- IBM, Google and Lyft give
microservices Istio
Its design, however, is not platform specific. The Istio CloudFoundry
Key Istio
Automatic zone-aware load balancing and failover for HTTP/1.1, HTTP/2, gRPC
Fine-grained control of traffic behavior with rich routing rules, fault tolerance, and fault injection.
A pluggable policy layer and configuration API supporting access controls, rate limits and quotas.
Automatic metrics, logs and traces for all traffic within a cluster, including cluster ingress and egress.
Secure service-to-service authentication with strong identity assertions between services in a cluster.
How does Istio
Improved visibility into the data flowing in and out of apps, without requiring extensive configuration and reprogramming.
https://developer.ibm.com/dwblog/2017/istio/

Istio
a platform, including APIs that let it integrate into any logging platform, or telemetry or policy system.
lets you successfully, and efficiently run a distributed micro-service architecture, and provides a uniform way to secure, connect, and monitor micro-services.
operators are managing
Developers must use micro-services to
What is a service mesh?
Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring.
A service mesh also often has more complex operational requirements, like A/B testing, canary releases, rate limiting, access control, and end-to-end authentication.
Why use
create a network of deployed services with load balancing, service-to-service authentication, monitoring,
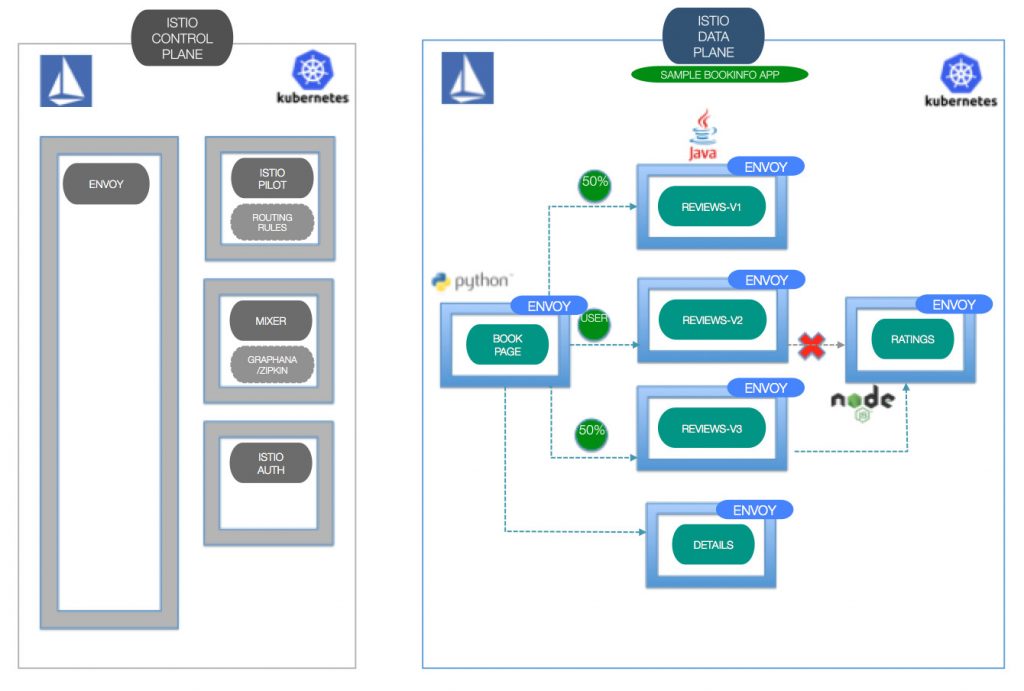
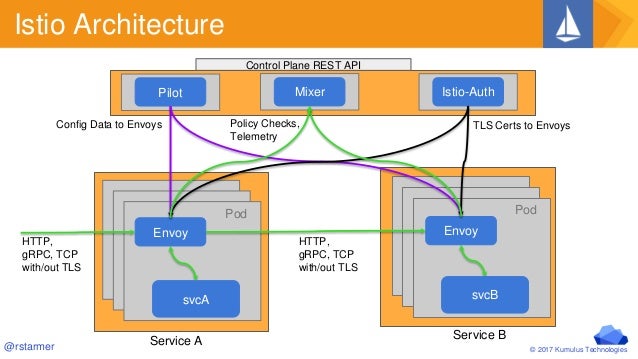
add Istio support to services by deploying a special sidecar proxy throughout your environment that intercepts all network communication between micro-services, then configure and manage Istio using its control plane functionality
Automatic load balancing for HTTP,
Fine-grained control of traffic behavior with rich routing rules, retries,
Automatic metrics, logs, and traces for all traffic within a cluster, including cluster ingress and egress.
Secure service-to-service communication in a cluster with a strong identity-based authentication and authorization
Core features
Traffic management
control the flow of traffic and API calls between services
configuration of service-level properties like circuit breakers, timeouts, and retries
tasks like A/B testing, canary rollouts, and staged rollouts with percentage-based traffic splits
Platform support
You can deploy
Service deployment on
Services registered with Consul
Services running on individual virtual machines
Architecture
An
The control plane manages and configures the proxies to route traffic.
https://istio.io/docs/concepts/what-is-istio/
- What is a service mesh?
Why use Istio
Automatic load balancing for HTTP, gRPC WebSocket
Fine-grained control of traffic behavior with rich routing rules, retries, failovers
A pluggable policy layer and configuration API supporting access controls, rate limits and quotas.
