- Secure by default
Secure By Default (SbD) is the concept of installing a minimal set of software in a secure configuration.
filesets are part of the SbD installation and contain all commands and files except for any applications that allow for the transmission of passwords over the network in clear text format such as telnet and ftp. In addition, applications that might be used, such as rsh, rcp, and sendmail, are excluded from the SbD filesets.
It is possible to have a securely configured system without using the SbD install option. For example, the AIX Security Expert High, Medium, or Low level security options can be configured on a regular installation.
The differences between an SbD-installed system and a regular installation with an AIX Security Expert High Level Security configuration is best illustrated by examining the telnet command. In both cases, the telnet command is disabled. In an SbD installation, the telnet binary or application is never even installed on the system.
https://www.ibm.com/docs/en/aix/7.1?topic=expert-secure-by-default
- Security by default, in software, means that the default configuration settings are the most secure settings possible, which are not necessarily the most user-friendly settings. In many cases, security and user-friendliness are evaluated based on both risk analysis and usability tests. This leads to the discussion of what the most secure settings are. As a result, the precise meaning of "secure by default" remains undefined.
In a network operating system, this typically means first and foremost that there are no listening INET(6) domain sockets after installation; that is, no open network ports. This can be checked on the local machine with a tool like netstat and remotely with a port scanner such as nmap. As a general rule, a secure network is only as secure as the least secure node in the entire network.
If a program uses secure configuration settings by default, the user will be better protected.[citation needed] However, not all users consider security[citation needed] and may be obstructed by secure settings. A common example is whether or not blank passwords are allowed for login. Not everyone can, or is willing to, type or memorize a password.[citation needed]
Another way to secure a program or system is through abstraction, where the user has presented an interface in which the user cannot (or is discouraged to) cause (accidental) data loss. This, however, can lead to less functionality or reduced flexibility.[citation needed] Having user control preferences does not typically cause this but at the cost of having a larger part of the user interface for configuration controls.
Some servers or devices that have an authentication system, have default usernames and passwords. If not properly changed, anyone who knows the default configuration can successfully authenticate. For non-unique defaults, this practice would violate the principle of 'security by default'.
OpenBSD claims to be the only operating system that is fully secure by default. This, however, does not mean it is inherently the most secure operating system. This is because that depends on the definition of an operating system. OpenBSD is a network operating system.
https://en.wikipedia.org/wiki/Secure_by_default
- Secure by design, in software engineering, means that software products and capabilities have been designed to be foundationally secure.
- Secure by Design
Secure by Design ensures that a product has been designed from the foundation with security
in mind. Manufacturers following a Secure by Design process are generally well aware of the
current threat landscape and are committed to developing products that are resistant, at the
point of manufacture, to such threats. Through life Secure by Design also requires an ongoing
vulnerability management programme that ensures vulnerabilities identified are mitigated in a
timely manner. This often includes a vulnerability disclosure process and the development and
distribution of software patches to correct the vulnerability
Secure by Default
Security by Default ensures that the default configuration settings of a product are the most
secure settings possible. It is important to appreciate that these will not necessarily be the most
user-friendly settings, and the balance between security and user friendliness often needs
consideration.
In putting together this guidance, consideration has been given to creating a set of minimum
requirements that will provide a baseline level of Secure by Default, whilst still balancing the
needs for a user-friendly experience for the installer and system integrator.
Secure by Default has an added benefit of removing the burden of knowledge away from the
installer or system integrator on how to lock a system down, providing them with an already
secure product.
https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/1014636/Secure_by_Default_Requirements_and_Guidance_FINAL.pdf
- What is Security by Design?
Legacy software, which was never developed to be secure, is the foundation on which modern, highly connected and business-critical software is operating. The difficulty of patching these older systems and integrating newer applications has served to make the problem worse. Building security in at the design phase reduces potential disruptions and avoids the much more difficult and expensive effort of attempting to add security to products after they have been developed and deployed.
Security by Design is a security assurance approach that enables customers to formalise security design, automate security controls and streamline auditing.
It is a systematic approach to ensure security; instead of relying on auditing security in a retrospective. Security by Design provides developers with the ability to build security control in throughout the development process. It begins with taking a more proactive approach to infrastructure security — one that does not rely on the typical protective or reactive third party security tools but builds security into your infrastructure from the ground up.
From requirements through design and implementation to testing and deployment, security must be integrated throughout the Software Development Lifecycle (SDLC) in order to provide the user community with the best, most secure software-based solutions.
