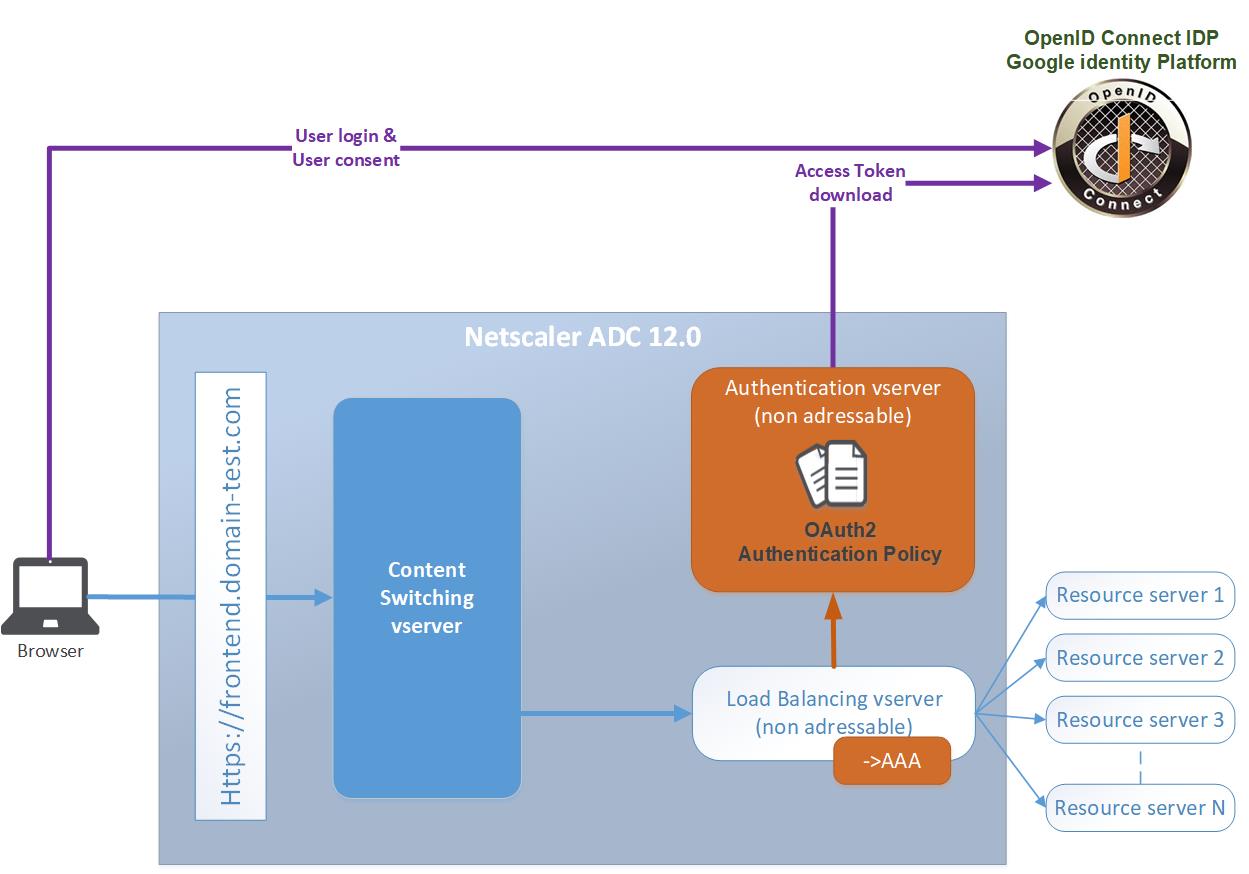
Microservices – OAuth2 OpenID
These services and web applications should
Token based security is
What is Cookie based security?
It is stateful, server keep track of sessions and client (browser) holds session identifier in the cookie.
It is implicit, browser send it automatically with every request to the domain (and
What is Token based security (using JWT)?
It is stateless,
Why token based security?
It is stateless, scalable and decoupled, JWT token contains all the information to check its validity and user’s identity and access details. Client system can access cross domain APIs using
Cookie
What is JWT (JSON Web Tokens)?
JWT tokens are JSON encoded data structures
What is
API Gateway:
API Gateway acts as a single entry point for
The API Gateway authenticates the user using
http://proficientblog.com/microservices-security/
- API Security:
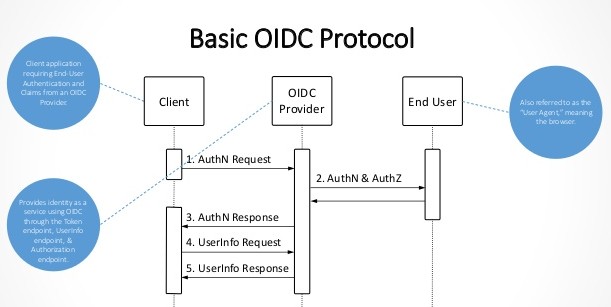
Deep Dive intoOAuth andOpenID Connect
You need to take additional measures to protect your servers and the mobiles that run your apps
Without a holistic approach, your API may be
Overview of
Beginning with
Delegated access
Reduction of password sharing between users and third-parties (the so called “password anti-pattern”)
Revocation of access
With
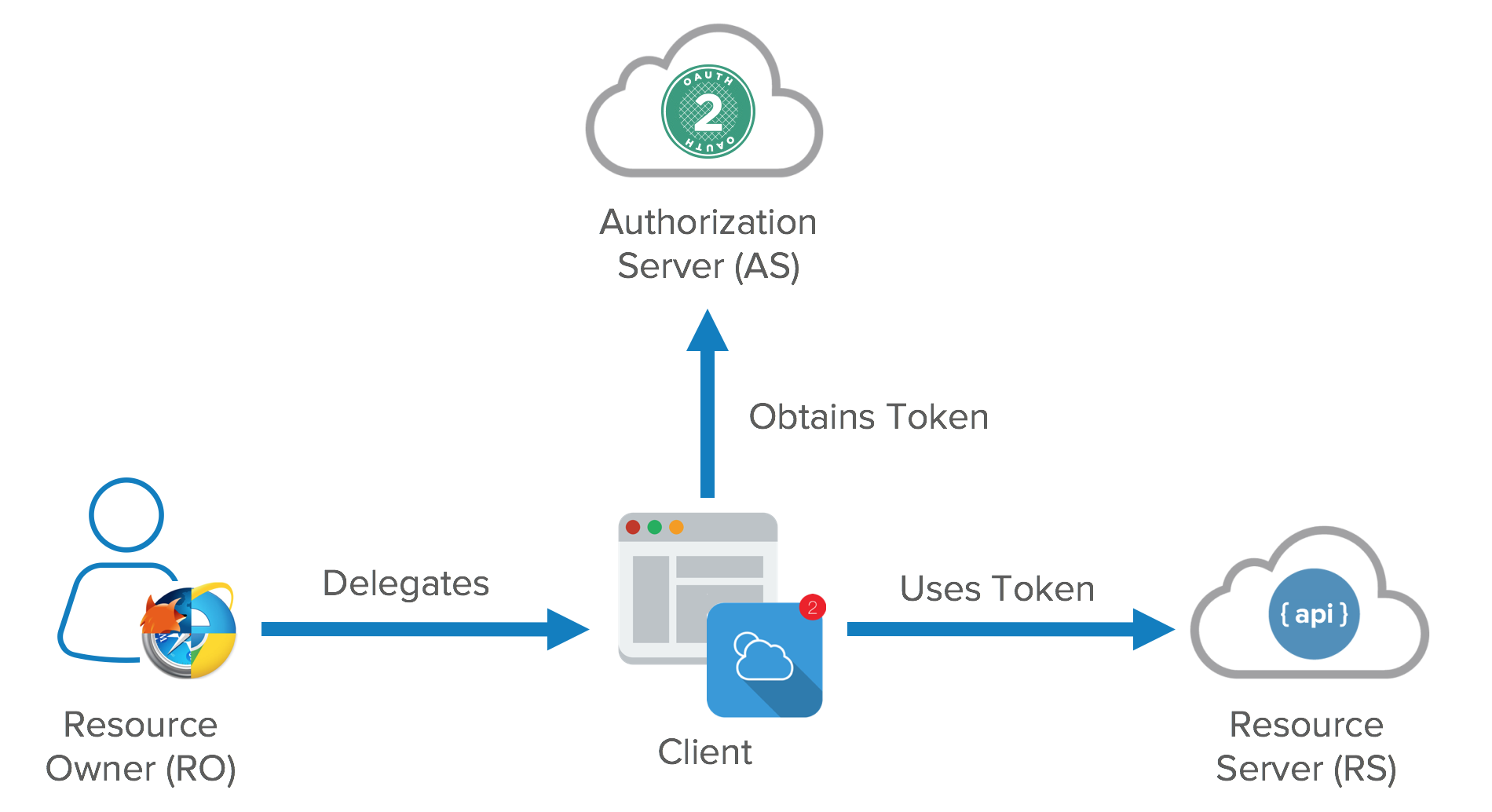
Actors in
There are four primary actors in
Resource Owner (RO): The entity
Client: The mobile app,
Authorization Server (AS): The Security Token Service (STS) or, colloquially, the
Resource Server (RS): The service that exposes the data, i.e., the AP
Scopes
the client may request certain rights, but the user may only grant some of them or allow
Kinds of Tokens
In
Access Tokens: These are tokens that
Refresh Tokens:
Think of access tokens like a session that
As long as that session is valid, you can continue to interact with the
Once that session
Refresh tokens are like passwords in this comparison. Also, just like passwords, the client needs to keep refresh tokens safe.
It should persist these in a secure credential store. Loss of these tokens will require the revocation of all consents that users have performed.
Passing Tokens
There are two distinct ways in which
By value
By reference
The run-time will either copy the data onto the stack as it invokes the function being called (by value) or it will push a pointer to the data (by reference).
Profiles of Tokens
There are different profiles of tokens
Bearer tokens
Holder of Key (
If you find a dollar bill on the ground and present it at a shop, the merchant will happily accept it. She looks at the issuer of the bill, and trusts that authority
Where some
Types of Tokens
The
Example types include:
WS-Security tokens, especially SAML tokens
JWT tokens (which I’ll get to next)
Legacy tokens (e.g., those issued by a Web Access Management system)
Custom tokens
Custom tokens are the most prevalent when passing them around by reference
JSON Web Tokens
JSON Web Tokens or JWTs (pronounced like the English word “jot”) are a
The issuer
The subject or authenticated uses (typically the Resource Owner)
How the user authenticated and when
These tokens are very flexible, allowing you to add your own claims (i.e., attributes or name/value pairs) that represent the subject.
If it helps, you can compare JWTs to SAML tokens. They are less expressive, however, and you cannot do everything that you can do with SAML tokens. Also, unlike SAML they do not use XML, XML name spaces, or XML Schema. This is a good thing as JSON imposes a much lower technical barrier on the processors of these types of tokens.
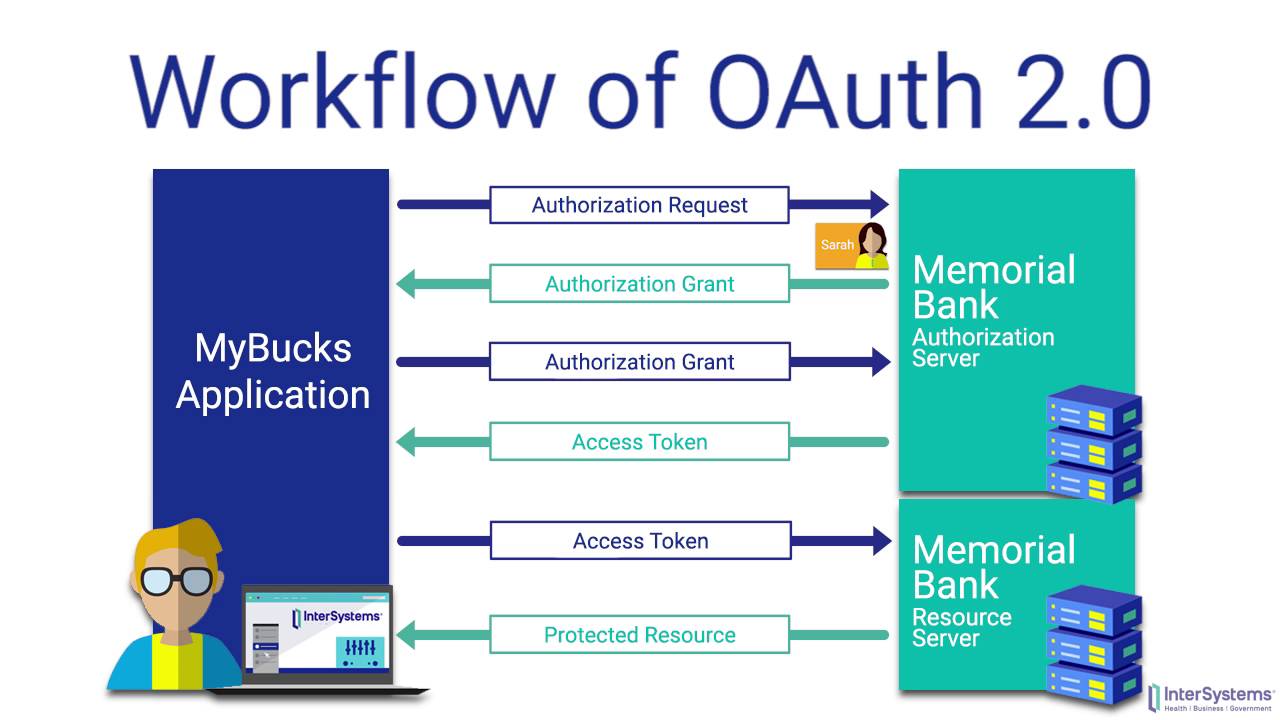
The code flow (or web server flow)
Client credential flow
Resource owner credential flow
Implicit flow
The code flow is by far the most common
It’s where the client is (typically) a web server, and that
You’ve probably used it as a Resource Owner many times, for example, when you login to a site using certain social network identities. Even when the social network isn’t using
Improper and Proper Uses of
It’s for delegation, and delegation only
To see how this nuance makes a
Building
By building on
How the user authenticated (i.e.,
When the user authenticated
Various properties about the authenticated user (e.g., first name, last name, shoe size, etc.)
This is useful when your client needs a bit of info to customize the user experience. Many times I’ve seen people use by value access tokens that contain this info, and they let the client take the values out of the API’s token
The User Info Endpoint and
The spec defines a few specific scopes that the client can pass to the
profile
address
phone
The others are used to inform the user about what type of data the OP will release to the client. If the user
Not Backward Compatible with v. 2
It’s important to
https://nordicapis.com/api-security-oauth-openid-connect-depth/
- API Security for Distributed Authorization Realms