Automatic metrics, logs, and traces for all traffic within a cluster, including cluster ingress and egress.
Secure service-to-service communication in a cluster with strong
Security
https://istio.io/docs/concepts/what-is-istio/


- Integrating Calico and
Istio Kubernetes - What’s a service mesh? And why do I need one?
External and internal threats exist on the network at all times.
Network locality is not sufficient for gaining
Every device, user, and workflow should be authenticated
Network policies must be dynamic and calculated
How can Calico and Istio
Calico is an open-source project designed to remove the complexities surrounding traditional software-defined networks and securing them through simple policy language in YAML. Calico is compatible with major cloud platforms, such as Kubernetes
Calico’s implementation of the Kubernetes Network Policy API enables granular selection and grouping. Policies are configured
https://www.altoros.com/blog/integrating-calico-and-istio-to-secure-zero-trust-networks-on-kubernetes/
A service mesh is a dedicated infrastructure layer for making service-to-service communication safe, fast, and reliable. If you’re building a cloud native application, you need a service mesh. In practice, the is typically implemented are deployed
WHAT IS A SERVICE MESH?
IS THE SERVICE MESH A NETWORKING MODEL?
The service mesh is a networking model that sits at a layer of abstraction above TCP/IP. It assumes that the underlying L3/L4 network is present and capable of delivering bytes from point to point
Just as the TCP stack abstracts the mechanics of reliably delivering bytes between network endpoints, the service mesh abstracts the mechanics of reliably delivering requests between services.
Like TCP, the service mesh doesn’t care about the actual payload or how it’s encoded.
The application has a high-level goal (“
WHAT DOES A SERVICE MESH ACTUALLY DO?
A service mesh like Linkerd a wide “
WHY IS THE SERVICE MESH NECESSARY?
Consider the typical architecture of a medium-sized web application in the 2000’s . complex, is limited , after all
When this architectural approach was pushed very
Companies like Google, Netflix, and Twitter, faced with massive traffic requirements
In these systems, a generalized communication layer became suddenly relevant, but typically took the form of a “fat client” library—Twitter’s Finagle, Netflix’s Hystrix
The cloud native model combines the microservices Kubernetes
THE FUTURE OF THE SERVICE MESH
The requirements for serverless linking,
https://blog.buoyant.io/2017/04/25/whats-a-service-mesh-and-why-do-i-need-one
How isIstio
Istio necessary
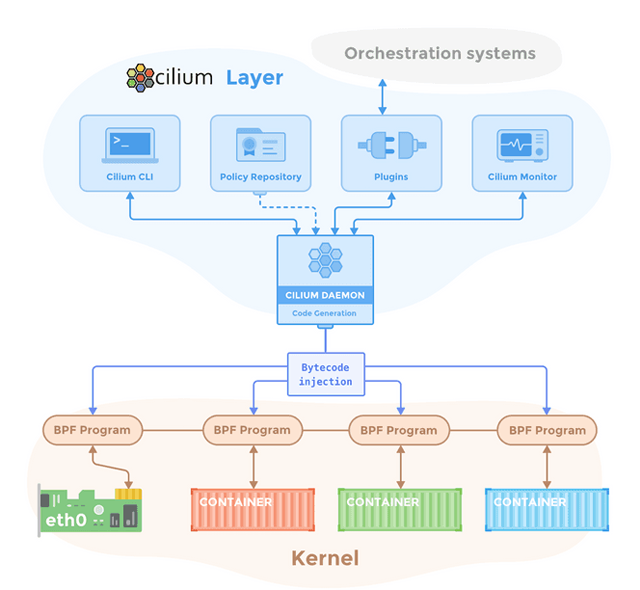
What is Cilium?
Cilium comes in the form of a networking plugin and thus integrates at a lower level with the orchestration system. Cilium andIstio gRPC
Cilium uses a combination of components to provide this functionality:
An agent written ingolang This agent is integrated Kubernetes
Adatapath utilizes Berkley Packet Filter very efficient networking, policy enforcement, and load balancing functionality.
A set ofuserspace
Can I run Cilium alongsideIstio
It is perfectly fine to run Cilium as a CNI plugin to provide networking, security, andloadbalancing Istio
How willIstio benefit from
We are very excited about BPF and how it is changing how security and networkingare done
Why is the In-kernel proxy faster than not running a proxy at all?
When changing how to approach a problem.Completely new is capable of having
The difference in the two lines between "No Proxy" and "Cilium In-Kernel" is thus the cost of the TCP/IP stack in the Linux kernel.
How else canIstio benefit from
Use of Istio Auth and the concept of identities to enforce the existing Cilium identity concept. This would allow enforcing existingNetworkPolicy
Ability to export telemetry from Cilium toIstio
Potential to offloadIstio
https://cilium.io/blog/istio/




load basically
Traditionally you may have had two almost identical servers: one that goes to all users and another with the new features that gets rolled out to only a set of users.
by usingGitOps your canary can be fully controlled
If something goes wrong and you need to roll back, you can redeploy a stable version all from Git.
AnIstio
With both a GA and a canary deployed, you can continue to iterate on the canary release until it meets expectations and youare able to
GitOps Istio
An engineer fixes the latency issue and cuts a new release by tagging the master branch as 0.2.1
GitHub notifies GCP Container Builder thata new tag has been committed
GCP Container Builder builds the Docker image, tags it as 0.2.1 and pushes it to to Quay.