Secure by Default applies the same principle to securing data at the source. It is referring to securing information. Secure by Default data makes the case that all data should have embedded security, and the systems that consume, process and store this data must adhere to the security policies embedded therein.
using the Security by Design and the Secure by Default model is critical. Think of it as a sort of domino effect. If an online retail company chooses a managed services provider to host their infrastructure and provide managed services, the design and security used to build and deliver the services are a critical consideration. If there are flaws of insecurity, the online retail company will get exposed to those security flaws, and so too will their customers, in turn—which will cause the business reputation to suffe
https://www.aeteurope.com/news/security-design-secure-default/





.jpg)
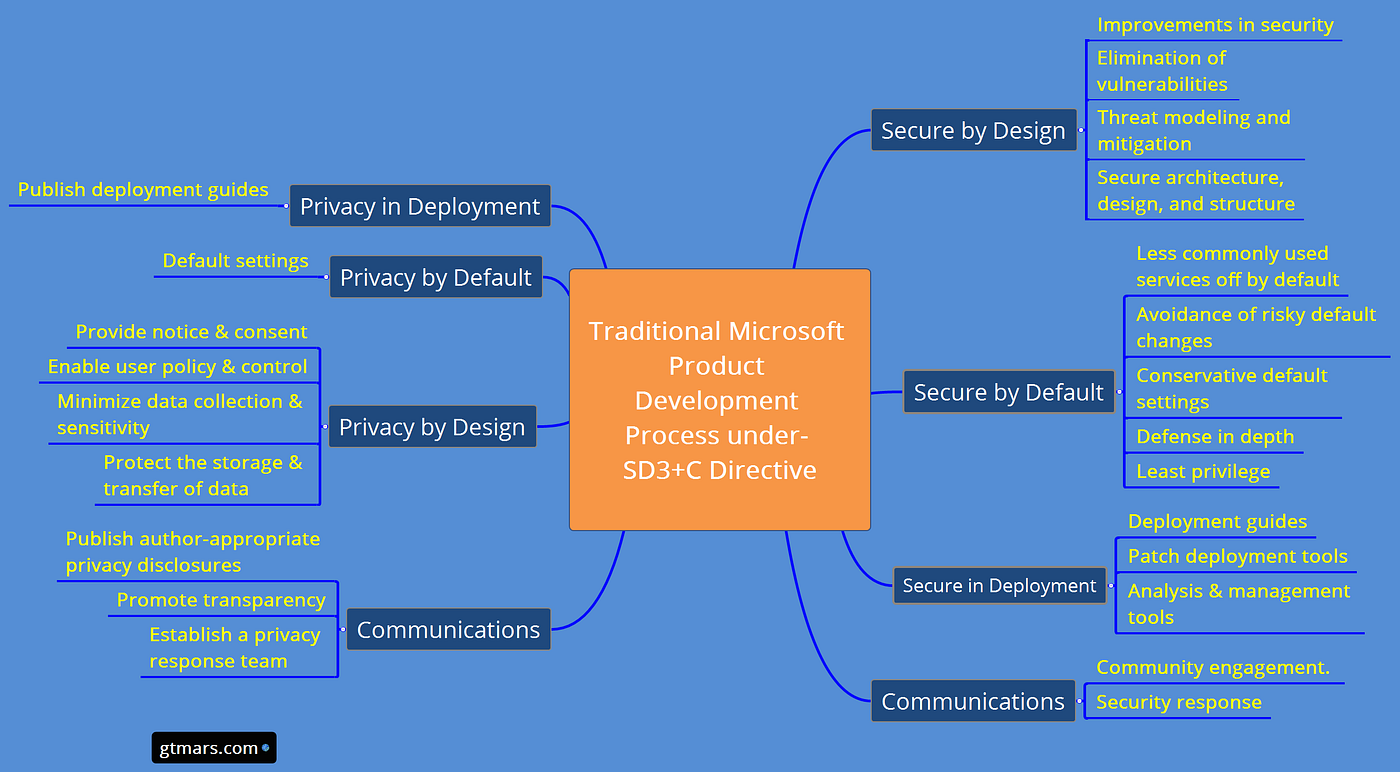
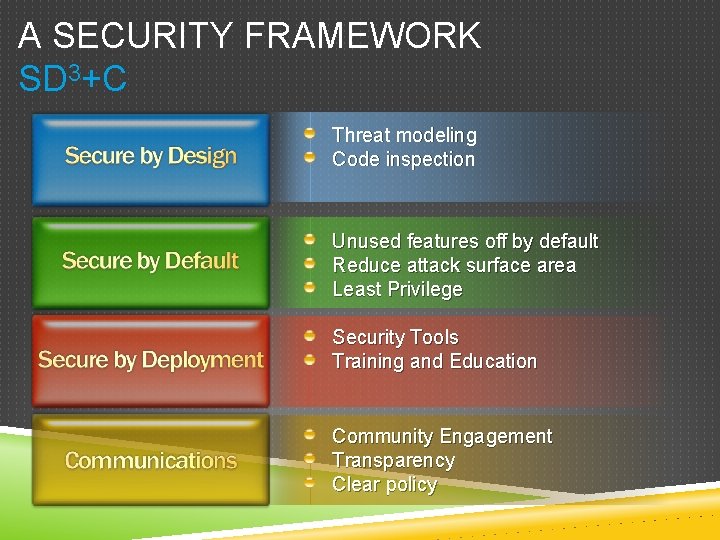
- "Secure by Design, Secure by Default, Secure in Deployment and Communication" (also known as SD3+C)
The goals of the Security Development Lifecycle (SDL), now embraced by Microsoft, are twofold: to reduce the number of security-related design and coding defects, and to reduce the severity of any defects that are left. This follows our oft-cited motto, "Secure by Design, Secure by Default, Secure in Deployment and Communication" (also known as SD3+C). SDL focuses mainly on the first two elements of this motto. Secure by Design means getting the design and code secure from the outset, and Secure by Default is a recognition that you never will. To be realistic, you never will get the code 100 percent correct, but more on this later when I discuss attack surface reduction.