A centralized API gateway with distributed authorization realms

Centralized OAuth2 providers

Centralized API gateway with centralized OAuth2
In the most basic API security use case pattern, we have one API gateway, one authorization realm, and one or more resource servers. An authorization realm is where the resource owner will authenticate and authorize OAuth2
https://wso2.com/library/articles/2018/02/api-security-for-distributed-authorization-realms/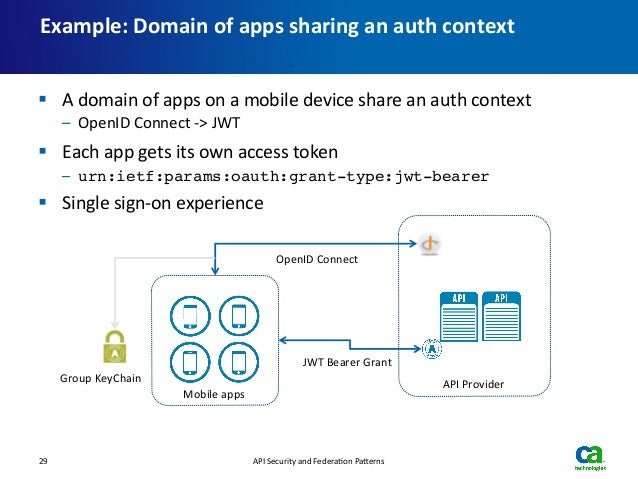
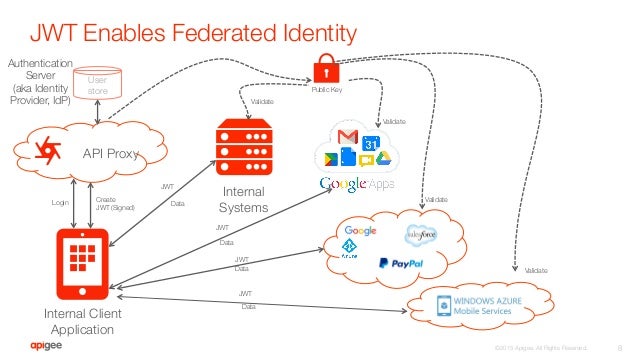
SAML2 vs JWT: Understanding OAuth2
- XACML (Extensible Access Control Markup Language) is an open standard XML-based language designed to express security policies and access rights to information for Web services, digital rights management (DRM), and enterprise security applications
https://searchcio.techtarget.com/definition/XACML
- XACML stands for "
eXtensible evaluate
https://en.wikipedia.org/wiki/XACML

Authorization for APIs with XACML and OAuth
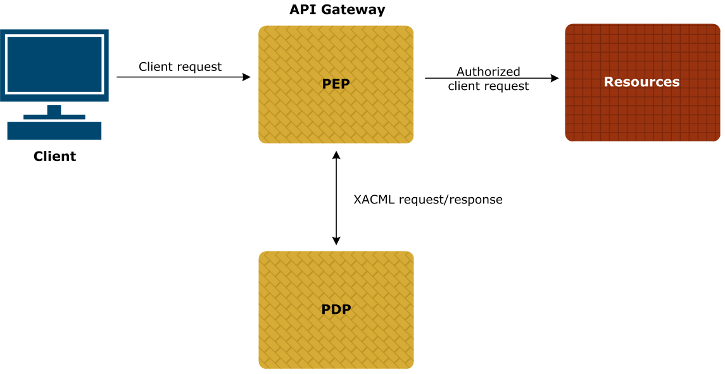
XACML PEP authorization

100% Pure XACML

- WS-Trust is a WS-* specification and OASIS standard that provides extensions to WS-Security, specifically dealing with the issuing, renewing, and validating of security tokens,
as well as
https://en.wikipedia.org › wiki › WS-Trust
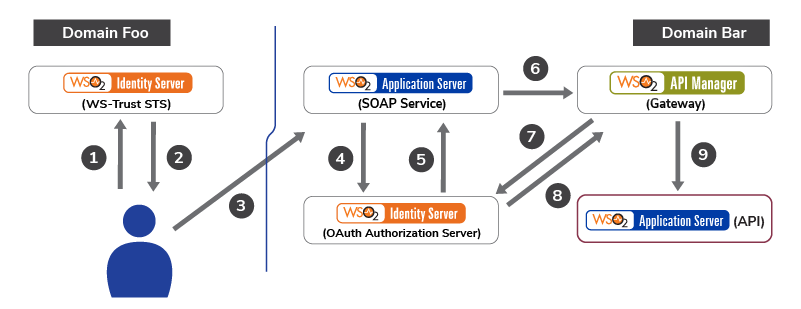
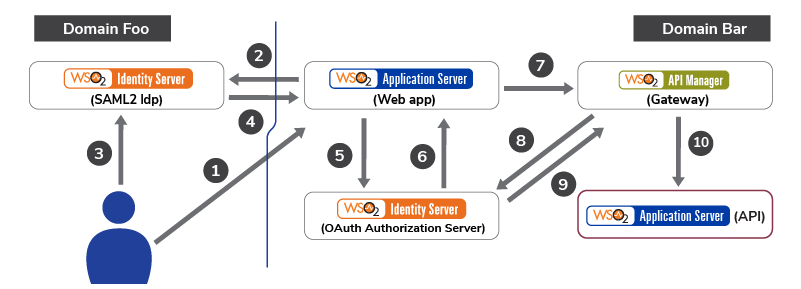
Building an Ecosystem for API Security

Access Control Service Oriented Architecture Security

API Security for Modern Web Apps
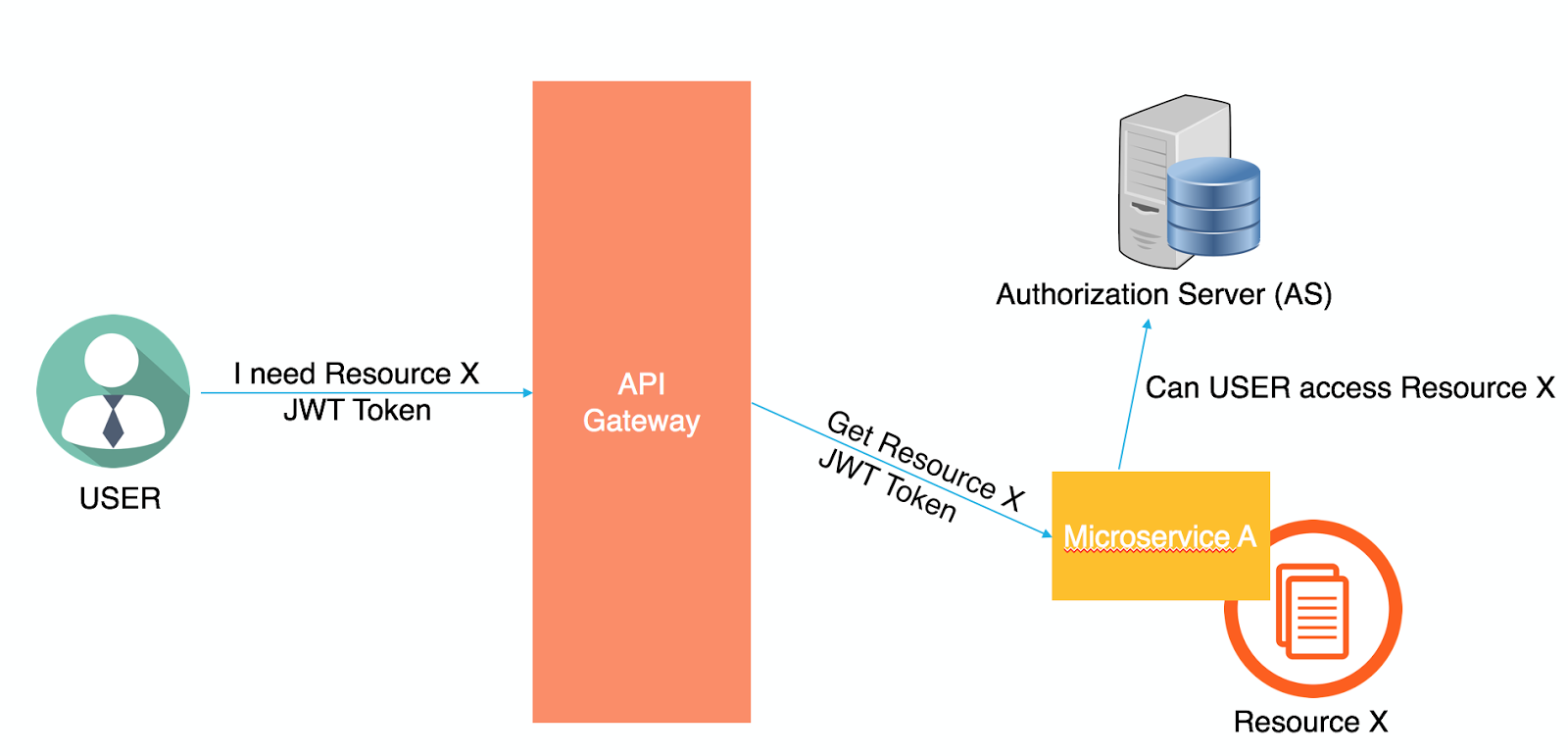
Securing Microservices
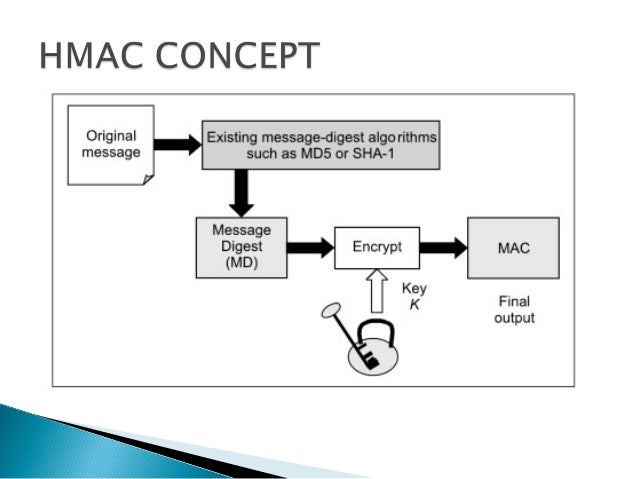
- Hash-based Message Authentication Code (HMAC)
Hash-based Message Authentication Code (HMAC) is a message authentication code that uses a cryptographic key
Hash-based message authentication code (HMAC) provides the server and the client each with a private key that
Once the server receives the request and regenerates its own unique HMAC, it compares the two HMACs. If they're equal, the client
https://searchsecurity.techtarget.com/definition/Hash-based-Message-Authentication-Code-HMAC