Weave Cloud detects the new tag and updates the Canary deployment definition
Weave Cloud commits the Canary deployment definition to GitHub in the cluster repo
Weave Cloud triggers a rolling update of the Canary deployment
Weave Cloud sends a Slack notification that the 0.2.1 patch hasbeen released
Once the Canaryis fixed modifying
With each Git push and manifest modification, Weave Cloud detects that the cluster state is out of sync withdesired
If you notice that the Canary doesn't behave well under load, revert the changes in Git.
You can keep iterating on the canary code until the SLA is on a par with the GA release.
https://www.weave.works/blog/gitops-workflows-for-istio-canary-deployments
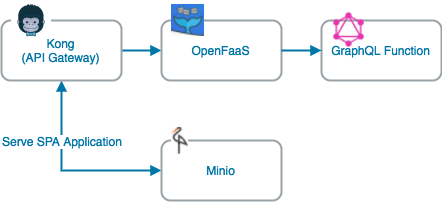
Invokeserverless
Kong is a scalable, open source API Layer (also known as an API Gateway, or API Middleware). Kong runs in front of any RESTful API andis extended
https://konghq.com/kong-community-edition/
Containers are an executable unit of software in whichapplication code is packaged that be run
To do this, containers take advantage of a form of operating system (OS) virtualization in which features of the OS (in the case of namespaces cgroups are leveraged disk
Containers are small, fast, and portable because unlike a virtual machine, containers do notneed , simply
Containers vs. VMs
Instead of virtualizing the underlying hardware, containers virtualize the operating system (typically Linux) so each individual container contains only the application and its libraries and dependencies. The absence of the guest OS is why containers are so lightweight and, thus, fast and portable.
Benefits
Lightweight: Containers share the machine OS kernel, eliminating the need for a full OS instance per application and making container files small and easy on resources.
Portable and platform independent: Containers carry all their dependencies with them, meaning that software canbe written without needing be re
Supports modern development and architecture: such as DevOps,serverless microservices are built
Containerization
Software needs tobe designed in order . be run
Container orchestration
container orchestration emerged as away lifecycle
Provisioning
Redundancy
Health monitoring
Resource allocation
Scaling and load balancing
Moving between physical hosts
While many container orchestration platforms (such as ApacheMesos were created to help Kubernetes the majority
Docker andKubernetes
Kubernetes
Docker turns program source code into containers and then executes them, whereasKubernetes
Istio Knative
the ecosystem of tools and projects designed to harden and expand production use cases continues to grow
Istio
As developers leverage containers to build and runmicroservice lifecycle the way that Istio was created to make traffic,
Knative
Knative serverless
Instead of running all the time and responding when needed (as a server does), aserverless is called
https://www.ibm.com/cloud/learn/containers
AWS Lambda is acompute
You can also buildserverless that are triggered by events CodePipeline CodeBuild
https://docs.aws.amazon.com/lambda/latest/dg
With Lambda, you can run code for virtually anytype of to automatically trigger
https://aws.amazon.com/lambda/
Data Engineers and Data Scientists often use tools from the python ecosystem such asNumpy which are designed to be high performance, intuitive and efficient libraries. Performing such operations on a small dataset in a fast and scalable manner is not challenging as long as the dataset can fit into the memory of a single machine. However, if the dataset is too big and cannot fit into a single machine, Data Engineers may be forced SparkML that can be computationally supported by a big EMR cluster
https://towardsdatascience.com/serverless-distributed-data-pre-processing-using-dask-amazon-ecs-and-python-part-1-a6108c728cc4
Utility computing, or The Computer Utility, is a service provisioning model in which a service provider makes computing resources and infrastructure management available to the customer as needed, and charges them forspecific
The name "serverless is used because the server management and capacity planning decisions are completely hidden serverless in conjunction microservices be written serverless
Most, but not all, serverless FaaS
Serverless is not suited be required given
https://en.wikipedia.org/wiki/Serverless_computing
Serverless serverless all the server management is done by AWS serverless serverless
https://aws.amazon.com/lambda/faqs/
Write short-lived functions in any language, and map them to HTTP requests (or other event triggers). Deploy functions instantly with one command. There are no containers to build, and no Docker registries to manage.
https://fission.io/
Web apps,Backends
In other words,serverless applications to be developed without concerns for implementing, tweaking, or scaling a server (at least, to the perspective of a user).
