- ChatGPT
Key Concepts of a Data Lake
1. Storage of Raw Data
Raw Data: Data lakes store data in its raw form, without the need for pre-processing or transformation before storage. This can include structured data (like relational databases), semi-structured data (like JSON or XML), and unstructured data (like text documents, images, or videos).
Flexibility: Unlike traditional databases or data warehouses, data lakes do not enforce a schema-on-write, meaning that data is stored as-is and schema is applied when the data is read (schema-on-read).
2. Scalability
- Big Data Handling: Data lakes are designed to handle large volumes of data, scaling horizontally by adding more servers or storage as needed. This makes them suitable for big data applications and scenarios where data volume grows rapidly.
3. Storage Cost Efficiency
- Cost-Effective Storage: Storing large amounts of data in a data lake is often more cost-effective compared to traditional databases or data warehouses, especially when using cloud-based solutions.
4. Data Accessibility
- Centralized Repository: Data lakes act as a central repository where all data, regardless of type or source, can be stored and accessed. This provides a single source of truth for data analysis and business intelligence.
5. Advanced Analytics and Machine Learning
Data Exploration: Analysts and data scientists can explore and analyze data from a data lake using various tools, including SQL queries, machine learning algorithms, and big data processing frameworks.
Integration with Analytical Tools: Data lakes integrate with data processing and analytics tools like Apache Hadoop, Apache Spark, and other big data frameworks, enabling complex data processing and advanced analytics.
Components of a Data Lake
Data Ingestion:
- Mechanisms for collecting and importing data from various sources into the data lake. This can include batch processing, real-time streaming, and data integration tools.
Data Storage:
- Storage infrastructure that can handle different types of data formats and volumes. In cloud environments, services like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage are commonly used.
Data Management:
- Tools and frameworks for organizing, cataloging, and managing the data stored in the lake. This includes metadata management, data governance, and data quality tools.
Data Processing:
- Technologies and frameworks for processing and analyzing the data. This can include data transformation, ETL (Extract, Transform, Load) processes, and big data processing engines.
Data Access and Security:
- Mechanisms to ensure secure access to the data, including authentication, authorization, and encryption. Data lakes implement policies and controls to protect sensitive information and manage user access.
Advantages of a Data Lake
- Flexibility: Can store diverse data types and formats, allowing organizations to adapt to changing data needs and use cases.
- Scalability: Easily scalable to accommodate growing data volumes and processing requirements.
- Cost Efficiency: Typically more cost-effective for large-scale data storage compared to traditional databases.
- Advanced Analytics: Supports advanced analytics and machine learning by providing access to large volumes of raw data.
Challenges of a Data Lake
- Data Quality and Governance: Managing and ensuring the quality of data can be challenging due to the volume and diversity of data stored.
- Complexity: Requires robust data management and processing frameworks to effectively handle and analyze the data.
- Security: Ensuring data security and compliance can be complex given the wide range of data types and sources.
Summary
A data lake is a powerful tool for organizations to store and manage large volumes of raw data from various sources. It provides the flexibility to handle diverse data types, supports scalability and advanced analytics, and offers cost-effective storage solutions. However, managing data quality, governance, and security remains essential to leveraging the full potential of a data lake.
- What is a data lake?
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data. It can store data in its native format and process any variety of it, ignoring size limits.
A data lake provides a scalable and secure platform that allows enterprises to: ingest any data from any system at any speed—even if the data comes from on-premises, cloud, or edge-computing systems; store any type or volume of data in full fidelity; process data in real time or batch mode; and analyze data using SQL, Python, R, or any other language, third-party data, or analytics application.
https://cloud.google.com/learn/what-is-a-data-lake#:~:text=A%20data%20lake%20is%20a,of%20it%2C%20ignoring%20size%20limits.


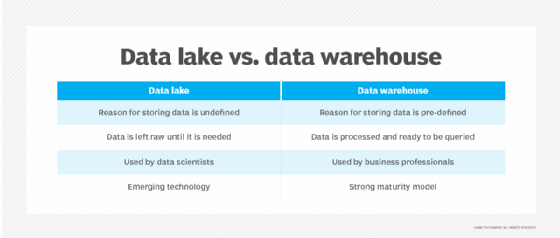
- Four key differences between a data lake and a data warehouse
Data Lake Data Warehouse
Data Structure Raw Processed
Purpose of Data Not yet determined Currently in use
Users Data scientists Business professionals
Accessibility Highly accessible and quick to update More complicated and costly to make changes
Organizations often need both. Data lakes were born out of the need to harness big data and benefit from the raw, granular structured and unstructured data for machine learning, but there is still a need to create data warehouses for analytics use by business users
https://www.talend.com/resources/data-lake-vs-data-warehouse/#:~:text=Data%20lakes%20and%20data%20warehouses,processed%20for%20a%20specific%20purpose.