- Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
A distributed systems kernel
Mesos is built using the same principles as the Linux kernel, only at a different level of abstraction.
The Mesos
kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elasticsearch) with API’s for
resource management and scheduling across entire
datacenter and cloud environments.
Mesos is built using the same principles as the Linux kernel, only at a different level of abstraction.
http://mesos.apache.org/
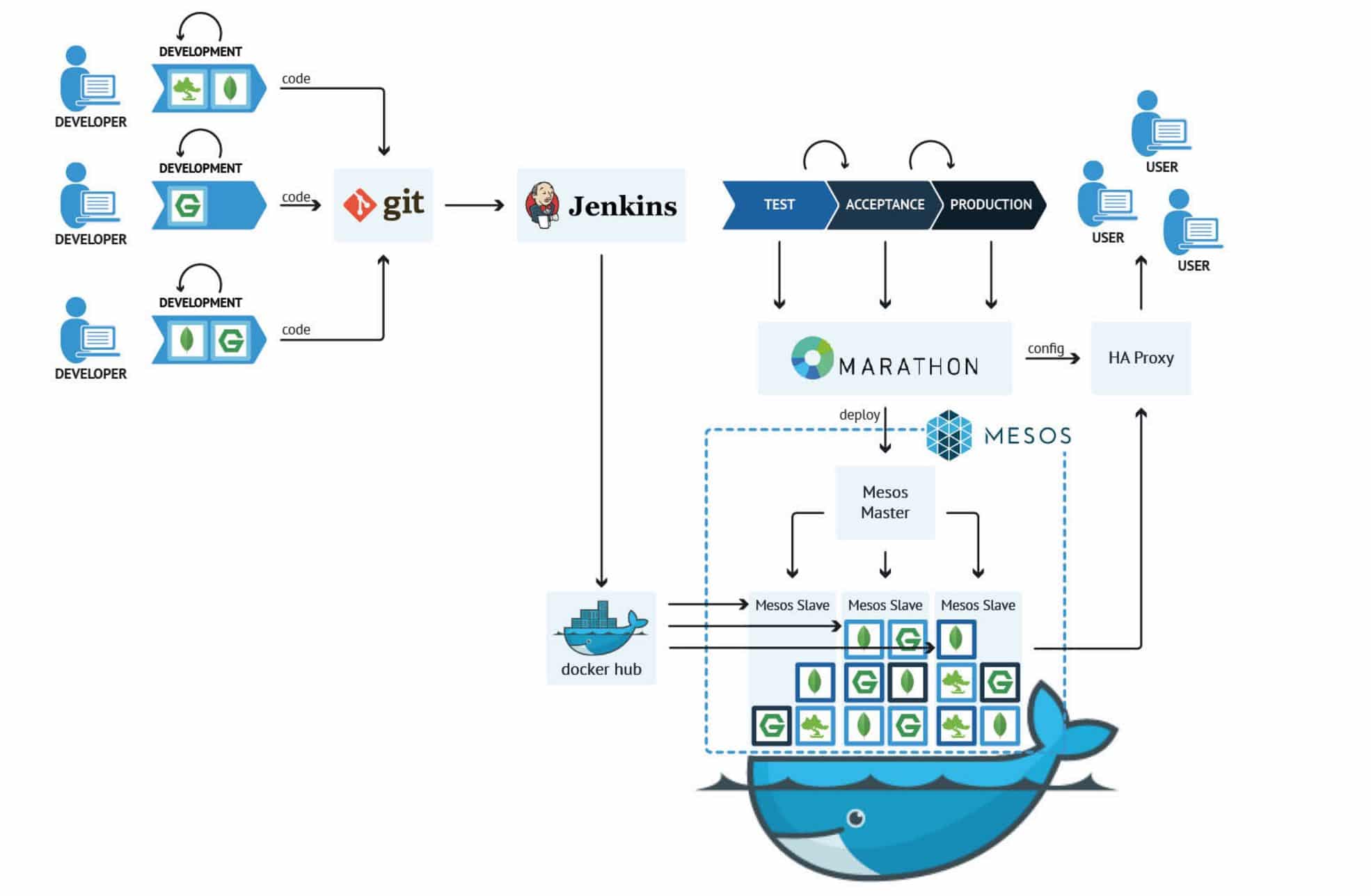
- Marathon is a production-grade container orchestration platform for Mesosphere’s Datacenter Operating System (DC/OS) and Apache Mesos.
https://mesosphere.github.io/marathon/
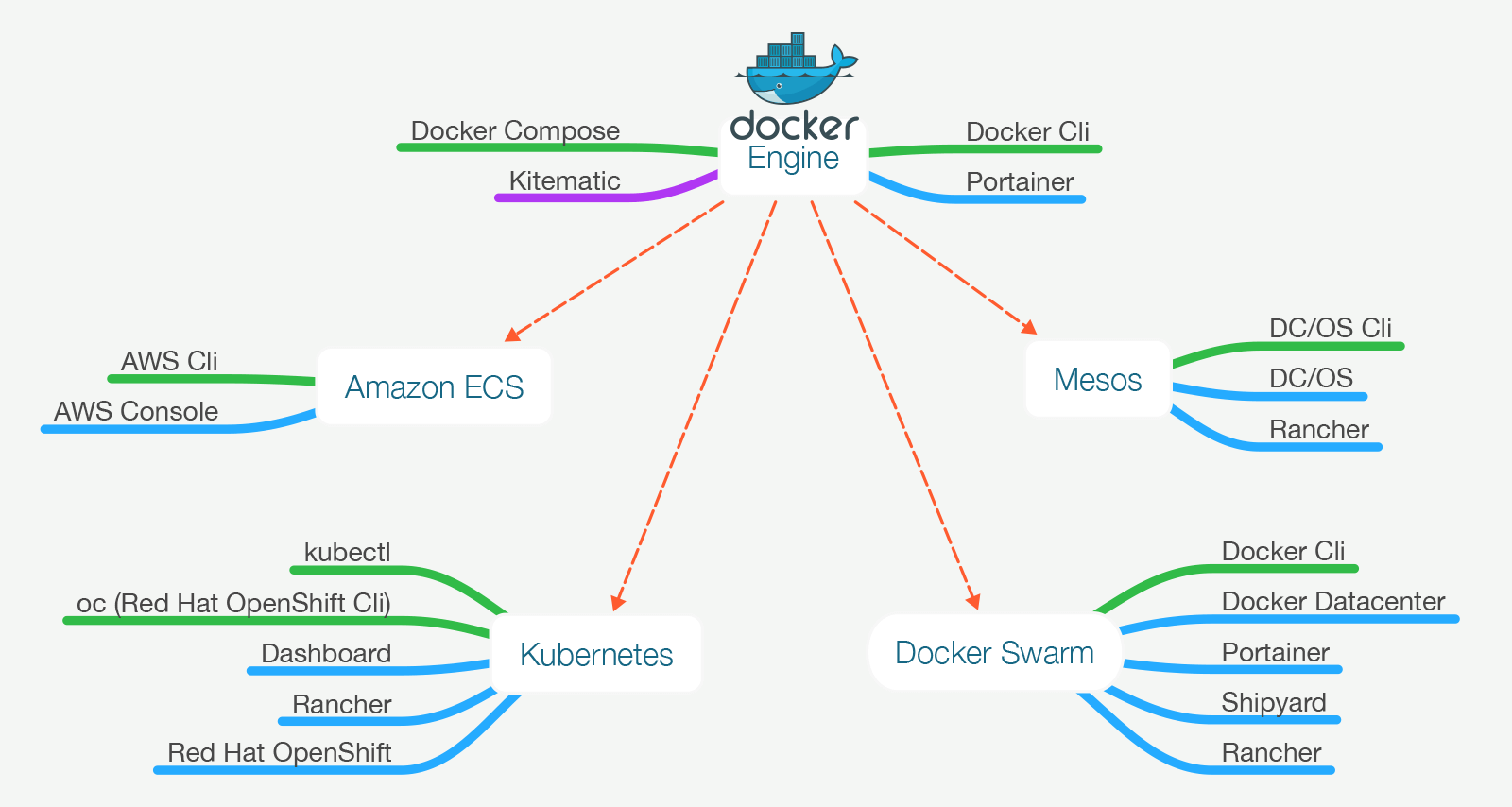
- DevOps Kubernetes vs. Docker Swarm vs. Apache Mesos: Container Orchestration Comparison
Google
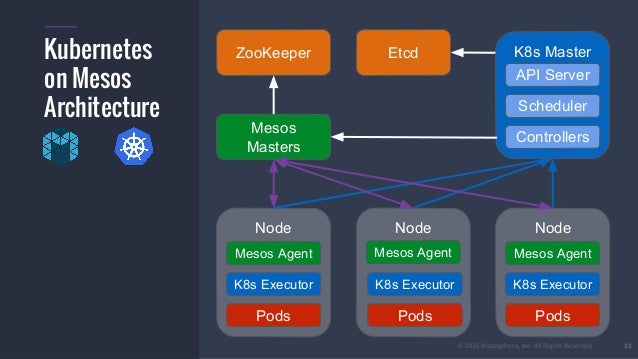
Kubernetes
While a single master can control our complete setup, in production environments multiple masters are the norm.
