- For the purposes of this chapter, we’ll define toil as the repetitive, predictable, constant stream of tasks related to maintaining a service.
System maintenance inevitably demands a certain amount of rollouts, upgrades, restarts, alert triaging, and so forth. These activities can quickly consume a team if left unchecked and unaccounted for. Google limits the time SRE teams spend on operational work (including both toil- and non-toil-intensive work) at 50%
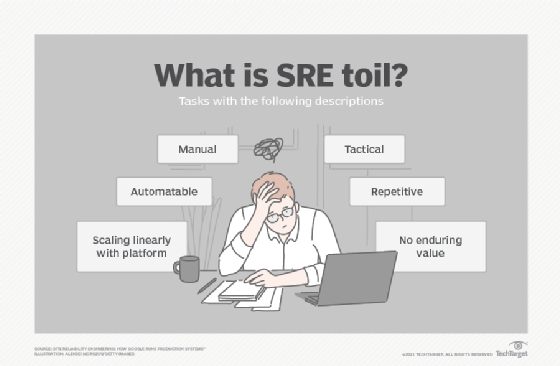
What Is Toil?
Here, we provide a concrete example for each toil characteristic:
Manual
When the tmp directory on a web server reaches 95% utilization, engineer Anne logs in to the server and scours the filesystem for extraneous log files to delete.
Repetitive
A full tmp directory is unlikely to be a one-time event, so the task of fixing it is repetitive.
Automatable
If your team has remediation documents with content like “log in to X, execute this command, check the output, restart Y if you see…,” these instructions are essentially pseudocode to someone with software development skills! In the tmp directory example, the solution has been partially automated. It would be even better to fully automate the problem detection and remediation by not requiring a human to run the script. Better still, submit a patch so that the software no longer breaks in this way.
Nontactical/reactive
When you receive too many alerts along the lines of “disk full” and “server down,” they distract engineers from higher-value engineering and potentially mask other, higher-severity alerts. As a result, the health of the service suffers.
Lacks enduring value
Completing a task often brings a satisfying sense of accomplishment, but this repetitive satisfaction isn’t a positive in the long run. For example, closing that alert-generated ticket ensured that the user queries continued to flow and HTTP requests continued to serve with status codes < 400, which is good. However, resolving the ticket today won’t prevent the issue in the future, so the payback has a short duration.
Grows at least as fast as its source
Many classes of operational work grow as fast as (or faster than) the size of the underlying infrastructure. For example, you can expect time spent performing hardware repairs to increase in lock-step fashion with the size of a server fleet. Physical repair work may unavoidably scale with the number of machines, but ancillary tasks (for example, making software/configuration changes) doesn’t necessarily have to.
Case Study 1: Reducing Toil in the Datacenter with Automation
Case Study 2: Decommissioning Filer-Backed Home Directories
Conclusion
At minimum, the amount of toil associated with running a production service grows linearly with its complexity and scale.
Automation is often the gold standard of toil elimination, and can be combined with a number of other tactics. Even when toil isn’t worth the effort of full automation, you can decrease engineering and operations workloads through strategies like partial automation or changing business processes.
https://sre.google/workbook/eliminating-toil/

- Prior to Google’s creation of the SRE position, System Administrators ran company operations.
System Administrators worked on the “operations” side of things, whereas engineers worked on the “development” side of things.
