- Artificial intelligence (AI), sometimes called machine intelligence, is intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans and other animals. In computer science, AI research is defined as the study of "intelligent agents": any device that perceives its environment and takes actions that maximize its chance of successfully achieving its goals.
Deep learning is an artificial neural network that can learn a long chain of causal links. For example, a
feedforward network with six hidden layers can learn a seven-link causal chain (six hidden layers + output layer) and has a "credit assignment path" (CAP) depth of seven. Many deep learning systems need to
be able to learn chains ten or more causal links
in length
Machine learning, a fundamental concept of AI research since the field's inception is the study of computer algorithms that improve automatically through experience
https://en.wikipedia.org/wiki/Artificial_intelligence
In artificial intelligence, an expert system is a computer system that emulates the decision-making ability of a human expert.
http://en.wikipedia.org/wiki/Expert_system
- Acumos is a platform which enhances the development, training, and deployment of AI models. This frees data scientists and model trainers to focus on their core competencies rather than endlessly customizing, modeling, and training an AI implementation
https://wiki.acumos.org/pages/viewpage.action?pageId=1015856
H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. H2O supports the most widely used statistical & machine learning algorithms
https://www.h2o.ai/
The Apache Mahout™ machine learning library's goal is to build scalable machine learning libraries
http://mahout.apache.org/
- Natural language processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. Specifically, it is the process of a computer extracting meaningful information from natural language input and/or producing natural language output.[1] In theory, natural language processing is a very attractive method of human-computer interaction. Natural language understanding is sometimes referred to as an AI-complete problem because it seems to require extensive knowledge about the outside world and the ability to manipulate it.
http://en.wikipedia.org/wiki/Natural_language_processing
- Artificial Intelligence vs. Machine Learning vs. Deep Learning
Artificial intelligence is a broader concept than machine learning, which addresses the use of computers to mimic the cognitive functions of humans.
When machines carry out tasks based on algorithms in an “intelligent” manner, that is AI. Machine learning is a subset of AI and focuses on the ability of machines to receive a set of data and learn for themselves, changing algorithms as they learn more about the information they are processing.
Training computers to think like humans
is achieved partly through the use of neural networks.
Neural networks are a series of algorithms modeled after the human brain.
Just as the brain can recognize patterns and help us categorize and classify information, neural networks do the same for computers
Deep learning goes yet another level deeper and can
be considered a subset of machine learning.
The concept of deep learning is sometimes just referred to as "deep neural networks," referring to the many layers involved.
https://www.datasciencecentral.com/profiles/blogs/artificial-intelligence-vs-machine-learning-vs-deep-learning
- Abstract thinking is the ability to think about objects, principles, and ideas that are not physically present. It is related to symbolic thinking, which uses the substitution of a symbol for an object or idea.
https://www.goodtherapy.org/blog/psychpedia/abstract-thinking
- Abstract thinking is a level of thinking about things that is removed from the facts of the “here and now”, and from specific examples of the things or concepts being thought about. Abstract thinkers are able to reflect on events and ideas, and on attributes and relationships separate from the objects that have those attributes or share those relationships. Thus, for example, a concrete thinker can think about this particular dog; a more abstract thinker can think about dogs in general. A concrete thinker can think about this dog on this rug; a more abstract thinker can think about spatial relations, like “on”. A concrete thinker can see that this ball is big; a more abstract thinker can think about size in general. A concrete thinker can count three cookies; a more abstract thinker can think about numbers. A concrete thinker can recognize that John likes Betty; a more abstract thinker can reflect on emotions, like affection.
http://www.projectlearnet.org/tutorials/concrete_vs_abstract_thinking.html
- Artificial Intelligence is the broader concept of machines being able to carry out tasks in a way that we would consider “smart”.
Machine Learning is a current application of AI based around the idea
that we should
really just be able to give machines access to data and let them learn for themselves.
Artificial Intelligence – devices designed to act intelligently – are often classified into one of two fundamental groups
– applied or general. Applied AI is far more common
– systems designed
to intelligently trade stocks and shares, or maneuver an autonomous vehicle would fall into this category.
Generalized AIs
– systems or devices which can, in theory, handle any task
– are less common, but this is where
some of the most exciting advancements are happening today. It is also the area that has led to the development of Machine Learning. Often referred to as a subset of AI
Neural Networks
The development of neural networks has been key to teaching computers to think and understand the world in the way we do while
retaining the innate advantages they hold over us such as speed, accuracy, and lack of bias.
A Neural Network is a computer system designed to work by classifying information in the same way a human brain does.
It can be taught to recognize, for example, images, and classify them according to elements they contain.
Essentially it works on a system of probability
– based on data fed to it, it
is able to make statements, decisions or predictions with
a degree of certainty. The addition of a feedback loop enables “learning”
– by sensing or being told whether its decisions are right or wrong, it
modifies the approach it takes
in the future.
These are all possibilities offered by systems based around ML and neural networks
another field of AI
– Natural Language Processing (NLP)
– has become a source of hugely exciting innovation in recent years, and one which is heavily reliant on ML.
https://www.forbes.com/sites/civicnation/2018/09/10/get-out-of-your-comfort-zone-and-start-with-votetogether/#55b9cbcb5a7a
- Over the past few years, AI has exploded, and especially since 2015. Much of that has to do with the wide availability of GPUs that make parallel processing ever faster, cheaper, and more powerful. It also has to do with the simultaneous one-two punch of practically infinite storage and a flood of data of every stripe (that whole Big Data movement) – images, text, transactions, mapping data
Artificial Intelligence — Human Intelligence Exhibited by Machines
the concept we think of as “General AI” — fabulous machines that have all our senses (maybe even more), all our reason, and think just like we do.
the concept of “Narrow AI.” Technologies
that are able to perform specific tasks
as well as, or better than, we humans can. Examples of narrow AI are things such as image classification on a service like Pinterest and face recognition on Facebook
Those are examples of Narrow AI in practice. These technologies exhibit
some facets of human intelligence. But how? Where does that intelligence come from? That gets us to the next circle, Machine Learning.
Machine Learning — An Approach to Achieve Artificial Intelligence
Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world
So rather than hand-coding software routines with a specific set of instructions to accomplish a particular task, the machine is “trained” using large amounts of data and algorithms that give it the ability to learn how to perform the task.
Deep Learning — A Technique for Implementing Machine Learning
Another algorithmic approach from the early machine-learning crowd, Artificial Neural Networks, came and mostly went over the decades. Neural Networks
are inspired by our understanding of the biology of our brains
– all those interconnections between the neurons. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, these artificial neural networks have discrete layers, connections, and directions of data propagation.
how correct or incorrect it is relative to the task being performed. The final output
is then determined by the total of those weightings. So think of our stop sign example. Attributes of a stop sign image
are chopped up and “examined” by the neurons — its
octogonal shape, its fire-engine red color, its distinctive letters, its traffic-sign size, and its motion or lack thereof. The neural network’s task is to conclude whether this is a stop sign or not. It comes up with a “probability vector,” really a highly educated guess, based on the weighting. In our example the system might be 86% confident the image is a stop sign, 7% confident it’s a speed limit sign, and 5% it’s a kite stuck in a tree, and so on — and the network architecture then tells the neural network whether it is right or not.
If we go back again to our stop sign example, chances are
very good that as the network is getting tuned or “trained” it’s coming up with wrong answers — a lot. What it needs is training. It needs to see hundreds of thousands,
even millions of images until the weightings of the neuron inputs are tuned so precisely that it gets the answer right practically every time
Ng’s breakthrough was to take these neural networks, and
essentially make them huge, increase the layers and the neurons, and then run massive amounts of data through the system to train it. Google’s
AlphaGo learned the
game, and trained for its Go match — it tuned its neural network — by playing against itself over and over and over.
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
- Machine learning is a field of computer science that uses statistical techniques to give computer systems the ability to "learn" (e.g., progressively improve performance on a specific task) with data, without being explicitly programmed
https://en.wikipedia.org/wiki/Machine_learning
- Awesome Interpretable Machine Learning
model interpretability (introspection, simplification, visualization, explanation).
Interpretable models
Simple decision trees
Rules
(Regularized) linear regression
k-NN
https://github.com/lopusz/awesome-interpretable-machine-learning
- Techniques for Interpretable Machine Learning
Interpretable machine learning tackles the important problem that humans cannot understand the behaviors of complex machine learning models and how these classifiers arrive at a particular decision
https://arxiv.org/abs/1808.00033
- Torch is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first.
