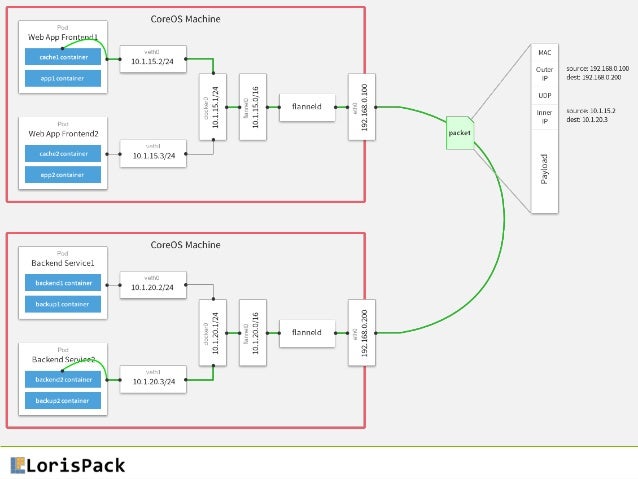
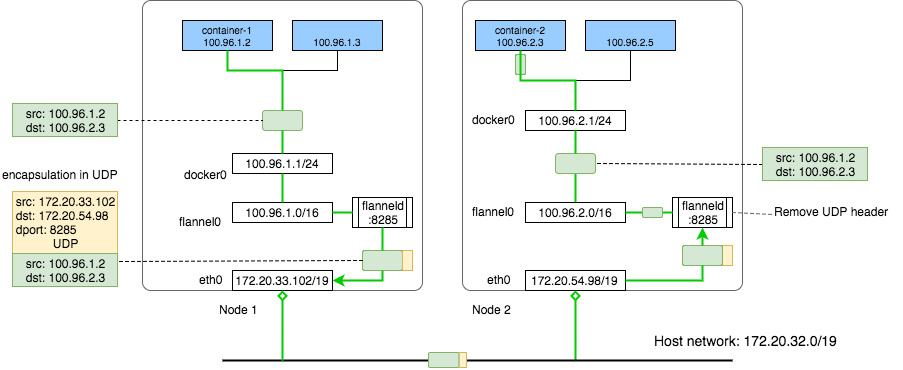
- flannel is a virtual network that gives a subnet to each host for use with container runtimes.
Platforms like Google's
https://coreos.com/flannel/docs/latest/
- Flannel is a simple and easy way to configure a layer 3 network fabric designed for
Kubernetes
Flannel runs a small, single binary agent called
https://github.com/coreos/flannel



- Free and open source,
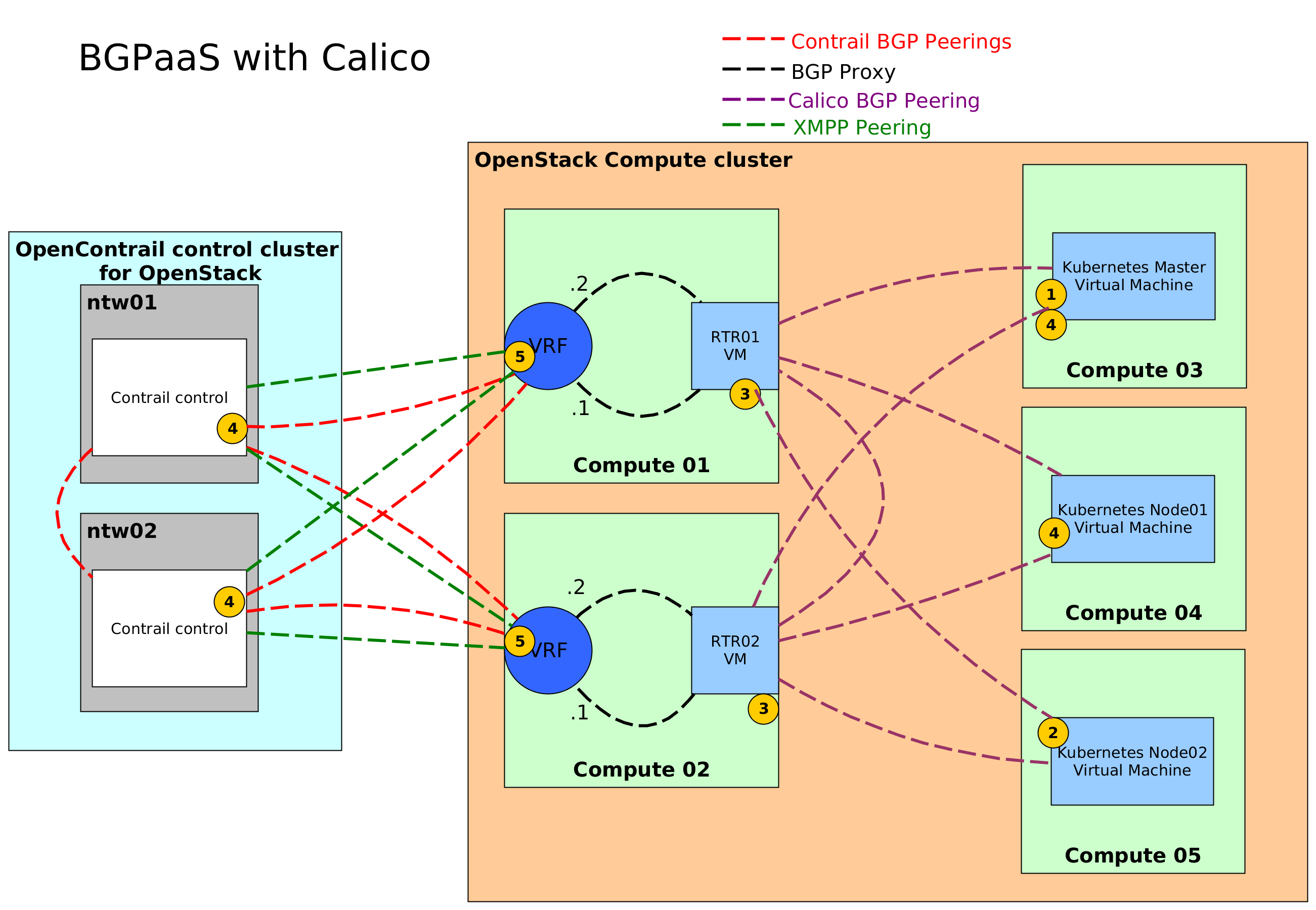
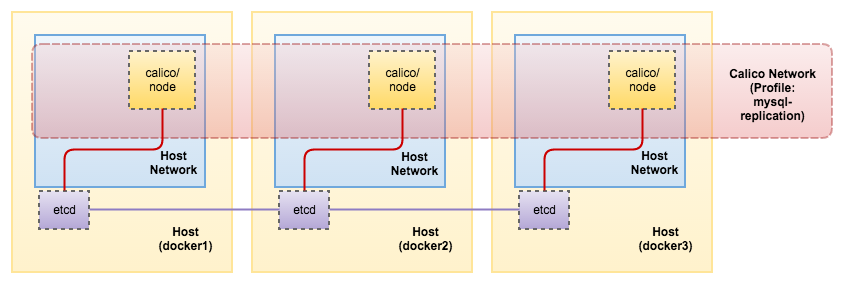
Project Calico is designed
Unlike SDNs that require a central controller, limiting scalability, Calico is built
https://www.projectcalico.org/
- container networking front
standardize one of a couple of
Standardizing networking and orchestration in the container space will really help take the technology mainstream
build a healthy ecosystem of technology providers
the network needs to be automated microservices
network interfaces for containers versus virtual machines
Virtual machines simulate hardware and include virtual network interface cards (NIC) that are used
containers are just processes, managed by a container runtime, that share the same host kernel.
containers can be connected namespace
In the ‘host’ mode, the containers run in the host network namespace
To expose the container outside the host, the container uses a port from the host’s port space.
you need to manage the ports that containers attach to since they are all sharing the same port space
The ‘bridge’ mode offers an improvement over the ‘host’ mode.
In ‘bridge’ mode, containers get IP addresses from a private network/networks, placed in their own network namespaces