https://docs.microsoft.com/en-us/archive/msdn-magazine/2005/november/a-look-inside-the-security-development-lifecycle-at-microsoft
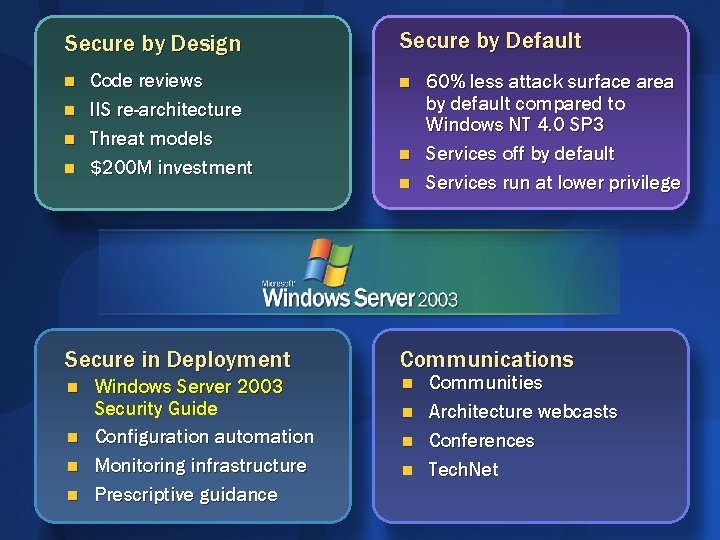
- SD3: Secure by Design, by Default, and in Deployment
Secure by Design
If a system is secure by design, it means you have taken appropriate steps to make sure the overall design of the product is sound from the outset.
The steps we recommend development groups take to achieve this include the following
Assign a go-to person for your security issues.This is the person who signs off on the product being secure.She is not a scapegoat, but someone who can sit in a meeting and say whether the product is secure enough to ship and, if it's not, what needs to be done to rectify the situation.
Require training for all personnel.
Make sure threat models are in place by the time the design phase is complete
Adhere to design and coding guidelines.
Fix all bugs that deviate from the guidelines as soon as possible.
Make sure the guidelines evolve. Security threats are not static; you should update the guidelines documents as you learn new vulnerabilities and learn new best practices for mitigating them.
Develop regression tests for all previously fixed vulnerabilities. This is an example of learning from past mistakes. When a security flaw is discovered, distill the attack code to its simplest form and go look for the other related bugs in other parts of your code.
Simplify the code, and simplify your security model.you should have plans in place to simplify old code by shedding unused and insecure features over time. Code tends to be more chaotic and harder to maintain over time, so the time spent removing old code and making things simpler rather than adding features and fixing bugs is time well spent from a security perspective. Code degeneration is often called code rot.
Perform penetration analysis before you ship. Have people try to break the application.Install test servers, and invite the team and external entities to break it. In fact, it may have a negative effect if not done properly by giving the development team a false sense of security. The same holds true for hack-fests where you invite external people to attack your systems. Typically, they are a waste of time unless you are testing for denial of service issues (because most people attempting to compromise the systems are not too bright and resort to flooding attacks).
Secure by Default
The goal of secure by default is to ship a product that is secure enough out of the box. Some ways to achieve this include these:
Do not install all features and capabilities by default. Apply only those features used by most of your users, and provide an easy mechanism to enable other features.
Allow least privilege in your application; don't require your code be used by members of the local or domain administrators group when it does not require such elevated capabilities(Running with Least Privilege ).
Apply appropriate protection for resources. Sensitive data and critical resources should be protected from attack.Determining Appropriate Access Control.