Note that, because the masters expose its API trough REST,
a load balancer solution is required in front of the masters
in order to have true high availability and multi-server load balancing.
a discovery layer is needed here, being "
etcd" one of the big players. Our
etcd layer should
be running inside their own
nodes, with at least two servers in an
etcd cluster
in order to provide redundancy. You can run
etcd either inside containers, or directly in the host operating system.
Linux solutions like CoreOS already include
etcd in its core packages. Like in Swarm,
etcd will keep a registry of what is running and where is running across the entire
Kubernetes infrastructure.
Apache
Mesos/Marathon
Marathon is a framework which uses
Mesos in order to orchestrate Docker containers.
Container Deployment
Docker Swarm: Completely Docker based and very easy
to setup.
Completely native to Docker.
Kubernetes: YAML based for all components in a deployed application (pods, services, and replication controllers).
Mesos: JSON based. All application definitions go inside a JSON file which
is passed to the
Mesos/Marathon REST API.
Minimum Size (Cluster)
Docker Swarm: One server running everything (for test purposes). In practical production environments, both the discovery and managers services need to be in highly available setups with at least two servers on each layer.
Multiple workers are also needed for services distribution and replication.
Kubernetes: One server for Master (and discovery), and one server for node/minion. In production setups, discovery services and Master services should
be clustered with at least 3 servers on each layer, and as many minions as your infrastructure requires.
Mesos: On master and one slave. In practical production environments, at least 3 masters and several slaves as needed.
Maturity
Docker Swarm: Mature, but still evolving.
Kubernetes: Very mature. Direct descendant of Google internal BORG Platform.
Mesos: Very mature, especially for
very big clusters counting in the thousands of servers.
https://www.loomsystems.com/blog/single-post/2017/06/19/kubernetes-vs-docker-swarm-vs-apache-mesos-container-orchestration-comparison
- Kubernetes vs Docker Swarm vs Mesos – A Look at the Major COEs from an Architect’s Perspective
Some high-level features
that they share are:
Container scheduling
High availability of either the application and containers or the orchestration system itself.
Parameters to determine container or application health.
Service discovery
Load Balancing requests
Attributing various types of storage to containers in a cluster.
Kubernetes
Google itself uses Kubernetes as its own Container
as s Service
(CaaS) platform, known as Google Container Engine. OpenShift, Red Hat and MS Azure are among some other platforms that support Kubernetes.
Kubernetes is purely built on YAML based deployment model, but it also supports JSON.
YAML is highly recommended due to its user-friendly functionalities.
Secret feature management, load balancing, auto-scaling and overall volume management are
some of the major built-in features present in
Kubernetes.
Mesos
a more distributed approach towards managing cloud resources and data centers.
Other container management frameworks can be run on top of
Mesos, including
Kubernetes, Apache Aurora, Chronos, and Mesosphere Marathon
Mesosphere DC/OS, a distributed
datacenter operating system,
is based on Apache
Mesos.
https://afourtech.com/kubernetes-vs-docker-swarm-vs-mesos/
- Kubernetes vs Docker Swarm
etcd: This component stores configuration data which can be accessed by the
Kubernetes Master’s API Server using simple HTTP or JSON API.
API Server: This component is the management hub for the
Kubernetes master node. It facilitates communication between the various components,
thereby maintaining cluster health.
Controller Manager: This component ensures that the cluster’s desired state matches the current state by scaling workloads up and down.
Scheduler: This component places the workload on the
appropriate node
– in this case, all workloads will
be placed locally on your host.
Kubelet: This component receives pod specifications from the API Server and manages pods running in the host.
The following list provides some other common terms associated with
Kubernetes:
Pods:
Kubernetes deploys and schedules containers in groups called pods. Containers in a pod run on the same node and share resources such as filesystems, kernel
namespaces, and an IP address.
Deployments:
These building blocks can be used to create and manage a group of pods.
Deployments can be used with a service tier for scaling horizontally or ensuring availability.
Services: Services are endpoints that can
be addressed by name and can
be connected to pods using label selectors. The service will automatically round-robin requests between pods.
Kubernetes will set up a DNS server for the cluster that watches for new services and allows
them to be addressed by name. Services are the “external face” of your container workloads.
Labels: Labels are key-value pairs attached to objects and can
be used to search and update multiple objects as a single set.
Kubernetes is also backed by enterprise offerings from both Google (GKE) and
RedHat (OpenShift).
Open source projects. Anyone can contribute using the Go programming language.
Logging and Monitoring add-ons. These external tools include Elasticsearch/Kibana (ELK),
sysdig,
cAdvisor,
Heapster/
Grafana/InfluxDB.
https://platform9.com/blog/kubernetes-docker-swarm-compared/
- Orchestration Platforms in the Ring: Kubernetes vs Docker Swarm
Much of Kubernetes’ success stems from its origin as an open-sourced version of Borg, the workload orchestration platform that supported Google’s infrastructure for over a decade prior to Kubernetes release.
This credibility was accompanied by a massive show of interest from the Developer Community, which has made Kubernetes into one of the most popular open-source projects on GitHub. This stamp of approval from the Open-Source Community backed with
a number of high profile successful installments of Kubernetes makes it
an extremely popular choice
today
One key advantage that Docker Swarm seems to have over
Kubernetes is the tight integration that it has with the Docker ecosystem
as a whole. Docker Swarm, being
a afterthought to the core Docker product, introduced orchestration that was backwards compatible and integrated with existing Docker tooling, such as docker-
compose
Docker Swarm also advertises itself as easy to use, especially
in comparison to other container orchestration offerings. It seeks to accomplish this through a declarative API that is immediately familiar to anyone who
is experienced with the Docker API. After
a swarm has been initialized on a node,
other nodes can be joined to the swarm through a simple “docker swarm join” command. This method lets users quickly begin experimenting with orchestrating containerized workloads on a
multi node Docker
swarm
Docker, realizing the strength of its container technology,
decided to build a platform that made it simple for Docker users to
begin orchestrating their container workloads across multiple nodes. However, their desire to preserve this tight coupling can
be said to have limited the extensibility of the platform.
