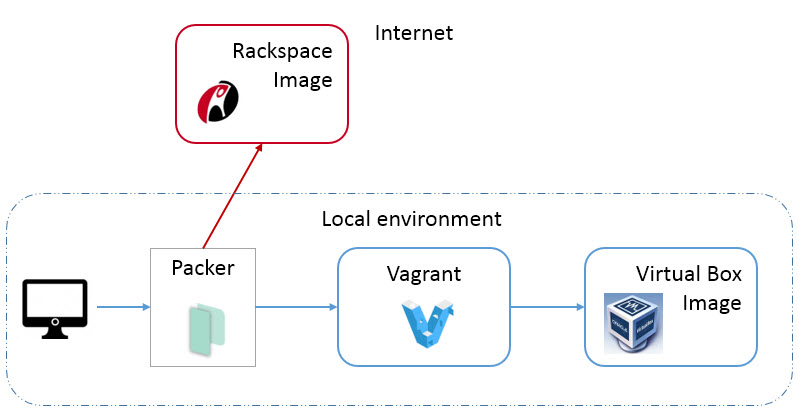
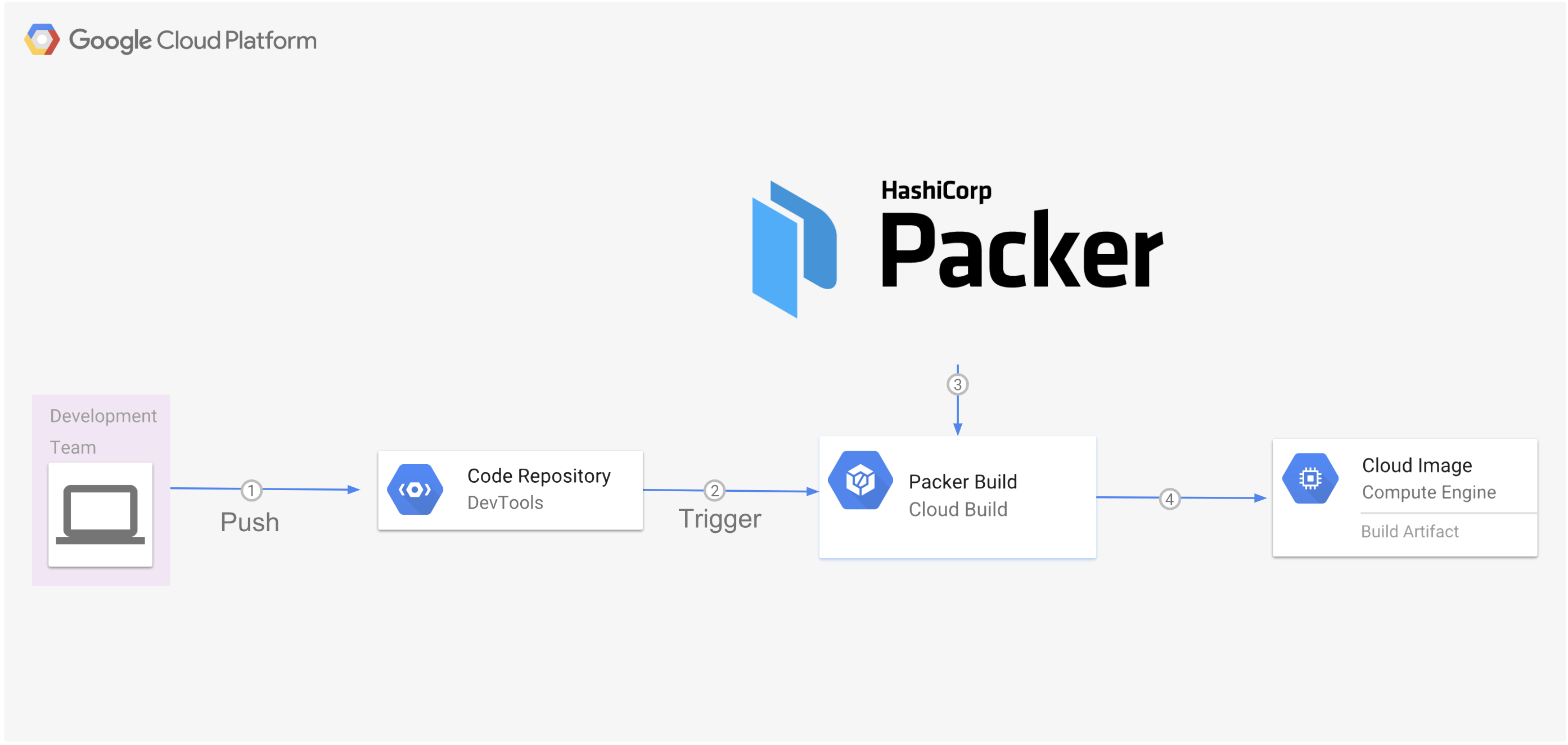
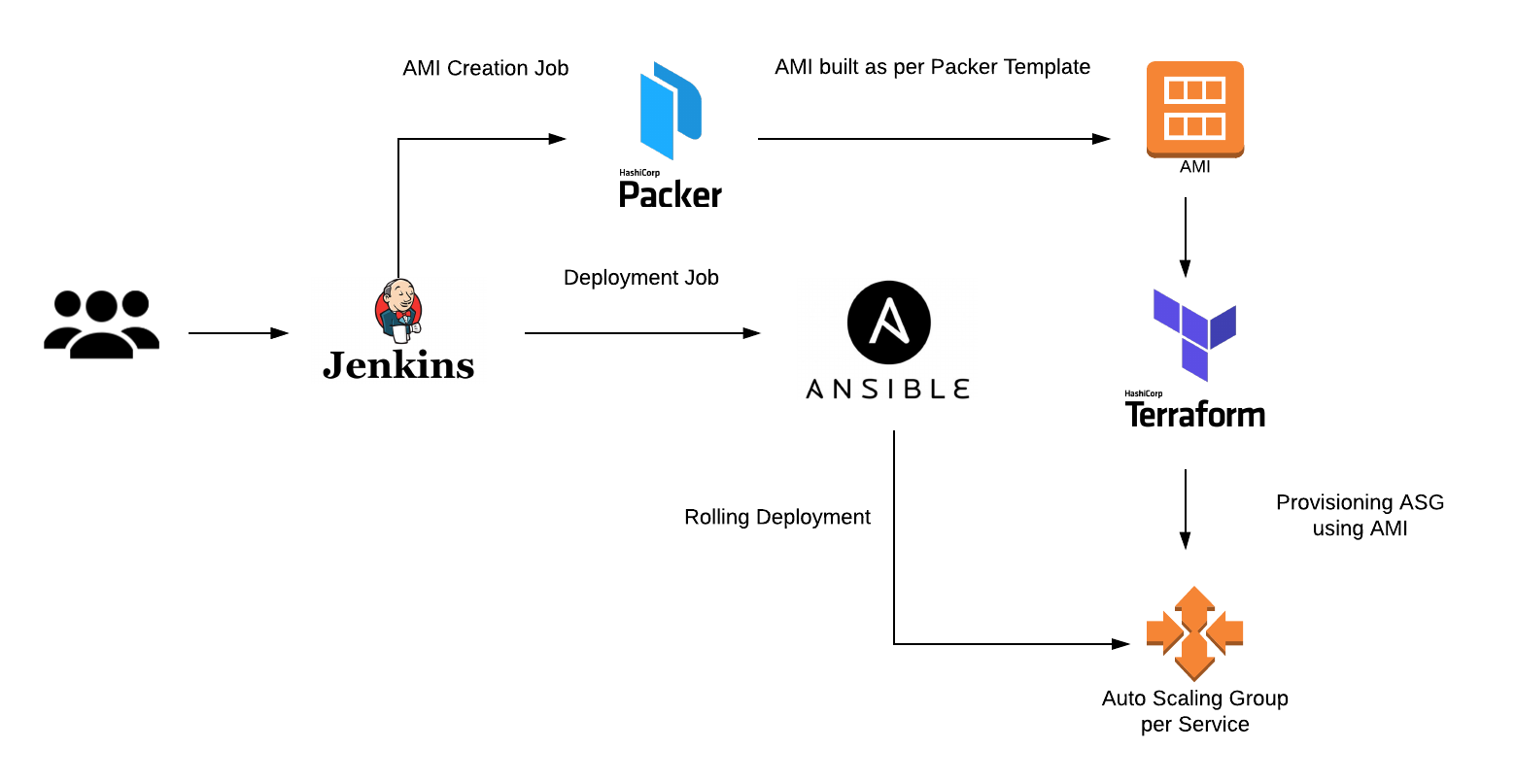
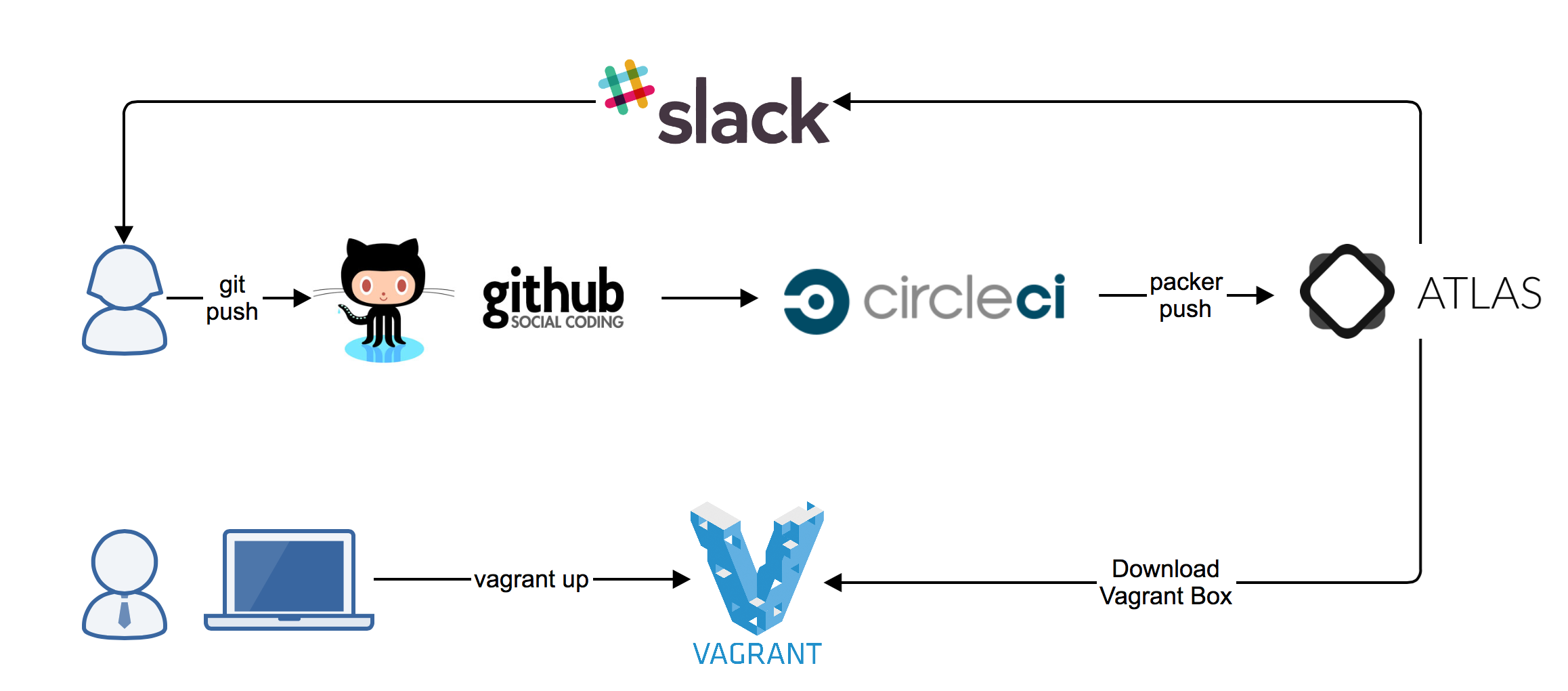
- In computer programming and software testing, smoke testing is preliminary testing to reveal simple failures severe enough to reject a prospective software release.
In this case, the smoke is metaphorical. A subset of test case
serverspecs that cover the most important functionality of a component or system is selected and run, to
ascertain if the most crucial functions of a program work correctly.
For example, a smoke test may ask basic questions like "Does the program run?", "Does it open a window?", or "Does clicking the main button do anything?"
The purpose is to determine whether the application is so badly broken that further testing is unnecessary.
As the book, "Lessons Learned in Software Testing" puts it,
"smoke tests broadly cover product features in a limited time ...
if key features don't work or if
key bugs haven't yet been fixed, your team won't waste further time installing or testing
http://en.wikipedia.org/wiki/Smoke_testing
- Smoke Testing, also known as “Build Verification Testing”, is a type of software testing that comprises of a non-exhaustive set of tests that aim at ensuring that the most important functions work. The results of this testing is used to decide if a build is stable enough to proceed with further testing.