Instead of scaling a monolithic REST server to handle potential load, you can now split the server into a bunch of functions which canbe scaled
https://medium.com/@BoweiHan/an-introduction-to-serverless-and-faas-functions-as
https://github.com/openfaas/faas






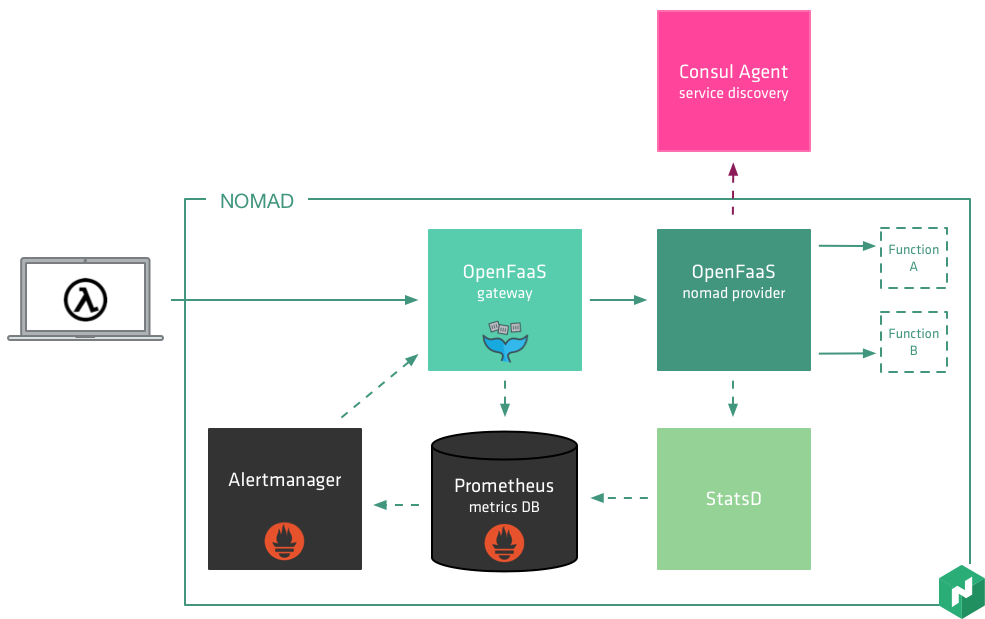
Building an application following this model is one way of achieving a "serverless architecture, is typically used microservices
Comparison withPaaS
Serverless PaaS a number of are simply added
In a FaaS system,the functions are expected in order , by contrast, period of time
Use Cases
Use cases forFaaS be powered
https://en.wikipedia.org/wiki/Function_as_a_service
Nuclio serverless
https://nuclio.io/
https://github.com/serverless/serverless
the flow of an application is determined by events
Serverless is simply hidden developers are relieved
What problems does OpenWhisk solve? What can you do with OpenWhisk?
OpenWhisk to solely focus OpenWhisk
https://openwhisk.apache.org/faq.html
microservice toolchain
As a result, developers spend too much time dealing with infrastructure and operational complexities like fault-tolerance, load balancing, auto-scaling, and logging features.
OpenWhisk for example, it can enable mobile developers to interface with backend logic running in a cloud without installing server-side middleware or infrastructure.
https://developer.ibm.com/code/open/projects/openwhisk/
Mobile Backend Development
Serverless serverless microservices backends
Data Processing
Data processing is a very dominant field forserverless OpenWhisk
Cognitive Processing
Similar to the data processing scenario is cognitive processing, whereOpenWhisk is used in conjunction
Streaming Analytics
He described an integration with Kafka and Bluemix where data posted in Kafka can immediatelystart being analyzed.
Internet of Things
Nauerz Abilisense OpenWhisk
GreenQ serverless


Kubernetes is a complex product that needs a lot of configuration to run properly. Developers must log into individual worker nodes to carry out repetitive tasks, such as installing dependencies and configuring networking rules. They must generate configuration files, manage logging and tracing, and write their own CI/CD scripts using tools like Jenkins. Before they can deploy their containers, they have to go through multiple steps to containerize their source code in the first place .
Knative helps developers by hiding many of these tasks, simplifying container-based management and enabling you to concentrate on writing code. It also supports for serverless functions
Knative consists of three main components: Build, Serve, and Event.
Knative offers a Serve component that runs containers as scalable services. Not only can it scale containers up to run in the thousands, but it can scale them down to the point where there are no instances of the container running at all.
Knative 's benefits can help solve a variety of real-world challenges facing today's developers, including the following :
Serverless computing is a relatively new way of deploying code that can help make cloud-native software even more productive. Instead of having a long-running instance of your software waiting for new requests (which means you are paying for idle time), the hosting infrastructure will only bring up instances of your code on an "as-needed" basis.
Knative breaks down the distinction between software services and functions by enabling developers to build and run their containers as both
Knative 's serving component incorporates Istio help manage tiny, container-based software services known as microservices .
Istio provides a routing mechanism that allows services to access each other via URLs in what's known as a service mesh.
Knative uses Istio ’s service mesh routing capabilities to route calls between the services that it runs.
Istio manages authentication for service requests and automatic traffic encryption for secure communication between services.
- What Cilium and BPF will bring to
Istio
How is
What is Cilium?
Cilium comes in the form of a networking plugin and thus integrates at a lower level with the orchestration system. Cilium and
Cilium uses a combination of components to provide this functionality:
An agent written in
A
A set of
Can I run Cilium alongside
It is perfectly fine to run Cilium as a CNI plugin to provide networking, security, and
How will
We are very excited about BPF and how it is changing how security and networking
Why is the In-kernel proxy faster than not running a proxy at all?
When changing how to approach a problem.
The difference in the two lines between "No Proxy" and "Cilium In-Kernel" is thus the cost of the TCP/IP stack in the Linux kernel.