Kubernetes, on the other hand, took key concepts taken from Google Borg, and, from a high level perspective,
decided to make containerization fit into the former platform’s existing workload orchestration model. This resulted in
Kubernetes emphasis on reliability, sometimes at the cost of simplicity and performance.
https://www.nirmata.com/2018/01/15/orchestration-platforms-in-the-ring-kubernetes-vs-docker-swarm/
- Docker Clustering Tools Compared: Kubernetes vs Docker Swarm
Kubernetes is based on Google’s experience of many years working with Linux containers.
It solved many of the problems that Docker itself had. We could mount persistent volumes that would allow us to move containers without loosing data, it used flannel to create networking between
containers, it has load balancer
integrated, it uses
etcd for service discovery, and so
on
However,
Kubernetes comes at a cost. It uses a different CLI, different API and different YAML definitions.
In other words, you cannot use Docker CLI nor you can use Docker Compose to define containers.
Kubernetes setup is quite more complicated and obfuscated. Installation instructions differ from OS to OS and
provider to
provider.
As an example, if you
choose to try it out with Vagrant, you
are stuck with Fedora. That does not mean that you cannot run it with Vagrant and, let’s say, Ubuntu or CoreOS. You can, but you need to
start searching for instructions outside the official
Kubernetes Getting Started page.
We might not want to run a script but make
Kubernetes be part of our Puppet, Chef or Ansible definitions
While some might not care about
which discovery tool is used, I love the simplicity behind Swarm and the logic “batteries included but removable”. Everything works out-of-the-box but we still have the option to substitute one component with the other. Unlike Swarm, Kubernetes is an opinionated tool. You need to live with the choices it made for you. If you want to use Kubernetes,
you have to use
etcd.
if you prefer, for example, to use Consul you’re in a very complicated situation and would need to use one for
Kubernetes and the other for the rest of your service discovery needs
Kubernetes requires you to learn its CLI and configurations. You cannot use docker-compose
.yml definitions you created earlier.
You’ll have to create Kubernetes equivalents. You cannot use Docker CLI commands you learned before.
You’ll have to learn Kubernetes CLI and, likely, make sure that the whole organization learns it
as well.
If you adopt Kubernetes,
be prepared to have multiple definitions of the same thing. You will need Docker Compose to run your containers outside Kubernetes. Developers will continue needing to run containers on their laptops, your staging environments might or might not be a big cluster, and so on.
In other words, once you adopt Docker, Docker Compose or Docker CLI are unavoidable.
You have to use them
one way or another. Once you
start using Kubernetes you
will discover that all your Docker Compose definitions (or whatever else you might
be using) need to
be translated to Kubernetes way of describing things and, from there on,
you will have to maintain both. With Kubernetes everything will have to
be duplicated resulting in
higher cost of maintenance. And it’s not only about duplicated configurations. Commands you’ll run outside of the cluster will
be different from those inside the cluster. All those Docker commands you learned and love will have to get their Kubernetes equivalents inside the
cluster
Swarm team
decided to match their API with the one from Docker. As a result, we have (almost) full compatibility. Almost everything we can do with Docker we can do with Swarm as well only on a much larger scale. There’s nothing new to do, no configurations to
be duplicated and nothing new to learn. No matter whether you use Docker CLI directly or go through Swarm, API is (more or less) the same. The negative side of that story is that if there is something you’d like Swarm to do and that something is not part of the Docker API, you’re in for a disappointment. Let us simplify this a bit. If you’re looking for a tool for deploying containers in a cluster that will use Docker API, Swarm is the solution.
On the other hand, if you want a tool that will overcome Docker limitations,
you should go with Kubernetes. It is power (Kubernetes) against simplicity (Swarm). Or, at least, that’s how it was until recently
Actually, we still cannot link them but now we have multi-host networking to help us connect containers running on different servers. It is a
very powerful feature.
Kubernetes used flannel to accomplish networking and now, since the Docker release 1.9, that feature is available as part of Docker CLI.
Another problem was persistent volumes. Now we have persistent volumes supported by Docker natively.
Both networking and persistent volumes problems were one
of the features supported by
Kubernetes for quite some time and the reason
why many were choosing it over Swarm. That advantage disappeared with Docker release 1.9.
Docker Swarm took a different approach. It is a native clustering for Docker.
The best part is that it exposes standard Docker API meaning that any tool
that you
used to communicate with Docker (Docker CLI, Docker Compose,
Dokku, Krane, and so on) can work equally well with Docker Swarm
If the API doesn’t support something, there is no way around it through Swarm API and some clever tricks need to
be performed.
Setting up Docker Swarm is easy, straightforward and flexible.
All we have to do is install one of the service discovery tools and run the swarm container on all nodes. Since the distribution
itself is packed as a Docker container, it works, in the same way, no matter the operating system.
We run the swarm container, expose a port and inform it about the address of the service discovery
when our usage of it becomes more serious, add
etcd, Consul or some of the other supported tools.
When trying to make a choice between Docker Swarm and Kubernetes, think in the following terms. Do you want to depend on Docker itself solving problems related to clustering? If you do, choose Swarm. If something
is not supported by
Docker it will be unlikely that
it will be supported by Swarm since it relies on Docker API.
On the other hand, if you want a tool that works around Docker limitations, Kubernetes might be the right one for you. Kubernetes
was not built around Docker but
is based on Google’s experience with containers. It is opinionated and tries to do things in its own way.
https://technologyconversations.com/2015/11/04/docker-clustering-tools-compared-kubernetes-vs-docker-swarm/
“
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.”
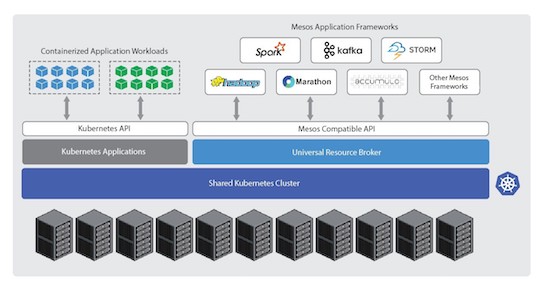
Apache
Mesos is an open-source cluster manager designed to scale
to very large clusters, from hundreds to thousands of hosts.
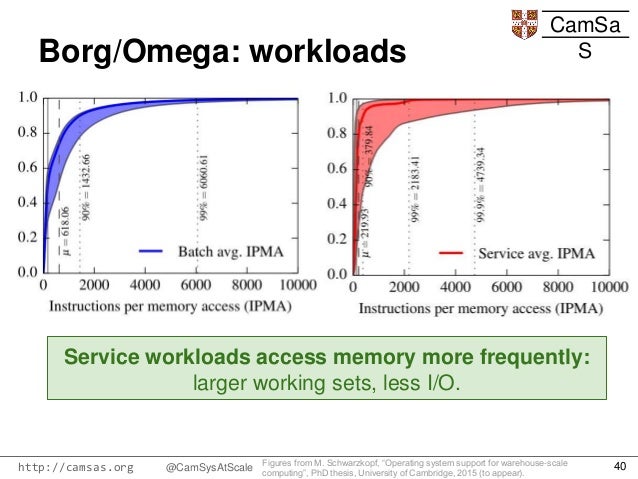
Mesos supports diverse kinds of workloads such as Hadoop
tasks, cloud-native applications
etc
Container Orchestration Tools: Compare
Kubernetes vs
Mesos
Mesos can work with multiple frameworks and Kubernetes is one of them. To give you more choice, if it meets your use case, it is also possible to run Kubernetes on
Mesos.
