- Why we want to use DFS?
Data sharing of multiple users
user mobility
location transparency
location independence
backups and centralized management
The actual problem of balanced / clustered solutions often the content server where you keep all data, that can be: databases, static files, uploaded files. All this content needs to
https://www.leaseweb.com/labs/2011/11/distributed-storage-for-ha-clusters/
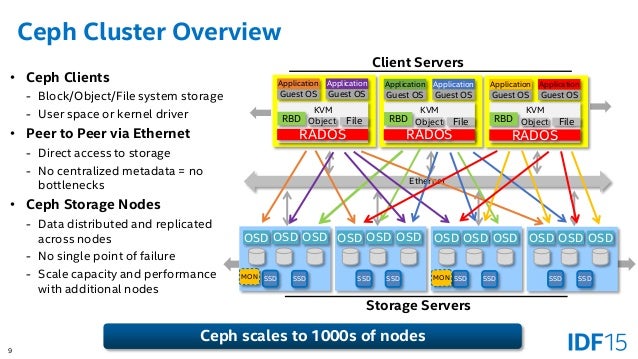
- Whether you want to provide Ceph Object Storage and/or Ceph Block Device services to Cloud Platforms, deploy a Ceph Filesystem or use Ceph for another purpose, all Ceph Storage Cluster deployments begin with setting up each Ceph Node, your network, and the Ceph Storage Cluster. A Ceph Storage Cluster requires at least one Ceph Monitor, Ceph Manager, and Ceph OSD (Object Storage Daemon).
The Ceph Metadata Server is also required when running Ceph Filesystem clients.
Monitors: A Ceph Monitor (ceph -mon) maintains maps of the cluster state, including the monitor map, manager map, the OSD map, and the CRUSH map. These maps are critical cluster state required for Ceph daemons to coordinate with each other. Monitors are also responsible for managing authentication between daemons and clients. At least three monitorsare normally required for redundancy and high availability.
Managers: A Ceph Manager daemon (ceph -mgr )is responsible for keeping track of runtime metrics and the current state of the Ceph cluster, including storage utilization, current performance metrics, and system load. The Ceph Manager daemons also host python-based plugins to manage and expose Ceph cluster information, including a web-based dashboard and REST API. Atleast two managers are normally required for high availability.
Ceph OSDs: A Ceph OSD (object storage daemon,ceph -osd ) stores data, handles data replication, recovery, rebalancing, and provides some monitoring information to Ceph Monitors and Managers by checking other Ceph OSD Daemons for a heartbeat. At least 3 Ceph OSDsare normally required for redundancy and high availability.
MDSs: A Ceph Metadata Server (MDS,ceph -mds ) stores metadata on behalf of the Ceph Filesystem (i.e., Ceph Block Devices and Ceph Object Storage do not use MDS). Ceph Metadata Servers allow POSIX file system users to execute basic commands (likels , find, etc.) without placing an enormous burden on the Ceph Storage Cluster.
http://docs.ceph.com/docs/master/start/intro/ - Ceph OSDs (
ceph -osd ) - Handles the data storage, data replication, and recovery. A Ceph cluster needs at least two Ceph OSD servers. We will use three Ubuntu 16.04 servers in this setup.
Ceph Monitor (ceph -mon) - Monitors the cluster state and runs the OSD map and CRUSH map. We will use one server here.
CephMeta Data Server (ceph -mds ) -this is needed if you want to use Ceph as a File System.
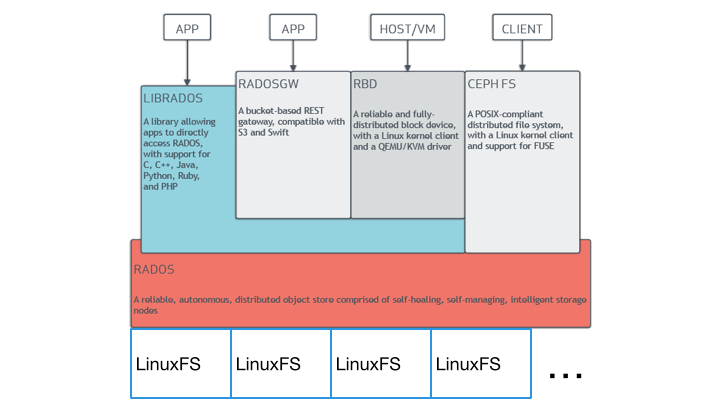
https://www.howtoforge.com/tutorial/how-to-install-a-ceph-cluster-on-ubuntu-16-04/ Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.- Ceph’s software libraries provide client applications with direct access to the RADOS object-based storage system, and also provide a foundation for some of Ceph’s advanced features, including RADOS Block Device (RBD), RADOS Gateway (RGW), and the Ceph File System (
CephFS ). - Ceph’s object storage system isn’t limited to native binding or RESTful APIs. You can mount Ceph as a thinly provisioned block device! When you write data to Ceph using a block device, Ceph automatically stripes and replicates the data across the cluster. Ceph’s RADOS Block Device (RBD) also integrates with Kernel Virtual Machines (KVMs), bringing Ceph’s virtually unlimited storage to KVMs running on your Ceph clients
- Object storage systems are a significant innovation, but they complement rather than replace traditional file systems. As storage requirements grow for legacy applications, organizations can configure their legacy applications to use the
Ceph file system too! This means you can run one storage cluster forobject , block and file-based data storage.




- The Ceph Filesystem (Ceph FS) is a POSIX-compliant filesystem that uses a Ceph Storage Cluster to store its data. The Ceph filesystem uses the same Ceph Storage Cluster system as Ceph Block Devices, Ceph Object Storage with its S3 and Swift APIs, or native bindings (
librados ).
Ceph Object Gateway
- S3-compatible: Provides object storage functionality with an interface
that is compatible with a large subset of the Amazon S3 RESTful API. - Swift-compatible: Provides object storage functionality with an interface
that is compatible with a large subset of the OpenStack Swift API.

Ceph Block Device
A block is a sequence of bytes (for example, a 512-byte block of data). Block-based storage interfaces are the most common way to store data with rotating media such as hard disks, CDs, floppy disks, and even traditional 9-track tape. The ubiquity of block device interfaces makes a virtual block device an ideal candidate to interact with a mass data storage system like Ceph .
http://docs.ceph.com/docs/master/rbd/- why is
ceph so dominant?
- What if you only had something like this in each data center:
Scalable distributed block storage
Scalable distributed object storageScalable distributed file system storage
Scalable control plane that manages
The fundamental problem with any multi-purpose tool is that it makes compromises in each “purpose” it serves.
If you want your screwdriver
RADOS itself is reliant on an underlying file system to store its objects.
Every new task or purpose it takes on includes overhead in terms of business logic, processing time, and resources consumed.
Test cases: “SSD only”, “SSD+HDD”, and “hybrid mode” with SSD as a cache for HDD
http://cloudscaling.com/blog/cloud-computing/killing-the-storage-unicorn-purpose-built-scaleio-spanks-multi-purpose-ceph-on-performance/
Demo: running Ceph in Docker containers
Deploy Red Hat Ceph Storage 1.3 on RHEL 7.1 with Ansible





Ceph uniquely delivers object , block, and file storage in one unified system.

Ceph provides an infinitely scalable Ceph Storage Cluster based upon RADOS
Ceph Monitor
Ceph OSD Daemon
The Ceph Storage Cluster was designed to store at least two copies of an object (i.e., size = 2), which is the minimum requirement for data safety. For high availability, a Ceph Storage Cluster should store more than two copies of an object (e.g., size = 3 and min size = 2) so that it can continue to run in a degraded state while maintaining data safety.