How else can
Use of Istio Auth and the concept of identities to enforce the existing Cilium identity concept. This would allow enforcing existing
Ability to export telemetry from Cilium to
Potential to offload
https://cilium.io/blog/istio/
- Cilium: Making BPF Easy on
Kubernetes
I wouldn’t say we compete with Istio, we complement each other,” is compromised as well
https://thenewstack.io/cilium-making-bpf-easy-on-kubernetes-for-improved-security-performance/
GitOps Istio
Traditionally you may have had two almost identical servers: one that goes to all users and another with the new features that gets rolled out to only a set of users.
by using
If something goes wrong and you need to roll back, you can redeploy a stable version all from Git.
An
With both a GA and a canary deployed, you can continue to iterate on the canary release until it meets expectations and you
An engineer fixes the latency issue and cuts a new release by tagging the master branch as 0.2.1
GitHub notifies GCP Container Builder that
GCP Container Builder builds the Docker image, tags it as 0.2.1 and pushes it to to Quay
Weave Cloud detects the new tag and updates the Canary deployment definition
Weave Cloud commits the Canary deployment definition to GitHub in the cluster repo
Weave Cloud triggers a rolling update of the Canary deployment
Weave Cloud sends a Slack notification that the 0.2.1 patch has
Once the Canary
With each Git push and manifest modification, Weave Cloud detects that the cluster state is out of sync with
If you notice that the Canary doesn't behave well under load, revert the changes in Git
You can keep iterating on the canary code until the SLA is on a par with the GA release.
https://www.weave.works/blog/gitops-workflows-for-istio-canary-deployments
- The World’s Most Popular Open Source
Microservice
Invoke
Kong is a scalable, open source API Layer (also known as an API Gateway, or API Middleware). Kong runs in front of any RESTful API and
https://konghq.com/kong-community-edition/
- What are containers?
Containers are an executable unit of software in which
To do this, containers take advantage of a form of operating system (OS) virtualization in which features of the OS (
Containers are small, fast, and portable because unlike a virtual machine, containers do not
Containers vs. VMs
Instead of virtualizing the underlying hardware, containers virtualize the operating system (typically Linux) so each individual container contains only the application and its libraries and dependencies. The absence of the guest OS is why containers are so lightweight and, thus, fast and portable.
Benefits
Lightweight: Containers share the machine OS kernel, eliminating the need for a full OS instance per application and making container files small and easy on resources.
Portable and platform independent: Containers carry all their dependencies with them, meaning that software can
Supports modern development and architecture: such as DevOps,
Containerization
Software needs to
Container orchestration
container orchestration emerged as a
Provisioning
Redundancy
Health monitoring
Resource allocation
Scaling and load balancing
Moving between physical hosts
While many container orchestration platforms (such as Apache
Docker and
Docker turns program source code into containers and then executes them, whereas
the ecosystem of tools and projects designed to harden and expand production use cases continues to grow
As developers leverage containers to build and run
Instead of running all the time and responding when needed (as a server does), a
https://www.ibm.com/cloud/learn/containers
- What Is AWS Lambda?
AWS Lambda is a
You can also build
https://docs.aws.amazon.com/lambda/latest/
- AWS Lambda lets you run code without provisioning or managing servers. You pay only for the
compute
With Lambda, you can run code for virtually any
https://aws.amazon.com/lambda/
- Distributed Data Pre-processing using Dask, Amazon ECS and Python
Data Engineers and Data Scientists often use tools from the python ecosystem such as
https://towardsdatascience.com/serverless-distributed-data-pre-processing-using-dask-amazon-ecs-and-python-part-1-a6108c728cc4
- Build highly scalable applications on a fully managed
serverless
App Engine enables developers to stay more productive and agile by supporting popular development languages and a wide range of developer tools.
Google App Engine (often referred to as GAE or simply
Applications are sandboxed .
https://cloud.google.com/appengine/
Your First Serverless Microservice
Intro to Serverless
Serverless Pricing is based
Utility computing, or The Computer Utility, is a service provisioning model in which a service provider makes computing resources and infrastructure management available to the customer as needed, and charges them for
The name "
https://en.wikipedia.org/wiki/Serverless_computing
- What is
serverless
https://aws.amazon.com/lambda/faqs/
- Fission is a framework for
serverless Kubernetes
Write short-lived functions in any language, and map them to HTTP requests (or other event triggers). Deploy functions instantly with one command. There are no containers to build, and no Docker registries to manage.
https://fission.io/
FaaS
Web apps,
In other words,
Instead of scaling a monolithic REST server to handle potential load, you can now split the server into a bunch of functions which can
https://medium.com/@BoweiHan/an-introduction-to-serverless-and-faas-
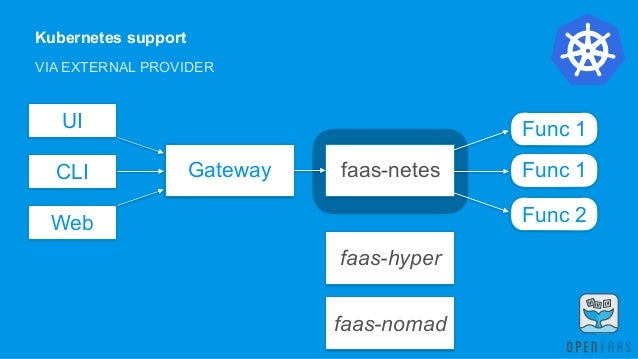
OpenFaaS Serverless Kubernetes first Any process can be packaged
https://github.com/openfaas/faas
- Function as a service (
FaaS
Building an application following this model is one way of achieving a "
Comparison with
In a FaaS system,
Use Cases
Use cases for
https://en.wikipedia.org/wiki/Function_as_a_service
Nuclio Serverless Functions
https://nuclio.io/
- The
Serverless – comprised of microservices
https://github.com/serverless/serverless
- What are event-driven programming and
serverless
What problems does OpenWhisk solve? What can you do with OpenWhisk?