LEVELS APPLICABLE TO
Smoke testing is normally used in Integration Testing, System Testing and Acceptance Testing levels.
http://softwaretestingfundamentals.com/smoke-testing/
- New Build is checked mainly for two things:
Build validation
Build acceptance
Some BVT basics:
It is a subset of tests that verify main functionalities.
The BVT’s are typically run on daily builds and if the BVT
fails the build is rejected and
a new build is released after
the fixes are done.
The advantage of BVT is it saves the efforts of a test team to set up and test a build when major functionality
is broken.
Design BVTs carefully enough to cover basic functionality.
Typically BVT should not run
more than 30 minutes.
BVT is a
type of regression testing, done on
each and every new build.
http://www.softwaretestinghelp.com/bvt-build-verification-testing-process/
- Molecule is designed to aid in the development and testing of Ansible roles. Molecule provides support for testing with multiple instances, operating systems and distributions, virtualization providers, test frameworks and testing scenarios.
https://molecule.readthedocs.io/en/latest/
- Today, we have over 98 Ansible roles of which 40 are "common" roles that are reused by other roles. One problem we wound up hitting along the way: A role isn't touched for months and when someone finally dusts it off to make some changes, they discover it is woefully out of date. Or even worse, a common role may be changed and a role that depends on it isn't updated to reflect the new changes.
Untested code that
isn't covered by tests running in continuous integration (CI) will inevitably rot given a long enough timeline.
It integrates with Docker, Vagrant, and OpenStack to run roles in a virtualized environment and works with popular infra testing tools like
ServerSpec and
TestInfra.
When adhering to TDD, one major recommended practice is to follow a cycle of “red, green,
refactor” as we write tests. This means that instead of moving on after passing a test, we take a little time out to
refactor since we have test coverage that allows us to
modify without fear
https://zapier.com/engineering/ansible-molecule/
- Molecule is generally used to test roles in isolation. However, it can also test roles from a monolith repo.
https://molecule.readthedocs.io/en/latest/examples.html#docker
- This project on has 2 linux instances and the rest are solely windows server so it was a bit different to what i was used to. what follows will be one example of how to get molecule running for a linux instance and also one for a windows instance.
this would
be using vagrant to provision a windows machine in
Virtualbox.which
in turn molecule can communicate with
https://medium.com/@elgallego/ansible-role-testing-molecule-7a64f43d95cb
- within the molecule directory you have a directory named default, that default directory is a scenario and you can create as many scenarios as you like, and also share scenarios between different roles.
https://medium.com/@elgallego/molecule-2-x-tutorial-5dc1ee6b29e3
Therefore Molecule introduces a consecutive list of steps that run one by one. Three
of these steps stand out from the rest: create, converge and verify. Why is that? Because a best practice in writing tests also implies three steps (originally lent from Behavior-driven Development (BDD)). Just give them other names and
you should be
quite familiar with them: Given, When and Then.
Molecule supports a wide range of infrastructure providers & platforms
– be it bare-metal, virtual, cloud or containers. Because it leverages the power of Ansible to connect and maintain testing infrastructure, Molecule can test everything that Ansible
is able to use
Molecule also supports different verifiers: right now these are Goss,
InSpec and
Testinfra. The latter is the default verifier where you can write
Unittest with a Python DSL.
It is built on top of the Python test framework
pytest.
As we use Vagrant as infrastructure provider for Molecule, we also need to install the python-vagrant pip package
which is done after the molecule installation.
The crucial directories inside our role named docker are tasks and molecule/default/tests. The first will contain our Ansible role we want to develop
– the “implementation” in TDD speech. The latter directory will be our starting point inside the TDD cycle where we will write our infrastructure test cases with the help of
Testinfra. As you may notice, I also renamed the test case according to our use case into
test_docker.py.
With
Testinfra you can write unit tests in Python to test actual state of your servers configured by management tools like Salt, Ansible, Puppet, Chef and so on.
Testinfra happens to be the Python-style equivalent to
Serverspec which again
is based on the Ruby BDD framework
RSpec.
it´s time to remember the three main phases of Molecule. We already successfully created our infrastructure within the Given step with the help of molecule create. Right after implementing the above playbook into tasks/main
.yml, we need to execute the When phase. This can
be achieved by running molecule converge which should look like this:
We could destroy the machine with molecule destroy, but we want to write and execute a test case in the next section. So we leave it in the created state
https://blog.codecentric.de/en/2018/12/test-driven-infrastructure-ansible-molecule/
- But using Vagrant also has its downsides. Although we get the best experience in terms of replication of our staging and production environments, the preparation step takes relatively long to complete since a whole virtual machine has to be downloaded and booted. And that´s nothing new. Docker has been here for a long time now to overcome this downside.
And
it is supported on all major cloud Continuous Integration platforms. So it would be ideal if we
were able to use Docker with Molecule.
. But we also don´t want to abandon Vagrant completely since there are maybe situations where we want to test our Ansible roles against full-blown virtual machines. Luckily Molecule can help us. 🙂 We
simply need to leverage
Molecule´s multi-scenario support.
a new Ansible role with Molecule support build in using the molecule init role command. Besides the standard Ansible role directories, this places a molecule folder inside the role skeleton. This
in turn contains the directory default which already defines a scenario name! If you ran a Molecule test, already
this scenario name could be also found inside the output. So it should be easy to extend our Molecule setup to support both Vagrant and Docker at the same time:
Molecule scenarios enable us to split the parts of our test suites into two kinds. The first one is scenario-specific and
is therefore placed into separate directories, which also defines the individual scenario name. This could contain infrastructure
provider specific configuration for example. The second kind are files that should stay the same across all scenarios. Our test cases are good candidates for this, they should remain the same all over our scenarios.
As Docker is the default infrastructure provider in Molecule, I
simply renamed default into vagrant-ubuntu. Then I created a new directory with the name default to contain all the Docker configuration for Molecule. This results in the following project structure which resembles
Molecule´s best practice on how to use multiple scenarios inside the same Ansible role:
As you may note,
all the files which belong only to a certain scenario are placed inside the scenario’s directory. For
example only the default Docker scenario contains a
Dockerfile.js. On the
contrary the vagrant-ubuntu scenario contains a prepare
.yml.
https://blog.codecentric.de/en/2018/12/continuous-infrastructure-ansible-molecule-travisci/
- A systemd enabled Docker image must be used for Ubuntu and CentOS
You might have to write a
systemd service file for the package you want to install if the package maintainer doesn’t provide one
You have to be able/willing to trust unofficial images from Docker Hub
You may
be locked into the latest versions of CentOS and Ubuntu — I haven’t tested earlier versions whilst researching for this article
Testinfra requires writing some basic Python functions to get the tests in place.
Writing tests first means you’re taking (business) requirements and mapping them into business tests
Linting means you’re following good standards and allows others
to easily adopt and hack against your code base
You can have a CI/CD process automatically run the tests and halt any delivery pipelines on failure, preventing faulty code reaching production systems
https://blog.opsfactory.rocks/testing-ansible-roles-with-molecule-97ceca46736a
- Testing Ansible roles with Molecule, Testinfra and Docker
Test Kitchen was created for testing Chef Cookbooks and like Chef, Test Kitchen is a Ruby application.
a Python clone of Test Kitchen, but more specific to Ansible: Molecule
Unlike Test kitchen with the
many different drivers, Molecule supports several
backends, like Vagrant, Docker, and OpenStack.
With Molecule you can make use of
Serverspec (Like Test Kitchen), but you can also make use of ‘
Testinfra’.
Testinfra is like
Serverspec a tool for writing unit tests, but
it is written in Python.
These were the basics for testing an Ansible role with Molecule, Docker and Test Infra.
https://werner-dijkerman.nl/2016/07/10/testing-ansible-roles-with-molecule-testinfra-and-docker/
- I then discovered Ansible which I was attracted to for its simplicity in comparison to writing Ruby code with Chef.
I immediately re-wrote
all of the Chef stuff we had at work and persuaded the team to make the switch. I still love Chef, just Ansible was a lot quicker to understand which
was going to mean
much easier on-boarding of new team members
I immediately re-wrote
all of the Chef stuff we had at work and persuaded the team to make the switch. I still love Chef, just Ansible was a lot quicker to understand which
was going to mean
much easier on-boarding of new team members
.After writing a lot of Ansible I couldn't help think something was missing, it was the TDD workflow I'd fallen in love with when writing Chef.
I've since discovered Molecule which allows me to write Ansible in a very similar way to how I used to write Chef.
I write tests first in
Testinfra which is the Python equivalent to the
Serverspec tests I'd got used to writing for Chef.
In addition to testing Molecule ensures you follow best practices by running your code through
ansible-lint and performs an
idempotence check.
In this post I hope to show how you can use Molecule to TDD a simple Ansible role which installs Ruby from source.
https://hashbangwallop.com/tdd-ansible.html
- With Testinfra you can write unit tests in Python to test actual state of your servers configured by management tools like Salt, Ansible, Puppet, Chef and so on.
Testinfra aims to be a
Serverspec equivalent in python and
is written as a plugin to the powerful
Pytest test engine
https://github.com/philpep/testinfra
- Testing Ansible roles in a cluster setup with Docker and Molecule
we configure Molecule for a role that is
installing and configuring a cluster on Docker, like MySQL or MongoDB.
I have a Jenkins job that validates a role that
is configured to run a 3 node setup (Elasticsearch, MariaDB and some others).
https://werner-dijkerman.nl/2016/07/31/testing-ansible-roles-in-a-cluster-setup-with-docker-and-molecule/
- Molecule is designed to aid in the development and testing of Ansible roles.
If Ansible can use it, Molecule can test it. Molecule
simply leverages Ansible’s module system to manage instances.
https://molecule.readthedocs.io/en/latest/index.html
- Continuous deployment of Ansible Roles
There are a lot of articles about Ansible with continuous deployment, but these are only about using Ansible as a tool to do continuous deployment
Hopefully you
didn’t make any errors in the playbook or role so all will be fine during deployment and no unwanted downtime
is caused, because
nothing is tested
Application developers write unit tests on their code and the application
is tested by either automated tests or by using
test|qa team. Application development is not any different
than writing software for your infrastructure
A
Jenkinsfile is the Jenkins job configuration file that contains all steps that Jenkins will execute.
Its the
.travis
.yml (Of Travis CI) file equivalent of Jenkins
I also have 1 git repository that contains all
ansible data, like
host_vars,
group_vars and the inventory file.
I have a Jenkins running with the Docker plugin and once
a job is started, a Docker container will
be started and
the job will be executed from this container. Once the Job
is done (Succeeded or Failed doesn’t matter which),
the container and all data in this container is removed.
Jenkins Jobs
All my Ansible roles has 3
jenkinsfiles stored in the
git repository for the following actions:
Molecule Tests
Staging deployment
Production deployment
Molecule Tests
The first job is that
the role is tested with Molecule. With Molecule we create 1 or more Docker containers and
the role is deployed to these containers
We get the latest
git commit id, because I use this id to create a tag in
git once the Molecule Tests succeeds.
I use separate stages with single commands so I can quickly see on which part the job fails and focus on that immediately without going to the console output and scrolling down to see where it fails.
After the Molecule verify stage,
the Tag git stage is executed. This will use the latest commit id as a tag, so I know that
this tag was triggered by Jenkins to run a build and was successful.
Staging deployment
The goal for this job is to deploy the role to
an staging server and validate if everything is still working correctly.
In this case we will execute the same tests on the staging
staging as we did with Molecule, but we can also create
an other test file and use that. In my case, there is only one staging server but it could also be a group of servers.
The first stage is to checkout 2 git repositories: The Ansible Role
and the 2nd is my “environment” repository that contains all Ansible data and
both are stored in their own
sub directory.
The 2nd Stage is to install the required applications, so not very interesting. The 3rd stage is to execute the playbook. In my “environment” repository (That holds all Ansible data)
there is a playbooks directory and in that directory contains the playbooks for the roles. For deploying the
ansible-access role, a playbook named
ansible-access
.yml is present and will be
use to install the role on the host:
The 4th stage is to execute the
Testinfra test script from the molecule directory to the staging server to verify the correct installation/configuration.
In this case I used the same tests as Molecule
In this job we create a new tag ${
params.COMMIT_ID}_staging and push it so we know that
the provided tag is deployed to our staging server.
Production deployment
This is the job that deploys the Ansible role to the rest of the servers.
With the 3rd stage “Execute role on host
(s)” we use
an different limit. We now use
all:!localhost:!staging to deploy to all hosts, but not to
localhost and staging. Same is for the 4th stage, for executing the tests. As the last stage in the job, we create a tag ${
params.COMMIT_ID}_production and we push it.