Ceph Clients
Ceph Block Device
Ceph Filesystem
Ceph FS separates the metadata from the data, storing the metadata in the MDS, and storing the file data in one or more objects in the Ceph Storage Cluster.
librados object enumeration: If your application is using librados directly and relies on object enumeration, cache tiering may not work as expected. (This is not a problem for RADOS Gateway, RBD, or CephFS .)
Rook is designed to run as a native Kubernetes service – it scales along side your apps.
BeeGFS transparently spreads user data across multiple servers. By increasing the number of servers and disks in the system, you can simply scale performance and capacity of the file system to the level that you need, seamlessly from small clusters up to enterprise-class systems with thousands of nodes
Glfs can be used in both distributed and distributed-replicated (as well as geo-replicated) form. See this PDF reference describing the different formats that Gluster can support.) FhGFS can also be completely or partially replicated,
amples include the smart power grid, self-driving cars, smart highways that help vehicles anticipate rapidly changing road
be captured . HDFS limits snapshots to append-only files, requires that snapshots be preplanned , and creates
them when the snapshot request reaches the HDFS server,introducing inaccuracy. Ceph pauses I/O during snapshot
throughput at 97Gbps, very close to the hardware limit.
are posted asynchronously and carried out using reliable zero-copy hardware DMA transfers. Our design uses the
it was originally created for the use of smart electric power grid, where developers are creating machine-intelligence solutions to improve the way electric power is managed and reduce wasteful and power generation that creates pollution. In this application, data collectors capture data from Internet of Things (IoT) devices, such as power-line monitoring units (so-called PMU and micro-PMU sensors), in-home smart meters, solar panels, and so on. The data is relayed into a cloud setting for analysis, often by an optimization program that will then turn around and adjust operating modes to balance power generation and demand.
namespace at all times.
The internal drives are divided into two RAID arrays. The first two 73GB SAS drives are configured as RAID1 and act as the boot device and the other four
300GB SAS drives are configured as RAID10 and act as the MDS storage. the MDS block devices are mirrored by means of the network-based RAID1 software
Disks in each disk group are spanned across all three disk arrays.
Lustre™ was designed with large sequential I/O in mind

The Lustre storage architecture is used for many different kinds of clusters. It is best known for powering many of the largest high-performance computing (HPC) clusters worldwide, with tens of thousands of client systems, petabytes (PB) of storage and hundreds of gigabytes per second (GB/sec) of I/O throughput. Many HPC sites use a Lustre file system as a site-wide global file system, serving dozens of clusters.



GlusterFS stores its dynamically generated configuration files at /var/lib/glusterd .
gluster peer probe server2
gluster peer probe server1
However this also means that a brick failure will lead to complete loss of data and one must rely on the underlying hardware for data loss protection.
The number of replicas in the volume can be decided by client while creating the volume.
Such a volume is used for better reliability and data redundancy.
files are distributed across replicated sets of bricks.
Also the order in which we specify the bricks matters since adjacent bricks become replicas of each other.
This volume is denoted as 4x2.
Similarly if there were eight bricks and replica count 4 then four bricks become replica of each other and we denote this volume as 2x4 volume.
GlusterFS is a userspace filesystem
GlusterFS is a userspace filesystem. This was a decision made by the GlusterFS developers initially as getting the modules into linux kernel is a very long and difficult process.
GlusterFS is an open-source, scalable network filesystem suitable for high data-intensive workloads such as media streaming, cloud storage, and CDN (Content Delivery Network)
glusterd – is a daemon that runs on all servers in the trusted storage pool.
GlusterFS components use DNS for name resolutions, so configure either DNS or set up a hosts entry. If you do not have a DNS on your environment, modify /etc/hosts file and update it accordingly.


A Ceph Node leverages commodity hardware and intelligent daemons, and a Ceph Storage Cluster accommodates large numbers of nodes, which communicate with each other to replicate and redistribute data dynamically.

A Ceph Storage Cluster consists of two types of daemons:
A Ceph Monitor maintains a master copy of the cluster map. A cluster of Ceph monitors ensures high availability should a monitor daemon fail. Storage cluster clients retrieve a copy of the cluster map from the Ceph Monitor.
A Ceph OSD Daemon checks its own state and the state of other OSDs and reports back to monitors.
Storage cluster clients and each Ceph OSD Daemon use the CRUSH algorithm to efficiently compute information about data location, instead of having to depend on a central lookup table.
Storing Data
The Ceph Storage Cluster receives data from Ceph Clients–whether it comes through a Ceph Block Device, Ceph Object Storage, the Ceph Filesystem or a custom implementation you create using librados –and it stores the data as objects. Each object corresponds to a file in a filesystem, which is stored on an Object Storage Device. Ceph OSD Daemons handle the read/write operations on the storage disks.
Scalability and High Availability
Ceph eliminates the centralized gateway to enable clients to interact with Ceph OSD Daemons directly. Ceph OSD Daemons create object replicas on other Ceph Nodes to ensure data safety and high availability. Ceph also uses a cluster of monitors to ensure high availability. To eliminate centralization, Ceph uses an algorithm called CRUSH.
High Availability Monitors
A Ceph Storage Cluster can operate with a single monitor; however, this introduces a single point of failure (i.e., if the monitor goes down, Ceph Clients cannot read or write data).
For added reliability and fault tolerance, Ceph supports a cluster of monitors. In a cluster of monitors, latency and other faults can cause one or more monitors to fall behind the current state of the cluster. For this reason, Ceph must have agreement among various monitor instances regarding the state of the cluster. Ceph always uses a majority of monitors (e.g., 1, 2:3, 3:5, 4:6, etc.) and the Paxos algorithm to establish a consensus among the monitors about the current state of the cluster
High Availability Authentication
To identify users and protect against man-in-the-middle attacks, Ceph provides its cephx authentication system to authenticate users and daemons.
A key scalability feature of Ceph is to avoid a centralized interface to the Ceph object store, which means that Ceph clients must be able to interact with OSDs directly. To protect data, Ceph provides its cephx authentication system, which authenticates users operating Ceph clients. The cephx protocol operates in a manner with behavior similar to Kerberos.
OSD Membership and Status: Ceph OSD Daemons join a cluster and report on their status. At the lowest level, the Ceph OSD Daemon status is up or down reflecting whether or not it is running and able to service Ceph Client requests. If a Ceph OSD Daemon is down and in the Ceph Storage Cluster, this status may indicate the failure of the Ceph OSD Daemon. If a Ceph OSD Daemon is not running (e.g., it crashes), the Ceph OSD Daemon cannot notify the Ceph Monitor that it is down. The Ceph Monitor can ping a Ceph OSD Daemon periodically to ensure that it is running. However, Ceph also empowers Ceph OSD Daemons to determine if a neighboring OSD is down, to update the cluster map and to report it to the Ceph monitor( s). This means that Ceph monitors can remain light weight processes.
Data Scrubbing: As part of maintaining data consistency and cleanliness, Ceph OSD Daemons can scrub objects within placement groups. That is, Ceph OSD Daemons can compare object metadata in one placement group with its replicas in placement groups stored on other OSDs. Scrubbing (usually performed daily) catches bugs or filesystem errors. Ceph OSD Daemons also perform deeper scrubbing by comparing data in objects bit-for-bit. Deep scrubbing (usually performed weekly) finds bad sectors on a drive that weren’t apparent in a light scrub
Replication: Like Ceph Clients, Ceph OSD Daemons use the CRUSH algorithm, but the Ceph OSD Daemon uses it to compute where replicas of objects should be stored (and for rebalancing). In a typical write scenario , a client uses the CRUSH algorithm to compute where to store an object, maps the object to a pool and placement group, then looks at the CRUSH map to identify the primary OSD for the placement group. The client writes the object to the identified placement group in the primary OSD. Then, the primary OSD with its own copy of the CRUSH map identifies the secondary and tertiary OSDs for replication purposes , and replicates the object to the appropriate placement groups in the secondary and tertiary OSDs (as many OSDs as additional replicas), and responds to the client once it has confirmed the object was stored successfully.