https://openwhisk.apache.org/faq.html
- Apache
OpenWhisk serverless
Microservice Microservices
As a result, developers spend too much time dealing with infrastructure and operational complexities like fault-tolerance, load balancing, auto-scaling, and logging features.
https://developer.ibm.com/code/open/projects/openwhisk/
- Introducing
Serverless
Mobile Backend Development
Data Processing
Data processing is a very dominant field for
Cognitive Processing
Similar to the data processing scenario is cognitive processing, where
Streaming Analytics
He described an integration with Kafka and Bluemix where data posted in Kafka can immediately
Internet of Things
-
Knative as an open source platform. It supports containers, a form of packaged applications that run in cloud environments.Knative runs on top of theKubernetes container orchestration system, which controls large numbers of containers in a production environment.
Build
The Build component of Knative turns source code into cloud-native containers or functions.
Serve
The first is configuration , which lets you create different versions of the same container-based service. Knative lets these different versions run concurrently,
The second feature is service routing. You can use Knative 's routing capabilities to send a percentage of user requests to the new version of the service, while still sending most other requests to the old one.
Eve
The Event component of Knative enables different events to trigger their container-based services and functions.
Benefits
Faster iterative development:
Focus on code:
Quick entry to serverless computing:
What challenges does Knative solve?
CI/CD set up
Easier customer rollouts
Serverless
Istio
It's essentially a switchboard for the vast, complex array of container-based services that can quickly develop in a microservice environment.
It can also gather detailed metrics about microservice operations to help developers and administrators plan infrastructure optimization.
https://www.ibm.com/cloud/learn/knative?cm_mmc=OSocial_Youtube-_-Watson+and+Cloud+Platform_Cloud+Platform-_-WW_WW-_-KnativeYTdescription&cm_mmca1=000023UA&cm_mmca2=10005900
The main advantage of this technology is the ability to create and run applications without the need for infrastructure management.
In other words, when using a serverless architecture, developers no longer need to allocate resources, scale and maintain servers to run applications, or manage databases and storage systems. Their sole responsibility is to write high-quality code.
There have been many open-source projects for building serverless frameworks (Apache OpenWhisk, IronFunctions, Fn from Oracle, OpenFaaS, Kubeless, Knative, Project Riff, etc).
OpenWhisk, Firecracker & Oracle FN
Apache OpenWhisk is an open cloud platform for serverless computing that uses cloud computing resources as services. Compared to other open-source projects (Fission, Kubeless, IronFunctions), Apache OpenWhisk is characterized by a large codebase, high-quality features, and the number of contributors. However, the overly large tools for this platform (CouchDB, Kafka, Nginx, Redis, and Zookeeper) cause difficulties for developers. In addition, this platform is imperfect in terms of security
Firecracker is a virtualization technology introduced by Amazon.Firecracker offers lightweight virtual machines called micro VMs, which use hardware-based virtualization technologies for their full isolation while at the same time providing performance and flexibility at the level of conventional containers.The project was developed at Amazon Web Services to improve the performance and efficiency of AWS Lambda and AWS Fargate platforms.
Oracle Fn is an open-server serverless platform that provides an additional level of abstraction for cloud systems to allow for Functions as Services (FaaS). As in other open platforms in Oracle Fn, the developer implements the logic at the level of individual functions. Unlike existing commercial FaaS platforms, such as Amazon AWS Lambda, Google Cloud Functions, and Microsoft Azure Functions, Oracle’s solution is positioned as having no vendor lock-in.
Kubeless is an infrastructure that supports the deployment of serverless functions in your cluster and enables us to execute both HTTP and event switches in your Python, Node.js, or Ruby code. Kubeless is a platform that is built using Kubernetes’ core functionality, such as deployment, services, configuration cards (ConfigMaps), and so on.
Fission is an open-source platform that provides a serverless architecture over Kubernetes. One of the advantages of Fission is that it takes care of most of the tasks of automatically scaling resources in Kubernetes, freeing you from manual resource management. The second advantage of Fission is that you are not tied to one provider and can move freely from one to another, provided that they support Kubernetes clusters (and any other specific requirements that your application may have).
Main Benefits of Using OpenFaaS and Knative
OpenFaaS and Knative are publicly available and free open-source environments for creating and hosting serverless functions
These platforms allow you to:
Reduce idle resources.
Quickly process data.
Interconnect with other services.
Balance load with intensive processing of a large number of requests.
How to Build and Deploy Serverless Functions With OpenFaaS
OpenFaaS is a Cloud Native serverless framework and therefore can be deployed by a user on many different cloud platforms as well as bare-metal servers.The main goal of OpenFaaS is to simplify serverless functions with Docker containers, allowing you to run complex and flexible infrastructures.There are installation options for Kubernetes and Docker Swarm.Docker is not the only runtime available in Kubernetes, so others can be used.