This deployment will fail or succeed with the quality of your tests.
https://werner-dijkerman.nl/author/wdijkerman/
- Testing Ansible roles with Molecule
When you're developing an automation, a typical workflow would start with a new virtual machine. I will use Vagrant to illustrate this idea, but you could use
libvirt, Docker,
VirtualBox, or VMware, an instance in a private or public cloud, or a virtual machine provisioned in your data center
hypervisor (
oVirt,
Xen, or VMware, for example).
What can
Testinfra verify?
Infrastructure is up and running from the user's point of view (e.g., HTTPD or Nginx is answering requests, and MariaDB or
PostgreSQL is handling SQL queries).
OS service
is started and enabled
A process is listening on a specific port
A process is answering requests
Configuration files
were correctly copied or generated from templates
Virtually anything you do to ensure that your server state is correct
What safeties do these automated tests provide?
Perform complex changes or introduce new features without breaking existing behavior (e.g., it still works in RHEL-based distributions after adding support for
Debian-based systems).
Refactor/improve the
codebase when new versions of Ansible
are released and new
best practices are introduced.
Molecule helps develop roles using tests. The tool can even initialize a new role with test cases: molecule init role
–role-name
foo
idempotence - Executes a playbook twice and fails in case of changes in the second run (non-idempotent)
virtualenv (optional)
The
virtualenv tool creates isolated environments, while
virtualenvwrapper is a collection of extensions that facilitate the use of
virtualenv.
These tools prevent dependencies and conflicts between Molecule and other Python packages in your machine.
https://opensource.com/article/18/12/testing-ansible-roles-molecule
- How To Test Ansible Roles with Molecule on Ubuntu 16.04
molecule: This is the main Molecule package
that you will use to test roles. Installing molecule automatically installs Ansible, along with other dependencies, and enables the use of Ansible playbooks to execute roles and tests.
docker: This Python library
is used by Molecule to interface with Docker. You will need this since you're using Docker as a driver.
source
my_env/bin/activate
python -
m pip install molecule docker
The -
r flag specifies the name of the role while -d specifies the
driver, which provisions the hosts for Molecule to use in testing.
molecule init role -
r ansible-apache -d
docker
cd
ansible-apache
Test the default role to check if Molecule has
been set up properly:
molecule test
pay attention to the PLAY_RECAP for each
test, and be sure that none of the default actions returns a failed status
Using
Testinfra, you will write the test cases as Python functions that use Molecule classes.
The
linting action executes
yamllint, flake8, and
ansible-lint:
yamllint:
This linter is executed on all YAML files present in the role directory.
flake8: This Python code linter checks tests created for
Testinfra.
ansible-lint: This linter for Ansible playbooks is executed in all scenarios.
In this article you created an Ansible role to install and configure Apache and
Firewalld.
You then wrote unit tests with
Testinfra that Molecule used to assert that the role ran successfully.
automate testing using a CI pipeline
https://www.digitalocean.com/community/tutorials/how-to-test-ansible-roles-with-molecule-on-ubuntu-16-04
- Testing Ansible Roles with Molecule
–
KitchenCI with an Ansible provisioner
– Molecule
t seems
to me to be the better option to use a tool that explicitly aims to test Ansible stuff, rather than using
TestKitchen which usually is used for Chef cookbooks but has an extension to support Ansible provisioning.
Molecule support multiple virtualization providers, including Vagrant, Docker, EC2, GCE, Azure, LXC, LXD, and OpenStack.
Additionally, various test frameworks
are supported to run syntax checks,
linting, unit- and integration tests.
Molecule is written in Python and the only supported installation method is Pip.
molecule init role -d
docker -
r ansible-
myrole
This will not only create files and directories needed for testing, but the whole Ansible role tree, including all directories and files to get started with a new role.
I
choose to use Docker as a virtualization driver.
With the init command you can also set the verifier to
be used for integration tests.
The default is
testinfra and I stick with that. Other options are
goss and
inspec.
Molecule uses Ansible to provision the containers for testing.
It creates automatically playbooks to prepare, create and delete those containers.
One special playbook is created to actually run your role.
By default cents:7 is the only platform used to test the role.
Platforms can be added to run the tests on multiple operating systems and versions.
https://blog.netways.de/2018/08/16/testing-ansible-roles-with-molecule/
- The first one is serverspec, which allows running BDD-like tests against local or remote servers or containers.
Like many tools nowadays,
goss keeps its configurations (server or container specs) in YAML files.
what’s cool I actually can do that semi-automatically by asking
goss to scan particular feature of current machine and add it to
config file.
To check if that’s
currently the case, I can ask
goss to add these features’ states to
config file, then bring it to all other servers (can’t test them remotely) and call
goss validate.
goss comes with evil-twin brother called
dgoss, which knows how to test Docker containers.
both
dgoss and
goss‘s exit codes reflect
whether the test was successful or not, it’s
quite easy to connect them to CI and validate, for instance, if
Dockerfiles still produce what they supposed to.
https://codeblog.dotsandbrackets.com/unit-test-server-goss/
- Goss files are YAML or JSON files describing the tests you want to run to validate your system.
https://velenux.
wordpress.com/2016/11/20/test-driven-infrastructure-with-goss/
- Goss is a YAML based serverspec alternative tool for validating a server’s configuration.
The project also includes
dgoss which is a Docker-focused wrapper for
goss. It includes two basic operations: edit and run.
Pre-requisites
In order to run tests locally,
you’ll need to install
dgoss
You’ll also need a Docker image under development.
https://circleci.com/blog/testing-docker-images-with-circleci-and-goss/
- Goss is a YAML based serverspec alternative tool for validating a server’s configuration. It eases the process of writing tests by allowing the user to generate tests from the current system state. Once the test suite is written they can be executed, waited-on, or served as a health endpoint
Docker 1.12 introduced the concept of HEALTHCECK, but only allows you to run one command. By letting Goss manage your checks. The
goss.yaml file can define as many checks or reference as many scripts/commands as you like.
https://medium.com/@aelsabbahy/docker-1-12-kubernetes-simplified-health-checks-and-container-ordering-with-goss-fa8debbe676c
- Goss is a YAML based serverspec alternative tool for validating a server’s configuration
The project also includes
dgoss which is a Docker-focused wrapper for
goss. It includes two basic operations: edit and run.
In order to run tests locally,
you’ll need to install
dgoss using the
appropriate steps depending on your OS.
Once inside the running Docker image, you can explore different tests, which the Goss command will automatically append to a
goss.yaml file.
This file will be copied into your local workstation after your exit.
https://circleci.com/blog/testing-docker-images-with-circleci-and-goss/
● Advanced test orchestrator
Open Source project
Originated in Chef community
Very pluggable on all levels
Implemented in Ruby
Configurable through simple single
yaml file
"Your infrastructure deserves tests too."
What is Kitchen?
Kitchen provides a test harness to execute infrastructure code on one or more platforms in isolation.
A driver plugin architecture is used to run code on various cloud providers and virtualization technologies such as Vagrant, Amazon EC2, and Docker.
Many testing frameworks are supported out of the box including
InSpec,
Serverspec, and Bats
http://kitchen.ci/
- We've just installed ChefDK, VirtualBox, and Vagrant. The reason we have done so is that the default driver for test-kitchen is kitchen-vagrant which uses Vagrant to create, manage, and destroy local virtual machines. Vagrant itself supports many different hypervisors and clouds but for the purposes of this exercise, we are interested in the default local virtualization provided by VirtualBox.
Kitchen is modular so that one may use a variety of different drivers (Vagrant, EC2, Docker), provisioners (Chef, Ansible, Puppet), or verifiers (InSpec,
Serverspec, BATS) but for
the purposes of the guide we're focusing on the default "happy path" of Vagrant with
VirtualBox, Chef, and InSpec.
https://kitchen.ci/docs/getting-started/installing
- Test Kitchen is Chef’s integrated testing framework. It enables writing test recipes, which will run on the VMs once they are instantiated and converged using the cookbook. The test recipes run on that VM and can verify if everything works as expected.
ChefSpec is something which only simulates a Chef run
Provisioner − It provides specification on how Chef runs. We are using
chef_zero because it enables to mimic a Chef server environment on the local machine. This allows to work with node attributes and Chef server specifications.
https://www.tutorialspoint.com/chef/chef_test_kitchen_setup.htm
- Chef - Test Kitchen and Docker
Let’s create a simple application cookbook for a simple
webserver configuration that uses the Apache 2 cookbook from the Chef Supermarket to install Apache
Switch to the user
that you will use for creating the application cookbook and create the folder ~/chef-repo.
This will be used as the local Chef repository for the source files for the application cookbook.
$ cd ~/chef-repo
$ chef generate app c2b2_website
This generates the following folder structure which includes a top level Test Kitchen instance for testing the cookbook.
https://www.c2b2.co.uk/middleware-blog/chef-test-kitchen-and-docker.php
- Detect and correct compliance failures with Test Kitchen
Knowing where your systems are potentially out of compliance
– the detect phase
– helps you accurately assess risk and prioritize remediation actions.
The second phase, correct, involves remediating the compliance failures you've identified in the first phase. Manual correction doesn't scale. It's also tedious and error-prone.
To help ensure that the automation code you write will place their systems in the desired state, most teams apply their code to test systems before they apply that code to their production systems. We call this process local development.
you'll use Test Kitchen to detect and correct issues using temporary infrastructure
You'll use Test Kitchen to run
InSpec tests to detect potential issues and then you'll use Chef to correct
some of the reported issues.
You'll continue to use the dev-sec/
linux-baseline
InSpec profile
By creating local test infrastructure that resembles your production systems, you can detect and correct compliance failures before you deploy changes to production.
For this module, you need:
Docker.
the Chef Development Kit, which includes Test Kitchen.
jq, a JSON processor (Linux and
macOS only).
Bring up a text editor
that you're comfortable using. Here are a few
popular graphical text editors.
Atom
Visual Studio Code
Sublime Text
The initial configuration specifies a configuration that uses Vagrant to manage local VMs on
VirtualBox. Because you're working with Docker containers, you need to
modify this configuration file.
The driver section specifies the software that manages test instances. Here, we specify kitchen-
dokken. This driver
is capable of creating Docker containers and running
InSpec and Chef on those containers.
The platforms section specifies to use the
dokken/ubuntu-16.04 Docker image. In this module, you use a Docker image based on Ubuntu 16.04. You can use Test Kitchen to spin up other Docker environments.
run_list specifies which Chef recipes to run. A recipe defines the steps required to configure one part of the system. Here, we specify the
auditd cookbook's default recipe. You'll work with this recipe shortly.
inspec_tests specifies which InSpec profiles to run. Here, we specify the dev-sec/
linux-baseline profile. This is the same profile you worked with in Try InSpec. By default, Test Kitchen fetches InSpec profiles from Chef Supermarket.
2. Detect potential
auditd failures
Run kitchen verify now to run the dev-sec/
linux-baseline profile on your container.
Limit testing to just the
auditd package
In
.kitchen
.yml, add a controls section to limit testing to just the "package-08" control. Make your copy look like this.
The control tests whether the
auditd package is installed and whether its configuration conforms to the recommended guidelines.
Write the output as JSON
let's format the results as JSON and write the report to disk.
Modify .kitchen
.yml
Run kitchen verify to generate the report.
Remember, if you don't have the
jq utility, you can just follow along or paste your file in an online JSON formatter such as
jsonformatter.org.
3. Correct the failures
In this part, you write Chef code to correct the failures. You do so by installing the
auditd package. After applying your code to the test container, you then re-run your
InSpec tests on the container to verify the configuration.
4. Specify the
auditd configuation
In this part, you
modify the
auditd configuration file to assign the value
keep_logs to
max_log_file_action.
Create the Chef template
A template enables you to generate files.
you can include placeholders in a template file that
are replaced with their actual values when Chef runs.
run the following chef generate template command to create a template named
auditd.conf
.erb.
chef generate template
auditd.conf
Update the default recipe to use the template
To do a complete Test Kitchen run, you can use the kitchen test command. This command:
destroys any existing instances (kitchen destroy).
brings up a new instance (kitchen create).
runs Chef on your instance (kitchen converge).
runs
InSpec tests (kitchen verify).
destroys the instance (kitchen destroy).
https://learn.chef.io/modules/detect-correct-kitchen#/
- Testing Ansible Roles With KitchenCI
KitchenCI
What is
KitchenCI? Kitchen provides a test harness to execute infrastructure code on one or more platforms in isolation.
KitchenCI has been integrated with Ansible with the Kitchen-Ansible Gem found on
Github.
kitchen verify
– This runs the test suite
inspec or
serverspec
ServerSpec which is a functional test tool which enables infrastructure developers to write
RSpec tests for checking your servers
are configured correctly
Serverspec tests your servers’ actual state by executing command locally, via SSH, via
WinRM, via Docker API and so on.