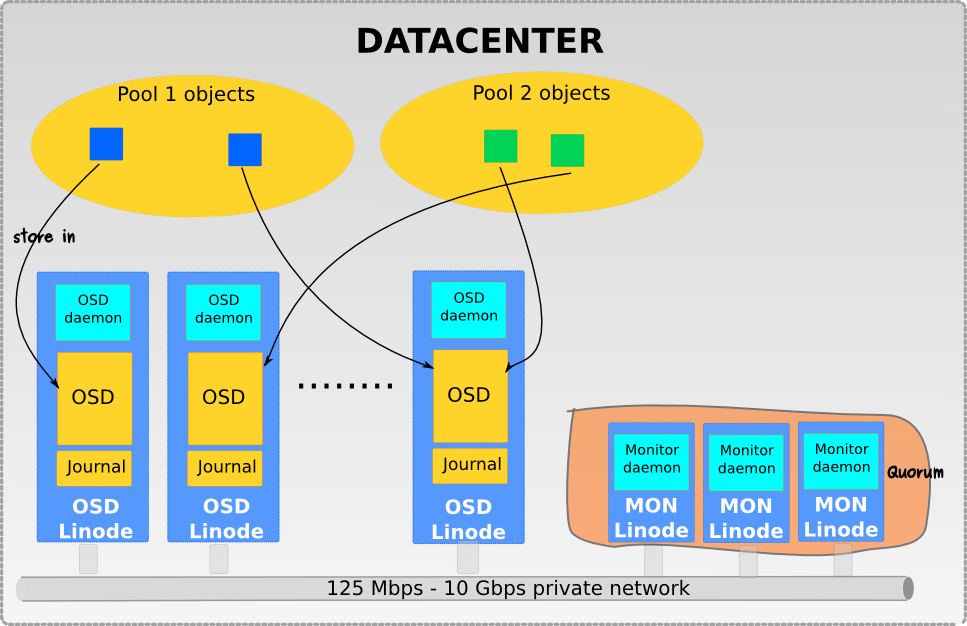
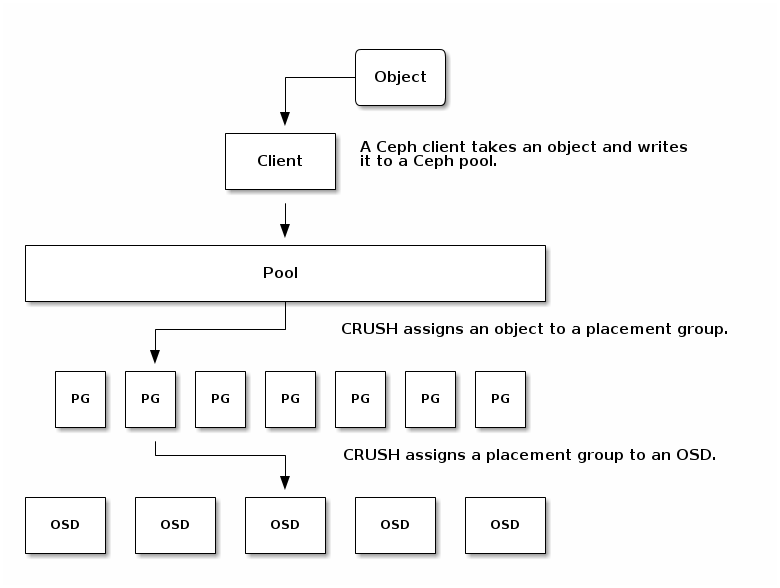
About Pools
The Ceph storage system supports the notion of ‘ Pools’, which are logical partitions for storing objects.
Ceph Clients retrieve a Cluster Map from a Ceph Monitor, and write objects to pools. The pool’s size or number of replicas, the CRUSH ruleset and the number of placement groups determine how Ceph will place the data.
Mapping PGs to OSDs
Each pool has a number of placement groups. CRUSH maps PGs to OSDs dynamically. When a Ceph Client stores objects, CRUSH will map each object to a placement group
Mapping objects to placement groups creates a layer of indirection between the Ceph OSD Daemon and the Ceph Client. The Ceph Storage Cluster must be able to grow (or shrink) and rebalance where it stores objects dynamically. If the Ceph Client “knew” which Ceph OSD Daemon had which object, that would create a tight coupling between the Ceph Client and the Ceph OSD Daemon. Instead, the CRUSH algorithm maps each object to a placement group and then maps each placement group to one or more Ceph OSD Daemons. This layer of indirection allows Ceph to rebalance dynamically when new Ceph OSD Daemons and the underlying OSD devices come online
Calculating PG IDs
When a Ceph Client binds to a Ceph Monitor, it retrieves the latest copy of the Cluster Map. With the cluster map, the client knows about all of the monitors, OSDs, and metadata servers in the cluster. However, it doesn’t know anything about object locations.
Object locations get computed.
Peering and Sets
In previous sections, we noted that Ceph OSD Daemons check each others heartbeats and report back to the Ceph Monitor. Another thing Ceph OSD daemons do is called ‘peering’, which is the process of bringing all of the OSDs that store a Placement Group (PG) into agreement about the state of all of the objects (and their metadata) in that PG
When a series of OSDs are responsible for a placement group, that series of OSDs, we refer to them as an Acting Set. An Acting Set may refer to the Ceph OSD Daemons that are currently responsible for the placement group, or the Ceph OSD Daemons that were responsible for a particular placement group as of some epoch.
Cache Tiering
A cache tier provides Ceph Clients with better I/O performance for a subset of the data stored in a backing storage tier. Cache tiering involves creating a pool of relatively fast/expensive storage devices (e.g., solid state drives) configured to act as a cache tier, and a backing pool of either erasure-coded or relatively slower/cheaper devices configured to act as an economical storage tier. The Ceph objecter handles where to place the objects and the tiering agent determines when to flush objects from the cache to the backing storage tier. So the cache tier and the backing storage tier are completely transparent to Ceph clients.
Ceph Storage Clusters are dynamic–like a living organism. Whereas, many storage appliances do not fully utilize the CPU and RAM of a typical commodity server, Ceph does. From heartbeats, to peering, to rebalancing the cluster or recovering from faults, Ceph offloads work from clients (and from a centralized gateway which doesn’t exist in the Ceph architecture) and uses the computing power of the OSDs to perform the work.
Data Striping
The most common form of data striping comes from RAID. The RAID type most similar to Ceph ’s striping is RAID 0, or a ‘striped volume’. Ceph ’s striping offers the throughput of RAID 0 striping, the reliability of n-way RAID mirroring and faster recovery.
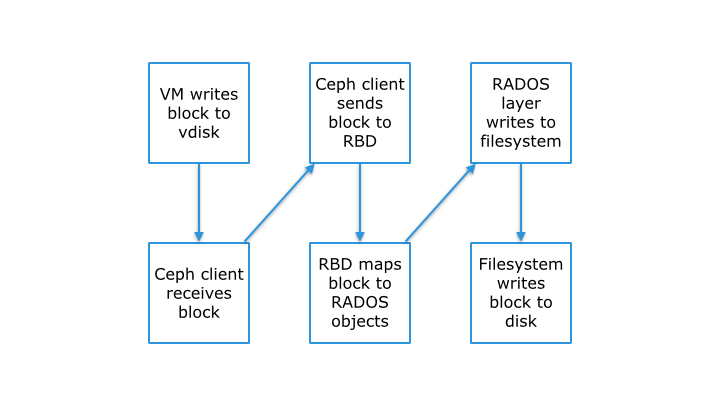
Ceph provides three types of clients: Ceph Block Device, Ceph Filesystem, and Ceph Object Storage. A Ceph Client converts its data from the representation format it provides to its users (a block device image, RESTful objects, CephFS filesystem directories) into objects for storage in the Ceph Storage Cluster.
