Relational Persistence for Java and .NET.Historically, Hibernate facilitated the storage and retrieval of Java domain objects via Object/Relational Mapping. Today, Hibernate is a collection of related projects enabling developers to utilize POJO-style domain models in their applications in ways extending well beyond Object/Relational Mapping.
http://www.hibernate.org
Oracle TopLink
Oracle TopLink delivers a proven standards based enterprise Java solution for all of your relational and XML persistence needs based on high performance and scalability, developer productivity, and flexibility in architecture and design.
http://www.oracle.com/technetwork/middleware/toplink/overview/index.html
Castor
Castor is an Open Source data binding framework for Java[tm]. It's the shortest path between Java objects, XML documents and relational tables. Castor provides Java-to-XML binding, Java-to-SQL persistence, and more.
http://www.castor.org/
FireStorm/DAO
FireStorm/DAO makes Java software developers more productive by automatically generating Java source code for data persistence.
http://www.codefutures.com/object-persistence/
ObJect Relational Bridge
Apache ObJectRelationalBridge (OJB) is an Object/Relational mapping tool that allows transparent persistence for Java Objects against relational databases
http://db.apache.org/ojb/
iBATIS / mybatis
Apache iBATIS is retired at the apache software foundation (2010/06/16)
The MyBatis data mapper framework makes it easier to use a relational database with object-oriented applications. MyBatis couples objects with stored procedures or SQL statements using a XML descriptor or annotations. Simplicity is the biggest advantage of the MyBatis data mapper over object relational mapping tools.
http://code.google.com/p/mybatis/
http://www.mybatis.org/
http://ibatis.apache.org/
EclipseLink
The EclipseLink project delivers a comprehensive open-source Java persistence solution addressing relational, XML, and database web services. It will run in any Java environment and read and write objects to virtually any type of data source, including relational databases, XML, or EIS systems EclipseLink will focus on providing leading edge support, including advanced feature extensions, for the dominant persistence standards for each target data source; Java Persistence API (JPA) for relational databases, Java API for XML Binding (JAXB) for XML, Java Connector Architecture (JCA) for EIS and other types of legacy systems, and Service Data Objects (SDO). http://www.eclipse.org/eclipselink/
Trac is an enhanced wiki and issue tracking system for software development projects
http://trac.edgewall.org/
Bugzilla
Bugzilla is server software designed to help you manage software development
http://www.bugzilla.org/
Lighthouse
Beautifully Simple Issue Tracking. Collaborate effortlessly on projects
lighthouseapp.com
JIRA
JIRA provides issue tracking and project tracking for software development teams to improve code quality and the speed of development.
http://www.atlassian.com/software/jira/
Mantis
MantisBT is a free popular web-based bugtracking system (feature list). It is written in the PHP scripting language and works with MySQL, MS SQL, and PostgreSQL databases and a webserver.
http://www.mantisbt.org
Confluence
one place online for teams to collaborate and capture knowledge – create, share, and discuss your files, ideas, minutes, specs, mockups, diagrams, and projects.A powerful rich editor, integration with Office and JIRA, and hundreds of add-ons help teams create intranets, technical documentation, and knowledge bases.
http://www.atlassian.com/software/confluence/overview
Redmine
Redmine is a flexible project management web application. Written using the Ruby on Rails framework, it is cross-platform and cross-database. http://www.redmine.org/
The Concurrent Versions System (CVS), also known as the Concurrent Versioning System, is a client-server free software revision control system in the field of software development. Version control system software keeps track of all work and all changes in a set of files, and allows several developers (potentially widely separated in space and/or time) to collaborate.
http://www.march-hare.com/cvspro/
http://savannah.nongnu.org/projects/cvs
SVN
Subversion is an open source version control system
http://subversion.apache.org/
GIT
Git is a free & open source, distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
GitHub is the best way to collaborate with others. Fork, send pull requests and manage all your public and private git repositories.
http://git-scm.com/
What is Git fork? What is the difference between fork, branch, and clone?
