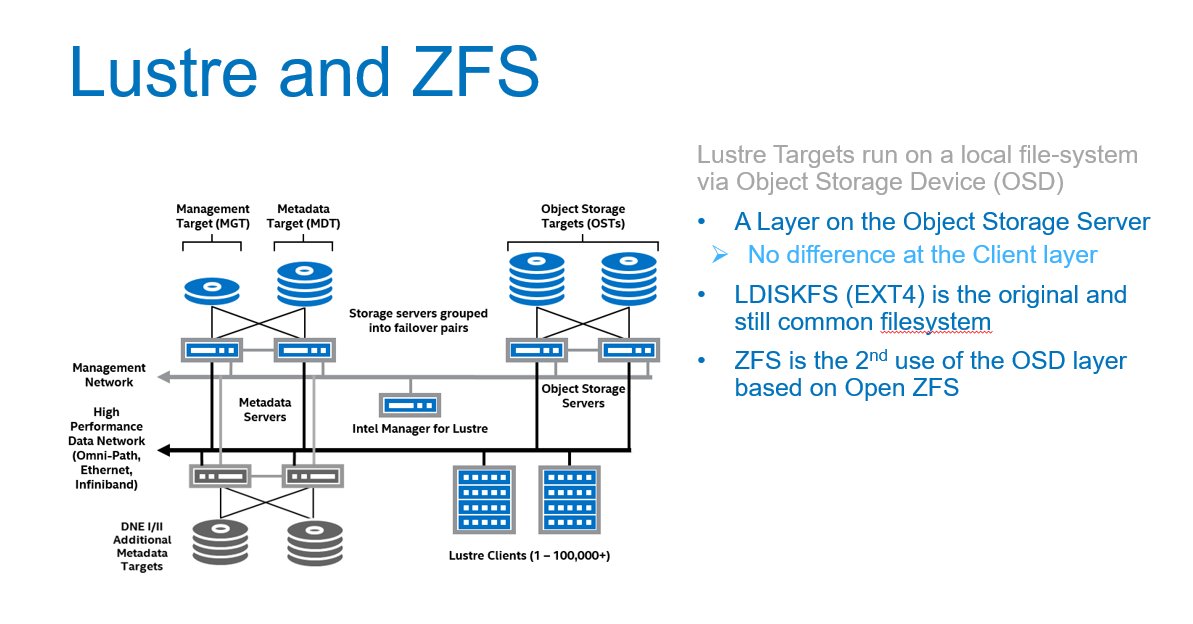
- The Lustre file system is a parallel file system used in a wide range of HPC environments
https://it.nec.com/it_IT/global/solutions/hpc/storage/lxfs.html?

- How the Lustre Developer Community is Advancing ZFS as a Lustre Back-end File System
Increasing support on Lustre for a 16 MB block size—already supported by ZFS—which will increase the size of data blocks written to each disk. A larger block size will reduce disk seeks and boost read performance. This, in turn, will require supporting a dynamic OSD-ZFS block size to prevent an increase in read/modify/write operations.
Implementing a dRAID mechanism instead of RAIDZ to boost performance when a drive fails. With RAIDZ, throughput of a disk group is limited by the spare disk’s bandwidth. dRAID will use a mechanism that distributes data to spare blocks among the remaining disks. Throughput is expected to improve even when the group is degraded because of a failed drive.
Creating a separate Metadata allocation class to allow a dedicated high throughput VDEV for storing Metadata. Since ZFS Metadata is smaller, but fundamental, reading it faster will result in enhanced IO performance. The VDEV should be an SSD or NVRAM, and it can be mirrored for redundancy.
https://www.codeproject.com/Articles/1191923/How-the-Lustre-Developer-Community-is-Advancing-ZF



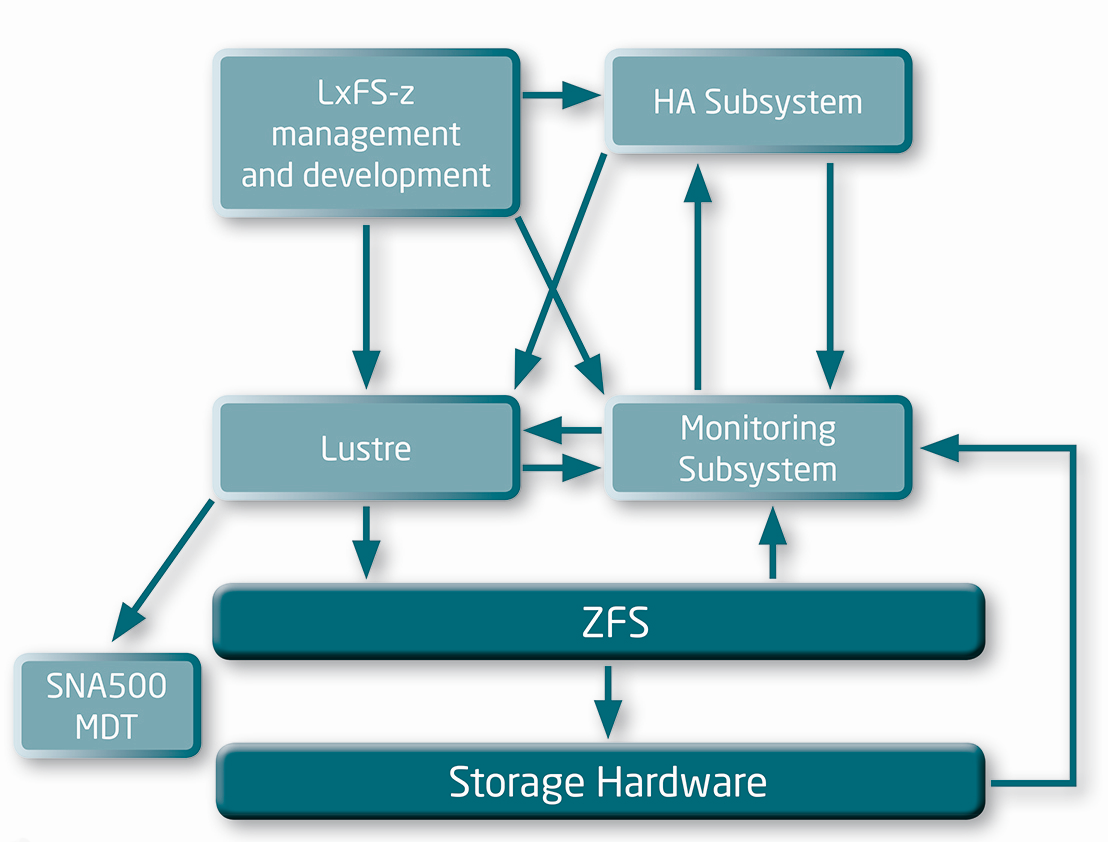
- ZFS OSD Hardware Considerations
The double parity implementation in OpenZFS (RAID-Z2) recommended for object storage targets (OST) uses an algorithm similar to RAID-6, but is implemented in software and not in a RAID card or a separate storage controller.
OpenZFS uses a copy-on-write transactional object model that makes extensive use of 256-bit checksums for all data blocks, using hash algorithms like Fletcher-4 and SHA-256. This makes the choice of CPU an important consideration when designing servers that use ZFS storage.
Metadata server workloads are IOps-centric, characterized by small transactions that run at very high rates and benefit from frequency-optimized CPUs.
Object storage server workloads are throughput-centric, often with long-running, streaming transactions. Because the workloads are oriented more toward streaming IO, object storage servers are less sensitive to CPU frequency than metadata servers,
http://wiki.lustre.org/ZFS_OSD_Hardware_Considerations