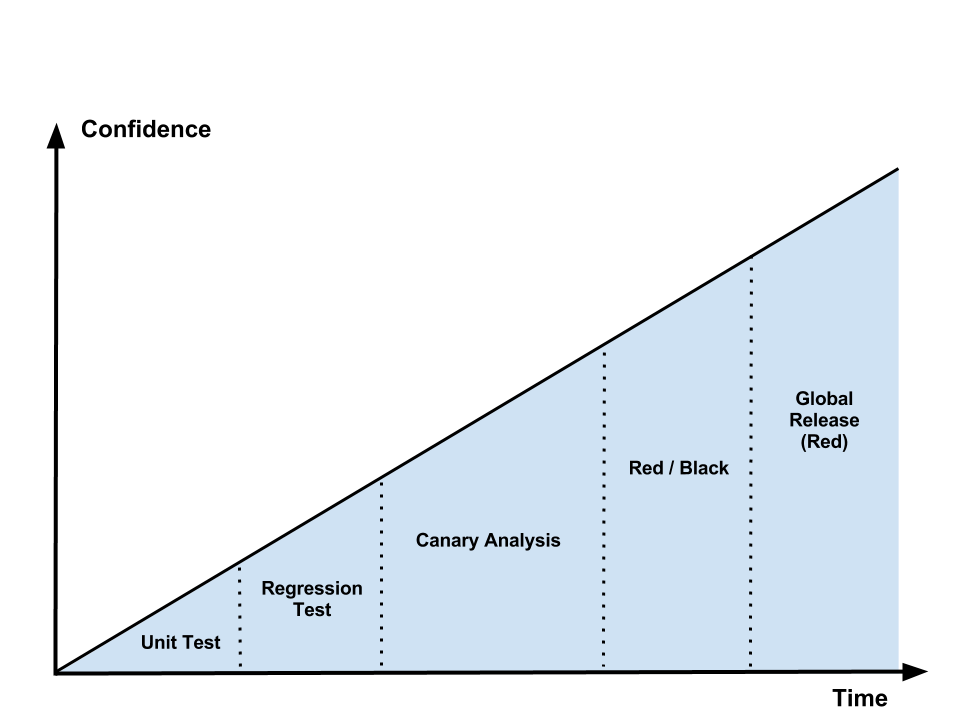
- Deploying the Netflix API
Development & Deployment Flow
The following diagram illustrates the logical flow of code from feature inception to global deployment to production clusters across all of our AWS regions. Each phase in the flow provides feedback about the “goodness” of the code, with each successive step providing more insight into and confidence about feature correctness and system stability.
https://medium.com/netflix-techblog/deploying-the-netflix-api-79b6176cc3f0
- Blue Green Deployments
Now, when you’re ready to
You monitor for any failures or exceptions because of the release. If everything looks good, you can eventually shut down the green environment and use it to stage any new releases. If not, you can quickly rollback to the green environment by pointing the load balancer back.
A/B Testing
A/B testing is a way of testing features in your application for various reasons like usability, popularity, noticeability, etc
The difference between blue-green deployments and A/B testing is A/B testing is for measuring functionality in the app.
Blue-green deployments are about releasing new software safely and rolling back predictably
You can
Canary releases
Canary releases are a way of sending out a new version of your app into production that plays the role of a “canary” to get an idea of how it will perform (integrate with other apps, CPU, memory, disk usage, etc).
Canary releases let you test the waters before pulling the trigger on a full release.
https://www.testingexcellence.com/difference-between-greenblue-deployments-ab-testing-and-canary-releases/
- How to configure AB Deployments on
Openshift
AB deployments are a simple and effective strategy to split traffic between different applications
One common use case is to split the load between the same application using a different template or database and measure the impact with different% of each application
You can also use it to switch off completely one version of one application by setting its load to 0%.
http://www.mastertheboss.com/soa-cloud/openshift/how-to-configure-ab-deployments-on-openshift
- What is A/B testing?
A/B testing deployment
Canary deployment on (full stack) application via load-balancing
This means there is a layer in between called a load balancer that directs traffic to manage the load over several identical web servers and fail-over when needed.