the containers are in their own namespace, space,do
the containers are still exposed
This requires the use of NAT (network address translation) to map between host IP:host IP:private
NAT rules are implemented IPtables
these solutions don’t address the problem of multi-host networking
multi-host networking became a real need for containers
or
they can be connected namespace,then
Recognizing that every network tends to have
a model where networking was decoupled
improves application mobility
networking is handled
manages the network interfaces and how the containers are connected
plugin assigns the IP address to the containers’ network interfaces
a well defined
Docker, the company behind the Docker container runtime, came up with the Container Network Model (CNM)
CoreOS, the company responsible for creating the rkt
Since Docker is a popular container runtime, Kubernetes
The primary technical objection against CNM was the fact that it was still seen was designed
After this decision by Kubernetes decided to use PaaS Containerizer
Container Network Model (CNM)
CNM has interfaces for both IPAM plugins and network plugin
CNM also requires a distributed key-value store like consul
Docker’s libnetwork be used to
Container Network Interface (CNI)
CNI exposes a simple set of interfaces for adding and removing a container from a network.
Unlike CNM, CNI doesn’t require a distributed key value store like etcd
There are several networking plugins that implement one or both of CNI and CNM
Calico, Contrail (Juniper), Contiv Nuage
IP address management
IP-per-container (or Pod in case of Kubernetes
multi-host connectivity.