It is easy to use and efficient, thanks to an easy and fast scripting language,
LuaJIT, and an underlying C/CUDA implementation.
Why Torch?
The goal of Torch is to have maximum flexibility and speed in building your scientific algorithms while making the process
extremely simple.
At the heart of Torch are the popular neural network and optimization libraries
which are simple to
use, while having maximum flexibility in implementing complex neural network topologies. You can build arbitrary graphs of neural
networks, and parallelize them over
CPUs and GPUs
in an efficient manner
http://torch.ch/
- An open source machine learning framework for everyone
TensorFlow™ is an open source software library for high performance numerical computation. Its flexible architecture allows easy deployment of computation across a variety of platforms (
CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices
https://www.tensorflow.org/
- Shogun is and open-source machine learning library that offers a wide range of efficient and unified machine learning methods.
http://shogun-toolbox.org/
- Apache SystemML provides an optimal workplace for machine learning using big data. It can be run on top of Apache Spark, where it automatically scales your data, line by line, determining whether your code should be run on the driver or an Apache Spark cluster. Future SystemML developments include additional deep learning with GPU capabilities such as importing and running neural network architectures and pre-trained models for training
https://systemml.apache.org
- H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Flow notebook/web interface, and works seamlessly with big data technologies like Hadoop and Spark.
https://github.com/h2oai/h2o-3
H2O makes
Hadoop do math! H2O scales statistics, machine learning and math over BigData. H2O is extensible and users can build blocks using simple math
legos in the core. H2O keeps familiar interfaces like R, Excel & JSON so that BigData enthusiasts & experts can explore,
munge, model and score datasets using a range of simple to advanced algorithms
https://github.com/h2oai/h2o-2
- Machine Learning in Python
Simple and efficient tools for data mining and data analysis
Built on
NumPy, SciPy, and
matplotlib
http://scikit-learn.org/stable/
- Pylearn2 is a machine learning library. Most of its functionality is built on top of Theano.
This means you can write Pylearn2 plugins (new models, algorithms, etc) using mathematical expressions, and Theano will optimize and stabilize those expressions for you, and compile them to a
backend of your choice (CPU or GPU).
http://deeplearning.net/software/pylearn2/
- Open source machine learning and data visualization
https://orange.biolab.si/
- PyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.
PyBrain is short for Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network Library
http://pybrain.org/
- Fuel is a data pipeline framework which provides your machine learning models with the data they need. It is planned to be used by both the Blocks and Pylearn2 neural network libraries.
https://fuel.readthedocs.io/en/latest/
- GoLearn is a 'batteries included' machine learning library for Go. Simplicity, paired with customisability, is the goal
https://github.com/sjwhitworth/golearn
- MLlib is Apache Spark's scalable machine learning library.
You can run Spark using its standalone cluster mode, on EC2, on
Hadoop YARN, on
Mesos, or on
Kubernetes. Access data in HDFS, Apache Cassandra, Apache
HBase, Apache Hive, and hundreds of other data sources.
https://spark.apache.org/mllib/
- The Accord.NET project provides machine learning, statistics, artificial intelligence, computer vision and image processing methods to .NET. It can be used on Microsoft Windows, Xamarin, Unity3D, Windows Store applications, Linux or mobile.
https://github.com/accord-net/framework/
- Caret Package is a comprehensive framework for building machine learning models in R.
https://www.machinelearningplus.com/machine-learning/caret-package/
https://github.com/mlr-org/mlr/
- Automated machine learning (AutoML) is the process of automating the end-to-end process of applying machine learning to real-world problems. In a typical machine learning application, practitioners must apply the appropriate data pre-processing, feature engineering, feature extraction, and feature selection methods that make the dataset amenable for machine learning. Following those preprocessing steps, practitioners must then perform algorithm selection and hyperparameter optimization to maximize the predictive performance of their final machine learning model. As many of these steps are often beyond the abilities of non-experts, AutoML was proposed as an artificial intelligence-based solution to the ever-growing challenge of applying machine learning.
- Python is a general-purpose high-level programming language that is being increasingly used in data science and in designing machine learning algorithms.
libraries like
numpy,
scipy, pandas,
matplotlib cover all important concepts such as exploratory data analysis, data
preprocessing, feature extraction, data visualization, and clustering, classification, regression and model performance evaluation.
projects that teach you the techniques and functionalities such as
news topic classification, spam email detection, online ad click-through prediction, stock prices forecast and other several important machine learning algorithms.
https://www.tutorialspoint.com/machine_learning_with_python/index.htm
- Python and its libraries like NumPy, SciPy, Scikit-Learn, Matplotlib are used in data science and data analysis.
extensively used for creating scalable machine learning algorithms.
Python implements popular machine learning techniques such as Classification, Regression, Recommendation, and Clustering.
includes several implementations achieved through algorithms such as linear regression, logistic regression, Naïve Bayes,
k-means,
K nearest neighbor, and Random Forest.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_introduction.htm
- Python in Machine Learning
Python has libraries that enable developers to use optimized algorithms. It implements popular machine learning techniques such as
recommendation, classification, and clustering
learning implies recognizing and understanding the input data and making informed decisions based on the supplied data.
Applications of Machine Learning Algorithms
Vision processing
Language processing
Forecasting things like stock market trends, weather
Pattern recognition
Games
Data mining
Expert systems
Robotics
The best way to get
started using Python for machine learning is to work through a project end-to-end and cover the key steps
like loading data, summarizing data,
evaluating algorithms and making
some predictions. This gives you a replicable method that can
be used dataset after dataset.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_concepts.htm
numpy − is used for its N-dimensional array objects
pandas − is a data analysis library that includes
dataframes
matplotlib − is 2D plotting library for creating graphs and plots
scikit-learn − the algorithms used for data analysis and data mining tasks
seaborn − a data visualization library based on
matplotlib
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_environment_setup.htm
Download and install Python separately from
python.org
For Linux OS, check if Python
is already installed
If Python 2.7 or later
is not installed, install Python
$
sudo apt-get install python3
download and install necessary libraries like
numpy,
matplotlib etc. individually using installers like pip
$pip install pandas
Method 2
install Anaconda distribution
Python implementation for Linux, Windows and OSX, and comprises various machine learning packages like
numpy,
scikit-learn, and
matplotlib
includes
Jupyter Notebook, an interactive Python environment.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_environment_setup.htm
- The main purpose of machine learning is to explore and construct algorithms that can learn from the previous data and make predictions on new input data.
The input to a learning algorithm is training data, representing experience, and the output is any expertise, which usually takes the form of another algorithm that can perform a task
.The input data to a machine learning system can be numerical, textual, audio, visual, or multimedia. The corresponding output data of the system can be a floating-point number, for instance, the velocity of a rocket, an integer representing a category or a class, for example, a pigeon or a sunflower from image recognition.
Concepts of Learning
Learning is the process of converting experience into expertise or knowledge
four categories of machine learning algorithms as shown below −
Supervised learning algorithm
Unsupervised learning algorithm
Semi-supervised learning algorithm
Reinforcement learning algorithm
the most commonly used ones are supervised and unsupervised learning.
Supervised Learning
Supervised learning is commonly used in
real world applications, such as face and speech recognition, products or movie recommendations, and sales forecasting. Supervised learning can
be further classified into two types - Regression and Classification.
Regression trains on and predicts a continuous-valued response, for example predicting real estate prices.
Classification attempts to find the
appropriate class label, such as analyzing positive/negative sentiment, male and female persons, benign and malignant tumors, secure and unsecure loans
etc.
Classification attempts to find the
appropriate class label, such as analyzing positive/negative sentiment, male and female persons, benign and malignant tumors, secure and unsecure loans
etc.
In supervised learning, learning data comes with description, labels, targets or desired outputs and the
objective is to find a general rule that maps inputs to outputs.
This kind of learning data is called labeled data.
The learned rule is then used to label new data with unknown outputs
Supervised learning involves building a machine learning model that
is based on labeled samples. For example, if we build a system to estimate the price of a plot of land or a house based on various features, such as size, location, and so on, we first need to create a database and label it. We need to teach the algorithm what features correspond to what prices. Based on this data, the algorithm will learn how to calculate the price of real estate using the values of the input features.
