- A recent performance benchmark completed by Intel and
BlueData using theBigBench in some cases
Under the hood, the
container-based Spark cluster vs. bare-metal Spark cluster.
For instance, scatter/gather pattern can
a distributed Pachyderm File System (PFS) and a data-aware scheduler Pachyderm Pipeline System (PPS) on top of
Pachyderm uses default
In addition, for FPS Pachyderm
Pachyderm is applying version control to your data as it's processed which processing jobs run on only the diff.
Custom schedulers
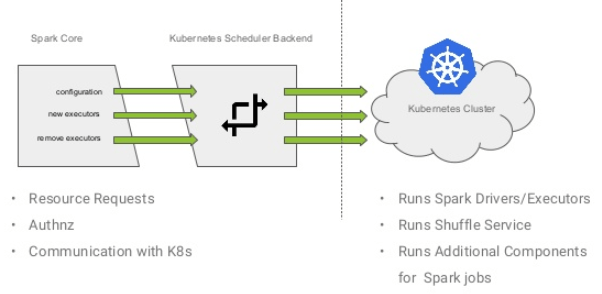
the performance of Spark with native Kubernetes scheduler can
This enables HDFS data locality by discovering the mapping of
It is possible to use YARN as
Heron is a real-time, distributed stream processing engine developed at Twitter.
Just like Apache Storm, Heron has a concept of topology.
A topology is a directed acyclic graph (DAG) used to process streams of data and it can be stateless or stateful.
Heron topology is essentially a set of pods that can be scheduled by
Heron scheduler converts packing plan for a topology into pod definitions which
Storage provisioning
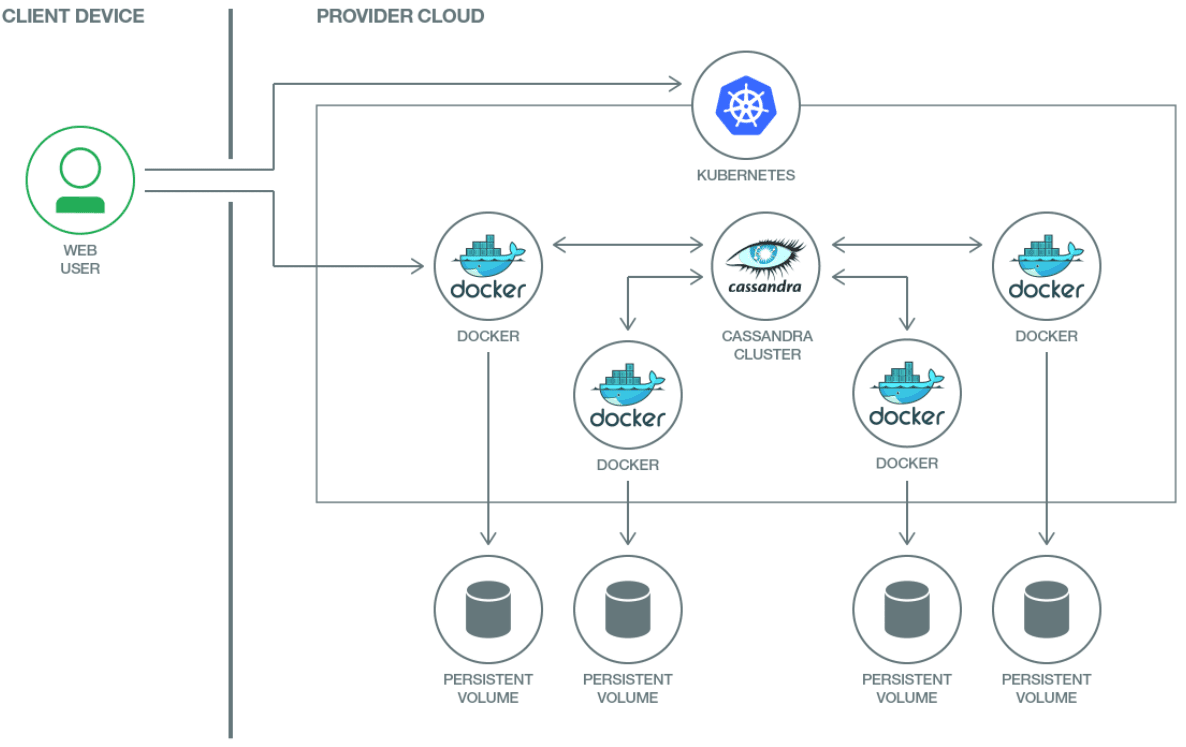
Storage options have been another big roadblock in porting data workloads on
These new Kubernetes storage options have enabled us to deploy more fault-tolerance stateful data workloads on Kubernetes without the risk of data loss. For instance, by levering
https://www.abhishek-tiwari.com/kubernetes-for-big-data-workloads/

- What is a container?
It’s similar to a virtual machine (VM), but it avoids a great deal of the trouble because it virtualizes the operating system (OS) rather than the underlying hardware.
This enables engineers to quickly develop applications that will run consistently across a large number of machines and software environments.
What is Docker?
The Docker Container Platform is an excellent tool for building and deploying containerized applications.
The platform helps developers easily isolate software into containers as they create it. It’s also an effective way to prepare existing applications for the cloud.
What is Kubernetes ?
While Docker does have its own container orchestration solution called Docker Swarm, Kubernetes and Docker mostly solve different problems and thus can coexist. Later versions of Docker even have built-in integration with Kubernetes.
https://www.ibm.com/blogs/cloud-computing/2018/07/30/kubernetes-docker-vs/