Function Watchdog
Almost any code can be converted to an OpenFaaS function. If your use case doesn’t fit one of the supported language templates then you can create your own OpenFaaS template using the watchdog to relay the HTTP requests to your code inside the container.
all developed functions, microservices, and products are stored in the Docker container, which serves as the main OpenFaaS platform for developers and sysadmins to develop, deploy, and run serverless applications with containers.
The Main Points for Installation of OpenFaaS on Docker
You can install OpenFaaS to any Kubernetes cluster, whether using a local environment, your own datacenter, or a managed cloud service such as AWS EKS
For running locally, the maintainers recommend using the KinD (Kubernetes in Docker) or k3d (k3s in Docker) project. Other options like Minikube and microk8s are also available.
Pros and Cons of OpenFaaS
In other words, OpenFaaS allows you to run code in any programming language anytime and anywhere.
OpenFaaS uses container images for functions
Each function replica runs within a container, and is built into a Docker image.
There is an option to avoid cold starts by having a minimum level of scale such as 20/100 or 1/5
Scaling to zero is optional, but if used in production, you can expect just under a two-second cold-start for the first invocation
The queue-worker enables asynchronous invocation, so if you do scale to zero, you can decouple any cold-start from the user
Deploying and Running Functions With Knative
Knative allows you to develop and deploy container-based server applications that you can easily port between cloud providers
Building
The Building component of Knative is responsible for ensuring that container assemblies in the cluster are launched from the source code. This component works on the basis of existing Kubernetes primitives and also extends them.
Eventing
The Eventing component of Knative is responsible for universal subscription, delivery, and event management as well as the creation of communication between loosely coupled architecture components. In addition, this component allows you to scale the load on the server.
Serving
The main objective of the Serving component is to support the deployment of serverless applications and features, automatic scaling from scratch, routing and network programming for Istio components, and snapshots of the deployed code and configurations. Knative uses Kubernetes as the orchestrator, and Istio performs the function of query routing and advanced load balancing.
Example of the Simplest Functions With Knative
Your choice will depend on your given skills and experience with various services including Istio, Gloo, Ambassador, Google, and especially Kubernetes Engine, IBM Cloud, Microsoft Azure Kubernetes Service, Minikube, and Gardener.
Pros and Cons of Knative
Like OpenFaaS, Knative allows you to create serverless environments using containers. This in turn allows you to get a local event-based architecture in which there are no restrictions imposed by public cloud services.
Both OpenFaaS and Knative let you automate the container assembly process, which provides automatic scaling. Because of this, the capacity for serverless functions is based on predefined threshold values and event-processing mechanisms.
In addition, both OpenFaaS and Knative allow you to create applications internally, in the cloud, or in a third-party data center. This means that you are not tied to any one cloud provider.
One main drawback of Knative is the need to independently manage container infrastructure. Simply put, Knative is not aimed at end-users.
It is worth noting that these platforms can not be easily compared because they are designed for different tasks.
From the point of view of configuration and maintenance, OpenFaas is simpler. With OpenFaas, there is no need to install all components separately as with Knative, and you don’t have to clear previous settings and resources for new developments if the required components have already been installed.
https://epsagon.com/tools/serverless-open-source-frameworks-openfaas-knative-more/
- Serverless Open-Source Frameworks: OpenFaaS, Knative, & More
The main advantage of this technology is the ability to create and run applications without the need for infrastructure management.
In other words, when using a serverless architecture, developers no longer need to allocate resources, scale and maintain servers to run applications, or manage databases and storage systems. Their sole responsibility is to write high-quality code.
There have been many open-source projects for building serverless frameworks (Apache OpenWhisk, IronFunctions, Fn from Oracle, OpenFaaS, Kubeless, Knative, Project Riff, etc).
OpenWhisk, Firecracker & Oracle FN
Apache OpenWhisk is an open cloud platform for serverless computing that uses cloud computing resources as services. Compared to other open-source projects (Fission, Kubeless, IronFunctions), Apache OpenWhisk is characterized by a large codebase, high-quality features, and the number of contributors. However, the overly large tools for this platform (CouchDB, Kafka, Nginx, Redis, and Zookeeper) cause difficulties for developers. In addition, this platform is imperfect in terms of security
Firecracker is a virtualization technology introduced by Amazon.Firecracker offers lightweight virtual machines called micro VMs, which use hardware-based virtualization technologies for their full isolation while at the same time providing performance and flexibility at the level of conventional containers.The project was developed at Amazon Web Services to improve the performance and efficiency of AWS Lambda and AWS Fargate platforms.
Oracle Fn is an open-server serverless platform that provides an additional level of abstraction for cloud systems to allow for Functions as Services (FaaS). As in other open platforms in Oracle Fn, the developer implements the logic at the level of individual functions. Unlike existing commercial FaaS platforms, such as Amazon AWS Lambda, Google Cloud Functions, and Microsoft Azure Functions, Oracle’s solution is positioned as having no vendor lock-in.
Kubeless is an infrastructure that supports the deployment of serverless functions in your cluster and enables us to execute both HTTP and event switches in your Python, Node.js, or Ruby code. Kubeless is a platform that is built using Kubernetes’ core functionality, such as deployment, services, configuration cards (ConfigMaps), and so on.
Fission is an open-source platform that provides a serverless architecture over Kubernetes. One of the advantages of Fission is that it takes care of most of the tasks of automatically scaling resources in Kubernetes, freeing you from manual resource management. The second advantage of Fission is that you are not tied to one provider and can move freely from one to another, provided that they support Kubernetes clusters (and any other specific requirements that your application may have).