A fork is a remote, server-side copy of a repository, distinct from the original.
A clone is not a fork; a clone is a local copy of some remote repository. When you clone, you are actually copying the entire source repository, including all the history and branches.
A branch is a mechanism to handle the changes within a single repository in order to eventually merge them with the rest of code
What's the difference between a "pull request" and a "branch"?
A branch is just a separate version of the code.
A pull request is when someone takes the repository, makes their own branch, does some changes, then tries to merge that branch in (put their changes in the other person's code repository).
What is the difference between "git pull" and "git fetch"?
git pull does a git fetch followed by a git merge.
When you use pull, Git tries to automatically do your work for you. It is context sensitive so Git will merge any pulled commits into the branch you are currently working in. pull automatically merges the commits without letting you review them first. If you don’t closely manage your branches, you may run into frequent conflicts.
When you fetch, Git gathers any commits from the target branch that do not exist in your current branch and stores them in your local repository. However, it does not merge them with your current branch. This is particularly useful if you need to keep your repository up to date, but are working on something that might break if you update your files. To integrate the commits into your master branch, you use merge
How to revert previous commit in git?
git reset --hard HEAD~1
git reset HEAD~1
git status
git reset --soft HEAD~1
What is "git cherry-pick"?
The command git cherry-pick is typically used to introduce particular commits from one branch within a repository onto a different branch. A common use is to forward- or back-port commits from a maintenance branch to a development branch.
git cherry-pick <commit-hash>
Tell me the difference between HEAD, working tree and index, in Git?
The working tree/working directory/workspace is the directory tree of (source) files that you see and edit.
The index/staging area is a single, large, binary file in <baseOfRepo>/.git/index, which lists all files in the current branch, their sha1 checksums, time stamps and the file name - it is not another directory with a copy of files in it.
HEAD is a reference to the last commit in the currently checked-out branch
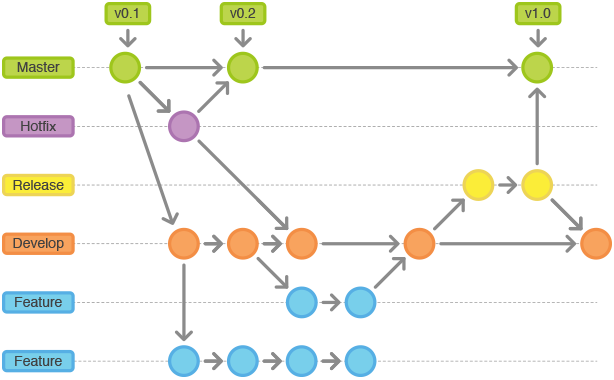
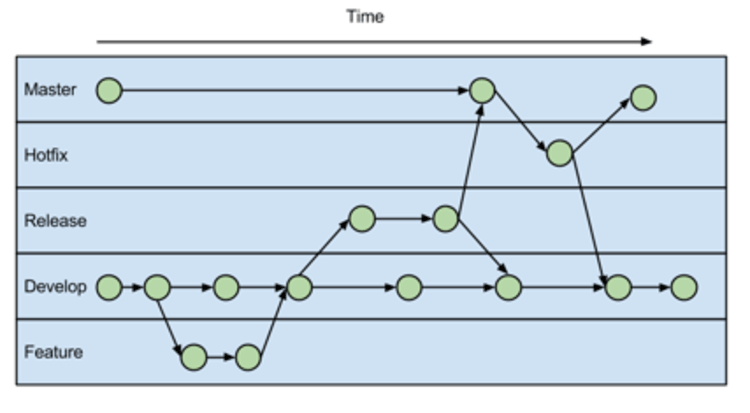
Could you explain the Gitflow workflow? Gitflow workflow employs two parallel long-running branches to record the history of the project, master and develop
Master - is always ready to be released on LIVE, with everything fully tested and approved (production-ready). Hotfix - Maintenance or “hotfix” branches are usedto quickly patch production releases. Hotfix branches are a lot like release branches and feature branches except they're based on master instead of develop.