Block Devices: The Ceph Block Device (a. k. a., RBD) service provides resizable, thin-provisioned block devices with snapshotting and cloning. Ceph stripes a block device across the cluster for high performance. Ceph supports both kernel objects (KO) and a QEMU hypervisor that uses librbd directly–avoiding the kernel object overhead for virtualized systems.
Object Storage: The Ceph Object Storage (a. k. a., RGW) service provides RESTful APIs with interfaces that are compatible with Amazon S3 and OpenStack Swift
Filesystem: The Ceph Filesystem (CephFS ) service provides a POSIX compliant filesystem usable with mount or as a filesytem in user space (FUSE)
A Ceph Block Device stripes a block device image over multiple objects in the Ceph Storage Cluster, where each object gets mapped to a placement group and distributed, and the placement groups are spread across separate ceph -osd daemons throughout the cluster. Thin-provisioned snapshottable Ceph Block Devices are an attractive option for virtualization and cloud computing. In virtual machine scenarios, people typically deploy a Ceph Block Device with the rbd network storage driver in Qemu/KVM, where the host machine uses librbd to provide a block device service to the guest. Many cloud computing stacks use libvirt to integrate with hypervisors. You can use thin-provisioned Ceph Block Devices with Qemu and libvirt to support OpenStack and CloudStack among other solutions.
The Ceph Filesystem service includes the Ceph Metadata Server (MDS) deployed with the Ceph Storage cluster. The purpose of the MDS is to store all the filesystem metadata (directories, file ownership, access modes, etc) in high-availability Ceph Metadata Servers where the metadata resides in memory. The reason for the MDS (a daemon called ceph -mds ) is that simple filesystem operations like listing a directory or changing a directory (ls , cd) would tax the Ceph OSD Daemons unnecessarily. So separating the metadata from the data means that the Ceph Filesystem can provide high performance services without taxing the Ceph Storage Cluster.
http://docs.ceph.com/docs/jewel/architecture/
- Setting Up a Cache Pool
In subsequent examples, we will refer to the cache pool as hot-storage and the backing pool as cold-storage.
http://docs.ceph.com/docs/jewel/rados/operations/cache-tiering/
- Points to Consider
Cache tiering may degrade the cluster performance for specific workloads. The following points show some of its aspects you need to consider:
Workload dependent: Whether a cache will improve performance is dependent on the workload. Because there is a cost associated with moving objects into or out of the cache, it can be more effective when most of the requests touch a small number of objects. The cache pool should be large enough to capture the working set for your workload to avoid thrashing .
Difficult to benchmark: Most performance benchmarks may show low performance with cache tiering . The reason is that they request a big set of objects, and it takes a long time for the cache to 'warm up'.
Possibly low performance: For workloads that are not suitable for cache tiering , performance is often slower than a normal replicated pool without cache tiering enabled.
https://www.suse.com/documentation/ses-4/book_storage_admin/data/sec_ceph_tiered_caution.html
- When to Use Cache
Tiering
Consider using cache tiering in the following cases:
You need to access erasure coded pools via RADOS block device (RBD).
You need to access erasure coded pools via iSCSI as it inherits the limitations of RBD.
You have a limited number of high performance storage and a large collection of low performance storage, and need to access the stored data faster.
https://www.suse.com/documentation/ses-4/book_storage_admin/data/sect1_3_chapter_book_storage_admin.html
- cache
tiering
http://iopscience.iop.org/article/10.1088/1742-6596/762/1/012025/pdf
-
Ceph Manager Daemon
The Ceph Manager daemon (ceph -mgr ) runs alongside monitor daemons, to provide additional monitoring and interfaces to external monitoring and management systems.
http://docs.ceph.com/docs/master/mgr/
The as RBD or RADOS Block Device.Ceph Block Device is also known
http://docs.ceph.com/docs/jewel/start/quick-rbd/
- File, Block, and Object Storage Services for your Cloud-Native Environments
Rook orchestrates battle-tested open-source storage technologies including Ceph , which has years of production deployments and runs some of the worlds largest clusters.
Rook offers storage for your Kubernetes app through persistent volumes.
Rook takes advantage of many benefits of the platform, such as streamlined resource management, health checks, failover, upgrades, and networking, to name just a few.
https://rook.io/
- The
ceph -helm project enables you to deployCeph in a Kubernetesenvironement . This documentation assumes a Kubernetesenvironement is availablehttp://docs.ceph.com/docs/master/start/kube-helm/
OpenEBS is an open source storage platform that provides persistent and containerized block storage for DevOps and container environments.
https://www.openebs.io/
BeeGFS (formerlyFhGFS ) is the leading parallel cluster file system, developedwith a strong focus on performance and designed for very easy installation and management.
https://www.beegfs.io/content
- We
evaluated the Fraunhofer (FhGFS ) and Gluster (Glfs ) distributed filesystem technologies on multiple hardware platforms under widely varying conditions
Both operate well over Infiniband and Ethernet simultaneously, however only FhGFS currently supports RDMA. Gluster has RDMA support in the code, has supported it, and indicates that they will soon support it again. Both support IPoIB .
Distributed filesystems are those where the files are distributed in whole or in part on different block devices, with direct interaction with client computers to allow IO scaling proportional to the number of servers. Acording to this definition, a network-shared NFS server would not be a distributed filesystem, whereas Lustre, Gluster, Ceph , PVFS2 (aka Orange), and Fraunhofer are distributed filesystems, altho they differ considerably on implementation details.
http://moo.nac.uci.edu/~hjm /fhgfs_vs_gluster .html#_what_is_a_distributed_filesystem
- Many applications perform real-time analysis on data streams. We argue that existing solutions
are poorly matched to theneed, and introduce our new Freeze-Frame File System. Freeze-Frame FSis able to accept streams of updates while satisfying “temporal reads” on demand. The system is fast and accurate: we keep all update history in a memory-mapped log, cache recently retrieved data for repeat reads, and use a hybrid of a real-time and a logical clock to respond to read requests in a manner that is both temporally precise and causally consistent. When RDMA hardware is available, the write and readthroughput of a single client reaches 2.6G Byte/s for writes, 5G Byte/s for reads, close to the limit on the hardware used in our experiments
https://github.com/songweijia/fffs
- FFFS implements a new
kind of temporal storage system in which each file system updateis represented separately and its time of updateis tracked . When a temporal read occurs, FFFS recovers the exact data that appliedat that time for that file. These data structures are highly efficient: FFFS outperforms HDFS even in standard non-temporal uses
https://community.mellanox.com/docs/DOC-2646
- Freeze-Frame FS
is able to accept streams of updates while satisfying “temporal reads” on demand.
we keep all update history in a memorymapped log, cache recently retrieved data for repeat reads,
and use a hybrid of a real-time and a logical clock to respond to read requests in a manner that is both temporally precise
and causally consistent.
Consider an Internet of Things application that captures data in real-time (perhaps onto a cloud-hosted server), runs a
machine-learning algorithm, and then initiates actions in the real-world. Such applications are increasingly common: ex-
conditions, smart home and cities, and so forth.
