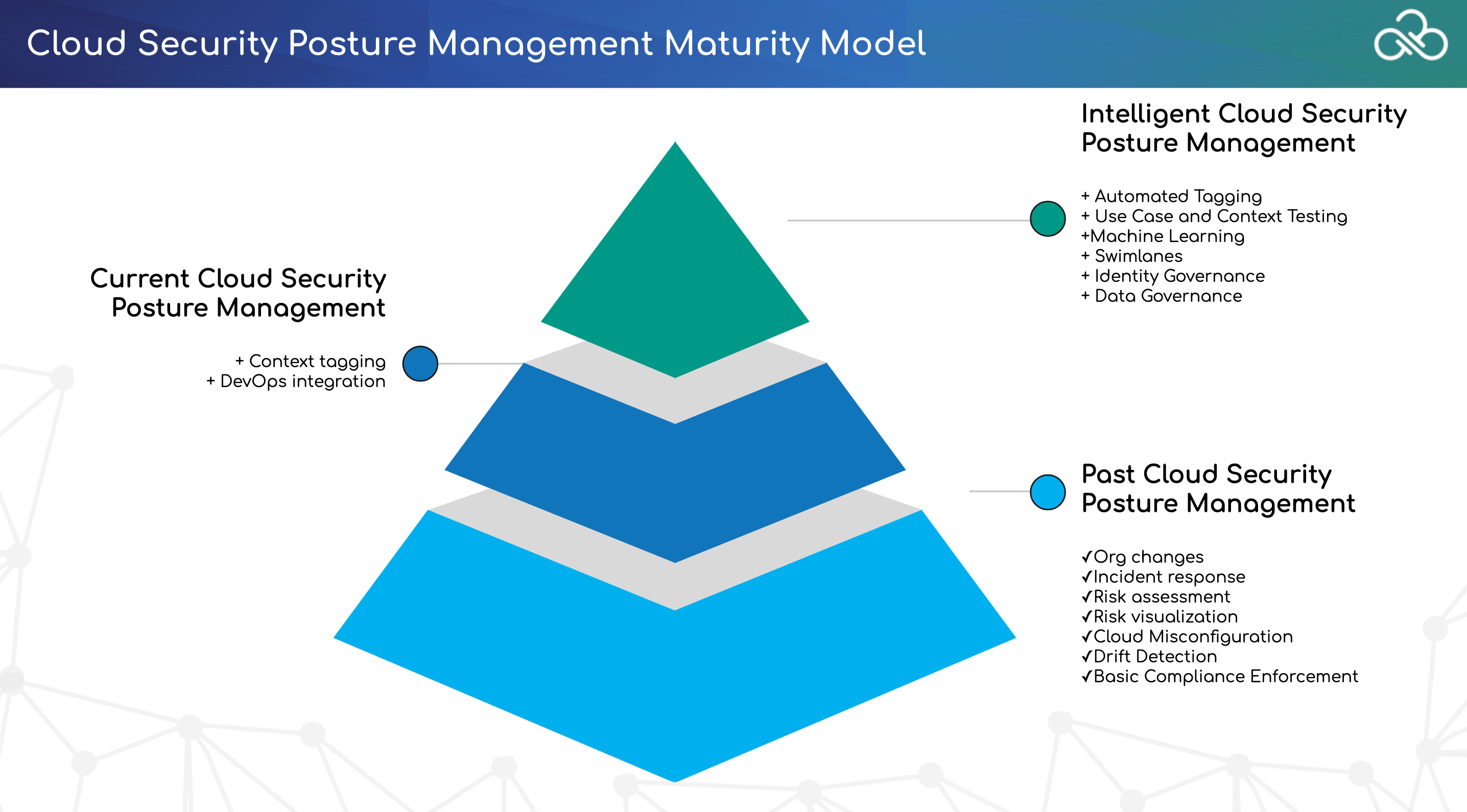
- Cloud Security Posture Management (CSPM)
Cloud Security Posture Management (CSPM) is a market segment for IT security tools that are designed to identify misconfiguration issues and compliance risks in the cloud
An important purpose of CSPM programming is to continuously monitor cloud infrastructure for gaps in security policy enforcement
CSPM as a new category of security products that can help automate security and provide compliance assurance in the cloud
CSPM tools work by examining and comparing a cloud environment against a defined set of best practices and known security risks
CSPM is typically used by organizations that have adopted a cloud-first strategy and want to extend their security best practices to hybrid cloud and multi-cloud environments.