- On a final note,
IPsec The generic HMAC procedure can be used IPsec
In HMAC, both parties share a secret key.
Recall that hash functions operate on a fixed-size block of input at one time; MD5 and SHA-1, for example, work on 64 byte blocks. These functions then generate a fixed-size hash value; MD5 and SHA-1, in particular, produce 16 byte (128 bit) and
The following steps provide a simplified, although reasonably accurate,
Alice pads K so
Alice transmits MESSAGE and the hash value.
Bob has also
Bob compares the computed hash value with the received hash value. If they match, then the sender — Alice — must know the secret key and her identity is, thus, authenticated.
https://www.garykessler.net/library/crypto.html

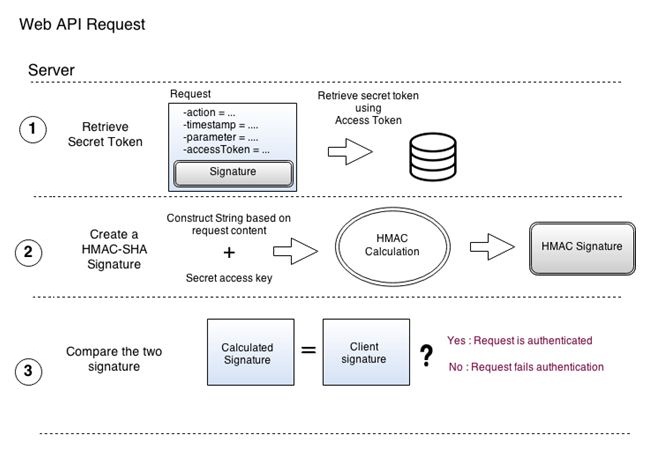
- HMAC Authentication
–
HMAC authentication provides a simple way to authenticate a HTTP is known secret Generally, this is created this signature is attached be served is dropped and
https://www.codeproject.com/Articles/766171/ApiFrame-A-simple-library-for-Web-API-security-exc


- JSON Web Tokens are an open, industry standard RFC 7519 method for representing claims securely between two parties.
JWT
https://jwt.io/
- How JSON Web Token (JWT) Secures Your API
You've probably heard that JSON Web Token (JWT) is the current state-of-the-art technology for securing APIs.
API Authentication
The difficulty in securing an HTTP API is that requests are stateless — the API has no way of knowing whether any two requests were from the same user or not.
JSON Web Token
What we need is a way to allow a user to supply their credentials just once, but then
Structure of the Token
Normally, a JSON web token
We can decode these strings to get a better understand of the structure of JWT.
Header
The header is meta information about the token.
Payload
The payload can include any data you like, but you might just include a user ID if the purpose of your token is API access authentication.
It's important to note that the payload is not secure.
Anyone can decode the token and see exactly what's in the payload.
Even though this payload is all that's needed to identify a user on an API, it doesn't provide a means of authentication.
So this brings us to the signature, which is the key piece for authenticating the token.
Hashing Algorithms
To begin with, it's a function for transforming a string into a new string called a hash.
The most important property of the hash is that you can't use the hashing algorithm to identify the original string by looking at the hash.
There are
JWT Signature
So, coming back to the JWT structure, let's now look at the third piece of the token, the signature.
Q. Why include the header and payload in the signature hash?
This ensures the signature is unique to this
Q. What's the secret?
We said before that you can't determine a hash's input from looking at the output
However, since we know that the signature includes the header and payload, as those are public information, if you know the hashing algorithm (hint: it's usually specified in the header), you could generate the same hash.
Including it in the hash prevents someone from generating their own hash to forge the token. And since the hash obscures the information used to create it, no one can figure out the secret from the hash, either.
Authentication Process
Login
The token then gets attached as the authorization header in the response to the login request.
Authenticating Requests
When the server receives a request with an authorization token attached, the following happens:
It decodes the token and extracts the ID from the payload.
It looks up the user in the database with this ID.
It compares the request token with the one that's stored with the user's model. If they match,
Logging Out
If the user logs out
https://dzone.com/articles/how-json-web-token-jwt-secures-your-api
- Using JWT (JSON Web Tokens) to
authorize
JSON Web Token (JWT) is an open standard (RFC 7519) that defines a compact and self-contained way for securely transmitting information between parties as a JSON object. This information can
Also note, that if you want to follow along completely, I will
https://medium.com/@maison
- Securing your APIs with
OpenID
OIDC provides a flexible framework for identity providers to validate and assert user identities for Single Sign-On (SSO) to web, mobile, and API workloads.
OIDC uses the same grant types as
https://www.ibm.com/support/knowledgecenter/en/SSMNED_5.0.0/com.ibm.apic.toolkit.doc/tapic_sec_api_config_oidc.html