Develop - is the branch to which all feature branches are merged and where all tests are performed. Only when everything’s been thoroughly checked and fixed it can be merged to the master.
Feature - Each new feature should reside in its own branch, which can be pushed to the develop branch as their parent one.
When should I use "git stash"?
The git stash command takes your uncommitted changes (both staged and unstaged), saves them away for later use, and then reverts them from your working copy.
git status
git stash
git status
# Assume the latest commit was already done
# start working on the next patch, and discovered I was missing something
# stash away the current mess I made
$ git stash save
# some changes in the working dir
# and now add them to the last commit:
$ git add -u
$ git commit --ammend
# back to work!
$ git stash pop
How to remove a file from git without removing it from your file system?
If you are not careful during a git add, you may end up adding files that you didn’t want to commit. However, git rm will remove it from both your staging area (index), as well as your file system (working tree), which may not be what you want.
git reset filename # or
echo filename >> .gitingore # add it to .gitignore to avoid re-adding it
When do you use "git rebase" instead of "git merge"? Both of these commands are designed to integrate changes from one branch into another branch - they just do it in very different ways.
With rebase you say to use another branch as the new base for your work.
git merge master
git rebase master
Is the branch you are getting changes from shared with other developers outside your team (e.g. open source, public)? If so, don't rebase. Rebase destroys the branch and those developers will have broken/inconsistent repositories unless they use git pull --rebase.
How skilled is your development team? Rebase is a destructive operation. That means, if you do not apply it correctly, you could lose committed work and/or break the consistency of other developer's repositories.
Does the branch itself represent useful information? Some teams use the branch-per-feature model where each branch represents a feature (or bugfix, or sub-feature, etc.) In this model the branch helps identify sets of related commits. In case of branch-per-developer model the branch itself doesn't convey any additional information (the commit already has the author). There would be no harm in rebasing.
Might you want to revert the merge for any reason? Reverting (as in undoing) a rebase is considerably difficult and/or impossible (if the rebase had conflicts) compared to reverting a merge. If you think there is a chance you will want to revert then use merge
The Gitflow Workflow defines a strict branching model designed around the project release.
Gitflowis ideally suited for projects that have a scheduled release cycle.
This workflow doesn’t add any new concepts or commands beyond what’s required for the Feature Branch Workflow.
Instead, it assigns very specific roles to different branches and defines how and when they should interact. In addition to feature branches, it uses individual branches for preparing, maintaining, and recording releases. Of course, you also get to leverage all the benefits of the Feature Branch Workflow: pull requests, isolated experiments, and more efficient collaboration.
Gitflow is really just an abstract idea of a Git workflow.
The git-flow toolset is an actual command line tool that has an installation process. The installation process for git-flow is straightforward. Packages for git-flow are available on multiple operating systems
Git-flow is a wrapper around Git. The git flow init command is an extension of the default git init command and doesn't change anything in your repository other than creating branches for you.
Develop and Master Branches
Instead of a single master branch, this workflow uses two branches to record the history of the project. The master branch stores the official release history, and the develop branch serves as an integration branch for features. It's also convenient to tag all commits in the master branch with a version number.
The core idea behind the Feature Branch Workflow is that all feature development should take place in a dedicated branch instead of the master branch. This encapsulation makes it easy for multiple developers to work on a particular feature without disturbing the main codebase. It also means the master branch will never contain broken code, which is a huge advantage for continuous integration environments.
Git plays a vital role when it comes to managing the code that the collaborators contribute to the shared repository. This code is then extracted for performing continuous integration to create a build and test it on the test server and eventually deploy it on the production.
Tools like Git enable communication between the development and the operations team. When you are developing a large project with a huge number of collaborators, it is very important to have communication between the collaborators while making changes in the project. Commit messages in Git play a very important role in communicating among the team. The bits and pieces that we all deploy lies in the Version Control system like Git. To succeed in DevOps, you need to have all of the communication in Version Control
https://www.edureka.co/blog/what-is-git/
What is the difference between Git and SVN?