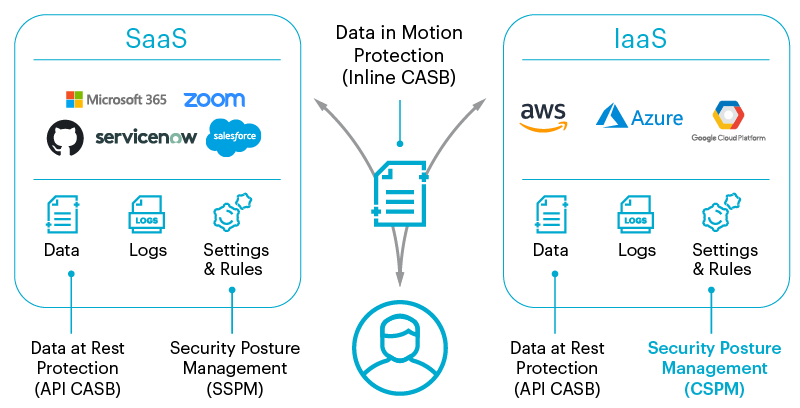
CSPM is often associated with Infrastructure as a Service (IaaS) cloud services, the technology can also be used to minimize configuration mistakes and reduce compliance risks in Software as a Service (SaaS) and Platform as a Service (PaaS) cloud environments
Key capabilities of CSPM
detect and perhaps automatically remediate cloud misconfigurations;
maintain an inventory of best practices for different cloud configurations and services;
map current configuration statuses to a security control framework or regulatory standard;
work with IaaS, SaaS and PaaS platforms in containerized, hybrid cloud and multi-cloud environments;
monitor storage buckets, encryption and account permissions for misconfigurations and compliance risks.
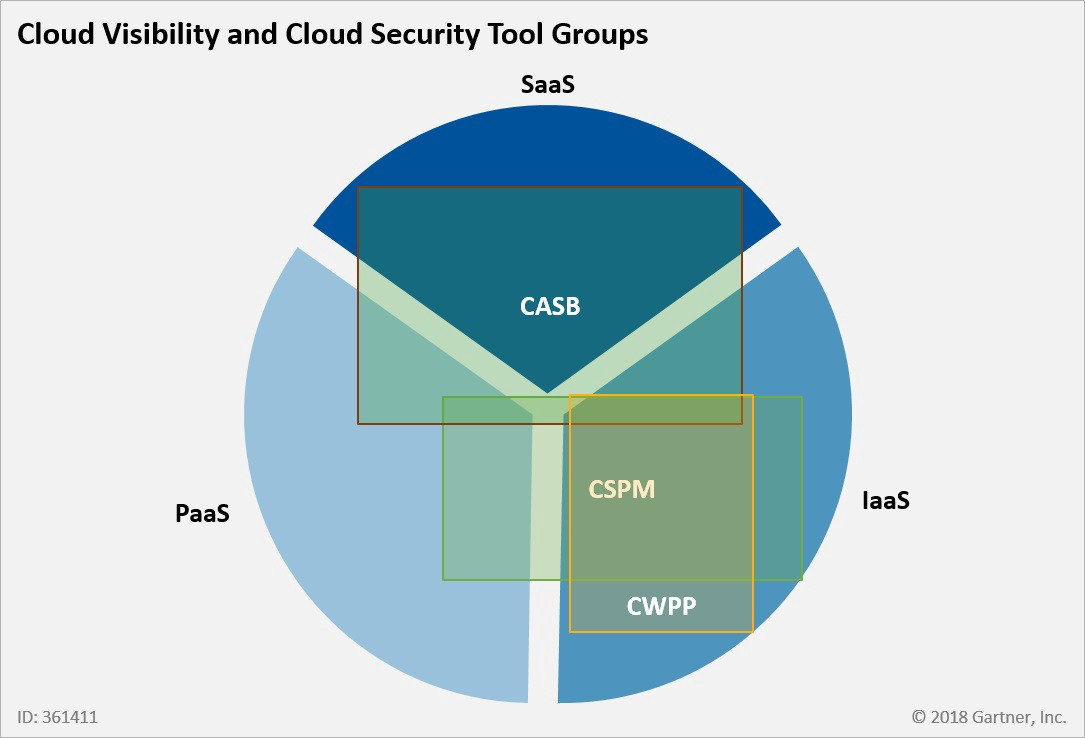
Other CSPM tools can be used in tandem with Cloud Access Security Broker (CASB) tools. CASB is a software tool or service that can safeguard the flow of data between on-premises IT infrastructure and a cloud provider's infrastructure.
https://www.techtarget.com/searchsecurity/definition/Cloud-Security-Posture-Management-CSPM
- What is CSPM?