Building an App Using Amazon Cognito and an OpenID
Configuring NGINX for OAuth OpenID Keycloak
- Securing REST API using
Keycloak
how Spring Boot REST APIs can
Using
Using
Using
https://medium.com/@bcarunmail/securing-rest-api-using-keycloak-and-spring-oauth2-6ddf3a1efcc2
- Securing a Cluster
Controlling access to the
Use Transport Level Security (TLS) for all API traffic
API Authentication
Choose an authentication mechanism for the API servers to use that matches the common access patterns when you install a cluster.
Larger clusters may wish to integrate an existing OIDC or LDAP server that allow
All API clients must
API Authorization
Once authenticated,
These permissions combine verbs (get, create, delete) with resources (pods, services, nodes) and can be
Controlling access to the
Production clusters should enable
Controlling the capabilities of a workload or user at runtime
Limiting resource usage on a cluster
Resource quota limits the number or capacity of resources granted to a
Limit ranges restrict the maximum or minimum size of
Controlling what privileges containers run with
Pod security policies can limit which users or service accounts can provide dangerous security context settings
Restricting network access
The network policies for a
When running
By default, there are no restrictions on which nodes may run a pod
Protecting cluster components from compromise
Restrict access to
Administrators should always use strong credentials from the API servers to their
Enable audit logging
Restrict access to alpha or beta features
When in doubt, disable features you do not use
Rotate infrastructure credentials frequently
The shorter the lifetime of a secret or credential the harder it is for an attacker to make use of that credential.
Set short lifetimes on certificates and automate their rotation
Use an authentication provider that can control how long issued tokens are available and use short lifetimes where possible.
If you use service account tokens in external integrations, plan to rotate those tokens frequently.
Review third party integrations before enabling them
Encrypt secrets at rest
https://kubernetes.io/docs/tasks/administer-cluster/securing-a-cluster/
- 9
Kubernetes
Upgrade to the Latest Version
Enable Role-Based Access Control (RBAC)
RBAC
Cluster-wide permissions should
Use
Is your team using
Separate Sensitive Workloads
For example, a compromised node’s
You can achieve this separation using node pools (in the cloud or on-premises) and
Secure Cloud Metadata Access
GKE’s metadata concealment feature changes the cluster deployment mechanism to avoid this exposure, and we recommend using it until
Create and Define Cluster Network Policies
Network Policies allow you to control network access into and out of your containerized applications
Run a Cluster-wide Pod Security Policy
As a start, you could require that deployments drop the NET_RAW capability to defeat certain classes of network spoofing attacks.
Harden Node Security
three steps to improve the security posture on your nodes
Ensure the host is secure and configured correctly.
One way to do so is to check your configuration against CIS Benchmarks
Control network access to sensitive ports. Make sure that your network blocks access to ports used by
Consider limiting access to the
Malicious users have abused access to these ports to run cryptocurrency miners in clusters that
Minimize administrative access to
Turn on Audit Logging
Make sure you have audit logs enabled and are monitoring them for anomalous or unwanted API calls, especially any authorization failures — these log entries will have a status message “Forbidden.” Authorization failures could mean that an attacker is trying to abuse stolen credentials
https://www.cncf.io/blog/2019/01/14/9-kubernetes-security-best-practices-everyone-must-follow
Securing APIs with JWT, SCIM,
- RBAC vs. ABAC: Definitions & When to Use
Someone logs into your computer system. What can that person do? If you use RBAC techniques, the answer to that question depends on that person's role.
The main difference between RBAC vs. ABAC is the way each method grants access. RBAC techniques allow you to grant access by roles. ABAC techniques let you determine access by user characteristics, object characteristics, action types, and more
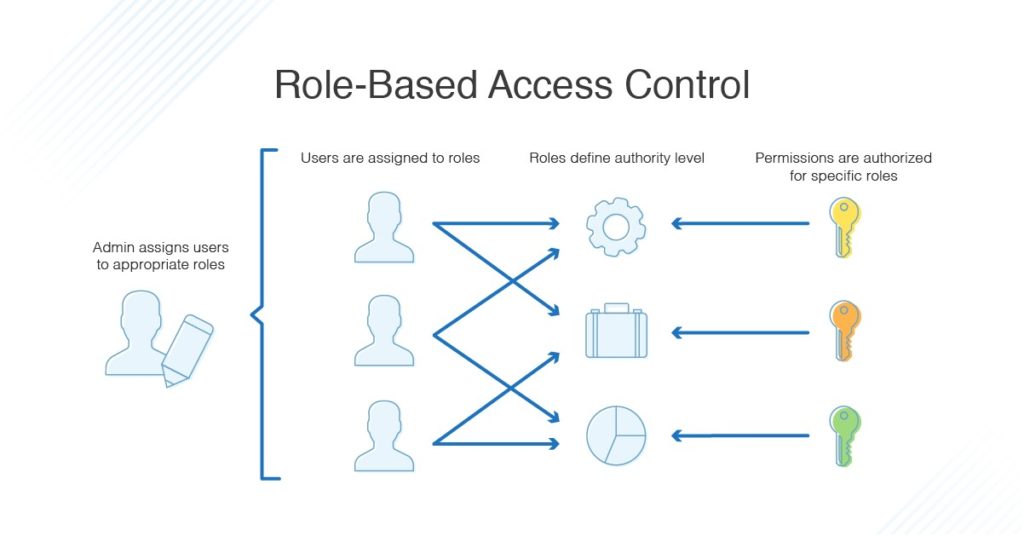
What Is Role-Based Access Control?
A role in RBAC language typically refers to a group of people that share certain characteristics, such as:
Departments
Locations
Seniority levels
Work duties
With a role defined, you can assign permissions. Those might involve:
Access. What can the person see?
Operations. What can the person read? What can the person write? Can the person create or delete files?
Sessions. How long can the person stay in the system? When will the login work? When will the login expire?
the National Institute of Standards and Technology defines four subtypes of RBAC
Flat: All employees have at least one role that defines permissions, but some have more than one.
Hierarchical: Seniority levels define how roles work together. Senior executives have their own permissions, but they also have those attained by their underlings.
Constrained: Separation of duties is added, and several people work on one task together. This helps to ensure security and prevent fraudulent activities.
Symmetrical: Role permissions are reviewed frequently, and permissions change as the result of that review.
These roles build upon one another, and they can be arranged by security level.
Level 1, Flat: This is the least complex form of RBAC. Employees use roles to gain permissions.
Level 2, Hierarchical: This builds on the Flat RBAC rules, and it adds role hierarchy.
Level 3, Constrained: This builds on Hierarchical RBAC, and it adds separation of duties.
Level 4, Symmetrical: This builds on the Constrained RBAC model, and it adds permission reviews.
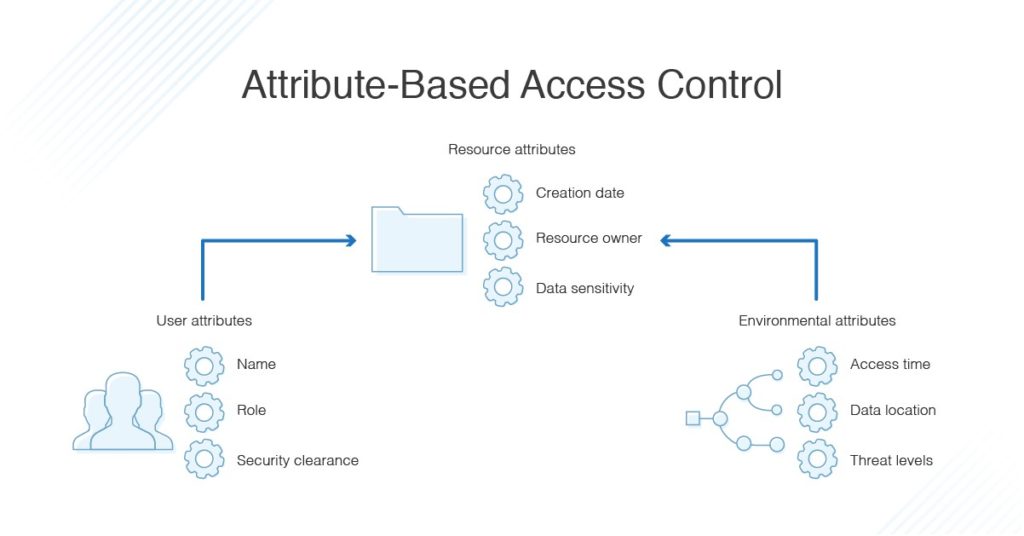
What Is Attribute-Based Access Control?
Someone logs into your computer system. What can that person do? ABAC protocols answer that question via the user, the resource attributes, or the environment
As the administrator of a system using ABAC, you can set permissions by:
User. A person's job title, typical tasks, or seniority level could determine the work that can be done.
Resource attributes. The type of file, the person who made it, or the document's sensitivity could determine access.
Environment. Where the person is accessing the file, the time of day, or the calendar date could all determine access.
In ABAC, elements work together in a coordinated fashion.
Subjects: Who is trying to do the work?
Objects: What file within the network is the user trying to work with?
Operation. What is the person trying to do with said file?
Relationships are defined by if/then statements. For example:
If the user is in accounting, then the person may access accounting files.
If the person is a manager, then that person may read/write files.
If the company policy specifies “no Saturday work” and today is Saturday, then no one may access any files today.
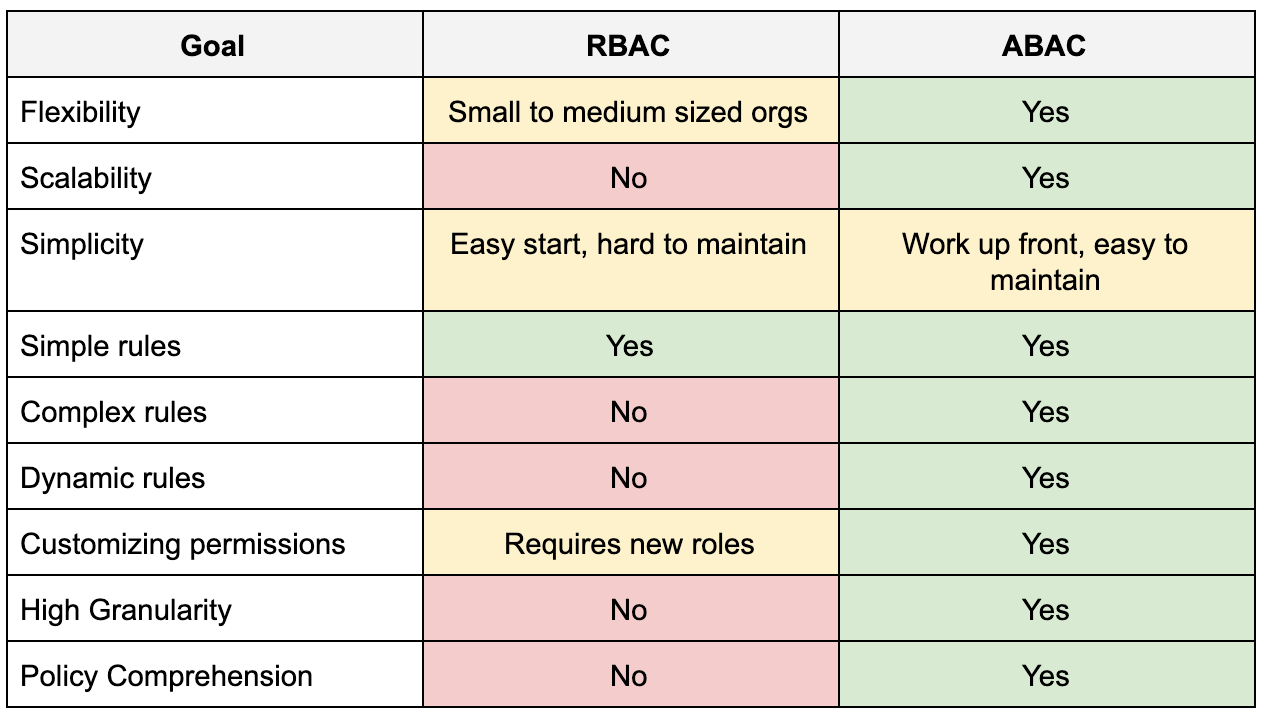
RBAC vs. ABAC: Pros & Cons
ABAC Cons
Time constraints
Defining variables and configuring your rules is a massive effort, especially at project kickoff.
RBAC Con
Role explosions
To add granularity to their systems, some administrators add more roles. That can lead to what researchers call "role explosions" with hundreds or even thousands of rules to manage.
5 Identity Management Scenarios to Study
1. Small workgroups. RBAC is best. Defining work by role is simple when the company is small and the files are few.
If you work within a construction company with just 15 employees, an RBAC system should be efficient and easy to set up.
2. Geographically diverse workgroups. ABAC is a good choice. You can define access by employee type, location, and business hours. You could only allow access during business hours for the specific time zone of a branch
3. Time-defined workgroups. ABAC is preferred. Some sensitive documents or systems shouldn't be accessible outside of office hours. An ABAC system allows for time-based rules.
4. Simply structured workgroups. RBAC is best. Your company is large, but access is defined by the jobs people do.
For example, a doctor's office would allow read/write scheduling access to receptionists, but those employees don't need to see medical test results or billing information. An RBAC system works well here.
5. Creative enterprises. ABAC is ideal because creative companies often use their files in unique ways. Sometimes, everyone needs to see certain documents; other times, only a few people do. Access needs change by the document, not by the roles.
The complexity of who should see these documents, and how they are handled, is best accomplished with ABAC.
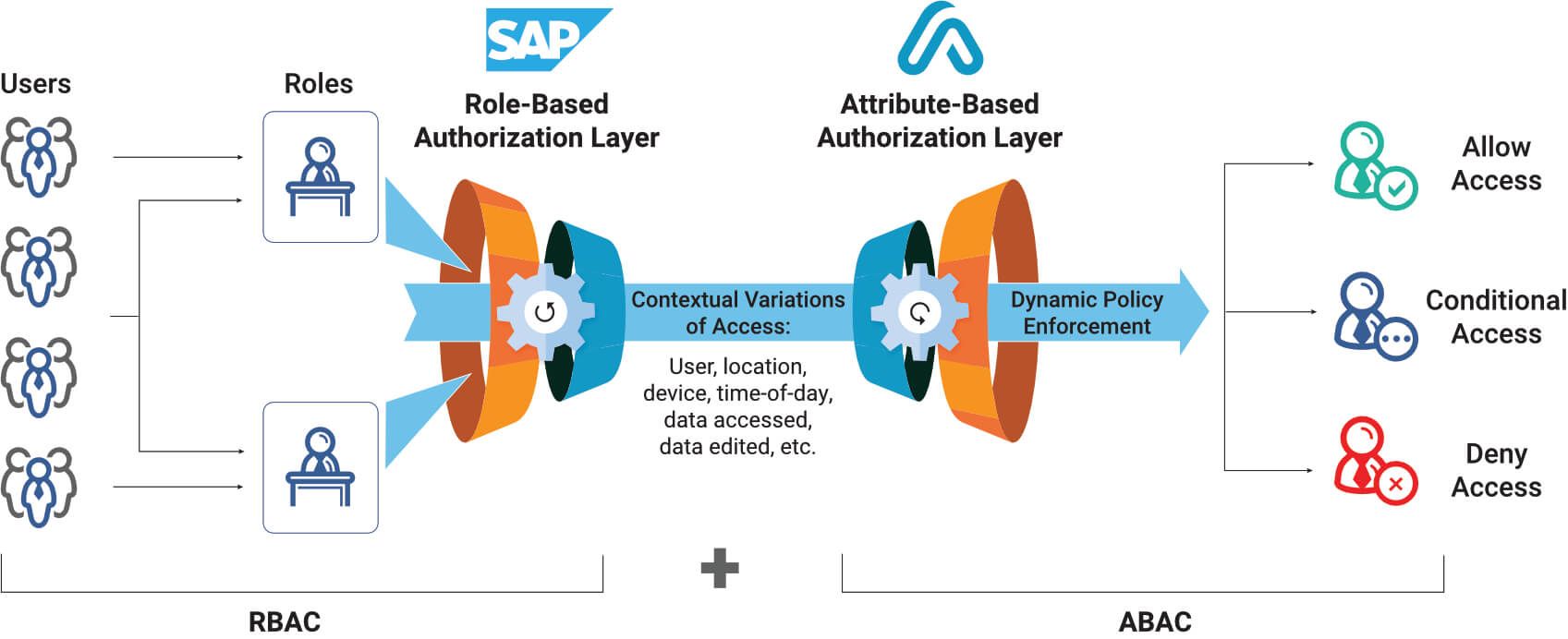
Many times neither RBAC or ABAC will be the perfect solution to cover all the use cases you need. That’s why most organizations use a hybrid system, where high-level access is accomplished through RBAC and then fine-grained controls within that structure are accomplished through ABAC.
For example, you might use the RBAC system to hide sensitive servers from new employees. Then, you might use ABAC systems to control how people alter those documents once they do have access.
RBAC offers leak-tight protection of sensitive files, while ABAC allows for dynamic behavior. Blending them combines the strengths of both.
https://www.okta.com/identity-101/role-based-access-control-vs-attribute-based-access-control/
- RBAC vs. ABAC: What’s the Difference?
In any company, network users must be both authenticated and authorized before they can access parts of the system
The process of gaining authorization is called access control.
Authentication and Authorization
The two fundamental aspects of security are authentication and authorization. After you enter your credentials to log in to your computer or sign in to an app or software, the device or application undertakes authentication to determine your level of authorization. Authorization may include what accounts you can use, what resources you have access to, and what functions you are permitted to carry out.
Role-Based Access Control (RBAC) vs. Attribute-Based Access Control (ABAC)
The primary difference between RBAC and ABAC is RBAC provides access to resources or information based on user roles, while ABAC provides access rights based on user, environment, or resource attributes.
Essentially, when considering RBAC vs. ABAC, RBAC controls broad access across an organization, while ABAC takes a fine-grain approach.
RBAC is role-based, so depending on your role in the organization, you will have different access permissions. This is determined by an administrator, who sets the parameters of what access a role should have, along with which users are assigned which roles. For instance, some users may be assigned to a role where they can write and edit particular files, whereas other users may be in a role restricted to reading files but not editing them.
An organization might use RBAC for projects like this because with RBAC, the policies don’t need to be changed every time a person leaves the organization or changes jobs: they can simply be removed from the role group or allocated to a new role. This also means new employees can be granted access relatively quickly, depending on the organizational role they fulfill.
Essentially, ABAC has a much greater number of possible control variables than RBAC.
For example, instead of people in the HR role always being able to access employee and payroll information, ABAC can place further limits on their access, such as only allowing it during certain times or for certain branch offices relevant to the employee in question.
This can reduce security issues and can also help with auditing processes later.
RBAC vs. ABAC
Generally, if RBAC will suffice, you should use it before setting up ABAC access control. Both these access control processes are filters with ABAC being the more complex of the two, requiring more processing power and time.
In many cases, RBAC and ABAC can be used together hierarchically, with broad access enforced by RBAC protocols and more complex access managed by ABAC.
This means the system would first use RBAC to determine who has access to a resource, followed by ABAC to determine what they can do with the resource and when they can access it.
https://www.dnsstuff.com/rbac-vs-abac-access-control