HDFS is oblivious to timestamps and hence often mixes frames from different times. If a file system can’t support making a movie, it clearly
couldn’t support other time-sensitive computations. Today,the only option is to build applications that understand time
signals in the data, but this pushes a non-trivial task to developers and makes it hard to leverage the huge base of
existing cloud-computing analytic tools that just run on files
Among existing file systems, snapshot capabilities are common, but few permit large numbers of real-time states to
creation, and snapshots are costly to create
To evaluate FFFS performance over RDMA, we equipped Fractus with Mellanox 100 Gbps RDMA dual-capable NICs,
and installed two 100Gbps Mellanox switches, one for RoCE and one for Infiniband . For the work reported here,
both yielded identical performance. Our experience shows that, even when jumbo frames and the TCP offload Engine are both enabled, a TCP/IP session will
only achieve 40Gbps if running over a network that uses Ethernet standards ( for example, on a 100Gbps Ethernet, our
experiments showed that TCP over IP peaked at 40Gbps). In contrast, using RoCE , we can easily achieve a read/write
RDMA supports two modes of operation: the so-called one-sided and two-sided cases. Both involve some set-up.
With one-sided RDMA, one node grants the other permission to read and write in some memory region; two-sided
RDMA is more like TCP, with a connection to which one side writes, and that the other reads. The actual operations
one-sided mode, with the FFFS DataNodes initiating all RDMA operations. Our design uses the one-sided mode, with the FFFS DataNodes initiating all
RDMA operations.
http://www.cs.cornell.edu/projects/Quicksilver/public_pdfs/fffs-camera-ready.pdf
FFFS was originally created for the use of smart electric power grid, where developers are creating machine-intelligence solutions to improve the wayelectric power is managed and reduce dirty power generation. In this setting, data collectors capture data from Internet of Things (IoT) devices, such as power-line monitoring units (so-called PMU and micro-PMU sensors), in-home smart meters, solar panels, and so on. FFFSimplements a new kind of temporal storage system in which each file system update is represented separately and its time of update is tracked . When a temporal read occurs, FFFS recovers the exact data that appliedat that time for that file.
https://community.mellanox.com/docs/DOC-2646
- When RDMA hardware is available, the write and read
throughput of a single client reaches 2.6G Byte/s for writes, 5G Byte/s for reads
https://github.com/songweijia/fffs
- This is where RDMA plays a key role:
FFFS is designed to leverage Mellanox RDMA solutions. FFFS with Mellanox RDMA is far faster than standard non-RDMA file systems (like the popularCeph or HDFS file systems) in all styles of use, andat the same time , FFFSis able to offer better consistency and temporal accuracy.
fast, scalable IoT solutions can be difficult to create. IoT applications often require real-time analysis on data streams, but most software is designed to just read data from existing files.
As a result, the developer may be forced to create entirely new applications that read data continuously. Developers who prefer to just build scripts that build new solutions from existing analytic tools would find this frustrating and time-consuming.
in today’s systems, the delay (latency) of the store-then-compute style of analysis is often very high.
The key is that FFFS bridges between a model of continuously writing data into files and one of performing analysis on snapshots representing instants in time (much as if it was a file system backup system creating a backup after every single file update operation).
One of the outstanding features of FFFS is that it uses a new form of temporal storage system wherein each file system update is represented separately and its time of update is tracked .
An Example Use Case
The greatest benefit happens when performing temporal analytics which is the analysis of the evolving state of the system over time, rather than just on the state of the system at a single instant
FFFS supports temporal access to a file at more than one point in time, from a single program. As such, one can easily write programs that explicitly search data in the time dimension! It is as if the same file could be opened again and again, with each file descriptor connecting to a different version from a different instant in time.
FFFS with Mellanox RDMA is far faster than standard non-RDMA file systems (like the popular Ceph or HDFS file systems) in all styles of use, and at the same time , FFFS is able to offer better consistency and temporal accuracy.
FFFS isn’t finished yet. In future work, I’ll be using Cornell’s RDMA-based Derecho programming platform to make FFFS highly available via data replication and fault-tolerance. This will also make it even more scalable, since we will be able to spread reads and writes over a large number of compute /storage nodes.
http://www.mellanox.com/blog/2016/11/experience-with-the-freeze-frame-file-system-fffs-on-mellanox-rdma/
- Derecho is a library that helps you build replicated, fault-tolerant services in a
datacenter with RDMA networking.
https://derecho-project.github.io/userguide.html
- The paper provides a detailed description of how to build a commodity “Dell Lustre™ Storage Brick” and provides comprehensive performance characteristics
obtained from the
Lustre storage brick when integrated into a gigabit Ethernet storage network.
The performance data shows good I/O throughput via the Lustre filesystem on top of the Dell storage brick, yielding 80% of the bare metal MD3000 storage array performance.
Dell Lustre Storage brick is able to provide 400MB/s read/write I/O bandwidth through the filesystem layer, this performance scaling linearly with each additional storage brick.
Over gigabit Ethernet each client is able to achieve an I /O bandwidth of 100MB/s which scales linearly with successive clients until the back-end bandwidth is saturated .
We have scaled such a system to hundreds of terabytes with over 2 GB/s total back-end storage I/O performance and 600 clients.
A large 270 TB (6 brick) configuration within the Cambridge production environment has demonstrated very good operational characteristics with an unscheduled downtime of less than 0.5% over 2 years of 24/7 service.
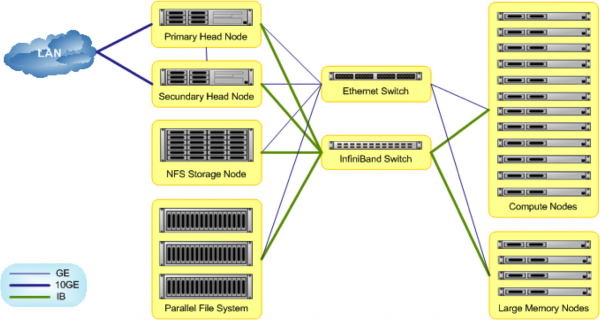
The continued growth of clustered computing and the large computational power of even modest departmental and workgroup HPC systems has resulted in a storage architecture challenge in which traditional NFS, NAS, SAN and DAS based storage solutions have not kept pace with the performance growth of a large segment of the HPC install base.
the HPC industry has seen a rise in use of parallel filesystems such as Lustre™ , GPFS™ (General Parallel File System™) and pNFS as an attempt to overcome the HPC storage architecture problem.
In fact Lustre is now used in over 50% of the top 50 supercomputers in the world.
2.0 Lustre Filesystem Design
The main components of Lustre are the Metadata Server (MDS), Object Storage Server (OSS) and Lustre client.
The Lustre clients are typically HPC cluster compute nodes which run Lustre client software and communicate with Lustre servers over Ethernet or Infiniband . The Lustre client software consists of an interface between the Linux virtual filesystem and the Lustre servers. Clients mounting the Lustre filesystem see a single, coherent, synchronised
4.1 HA-MDS Module
known as DRBD .
5.0 Software Components Overview
The Dell Lustre™ Storage System software stack installed on the Metadata Servers and Object Storage Servers includes the following software components
Linux operation system
Lustre filesystem
HA-Linux Heartbeat failover
DRBD network mirroring tool
Dell configuration and monitoring tools
The Dell Lustre Storage system uses the Scientific Linux 5.4 Linux operating system distribution (SL5.4).
This is a rebuild of the Red Hat Enterprise Linux distribution (RHEL5.4) This Linux distribution is an
Enterprise-level operating system which provides the industry's most comprehensive suite of Linux
solutions.
The Dell Lustre Storage system uses Lustre version 1.8 which is the latest stable
version of Lustre.
DRBD® is a distributed storage system for the Linux platform. DRBD® refers to both the software (kernel module) and also a specific logical block device managed by the software.
Dell PowerVault MD3000 Lustre Configuration Best Practices
There are 4 RAID6 disk groups configured. Each RAID6 disk group consists of 8 data disks and 2 parity disks.
The segment size of the disk group is 512KB and the stripe size is 4096KB.
Such a large segment size minimises the number of disks that need to be accessed to satisfy a single I/O operation.