Docker API and so on. So you
don’t need to install any agent softwares on your servers and can use any configuration management tools, Puppet, Ansible, CFEngine,
Itamae and so on.
http://www.briancarpio.com/2017/08/24/testing-ansible-roles-with-kitchenci/
- Ansible Galaxy – Testing Roles with Test Kitchen
To get started we will need a handful of dependencies:
A working Python install with Ansible installed
A working Ruby install with bundler installed
Docker installed and running. Please see install instructions.
The most important thing at the moment is the
additional_copy_path. At the moment testing an Ansible Galaxy role doesn’t just work out of the box with kitchen-
ansible. By specifying the copy path to be the role directory you get it copied into the provisioner which can then be
ran as a normal role within a playbook.
Some shortcomings
Currently you need to define an empty roles key in your playbook being ran. Kitchen
ansible was mainly built to run against an
ansible project with multiple roles rather than a Galaxy role. This may change
in the future, making this process easier.
The spec pattern is being used here to workaround a path issue with where the verifier is looking for spec files. This means the spec files matching spec/*_spec
.rb will
be executed for every test suite at the moment. It would be nice to have a suite directory with spec files per suite, similar to a per role suite in the normal testing pattern.
Using the
additional_copy_path had to
be used to get the galaxy role into the container where provisioning needed to happen. Ideally there would be a nicer way to say your role that is being tested is the current directory or is a galaxy role to avoid this.
https://blog.el-chavez.me/2016/02/16/ansible-galaxy-test-kitchen/
- add Test Kitchen to your Gemfile inside your Chef Cookbook
kitchen-vagrant is a "Test Kitchen driver" - it tells test-kitchen how to interact with an appliance (machine), such as Vagrant, EC2, Rackspace,
etc.
run the bundle command to install
bundle install
verify
Test Kitchen is installed
bundle exec kitchen help
By default, Test Kitchen will look in the test/integration directory for your test files. Inside there will be a folder, inside the folder a
busser, and inside the
busser, the tests:
https://github.com/test-kitchen/test-kitchen/wiki/Getting-Started
- Using Test Kitchen with Docker and serverspec to test Ansible roles
we are using the test kitchen framework and
serverspec for the Ansible role: dj-wasabi
.zabbix-agent.
With test kitchen we can start
an vagrant box or
an docker image and our Ansible role will
be executed on this instance.
When the Ansible role
is installed,
serverspec will be executed so we can verify
if the installation and configuration is done correctly.
Ideally you want to execute this every time when
an change is done for the Role, so the best way is to do everything with Jenkins
gem install test-kitchen
kitchen init
--create-
gemfile --driver=kitchen-docker
We update the
Gemfile by adding the next line at the end of the file
gem "kitchen-
ansible"
bundle install
set some version restrictions in this file
install test-kitchen with version 1.4.0 or higher
gem 'test-kitchen', '>= 1.4.0'
gem 'kitchen-docker', '>= 2.3.0'
gem 'kitchen-
ansible'
We remove the
chefignore file, as we don’t use chef in this case.
The following example is the “suites” part of the dj-wasabi
.zabbix-server role:
suites:
- name:
zabbix-server-
mysql
provisioner:
name:
ansible_playbook
playbook: test/integration/
zabbix-server-
mysql.yml
- name:
zabbix-server-
pgsql
provisioner:
name:
ansible_playbook
playbook: test/integration/
zabbix-server-
pgsql.yml
There are 2 suits with their own playbooks.
There are 2 suits with their own playbooks. In the above case, there is
an playbook which will be executed with the “MySQL” as backend and there is
an playbook with the “
PostgreSQL” as backend.
Both playbooks will be executed in their own docker instance. So it will start
with for
example the ‘
zabbix-server-
mysql’ suits and when this
is finished successfully, it continues with the suit ‘
zabbix-server-
pgsql’.
We now create our only playbook
vi test/integration/default
.ym
---
- hosts:
localhost
roles:
- role:
ansible-
zabbix-agent
We have configured the playbook
which will be executed against the docker image on ‘
localhost’.
But we are not there yet, we will
need create some
serverspec tests to.
create the following directory: test/integration/default/
serverspec/
localhost
create the
spec_helper.rb file
you’ll create
an Jenkins job which pulls for changes from your
git repository. You’ll create
an job which has 2 “Execute shells” steps:
Install bundler and test-kitchen and run bundle install
Execute kitchen test
Installation of the gem
step:s:
1st build step:
gem install bundler
--no-
rdoc --no-
ri
gem install test-kitchen
--no-
rdoc --no-
ri
bundle install
And 2nd build step:
kitchen test
https://werner-dijkerman.nl/2015/08/20/using-test-kitchen-with-docker-and-serverspec-to-test-ansible-roles/
- Testing Ansible with Kitchen
Using kitchen we can automate the testing of our configuration management code across a variety of platforms using Docker as a driver
to setup the environment and
serverspec in order to perform the tests
https://www.tikalk.com/posts/2017/02/21/testing-ansible-with-kitchen/
- Prerequisite Tools/Packages
Install Ansible
Install Vagrant
Initializing an Ansible Role
Initializing kitchen-
ansible
A great tool for this is
kitchen-
ansible which is a derivative of test-kitchen
designed specifically for Ansible.
Using Vagrant
The benefits of using Vagrant as the provider is that
full virtual machines are used as the base for provisioning. This means an entire guest operating system and all the
appropriate tools
are included in a self-contained virtual machine.
In some cases this is necessary over using Docker (see below) as some lower-level systems require low-level administrative privileges to work properly. These can either be dangerous to allow in Docker or,
in some cases, impossible.
Using Docker
Docker has the benefit of being significantly more lightweight than Vagrant. Docker doesn't build an entire virtual machine but
instead creates a container with just the parts of the system
that are different from the host operating system needed to run the code within the container.
Another draw-back with Docker development is that some functionality
is restricted in containers at very low levels. For example,
systemd is becoming more and more popular in modern Linux distributions but it requires certain low-level privileges in the kernel that
are normally restricted within Docker as they pose a security risk with other containers running on the same host. While there are ways of getting around this
particular issue, it requires forcing unsafe Docker usage and isn't entirely reliable.
Initialize a Docker-based test-kitchen project
kitchen init
--driver=docker --provisioner=ansible --create-
gemfile
Initialize a Vagrant-based test-kitchen project
kitchen init
--driver=vagrant --provisioner=ansible --create-
gemfile
Initializing an Ansible Role
ansible-galaxy init
helloworld
Initializing kitchen-
ansible
kitchen init
--driver=vagrant --provisioner=ansible --create-
gemfile
https://tech.superk.org/home/ansible-role-development
- ServerSpec is a framework that gives you RSpec tests for your infrastructure. Test-kitchen’s busser plugin utilizes busser-serverspec for executing ServerSpec tests.
https://kitchen.ci/docs/verifiers/serverspec/
- With Serverspec, you can write RSpec tests for checking your servers are configured correctly.
Serverspec tests your servers’ actual state by executing command locally, via SSH, via
WinRM, via Docker API and so on. So you
don’t need to install any agent softwares on your servers and can use any configuration management tools, Puppet, Ansible, CFEngine,
Itamae and so on
the true aim of
Serverspec is to help
refactoring infrastructure code.
http://serverspec.org/
It is a Ruby-based framework, which uses internally Shell
(Linux environments),
Powershell(Windows environment) scripts for checking the target machines if the configuration management tool has configured them correctly.
https://damyanon.net/post/getting-started-serverspec/
- Testing infrastructure with serverspec
Checking if your servers
are configured correctly can
be done with IT automation tools like Puppet, Chef, Ansible or Salt. They allow an administrator to specify a target configuration and ensure
it is applied. They can also run in a dry-run mode and report servers not matching the expected configuration.
Advanced use⚓︎
Out of the box,
serverspec provides a strong
fundation to build a compliance tool to
be run on all systems. It comes with some useful advanced tips,
like sharing tests among similar hosts or executing several tests in parallel.
By default,
serverspec-init generates a template where each host has its own directory with its unique set of tests.
serverspec only handles test execution on remote hosts: the test execution flow (
which tests are executed on which servers)
is delegated to some
Rakefile.
Parallel execution
By default,
each task is executed when the previous one has finished. With many hosts, this can take some time. rake provides the -
j flag to specify the number of tasks to
be executed in parallel and the -
m flag to apply parallelism to all tasks
This does not scale well if you have dozens or hundreds of hosts to test.
Moreover, the output
is mangled with parallel execution. Fortunately,
rspec comes with the ability to save results in JSON format. These per-host results can then
be consolidated into a single JSON file.
All this can be done in the
Rakefile:
For each task, set
rspec_opts to
--format
json --out
./reports/current/#{target}
.json. This
is done automatically by the subclass
ServerspecTask which also handles passing the hostname in an environment variable and a more concise and colored output
Add a task to collect the generated JSON files into a single report.
The test source code is also embedded in the report to make it self-sufficient.
Moreover, this task
is executed automatically by adding it as a dependency of the last
serverspec-related task.
https://vincent.bernat.ch/en/blog/2014-serverspec-test-infrastructure
- Writing Efficient Infrastructure Tests with Serverspec
One of the core tenants of infrastructure as code is testability; your infra code should
be covered with unit and integration
tests just like your application code and those tests should be run early and often
Serverspec is a great tool for verifying the end state of your infrastructure and
is commonly used in conjunction with Test Kitchen to help automate pipelines by launching a test instance upon each commit and executing your configuration management tool of choice (Chef, Puppet, Ansible etc), and then running tests against the newly configured instance to make sure everything’s kosher
https://www.singlestoneconsulting.com/articles/writing-efficient-infrastructure-tests-with-serverspec
Keep your system up &
runnin vs. Build according to a specification and prove compliance with it
https://www.netways.de/fileadmin/images/Events_Trainings/Events/OSDC/2014/Slides_2014/Andreas_Schmidt_Testing_server_infrastructure_with_serverspec.pdf
Serverspec is an integration testing framework written on top of the Ruby
RSpec dsl with custom resources and
matchers that form expectations targeted at infrastructure.
Serverspec tests verify the actual state of your infrastructure such as (bare-metal servers, virtual machines, cloud resources) and
ask the question are they configured correctly?
Test can be driven by many of the popular configuration management tools, like Puppet, Ansible, CFEngine and
Itamae.
https://stelligent.com/2016/08/17/introduction-to-serverspec-what-is-serverspec-and-how-do-we-use-it-at-stelligent-part1/
- RSpec is a unit test framework for the Ruby programming language. RSpec is different than traditional xUnit frameworks like JUnit because RSpec is a Behavior driven development tool. What this means is that, tests written in RSpec focus on the "behavior" of an application being tested. RSpec does not put emphasis on, how the application works but instead on how it behaves, in other words, what the application actually does.
https://www.tutorialspoint.com/rspec/index.htm
- Serverspec is the name of a Ruby tool which allows you to write simple tests, to validate that a server is correctly configured.
ServerSpec is designed to allow testing the state of a series of remote hosts. You express how your server should be
setup, and it will test that the current-setup matches your expectations.
the
serverspec tool
is written in Ruby, and
is distributed as a "gem" (which is the name given to self-contained Ruby libraries, tools, and extensions)
With this
Gemfile in-place you can now configure the libraries to
be downloaded beneath your test-directory, and this is a good thing because it means you
don't need to be
root, nor do you need to worry about the complications of system-wide gem installation and
maintainance
a top-level
Rakefile. rake-files are like make-files, but written in Ruby.
https://debian-administration.org/article/703/A_brief_introduction_to_server-testing_with_serverspec
- Automated server testing with Serverspec, output for Logstash, results in Kibana
Automagically create VMs (AWS, OpenStack, etc)
Configure the VMs with some config management tool (Puppet, Chef, etc)
Perform functional testing of VMs with
Serverspec
Output logs that
are collected by Logstash
Visualise output in Kibana
Install and set up a
la the Serverspec documentation
$ gem install
serverspec
$
mkdir /opt/
serverspec
$ cd /opt/
serverspec
$
serverspec-init
This will have created you a basic directory structure with some files to get you started. Right now we have:
$
ls /opt/
serverspec
Rakefile
spec/
spec_helper.rb
www
.example.com/
http://annaken.github.io/automated-testing-serverspec-output-logstash-results-kibana
Rake is a Make-like program implemented in Ruby.
Tasks and dependencies are specified in standard Ruby syntax.
https://ruby.github.io/rake/
- Getting Started with Rake
Rake is an Embedded Domain Specific Language (EDSL) because, beyond the walls of Ruby, it has no existence. The term EDSL suggests that Rake is a domain-specific language that
is embedded inside another language (Ruby) which has greater scope.