- What’s Access Control?
Think of a company’s network and resources as a secure building. The only entry point is protected by a security guard, who verifies the identity of anyone and everyone entering the building. If someone fails to prove their identity, or if they don’t have the necessary rights to enter the building, they are sent away. In this analogy, the security guard is like an access control mechanism, which lays the foundation of a company’s security infrastructure.
What is Role-Based Access Control (RBAC)?
In an RBAC system, people are assigned privileges and permissions based on their “roles.” These roles are defined by an administrator who categorizes people based on their departments, responsibilities, seniority levels, and/or geographical locations.
For example, a chief technology officer may have exclusive access to all the company’s servers. A software engineer may only have access to a small subset of application servers.
E.g., a third-party contractor is assigned the outsider role, which grants them access to a server for x hours. On the other hand, an internal software developer may be allowed indefinite access to the same server.
It’s also possible for one user to be assigned multiple roles. For example, a software architect oversees different teams that are building different projects. They need access to all the files related to all these projects. To this end, the administrator assigns them multiple roles with each giving them access to files from a particular project.
Types of RBAC
The NIST model for role-based access control defines the following RBAC categories:
Flat RBAC: Each employee is assigned at least one role, but some can have more than one. If someone wants access to a new file/resource/server, they need to first obtain a new role.
Hierarchical RBAC: Roles are defined based on seniority levels. In addition to their own privileges, senior employees also possess those of their subordinates.
Constrained RBAC: This model introduces separation of duties (SOD). SOD spreads the authority of performing a task, across multiple users, reducing the risk of fraudulent and/or risky activities. E.g., if a developer wants to decommission a server, they need approval from not only their direct manager, but also the head of infrastructure. This gives the infrastructure head a change to deny risky and/or unnecessary requests.
Symmetric RBAC: All organizational roles are reviewed regularly. As a result of these reviews, privileges may get assigned or revoked, and roles may get added or removed.
In an ABAC environment, when a user logs in, the system grants or rejects access based on different attributes.
User. In ABAC terms, the requesting user is also known as the subject. User attributes can include designation, usual responsibilities, security clearance, department, and/or seniority levels.
For example, let’s say Bob, a payroll analyst, tries to access the HR portal. The system checks their “department,” “designation,” and “responsibilities” attributes to determine that they should be allowed access
Accessed resource. This can include name and type of the resource (which can be a file, server, or application), its creator and owner, and level of sensitivity.
For example, Alice tries to access a shared file which contains the best practices for software development. Since the “sensitivity level” attribute for the file is low, Alice is allowed access to it, even though she doesn’t own it. However, if she tries to access a file from a project she doesn’t work on, the “file owner” and “sensitivity level” attributes will prevent her from doing so.
Action. What is the user trying to do with the resource? Relevant attributes can include “write,” “read,” “copy,” “delete,” “update,” or “all.”
For example, if Alice only has the “read” attribute set in her profile, for a particular file, she will not be allowed to update the source code written in that file. However, someone with the “all” attribute set can do whatever they want.
Environment. Some of the considered attributes are time of day, the location of the user and the resource, the user device and the device hosting the file.
For example, Alice may be allowed to access a file in a “local” environment, but not when it’s hosted in a “client” environment.
RBAC vs. ABAC: Pros and Cons
RBAC CONS
To establish granular policies, administrators need to keep adding more roles. This can very easily lead to “role explosion,” which requires administrators to manage thousands of organizational roles.
In the event of a role explosion, translating user requirements to roles can be a complicated task.
ABAC CONS
Can be hard to implement, especially in time-constrained situations
Recovering from a bad ABAC implementation can be difficult and time-consuming.
Implementing ABAC often requires more time, resources, and expensive tooling, which add to the overall cost. However, a successful ABAC implementation can be a future-proof, financially viable investment.
When to use RBAC or ABAC?
ABAC is widely considered an evolved form of RBAC
Choose ABAC if you:
have the time, resources, and budget for a proper ABAC implementation
in a large organization, which is constantly growing. ABAC enables scalability
Have a workforce that is geographically distributed. ABAC can help you add attributes based on location and time-zone.
Want as granular and flexible an access control policy as possible
Want to future-proof your access control policy. The world is evolving, and RBAC is slowly becoming a dated approach. ABAC gives you more control and flexibility over your security controls.
Choose RBAC if you:
Are in a small-to-medium sized organization
Have well-defined groups within your organization, and applying wide, role-based policies makes sense.
Have limited time, resources, and/or budget to implement an access control policy.
Don’t have too many external contributors and don’t expect to onboard a lot of new people.
https://www.onelogin.com/learn/rbac-vs-abac
- The System for Cross-domain Identity Management (SCIM)
http://www.simplecloud.info/
SCIM, or System for Cross-domain Identity Management, is an open standard that allows for the automation of user provisioning.
Why use SCIM?
SCIM communicates user identity data between identity providers (such as companies with multiple individual users) and service providers requiring user identity information (such as enterprise SaaS apps).
With SCIM, user identities can
Employees outside of IT can take advantage of
How it works
SCIM is a
https://www.okta.com/blog/2017/01/what-is-scim/


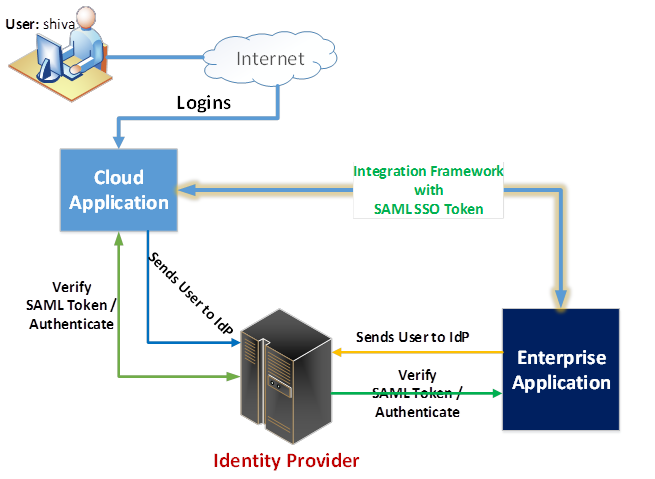
- Security Assertion Markup Language (SAML)
Using Security Assertion Markup Language (SAML) web browser single sign-on (SSO), administrators can use an identity provider to manage the identities of their users and the applications they use.
Supported SAML services
We offer limited support for all identity providers that implement the SAML 2.0 standard. We officially support these identity providers that have
Active Directory Federation Services (AD FS)
Azure Active Directory (Azure AD)
Okta
OneLogin
Shibboleth
https://help.github.com/en/articles/about-identity-and-access-management-with-saml-single-sign-on