The Lustre typical I/O size is 1MB, therefore each I/O operation requires access to two disks in a RAID stripe.
This leads to faster disk access per I/O operation.
For optimal performance only one virtual disk per disk group is configured , which results in more sequential access of the RAID disk group and which may significantly improve I/O performance.
Lustre manual suggests using the full device instead of a partition (sdb vs sdb1). When using the full device, Lustre writes well-aligned 1 MB chunks to disk. Partitioning the disk removes this alignment and will noticeably impact performance.
Disabling the read cache retains all the cache memory for write operations, which has a positive effect on write speeds. Linux® OS can compensate for the absence of a controller read cache by means of an adaptive read-ahead cache.
6.6 LVM Configuration
LVM allows one to regularly backup MDT device content by using LVM snapshots. This can be done without taking the Lustre filesystem offline
6.7 Lustre Administration Best Practices
6.7.1 Small Files Lustre Performance
Although in general Lustre is designed to work with large files it is possible to tune lustre client parameters to improve small file performance.
It is especially useful to perform this tuning on nodes that are interactively accessed by users, for example login nodes:
http://www.dell.com/downloads/global/solutions/200-DELL-CAMBRIDGE-SOLUTIONS-WHITEPAPER-20072010b.pdf

- The Lustre® file system is an open-source, parallel file system that supports many requirements of leadership class HPC simulation environments.
http://lustre.org/
- What a Lustre File System Is (and What It Isn't)
The Lustre architecture is a storage architecture for clusters. The central component of the Lustre architecture is the Lustre file system, which is supported on the Linux operating system and provides a POSIX *standard-compliant UNIX file system interface.
The ability of a Lustre file system to scale capacity and performance for any need reduces the need to deploy many separate file systems, such as one for each compute cluster. Storage management is simplified by avoiding the need to copy data between compute clusters. In addition to aggregating storage capacity of many servers, the I /O throughput is also aggregated and scales with additional servers. Moreover, throughput and/or capacity can be easily increased by adding servers dynamically.
While a Lustre file system can function in many work environments, it is not necessarily the best choice for all applications. It is best suited for uses that exceed the capacity that a single server can provide, though in some use cases, a Lustre file system can perform better with a single server than other file systems due to its strong locking and data coherency.
A Lustre file system is currently not particularly well suited for "peer-to-peer" usage models where clients and servers are running on the same node, each sharing a small amount of storage, due to the lack of data replication at the Lustre software level. In such uses, if one client/server fails, then the data stored on that node will not be accessible until the node is restarted .
http://doc.lustre.org/lustre_manual.xhtml

- Recently one
of the founders ofGlusterFS , Anand Babu Periasamy, announced a new open source project, Minio.Minio is designed to enable application developers to build their own cloud storage.
Because GlusterFS is being used for redundancy (and if you’d like, to pool resources further), you will want to start Minio on nodes with the Gluster mountpoint , rather than the volume mountpoint . If you do not wish to have this replication, you can use the volume mountpoint directly.
https://medium.com/@jmarhee/building-an-object-storage-service-ecd771d91483
- There are many solutions to syncing file on two different servers such as GlusterFS, and NFS. While using GlusterFS, the core directory in Drupal always replied with
a Input /output error. As a result, I willbe using Unison to sync files across web1 and web2. As an alternative you can also use a script I wrote thatutilize inotifywait andscp to sync fileshttp://www.kalose.net/oss/drupal-8-load-balancing-haproxy/
- While
GlusterFS handles monitoring and failover itself,a separate service is needed for the database cluster. For this, we useKeepalived with a failover IP address. The failover IP address issimply a private IP address that canbe reassigned between nodes as needed when one fails.Keepalived uses virtual router redundancy protocol, or VRRP,to automatically assign the failover IP address to any of the database nodes. Thekeepalived service uses user-defined rules to monitor for a certain number of failures by a database node. When that failure thresholdis met ,keepalived assigns the failover IP address to a different nodeso that there is no interruption tothe fulfillment of requests while the first node waits tobe fixed In our configuration, the database nodes are a cluster of PerconaXtraDB servers, using Galera for replication. Galera offers synchronous replication,meaning data is written to secondary database nodes at the same time as it’s being written to the primary. This method of replication provides excellent redundancy to the database cluster because it avoids periods of time where the database nodes are not in matching states. Galera also provides multi-master replication, meaning anyone of the database nodes can respond to client queries.https://linode.com/docs/websites/introduction-to-high-availability
- In its native form, GlusterFS gives you redundancy and high availability (HA). However, the clients that connect to your GlusterFS volumes by using its NFS or Samba exports need to have some additional services installed and configured on the GlusterFS nodes. This article explains how to add HA to NFS and Samba exports that
are managed by the GlusterFS nodes when you build your volumeOne drawback to using the NFS or Samba exports is that, unlike using the native client, if a node goes offline, your clients won’t be ableto automatically reconnect to a differentGlusterFS node.https://support.rackspace.com/how-to/glusterfs-high-availability-through-ctdb/
- The goal of Minio is to enable application developers to build their own storage clouds, just like how Amazon, Google, and Facebook developed their own proprietary cloud storage.
https://opensource.com/business/15/7/minimal-object-storage-minio
Heketi provides a RESTful management interfacewhich can be used to Heketi , cloud services like OpenStack Manila,Kubernetes , and OpenShift can dynamically provision GlusterFS volumes with any of the supported durability types.Heketi will automatically determine the location for bricks across the cluster,making sure to place bricks and its replicas across different failure domains.Heketi also supportsany number of GlusterFS clusters, allowing cloud services to provide network file storage without being limited to a single GlusterFS cluster.
https://github.com/heketi/heketi
- This guide enables the integration, deployment, and management of
GlusterFS containerized storage nodes in a Kubernetes cluster. This enables Kubernetes administrators to provide their users with reliable, shared storage.
Another important resource on this topic is the gluster -kubernetes project. It is focused on the deployment of GlusterFS within a Kubernetes cluster, and provides streamlined tools to accomplish this task. It includes a setup guide. It also includes a Hello World featuring an example web server pod using a dynamically-provisioned GlusterFS volume for storage. For those looking to test or learn more about this topic, follow the Quick-start instructions found in the main README for gluster -kubernetes
https://github.com/heketi/heketi/blob/master/docs/admin/install-kubernetes.md
- Gluster is a scalable network filesystem. Using common off-the-shelf hardware, you can create large, distributed storage solutions for media streaming, data analysis, and other data- and bandwidth-intensive tasks. Gluster is free.
https://www.gluster.org/
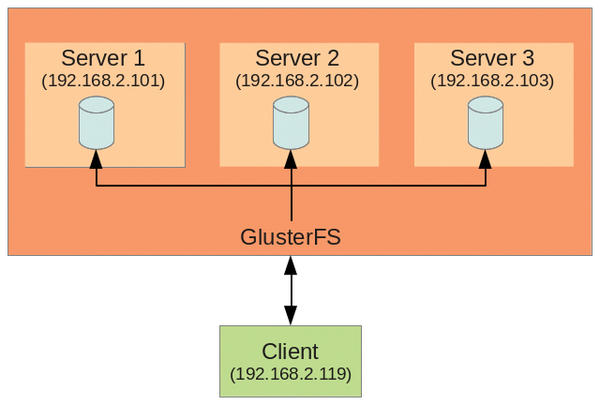
GlusterFS combines the unused storage space on multiple servers to create a single, large, virtual drive that you can mount like a legacy filesystem– using NFS or FUSE on a client PC. And, you can add more servers or remove existing servers from the storage pool on the fly.GlusterFS workskind of like “RAID on the network,” and if you look closely, you will discover many RAID concepts during setup.
http://www.admin-magazine.com/HPC/Articles/GlusterFS
-----------------------------------------------------------------------------------------------------
- At least two virtual disks, one for the OS installation, and one to
be used to serveGlusterFS storage (sdb ).