Now let’s say that one
“You will automate the server provisioning process to reduce the labor of our networking engineering and
“SREs are Software Engineers who specialize in reliability. SREs apply the principles of computer science and engineering to the design and development of computer systems:
By eliminating human interaction through automation, SREs make systems more reliable
https://hackernoon.com/so-you-want-to-be-an-sre-34e832357a8c
- Site Reliability Engineering
This systems administrator, or
As the system grows in complexity and traffic volume, generating a corresponding increase in events and updates, the
The
The
Direct costs are neither subtle nor ambiguous. Running a service with a team that relies on manual intervention for both change management and event handling becomes expensive as the service and/or traffic to the service grows, because the size of the team
The indirect costs of the development/ops split can be subtle, but are often more expensive to the organization than the direct costs. These costs arise from the fact that the two teams are
Traditional operations teams and their counterparts in product development thus often end up in conflict, most visibly over how quickly software can
("We want to launch anything,
The ops team attempts to safeguard the running system against the risk of change by introducing launch and change gates
The dev team quickly learns how to respond. They have fewer "launches" and more "flag flips," "incremental updates," or "
our Site Reliability Engineering teams focus on hiring software engineers to run our products and to create systems to accomplish the work that would otherwise
What exactly is Site Reliability Engineering, as it
As a whole, SREs can
50–60% are Google Software Engineers, or more precisely, people who have
Therefore, SRE is
Eventually, a traditional
we want systems that are automatic, not just automated.
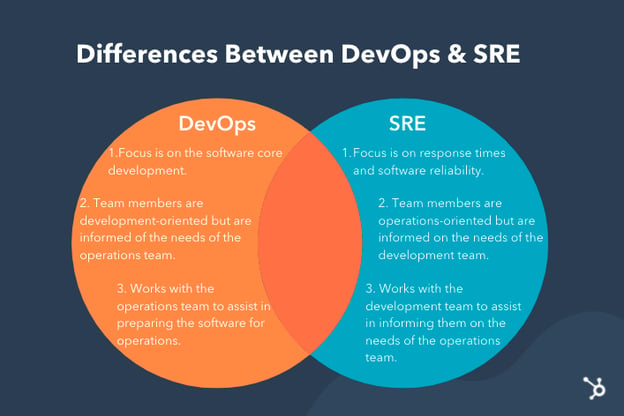
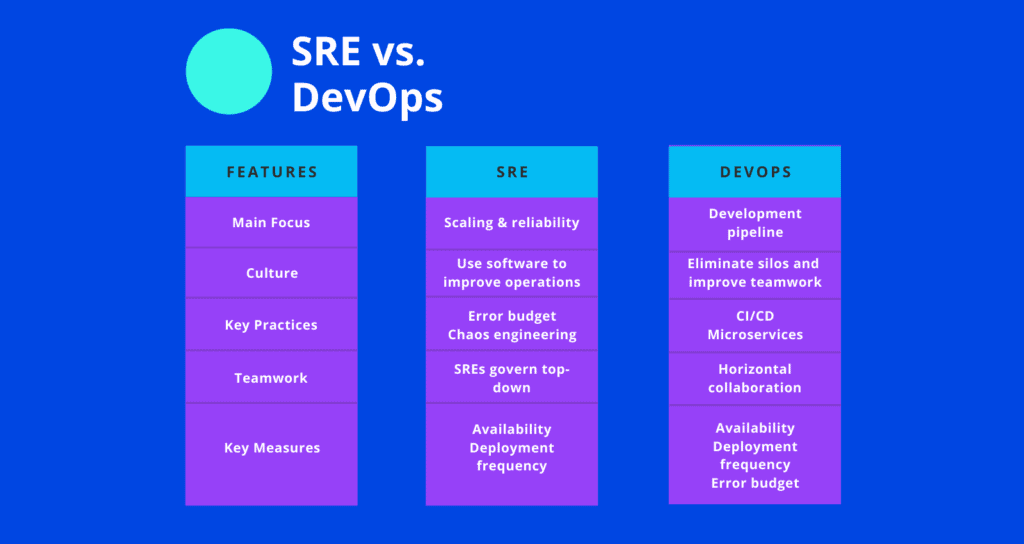
DevOps or SRE?
Its core principles—involvement of the IT function in each phase of a system’s design and development, heavy reliance on automation versus human effort, the application of engineering practices and tools to operations tasks—are consistent with many of SRE’s principles and practices
One could view DevOps as a generalization of
https://landing.google.com/sre/book.html
- while R&D focused on creating new features and pushing them to production, the Operations group was trying to keep production as stable as possible—the two teams were pulling in opposite directions.