- Security Assertion Markup Language (SAML) is an open standard that allows identity providers (IdP) to pass authorization credentials to service providers (SP).
SAML is the link between the authentication of a user’s identity and the authorization to use a service.
SAML enables Single-Sign On (SSO), a term that means users can log in once, and
What is SAML Used For?
SAML simplifies federated authentication and authorization processes for users, Identity providers, and service providers.
SAML provides a solution to allow your identity provider and service providers to exist separately from each other, which centralizes user management and provides access to SaaS solutions.
SAML authentication is
SAML vs.
Facebook and Google are two
What is
Authentication assertions prove identification of the user and provide the time the user logged in and what method of authentication they used (I.e., Kerberos, 2 factor, etc.)
The attribution assertion passes the SAML attributes to the service provider
An authorization decision assertion says if
https://www.varonis.com/blog/what-is-saml/
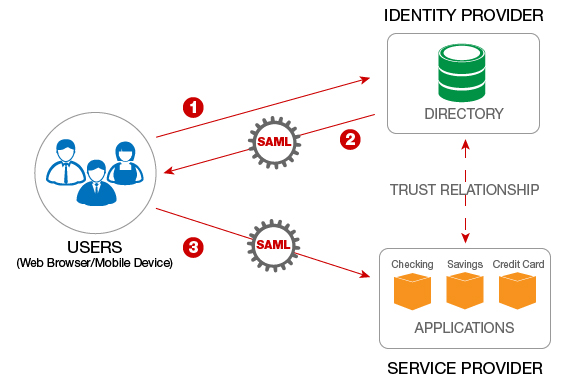
SAML – – Applications Security
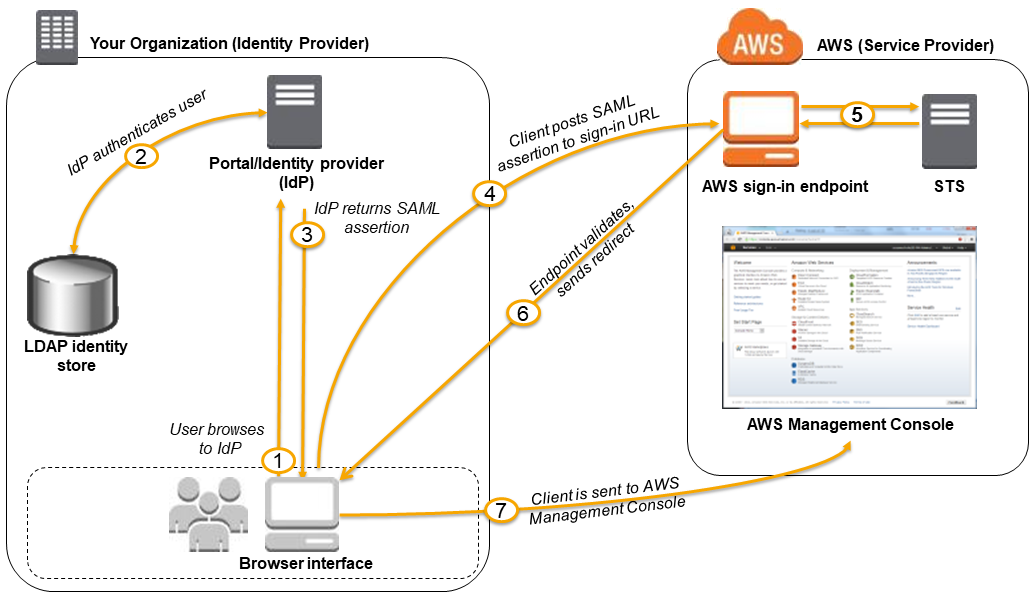
Enabling SAML 2.0 Federated Users to Access the AWS Management Console
OpenID OAuth
The gradual integration of applications and services external to an organization’s domain motivated both the creation and adoption of federated identity services
Single sign-on (SSO), a forerunner to identity federation, was an effective solution which could manage a single set of user credentials for resources which existed within a single domain
Federated identities offered organizations the opportunity to preserve the benefits of SSO while extending the reach of a user’s credentials to include external resources which reduces costs and when implemented correctly, can increase security.
preferred 3rd party
For developers,
The
The end user or the entity that is looking to verify its identity
The relying party (RP), which is the entity looking to verify the identity of the end user
The OpenID Connect provider (OP), which is the entity that registers the OpenID URL and can verify the end user’s identity
SAML v2.0
Security Assertion Markup Language (SAML) is
The SAML specification defines three roles,
The principal, which is typically the user looking to verify his or her identity
The identity provider (
The service provider (SP), which is the entity looking to use the identity provider to verify the identity of the end user
The
The end user or the entity that owns the resource in question
The resource server (
The client (
https://www.softwaresecured.com/differentiating-federated-identities-openid-connect-saml-v2-0-and-oauth-2-0/
Radiant Logic: What is a Federated Identity Service?
Logical layer that Federated Identity Service
1- Authentication and SSO
2- Authorization
SSO: Global view of all your identities without overlapping users
one user may have multiple identifiers or two different users may share same identifier
You send tokens not passwords across the firewall
easy migration from on-premises/cloud to on-premises/cloud
easy implementation for company mergings
Identity, Authentication + OAuth OpenID
OAuth OpenId
OAuth defined
OpenId defined OpenId are built
Delegated Authorization
Let’s say Joe owns certain resources( eg. are hosted eg. . that he is using (eg. be able to . server, authorize .
OAuth
In the above exampleJoe is considered resides ( . server) is called the “Resource Server”. The Yelp App that is trying to access the resources on the resource server is called the “Client”.
Joe (resource owner) is “delegating” the responsibility to “authorize ( ) . .
Federated Authentication
Federated Authentication is the ability for you to login to an App (eg.
In this case
Federated Authentication allows you to login to a site using your facebook or google account.
Delegated Authorization is the ability of an external app to access resources. This use case would be for example Spotify trying to access your google contacts list to import it into Spotify.
OpenId
There are two popular industry standards for Federated Authentication. SAML (or Security Assertion Markup Language) flow, andOpenId
OpenId OAuth
SAML flow is independent ofOAuth 0,
Both flows allow for SSO (Single Sign On), i.e. the ability to log into a website using your login credentials from a different site (eg.
OpenId OAuth is tried
SAML is its oldercousin, eg.
https://hackernoon.com/demystifying-oauth-2-0-and-openid-connect-and-saml-12aa4cf9fdba



How To: Cisco & F5 Deployment Guide: ISE Load Balancing Using BIG-IP
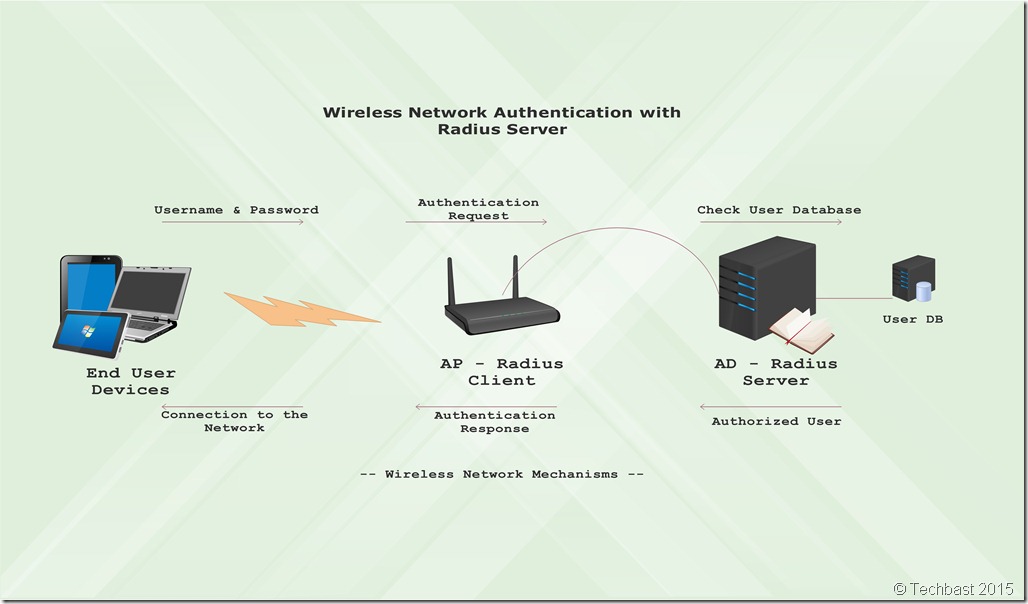 Setting up Radius Server Wireless Authentication in Windows Server 2012 R2
Setting up Radius Server Wireless Authentication in Windows Server 2012 R2
 Setup radius server 2008 r2 for wireless
Setup radius server 2008 r2 for wireless(
 WiFi with WSSO using Windows NPS and
WiFi with WSSO using Windows NPS and FortiGate
 RADIUS Bridge provides Two-Factor authentication with all
RADIUS Bridge provides Two-Factor authentication with all OpenOTP One-Time Password methods

 Integrate your existing NPS infrastructure with Azure Multi-Factor Authentication
Integrate your existing NPS infrastructure with Azure Multi-Factor Authentication
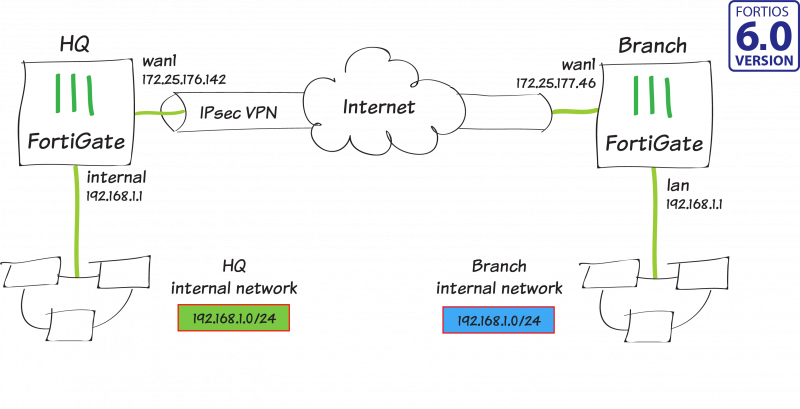 Site-to-site
Site-to-site IPsec
 Security Partner Ecosystem
Security Partner Ecosystem
 Dynamic Security for AWS
Dynamic Security for AWS
only the correct combination of a bank card
(something that the user possesses) and a PIN (personal identification
number, something that the user knows) allows the transaction to be carried out.
https://en.wikipedia.org/wiki/Multi-factor_authentication
In the enterprise, two-factor Web authentication systems rely on hardware-based security tokens that generate passcodes; these passcodes or PINs are valid for about 60 seconds and mustbe entered each and
https://searchsecurity.techtarget.com/tip/Intro-to-two-factor-authentication-in-Web-authentication-scenarios
But because usernames and passwords fall are under the same factor, when combined they formwhat is known as single authentication factors can be divided generally
A knowledge authentication factor includes information only a user should know (i.e
A possession authentication factor includes credentials retrieved from a user’s physical possession, usually in thefrom
An inherence authentication factor includes a user’s identifiable biometric characteristic (i.e. fingerprint, voice, iris scan)
https://www.cloudbric.com/blog/2017/07/two-factor-vs-multi-factor-authentication/





Yubico
YubiKeys
Say you have an existingGMail decide to
Without an API for exchanging this list of contacts, you would have to give LinkedIn the username and password to yourGMail thereby
This is whereOAuth GMail OAuth authorize GMail
I have supposed a scenario where a website( stackoverflow oAuth and stackoverflow oAuth
This is the best part user( stackoverflow
Only then facebook will give access token tostackoverflow is used stackoverflow retrive password
http://stackoverflow.com/questions/4201431/what-exactly-is-oauth-open-authorization
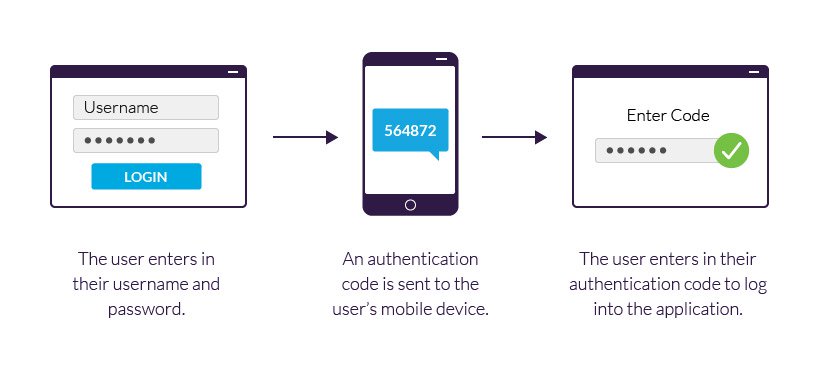
Two-step verification is a method of authentication that requiresmore than
Something you know (typically a password)
Something you have (a trusted device thatis not easily duplicated
Something you are (biometrics)
https://docs.microsoft.com/en-us/azure/multi-factor-authentication/multi-factor-authentication