Cloud security posture management (CSPM) is a category of automated data security solution that manages monitoring, identification, alerting, and remediation of compliance risks and misconfigurations in cloud environments.
Why do we need CSPM?
Data breaches resulting from misconfigurations of cloud infrastructure, which can expose enormous amounts of sensitive data, leading to legal liability and financial losses.
Continuous compliance for cloud apps and workloads, which is impossible to achieve using traditional on-premises tools and processes
Challenges implementing cloud governance (visibility, permissions, policy enforcement across business units, lack of knowledge about cloud security controls), which grow alongside cloud adoption within the organization.
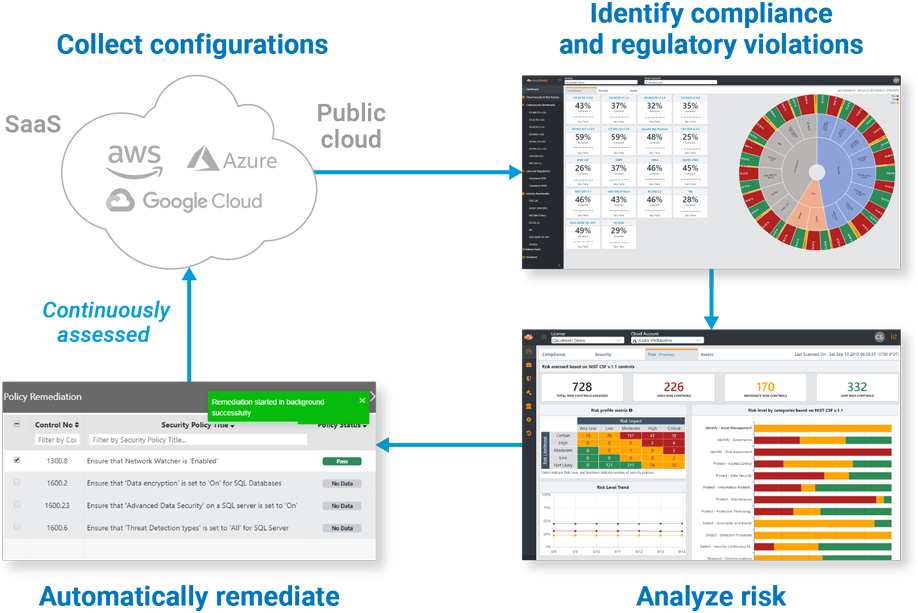
How does CSPM work?
Provides visibility into your cloud assets and configurations.
Manages and remediates misconfigurations.
Discovers new potential threats.
What are the key capabilities of CSPM?
Identify your cloud environment footprint and monitor for the creation of new instances or storage resources, such as S3 buckets.
Provide policy visibility and ensure consistent enforcement across all providers in multicloud environments.
Scan your compute instances for misconfigurations and improper settings that could leave them vulnerable to exploitation.
Scan your storage buckets for misconfigurations that could make data accessible to the public.
Audit for adherence to regulatory compliance mandates such as HIPAA, PCI DSS, and GDPR.
Perform risk assessments against frameworks and external standards such as those put forth by the International Organization for Standardization (ISO) and the National Institute of Standards and Technology (NIST).
Verify that operational activities (e.g., key rotations) are being performed as expected.
Automate remediation or remediate at the click of a button.
https://www.zscaler.com/resources/security-terms-glossary/what-is-cloud-security-posture-management-cspm
- What is Cloud Security Posture Management (CSPM)?
Cloud security posture management (CSPM) automates the identification and remediation of risks across cloud infrastructures, including Infrastructure as a Service (IaaS), Software as a Service (Saas), and Platform as a Service (PaaS). CSPM is used for risk visualization and assessment, incident response, compliance monitoring, and DevOps integration, and can uniformly apply best practices for cloud security to hybrid, multi-cloud, and container environments.