Git is a Decentralized Version Control tool
Clients can clone entire repositories on their local systems
Commits are possible even if offline
SVN is a Centralized Version Control tool Version history is stored on a server-side repository
Only online commits are allowed
What is ‘bare repository’ in Git?
A “bare” repository in Git just contains the version control information and no working files (no tree) and it doesn’t contain the special .git sub-directory. Instead, it contains all the contents of the .git sub-directory directly in the main directory itself, where as working directory consist of:
A .git subdirectory with all the Git related revision history of your repo.
A working tree, or checked out copies of your project files.
In Git how do you revert a commit that has already been pushed and made public?
There can be two answers to this question
Remove or fix the bad file in a new commit and push it to the remote repository. This is the most natural way to fix an error.
Create a new commit that undoes all changes that were made in the bad commit.
git revert <name of bad commit>
What is the difference between git pull and git fetch?
Git pull command pulls new changes or commits from a particular branch from your central repository and updates your target branch in your local repository.
Git fetch is also used for the same purpose but it works in a slightly different way
When you perform a git fetch, it pulls all new commits from the desired branch and stores it in a new branch in your local repository.
If you want to reflect these changes in your target branch, git fetch must be followed with a git merge.
Git pull = git fetch + git merge
What is ‘staging area’ or ‘index’ in Git?
That before completing the commits, it can be formatted and reviewed in an intermediate area known as ‘Staging Area’ or ‘Index’.
What is Git stash?
Stashing takes your working directory that is, your modified tracked files and staged changes and saves it on a stack of unfinished changes that you can reapply at any time.
Often, when you’ve been working on part of your project, things are in a messy state and you want to switch branches for sometime to work on something else. The problem is, you don’t want to do a commit of half-done work just so you can get back to this point later. The answer to this issue is Git stash.
How do you find a list of files that has changed in a particular commit?
git diff-tree -r {hash}
How do you squash last N commits into a single commit?
There are two options to squash last N commits into a single commit
If you want to write the new commit message from scratch use the following command
git reset –soft HEAD~N &&
git commit
If you want to start editing the new commit message with a concatenation of the existing commit messages then you need to extract those messages and pass them to Git commit for that I will use
git reset –soft HEAD~N &&
git commit –edit -m”$(git log –format=%B –reverse .HEAD@{N})”
What is Git bisect?
This command uses a binary search algorithm to find which commit in your project’s history introduced a bug
Describe branching strategies you have used?
Feature branching
A feature branch model keeps all of the changes for a particular feature inside of a branch. When the feature is fully tested and validated by automated tests, the branch is then merged into master.
Task branching
In this model each task is implemented on its own branch with the task key included in the branch name. It is easy to see which code implements which task, just look for the task key in the branch name
Release branching
Once the develop branch has acquired enough features for a release, you can clone that branch to form a Release branch. Creating this branch starts the next release cycle, so no new features can be added after this point, only bug fixes, documentation generation, and other release-oriented tasks should go in this branch. Once it is ready to ship, the release gets merged into master and tagged with a version number. In addition, it should be merged back into develop branch, which may have progressed since the release was initiated.
How will you know in Git if a branch has already been merged into master?
git branch –merged It lists the branches that have been merged into the current branch.
git branch –no-merged It lists the branches that have not been merged.
What is Git rebase and how can it be used to resolve conflicts in a feature branch before merge? According to me you should start by saying git rebase is a command which will merge another branch into the branch where you are currently working, and move all of the local commits that are ahead of the rebased branch to the top of the history on that branch.
If a feature branch was created from the master, and since then the master branch has received new commits, Git rebase can be used to move the feature branch to the tip of master. The command effectively will replay the changes made in the feature branch at the tip of master, allowing conflicts to be resolved in the process. When done with care, this will allow the feature branch to be merged into master with relative ease and sometimes as a simple fast-forward operation.