This will emulate a real- world deployment, where you would want to separate GlusterFS storage from the OS install.
If at any point in time GlusterFS is unable to write to these files (for example, when the backing filesystem is full), it will at minimum cause erratic behavior for your system; or worse, take your system offline completely. It is advisable to create separate partitions for directories such as /var/log to ensure this does not happen.
We are going to use the XFS filesystem for the backend bricks
Step 5 - Configure the trusted pool
From "server1"
From "server2"
Step 7 - Testing the GlusterFS volume
as if it were that "client".
http://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/
- Volume is the collection of bricks and most of the
gluster file system operations happen on the volume.
1. Distributed Glusterfs Volume - This is the default glusterfs volume i.e , while creating a volume if you do not specify the type of the volume,
Hence there is no data redundancy.
The purpose for such a storage volume is to easily & cheaply scale the volume size.
So we need to have at least two bricks to create a volume with 2 replicas or a minimum of three bricks to create a volume of 3 replicas.
2. Replicated Glusterfs Volume
Here exact copies of the data are maintained on all bricks.
3. Distributed Replicated Glusterfs Volume
The number of bricks must be a multiple of the replica count.
So if there were eight bricks and replica count 2 then the first two bricks become replicas of each other then the next two and so on.
4. Striped Glusterfs Volume
So the large file will be divided into smaller chunks (equal to the number of bricks in the volume) and each chunk is stored in a brick
5. Distributed Striped Glusterfs Volume
This is similar to Striped Glusterfs volume except that the stripes can now be distributed across more number of bricks. However the number of bricks must be a multiple of the number of stripes.
Being a userspace filesystem, to interact with kernel VFS, GlusterFS makes use of FUSE (File System in Userspace )
FUSE is a kernel module that support interaction between kernel VFS and non-privileged user applications and it has an API that can be accessed from userspace .
http://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
- All this content needs to
be distributed across all your servers andyou’ll have to keep track on modifications, which is notreally convenient. In other case you will have a single point of failure of your balanced solution. You can usersync orlsyncd for doing this, but to make things more simple fromadministrative perspective and get more advantage for future, you can use a DFS (distributed file system), nowadays there are plenty suitable open source options like:ocfs ,glusterfs ,mogilefs , pvfs2,chironfs ,xtreemfs etc .
Why we want to use DFS?
Data sharing of multiple users
user mobility
location transparency
location independence
backups and centralized management
I choose GlusterFS to start with. Why?
It is opensource, it has modular , plug-able interface and you can run it on any linux based server without upgrading your kernel.
We also want to run our storage on a separated network card, let’s configure eth1 for that using internal IP range:
Ensure that TCP ports 111, 24007,24008, 24009-( 24009 + number of bricks across all volumes) are open on all Gluster servers.
The Gluster Console Manager provides functionality similar to the LVM (Logical Volume Manager) CLI or ZFS Command Line Interface, but across multiple storage servers.
Before configuring a GlusterFS volume, you need to create a trusted storage pool consisting of the storage servers that will make up the volume.
A storage pool is a trusted network of storage servers. When you start the first server, the storage pool consists of that server alone. To add additional storage servers to the storage pool, you can use the probe command from a storage server.
A volume is a logical collection of bricks where each brick is an export directory on a server in the trusted storage pool.
Replicated volumes replicate files throughout the bricks in the volume.
You can use replicated volumes in environments where high-availability and high-reliability are critical.
setup GlusterFS client to access our volume, Gluster offers multiple options to access gluster volume
Gluster Native Client – This method provides high concurrency, performance and transparent failover in GNU/Linux clients. The Gluster Native Client is POSIX conformant. For accessing volumes using gluster native protocol, you need to install gluster native client.
NFS – This method provides access to gluster volumes with NFS v3 or v4.
CIFS – This method provides access to volumes when using Microsoft Windows as well as SAMBA clients. For this access method, Samba packages need to be present on the client side.
Gluster Native Client as it is a POSIX conformant, FUSE-based, the client running in userspace . Gluster Native Client is recommended for accessing volumes when high concurrency and high write performance is required .
https://www.leaseweb.com/labs/2011/11/distributed-storage-for-ha-clusters/
- Client machines/users can access the storage as like local storage. Whenever the user creates data on the Gluster storage,
the data will be mirrored /distributed to other storage nodes
Brick – is basic storage (directory) on a server in the trusted storage pool.
Volume – is a logical collection of bricks.
Cluster – is a group of linked computers, working together as a single computer.
Distributed File System – A filesystem in which the data is spread across the multiple storage nodes and allows the clients to access it over a network.
Client – is a machine which mounts the volume.
Server – is a machine where the actual file system is hosted in which the data will be stored .
Replicate – Making multiple copies of data to achieve high redundancy.
Fuse – is a loadable kernel module that lets non-privileged users create their own file systems without editing kernel code.
RAID – Redundant Array of Inexpensive Disks (RAID) is a technology that provides increased storage reliability through redundancy
https://www.itzgeek.com/how-tos/linux/ubuntu-how-tos/install-and-configure-glusterfs-on-ubuntu-16-04-debian-8.html
- OpenStack can use different backend technologies for Cinder Volumes Service to create volumes for Instances running in a cloud. The default and most common backend used for Cinder Service is LVM (Logical Volume Manager), but it has one basic disadvantage
– it’s slow and overloads the server which serves LVM (usually Controller), especially during volume operations like volume deletion. OpenStack supports other Cinder backend technologies, likeGlusterFS which is more sophisticated and reliable solution, provides redundancy and does not occupy Controller’s resources, because it usually runs on separate dedicated servers.
http://www.tuxfixer.com/install-and-integrate-openstack-mitaka-on-centos-7-with-glusterfs-cinder-volume-backend/
- With
GlusterFS you can create the followingtypes of Gluster Volumes:
Distributed Volumes: (Ideal for Scalable Storage, No Data Redundancy)
Replicated Volumes: (Better reliability and data redundancy)
Distributed-Replicated Volumes: (HA of Data due to Redundancy and Scaling Storage)
https://sysadmins.co.za/setup-a-distributed-storage-volume-with-glusterfs/
Distributed file systems differ in their performance, mutability of content, handling of concurrent writes, handling of permanent or temporary loss of nodes or storage, and their policy of storing content.
https://en.wikipedia.org/wiki/Comparison_of_distributed_file_systems
NFS4 does most everything Lustre can with one very important exception, IO bandwidth.
http://wiki.lustre.org/NFS_vs._Lustre
Multiple NFS servers can be used to spread storage across a network, but individual files are only accessible through a single server.
Multiple storage devices and multiple paths to data are utilized to provide a high degree of parallelism, reducing bottlenecks imposed by accessing only a single node at a time. However, parallel I/O can be difficult to coordinate and optimize if working directly at the level of API or POSIX I/O Interface. By introducing intermediate data access and coordination layers, parallel file systems provide application developers a high-level interface between the application layer and the I /O layer
Parallel file systems are broken up into two main pieces:
BeeGFS
GlusterFS
- File Storage Types and Protocols for Beginners
- Comparison of distributed file systems
Distributed file systems differ in their performance, mutability of content, handling of concurrent writes, handling of permanent or temporary loss of nodes or storage, and their policy of storing content.
https://en.wikipedia.org/wiki/Comparison_of_distributed_file_systems
- NFS vs. Lustre
NFS4 does most everything Lustre can with one very important exception, IO bandwidth.
http://wiki.lustre.org/NFS_vs._Lustre
- HPC storage on Azure
In Azure HPC clusters, compute nodes are virtual machines that can be spun up, as needed, to perform whatever jobs the cluster has been assigned . These nodes spread computation tasks across the cluster to achieve the high performance parallel processing needed to solve the complex problems HPC is applied to.