Instead of having an Ops team built solely from system administrators, software engineers—with an R&D background and mentality—could enrich the way the team worked with the development group, change its goals and help with automating solutions.
According to Google, SRE engineers are responsible for the stability of the production environment, but
Google decided
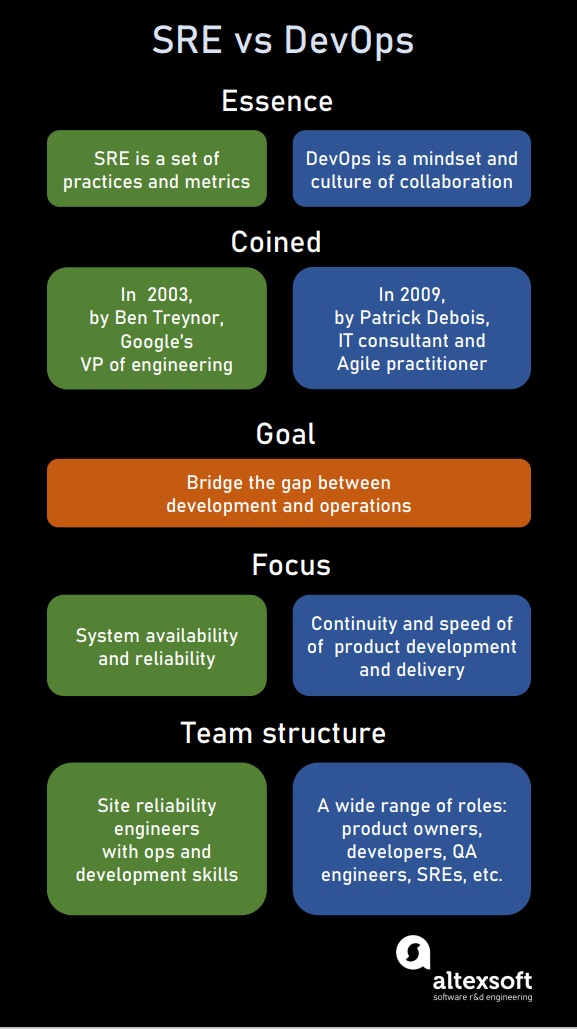
Both SRE and DevOps are methodologies addressing organizations’ needs for production operation management
While DevOps raise problems and dispatch them to Dev to solve, the SRE approach is to find problems and solve some of them themselves.
While DevOps teams would usually choose the more conservative approach, leaving the production environment untouched unless
For each service, the SRE team sets a service-level agreement (SLA) that defines how reliable the system needs to be to end users.
For each service, the SRE team sets a service-level agreement (SLA) that defines how reliable the system needs to be to end users. If the team agrees on a 99.9 percent SLA, that gives them an error budget of 0.1 percent. An error budget is exactly what the name suggests: the maximum allowable threshold for errors and outages. Here’s the interesting thing: the development team can “spend” this error budget in any way they like. If the product is
To
https://devops.com/sre-vs-devops-false-distinction/
- The DevOps movement began because developers would write code with little understanding of how it would run in production. They would throw this code over the proverbial wall to the operations team, which would
be responsible for keeping the applications up and running. This often resulted in tension between the two groups, as each group's prioritieswere misaligned with the needs of the business
DevOps emerged as a culture and a set of practices that aims to reduce the gaps between software development and software operation. However, the DevOps movement does not explicitly define how to succeed in these areas
SRE
If you think of DevOps like an interface in a programming language, class SRE implements DevOps.