Rake extends Ruby, so you can use all the features and extensions that come with Ruby.
You can take advantage of Rake by using it to automate some tasks that have been continually challenging you.
https://www.sitepoint.com/rake-automate-things/
- Using Rake to ServerSpec test
If you don't like kitchen, or your team is using Rake you may
choose to use the rake spec command for
serverspec testing.
The directory layout is simpler than Kitchen, but requires more configuration as you need to create the following files;
Rakefile
spec_helper.rb
Vagrantfile
Provisioning script for the Vagrant VMs
http://steveshilling.blogspot.com/2017/05/puppet-rake-serverspec-testing.html
- You may want to run maintenance tasks, periodic calculations, or reporting in your production environment, while in development, you may want to trigger your full test suite to run.
The rake gem is Ruby’s most widely accepted solution for performing these types of tasks.
Rake is a ‘ruby build
program with capabilities similar to make’ providing you a convenient way to make your Ruby libraries executable on your system.
http://tutorials.jumpstartlab.com/topics/systems/automation.html
- This log can now be collected by Logstash, indexed by Elasticsearch, and visualised with Kibana.
Custom Resource Types in
Serverspec
Serverspec comes ready to go with many useful resource types.
Extending
Serverspec
I needed a resource provider, that could check
nginx configuration in multiple files at once:
Our
serverspec tests in the hardening project are not limited to just verifying Chef and Puppet runs. We also want them to check if a system has a valid configuration (compliance checks).
Without custom resource types, this is not possible, as you sometimes cannot expect
a system to be configured in a certain way.
http://arlimus.github.io/articles/custom.resource.types.in.serverspec/
In these examples, I'm using should syntax instead of expect syntax because I think should syntax is more readable than expect syntax and I like it.
Using expect
syntax is recommended way because adding should to every object causes failures when used with
BasicObject-
subclassed proxy objects.
http://burtlo.github.io/serverspec.github.io/resource_types.html
- Testing Ansible with Kitchen
Install
Requirments
sudo apt-get install gem
sudo gem install test-kitchen
kitchen-docker kitchen-
ansible
https://www.tikalk.com/posts/2017/02/21/testing-ansible-with-kitchen/
- Writing Sensu Plugin Tests with Test-Kitchen and Serverspec
My simple heuristic is unit tests for libraries, integration tests for plugins.
Install Dependencies
For plugins we have standardized our integration testing around the following tools:
Test-kitchen: Provides a framework for developing and testing infrastructure code and software on isolated platforms.
Kitchen-docker: Docker driver for test-kitchen to allow use in a more lightweight fashion than traditional virtualization such as vagrant +
virtualbox.
Serverspec: The verification platform. It is an expansion on
rspec that allows you to write very simple tests.
Setting Up Your Framework
What platforms do I want to test? For example
Debian, Centos, Windows, etc.
What versions of languages do I want to test? For example ruby2.1, 2.2, 2.3.0, 2.4.0
What driver you will use for test-kitchen?
For
example kitchen-docker
(preferred),
kitchen-vagrant (
a bit heavy but super helpful for certain scenarios),
kitchen-
dokken (a
pretty reasonable solution when using process supervisors), or
kitchen-ec2 (convenient but costs money).
https://dzone.com/articles/writing-sensu-plugin-tests-with-test-kitchen-and-s
- Integration Testing Infrastructure As Code With Chef, Puppet, And KitchenCI
Integration Testing
Basically, we want to automate the manual approach we used to verify if
a specification is met and get a nice report
indicating success or failure.
One very popular approach is
Rspec
RSpec is a testing tool for the Ruby programming language. Born under the banner of Behaviour-Driven Development, it is designed to make Test-Driven Development a productive and enjoyable experience
Rspec is a Domain Specific Language for Testing. And there is an even better matching candidate: Serverspec
With serverspec, you can write RSpec tests for checking your servers are configured correctly.
With serverspec, you can write RSpec tests for checking your servers are configured correctly.
Serverspec supports a lot of resource types out of the box. Have a look at Resource Types.
This is agnostic to the method we provisioned our server! Manual, Chef, Puppet, Saltstack, Ansible, … you name it.
To be able to support multiple test suites lets organize them in directories and use a Rakefile to choose which suite to run.
Converge The Nodes
Now its time to provide some infrastructure-as-code to be able to converge any node to our specification
You can find this in the repo tests-kitchen-example
https://github.com/ehaselwanter/tests-kitchen-example
The Puppet Implementation
https://forge.puppet.com/puppetlabs/ntp
The Chef Implementation
https://supermarket.chef.io/cookbooks/ntp
Don’t Repeat Yourself In Integration Testing
Now we are able to converge our node with Chef or Puppet, but we still have to run every step manually. It’s time to bring everything together. Have Puppet as well as Chef converge our node and verify it automatically.
Test-Kitchen must be made aware that we already have our tests somewhere, and that we want to use them in our Puppet as well as Chef integration test scenario.
http://ehaselwanter.com/en/blog/2014/06/03/integration-testing-infrastructure-as-code-with-chef-puppet-and-kitchenci/
The most recent thing I’ve done is set up a Jenkins build server to run test-kitchen on cookbooks.
The cookbook, kitchen-jenkins is available on the Chef Community site
https://supermarket.chef.io/cookbooks/kitchen-jenkins
http://jtimberman.housepub.org/blog/2013/05/08/test-kitchen-and-jenkins/
- We started out by running kitchen tests locally, on our development machines, agreeing to make sure the tests passed every time we made changes to our cookbooks.
we had decided to build our test suite on a very interesting tool called Leibniz,
This is basically a glue layer between cucumber and test kitchen, and it enabled us to develop our infrastructure using the Behavior Driven Development approach that we are growingly familiar with.
a Jenkins build that automatically runs all of our infrastructure tests and is mainly based on the following tools:
Test Kitchen, automating the creation of test machines for different platforms
Vagrant, used as a driver for Test Kitchen, is in charge of actually instantiating and managing the machine’s state
Chef, used to provision the test machine bringing it into the desired state, so it can be tested as necessary
Libvirt, the virtualization solution that we adopted for the test machines
how to setup a Jenkins build to run Kitchen tests using Vagrant and libvirt.
In our setup we used two separate machines: one is a VM running Jenkins and one is a host machine in charge of hosting the test machines.
Install Vagrant on the host machine
Vagrant plugins
In order to use libvirt as virtualization solution for the test VMs, a few Vagrant plugins are necessary
vagrant-libvirt adds a Libvirt provider to Vagrant
vagrant-mutate Given the scarce availability of Vagrant boxes for Libvirt, this plugin allows to adapt boxes originally prepared for other providers (e.g. Virtualbox) to Libvirt
Ruby environment
This is an optional step, but it is highly recommended as it isolates the ruby installation used by this build from the system ruby and simplifies maintenance as well as troubleshooting.
Install the rbenv Jenkins plugin
It can be used to instruct the Jenkins build to use a specific rbenv instead of the system’s one. This plugin can be easily installed using Jenkins’ plugin management interface.
Configure the Jenkins build
add a build step of type ‘Execute shell’ to install the ruby dependencies:
cd /path/to/cookbook_s_Gemfile;
bundle install;
Prepare Vagrant boxes
you can download a Debian 8.1 box originally prepared for virtualbox with the following command
vagrant box add ospcode-debian-8.1 box_url
where box_url should be updated to point to a valid box url (the boxes normally used by Test Kitchen can be found here)
https://github.com/chef/bento
it can be adapted for Libvirt like this
vagrant mutate ospcode-debian-8.1 libvirt
Configure Kitchen to use Libvirt
By default, Test Kitchen will try to use virtualbox as provider and will bail out if it does not find it
The actual tests
we started out test suite using Leibniz.
we eventually decided to switch to something else. Our choice was first BATs tests and then Serverspec.
Serverspec is, as of today, our framework of choice for testing our infrastructure with its expressive and comprehensive set of resource types.
Troubleshooting
two environment variables can be used that instruct respectively test kitchen and Vagrant to be more verbose about their output:
export KITCHEN_LOG=‘debug’
export VAGRANT_LOG=‘debug’
we will have to find a way to instruct kitchen to, in turn, instruct serverspec to produce JUnit-style test reports that Jenkins can easily parse.
An additional improvement can take advantage of the possibility of creating custom packer boxes that have basic common software and configuration already pre-installed.
This can noticeably speed up the time to prepare the test machines during our builds.
Furthermore, a possible performance bump can be obtained by caching as much as possible of the resources that each test machine downloads every single time the tests run, like software update packages, gems and so on.
the vagrant-cachier plugin for Vagrant looks like the perfect tool for the job.
http://www.agilosoftware.com/blog/configuring-test-kitchen-on-jenkins/
- Getting Started Writing Chef Cookbooks the Berkshelf Way, Part 3
Test Kitchen is built on top of vagrant and supplements the Vagrantfile file you have been using so far in this series to do local automated testing.
Iteration #13 - Install Test Kitchen
Edit myface/Gemfile and add the following lines to load the Test Kitchen gems
gem 'test-kitchen'
gem 'kitchen-vagrant'
After you have updated the Gemfile run bundle install to download the test-kitchen gem and all its dependencies
Iteration #14 - Create a Kitchen YAML file
In order to use Test Kitchen on a cookbook, first you need to add a few more dependencies and create a template Kitchen YAML file. Test Kitchen makes this easy by providing the kitchen init command to perform all these initialization steps automatically
$ kitchen init
create .kitchen.yml
append Thorfile
create test/integration/default
append .gitignore
append .gitignore
append Gemfile
append Gemfile
You must run 'bundle install' to fetch any new gems.
Since kitchen init modified your Gemfile, you need to re-run bundle install (as suggested above) to pick up the new gem dependencies:
Most importantly, this new bundle install pass installed the kitchen-vagrant vagrant driver for Test Kitchen.
Everything in the YAML file should be straightforward to understand, except perhaps the attributes item in the suites stanza. These values came from the Vagrantfile we used in the previous installments of this series
For example, you can assign a host-only network IP so you can look at the MyFace website with a browser on your host. Add the following network: block to a platform’s driver_config::
Testing Iteration #14 - Provision with Test Kitchen
The Test Kitchen equivalent of the vagrant up command is kitchen converge.
Try running the kitchen converge command now to verify that your .kitchen.yml file is valid. When you run kitchen converge it will spin up a CentOS 6.5 vagrant test node instance and use Chef Solo to provision the MyFace cookbook on the test node:
Iteration #16 - Writing your first Serverspec test
It’s helpful to know that Test Kitchen was designed as a framework for post-convergence system testing.
You are supposed to set up a bunch of test instances, perform a Chef run to apply your cookbook’s changes to them, then when this is process is complete your tests can inspect the state of each test instance after the Chef run is finished.
http://misheska.com/blog/2013/08/06/getting-started-writing-chef-cookbooks-the-berkshelf-way-part3/
- A Test Kitchen Driver for Vagrant.
This driver works by generating a single Vagrantfile for each instance in a sandboxed directory. Since the Vagrantfile is written out on disk, Vagrant needs absolutely no knowledge of Test Kitchen. So no Vagrant plugins are required.
https://github.com/opscode/kitchen-vagrant/blob/master/README.md
- Docker Driver (kitchen-docker)
Chef Training Environment Setup
you’ll need to spin up a virtual machine with Docker installed in order to play around with a container environment.
We’ve created a Chef training environment that has Docker and the Chef Development Kit used in this book preinstalled on a Linux virtual machine.
It’s also a handy environment for playing around with containers using Test Kitchen.
make sure you install Vagrant and VirtualBox or Vagrant and VMware.
Create a directory for the Chef training environment project called chef and make it the current directory.
mkdir chef
cd chef
Add Test Kitchen support to the project using the default kitchen-vagrant driver by running kitchen init
kitchen init --create-gemfile
Then run bundle install to install the necessary gems for the Test Kitchen driver.
bundle install
Run kitchen create to spin up the image:
Then run kitchen login to use Docker
You will be running the Test Kitchen Docker driver inside this virtual machine
kitchen-docker Setup
Run the following kitchen init command to add Test Kitchen support to your project using the kitchen-docker driver:
$ kitchen init --driver=kitchen-docker --create-gemfile
Physical Machine Drivers
Until Test Kitchen supports chef-metal, the only way to use Test Kitchen with physical machines currently (other than your local host) is to use the kitchen-ssh driver. This is actually a generic way to integrate any kind of machine with Test Kitchen, not just physical machines. As long as the machine accepts ssh connections, it will work.
http://misheska.com/blog/2014/09/21/survey-of-test-kitchen-providers/#physical-machine-drivers
- InSpec framework for testing and auditing your applications and infrastructure. It can be utilized for validating test-kitchen instance via thekitchen-inspec plugin.
https://kitchen.ci/docs/verifiers/inspec/
- InSpec Tutorial: Day 1 - Hello World
I want to start a little series on InSpec to gain a fuller understanding, appreciation for, and greater flexibility with Compliance.