The configuration is compatible with
Canary deployment on micro-services via URL routing
https://melv1n.com/ab-testing-guide-product-managers/
- Stop Gambling with Upgrades, Murphy’s Law Always Wins
Take your running cluster and upgrade each component one by one.
Once traffic stops, upgrade the unused cluster member then run whatever tests need to
Once all tests pass, add the new member back to the load balancer and start sending production traffic to it.
Repeat until the entire cluster
What do you do if configuration management hangs or if the tests don’t succeed
Red Black Deployments
The approach is fairly
Send production traffic to the new system only after it’s up and in a known, confirmed state.
The big benefit here is no changes to the ‘production’ environment happen until
The drawback is the need for extra capacity to create this new environment. Using a public or private cloud provider is one way to make sure the extra capacity is there when it’s needed.
https://rhelblog.redhat.com/2015/05/07/stop-gambling-with-upgrades-murphys-law-always-wins/#more-908
- Red-Black Deployment
Red-Black deployment is a release technique that reduces downtime and risk by running two identical production environments called Red and Black.
As we prepare a new release of our application, deployment and the final stage of testing takes place in the environment that is not live: in this example, Black. Once we have deployed and fully tested the software in Black, we switch the ASG attached behind ELB all incoming requests now go to Black instead of Red. Black is now live, and Red is idle
This technique can eliminate downtime
https://sweetibharti.
- Ultralight service mesh for
Kubernetes and beyond
https://linkerd.io/




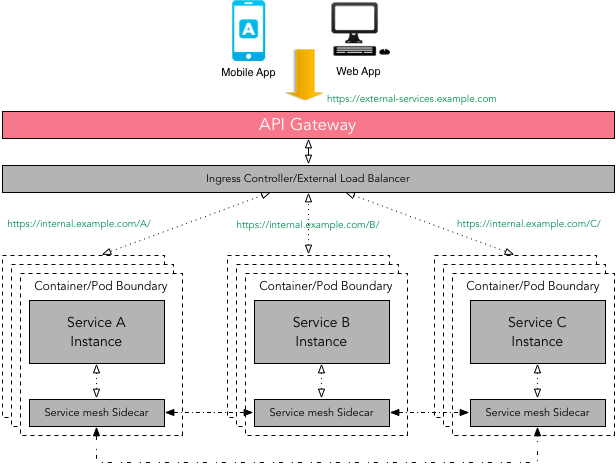

- In this article, we’ll show you how to use
linkerd as a service mesh to add TLS to all service-to-service HTTP calls,without modifying any application code.
https://blog.linkerd.io/2016/10/24/a-service-mesh-for-kubernetes-part-iii-encrypting-all-the-things/
Computer Networking Tutorial - 15 - Mesh Topology
advantages
provides alternative routes if one node fails
the more nodes you add the more communication routes you have
suitable for MAN, WAN not LAN
disadvantages
expensive to set up
Define your service using Protocol Buffers, a powerful binary serialization toolset and language
Works across languages and platforms
Automatically generate idiomatic client and server stubs for your service in a variety of languages and platforms
Start quickly and scale
Install runtime and dev environments with a single line and also scale to millions of RPCs per second with the framework
Bi-directional streaming and integrated auth
Bi-directional streaming and fully integrated pluggable authentication with http/2 based transport
gRPC is a modern open source high performance RPC framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication. It is also applicable in last mile of distributed computing to connect devices, mobile applications and browsers to backend services.