Compute nodes need to perform read/write operations on shared working storage while executing jobs. The way nodes access this storage falls on a continuum between these two scenarios:
· One set of data to many compute nodes
· Many sets of data to many compute nodes
Limits of NFS
Network file system (NFS) is commonly used to provide access to shared storage locations. With NFS a server VM shares out its local file system, which in the case of Azure is stored on one or more virtual hard disks (VHD) hosted in Azure Storage. Clients can then mount the server's shared files and access the shared location directly.
In HPC scenarios, the file server can often serve as a bottleneck, throttling overall performance. Currently the maximum per VM disk capacity is 80,000 IOPS and 2 Gbps of throughput. In a scenario where dozens of clients are attempting to work on data stored on a single NFS server, these limits can easily be reached , causing your entire application's performance to suffer.
Parallel file systems on Azure
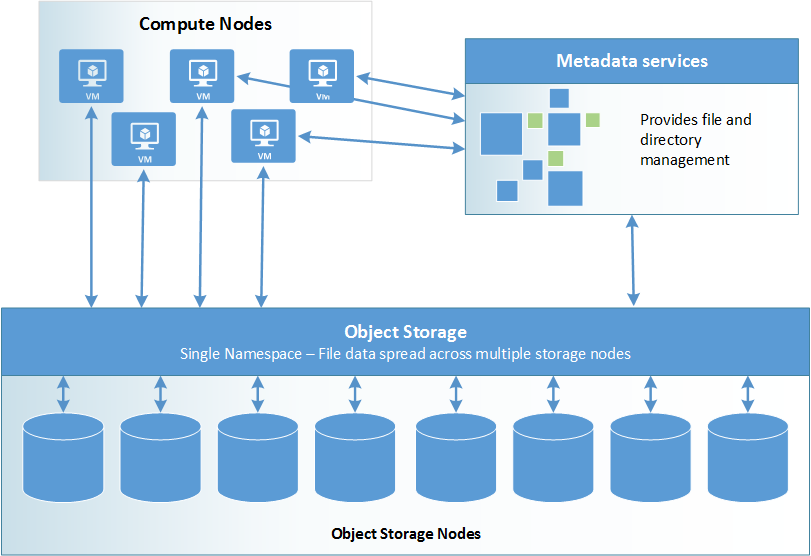
Parallel file systems distribute block level storage across multiple networked storage nodes. File data is spread amongst these nodes, meaning file data is spread among multiple storage devices. This pools any individual storage I/O requests across multiple storage nodes that are accessible through a common namespace .
Metadata services Metadata services store namespace metadata, such as filenames, directories, access permissions, and file layout. Depending on the particular parallel file system, metadata services are provided either through a separate server cluster or as an integrated part of the overall storage node distribution.
Object storage Object storage contains actual file data. Clients pull the location of files and directories from the metadata services, then access file storage directly.
Azure-supported parallel file systems
Lustre
Lustre uses centralized metadata and management servers, and requires at least one VM for each of those, in addition to the VMs assigned as object storage nodes.
Unlike Lustre, BeeGFS metadata is managed at a directory level, and that metadata gets distributed among metadata servers providing comparable parallelism to object storage
a scalable parallel file system specially optimized for cloud storage and media streaming. It does not have separate metadata servers, as metadata is integrated into file storage.
https://blogs.msdn.microsoft.com/azurecat/2017/03/17/parallel-file-systems-for-hpc-storage-on-azure/
Parallel File Systems for HPC Storage on Azure
Architecture of the HPC
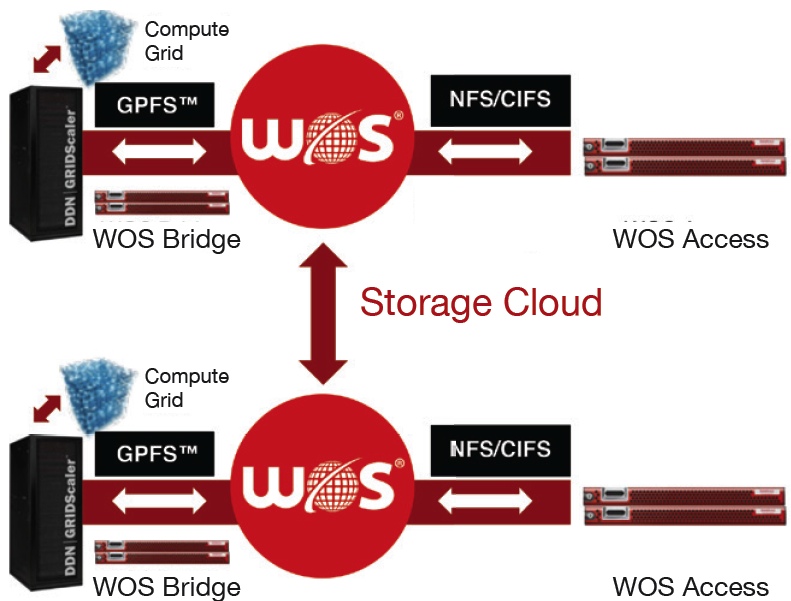
Federated Tiering Capability for DDN Lustre and GPFS Environments
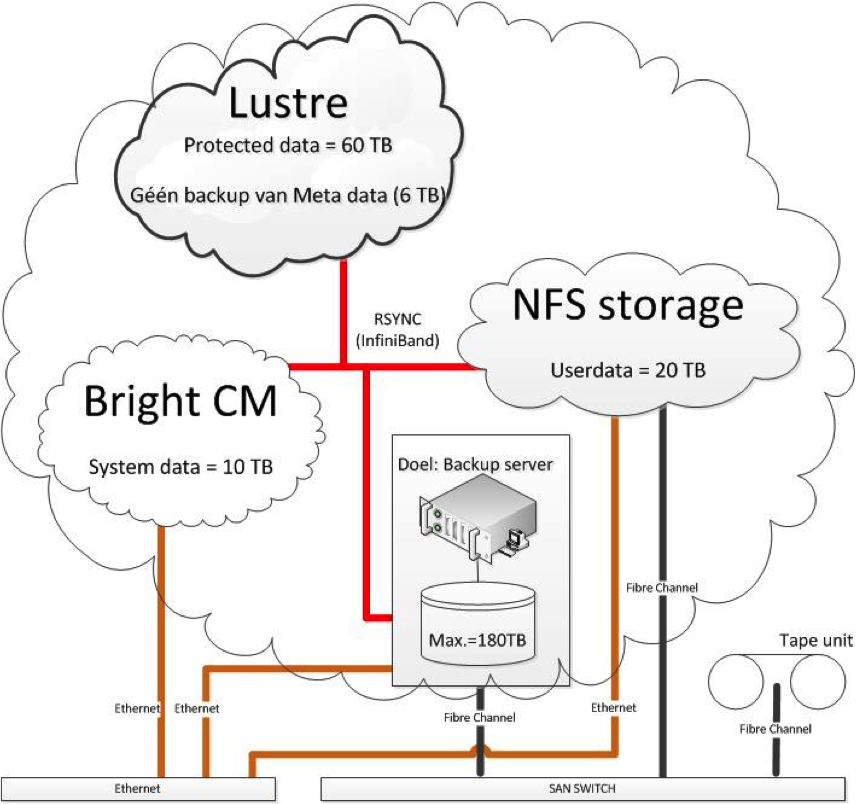
Schematic overview of storage components of the B4F cluster
- The goals for NFS were:
Share a local file system name space across the network.
Strengths and Weaknesses of the Two
NFS4 does most everything Lustre can with one very important exception, IO bandwidth.
http://wiki.lustre.org/NFS_vs._Lustre