Git is a revision control system, a tool to manage your source code history. GitHub is a hosting service for Git repositories
In the SVN analogy, Git replaces SVN, while GitHub replaces SourceForge
If this project of yours is new, then you can still commit to your local Git, then you can push to GitHub later on. You will need to add your GitHub repo as a 'remote repository' in your Git setup.
What branching strategy to use? Should develop branch be stable or not, or to what extent it should be stable
Or, in other words, can you merge your feature branch with the main one and deploy it right away? If no, apparently, your code needs further testing — be it manual or with functional tests. So if you have a single main branch which corresponds to what is currently in production environment, or, in Fowler’s term, a mainline — you can’t just merge your branch in it: time between this merge and the moment when this feature will be tested and all bugs fixed can be significant
So the only viable option is to test those features in their branches and merge into the main branch subsequently, so that there is no way they could unpredictably interfere with each other, but more on testing in the following section.
Typical approach
You write some code, probably with some unit tests. You have no confidence that everything works fine though. Anyway, by the time when you’re done with your user-story you can’t be sure that everything works as expected and you don’t break anything. The worst thing you can do is to keep this code in its own branch and postpone an inevitable pain of code integration until the end of the sprint.
The better option, as mentioned earlier, is to merge it right away into develop branch. After that, your colleagues pull develop into their own branches. Even when none of them writes tests, chances are they encounter wrong behavior, but it’s way easier to fix it, because they know that it was the latest git pull origin develop that broke their branch.So instead of searching for the bug in two-weeks code pile, they just look through the yesterday’s work. And very likely, if they ask about the problem in their dev chat or in the room they all sit in, they will get an answer right away. Once again: it’s easier to find the reason of false behavior if the time between when a bug has appeared and the time it has been discovered is small.
It just doesn’t make any sense to test user stories during the sprint manually since any following commit can break things. Moreover, in case the testing process lingers, it shouldn’t block developers from implementing the user stories from the next sprint. So QA team has to have their own branch for testing the sprint.
Do you recognize what branching strategy corresponds to this workflow? Right, it’s gitflow.
Deployment
Do you deploy manually? Automatically? How long does it take? Are you ready to deploy every commit in the main branch? If no, you probably need to have at least one stable branch that is currently on production and is used for urgent bug fixing, and the second one is, although stable, but due to deploy process difficulties, is deployed, say, once a day.
Microsoft Visual SourceSafe, a file-level version control system that delivers restore point and team coordination capabilities
http://msdn.microsoft.com/en-us/library/ms181038%28v=VS.80%29.aspx
Team Foundation Server
Team Foundation Server (commonly abbreviated to TFS) is a Microsoft product offering source control, data collection, reporting, and project tracking, and is intended for collaborative software development projects
http://en.wikipedia.org/wiki/Team_Foundation_Server
Java CSV Library
Java CSV is a small fast open source java library for reading and writing CSV and plain delimited text files. All kinds of CSV files can be handled, text qualified, Excel formatted, etc
http://sourceforge.net/projects/javacsv
Version control is incredibly important, especially in today's high-paced environment with increasingly shorter product release cycles. By tracking changes across all software assets and facilitating seamless collaboration, a version control system allow development and DevOps teams to build and ship better products faster.
uberSVN is a Freeware software product developed by WANdisco Plc. It provides a Web Application for installation, administration and use of the Apache Subversion software versioning and revision control system.
http://en.wikipedia.org/wiki/UberSVN
Subversion is a leading and fast growing Open Source version control system. SVNKit brings Subversion closer to the Java world! SVNKit is a pure Java toolkit
https://svnkit.com/
Subversive - JavaHL - SvnKit
The two connectors should both work, here are the differences (more from experience by using them, not by reading their source code):
SVN Kit:
Works on all platforms, is a Java-only implementation (no need for DLLs or shared libraries).