In reality, however, the built-in Compliance profiles will get you to 80% of what you need, and then you’ll want to add or modify a bunch of other specific tests from the profiles to meet the other 20% of your needs
It’s possible that you’re part of a company, perhaps without a dedicated security team, that uses Chef Compliance from within Chef Automate. And it’s possible that you’re totally content to run scans off of the premade CIS profiles and call it a day. That’s a huge selling point of Compliance.
In reality, however, the built-in Compliance profiles will get you to 80% of what you need, and then you’ll want to add or modify a bunch of other specific tests from the profiles to meet the other 20% of your needs.
If you already have the updated versions of Homebrew, Ruby, and InSpec, then skip ahead
It’s preferable to use the InSpec that comes with the ChefDK, but if you’re not using ChefDK otherwise, feel free to use the standalone version of InSpec.
http://www.anniehedgie.com/inspec-basics-1
- InSpec: Inspect Your Infrastructure
InSpec is an open-source testing framework for infrastructure with a human- and machine-readable language for specifying compliance, security and policy requirements
https://github.com/inspec/inspec#installation
- Compliance as Code: An Introduction to InSpec
Another aspect of its accessibility is that, while InSpec is owned by Chef, it’s completely platform agnostic,
Now, imagine that you can put the link to a stored InSpec profile where it says test.rb. If you have InSpec installed on your machine, then you can run either of these commands right now using a profile stored on the Chef Supermarket to verify that all updates have been installed on a Windows machine.
# run test stored on Github locally
inspec exec https://github.com/dev-sec/windows-patch-baseline
# run test stored on Github on remote windows host on WinRM
inspec exec https://github.com/dev-sec/windows-patch-baseline -t winrm://Administrator@windowshost --password 'your-password'
Now, imagine putting those commands in a CI/CD pipeline and using them across all of your environments<.
https://www.10thmagnitude.com/compliance-code-introduction-inspec/
Use InSpec as a Kitchen verifier with kitchen-inspec.
Add the InSpec verifier to the .kitchen.yml file:
https://www.inspec.io/docs/reference/plugin_kitchen_inspec/
InSpec is an open-source testing framework by Chef that enables you to specify compliance, security, and other policy requirements.
InSpec is code. Built on the Ruby programming language
InSpec can run on Windows and many Linux distributions. Although you can use InSpec to scan almost any system
Detect and correct
You can think of meeting your compliance and security goals as a two-phase process. We often refer to this process as detect and correct.
The first phase, detect, is knowing where your systems are potentially out of compliance or have potential security vulnerabilities.
The second phase, correct, involves remediating the compliance failures you've identified in the first phase.
After the correct process completes, you can run the detect process a second time to verify that each of your systems meets your policy requirements.
Although remediation can happen manually, you can use Chef or some other continuous automation framework to correct compliance failures for you.
This module focuses on the detect phase.
With InSpec, you can generate reports that prove your systems are in compliance in much less time.
1. Install Docker and Docker Compose
The installation is a set of containers orchestrated with Docker Compose, a tool for defining and running multi-container Docker applications.
The setup includes two systems – one that acts as your workstation and a second that acts as the target
3. Detect and correct manually
Let's say you require auditd, a user-space tool for security auditing, to be installed on each of your systems.
You'll first verify that the package is not installed on your workstation container and then manually install the package
Phase 1: detect
the first phase of meeting your compliance goals is to detect potential issues.You can see that auditd is not installed.
Phase 2: correct
To correct this issue, run the following apt-get install command to install the auditd package.
Although this is an elementary example, you may notice some potential problems with this manual approach
It's not portable.
dpkg and apt-get are specific to Ubuntu and other Debian-based systems.
auditd is called audit on other Linux distributions.
It's not documented.
You need a way to document the requirements and processes in a way others on your team can use.
It's not verifiable.
You need a way to collect and report the results to your compliance officer consistently.
4. Detect using InSpec
An InSpec test is called a control. Controls are grouped into profiles. Shortly, you'll download a basic InSpec profile we've created for you.
4.1. Explore the InSpec CLI
you typically run InSpec remotely on your targets, or the systems you want to monitor.
InSpec works over the SSH protocol when scanning Linux systems, and the WinRM protocol when scanning Windows systems.
Your auditd profile checks whether the auditd package is installed. But there are also other aspects of this package you might want to check. For example, you might want to verify that its configuration:
specifies the correct location of the log file.
incrementally writes audit log data to disk.
writes a warning to the syslog if disk space becomes low.
suspends the daemon if the disk becomes full.
You can express these requirements in your profile.
5.1. Discover community profiles
You can browse InSpec profiles on Chef Supermarket, supermarket.chef.io/tools. You can also see what's available from the InSpec CLI.
you know that Chef Supermarket is a place for the community to share Chef cookbooks.
You can also use and contribute InSpec profiles through Chef Supermarket.
You can run inspec supermarket info to get more info about a profile. As you explore the available profiles, you might discover the dev-sec/linux-baseline profile.
If you browse the source code for the dev-sec/linux-baseline profile, you would see that this profile provides many other commonly accepted hardening and security tests for Linux.
Automating correction
In practice, you might use Chef or other continuous automation software to correct issues. For example, here's Chef code that installs the auditd package if the package is not installed
Chef Automate also comes with a number of compliance profiles, including profiles that implement many DevSec and CIS recommendations.
You detected issues both by running InSpec locally and by running InSpec remotely on a target system.
You downloaded a basic InSpec profile and used a community profile from Chef Supermarket.
You limited your InSpec runs to certain controls and formatted the output as JSON so you can generate reports.
You packaged your profile to make it easier to distribute.
https://learn.chef.io/modules/try-inspec#/
- A Test-Kitchen provisioner takes care of configuring the compute instance provided by the driver. This is most commonly a configuration management framework like Chef or the Shell provisioner, both of which are included in test-kitchen by default.
https://kitchen.ci/docs/provisioners/
- A Test-Kitchen driver is what supports configuring the compute instance that is used for isolated testing. This is typically a local hypervisor, hypervisor abstraction layer (Vagrant), or cloud service (EC2).
https://kitchen.ci/docs/drivers/
- A Kitchen Instance is a combination of a Suite and a Platform as laid out in your .kitchen.yml file.
Kitchen has auto-named our only instance by combining the Suite name ("default") and the Platform name ("ubuntu-16.04") into a form that is safe for DNS and hostname records, namely "default-ubuntu-1604"
https://kitchen.ci/docs/getting-started/instances/
- Kitchen is modular so that one may use a variety of different drivers (Vagrant, EC2, Docker), provisioners (Chef, Ansible, Puppet), or verifiers (InSpec, Serverspec, BATS) but for the purposes of the guide we’re focusing on the default “happy path” of Vagrant with VirtualBox, Chef, and InSpec.
https://kitchen.ci/docs/getting-started/installing/
- Bats: Bash Automated Testing System
Bats is a TAP-compliant testing framework for Bash. It provides a simple way to verify that the UNIX programs you write behave as expected.
https://github.com/sstephenson/bats
- Extending the Ansible Test Kitchen tests with BATS tests
Server spec is a little bit limited, as we only tested the installation in an sort of technical way: Process is running, port is open, file is created and owner by user x etc.
Sometimes this isn’t enough to validate your setup, BATS is the answer.
we created the directory structure: test/integrations/default. And in this directory we created an directory named serverspec.
In this “default” directory we also create an directory named bats
https://werner-dijkerman.nl/2016/01/15/extending-the-ansible-test-kitchen-tests-with-bats-tests/
- One of the advantages of kitchen-inspec is that the InSpec tests are executed from the host over the transport (SSH or WinRM) to the instance. No tests need to be uploaded to the instance itself.
https://kitchen.ci/docs/getting-started/running-verify/
- Each instance has a simple state machine that tracks where it is in its lifecycle. Given its current state and the desired state, the instance is smart enough to run all actions in between current and desired
https://kitchen.ci/docs/getting-started/adding-platform/
- Install Chef Development Kit
Create A Repo
Test Driven Workflow
https://devopscube.com/chef-cookbook-testing-tutorial/
- Test kitchen is Chef’s integration testing framework. It enables writing tests, which run after VM is instantiated and converged using the cookbook. The tests run on VM and can verify that everything works as expected.
https://www.tutorialspoint.com/chef/chef_testing_cookbook_with_test_kitchen.htm
- First, Test-Kitchen is packaged as a RubyGem. You'll also need to install Git. To make VM provisioning easy, I'll be using Vagrant so we'll need that as well. And finally, use VirtualBox as a Test-Kitchen provider that will actually bring up the VMs. Once you've got each of these tools installed, you can proceed. Test-Kitchen can be run on Windows, Linux or MacOS
http://www.tomsitpro.com/articles/get-started-with-test-kitchen,1-3434.html
- Test Kitchen should be thought of as TDD for infrastructure
With the emergence of ‘infrastructure as code’, the responsibility for provisioning infrastructure is no longer the domain of a system administrator alone.
This is where Test Kitchen comes in – as the glue between provisioning tools e.g. Chef, Puppet or Ansible, the infrastructure being provisioned, e.g. AWS, Docker or VirtualBox and the tests to validate the setup is correct.
Historically, Test Kitchen is used to test single cookbooks or packages, but is easily adapted to test the group of cookbooks that make up your environment.
The concept behind Test Kitchen is that it allows you to provision (convergence testing) an environment on a given platform (or platforms) and then execute a suite of tests to verify the environment has been set up as expected.
This can be particularly useful if you want to verify a setup against different operating systems (OS) and/or OS package versions. This can even be set up as part of your Continuous Integration (CI) and/or delivery pipelines, and also feeds nicely into the concept of ‘immutable infrastructure’
The Provisioner section defines what you want to use to converge the environment. Chef Solo/Zero and shell provisioners are the easiest to get started with, but there are provisioners also available for Puppet and Ansible
the Test Suites section is where the actual value comes into play. This is where you define the tests to run against each platform
In more complex setups, it is possible to set the driver on a per-test or platform basis to allow you to run against different virtualisation platforms.
The easiest to get running is to write simple Bash script tests using Bats.
If you require more complex tests, then Serverspec might be a better fit since it has a far richer domain for writing platform-agnostic tests.
To make connecting to a provisioned environment easier, Test Kitchen provides a login command so you don’t have to worry about figuring out ports and SSH keys
After you have Test Kitchen in place, you could set up a tool such as Packer to generate your infrastructure VMs with confidence it will work. All this together would put you in a good position to implement a successful CD pipeline.
http://www.techinsight.io/review/devops-and-automation/testing-infrastructure-with-test-kitchen/
First, install the ChefDK. This package includes Chef, Kitchen, Berkshelf, and a variety of useful tools for the Chef ecosystem.
Kitchen is modular so that one may use a variety of different drivers (Vagrant, EC2, Docker), provisioners (Chef, Ansible, Puppet), or verifiers (InSpec,
Serverspec, BATS) but for
the purposes of the guide we're focusing on the default "happy path" of Vagrant with
VirtualBox, Chef, and InSpec.
https://kitchen.ci/docs/getting-started/installing
- Integration Testing for Chef-Driven Infrastructure with Test Kitchen
To start writing Serverspec tests, you need to create a directory named integration inside the test directory, where all the integration tests live. This directory should contain a subdirectory for each testing framework we'll use, which means that you are able to use many testing frameworks as you want on the same suite, without any collision.
We intend to use serverspec as the framework of choice, so let's create a corresponding directory structure for it:
The first thing we need is a Ruby helper script which loads Serverspec and sets the general configuration options, like the path used by the binary while executing tests.
With Serverspec, there is a much nicer way to check specific resources like commands.
Serverspec can also check the status of packages, which we can use in this case, since our example used packages provided by our distribution of choice.
In the RSpec manner, every test should include the standard describe / it structure for defining test cases
Because the instance is already converged in the step above, you can easily apply new changes to it and check test results.
Integration tests for servers managed by Chef
Test Kitchen as a test runner for virtual machines, backed by Vagrant and VirtualBox
The actual test will be written in Ruby using the Serverspec testing framework.
installing Vim from source
test two scenarios, one that includes the recipe for installing Vim from packages, and one that will install it from the source.
Test Kitchen is a test automatization tool distributed with ChefDK.
It manages virtual machines, internally called nodes
When running integration tests, you can and should use the same Chef configuration as the one you run on a real server - the same run list, recipes, roles and attributes.
Optionally, you can provide custom attributes used only in the test environment, like fake data for example.
A Node can be represented with any type of virtualization via Test Kitchen's plugins, called drivers.
https://semaphoreci.com/community/tutorials/integration-testing-for-chef-driven-infrastructure-with-test-kitchen
- InSpec is compliance as code
Turn your compliance, security, and other policy requirements into automated tests
https://www.inspec.io/
Packer is easy to use and automates the creation of any type of machine image. It embraces modern configuration management by encouraging you to use a framework such as Chef or Puppet to install and configure the software within your Packer-made images.