- Demystifying
OAuth OpenId
Delegated Authorization
Let’s say Joe owns certain resources
In the above example
Joe (resource owner) is “delegating” the responsibility to “
Federated Authentication
Federated Authentication is the ability for you to login to an App (
Federated Authentication allows you to login to a site using your facebook or google account.
Delegated Authorization is the ability of an external app to access resources. This use case would be for example Spotify trying to access your google contacts list to import it into Spotify.
There are two popular industry standards for Federated Authentication. SAML (or Security Assertion Markup Language) flow, and
SAML flow is independent of
Both flows allow for SSO (Single Sign On), i.e. the ability to log into a website using your login credentials from a different site (
SAML is its older
https://hackernoon.com/demystifying-oauth-2-0-and-openid-connect-and-saml-12aa4cf9fdba
- Multi-factor authentication (MFA) is a method of computer access control in which a user
is granted several separate –
- Two-factor authentication (also known as 2FA) is a method of confirming a user's claimed identity by
utilizing type of
https://en.wikipedia.org/wiki/Multi-factor_authentication
All 2FA systems are based possible obtains would not be able to
In the enterprise, two-factor Web authentication systems rely on hardware-based security tokens that generate passcodes; these passcodes or PINs are valid for about 60 seconds and must
https://searchsecurity.techtarget.com/tip/Intro-to-two-factor-authentication-in-Web-authentication-scenarios
- Loosely defined, an authentication factor is a category of methods
for verifying a user’s identity when requesting access to a system.
Simply put that they are who they say they are.
But because usernames and passwords fall are under the same factor, when combined they form
A knowledge authentication factor includes information only a user should know (
A possession authentication factor includes credentials retrieved from a user’s physical possession, usually in the
An inherence authentication factor includes a user’s identifiable biometric characteristic (i.e. fingerprint, voice, iris scan)
https://www.cloudbric.com/blog/2017/07/two-factor-vs-multi-factor-authentication/
- Universal 2nd Factor (U2F) is an open authentication standard that strengthens and simplifies
two
https://en.wikipedia.org/wiki/Universal_2nd_Factor
The use of was supposed
2FA
implementations have their own limitations. For example, when your
2-factor authentication relies on a verification code sent through an
SMS text message, crooks can break it by using social engineering or
compromising the user's phone. Using smartphones as a second
authentication factor also presents other risks, such as the need to
protect the application logic from malware.
Another
challenge for implementing two-factor authentication is the price tag.
Companies such as Google or Facebook that have billions of users can't
implement expensive or complex solutions, such as providing every user
with a unique token or smart card for its service, because this would be
too expensive.
The U2F open authentication standard, created by Google and Yubico
https://techbeacon.com/security/beyond-two-factor-how-use-u2f-improve-app-security
- At
Yubico we are often asked YubiKeys
As good as it is, traditional OTP has limitations.
Users need to
Manufacturers often possess the seed value of the tokens.
Administrative overhead resulting from having to set up and provision devices for users.
The technology requires the storage of secrets on servers, providing a single point of attack.
The user never has to type a code instead he just touches a button.
Enterprises can configure their own encryption secrets on a YubiKey
OTPs generated by a YubiKey
It is easy to implement with any existing website with no client software needed.
For the OATH standard, Yubico be used
https://www.yubico.com/2016/02/otp-vs-u2f-strong-to-stronger/
OAuth
Say you have an existing
Without an API for exchanging this list of contacts, you would have to give LinkedIn the username and password to your
This is where
I have supposed a scenario where a website
This is the best part user
Only then facebook will give access token to
http://stackoverflow.com/questions/4201431/what-exactly-is-oauth-open-authorization
OAuth authorize . mechanism is used by companies third party
OAuth OAuth OAuth OAuth
- Microsoft Azure Multi-Factor Authentication (MFA) is an
authentication service that requires users to verify their sign-in
attempts by using a mobile app,
phone Azure MFA can be used
- What is Azure Multi-Factor Authentication?
Two-step verification is a method of authentication that requires
Something you know (typically a password)
Something you have (a trusted device that
Something you are (biometrics)
https://docs.microsoft.com/en-us/azure/multi-factor-authentication/multi-factor-authentication
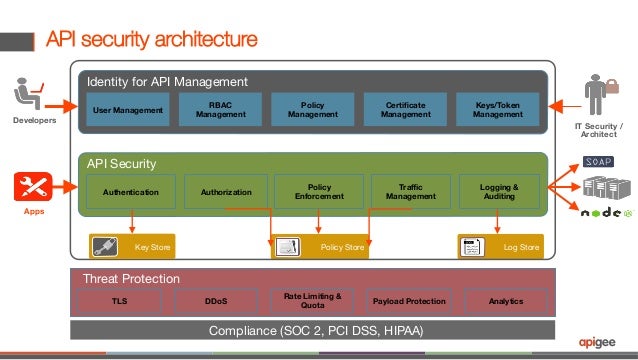
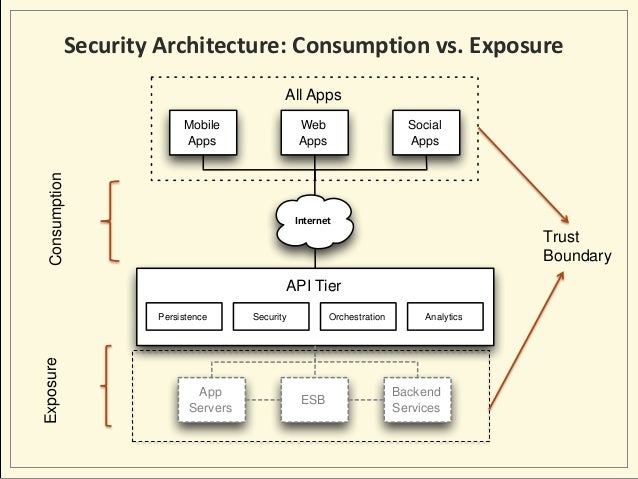
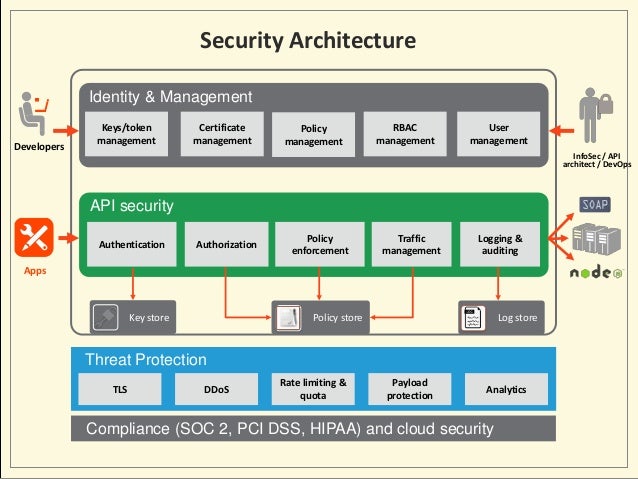
How to Achieve Agile API Security
Four Pillars of API Security
 Ensuring the Security of Your APIs
Ensuring the Security of Your APIs










a business may have an internal-facing employee portal with links to intranet sites regarding timesheets, health insurance, or company news. Rather than requiring an employee to log in at each website, a better solution would be to have the employee log in at a portal, and have that portal automatically authenticate the user with the other intranet sites. This idea, called single sign-on (SSO), allows a user to enter one username and password in order
the use of. single be stored developers of the various applications don’t have to store passwords. Instead, they can accept proof of identity or authorization from a trusted source.
OpenID
OpenID
OpenID . openid to manually enter OpenID
OAuth2 OAuth2 OAuth2 OAuth2
an OAuth2 is offered she is redirected is asked yes, is forwarded
OAuth2 OAuth completely OpenId
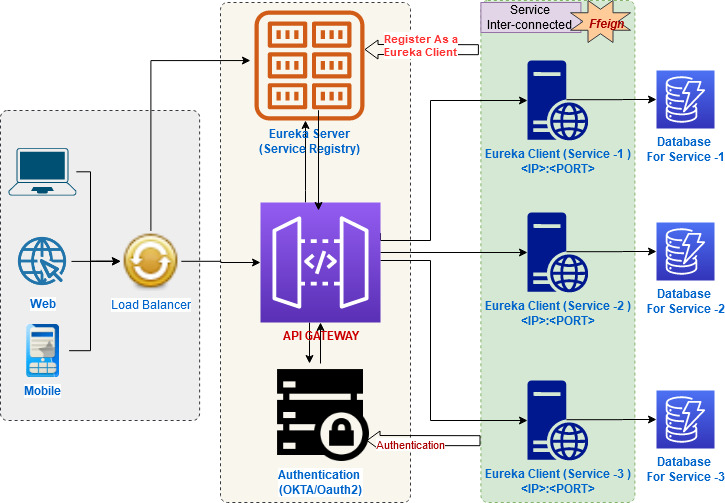