Is a little bit slower than JavaHL Native.
Keeps its configuration at some other place than a real subversion client like TortoiseSVN (on windows). So if you need both, you have to keep that in mind. JavaHL Native:
Needs a shared library (DLL), that has the same major version as the installed Subversion client. So if you use SVN command client 1.6.x, you should install / use the corresponding JavaHL version.
Is easy to use under Windows, more difficult to find the right version for Linux or Mac OS X (see Subclipse Wiki: JavaHL
Is faster and uses the same configuration as the installed SVN command client or TortoiseSVN client.
So you may install both, and switch between them under Windows > Preferences > Team > SVN > SVN Connector. I have used both and did not notice much difference in my normal word, only in special circumstances. If JavaHL fits in, it is the better connector in my opinion.
Version control tracks changes to source code or any other files
A good version control system can tell you what was changed, who changed it, and when it was changed
It allows a software developer to undo any changes to the code, going back to any prior version, release, or date.
This can be particularly helpful when a researcher is trying to reproduce results from an earlier paper or report and merely requires documentation of
the version number
Version control also provides a mechanism for incorporating changes from multiple developers, an essential feature for large software projects or any projects
with geographically remote developers
repository – a location where the current and all prior versions of the files are stored; in distributed version control systems, there is a master repository which can be copied (or “cloned”) locally for development
working copy – the local copy of a file from the repository which can be modified and then checked in or “committed” to the repository
check-out – the process of creating a working copy from a repository (either the current version or an earlier version)
check-in – a check-in or commit occurs when changes made to a working copy are merged into a repository
push – the merging of changes from a local repository to the master repository (for distributed version control systems)
pull – merges recent changes to the master repository into a local repository (for distributed version control systems)
diff – a summary of the differences between two versions of a file, often taking the form of the two files side-by-side with differences highlighted
update – merges recent changes to a repository into a working copy (for centralized version control systems)
conflict – a conflict occurs when two or more developers attempt to make changes to the same file and the system is unable to reconcile the changes (note: conflicts generally must be resolved by either choosing one version over the other or by integrating the changes from both into the repository by hand)
The basic steps that one would use to get started with a centralized version control system (such as Subversion/SVN) are as follows:
1. Create a repository
2. Import a directory structure and/or files into the repository
3. Check-out the repository version as a working copy
4. Edit/modify the files in the working copy and examine the differences
between the working copy and the repository (i.e., diff)
5. Check-in (or commit) the changes to the repository
The basic steps that one would use to get started with a distributed version control
system (such as Git) are as follows:
1. Create an original “master” repository
2. Clone the repository to allow development
3. Add a directory structure and/or files into the local repository
4. Check-in or “commit” the directory structure and/or files to the local
repository
5. Push these modifications of the local repository into the master repository
6. Edit/modify the files in the working copy and examine the differences
between the modified files and those in the repository (i.e., diff)
7. Check-in or “commit” the file modifications to the local repository
8. Pull any modifications from the original repository into the local repository
(in case someone has modified some files and your files are out of date)
9. Push these modifications of the local repository into the master repository
Version Control Tutorial using TortoiseSVN and TortoiseGit
Christopher J. Roy, Associate Professor
Tortoise-SVN-Git-Tutorial.pdf
The Revision Control System (RCS) manages multiple revisions of files.
RCS is useful for text that is revised frequently, including source code, programs, documentation, graphics, papers, and form letters.
https://www.gnu.org/software/rcs/
Trunk would be the main body of development, originating from the start of the project until the present.
Branch will be a copy of code derived from a certain point in the trunk that is used for applying major changes to the code while preserving the integrity of the code in the trunk. If the major changes work according to plan, they are usually merged back into the trunk.
Tag will be a point in time on the trunk or a branch that you wish to preserve. The two main reasons for preservation would be that either this is a major release of the software, whether alpha, beta, RC or RTM, or this is the most stable point of the software before major revisions on the trunk were applied.