There are many supervised learning algorithms such as Logistic Regression, Neural networks, Support Vector Machines (SVMs), and Naive Bayes classifiers
Common examples of supervised learning include classifying e-mails into spam and not-spam categories, labeling webpages based on their content, and voice recognition.
Unsupervised Learning
Unsupervised learning is used to detect anomalies, outliers, such as fraud or defective equipment, or
to group customers with similar behaviors for a sales campaign.
It is the opposite of supervised learning. There is no labeled data here
it is up to the coder or to the algorithm to find the structure of the underlying data, to discover hidden patterns, or to determine how to describe the data.
This kind of learning data is called unlabeled data.
Suppose that we have
a number of data points, and we want to classify them into several groups. We may not exactly know what the criteria of classification would be. So, an unsupervised learning algorithm tries to classify the
given dataset into a certain number of groups
in an optimum way.
They are most commonly used for clustering similar input into logical groups. Unsupervised learning algorithms include
Kmeans, Random Forests, Hierarchical clustering and so on
Semi-supervised Learning
If some learning samples
are labeled, but
some other are not labeled, then it is semi-supervised learning. It
makes use of a large amount of unlabeled data for training and a small amount of labeled data for testing.
Semi-supervised learning is applied in cases where it is expensive to
acquire a fully labeled dataset while more practical to label a small subset. For example, it often requires skilled experts to label certain remote sensing images, and lots of field experiments to locate oil at a particular location, while
acquiring unlabeled data is relatively easy.
Reinforcement Learning
Here learning data gives feedback so that the system adjusts to dynamic conditions
in order to achieve a certain
objective.
The
best known instances include self-driving cars and chess master algorithm
AlphaGo
As a field of science, machine learning shares common concepts with other disciplines such as statistics, information theory, game theory, and optimization.
As a subfield of information technology, its
objective is to program machines so
that they will learn.
However, it is to
be seen that, the purpose of machine learning is not building an automated duplication of intelligent behavior, but using the power of computers to complement and supplement human intelligence. For example, machine learning programs can scan and process huge databases detecting patterns
that are beyond
the scope of human perception.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_types_of_learning.htm
- We need to preprocess the raw data before it is fed into various machine learning algorithms.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_data_preprocessing_analysis_visualization.htm
- Memorizing the training set is called over-fitting.
Regularization may be applied to many models to reduce over-fitting.
In addition to the training and test data, the third set of observations, called a validation or hold-out set,
is sometimes required. The validation set is used to tune variables called
hyperparameters, which control how the model
is learned.
It is common to allocate 50 percent or more of the data to the training set, 25 percent to the test set, and the
remainder to the validation set.
Inexpensive storage, increased network connectivity, the ubiquity of sensor-packed smartphones, and shifting attitudes toward privacy have contributed to the contemporary state of big data, or training sets with millions or billions of examples.
Many supervised training sets
are prepared manually, or by semi-automated processes.
Fortunately, several datasets
are bundled with
scikit-learn, allowing developers to focus on experimenting with models instead.
During development, and particularly when training data is scarce,
a practice called cross-validation can be used to train and validate an algorithm on the same data
For supervised learning problems, many performance metrics measure the number of prediction errors.
There are two fundamental causes of prediction error for a model -bias and variance.
Ideally, a model will have both low bias and variance, but efforts to decrease one will frequently increase the other. This is known as the bias-variance trade-off.
Unsupervised learning problems do not have an error signal to measure; instead, performance metrics for unsupervised learning problems measure some attributes of the structure discovered in the data
While accuracy does measure the program's performance, it does not make a distinction between malignant tumors that were classified as being benign, and benign tumors that were classified as being malignant.
In this problem, however, failing to identify malignant tumors is a more serious error than classifying benign tumors as being malignant by mistake.
When the system correctly classifies a tumor as being malignant, the prediction is called a true positive. When the system incorrectly classifies a benign tumor as being malignant, the prediction is a false positive. Similarly, a false negative is an incorrect prediction that the tumor is benign, and a true negative is a correct prediction that a tumor is benign. These four outcomes can be used to calculate several common measures of classification performance, like accuracy, precision, recall and so on.
The precision and recall measures could reveal that a classifier with impressive accuracy actually fails to detect most of the malignant tumors.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_training_test_data.htm
A credit card company receives tens of thousands of applications for new credit cards. These applications contain information about several different features like age, location, sex, annual salary, credit record etc. The task of the algorithm here is to classify the card applicants into categories like those who have a good credit record, bad credit record and those who have a mixed credit record.
In a hospital, the emergency room has more than 15 features (age, blood pressure, heart condition, severity of ailment etc.) to analyze before deciding whether a given patient has to be put in an intensive care unit as it is a costly proposition and only those patients who can survive and afford the cost are given top priority. The problem here is to classify the patients into high risk and low-risk patients based on the available features or parameters.
While classifying a given set of data, the classifier system performs the following actions −
Initially, a new data model is prepared using any of the learning algorithms.
Then the prepared data model is tested.
Later, this data model is used to examine the new data and to determine its class.
Applications of classification include predicting whether on a day it will rain or not, or predicting if a certain company’s share price will rise or fall, or deciding if an article belongs to the sports or entertainment section.
A classification is a form of supervised learning. Mail service providers like Gmail, Yahoo and others use this technique to classify a new mail as spam or not spam.
The classification algorithm trains itself by analyzing user behavior of marking certain emails as spams. Based on that information, the classifier decides whether a new mail should go into the inbox or into the spam folder.
Applications of Classification
Detection of Credit card fraud - The Classification method is used to predict credit card frauds. Employing historical records of previous frauds, the classifier can predict which future transactions may turn into frauds.
E-mail spam - Depending on the features of previous spam emails, the classifier determines whether a newly received e-mail should be sent to the spam folder
Naive Bayes Classifier Technique
These have worked well in spam filtering and document classification.
Regression
Examples of regression problems include predicting the sales for a new product, or the salary for a job based on its description. Similar to classification, regression problems require supervised learning
Recommendation
The recommendation is a popular method that provides close recommendations based on user information such as the history of purchases, clicks, and ratings. Google and Amazon use this method to display a list of recommended items for their users, based on the information from their past actions.
A recommendation engine is a model that predicts what a user may be interested in based on his past record and behavior.
When this is applied in the context of movies, this becomes a movie-recommendation engine.
the difference between the two types is in the way the recommendations are extracted. Collaborative filtering constructs a model from the past behavior of the current user as well as ratings given by other users. This model then is used to predict what this user might be interested in.
Content-based filtering, on the other hand, uses the features of the item itself in order to recommend more items to the user. The similarity between items is the main motivation here. Collaborative filtering is often used more in such recommendation methods.
Clustering
Groups of related observations are called clusters. A common unsupervised learning task is to find clusters within the training data.
Applications of Clustering
Clustering finds applications in many fields such market research, pattern recognition, data analysis, and image processing
Helps marketers to discover distinct groups in their customer basis and characterize their customer groups based on purchasing patterns.
In biology, it can be used to derive plant and animal taxonomies, categorize genes with similar functionality and gain insight into structures inherent in populations.
Helps in the identification of areas of similar land use in an earth observation database.
Helps in classifying documents on the web for information discovery.
Used in outlier detection applications such as detection of credit card fraud.
For example, given a collection of movie reviews, a clustering algorithm might discover sets of positive and negative reviews.
A common application of clustering is discovering segments of customers within a market for a product.
Clustering is also used by Internet radio services; for example, given a collection of songs, a clustering algorithm might be able to group the songs according to their genres.
Clustering is a form of unsupervised learning. Search engines such as Google, Bing and Yahoo! use clustering techniques to group data with similar characteristics. Newsgroups use clustering techniques to group various articles based on related topics.
Types of Clustering
There are two types of clustering - flat clustering and hierarchical clustering.
In general, we select flat clustering when efficiency is important and hierarchical clustering when one of the potential problems of flat clustering is an issue.
Clustering Algorithms
You need clustering algorithms to cluster a given data. Two algorithms are frequently used - Canopy clustering and K-Means clustering.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_techniques.htm
- Machine learning algorithms can be broadly classified into two types - Supervised and Unsupervised.
Supervised Learning
This algorithm consists of a target or outcome or dependent variable which is predicted from a given set of predictor or independent variables. Using these set of variables, we generate a function that maps input variables to desired output variables. The training process continues until the model achieves the desired level of accuracy on the training data.