https://platform9.com/blog/compare-kubernetes-vs-mesos/
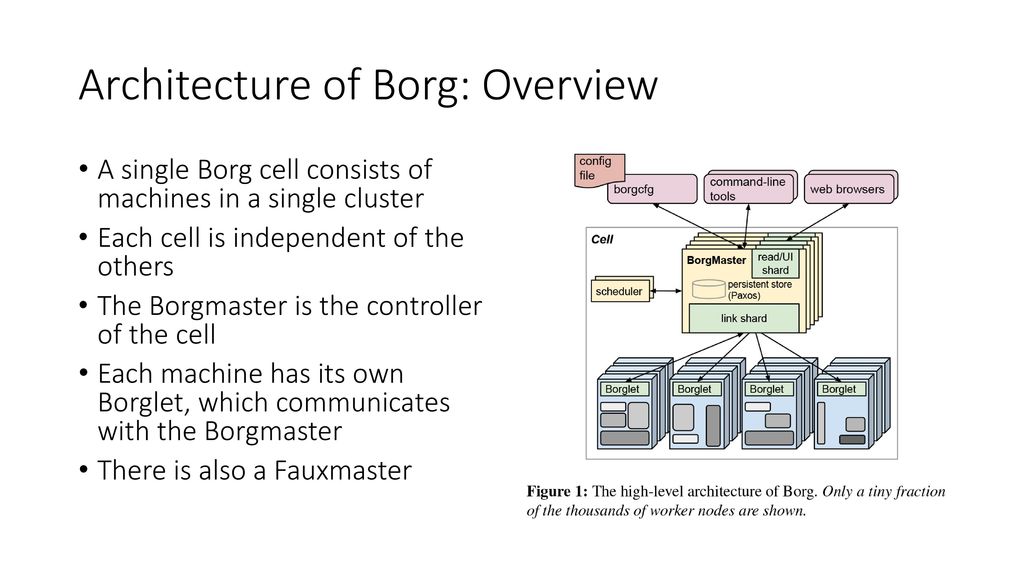
- Google's Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across a number of clusters each with up to tens of thousands of machines.
It achieves high utilization by combining admission control, efficient task-packing
https://ai.google/research/pubs/pub43438
- At Google, we have been managing Linux containers at scale for more than ten years and built three different container-management systems in that time.
The first unified container-management system developed at Google was the system we internally call Borg
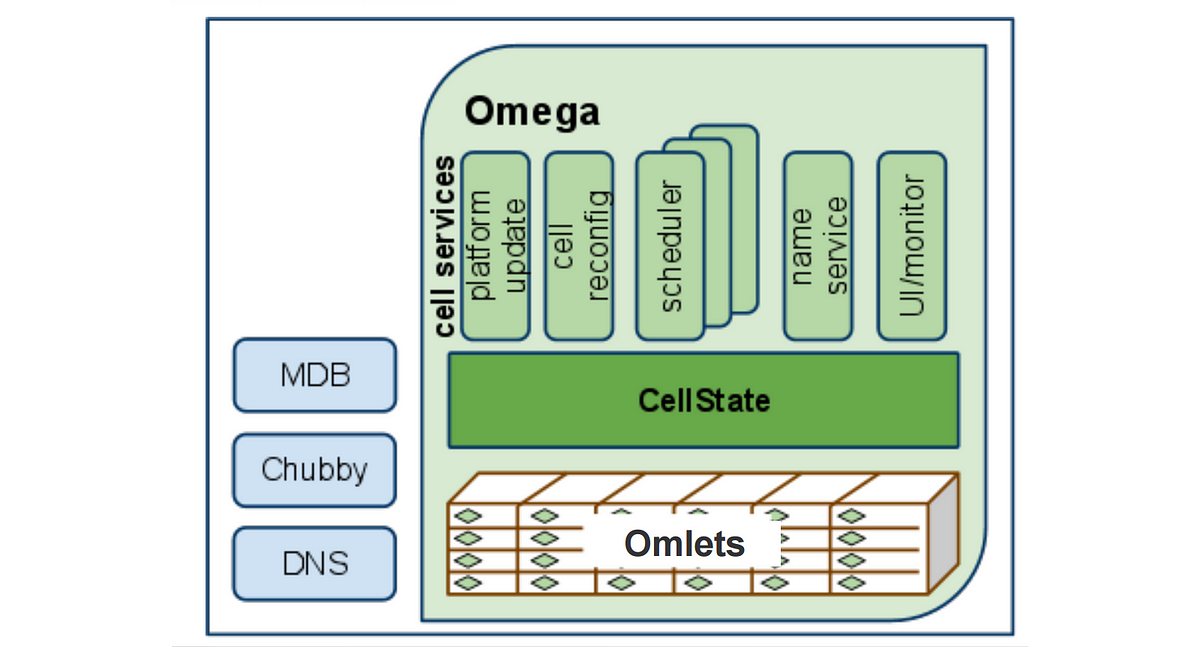
Omega,
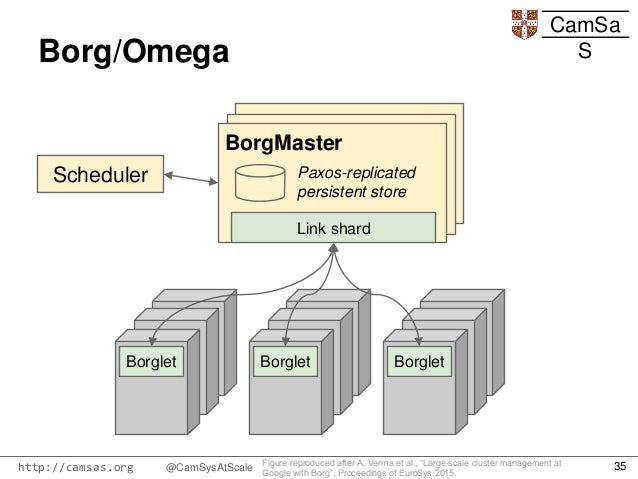
an offspring of Borg, was driven by a desire to improve the software engineering of the Borg ecosystem.
Omega stored the state of the cluster in a centralized Paxos-based transaction-oriented store
that was accessed by the different parts of the
cluster control plane (such as schedulers)
The third container-management system developed at Google was
Kubernetes
Kubernetes is
open source—a contrast to Borg and Omega, which
were developed as purely Google-internal systems.
In contrast to Omega, which exposes the store directly to
trusted control-plane components,
state in
Kubernetes is accessed exclusively through a domain-specific REST API that applies higher-level versioning,
validation, semantics, and policy,
in support of a more diverse array of clients.
More importantly,
Kubernetes was developed with a stronger focus on the experience of
developers writing applications that run in a cluster: its main design goal is to make it easy to deploy and manage complex
distributed systems, while still
benefiting from the improved utilization that containers enable.
The key to making this abstraction work is having a hermetic container image that can encapsulate almost all of an application’s dependencies into a package that can
be deployed into the container.
applications can still
be exposed to churn in the OS interface, particularly in the wide surface area exposed by
socket options, /proc, and arguments to
ioctl calls.