Main Benefits of Using OpenFaaS and Knative
OpenFaaS and Knative are publicly available and free open-source environments for creating and hosting serverless functions
These platforms allow you to:
Reduce idle resources.
Quickly process data.
Interconnect with other services.
Balance load with intensive processing of a large number of requests.
How to Build and Deploy Serverless Functions With OpenFaaS
OpenFaaS is a Cloud Native serverless framework and therefore can be deployed by a user on many different cloud platforms as well as bare-metal servers.The main goal of OpenFaaS is to simplify serverless functions with Docker containers, allowing you to run complex and flexible infrastructures.There are installation options for Kubernetes and Docker Swarm.Docker is not the only runtime available in Kubernetes, so others can be used.
Function Watchdog
Almost any code can be converted to an OpenFaaS function. If your use case doesn’t fit one of the supported language templates then you can create your own OpenFaaS template using the watchdog to relay the HTTP requests to your code inside the container.
all developed functions, microservices, and products are stored in the Docker container, which serves as the main OpenFaaS platform for developers and sysadmins to develop, deploy, and run serverless applications with containers.
The Main Points for Installation of OpenFaaS on Docker
You can install OpenFaaS to any Kubernetes cluster, whether using a local environment, your own datacenter, or a managed cloud service such as AWS EKS
For running locally, the maintainers recommend using the KinD (Kubernetes in Docker) or k3d (k3s in Docker) project. Other options like Minikube and microk8s are also available.
Pros and Cons of OpenFaaS
In other words, OpenFaaS allows you to run code in any programming language anytime and anywhere.
OpenFaaS uses container images for functions
Each function replica runs within a container, and is built into a Docker image.
There is an option to avoid cold starts by having a minimum level of scale such as 20/100 or 1/5
Scaling to zero is optional, but if used in production, you can expect just under a two-second cold-start for the first invocation
The queue-worker enables asynchronous invocation, so if you do scale to zero, you can decouple any cold-start from the user
Deploying and Running Functions With Knative
Knative allows you to develop and deploy container-based server applications that you can easily port between cloud providers
Building
The Building component of Knative is responsible for ensuring that container assemblies in the cluster are launched from the source code. This component works on the basis of existing Kubernetes primitives and also extends them.
Eventing
The Eventing component of Knative is responsible for universal subscription, delivery, and event management as well as the creation of communication between loosely coupled architecture components. In addition, this component allows you to scale the load on the server.
Serving
The main objective of the Serving component is to support the deployment of serverless applications and features, automatic scaling from scratch, routing and network programming for Istio components, and snapshots of the deployed code and configurations. Knative uses Kubernetes as the orchestrator, and Istio performs the function of query routing and advanced load balancing.
Example of the Simplest Functions With Knative
Your choice will depend on your given skills and experience with various services including Istio, Gloo, Ambassador, Google, and especially Kubernetes Engine, IBM Cloud, Microsoft Azure Kubernetes Service, Minikube, and Gardener.
Pros and Cons of Knative
Like OpenFaaS, Knative allows you to create serverless environments using containers. This in turn allows you to get a local event-based architecture in which there are no restrictions imposed by public cloud services.
Both OpenFaaS and Knative let you automate the container assembly process, which provides automatic scaling. Because of this, the capacity for serverless functions is based on predefined threshold values and event-processing mechanisms.
In addition, both OpenFaaS and Knative allow you to create applications internally, in the cloud, or in a third-party data center. This means that you are not tied to any one cloud provider.
One main drawback of Knative is the need to independently manage container infrastructure. Simply put, Knative is not aimed at end-users.
It is worth noting that these platforms can not be easily compared because they are designed for different tasks.
From the point of view of configuration and maintenance, OpenFaas is simpler. With OpenFaas, there is no need to install all components separately as with Knative, and you don’t have to clear previous settings and resources for new developments if the required components have already been installed.
https://epsagon.com/tools/serverless-open-source-frameworks-openfaas-knative-more/
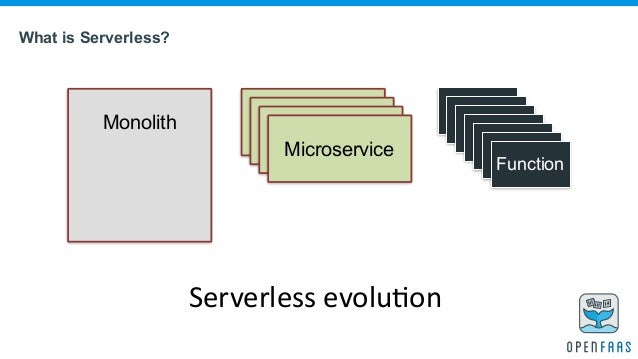
What is Serverless?
pay for execution time only but not idle time
outsourcing managinng, provisioning and maintaining servers to cloud provider
FaaS
faas-functions-events
What is FaaS (Functions as a Service)?
on-premises
abstraction further
hardware-virtualization-operating system-runtimes-application
IaaS(hardware-virtualization)-operating system-runtimes-application
Paas(hardware-virtualization-operating system-runtimes)-application
FaaS(hardware-virtualization-operating system-runtimes-application) - functions
Good Post Thanks for sharing this blog. Keep on sharing
ReplyDeleteGCP Training Online
Online GCP Training