Traditional security doesn’t work in the cloud because:
there is no perimeter to protect
manual processes cannot occur with the necessary scale or speed
the lack of centralization makes visibility extremely difficult to achieve
the idea of Infrastructure as Code (IaC), in which infrastructure is managed and provisioned by machine-readable definition files. This API-driven approach is integral to cloud-first environments because it makes it easy to change the infrastructure on the fly, but also makes it easy to program in misconfigurations that leave the environment open to vulnerabilities.
Underlying all of these issues is the greatest vulnerability of all: lack of visibility. In environments as complex and fluid as the typical enterprise cloud, there are hundreds of thousands of instances and accounts, and knowing what or who is running where and doing what is only possible through sophisticated automation
Without that help, vulnerabilities arising from misconfigurations can remain undetected for days, or weeks, or until there is a breach.
Benefits of Cloud Security Posture Management
There are two types of risk: intentional and unintentional.
the intentional: outside attacks and malicious insiders.
unintentional mistakes, such as leaving sensitive data exposed to the public in S3 buckets
CSPMs also reduce alert fatigue because the alerts come through one system rather than the usual six or more, and false positives are reduced through the use of artificial intelligence. This, in turn, improves security operations center (SOC) productivity.
CSPMs continuously monitor and assess the environment for adherence to compliance policies. When drift is detected, corrective actions can occur automatically.
CSPM uncovers hidden threats through its continuous scans of the entire infrastructure, and faster detection means shorter times to remediation.
How Does Cloud Security Posture Management Work?
Discovery and Visibility
Users can access a single source of truth across multi-cloud environments and accounts.
Cloud resources and details are discovered automatically upon deployment, including misconfigurations, metadata, networking, security and change activity.
Security group policies across accounts, regions, projects, and virtual networks are managed through a single console.
Misconfiguration Management and Remediation
CSPM eliminates security risks and accelerates the delivery process by comparing cloud application configurations to industry and organizational benchmarks so violations can be identified and remediated in real-time.
Storage is monitored so the proper permissions are always in place and data is never accidentally made accessible to the public.
database instances are monitored to ensure high availability, backups, and encryption are enabled.
Continuous Threat Detection
The number of alerts is reduced because the CSPM focuses on the areas adversaries are most likely to exploit, vulnerabilities are prioritized based on the environment, and vulnerable code is prevented from reaching production. The CSPM will also continuously monitor the environment for malicious activity, unauthorized activity, and unauthorized access to cloud resources using real-time threat detection.
DevSecOps Integration
Security operations and DevOps teams get a single source of truth, and security teams can stop compromised assets from progressing through the application lifecycle
The CSPM should be integrated with the SIEM to streamline visibility and capture insights and context about misconfigurations and policy violations.
The CSPM should also integrate with DevOps tool sets that are already in use, which will enable faster remediation and response within the DevOps tool set.
Differences between CSPM and other cloud security solutions
Cloud Infrastructure Security Posture Assessment (CISPA)
CISPA is the name of the first generation of CSPMs.
Cloud Workload Protection Platforms (CWPPs)
CSPMs are purpose-built for cloud environments and assess the entire environment, not just the workloads.
CSPMs also incorporate more sophisticated automation and artificial intelligence, as well as guided remediation
Cloud Access Security Brokers (CASBs)
Cloud access security brokers are security enforcement points placed between cloud service providers and cloud service customers.
CASBs typically offer firewalls, authentication, malware detection, and data loss prevention, while CSPMs deliver continuous compliance monitoring, configuration drift prevention, and security operations center investigations.
https://www.crowdstrike.com/cybersecurity-101/cloud-security/cloud-security-posture-management-cspm/
- Cloud Security Posture Management
Eliminate cloud blind spots, achieve compliance, and proactively address risks.
Complete visibility and protection across any cloud
Improved efficiency and collaboration with automation
Integrated data security and entitlement controls
Visibility, Compliance and Governance
Cloud asset inventory
Configuration assessment
Compliance management
Automated remediation
Threat Detection
Network anomaly detection
User entity behavior analytics (UEBA)
Integrated threat detection dashboards
Data Security
Data visibility and classification
Data governance
Malware detection
Alerting
https://www.paloaltonetworks.com/prisma/cloud/cloud-security-posture-management





 Bard:How does designing the API around the database schema differ from designing it based on the principles of REST? What are the advantages and disadvantages of each approach?
Bard:How does designing the API around the database schema differ from designing it based on the principles of REST? What are the advantages and disadvantages of each approach?