the isolation and dependency minimization provided by containers have proved
quite effective at Google
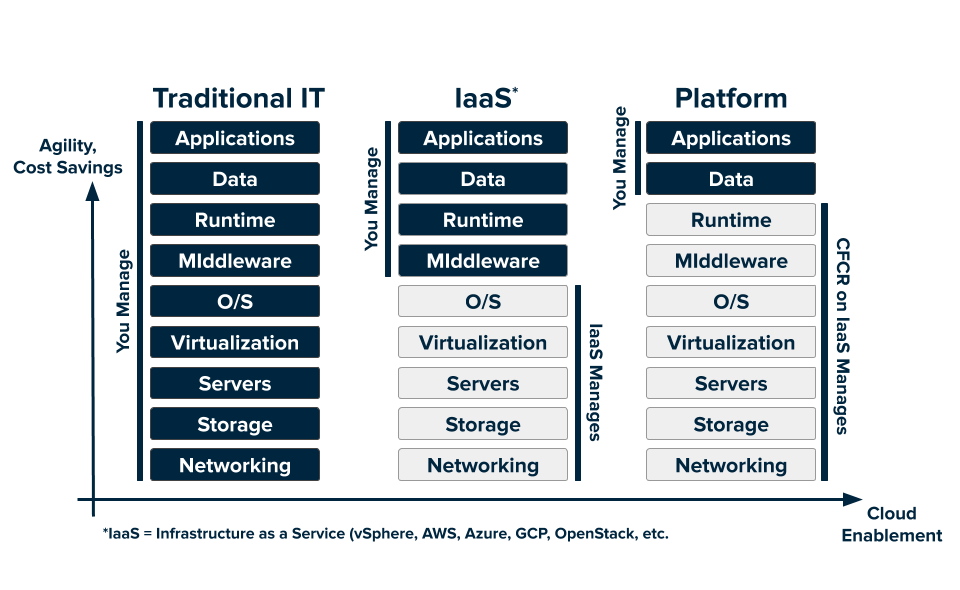
(1) it relieves application developers and operations teams from worrying about specific details of machines and operating systems;
(2) it provides the infrastructure team flexibility to roll out new hardware and upgrade operating systems with minimal impact on running applications and their developers;
(3) it ties telemetry collected by the management system (e.g., metrics such as CPU and memory usage) to applications rather than machines, which dramatically improves
application monitoring and introspection, especially when scale-up, machine failures, or maintenance cause application instances to move.
For example, the /
healthz endpoint reports application health to the orchestrator. When an unhealthy application
is detected, it
is automatically terminated and restarted. This self-healing is a key building block for reliable distributed systems.
(
Kubernetes offers similar functionality; the health check uses a user-specified HTTP endpoint or exec command that runs inside the container.)
For example, Borg applications can provide a simple text status message that can
be updated dynamically, and
Kubernetes
provides key-value annotations stored in each object’s metadata that can
be used to communicate application structure.
This is simpler, more robust, and permits finer-grained reporting and control of metrics and logs. Compare
this to having to ssh into a machine to run top
. Though it is possible for developers to ssh into their containers, they rarely need to.
The application-oriented shift has ripple effects throughout the management infrastructure. Our load balancers don’t balance traffic
across machines;
they balance across application instances.
Logs
are keyed by application, not the machine, so they can easily
be collected and aggregated across instances without
pollution from multiple applications or system operations.
In reality, we use nested containers that are co-scheduled on the same machine: the outermost
one provides a pool of resources; the inner ones provide deployment isolation
In Borg, the outermost container
is called a resource allocation, or
alloc; in
Kubernetes, it
is called a pod
Kubernetes regularizes things and always runs an application container inside a top-level pod, even if the pod contains a single container.
The original Borg system made it possible to run disparate workloads on shared machines to improve resource utilization.
Kubernetes is built from a set of composable building blocks
that can readily be extended by its users.
For example, the pod API is usable by people, internal
Kubernetes components, and external automation tools.
To further this consistency,
Kubernetes is being extended to enable users to add their own APIs dynamically, alongside the core
Kubernetes functionality.
A good example of this is the separation between the
Kubernetes replication controller and its horizontal auto-scaling system.
A replication controller ensures the existence of the desired number of pods for a
given role (e.g., “front end”)
.The
autoscaler, in turn, relies on this capability and
simply adjusts the desired number of pods, without worrying about
how those pods
are created or deleted
Decoupling ensures that multiple related but different components share a similar look and feel.
The design of
Kubernetes as a combination of
microservices and small control loops is an example
of control through choreography
—achieving a desired emergent behavior by combining the effects of separate,
autonomous entities that collaborate.
We present some of them here
in the hopes that others can focus on making new mistakes, rather than repeating ours.
Don’t make the container system
manage port numbers
Don’t just number containers give them labels
Be careful with ownership
Don’t expose raw state
if one of these pods
starts misbehaving, that pod can
be quarantined from serving requests by removing
one or more of the labels that cause it to be targeted by the
Kubernetes service load balancer. The pod is no longer
serving traffic, but it will remain up and can
be debugged in situ. In the meantime, the replication controller managing
the pods that implements the service automatically creates a replacement pod for the misbehaving one.
SOME OPEN HARD PROBLEMS
Configuration; managing configurations
—the set of values supplied to applications, rather than hard-coded into them.
Dependency management; instantiating the dependencies is rarely as simple as just starting a new copy
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/44843.pdf
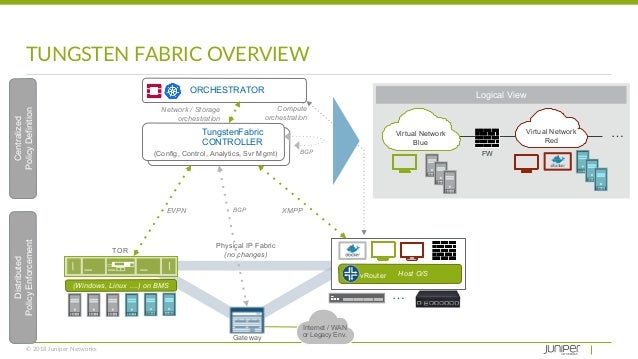
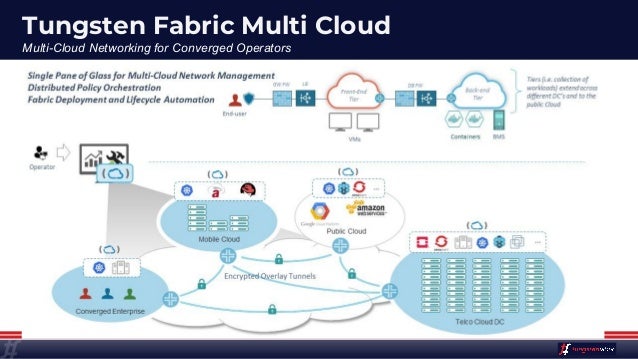
- Solve your tooling complexity and overload with the simplicity of only one networking and security tool. Save time and swivel-chair fatigue from context switches as you consolidate:
- Connecting multiple orchestration stacks like Kubernetes, Mesos/SMACK, OpenShift, OpenStack and VMware.
- Choosing an SDN plug-in for CNI, Neutron, or vSphere.
- Networking and security across legacy, virtualized and containerized applications.
- Multistack and across-stack policy control, visibility and analytics.



- fabric8 is an end to end development platform spanning ideation to production for the creation of cloud native applications and microservices. You can build, test and deploy your applications via Continuous Delivery pipelines then run and manage them with Continuous Improvement and ChatOps
http://fabric8.io/
- Pacemaker is a high-availability cluster resource manager.