Super fast infrastructure deployment. Packer images allow you to launch completely provisioned and configured machines in seconds, rather than several minutes or hours
Multi-provider portability. Because Packer creates identical images for multiple platforms, you can run production in AWS, staging/QA in a private cloud like OpenStack, and development in desktop virtualization solutions such as VMware or VirtualBox. Each environment is running an identical machine image, giving ultimate portability.
Improved stability. Packer installs and configures all the software for a machine at the time the image is built. If there are bugs in these scripts, they'll be caught early, rather than several minutes after a machine is launched.
Greater testability. After a machine image is built, that machine image can be quickly launched and smoke tested to verify that things appear to be working
https://www.packer.io/intro/why.html
- With this builder, you can repeatedly create Docker images without the use of a Dockerfile. You don't need to know the syntax or semantics of Dockerfiles.
https://www.packer.io/docs/builders/docker.html
- Testing Packer builds with Serverspec
Lately, I’ve been working on building base AMIs for our infrastructure using Packer, and verifying these images with Serverspec. In the opening stages my workflow looked like:
Build AMI with Packer
Launch instance based on AMI
Run Serverspec tests against an instance
This works fine, and could potentially be converted into a Jenkins pipeline
My preferred pipeline would look like:
Build AMI with Packer
As the final build step, run Serverspec
If the tests fail, abort the build
http://annaken.github.io/testing-packer-builds-with-serverspec
Packer is lightweight, portable, and command-line driven. This makes it the perfect tool to put in the middle of your continuous delivery pipeline. Packer can be used to generate new machine images for multiple platforms on every change to Chef/Puppet.
As part of this pipeline, the newly created images can then be launched and tested, verifying the infrastructure changes work. If the tests pass, you can be confident that the image will work when deployed. This brings a new level of stability and testability to infrastructure changes.
Dev/Prod Parity
Packer helps keep development, staging, and production as similar as possible. Packer can be used to generate images for multiple platforms at the same time. So if you use AWS for production and VMware (perhaps with Vagrant) for development, you can generate both an AMI and a VMware machine using Packer at the same time from the same template.
Appliance/Demo Creation
Since Packer creates consistent images for multiple platforms in parallel, it is perfect for creating appliances and disposable product demos. As your software changes, you can automatically create appliances with the software pre-installed
https://www.packer.io/intro/use-cases.html
- In the previous page of this guide, you created your first image with Packer. The image you just built, however, was basically just a repackaging of a previously existing base AMI. The real utility of Packer comes from being able to install and configure software into the images as well. This stage is also known as the provision step. Packer fully supports automated provisioning in order to install software onto the machines prior to turning them into images.
This way, the image we end up building actually contains Redis pre-installed.
https://www.packer.io/intro/getting-started/provision.html
So far we've shown how Packer can automatically build an image and provision it. This on its own is already quite powerful. But Packer can do better than that. Packer can create multiple images for multiple platforms in parallel, all configured from a single template
https://www.packer.io/intro/getting-started/parallel-builds.html
Packer also has the ability to take the results of a builder (such as an AMI or plain VMware image) and turn it into a Vagrant box.
Post-processors are a generally very useful concept. While the example on this getting-started page will be creating Vagrant images, post-processors have many interesting use cases. For example, you can write a post-processor to compress artifacts, upload them, test them, etc.
https://www.packer.io/intro/getting-started/vagrant.html
- Build, Test, and Automate Server Image Creation
This combination reduced our time-to-deploy, took our visibility from ‘translucent’ to ‘transparent’, improved our traceability
Problem
Spin up an EC2 instance using a custom base image
Run an Ansible playbook to provision the instance
Do a manual sanity check for all the services running on the instance
building the server image is slow, and there are no checks in place to test the image before use
Additionally, there were no provisioning logs for debugging the server image, which made it difficult for our Operations Engineers to troubleshoot
Packer is a tool for creating server images for multiple platforms.
It is easy to use and automates the process of creating server images. It supports multiple provisioners, all built into Packer.
Challenges with Packer
as Packer uses Ansible “local” provisioner which requires the playbook to be run locally on the server being provisioned. Our playbooks always assume the servers are being provisioned remotely, which led problems because some playbooks are shared across projects and require very specific path inclusions. These playbooks had to be rewritten in a way that can work with Packer.
While using the Ansible provisioner we found that the playbooks that were written using “roles” could be easily integrated with Packer. Some of our Ansible playbooks are shared across various projects
Provision Logs
During the provisioning process, the logs that are generated by Ansible are stored on the server image for debugging purposes.
Benefits of Using Packer
There are various benefits of using Packer in terms of performance, automation, and security:
Benefits of Using Packer
There are various benefits of using Packer in terms of performance, automation, and security:
Packer spins up an EC2 instance, creates temporary security groups for the instance, creates temporary keys, provisions the instance, creates an AMI, and terminates the instances – and it’s all completely automated
Packer uploads all the Ansible playbooks and associated variables to the remote server, and then runs the provisioner locally on that machine. It has a default staging directory (/tmp/packer-provisioner-ansible-local/) that it creates on the remote server, and this is the location where it stores all the playbooks, variables, and roles. Running the playbooks locally on the instance is much faster than running them remotely.
Packer implements parallelization of all the processes that it implements
With Packer we supply Amazon’s API keys locally. The temporary keys that are created when the instance is spun up are removed after the instance is provisioned, for increased security.
Testing Before Creating Server Images
What is ServerSpec?
ServerSpec offers RSpec tests for your provisioned server. RSpec is commonly used as a testing tool in Ruby programming, made to easily test your servers by executing few commands locally.
Integrating ServerSpec with Packer
ServerSpec was integrated with Packer right after the provisioning was complete. This was done by using Packer’s “shell” and “file” provisioners.
Automation Using Jenkins
Jenkins was used to automate the process of creating and testing images. A Jenkins job was parameterized to take inputs such as project name, username, Amazon’s API keys, test flags, etc., which allowed our engineers to build project specific image rapidly without installing Packer and its CLI tools. Jenkins took care of the AMI tagging, CLI parameters for Packer, and notifications to the engineering team about the status of the Job:
http://code.hootsuite.com/build-test-and-automate-server-image-creation/
Vagrant provides a repeatable VM development environment
Packer
The typical workflow is for developer to create development environment in Vagrant and once it becomes stable, the production image can be built from Packer
Since the provisioning part is baked into the image, the deployment of production images becomes much faster.
Terraform allows us to describe the whole data center as a configuration file and it takes care of deploying the infrastructure on either VM, baremetal or cloud. Once the configuration file is under source code, Infrastructure can be treated as Software
it is provider agnostic and it can integrate with any provider.
https://sreeninet.wordpress.com/2016/02/06/hashicorp-atlas-workflow-with-vagrant-packer-and-terraform/
- Create and configure lightweight, reproducible, and portable development environments.
https://www.vagrantup.com/
- Vagrant vs. Docker
Currently, Docker lacks support for certain operating systems (such as BSD). If your target deployment is one of these operating systems, Docker will not provide the same production parity as a tool like Vagrant. Vagrant will allow you to run a Windows development environment on Mac or Linux, as well.
https://www.vagrantup.com/intro/vs/docker.html
- Creating Vagrant Boxes with Packer
the repeatable and automated builds will end any manual management of boxes
all boxes will be stored and served from Terraform Enterprise, keeping a history along the way
https://www.terraform.io/docs/enterprise/packer/artifacts/creating-vagrant-boxes.html?_ga=2.89191771.1755382601.1512478494-690169036.1512478494
- Installing Vagrant and Virtual box on Ubuntu 14.04 LTS
Vagrant is an open source tool for building a complete virtual development environment.
Very often, a test environment is required for testing the latest release and new tools.
Also, it reduces the time spent in re-building your OS.
By default, vagrant uses virtualbox for managing the Virtualization.
Vagrant acts as the central configuration for managing/deploying multiple reproducible virtual environments with the same configuration.
https://www.olindata.com/en/blog/2014/07/installing-vagrant-and-virtual-box-ubuntu-1404-lts
- Sharing a common development environment with everyone on your team is important.
Packer lets you build Virtual Machine Images for different providers from one json file.
You can use the same file and commands to build an image on AWS, Digital Ocean or for VirtualBox and vagrant
You need Virtualbox and Packer installed.
Packer is even easier, just download the right zip for your system and unzip it into your PATH
Packer uses builders, provisioners, and post-processors as the main configuration attributes.
A builder can, for example, be VirtualBox or AWS.
A provisioner can be used to run different scripts.
Post-processors can be run after the machine image is done.
For example, converting a Virtualbox image into a suitable image for vagrant is done in a post-processor.
https://blog.codeship.com/packer-vagrant-tutorial/
- A Vagrant “.box” is simply a tarred gzip package containing, at a minimum, the VM’s metafiles, disk image(s), and a metadata.json; which identifies the provider the box has been created for.
Vagrant is a tool developed at HashiCorp intended to relieve the effort to set up the development environment.
According to its document, Vagrant is able to “create and configure lightweight, reproducible, and portable development environments”.
It realizes the vision through virtualization technologies like VirtualBox.
The biggest pain point Vagrant solves is how to boot up a consistent development environment in every host.
The whole development environment is defined in Vagrantfile which is Ruby code in fact. That means the environment can be versioned with version control system like Git and thus could be shared easily.
The Vagrant command line tool creates a Vagrantfile with following content which indicates that vagrant should boot up a virtual machine based on the OS image called centos/7.
Vagrant tries to locate the OS image in the local image repo. If not found, it attempts to download the image from HashiCorp’s box search service. The path of local image repo is $HOME/.vagrant.d/boxes
Create a virtual machine based on the OS image
A typical Vagrant development environment includes 2 parts
A virtual machine
Toolchains like GCC, lib dependencies and Java running in the virtual machine
Provider means the type of underlying virtualization technology.
Vagrant is not a hypervisor itself. Instead, it is just abstraction of managing virtual machines in different hypervisors.
Box packages OS images required by the underlying hypervisor to run the virtual machine.
Typically, each hypervisor has its own OS image format.
Use Packer, another tool from HashiCorp to build boxes from iso images.
Chef provides a whole bunch of Packer templates in GitHub to make life much easier.
Use Packer, another tool from HashiCorp to build boxes from iso images. Chef provides a whole bunch of Packer templates in GitHub to make life much easier.
Create box from existing virtual machines running in the different hypervisor.
Provisioner
It is impractical to package all the development tools in a box thus the Vagrant provides facility to customize the virtual machine.
There are many deveops tools available to automate configuration management such as Ansible, Puppet, SaltStack, and Chef.
makes an abstract on different tools so the users could choose any technique they want. The tools are called provisioners.
QEMU provider: VirtualBox is great and most of the time it is adequate. But it does not support nested virtualization which is the ability to run virtual machines within another virtual machine. Most of the hypervisors like VMware Fusion, Hyper-V and QEMU except VirtualBox support such a feature. Nested virtualization is very useful when creating demo cluster. There is also a company named Ravello who has been acquired by Oracle focusing on nested virtualization technique. Hyper-V is not cross-platform and VMware Fusion/Workstation is charged. Vagrant provider for VMware Fusion/Workstation is also charged. So QEMU is another provider worthy playing with.
Docker provider: As one of the hottest techniques, Docker is worth noting. Compared with hypervisors like VirtualBox, Docker is much much more lightweight. It is not a hypervisor, but it does provide some abstraction of a virtual machine. Its overhead is very low too which makes it is easy to boot dozens of Docker containers in your laptop. Of course, it is not as versatile as hypervisors but if it meets your need, it would be a good choice.
https://blog.jeffli.me/blog/2016/12/06/a-beginners-guide-for-vagrant/
- Figure-1 depicts a typical home networking topology
The public network gives the VM the same network visibility as the Vagrant host.
The word public does not mean that the IP addresses have to be public routable IP addresses.
The doc also states that bridged networking would be more accurate
In fact, public networking is called bridged networking in the early days
in private networking, a virtualized subnet that is invisible from outside of Vagrant host will be created by the underlying provider
Forwarded ports expose the accessibility of virtual machines to the world outside the Vagrant host. In Figure-4, assume that an Nginx HTTP server runs in the virtual machine which uses private networking. Thus it is impossible to access the service from outside of the host. But through a forwarded port, the service is able to be exposed as a service of the Vagrant host which makes it publi
Public networking attaches virtual machines to the same subnet with the Vagrant host
Private networking hides virtual machines from the outside of the Vagrant host
Forwarded ports create tunnels from virtual machines to outside world
https://blog.jeffli.me/blog/2017/04/22/vagrant-networking-explained/
To use the available boxes just replace {title} and {url} with the information in the table below.