Unsupervised Learning
In this algorithm, there is no target or outcome or dependent variable to predict or estimate. It is used for clustering a given data set into different groups, which is widely used for segmenting customers into different groups for specific intervention.
Reinforcement Learning
Using this algorithm, the machine is trained to make specific decisions. Here, the algorithm trains itself continually by using trial and error methods and feedback methods. This machine learns from past experiences and tries to capture the best possible knowledge to make accurate business decisions
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_algorithms.htm
- Automated Video Surveillance
Video surveillance systems nowadays are powered by AI and machine learning is the technology behind this that makes it possible to detect and prevent crimes before they occur. They track odd and suspicious behavior of people and sends alerts to human attendants, who can ultimately help accidents and crimes.
Detection of Online frauds
Machine learning is used to track monetary frauds online. For example - Paypal is using ML to prevent money laundering. The company is using a set of tools that helps them compare millions of transactions and make a distinction between legal or illegal transactions taking place between the buyers and sellers.
Email Spam and Malware Filtering
Machine learning is being extensively used in spam detection and malware filtering and the databases of such spams and malware keep on getting updated so these are handled efficiently.
Social Media
Facebook continuously monitors the friends that you connect with, your interests, workplace, or a group that you share with someone etc. Based on continuous learning, a list of Facebook users is given as friend suggestions.
https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_applications.htm
- Automating the end-to-end process of applying machine learning offers the advantages of producing simpler solutions, faster creation of those solutions, and models that often outperform models that were designed by hand.
https://en.wikipedia.org/wiki/Automated_machine_learning
Automated Machine Learning provides methods and processes to make Machine Learning available for non-Machine Learning experts, to improve the efficiency of Machine Learning and to accelerate research on Machine Learning.
Machine learning (ML) has achieved considerable successes in recent years and an ever-growing number of disciplines rely on it. However, this success crucially relies on human-machine learning experts to perform the following tasks:
Preprocess and clean the data.
Select and construct appropriate features.
Select an appropriate model family.
Optimize model hyperparameters.
Postprocess machine learning models.
Critically analyze the results obtained.
As the complexity of these tasks is often beyond non-ML-experts, the rapid growth of machine learning applications has created a demand for off-the-shelf machine learning methods that can be used easily and without expert knowledge. We call the resulting research area that targets progressive automation of machine learning AutoML.
https://www.automl.org/
- Auto-Keras is an open source software library for automated machine learning (AutoML). It is developed by DATA Lab at Texas A&M University and community contributors. The ultimate goal of AutoML is to provide easily accessible deep learning tools to domain experts with limited data science or machine learning background. Auto-Keras provides functions to automatically search for architecture and hyperparameters of deep learning models.
https://autokeras.com/
Train high-quality custom machine learning models with minimum effort and machine learning expertise.
Try AutoML Translation, Natural Language, and Vision, now in beta.
https://cloud.google.com/automl/
The term neural network was traditionally used to refer to a network or circuit of biological neurons.
The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes
http://en.wikipedia.org/wiki/Neural_network
- Artificial neural network
An artificial neural network is an interconnected group of nodes, akin to the vast network of neurons in a brain.
Artificial neural networks (ANN) or connectionist systems are computing systems vaguely inspired by the biological neural networks that constitute animal brains
Such systems "learn" to perform tasks by considering examples, generally without being programmed with any task-specific rules. For example, an image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as "cat" or "no cat" and using the results to identify cats in other images. They do this without any prior knowledge about cats, e.g., that they have fur, tails, whiskers and cat-like faces. Instead, they automatically generate identifying characteristics from the learning material that they process.
https://en.wikipedia.org/wiki/Artificial_neural_network
- Deep learning is a class of machine learning algorithms
Deep learning (also known as deep structured learning or hierarchical learning) is part of a broader family of machine learning methods based on learning data representations, as opposed to task-specific algorithms. Learning can be supervised, semi-supervised or unsupervised
Cyberthreat
As deep learning moves from the lab into the world, research and experience show that artificial neural networks are vulnerable to hacks and deception. By identifying patterns that these systems use to function, attackers can modify inputs to ANNs in such a way that the ANN finds a match that human observers would not recognize. For example, an attacker can make subtle changes to an image such that the ANN finds a match even though the image looks to a human nothing like the search target. Such a manipulation is termed an “adversarial attack.” In 2016 researchers used one ANN to doctor images in trial and error fashion, identify another's focal points and thereby generate images that deceived it. The modified images looked no different to human eyes. Another group showed that printouts of doctored images then photographed successfully tricked an image classification system
One defense is reverse image search, in which a possible fake image is submitted to a site such as TinEye that can then find other instances of it. A refinement is to search using only parts of the image, to identify images from which that piece may have been taken
ANNs can, however, be further trained to detect attempts at deception, potentially leading attackers and defenders into an arms race similar to the kind that already defines the malware defense industry. ANNs have been trained to defeat ANN-based anti-malware software by repeatedly attacking a defense with malware that was continually altered by a genetic algorithm until it tricked the anti-malware while retaining its ability to damage the target
Another group demonstrated that certain sounds could make the Google Now voice command system open a particular web address that would download malware
In “data poisoning”, false data is continually smuggled into a machine learning system’s training set to prevent it from achieving mastery
https://en.wikipedia.org/wiki/Deep_learning
- Deep learning generally involves training artificial neural networks on lots of data, like photos, and then getting them to make inferences about new data.
“PyTorch is great for research, experimentation and trying out exotic neural networks, while Caffe2 is headed towards supporting more industrial-strength applications with a heavy focus on mobile,”
In 2015 Google made a splash when it open-sourced its own framework, TensorFlow.
https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
- A Docker image containing almost all popular deep learning frameworks: theano, tensorflow, sonnet, pytorch, keras, lasagne, mxnet, cntk, chainer, caffe, torch.
https://hub.docker.com/r/ufoym/deepo
- Unlock deeper learning with the new Microsoft Cognitive Toolkit
The Microsoft Cognitive Toolkit—previously known as CNTK—empowers you to harness the intelligence within massive datasets through deep learning by providing uncompromised scaling, speed, and accuracy with commercial-grade quality and compatibility with the programming languages and algorithms you already use.
https://www.microsoft.com/en-us/cognitive-toolkit/
Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit
The Microsoft Cognitive Toolkit (https://cntk.ai) is a unified deep learning toolkit that describes neural networks as a series of computational steps via a directed graph. In this directed graph, leaf nodes represent input values or network parameters, while other nodes represent matrix operations upon their inputs. CNTK allows users to easily realize and combine popular model types such as feed-forward DNNs, convolutional nets (CNNs), and recurrent networks (RNNs/LSTMs). It implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers
https://github.com/Microsoft/CNTK
- The Microsoft Cognitive Toolkit
The Microsoft Cognitive Toolkit (CNTK) is an open-source toolkit for commercial-grade distributed deep learning. It describes neural networks as a series of computational steps via a directed graph. CNTK allows the user to easily realize and combine popular model types such as feed-forward DNNs, convolutional neural networks (CNNs) and recurrent neural networks (RNNs/LSTMs). CNTK implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
https://docs.microsoft.com/en-us/cognitive-toolkit/
- A New Lightweight, Modular, and Scalable Deep Learning Framework
Caffe2 aims to provide an easy and straightforward way for you to experiment with deep learning and leverage community contributions of new models and algorithms. You can bring your creations to scale using the power of GPUs in the cloud or to the masses on mobile with Caffe2's cross-platform libraries.
https://caffe2.ai/
- Caffe is a deep learning framework made with expression, speed, and modularity in mind
http://caffe.berkeleyvision.org/
- CaffeOnSpark brings deep learning to Hadoop and Spark clusters. By combining salient features from deep learning framework Caffe and big-data frameworks Apache Spark and Apache Hadoop, CaffeOnSpark enables distributed deep learning on a cluster of GPU and CPU servers.
https://github.com/yahoo/CaffeOnSpark
- An open source deep learning platform that provides a seamless path from research prototyping to production deployment.
https://pytorch.org/
- Bridge the gap between algorithms and implementations of deep learning
A Powerful, Flexible, and Intuitive Framework for Neural Networks
https://chainer.org/
- Keras: The Python Deep Learning library
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.
https://keras.io/
- neon is Intel Nervana ‘s reference deep learning framework committed to best performance on all hardware.