DevOps and SRE are not two competing methods for software development and operations, but
SLIs, SLOs and SLAs tie back closely to the DevOps pillar of "measure everything" and one
https://cloudplatform.googleblog.com/2018/05/SRE-vs-DevOps-competing-standards-or-close-friends.html
- an SDET should have at least the following skills and attributes:
Has a tester mindset, is curious and can come up with interesting test scenarios
Has a solid understanding of testing principles and methodologies
Knows that all testing is exploratory
Can apply appropriate test methods for a
knows the difference between testing and QA
Can code in at least one scripting or programming language (Java and Javascript
Understands HTTP and
Can write UI
Knows Git, Pull Requests, Branching, etc…
Is agile
Can write performance test scripts (Gatling and/or
Thinks about security and
Understands CI/CD and Build pipelines
Knows the services offered by cloud platform providers such as AWS, Azure and Google Cloud
https://www.testingexcellence.com/sdet-hiring-software-developers-in-test/
- Site reliability engineers will spend up to 50% of their time doing "ops" related work such as handling issues, integrating services, building up CI/CD flows. Since the software system that an SRE is working with is expected to be highly automatic and self-healing, the SRE should spend the other 50% of their time on development tasks like adding new features, such as autoscaling or doing automation.
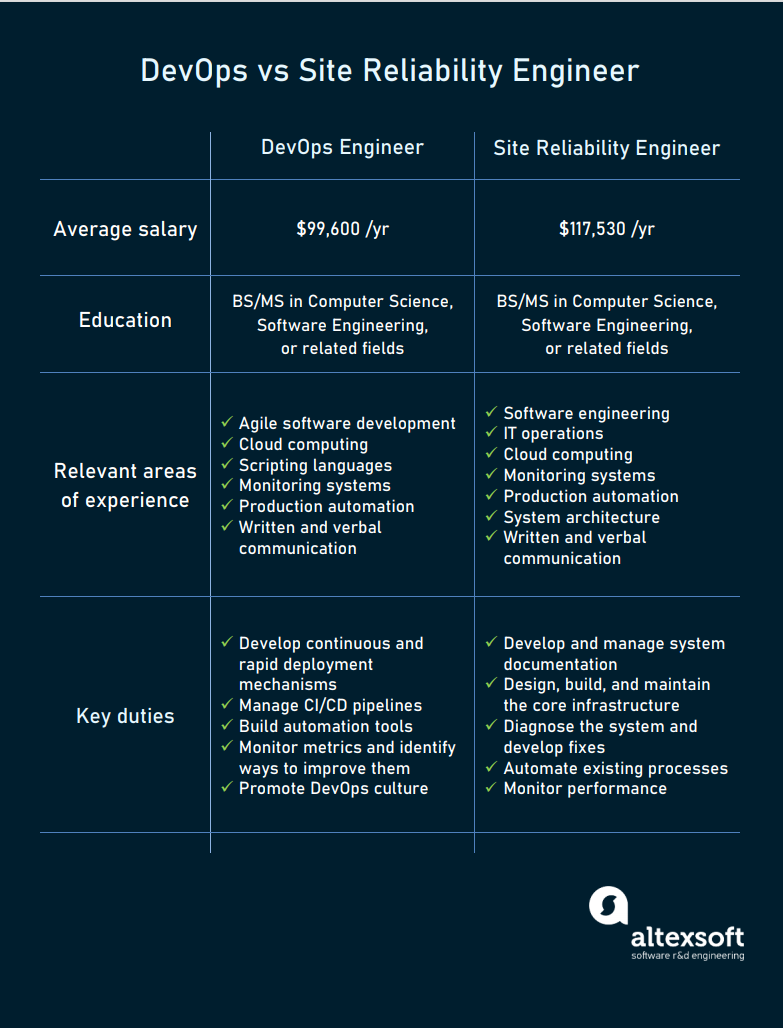
A site reliability engineer is usually either a software engineer with a good integration knowledge and troubleshooting approach or a skilled system administrator with knowledge of coding and automation.
https://www.impressiongroup.biz/site-reliability-engineer

- What Problems Do SREs Solve?
Site Reliability Engineering teams focus on safety, health, uptime, and the ability to remedy unforeseen problems
during an incident, helping devise remedies for problems until the engineering teams can make proper remediation
combating incidents, and SREs spend a good deal of time making sure the firefight doesn’t occur with their vast expertise.