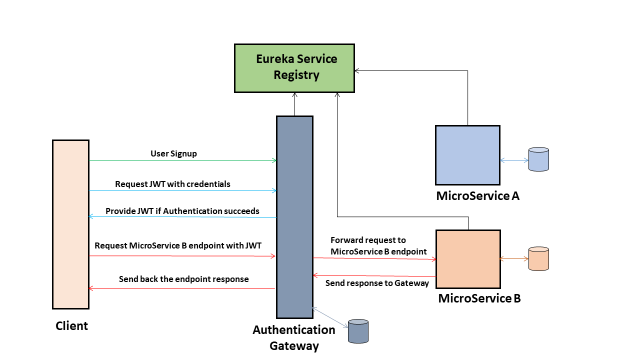

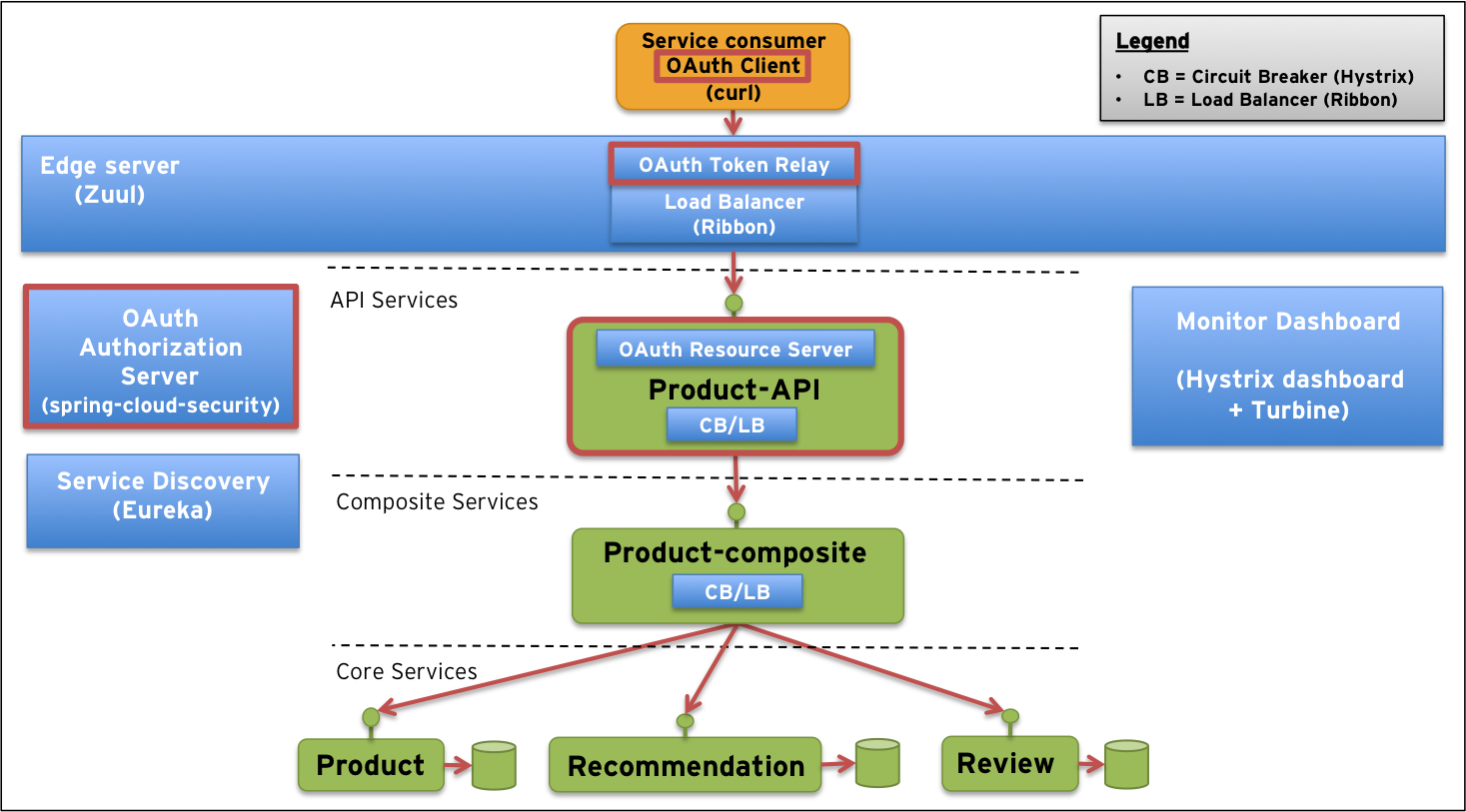
Building microservices OAuth
API Security from the DevOps and CSO Perspectives (Webcast)
- Authentication and Authorization:
OpenID OAuth2
what’s going on when you click that ubiquitous “Sign in with Google/Facebook” button.
Authorization & Authentication Basics
Our project, a single-page application, will be a public-facing website.
We want to restrict access to registered users only.
we want to tailor each user’s experience, and the amount and type of data that they can view, to their individual roles and access levels.
Authentication means verifying that someone is indeed
Authorization means deciding which resources a certain user should be able to access, and what they should be allowed
With sites like Facebook or Google, a user can log in to one application with a set of credentials. This same set of credentials can then be used to log in to related websites or applications (like websites that ask you, “Sign up with Facebook or Google account?”).
There are multiple solutions for implementing SSO. The three most common web security protocols (at the time of this writing) are OpenID OAuth
A user must obtain
The latest version of OpenID is OpenID Connect, which combines OpenID authentication and OAuth2
SAML
It’s an open standard that provides both authentication and authorization.
Security Risks
Phishing
Phishing
Identity providers have a log of OpenID
SAML
XML Signature Wrapping to impersonate any user
https://spin.atomicobject.com/2016/05/30/openid-oauth-saml/
- microservices are the new application platform for cloud development. Microservices are deployed and managed independently, and once implemented inside containers they have very little interaction with the underlying OS.
What are the features of Microservices?
Decoupling – Services within a system are largely decoupled. So the application as a whole can be easily built, altered, and scaled
Componentization – Microservices are treated as independent components that can be easily replaced and upgraded
Business Capabilities – Microservices are very simple and focus on a single capability
Autonomy – Developers and teams can work independently of each other, thus increasing speed
Continous Delivery – Allows frequent releases of software, through systematic automation of software creation, testing, and approval
Responsibility – Microservices do not focus on applications as projects. Instead, they treat applications as products for which they are responsible
Decentralized Governance – The focus is on using the right tool for the right job. That means there is no standardized pattern or any technology pattern. Developers have the freedom to choose the best useful tools to solve their problems
Agility – Microservices support agile development. Any new feature can be quickly developed and discarded again
What are the best practices to design Microservices?
seperate datastore for each microservice
seperate build for each microservice
treat servers as stateless
deploy into containers
How does Microservice Architecture work?
Clients – Different users from various devices send requests.
Identity Providers – Authenticates user or clients identities and issues security tokens.
API Gateway – Handles client requests.
Static Content – Houses all the content of the system.
Management – Balances services on nodes and identifies failures.
Service Discovery – A guide to find the route of communication between microservices.
Content Delivery Networks – Distributed network of proxy servers and their data centers.
Remote Service – Enables the remote access information that resides on a network of IT devices.
What are the pros and cons of Microservice Architecture?
Cons of Microservice Architecture
Increases troubleshooting challenges
Increases delay due to remote calls
Increased efforts for configuration and other operations
Difficult to maintain transaction safety
Tough to track data across various boundaries
Difficult to code between services
What is the difference between Monolithic, SOA and Microservices Architecture?
Monolithic Architecture is similar to a big container wherein all the software components of an application are assembled together and tightly packaged.
A Service-Oriented Architecture is a collection of services which communicate with each other. The communication can involve either simple data passing or it could involve two or more services coordinating some activity.
Microservice Architecture is an architectural style that structures an application as a collection of small autonomous services, modeled around a business domain.
What is REST/RESTful and what are its uses?
Microservices can be implemented with or without RESTful APIs, but it’s always easier to build loosely coupled microservices using RESTful APIs.
What is OAuth?
OAuth stands for open authorization protocol. This allows accessing the resources of the resource owner by enabling the client applications on HTTP services such as third-party providers Facebook, GitHub, etc. So with this, you can share resources stored on one site with another site without using their credentials.
What is End to End Microservices Testing?
End-to-end testing validates each and every process in the workflow is functioning properly. This ensures that the system works together as a whole and satisfies all requirements.
What is the use of Container in Microservices?
You can encapsulate your microservice in a container image along with its dependencies, which then can be used to roll on-demand instances of microservice without any additional efforts required.
What is the role of Web, RESTful APIs in Microservices?
each microservice must have an interface. This makes the web API a very important enabler of microservices. Being based on the open networking principles of the Web, RESTful APIs provide the most logical model for building interfaces between the various components of a microservice architecture.
https://www.edureka.co/blog/interview-questions/microservices-interview-questions/
- How to implement security for microservices
Microservices Security can be implemented either using OAuth2 or JWT.
Develop a Spring Boot Application to expose a Simple REST GET API with mapping /hello.
Configure Spring Security for JWT. Expose REST POST API with mapping /authenticate using which User will get a valid JSON Web Token. And then allow the user access to the api /hello only if it has a valid token
How to implement distributed logging for microservices
Spring Cloud Sleuth is used to generate and attach the trace id, span id to the logs so that these can then be used by tools like Zipkin and ELK for storage and analysis
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in service architectures. Features include both the collection and lookup of this data.
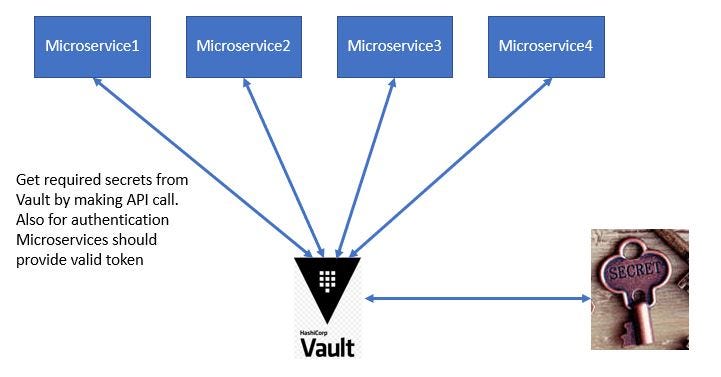
What is Hashicorp Valut? How to use it with microservices
Microservices architecture have multiple services which interact with each other and external resources like databases. They also need access to usernames and passwords to access these resources.
Usually these credentials are stored in config properties.So each microservice will have its own copy of credentials
If any credentials change we will need to update the configurations in all microservices
Hashicorp Vault is a platform to secure, store, and tightly control access to tokens, passwords, certificates, encryption keys for protecting sensitive data and other secrets in a dynamic infrastructure.
Using vault we will be retrieving the credentials from the vault key/value store
https://www.javainuse.com/spring/microservices-interview-quesions

- Understanding the need for JSON Web Token(JWT)
JWT stands for JSON Web Token
It is pronounced as JAWT
It is Open Standard - RFC7519
JWT makes it possible to communicate securely between two bodies
JWT is used for Authorization
In order to understand Authorization we will be taking example of user interaction with Gmail. Consider a scenario where a user wants to access his Gmail inbox page. This will involve user interaction with the Gmail server. For this the user will be sending HTTP requests to Gmail server and in response will expect the response from Gmail Server.
The steps will be as follows-
The user will send a http request to Gmail server with url /login. Along with this request the user will also be sending the username and password for authentication.
The Gmail server will authenticate this request if it is successful it will return the Gmail inbox page as response to the user.
Now suppose the user wants to access his sent mail page, so he will again send a request to the Gmail server with url /sentmails. This time he will not be sending the username and password since he user has already auntenticated himself in the first request.
The user expects Gmail to return the sent mail page. However this will not be the case. The Gmail server will not return the sent mail page but will instead not recognize the user.
The reason for this is HTTP is a stateless protocol. As the name suggests no state is maintained by HTTP. So in case of HTTP protocol for the Gmail server each request is from a new user. It cannot distinguish between new and returning users. One solution for this issue could be to pass username and password along with each request. But then this is not a good solution.
Once a user has been authenticated. For all subsequent requests the user should be authorized to perform allowed operations
Authorization can be implemented using
Session Management
JSON Web Token
Drawbacks of Session Management for Authorization
Session Id is not self contained. It is a reference token. During each validation the Gmail server needs to fetch the information corresponding to it.
Not suitable for microservices architecture involving multiple API's and servers
Using JWT for Authorization
We make use of the JWT for authorization so the server will know that the user is already authenticated and so the user does not need to send the credentials with each and every request.
Advantages of JWT Authorization
JWT is self contained. It is a value token. So during each validation the Gmail server does not needs to fetch the information corresponding to it.
It is digitally signed so if any one modifies it the server will know about it
It is most suitable for Microservices Architecture
It has other advantages like specifying the expiration time.
https://www.javainuse.com/webseries/spring-security-jwt/chap1
- Understand JSON Web Token(JWT) Structure
A JWT consists of 3 parts -
Header
Payload
Signature
The 3 parts of JWT are seperated by a dot.Also all the information in the 3 parts is in base64 encoded format.
An important point to remember about JWT is that the information in the payload of the JWT is visible to everyone. There can be a "Man in the Middle" attack and the contents of the JWT can be changed. So we should not pass any sensitive information like passwords in the payload. We can encrypt the payload data if we want to make it more secure
https://www.javainuse.com/webseries/spring-security-jwt/chap2
Learn the basics of Microservices, Docker, and Kubernetes with us! Watch our video at Nooble to gain complete information regarding the introduction to Microservices.
ReplyDeleteOauth Microservices