http://neon.nervanasys.com/index.html/
- Based on Python* and optimized for Intel® architecture, this deep learning framework is designed for ease of use and extensibility on modern deep neural networks, such as AlexNet, Visual Geometry Group (VGG), and GoogLeNet.
https://software.intel.com/en-us/ai-academy/frameworks/neon
- ConvNetJS is a Javascript implementation of Neural networks, together with nice browser-based demos. It currently supports:
Common Neural Network modules (fully connected layers, non-linearities)
Classification (SVM/Softmax) and Regression (L2) cost functions
Ability to specify and train Convolutional Networks that process images
An experimental Reinforcement Learning module, based on Deep Q Learning
https://github.com/karpathy/convnetjs
- deeplearn.js is an open source hardware-accelerated JavaScript library for machine intelligence. deeplearn.js brings performant machine learning building blocks to the web, allowing you to train neural networks in a browser or run pre-trained models in inference mode.
https://github.com/tambien/deeplearnjs
DeepDream is a computer vision program created by Google engineer Alexander Mordvintsev which uses a convolutional neural network to find and enhance patterns in images via algorithmic pareidolia, thus creating a dream-like hallucinogenic appearance in the deliberately over-processed images
https://en.wikipedia.org/wiki/DeepDream
- Create inspiring visual content in a collaboration with our AI enabled tools
https://deepdreamgenerator.com/
- This repository contains IPython Notebook with sample code, complementing Google Research blog post about Neural Network art.
https://github.com/google/deepdream
- the basics of Python and develop applications involving deep learning techniques such as convolutional neural nets, recurrent nets, back propagation, etc
Prerequisites
Before you proceed with this tutorial, we assume that you have prior exposure to Python, Numpy, Pandas, Scipy, Matplotib, Windows, any Linux distribution, prior basic knowledge of Linear Algebra, Calculus, Statistics and basic machine learning techniques.
https://www.tutorialspoint.com/python_deep_learning/index.htm
- Deep structured learning or hierarchical learning or deep learning, in short, is part of the family of machine learning methods which are themselves a subset of the broader field of Artificial Intelligence.
Deep learning is a class of machine learning algorithms that use several layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input.
Deep Learning Algorithms and Networks −
are based on the unsupervised learning of multiple levels of features or representations of the data. Higher-level features are derived from lower level features to form a hierarchical representation.
use some form of gradient descent for training
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_introduction.htm
- Artificial Intelligence (AI) is any code, algorithm or technique that enables a computer to mimic human cognitive behaviour or intelligence.
Machine Learning (ML) is a subset of AI that uses statistical methods to enable machines to learn and improve with experience
Deep Learning(DL) is a subset of Machine Learning, which makes the computation of multi-layer neural networks feasible.
Machine Learning is seen as shallow learning while Deep Learning is seen as hierarchical learning with abstraction.
Machine learning deals with a wide range of concepts. The concepts are listed below −
supervised
unsupervised
reinforcement learning
linear regression
cost functions
overfitting
under-fitting
hyper-parameter, etc.
In unsupervised learning, we make inferences from the input data that is not labeled or structured. If we have a million medical records and we have to make sense of it, find the underlying structure, outliers or detect anomalies, we use a clustering technique to divide data into broad clusters.
An algorithm classified 1 million images into 1000 categories successfully using 2 GPUs and latest technologies like Big Data.
Relating Deep Learning and Traditional Machine Learning
One of the major challenges encountered in traditional machine learning models is a process called feature extraction
Entering raw data into the algorithm rarely works, so feature extraction is a critical part of the traditional machine learning workflow.
This places a huge responsibility on the programmer, and the algorithm's efficiency relies heavily on how inventive the programmer is. For complex problems such as object recognition or handwriting recognition, this is a huge issue
Deep learning, with the ability to learn multiple layers of representation, is one of the few methods that has to help us with automatic feature extraction.
The lower layers can be assumed to be performing automatic feature extraction, requiring little or no guidance from the programmer.
https://www.tutorialspoint.com/python_deep_learning/python_deep_basic_machine_learning.htm
- Each column is a layer. The first layer of your data is the input layer. Then, all the layers between the input layer and the output layer are the hidden layers.
If you have one or a few hidden layers, then you have a shallow neural network. If you have many hidden layers, then you have a deep neural network.
The act of sending data straight through a neural network is called a feed forward neural network.
When we go back and begin adjusting weights to minimize loss/cost, this is called back propagation.
This is an optimization problem. With the neural network, in real practice, we have to deal with hundreds of thousands of variables, or millions, or more.
That is why Neural Networks were mostly left on the shelf for over half a century. It was only very recently that we even had the power and architecture in our machines to even consider doing these operations, and the properly sized datasets to match.
For simple classification tasks, the neural network is relatively close in performance to other simple algorithms like K Nearest Neighbors. The real utility of neural networks is realized when we have much larger data, and much more complex questions, both of which outperform other machine learning models
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_artificial_neural_networks.htm
- A deep neural network (DNN) is an ANN with multiple hidden layers between the input and output layers. Similar to shallow ANNs, DNNs can model complex non-linear relationships.
The main purpose of a neural network is to receive a set of inputs, perform progressively complex calculations on them, and give output to solve real world problems like classification.
Neural networks are widely used in supervised learning and reinforcement learning problems. These networks are based on a set of layers connected to each other.
We mostly use the gradient descent method for optimizing the network and minimizing the loss function.
Training the data sets forms an important part of Deep Learning models. In addition, Backpropagation is the main algorithm in training DL models.
DL deals with training large neural networks with complex input output transformations.
One example of DL is the mapping of a photo to the name of the person(s) in the photo as they do on social networks and describing a picture with a phrase is another recent application of DL.
The best use case of deep learning is the supervised learning problem
We can train deep a Convolutional Neural Network with Keras to classify images of handwritten digits from this dataset.
The firing or activation of a neural net classifier produces a score. For example, to classify patients as sick and healthy, we consider parameters such as height, weight and body temperature, blood pressure etc.
A high score means a patient is sick and a low score means he is healthy.
Each node in output and hidden layers has its own classifiers. The input layer takes inputs and passes on its scores to the next hidden layer for further activation and this goes on until the output is reached.
This progress from input to output from left to right in the forward direction is called forward propagation.
Credit assignment path (CAP) in a neural network is the series of transformations starting from the input to the output. CAPs elaborate probable causal connections between the input and the output.
For recurrent neural networks, where a signal may propagate through a layer several times, the CAP depth can be potentially limitless.
CAP depth for a given feed forward neural network or the CAP depth is the number of hidden layers plus one as the output layer is included.
Deep Nets and Shallow Nets
There is no clear threshold of depth that divides shallow learning from deep learning; but it is mostly agreed that for deep learning which has multiple non-linear layers, CAP must be greater than two.
A basic node in a neural net is a perception mimicking a neuron in a biological neural network. Then we have multi-layered Perception or MLP. Each set of inputs is modified by a set of weights and biases; each edge has a unique weight and each node has a unique bias.
The prediction accuracy of a neural net depends on its weights and biases.
The process of improving the accuracy of a neural network is called training.
The cost function or the loss function is the difference between the generated output and the actual output.
The point of training is to make the cost of training as small as possible across millions of training examples. To do this, the network tweaks the weights and biases until the prediction matches the correct output.
When the pattern gets complex and you want your computer to recognize them, you have to go for neural networks. In such complex pattern scenarios, neural network outperformsall other competing algorithms.
If there is the problem of recognition of simple patterns, a support vector machine (svm) or a logistic regression classifier can do the job well, but as the complexity of pattern increases, there is no way but to go for deep neural networks.
Therefore, for complex patterns like a human face, shallow neural networks fail and have no alternative but to go for deep neural networks with more layers
recent high-performance GPUs have been able to train such deep nets under a week; while fast cpus could have taken weeks or perhaps months to do the same.
Choosing a Deep Net
How to choose a deep net? We have to decide if we are building a classifier or if we are trying to find patterns in the data and if we are going to use unsupervised learning.
To extract patterns from a set of unlabelled data, we use a Restricted Boltzman machine or an Auto encoder.
Consider the following points while choosing a deep net −
For text processing, sentiment analysis, parsing, and name entity recognition, we use a recurrent net or recursive neural tensor network or RNTN;
For any language model that operates at the character level, we use the recurrent net.
For image recognition, we use deep belief network DBN or convolutional network.
For object recognition, we use an RNTN or a convolutional network.
For speech recognition, we use the recurrent net.