Typically one "repository" per project.
Server can have an unlimited number of "repositories".
Work cycle
-create local copy svn checkout svn update
-make changes svn add svn move svn delete
-see what's changed meanwhile svn status -u
-update your local copy svn update
-resolve conflicts-merge your changes svn diff svn resolved
-submit your changes svn commit
Logging a Revision
Contentwhat has changed?
Datewhen did it change?
Authorwho changed it?
Reasonwhy has it changed?
List files in the repository:
> svn list http://se.cpe.ku.ac.th/svn/demo
Change to a suitable directory
> cd d:\workspace
check out the "trunk" to a directory named "demo"
> svn checkout http://se/svn/demo/trunk demo
"Conflict" means you have made changes to a file, and the version in the repository has been changed, too.
So there is a "conflict" between your work and work already in the repository.
Subversion client creates 4 files when a conflict exists.
Edit-Conflict tool of TortoiseSVN
The choices are:
(1) merge local & remote changes into one file.
(2) accept remote, discard your local changes.
(3) override remote, use your local changes.
After resolving all conflicts, mark the file as "resolved".
Subversion will delete the extra 3 copies.
"Importing" a Project
The initial check-in of code into subversion
Decide what not to import. Examples:
compiler output (*.class, *.obj, *.exe)
large image files, video, other "data"
3rd party libraries you can get from Internet, e.g. log4j.jar, mysql-connector-5.1.jar, ...
if you need an online copy of 3rd party libraries, put them in a separate project and link it as an "external" in your project
In the project root directory create a file named .svnignore
Put any file patterns (including "*" wildcard) and names of directories that you don't want to import into subversion
*.obj
*.class
*.bak .classpath
Eclipse and other IDE automatically ignore most of these (bin, dist, build).
Import your project directory into a "trunk" directory inside repository:
cmd> cd myproject
cmd> svn import . http://svnserver/svn/myrepo/trunk \ --username jim
cmd> svnmkdir -m "create branches dir" \ http://svnserver/svn/myrepo/branches
cmd> svnmkdir -m "create tags dir" \ http://svnserver/svn/myrepo/tags
For single project, path should look like one of these:
http://servername/svn/myproject/trunk
http://servername/svn/myrepo/myproject/trunk
Why do we need tags?
Mark a release version of a product.
Mark a snapshot of the current development.
Typical Release names: Release-1.0.0 REL-0.3.0RC1
A Tag name must be unique.
Contents of a "tag" should not be changed. ...but Subversion won't stop you from changing them!
Tagging by Copy: command line svn copy source destination -m "comment" svn copy http://svnserver/calc/trunk http://svnserver/calc/tags/RELEASE-1.0.0 -m ”Create Release Tag for Release 1.0.0”
If path contains space or special characters, use quotes: 'rel 1.0' Don't use spaces in release names.
Why Branching?
This could happen to you: You create a great product and it has been delivered to your customers. Before you delivered the product you create a svn tag, named it REL-1.0.0 Your development team is modifying the trunk version with new features.
And now Murphy‘s Law strikes! Customer reports that he found a major bug in your software!
The development has continued after the release of REL-1.0.0
You want to fix the bug to satisfy your customer!
In your current development you have enhanced many of the product’s functions but you don‘t want to deliver product with more features and you haven‘t finished testing yet.
How to solve this situation?
Based on the tag you‘ve created during the delivery you can check out the exact state of the delivery
You create a Branch to fix the bug in the software.
RELEASE 1.0.0 -> BUGFIX_BRANCH
After you have fixed the bug
you can tag the Branch and deliver another version to the customer.
BUGFIX_BRANCH->RELEASE 1.0.1 Your customer is satisfied that you fixed the bug so fast.