$ vagrant box add {title} {url}
$ vagrant init {title}
$ vagrant up
http://www.vagrantbox.es/
- There is a special category of boxes known as "base boxes." These boxes contain the bare minimum required for Vagrant to function, are generally not made by repackaging an existing Vagrant environment (hence the "base" in the "base box").
https://www.vagrantup.com/docs/boxes/base.html
- This is useful since boxes typically are not built perfectly for your use case. Of course, if you want to just use vagrant ssh and install the software by hand, that works. But by using the provisioning systems built-in to Vagrant, it automates the process so that it is repeatable. Most importantly, it requires no human interaction, so you can vagrant destroy and vagrant up and have a fully ready-to-go work environment with a single command. Powerful.
https://www.vagrantup.com/docs/provisioning/
- Suspending the virtual machine by calling vagrant suspend will save the current running state of the machine and stop it.
When you are ready to begin working again, just run vagrant up,
Halting the virtual machine by calling vagrant halt will gracefully shut down the guest operating system and power down the guest machine. You can use vagrant up when you are ready to boot it again.
Destroying the virtual machine by calling vagrant destroy will remove all traces of the guest machine from your system. It'll stop the guest machine, power it down, and remove all of the guest hard disks. Again, when you are ready to work again, just issue a vagrant up.
https://www.vagrantup.com/intro/getting-started/teardown.html
- Once you have a provider installed, you do not need to make any modifications to your Vagrantfile, just vagrant up with the proper provider and Vagrant will do the rest:
https://www.vagrantup.com/intro/getting-started/providers.html
- While Vagrant ships out of the box with support for VirtualBox, Hyper-V, and Docker, Vagrant has the ability to manage other types of machines as well. This is done by using other providers with Vagrant.
https://www.vagrantup.com/docs/providers/
Builders are responsible for creating machines and generating images from them for various platforms. For example, there are separate builders for EC2, VMware, VirtualBox, etc
https://www.packer.io/docs/builders/index.html
The VirtualBox Packer builder is able to create VirtualBox virtual machines and export them in the OVA or OVF format.
https://www.packer.io/docs/builders/virtualbox.html
- The builder builds a virtual machine by creating a new virtual machine from scratch, booting it, installing an OS, provisioning software within the OS, then shutting it down. The result of the VirtualBox builder is a directory containing all the files necessary to run the virtual machine portably.
https://www.packer.io/docs/builders/virtualbox-iso.html
- In NAT mode, the guest network interface is assigned to the IPv4 range 10.0.x.0/24 by default where x corresponds to the instance of the NAT interface +2. So x is 2 when there is only one NAT instance active. In that case the guest is assigned to the address 10.0.2.15, the gateway is set to 10.0.2.2 and the name server can be found at 10.0.2.3.
If, for any reason, the NAT network needs to be changed, this can be achieved with the following command:
VBoxManage modifyvm "VM name" --natnet1 "192.168/16"
This command would reserve the network addresses from 192.168.0.0 to 192.168.254.254 for the first NAT network instance of "VM name". The guest IP would be assigned to 192.168.0.15 and the default gateway could be found at 192.168.0.2.
https://www.virtualbox.org/manual/ch09.html#changenat
- Note that having the ansible.verbose option enabled will instruct Vagrant to show the full ansible-playbook command used behind the scene
re-run a playbook on an existing VM
$ vagrant provision
http://docs.ansible.com/ansible/latest/guide_vagrant.html
Vagrant is able to define and control multiple guest machines per Vagrantfile.
This is known as a "multi-machine" environment
These machines are generally able to work together or are somehow associated with each other. Here are some use-cases people are using multi-machine environments for today:
Accurately modeling a multi-server production topology, such as separating a web and database server.
Modeling a distributed system and how they interact with each other.
Testing an interface, such as an API to a service component.
Disaster-case testing: machines dying, network partitions, slow networks, inconsistent worldviews, etc.
Commands that only make sense to target a single machine, such as vagrant ssh, now require the name of the machine to control. Using the example above, you would say vagrant ssh web or vagrant ssh DB.
In order to facilitate communication within machines in a multi-machine setup, the various networking options should be used. In particular, the private network can be used to make a private network between multiple machines and the host.
https://www.vagrantup.com/docs/multi-machine/
- The Docker provider does not require a config.vm.box setting. Since the "base image" for a Docker container is pulled from the Docker Index or built from a Dockerfile, the box does not add much value, and is optional for this provider.
If the system cannot run Linux containers natively, Vagrant automatically spins up a "host VM" to run Docker. This allows your Docker-based Vagrant environments to remain portable, without inconsistencies depending on the platform they are running on.
Vagrant will spin up a single instance of a host VM and run multiple containers on this one VM.
By default, the host VM Vagrant spins up is backed by boot2docker, because it launches quickly and uses little resources.
But the host VM can be customized to point to any Vagrantfile.
This allows the host VM to more closely match production by running a VM running Ubuntu, RHEL, etc. It can run any operating system supported by Vagrant.
https://www.vagrantup.com/docs/docker/basics.html
- Docker requires a Linux host as Docker itself leverages the LXC (Linux Containers) mechanism in Linux. This means that in order to work with Docker on non-Linux systems – Windows, Mac OS X, Solaris – we first need to set up a Virtual Machine running Linux.
Vagrant has embraced Docker as a provider, just as it supports providers for VirtualBox and VMWare. This means that a Vagrant configuration file can describe a Docker container just as it can describe the configuration of a VirtualBox VM.
One very nice additional touch is that Vagrant is aware of the fact that Docker containers cannot run natively at present on Windows or Mac OS X
When Vagrant is asked to provision a Docker container on one of these operating systems, it can either automatically engage boot2docker as a vehicle to create and run the Docker container in or provision a Linux based VM image that it then enables for Docker and creates the Docker container into
https://technology.amis.nl/2015/08/22/first-steps-with-provisioning-of-docker-containers-using-vagrant-as-provider/
- This page only documents the specific parts of the ansible_local provisioner. General Ansible concepts like Playbook or Inventory are shortly explained in the introduction to Ansible and Vagrant.
The Ansible Local provisioner requires that all the Ansible Playbook files are available on the guest machine, at the location referred by the provisioning_path option. Usually, these files are initially present on the host machine (as part of your Vagrant project), and it is quite easy to share them with a Vagrant Synced Folder.
https://www.vagrantup.com/docs/provisioning/ansible_local.html
Community-driven templates and tools for creating cloud, virtual machines, containers and metal operating system environments
https://github.com/boxcutter
- Bento is a project that encapsulates Packer templates for building Vagrant base boxes. A subset of templates are built and published to the bento org on Vagrant Cloud. The boxes also serve as default boxes for kitchen-vagrant.
https://github.com/chef/bento
- Using kickstart, a system administrator can create a single file containing the answers to all the questions that would normally be asked during a typical RHEL Linux installation.
Use kickstart GUI tool called “Kickstart Configurator” (run system-config-kickstart command to start the tool) to create a file called ks.cfg as follows:
Upload this file to a web server as ks.cfg. You can use nfs server too.
KVM: Install CentOS / RHEL Using Kickstart File (Automated Installation)
https://www.cyberciti.biz/faq/kvm-install-centos-redhat-using-kickstart-ks-cfg/
- how to automate the installation of CentOS7 via a Kickstarter file located in an accessible web server over the Internet.
[OPTIONAL] Install CentOS7 using your preferred method
[OPTIONAL] Copy the resulting installation file located under /root/anaconda-ks.cfg
Open your kickstart file and begin writing your desired configuration
Save it when it suits your needs and upload it to any HTTP server you have in your reach (you can alternatively use onedrive, dropbox, or even github’s gist)
alternatively, install CentOS7 in an unattended installation manner and then modify the resulting kickstarter file named ‘anaconda-ks.cfg’, located under the /root directory.
- 26.2. How Do You Perform a Kickstart Installation?
Kickstart installations can be performed using a local DVD, a local hard drive, NFS, FTP, HTTP, or HTTPS.
To use Kickstart, you must:
Create a Kickstart file.
Make the Kickstart file available on removable media, a hard drive or a network location.
Create boot media, which will be used to begin the installation.
Make the installation source available.
Start the Kickstart installation.
The recommended approach to creating Kickstart files is to perform a manual installation on one system first.
After the installation completes, all choices made during the installation are saved into a file named anaconda-ks.cfg, located in the /root/ directory on the installed system.
You can then copy this file, make any changes you need, and use the resulting configuration file in further installations.
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/installation_guide/sect-kickstart-howto
- You can later change the password in ks.cfg file manually. If you chose to encrypt your password, the supported hash in Kickstart configuration is MD5. Use Open SSL command openssl passwd -1 yourpassword in Terminal to generate the new password.
2. Create Preseed file
Pressed commands work when they are directly written inside the Kickstart file
http://gyk.lt/ubuntu-14-04-desktop-unattended-installation/
https://marclop.svbtle.com/creating-an-automated-centos-7-install-via-kickstart-file
- In fact, some organizations dedicate multiple servers to a single service. (For example, I understand some enterprises dedicate a dozen servers just to the Domain Name Service [DNS].) With the advantages associated with virtualization, I suspect even some smaller organizations now configure 100 or more virtual servers (on fewer physical systems).
administrators need to be able to automate the Ubuntu installation process.
Automation of any Linux installation requires an “answers file” that configures the installation with information that would otherwise require real-time manual input.
The principles of Kickstart for Ubuntu and Red Hat are the same.
Before using Kickstart on an Ubuntu release, install the applicable Kickstart configuration tool.
http://infoyard.net/linux/how-to-automate-ubuntu-installation-with-kickstart.html
- Unattended Ubuntu installations made easy
Creating an unattended install consists of the following steps:
1. Create a configuration file, ks.cfg, using the GUI Kickstart tool.
2. Extract the files from the Ubuntu install ISO.
3. Add the ks.cfg file to the install disk and alter the boot menu to add automatic install as an install option.
4. Reconstitute the ISO file.
http://www.ubuntugeek.com/unattended-ubuntu-installations-made-easy.html
- Introduction to automated installation mechanisms
Red Hat Enterprise Linux: kickstart
SUSE Linux Enterprise: autoyast
Ubuntu: preseed
http://www.vm.ibm.com/education/lvc/LVC0803.pdf
- There are two most commonly used methods when it comes to automating Ubuntu installations: Preseed and Kickstart. The first one is an official method for Ubuntu to suppress all the questions in the installation process, but it has really steep learning curve if you are making automatic Ubuntu installer for the first time. Second method is really easy to start with because Ubuntu supports most of the RedHat's Kickstart options, but since it isn't an official method, we are still going to use some Preseed commands.
http://gyk.lt/ubuntu-14-04-desktop-unattended-installation/
- how to automate the deployment, configuration, and upgrades of your Linux infrastructure.
The Preboot eXecution Environment (PXE, also known as Pre-Execution Environment; sometimes pronounced “pixie”) is an environment to boot computers using a network interface independently of data storage devices (like hard disks) or installed operating systems.”
http://www.briancarpio.com/2012/04/04/system-automation-part-1/
- Difference between FAT and SAT
Input are simulated to test the operation of the software.
Factory Acceptance Test
The main objective of the FAT is to test the instrumented safety system (logic solver and associated software). The tests are normally carried out during the final part of the design and engineering phase before the final installation in the plant. The FAT is a customized procedure to verify the instrumented safety system and the instrumented safety functions according to the specification of safety requirements.
It is important to note here that there are different levels of a FAT. They can be done at a very basic level, such as configuring the main parts of the system with temporary wiring and making sure that everything moves as it is supposed to, or a more complete FAT can be carried out where the manufacturer physically constructs the entire system in your store to test it completely. In the last example, the system is dismantled, moved to the client’s site and reassembled
Benefits of the factory acceptance test
Clients can “touch and feel” the equipment while in operational mode before sending it.
The manufacturer can provide some initial customer training, which gives operations personnel more confidence when using the machinery for the first time in real environments.
The key people of the project from both sides are together, which makes it the ideal time to review the list of materials, analyze the necessary and recommended parts (for the start-up and the first year of operation) and review the procedures for maintenance and equipment limitations.
The comprehensive FAT documentation can be used as a template for the Validated installation / installation installation qualification part.
Based on the results of the FAT, both parties can create a list of additional elements that must be addressed before shipment.
Site Acceptance Testing
The Site Acceptance Test(SAT) is performed after all system have been tested and Verified. Before this final stage, the complete system must be tested and commissioned.
One final step in many SCADA projects is the SAT. This is usually a continuous operation or run of the complete system for a period of 1–2 weeks without any major problems. if some problem is occur The parties must again meet to discuss how to handle the situation and decide if the current operation is correct or if a change is required
https://automationforum.co/difference-between-fat-and-sat/