In general, deep belief networks and multilayer perceptrons with rectified linear units or RELU are both good choices for classification.
For time series analysis, it is always recommended to use a recurrent net.
The reason is that they are hard to train; when we try to train them with a method called back propagation, we run into a problem called vanishing or exploding gradients. When that happens, training takes a long time and accuracy takes a back-seat
When training a data set, we are constantly calculating the cost function, which is the difference between predicted output and the actual output from a set of labeled training data. The cost function is then minimized by adjusting the weights and biases values until the lowest value is obtained. The training process uses a gradient, which is the rate at which the cost will change with respect to change in weight or bias values.
Restricted Boltzman Networks or Autoencoders -RBNs
The first layer is the visible layer and the second layer is the hidden layer. Each node in the visible layer is connected to every node in the hidden layer. The network is known as restricted as no two layers within the same layer are allowed to share a connection.
An interesting aspect of RBM is that data need not be labeled. This turns out to be very important for real world data sets like photos, videos, voices, and sensor data, all of which tend to be unlabelled.
Deep Belief Networks - DBNs
Deep belief networks (DBNs) are formed by combining RBMs and introducing a clever training method.
A DBN is similar in structure to an MLP (Multi-layer perceptron), but very different when it comes to training. it is the training that enables DBNs to outperform their shallow counterparts
A DBN works globally by fine-tuning the entire input in succession as the model slowly improves like a camera lens slowly focussing a picture. A stack of RBMs outperforms a single RBM as a multi-layer perceptron MLP outperforms a single perceptron.
At this stage, the RBMs have detected inherent patterns in the data but without any names or label. To finish training of the DBN, we have to introduce labels to the patterns and fine tune the net with supervised learning
Generative Adversarial Networks - GANs
Generative adversarial networks are deep neural nets comprising two nets, pitted one against the other, thus the “adversarial” name.
In a GAN, one neural network, known as the generator, generates new data instances, while the other, the discriminator, evaluates them for authenticity
Recurrent Neural Networks - RNNs
These networks are used for applications such as language modeling or Natural Language Processing (NLP).
The basic concept underlying RNNs is to utilize sequential information. In a normal neural network, it is assumed that all inputs and outputs are independent of each other. If we want to predict the next word in a sentence we have to know which words came before it.
RNNs thus can be said to have a “memory” that captures information about what has been previously calculated
Long short-term memory networks (LSTMs) are most commonly used RNNs.
Together with convolutional Neural Networks, RNNs have been used as part of a model to generate descriptions for unlabelled image
Convolutional Deep Neural Networks - CNNs
CNNs are extensively used in computer vision; have been applied also in acoustic modeling for automatic speech recognition.
The idea behind convolutional neural networks is the idea of a “moving filter” which passes through the image. This moving filter, or convolution, applies to a certain neighborhood of nodes which for example may be pixels, where the filter applied is 0.5 x the node value −
Facebook as facial recognition software uses these nets. CNN has been the go to solution for machine vision projects.
In a nutshell, Convolutional Neural Networks (CNNs) are multi-layer neural networks. The layers are sometimes up to 17 or more and assume the input data to be images.
CNNs drastically reduce the number of parameters that need to be tuned. So, CNNs efficiently handle the high dimensionality of raw images.
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_deep_neural_networks.htm
- The inputs and outputs are represented as vectors or tensors. For example, a neural network may have the inputs where individual pixel RGB values in an image are represented as vectors. Different architectures of neural networks are formed by choosing which neurons to connect to the other neurons in the next layer.
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_fundamentals.htm
- learn how to train a neural network.
learn back propagation algorithm
a backward pass in Python Deep Learning
We have to find the optimal values of the weights of a neural network to get the desired output. To train a neural network, we use the iterative gradient descent method. We started initially with random initialization of the weights. After random initialization, we make predictions on some subset of the data with a forward-propagation process, compute the corresponding cost function C, and update each weight w by an amount proportional to dC/dw, i.e., the derivative of the cost functions w.r.t. the weight. The proportionality constant is known as the learning rate.
The gradients can be calculated efficiently using the back-propagation algorithm. The key observation of backward propagation or backward prop is that because of the chain rule of differentiation, the gradient at each neuron in the neural network can be calculated using the gradient at the neurons, it has outgoing edges to. Hence, we calculate the gradients backward, i.e., first calculate the gradients of the output layer, then the top-most hidden layer, followed by the preceding hidden layer, and so on, ending at the input layer
The back-propagation algorithm is implemented mostly using the idea of a computational graph, where each neuron is expanded to many nodes in the computational graph and performs a simple mathematical operation like addition, multiplication. The computational graph does not have any weights on the edges; all weights are assigned to the nodes, so the weights become their own nodes. The backward propagation algorithm is then run on the computational graph. Once the calculation is complete, only the gradients of the weight nodes are required for the update. The rest of the gradients can be discarded
Gradient Descent Optimization Technique
One commonly used optimization function that adjusts weights according to the error they caused is called the “gradient descent.”
Gradient is another name for slope, and slope, on an x-y graph, represents how two variables are related to each other
In this case, the slope is the ratio between the network’s error and a single weight; i.e., how does the error change as the weight is varied.
To put it more precisely, we want to find which weight produces the least error. We want to find the weight that correctly represents the signals contained in the input data, and translates them to a correct classification.
As a neural network learns, it slowly adjusts many weights so that they can map signal to meaning correctly. The ratio between network Error and each of those weights is a derivative, dE/dw that calculates the extent to which a slight change in a weight causes a slight change in the error.
Each weight is just one factor in a deep network that involves many transforms; the signal of the weight passes through activations and sums over several layers, so we use the chain rule of calculus to work back through the network activations and outputs. This leads us to the weight in question, and its relationship to overall error.
Given two variables, error and weight, are mediated by a third variable, activation, through which the weight is passed
We can calculate how a change in weight affects a change in error by first calculating how a change in activation affects a change in Error, and how a change in weight affects a change in activation.
The basic idea in deep learning is nothing more than that: adjusting a model’s weights in response to the error it produces until you cannot reduce the error anymore.
The deep net trains slowly if the gradient value is small and fast if the value is high.
The process of training the nets from the output back to the input is called back propagation or back prop
We know that forward propagation starts with the input and works forward. Back prop does the reverse/opposite calculating the gradient from right to left
Challenges in Deep Learning Algorithms
There are certain challenges for both shallow neural networks and deep neural networks, like overfitting and computation time.
DNNs are affected by overfitting because the use of added layers of abstraction which allow them to model rare dependencies in the training data.
Regularization methods such as
drop out,
early stopping,
data augmentation,
transfer learning
are applied during training to combat overfitting.
Drop out regularization randomly omits units from the hidden layers during training which helps in avoiding rare dependencies
Finding optimal parameters is not always practical due to the high cost in time and computational resources.
Dropout
Dropout is a popular regularization technique for neural networks. Deep neural networks are particularly prone to overfitting
Dropout is a technique where during each iteration of gradient descent, we drop a set of randomly selected nodes. This means that we ignore some nodes randomly as if they do not exist.
The idea behind Dropout is as follows − In a neural network without dropout regularization, neurons develop co-dependency amongst each other that leads to overfitting.
Implementation trick
Dropout is implemented in libraries such as TensorFlow and Pytorch by keeping the output of the randomly selected neurons as 0. That is, though the neuron exists, its output is overwritten as 0
Early Stopping
We train neural networks using an iterative algorithm called gradient descent.
The idea behind early stopping is intuitive; we stop training when the error starts to increase. Here, by error, we mean the error measured on validation data, which is the part of training data used for tuning hyper-parameters. In this case, the hyper-parameter is the stop criteria.
Data Augmentation
The process where we increase the quantum of data we have or augment it by using existing data and applying some transformations on it. The exact transformations used to depend on the task we intend to achieve. Moreover, the transformations that help the neural net depend on its architecture
Transfer Learning
The process of taking a pre-trained model and “fine-tuning” the model with our own dataset is called transfer learning.
The concept behind this is that the pre-trained model will act as a feature extractor, and only the last layer will be trained on the current task.
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_training_a_neural_network.htm
- Deep learning is the next big leap after machine learning with a more advanced implementation. Currently, it is heading towards becoming an industry standard bringing a strong promise of being a game changer when dealing with raw unstructured data.
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_applications.htm
Theano is python library which provides a set of functions for building deep nets that train quickly on our machine.