Secure in Deployment
Secure in deployment means the system is maintainable once your users install the product. You might create a very well-designed and written application, but if it's hard to deploy and administer, it might be hard to keep the application secure as new threats arise. To achieve the secure in deployment goal, you should follow a few simple guidelines:
Make sure the application offers a way to administer its security functionality. This includes the ability to know what level of patching the system is at.
Create good quality security patches as soon as feasible.
https://flylib.com/books/en/1.287.1.28/1/
- Bard: explain the difference between paradigms such as "Secure by design", "Secure by default", "Privacy by design"
Secure by design, secure by default, and privacy by design are all security paradigms that focus on building security into systems and products from the ground up. They differ in their focus and approach, but they all share the goal of making systems and products more secure.
Secure by design is a comprehensive approach to security that considers security throughout the entire product development lifecycle. It involves building security into the system architecture, design, implementation, and testing. Secure by design also includes a focus on risk management and continuous improvement.
Secure by default is a specific implementation of secure by design that focuses on ensuring that systems and products are secure by default. This means that they should be secure without any additional configuration or user intervention. Secure by default can be achieved through a variety of methods, such as using strong defaults, providing clear and concise security documentation, and making it easy for users to configure security settings.
Privacy by design is a security paradigm that focuses on protecting the privacy of individuals. It is based on the principle that privacy should be considered at every stage of the system development lifecycle. Privacy by design includes a focus on transparency, user control, and accountability.
The three paradigms are complementary and can be used together to create more secure and privacy-protective systems and products.
Here is a table that summarizes the key differences between the three paradigms:
| Paradigm | Focus | Approach |
|---|---|---|
| Secure by design | Security | Comprehensive, holistic approach |
| Secure by default | Security | Ensuring that systems are secure without any additional configuration or user intervention |
| Privacy by design | Privacy | Protecting the privacy of individuals |
It is important to note that these are just three of many security paradigms that exist. There is no single "best" security paradigm, and the best approach for a given system or product will vary depending on the specific risks and requirements. However, all three of these paradigms can be valuable tools for building more secure and privacy-protective systems and products
- Chat GPT:explain the difference between paradigms such as "Secure by design", "Secure by default", "Privacy by design"
The following are brief explanations of the differences between the paradigms of "Secure by design," "Secure by default," and "Privacy by design":
Secure by Design: "Secure by design" is a paradigm that emphasizes incorporating security measures and considerations throughout the entire design and development process of a system or software. It involves implementing security controls, features, and best practices from the very beginning of the design phase. By building security into the core architecture, the system is designed to be resilient against potential threats and vulnerabilities. The goal is to proactively address security requirements, risk assessments, and potential attack vectors, resulting in a more robust and secure product.
Secure by Default: "Secure by default" refers to the principle of configuring systems, software, or devices with secure settings as the default configuration. It means that when a user deploys or installs a product, it is already preconfigured with the highest security settings, minimizing the need for manual adjustments. By implementing secure defaults, users are protected from common security risks, such as using weak passwords or leaving unnecessary ports open. The aim is to ensure that users are immediately protected without requiring additional steps or modifications.
Privacy by Design: "Privacy by design" is a principle that focuses on embedding privacy considerations into the design and development of systems, products, or services. It involves proactively considering privacy implications and incorporating privacy-enhancing features from the outset. Privacy by design aims to protect individuals' personal information and provide transparency and control over how their data is collected, stored, and processed. It involves practices such as minimizing data collection, implementing strong security measures, obtaining informed consent, and enabling user-centric privacy settings.
While there may be overlapping elements among these paradigms, they each address different aspects of security and privacy. "Secure by design" emphasizes building security into the core of the system, "Secure by default" focuses on preconfiguring systems with secure settings, and "Privacy by design" centers around embedding privacy considerations into the design and development process. Adopting these paradigms collectively can lead to more secure and privacy-conscious systems and software.
Bing:explain the difference between paradigms such as "Secure by design", "Secure by default", "Privacy by design"
“Secure by design” is a security paradigm that emphasizes the importance of designing systems with security in mind from the beginning. This means that security is integrated into every aspect of the system’s design, rather than being added as an afterthought. “Secure by default” is another security paradigm that emphasizes the importance of having secure settings as the default configuration for systems and applications. This means that users don’t have to take any additional steps to secure their systems or applications beyond what is already provided by default. “Privacy by design” is a related paradigm that emphasizes the importance of designing systems with privacy in mind from the beginning. This means that privacy is integrated into every aspect of the system’s design, rather than being added as an afterthought1





 Bard:How does designing the API around the database schema differ from designing it based on the principles of REST? What are the advantages and disadvantages of each approach?
Bard:How does designing the API around the database schema differ from designing it based on the principles of REST? What are the advantages and disadvantages of each approach?