https://grpc.io/
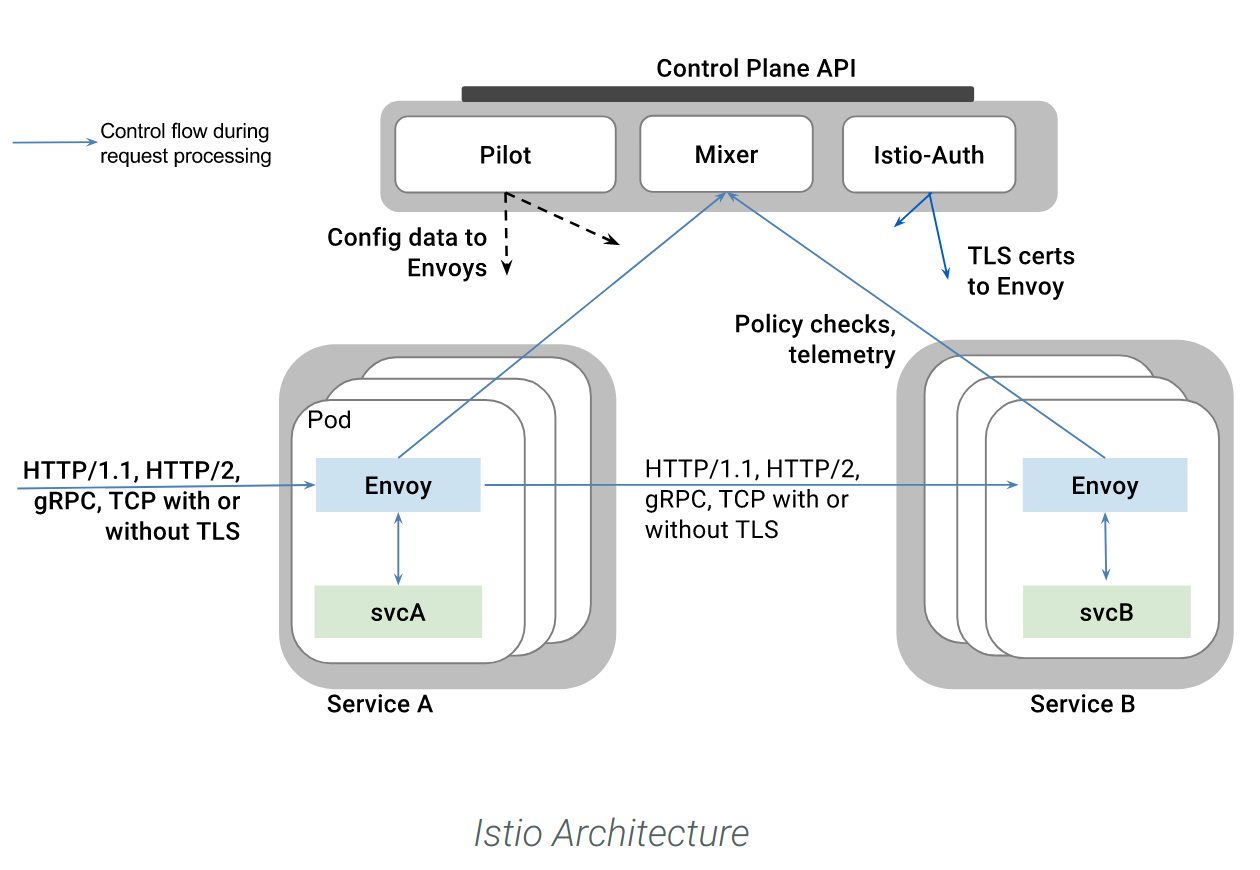
Istio + envoy + grpc + metrics winning with service mesh in practice

https://zipkin.io/
- A high-performance, open-source universal RPC framework
Define your service using Protocol Buffers, a powerful binary serialization toolset and language
Works across languages and platforms
Automatically generate idiomatic client and server stubs for your service in a variety of languages and platforms
Start quickly and scale
Install runtime and dev environments with a single line and also scale to millions of RPCs per second with the framework
Bi-directional streaming and integrated auth
Bi-directional streaming and fully integrated pluggable authentication with http/2 based transport
https://grpc.io/
How to Deploy a gRPC Mode Istio Mixer Adapter into Kubernetes
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems inmicroservice architectures.
https://zipkin.io/
Excellent Blog, I like your blog and It is very informative. Thank you
ReplyDeletePytest
Plugins
ReplyDeleteGreat Blog!!! thanks for sharing with us.
career in software testing
software testing career