Technically speaking, both neural nets and input data can be represented as matrices and all standard net operations can be redefined as matrix operations. This is important since computers can carry out matrix operations very quickly.
We can process multiple matrix values in parallel and if we build a neural net with this underlying structure, we can use a single machine with a GPU to train enormous nets in a reasonable time window.
TensorFlow and Keras can be used with Theano as backend.
Deep Learning with TensorFlow
Googles TensorFlow is a python library.
Much like the Theano library, TensorFlow is based on computational graphs where a node represents persistent data or math operation and edges represent the flow of data between nodes, which is a multidimensional array or tensor; hence the name TensorFlow
Even though TensorFlow was designed for neural networks, it works well for other nets where computation can be modeled as data flow graphs
TensorFlow also uses several features from Theano such as common and sub-expression elimination, auto differentiation, shared and symbolic variables.
Different types of deep nets can be built using TensorFlow like convolutional nets, Autoencoders, RNTN, RNN, RBM, DBM/MLP and so on.
However, there is no support for hyperparameter configuration in TensorFlow.For this functionality, we can use Keras.
Deep Learning with Keras
Keras is a powerful easy-to-use Python library for developing and evaluating deep learning models.
It wraps the efficient numerical computation libraries Theano and TensorFlow and allows us to define and train neural network models in a few short lines of code.
It is a high-level neural network API, helping to make wide use of deep learning and artificial intelligence. It runs on top of a number of lower-level libraries including TensorFlow, Theano, and so on. Keras code is portable; we can implement a neural network in Keras using Theano or TensorFlow as a backend without any changes in code.
https://www.tutorialspoint.com/python_deep_learning/python_deep_learning_libraries_and_frameworks.htm
- Deep learning, the branch of AI that uses artificial neural networks to build prediction and pattern matching models from large datasets relevant to a particular application
developing deep learning software isn’t easy since the models are customized for a particular use. Indeed, developing models is more like making a custom-fitted suit, not off-the-rack clothing in standard sizes.
Deep learning encompasses a large category of software, not a general-purpose solution, and describes a broad range of algorithms and network types, each better suited to particular types of problems and data than others.
The diversity of models, each requiring specialized AI development knowledge and domain expertise, limits the use of deep learning to organizations with the R&D budget and time horizon needed to produce software tailored to a particular problem.
In the meantime, a promising compromise would be the ability to automate model selection and tuning based on the problem and available data, and then select the best options from a portfolio of deep learning software each designed for different applications.
For example, convolutional neural networks (CNNs) based on the synaptic connections between neurons in the brain, are extremely effective at image recognition, exceeding 90% accuracy at identifying objects in a standard image dataset used by most developers.
However, the same type of model would be ineffective at learning to make the decisions required to play a strategy game like chess or go. Instead, models based on reinforcement learning that reward correct or good choices and penalizes bad choices are better at completing complicated tasks.
The most advanced applications of AI, such as robots used for multi-purpose manufacturing or logistics tasks will require several deep learning applications, such as a CNN for vision and object identification, recurrent neural networks (RNNs) for speech recognition and reinforcement learning for task completion.
Enam also notes that debugging and optimizing ML is “exponentially harder” than conventional software both in the difficulty of figuring out what went wrong and the time required to train and execute the models.Here, we would add that the black-box nature of deep learning networks, which makes them impossible to reverse engineer to understand how they arrived at a decision, only compounds the difficulty.
The emerging field of AutoML, which broadly consists of algorithm selection, hyperparameter tuning, iterative modeling, and model assessment, builds a meta-layer of abstraction on top of ML that can be used to automate model development and optimization.
https://diginomica.com/2017/08/09/automated-deep-learning-finding-right-model/
- keras-pandas allows users to rapidly build and iterate on deep learning models.
https://pypi.org/project/keras-pandas/
- Keras-Pandas: Automated Deep Learning
https://www.meetup.com/Metis-Seattle-Data-Science/events/253815938/
- Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search
https://github.com/arberzela/EfficientNAS
- Now there are three platforms that offer Automated Deep Learning (ADL) so simple that almost anyone can do it.
Microsoft CustomVision.AI
Late in 2017 MS introduced a series of greatly simplified DL capabilities covering the full range of image, video, text, and speech under the banner of the Microsoft Cognitive Services.
Google Cloud AutoML
Like Microsoft, the service utilizes transfer learning from Google’s own prebuilt complex CNN classifiers. They recommend at least 100 images per label for transfer learning.
OneClick.AI
OneClick.AI is an automated machine learning (AML) platform new in the market late in 2017 which includes both traditional algorithms and also deep learning algorithms.
https://www.datasciencecentral.com/profiles/blogs/automated-deep-learning-so-simple-anyone-can-do-it
- An automated deep-learning platform
http://noos-ai.com/
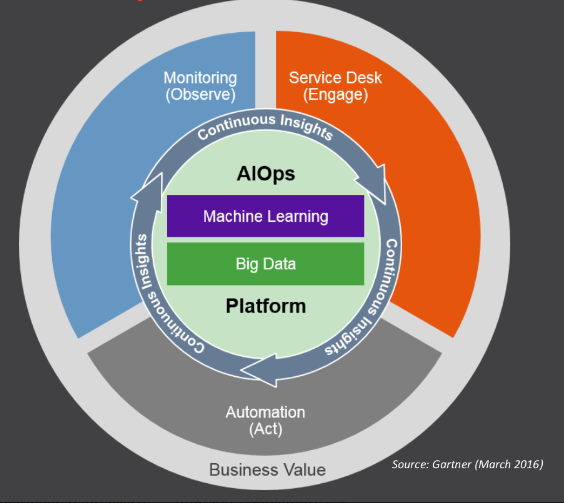
What is AIOps?
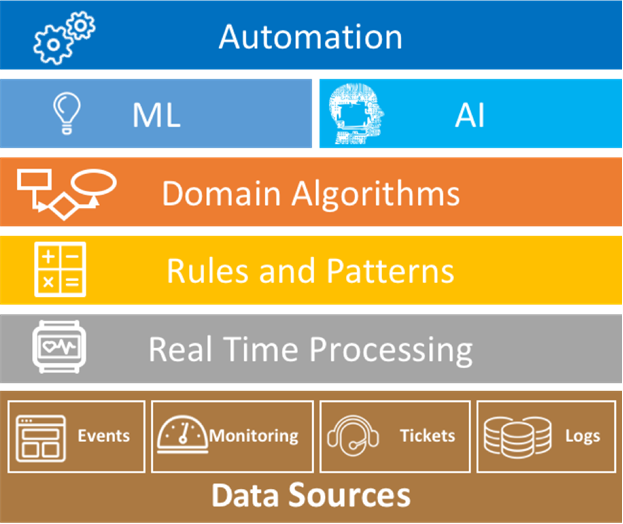
AIOps refers to multi-layered technology platforms that automate and enhance IT operations by 1) using analytics and machine learning to analyze big data collected from various IT operations tools and devices, in order to 2) automatically spot and react to issues in real time
Gartner explains how an AIOps platform works by using the diagram in figure 1. AIOps has two main components: Big Data and Machine Learning
It requires a move away from siloed IT data in order to aggregate observational data (such as that found in monitoring systems and job logs) alongside engagement data (usually found in ticket, incident, and event recording) inside a Big Data platform
AIOps then implements Analytics and Machine Learning (ML) against the combined IT data.
The desired outcome is continuous insights that can yield continuous improvements with the implementation of automation.
AIOps can be thought of as Continuous Integration and Deployment (CI/CD) for core IT functions
AIOps bridges three different IT disciplines—service management, performance management, and automation—to accomplish its goals of continuous insights and improvements.
What’s driving AIOps?
The promise of artificial Intelligence has been to do what humans do but do it better, faster and at scale
It’s becoming a misnomer to use the term “infrastructure” here, as modern IT environments include managed cloud, unmanaged cloud, third party services, SaaS integrations, mobile, and more.
https://www.bmc.com/blogs/what-is-aiops/
- What Does AIOps Mean for IT?
Gain Access to All Data
Conventional approaches, tools and solutions weren’t designed in anticipation of the volume, variety and velocity generated by today’s complex and connected IT environments. Instead, they consolidate and aggregate data and roll them up into averages, compromising data fidelity. A fundamental tenet of an AIOps platform is its ability to capture large data sets of any type, from across the environment, while maintaining data fidelity for comprehensive analysis.