It achieves maximum availability for your cluster services (a
.k
.a. resources) by detecting and recovering from node- and resource-level failures by making use of the messaging and membership capabilities provided by Corosync.
https://wiki.clusterlabs.org/wiki/Pacemaker
Fencing Devices
The fencing device is a hardware/software device which helps to disconnect the problem node by resetting node / disconnecting shared storage from accessing it
https://www.itzgeek.com/how-tos/linux/centos-how-tos/configure-high-avaliablity-cluster-on-centos-7-rhel-7.html
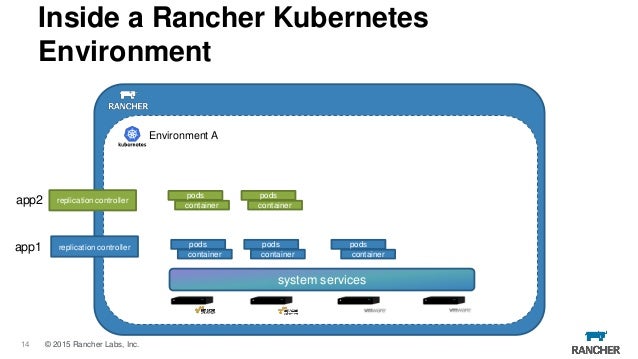
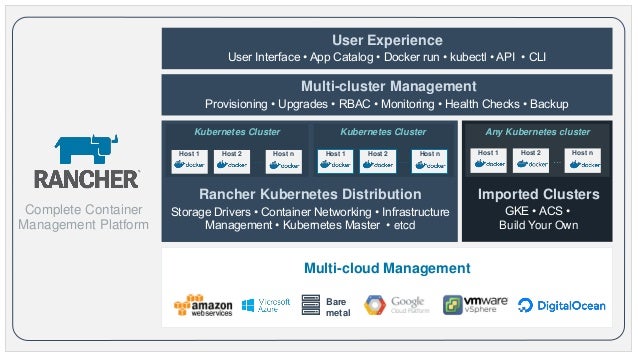
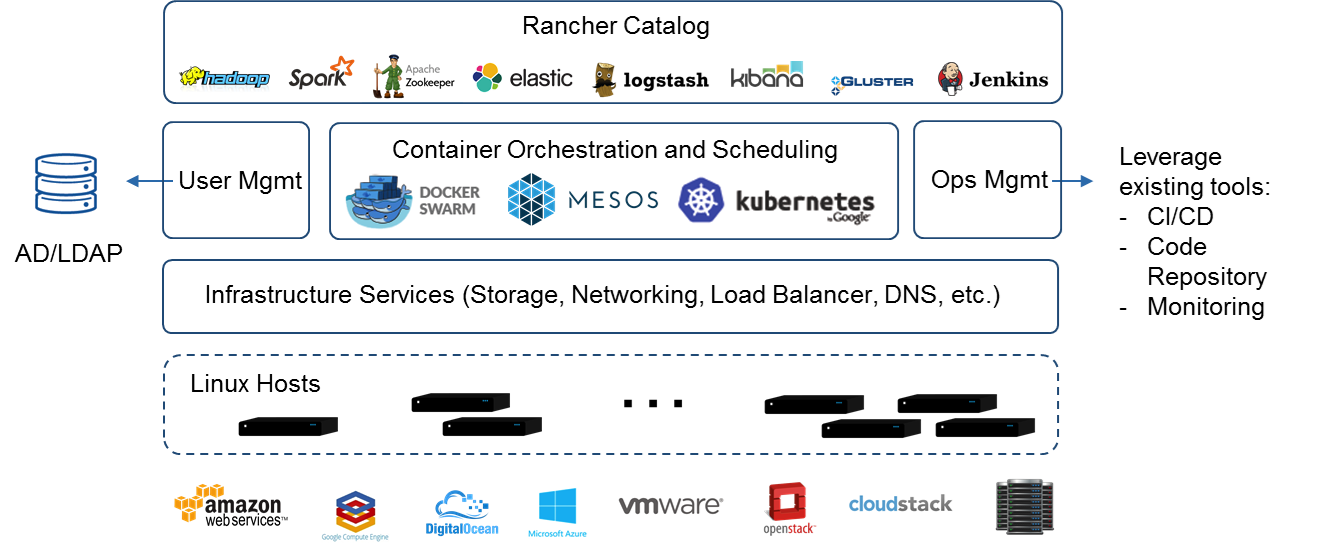
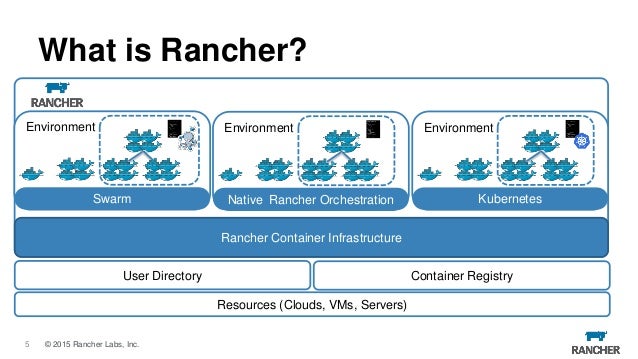
- Rancher is an open source project that provides a complete platform for operating Docker in production. It provides infrastructure services such as multi-host networking, global and local load balancing, and volume snapshots. It integrates native Docker management capabilities such as Docker Machine and Docker Swarm. It offers a rich user experience that enables devops admins to operate Docker in production at large scale.
https://rancher.com/what-is-rancher/open-source/
- As the global industry standard for PaaS open source technology, we operate under an open governance by contribution model.Cloud Foundry gives companies the speed, simplicity and control they need to develop and deploy applications faster and easier.Cloud Foundry makes it faster and easier to build, test, deploy and scale applications, providing a choice of clouds, developer frameworks, and application services. It is an open source project and is available through a variety of private cloud distributions and public cloud instances.
https://www.cloudfoundry.org/
- Docker Compose is used to run multiple containers as a single service
For example, suppose you had an application which required NGNIX and MySQL, you could create one file which would start both the containers as a service without the need to start each one separately.
All Docker Compose files are YAML files.
https://www.tutorialspoint.com/docker/docker_compose.htm
- What is Docker Compose?
If your Docker application includes
more than one container (for example, a
webserver and database running in separate containers), building, running, and connecting the containers from separate
Dockerfiles is cumbersome and time-consuming. Docker Compose solves this problem by allowing you to use a YAML file to define multi-container apps. You can configure as many containers as you want, how they should
be built and connected, and where data should
be stored. When the YAML file is complete, you can run a single command to build, run, and configure
all of the containers.
https://www.linode.com/docs/applications/containers/how-to-use-docker-compose
- For instance, as a developer,
how can I easily recreate a
microservice architecture on my development machine?
And how can I be sure
that it remains unchanged as it propagates through a Continuous Delivery process?
And finally, how can I be sure that a complex build & test environment can
be reproduced easily?
For multi-host deployment,
you should use more advanced solutions, like Apache
Mesos or a complete Google
Kubernetes architecture.
The main function of Docker Compose is the creation of
microservice architecture, meaning the containers and the links between them.
https://blog.codeship.com/orchestrate-containers-for-development-with-docker-compose
- Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration.
https://docs.docker.com/compose/overview/
- Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration
Common use cases
Development environments
When you’re developing software, the ability to run an application in an isolated environment and interact with it is crucial
Automated testing environments
An important part of any Continuous Deployment or Continuous Integration process is the automated test suite. Automated end-to-end testing requires an environment in which to run tests. Compose provides a convenient way to create and destroy isolated testing environments for your test suite. By defining the full environment in a Compose file, you can create and destroy these environments in just a few commands
Single host deployments
You can use Compose to deploy to a remote Docker Engine. The Docker Engine may be a single instance provisioned with Docker Machine or an entire Docker Swarm cluster
https://docs.docker.com/compose/overview/#automated-testing-environments
- The main function of Docker Compose is the creation of microservice architecture, meaning the containers and the links between them.
Docker Compose Workflow
There are three steps to using Docker Compose:
Define each service in a
Dockerfile.
Define the services and their relation to each other in the docker-compose
.yml file.