You haven‘t disturbed the current development
You can create a branch using the following command: svn copy http://svnserver/calc/trunk http://svnserver/calc/branches/my-branch -m”- Create the branch”
Based on your company’s policy you may have subdirectories under the branches directory in the repository:
branches/release-candidates
branches/sub-projects
branches/user-branches
You would like to work on the branch to fix the bug
You can do it in two ways: Check out a complete new working copy from the branch. switch your current working copy to the particular branch.
You can switch your current working copy to a branch with the following command: svn switch destination destination:The name of the branch to use.
Fix the bug through doing the necessary modifications and finally commit the changes to the branch.
After having fixed the bug on the branch create a tag to mark the new release which can be delivered to the customer
Create the new Release Tag: svn copy file:///home/kama/repos/project1/branches/BUGFIX_BRANCH file:///home/kama/repos/project1/tags/RELEASE-1.0.1 -m”Fixed Release 1.0.1”
Merging From a Branch
What’s with the bug you've fixed on the bug-fix-branch?
What about your current development? You have to merge the changes made in the branch back to the main line.
RELEASE 1.0.0 -> BUGFIX_BRANCH ->RELEASE 1.0.1->MERGE BACK TO TRUNK
You can merge the changes from the branch into your current working copy with the following command svn merge -r 267:HEAD branchname
The revision in which we created the branch (267) and HEAD for the complete branch.
You can find the revision number when the branch was created using the command: svn log --verbose --stop-on-copy branchname
Merge tracking:
Subversion does not have any function to track merges that have already been done,
i.e., to prevent you to merge a branch a second time.
Example: after merging, create a README-merged file in the branch stating that it was merged into trunk revision r99.
The intention of a tag is that it should be used as read-only area whereas a branch is used to continue development (interim code, bug-fixing, release candidate etc.). Technically you can use a tag to continue development and check in etc. but you shouldn’t do it.
Version Control Best Practices
Plan the directory structure
Decide what work products to put in version control
Decide what to exclude
Big decision: repository layout one "project" per repo? many projects per repo? Example: separate Eclipse projects for "core", "web", and "web services" components of your software
Commit all files related to the same task as one commit.
This makes comments more meaningful.
Create a tag for each milestone and each release.
Create branches for experimental work and bug fixes.
Avoid too many branches.
Developer Branches Separation of team members can be realized with branches.
One branch per team member or several members on a branch - the decision is based on the size of the teams
Advantages using branches for team work: No changes during development on the main line needed => Code stability. Every team member can work in its own environment
Disadvantages: Sometimes the mainline and the branch will diverge if the branch lives too long.
Feature Branches
Separation by features (one branch each).
Using Subversion -James Brucker
How CVS works? An example of team collaboration in Eclipse
Trunk is the main version of a project.
There is one and only one trunk for each CVS repository
http://www.programcreek.com/2012/04/how-cvs-works-example-of-team-collaboration-in-eclipse/
Tagging is useful anytime you want a snapshot in time of the state of your project.
Difference between trunk, tags and branches in SVN or Subversion source control system
In short
- A trunk in SVN is main development area, where major development happens.
- A branch in SVN is sub development area where parallel development on different functionalities happens. After completion of a functionality, a branch is usually merged back into trunk.
- A tag in SVN is read only copy of source code from branch or tag at any point of time. tag is mostly used to create a copy of released source code for restore and backup.
division is purely based on how programmer uses trunk and branches.
Main difference between branch and tag in subversion is that, tag is a read only copy of source code at any point and no further change on tag is accepted, while branch is mainly for development. Other source control like CVS doesn't allow modification on tags but SVN allows changes on tags, which is considered as bad practice. You should not be making any change on tag once created, it should be treated as read only copy of source code only for restore purpose.
http://javarevisited.blogspot.com/2013/04/difference-between-trunk-tags-and-branch-svn-cvs-git-scm-subversion.html#ixzz2h72XRAOi
Branching lets you manage different versions of your code base in parallel for things like maintaining older versions, the development of new features and so on.
But no sooner do you start branching, then you'll need tostart merging
http://blog.daemon.com.au/go/blog-post/merging-with-subversion-and-eclipse