Simplify Data Analysis
How do you automate the analysis of that data to help you gain insights that drive meaningful action? That’s where artificial intelligence (AI) comes in. AI—powered by machine learning (ML)—applies algorithms to large sets of data to automate insights and action. This helps IT have a seat at the table and drive data-driven business decisions.
What Problems Does AIOps Help You Solve?
The emphasis on AIOps platforms is in the ability to collect all formats of data in varying velocity and volume. It then applies automated analysis on that data to empower your IT teams to be smarter, more responsive and proactive—accelerating data-validated decisions.
By marrying machine data with machine learning for classification, correlation, prediction and forecasting, pattern discovery, anomaly detection and root-cause analysis, Splunk delivers a modern approach to AIOps and leverages it to bring intelligence to modern IT organizations
https://www.splunk.com/blog/2017/11/16/what-is-aiops-and-what-it-means-for-you.html#
- Swarm intelligence (SI) is the collective behavior of decentralized, self-organized systems, natural or artificial.The concept is employed in work on artificial intelligence.
there is no centralized control structure dictating how individual agents should behave
Examples of swarm intelligence in natural systems include ant colonies, bird flocking, animal herding, bacterial growth, fish schooling and microbial intelligence.
The application of swarm principles to robots is called swarm
robotics, while 'swarm intelligence' refers to the more general set of algorithms.
'Swarm prediction' has been used in
the context of forecasting problems.
https://en.wikipedia.org/wiki/Swarm_intelligence
- “Ninety-nine percent of AI currently being developed is about replacing and ultimately exceeding human intelligence. Ours is different. It’s about amplifying human intelligence.”
The idea is that rather than dividing groups in
the way that a poll would, UNU taps into the collective knowledge and intuition of the group to give a unified voice. The key is
compromise.
“Taking a vote or poll is a great simple way to take a decision
but it
doesn’t help a group find consensus,”
“It
actually polarizes people and highlights the differences between them. People end up getting entrenched in their views.
“Beyond individual intelligence, nature has also cultivated intelligence through swarms.
For example, bees, birds and fish act in a more intelligent way when acting together as a swarm, flock or school.
”
The life-or-death problem involves a process of
collective fact-finding undertaken by several hundred scout bees working together to find possible locations.
https://www.newsweek.com/swarm-intelligence-ai-algorithm-predicts-future-418707
- platform that combines big data and artificial intelligence (AI) functionality to replace a broad range of IT Operations processes and tasks including availability and performance monitoring, event correlation and analysis, IT service management, and automation.
By harnessing log, application, cloud, network, metric data and more, AIOps enables organizations to monitor, flag and surface possible dependencies and issues in their systems. It automates routine practices in order to increase accuracy and speed of issue recognition and streamline operations.
Imagine a world where 30 minutes before an incident even crosses the service desk, your team is alerted of the potential incident.
You need a solution that can wrangle all of your data across all silos, and uses sophisticated predictive AI and machine learning.
Training on relevant, available data is critical in making this strategy work
You need lots of historical and real-time data for context that helps understand the past, in turn, helping you predict what most likely will happen in the future.
Only then can you be proactive and prevent costly incidents from happening.
MTTI
mean time to investigate
MTTD
mean time to detect
MTBF
mean time between failures
MTTR
mean time to resolution
https://www.splunk.com/en_us/it-operations/artificial-intelligence-aiops.html
The simple answer is that AIOps stands for Artificial Intelligence for IT Operations.
It’s the next generation of IT operations analytics, or ITOA
https://fixstream.com/aiops/
- Our unsupervised anomaly detection algorithm Donut for seasonal KPIs,based on VAE, greatly outperforms state-of-art supervised and vanilla VAE anomaly detection algorithms.
PIs are time sequences, yet one of the most fundamental system monitoring indicators. A failure usually causes more or less anomalies on at least one KPI. Thus anomaly detection for KPIs are very useful in
Artificial Intelligence for IT Operations (AIOps).
For web applications, the user activities are usually seasonal, so are the KPIs, including high level KPIs like the trading volumes, and low level KPIs like the CPU consumptions.
https://netman.aiops.org/wp-content/uploads/2018/05/www2018-slide.pdf
- Data fidelity and cybersecurity
When discussing cybersecurity data, the environment where the data is created varies depending on the location and type of data. For example, consider an intrusion detection system (IDS) alert. An IDS alert can occur on the
network (on the wire) or on the actual host. In both cases, the alert is trusted by the software that processes it.
However, the actual event may not match the reported event.If, in addition to the event information, other environmental variables such as memory usage and CPU cycles are captured, the contextual information around the event can be viewed and can provide the necessary data to possibly assure the fidelity of the event data.
if the network IDS systems are saying all the connections are normal, but the traffic sessions appear to be larger than normal, or the number of connections is significantly greater than normal, then we can infer that something is not right.Presently, this does not differ much from basic anomaly detection. However, when the data is compared against the normal variance of baselined data, or when the data is compared against existing security information event management (SIEM) data and a difference is found, we can question the fidelity of our SIEM data.
consider a case where the host is involved. Perhaps the file system remains acceptably changed, but the normal processes are taking longer than normal and using additional CPU cycles. In this case, like the previous example, a perturbation has occurred in the environment.
Data fidelity in IoT environments
the environment may appear normal, but the object or alert may have changed, suggesting a potential false alarm. this is a common problem with anomaly detection systems. In this case, by having the object and environmental variables coupled together, we can potentially reduce the number of false positives. Minimally, we can gain better insights into the false positive problem without introducing false negatives
there are common areas that provide the basis of observables. For example, messaging rate baselines can be observed and established for various states, recognizing that certain stressed states are suboptimal for automated actions.
Table 1 is applicable to each of the three environments -- network, host and IoT -- as well as each of the meta-states that these inhabit at various processing times. The meta-processing states for each of the environments are start up, idle, normal processing, stressed processing, degraded processing and shutdown. Each of these meta-states has associated variables that can be accessed and examined to determine if these are controlled events, anomalous events or potential problems.
variations occur in each state of each environment, and this is why baselines are important. Baselining is sometimes thought of as the custodial work of cybersecurity, which is why many have tried to use machine learning for the task.
Conclusion
The data fidelity problem will likely continue to plague security software in part because of the human-machine trust relationship, as well as because of the fundamental assumptions made by security experts and product developers in the early days of internet security. These assumptions, much like the signature-based detection model, will continue to be invalidated until data resilience, a significant component of data fidelity moves to the forefront of the security discussion.
https://searchsecurity.techtarget.com/tip/Why-data-fidelity-is-crucial-for-enterprise-cybersecurity
- Knowledge representation and reasoning
the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can
utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language.
Knowledge representation incorporates findings from psychology
[1] about how humans solve problems and represent knowledge
in order to design formalisms that will make complex systems easier to design and build.
Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning, such as the application of rules or the relations of sets and subsets
Examples of knowledge representation formalisms include semantic nets, systems architecture, frames, rules, and ontologies.
https://en.wikipedia.org/wiki/Knowledge_representation_and_reasoning
XGBoost is an implementation of gradient boosted decision trees designed for speed and performance
XGBoost stands for
eXtreme Gradient Boosting
The implementation of the model supports the features of the
scikit-learn and R implementations, with new additions like a regularization.
Three main forms of gradient boosting are supported:
Gradient Boosting algorithm also called gradient boosting machine including the learning rate.
Stochastic Gradient Boosting with sub-sampling at the row, column and column per split levels.
Regularized Gradient Boosting with both L1 and L2 regularization
https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
Density-based spatial clustering of applications with noise (DBSCAN) is a well-known data clustering algorithm that
is commonly used in data mining and machine learning
The DBSCAN algorithm should be used to find associations and structures in data
that are hard to find manually but that can be relevant and useful to find patterns and predict trends.
https://towardsdatascience.com/how-dbscan-works-and-why-should-i-use-it-443b4a191c80
- Principal Component Analysis(PCA)
Variable Reduction Technique
PCA is a method used to reduce the number of variables in your data by extracting important one from a large pool
this method combines highly correlated variables together to form a smaller number of an artificial set of variables
which is called “principal components” that account for most variance in the data.
https://towardsdatascience.com/principal-component-analysis-intro-61f236064b38
- Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization.
Yes, it is possible to apply Weka to process big data and perform deep learning!
https://www.cs.waikato.ac.nz/ml/weka/