Use docker-compose up to start the system.
https://blog.codeship.com/orchestrate-containers-for-development-with-docker-compose/
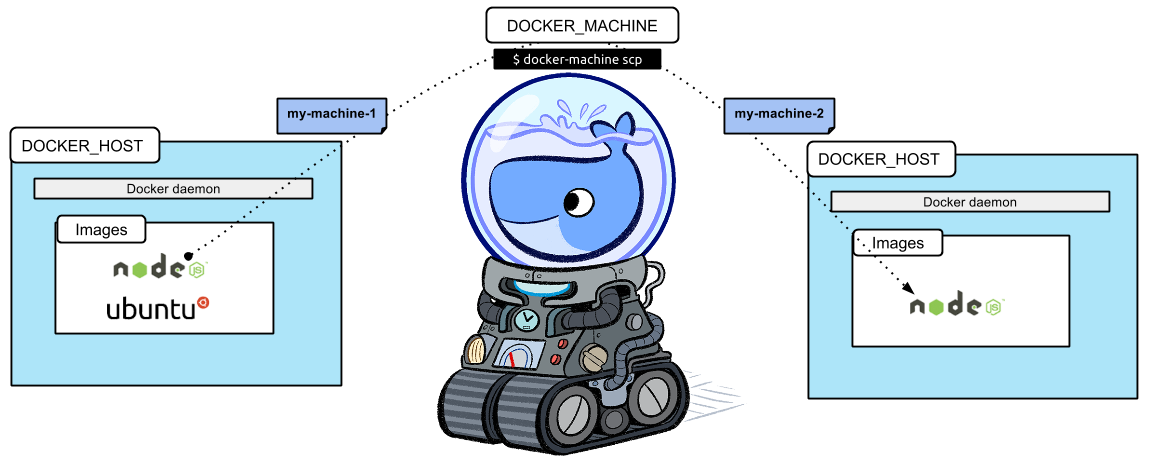
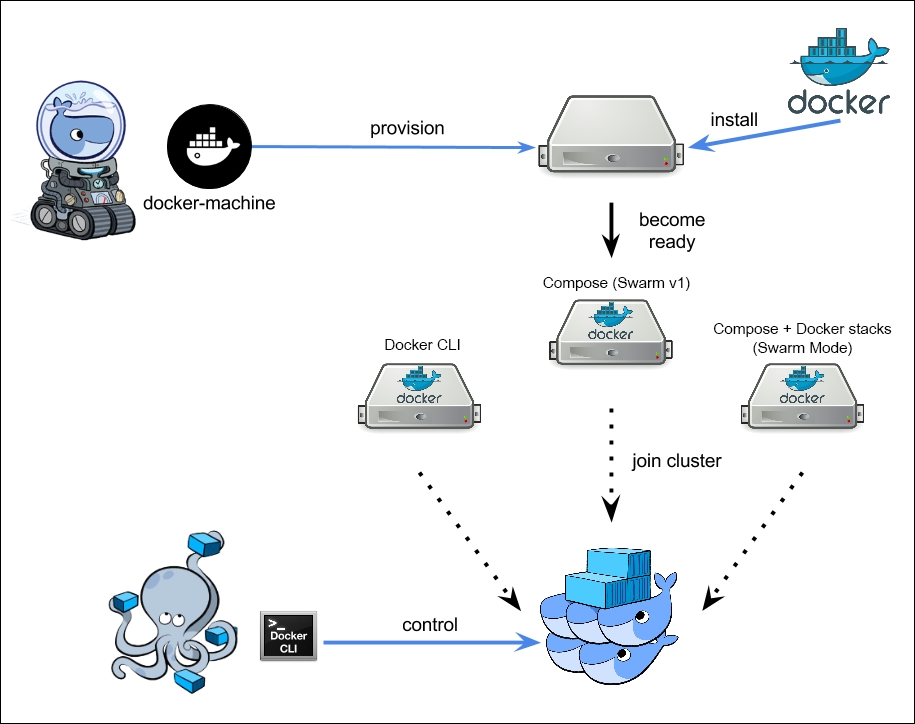
- You can use Docker Machine to:
Install and run Docker on Mac or Windows
Provision and manage multiple remote Docker hosts
Provision Swarm clusters
What is Docker Machine?
Docker Machine is a tool that lets you install Docker Engine on virtual
hosts, and manage the hosts with docker-machine commands. You can use Machine to create Docker hosts on your local Mac or Windows box, on your company network, in your data center, or on cloud providers like Azure, AWS, or Digital Ocean.
https://docs.docker.com/machine/overview/
- What is Docker Machine?
Docker Machine is a tool that lets you install Docker Engine on virtual
hosts, and manage the hosts with docker-machine commands. You can use Machine to create Docker hosts on your local Mac or Windows box, on your company network, in your data center, or on cloud providers like Azure, AWS, or Digital Ocean.
Why should I use it?
Docker Machine enables you to provision multiple remote Docker hosts on various flavors of Linux.
Docker Engine runs natively on Linux systems. If you have a Linux box as your primary system, and want to run
docker commands, all you need to do is download and install Docker Engine. However, if you want an efficient way to provision multiple Docker hosts on a network, in the cloud or even locally, you need Docker Machine.
What’s the difference between Docker Engine and Docker Machine?
When people say “Docker” they typically mean Docker Engine, the client-server application made up of the Docker daemon, a REST API that specifies interfaces for interacting with the daemon, and a
command line interface (CLI) client that talks to the daemon (through the REST API wrapper). Docker Engine accepts
docker commands from the CLI, such as docker run <image>,
docker ps to list running containers,
docker image
ls to list images, and so on.
Docker Machine is a tool for provisioning and managing your Dockerized hosts (hosts with Docker Engine on them). Typically, you install Docker Machine on your local system. Docker Machine has its own
command line client docker-machine and the Docker Engine client, docker. You can use Machine to install Docker Engine on one or more virtual systems. These virtual systems can be local (as when you use Machine to install and run Docker Engine in
VirtualBox on Mac or Windows) or remote (as when you use Machine to provision Dockerized hosts on cloud providers). The Dockerized hosts
themselves can be thought of, and
are sometimes referred to as, managed “machines”.
https://docs.docker.com/machine/overview/#what-is-docker-machine
Docker Stack:
Define and run multiple containers on a swarm cluster.
Just like docker-compose helps you define and run multi-container applications on a single host, docker-stack helps you define and run multi-container applications on a swarm cluster.
Docker:
Build, ship, publish, download, and run docker images.
Docker Compose:
Define and run multiple containers linked
together on a single host.
Useful for setting up development and testing workflows.
Docker Machine:
Tool for provisioning and managing docker hosts (virtual hosts running docker engine).
It automatically creates hosts, installs Docker Engine on them, then configures the docker clients.
You can use Machine to create Docker hosts on your local machine using a virtualization software like
VirtualBox or
VMWare Fusion.
Docker machine also supports various cloud providers like AWS, Azure, Digital Ocean, Google Compute Engine, OpenStack,
RackSpace etc.
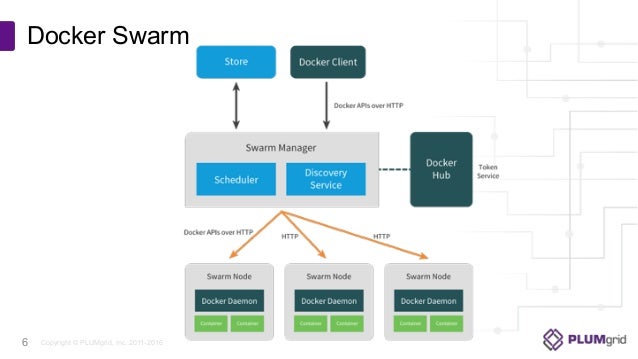
Docker Swarm:
A swarm is a group of docker hosts linked
together into a cluster.
The swarm cluster
consists of a
swarm manager and a set of workers.
You interact with the cluster by executing commands on the
swarm manager.
With
swarm, you can deploy and scale your applications to multiple hosts.
Swarm helps with managing, scaling, networking, service discovery, and load balancing between the nodes in the cluster.
Docker Stack:
Define and run multiple containers on a swarm cluster.
https://www.callicoder.com/docker-machine-swarm-stack-golang-example/
Containers as a Service (CaaS)
To deliver the consistent experience for developers and IT ops, teams began using Docker for Containers as a Service (
CaaS).