One area that isn’t addressed
CNI has now been adopted Kubernetes Mesos
It has also been accepted
http://www.nuagenetworks.net/blog/container-networking-standards/
- Access service from outside
Kubernetes
To expose your application / service for access from outside the cluster, following options exist:
This tutorial discusses how to enable access to your application from outside the Kubernetes (
For internal communication amongst pods and services (sometimes called East-West traffic)
Service Types
A Service in Kubernetes
Type ClusterIP
A service of type ClusterIP cluster, no type is specified
Type NodePort
A service of type NodePort is a ClusterIP as well as this is accomplished pretty Kubernetes kube Connections to this port are forwarded
Type LoadBalancer
A service of type LoadBalancer NodePort to setup
https://gardener.cloud/050-tutorials/content/howto/service-access/
- highly available (HA)
Kubernetes
With stacked control plane nodes, where etcd colocated
With external etcd etcd
Stacked etcd
distributed data storage cluster provided by etcd kubeadm
Each control plane node runs an instance of
The kube apiserver is exposed
Each control plane node creates a local etcd etcd kube apiserver kube kube
This topology couples the control planes and etcd
simpler to set up than a cluster with external etcd
a stacked cluster runs the risk of
If one node goes down, both an etcd are lost redundancy is compromised
mitigate this risk by adding more control plane nodes.
A local etcd kubeadm kubeadm --
External etcd
distributed data storage cluster provided by etcd
Like the stacked etcd etcd kube apiserver kube kube kube apiserver is exposed
This topology decouples the control plane and etcd
losing a control plane instance or an etcd
this topology requires twice the number of hosts as the stacked HA topology.
A minimum of three hosts for control plane nodes and three hosts for etcd
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
- The ~/
. kube Kubernetes kubectl . kube
First, you can specify another file by using the -- kubeconfig kubectl
Second, you can define the KUBECONFIG environment variable to avoid having to type -- kubeconfig
Third, you can merge contexts in the same config file and then you can switch contexts.
How to Check the Nodes of Your Kubernetes
A node, in the context of
In Kubernetes, to tell your cluster what to run, you usually use images from a registry. By default, Kubernetes will try to fetch images from the public Docker Hub registry. However, you can also use private registries if you prefer keeping your images, well, private
Deployment: Basically speaking the context of In this case are specifying
Using Services and Ingresses to Expose Deployments
To configure ingress rules in your Kubernetes many different
https://auth0.com/blog/kubernetes-tutorial-step-by-step-introduction-to-basic-concepts/
- Configuring HA
Kubernetes GlusterFS MetalLB .
In this part of article MetalLB GlusterFS available Kubernetes
https://medium.com/faun/configuring-ha-kubernetes-cluster-on-bare-metal-servers-with-glusterfs-metallb-2-3-c9e0b705aa3d
- Publishing Services (
ServiceTypes
NodePort: Exposes the Service on each Node’s IP at a static port (the NodePort). A ClusterIP the NodePort Service routes, is automatically created NodeIP>:<NodePort
with its value. No proxying
You can also use Ingress to expose your Service. Ingress is not a Service type, but it acts as the entry point for your cluster. It lets you consolidate
External IPs
If there are external IPs that route to one or more cluster nodes, Kubernetes Services can be exposed externalIPs be routed externalIPs are not managed
In the Service spec, externalIPs ServiceTypes my-service” can be accessed by clients externalIP:port
https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport
- Bare-metal considerations
In traditional cloud environments, where network load balancers are available on-demand, a single Kubernetes kind of
A pure software solution: MetalLB
https://kubernetes.github.io/ingress-nginx/deploy/baremetal/
- The Ingress is a Kubernetes resource that lets you configure an HTTP load balancer for applications running on Kubernetes, represented by one or more Services. Such a load balancer is necessary to deliver those applications to clients outside of the Kubernetes cluster.
The Ingress resource supports the following features:
Content-based routing:
Host-based routing. For example, routing requests with the host header foo
Path-based routing. For example, routing requests with the URI that starts with /
TLS/SSL termination for each hostname, such as foo
https://github.com/nginxinc/kubernetes-ingress/
- Setup Jenkins On
Kubernetes
Create a
Create a deployment
Create a service
Access the Jenkins application on a Node Port.
For using persistent volume for your Jenkins data, you need to create volumes of relevant cloud or on-
we are using the type as
https://devopscube.com/setup-jenkins-on-kubernetes-cluster/
- Getting Started with
Kubernetes
The goal of the
We’re using Vagrant for a few reasons, but primarily because it shows how to deploy
A Pod is a group of containers that can communicate with each other as though they are running within the same system. For those familiar with Docker, this may sound
The goal of a Pod is to allow applications running within the Pod to interact in the same way they would as though they were not running in containers but
A Deployment, or Deployment Object, is
While containers within Pods can connect to systems external to the cluster, external systems and even other Pods cannot communicate with them. This is because, by default,
the flag
Service types
At the moment,
If we wanted to only expose this service to other Pods within this cluster, we can use the
The
Since we did not specify a port to use when defining our
we can see that the Ghost Pod is running on
In the case above, this means that even though the HTTP request
This feature allows users to run services without having to worry about where the service is and
https://blog.codeship.com/getting-started-with-kubernetes/
Your blog is in a convincing manner, thanks for sharing such an information with lots of your effort and time
ReplyDeleteKubernetes online training
Kubernetes certification training
Kubernetes training
Kubernetes course