By removing some of the complex burdens in how to scale and maintain uptime in distributed systems, SRE practices allow development teams to focus on feature development instead of the nuances of achieving and maintaining service level commitments.
SLAs, SLOs, and SLIs
Both DevOps and SRE teams value metrics, as you can’t improve on what you can’t measure. Indicators and measurements of how well a system is performing can be represented by one of the Service Level (SLx) commitments. There is a trio of metrics, SLAs, SLOs, and SLIs, that paint a picture of the agreement made vs the objectives and actuals to meet the agreement. With SLOs and SLIs, you can garner insight into the health of a system.
SLAs
Service Level Agreements are the commitment/agreement you make with your customers. Your customers might be internal, external, or another system. SLAs are usually crafted around customer expectations or system expectations. SLAs have been around for some time, and most engineers would consider an SLA to be “we need to reply in 2000ms or less,” which in today’s nomenclature would actually be an SLO. An SLA, in that case, would be “we require 99% uptime.”
SLOs
Service Level Objectives are goals that need to be met in order to meet SLAs. Looking at Tom Wilkie’s RED method can help you come up with good metrics for SLOs: requests, errors, and duration. In the above example of “we need to reply in 2000ms or less 99% of the time,” that would fall under duration, or the amount of time it takes to complete a request in your system. Google’s Four Golden Signals are also great metrics to have as SLOs, but also includes saturation. Measuring SLOs is the purpose of SLIs.
SLIs
Service Level Indicators measure compliance/conformance with an SLO. Harping on the “we need to reply in 2000ms or less 99% of the time” SLO from above, the SLI would be the actual measurement. Maybe 98% of requests have a reply in less than 2000ms, which is not up to the goal of the SLO. If SLOs/SLIs are being broken, time should be spent to remedy/fix issues related to the slowdowns.
https://harness.io/blog/sre-vs-devops#:~:text=In%20a%20nutshell%2C%20DevOps%20Engineers,operational%2Fscale%2Freliability%20problems.
- SLA vs. SLO vs. SLI: What’s the difference?
SLAs, SLOs, and SLIs—three initialisms that represent
the promises we make to our users,
the internal objectives that help us keep those promises,
and the trackable measurements that tell us how we’re doing.
The goal of all three things is to get everybody—vendor and client alike—on the same page about system performance
How often will your systems be available?
How quickly will your team respond if the system goes down?
What kind of promises are you making about speed and functionality?
https://www.atlassian.com/incident-management/kpis/sla-vs-slo-vs-sli
Telemetry is the in situ collection of measurements or other data at remote points and their automatic transmission to receiving equipment (telecommunication) for monitoring
Although the term commonly refers to wireless data transfer mechanisms (e.g., using radio, ultrasonic, or infrared systems), it also encompasses data transferred over other media such as a telephone or computer network, optical link or other wired communications like power line carriers. Many modern telemetry systems take advantage of the low cost and ubiquity of GSM networks by using SMS to receive and transmit telemetry data.
A telemeter is a physical device used in telemetry. It consists of a sensor, a transmission path, and a display, recording, or control device. Electronic devices are widely used in telemetry and can be wireless or hard-wired, analog or digital. Other technologies are also possible, such as mechanical, hydraulic and optical
Telemetry may be commutated to allow the transmission of multiple data streams in a fixed frame.
https://en.wikipedia.org/wiki/Telemetry
Incredible! This blog looks exactly like my old one! It's on a totally different subject but it has pretty much the same page layout and design. Excellent choice of colors!
ReplyDeleteWhat i do not realize is in fact how you are no longer really a lot more neatly-preferred than you may be right now. You're so intelligent. You realize thus significantly in the case of this subject, produced me in my view believe it from numerous numerous angles. Its like women and men are not interested unless it is one thing to accomplish with Girl gaga! Your own stuffs outstanding. At all times deal with it up!
ReplyDelete