Containers as a Service is a model where IT organizations and developers can work together to build, ship and run their applications anywhere.
CaaS enables an IT secured and managed application environment
consisting of content and infrastructure, from which developers are
able build and deploy applications in a
self service manner.
https://blog.docker.com/2016/02/containers-as-a-service-caas
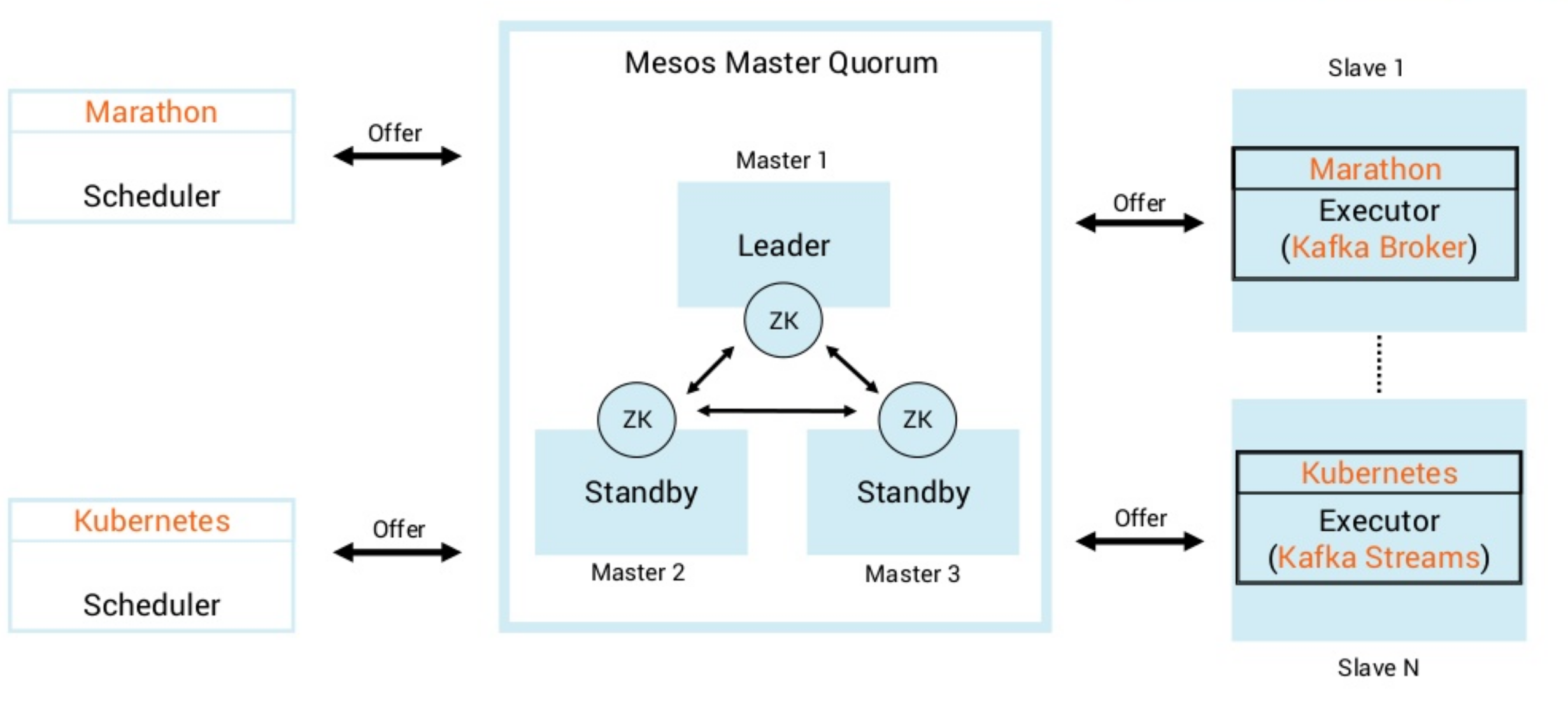
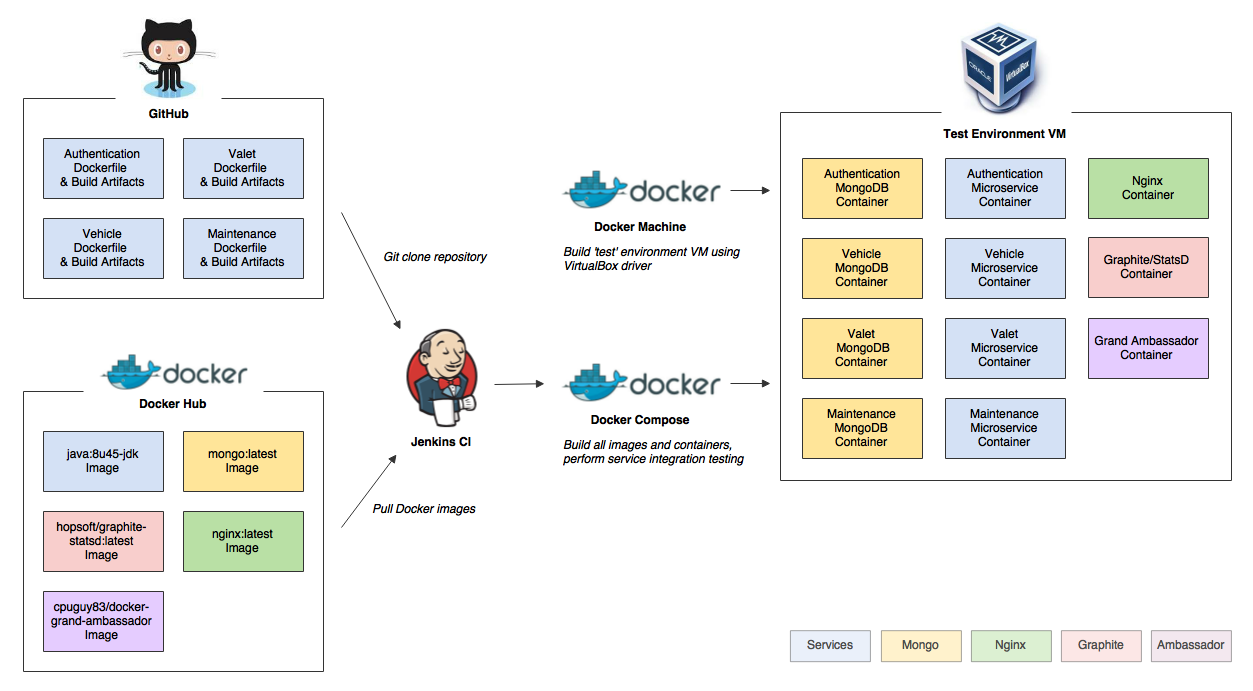
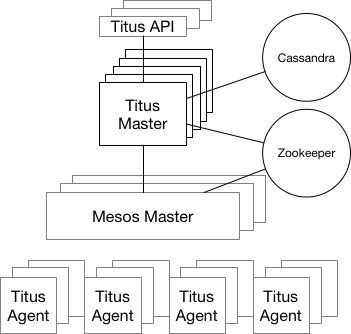
- Titus is a container management platform that provides scalable and reliable container execution and cloud-native integration with Amazon AWS
Titus is a framework on top of Apache
Mesos, a cluster-management system that brokers available resources across a fleet of machines. Titus
consists of a replicated, leader-elected scheduler called Titus Master, which handles the placement of containers onto a large pool of EC2 virtual machines called Titus Agents, which manage each container's life cycle. Zookeeper manages leader election, and Cassandra persists the master's data.
The Titus architecture is shown below.
https://netflix.github.io/titus/overview/