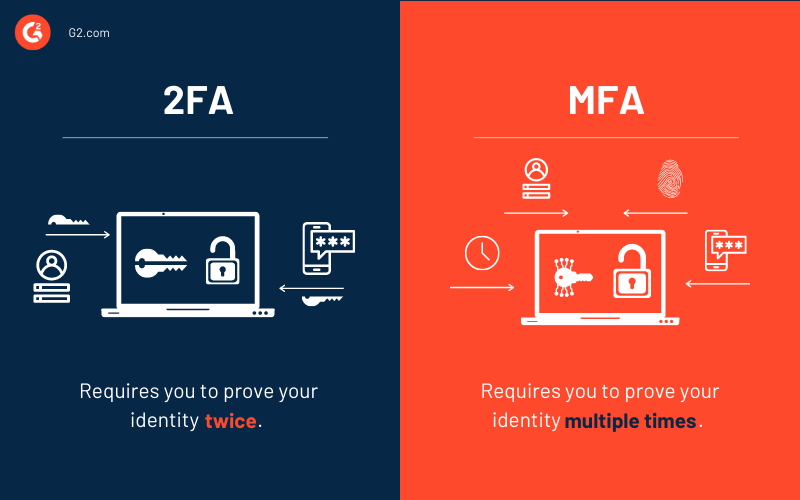
- Two-Factor Authentication vs. Multi-Factor Authentication: What Are the Risks
Business networks are crucial to protect, so firms want only authorized people accessing them.
In cybersecurity, authentication means verifying that a person or device is who they claim to be.
It usually involves checking the identity claim against what's called a factor.
This could be a password, a biometric identifier (a fingerprint, an iris scan), or the ability to control a trusted piece of equipment such as an electronic ID card or a cell phone.
Single-Factor Authentication
A user has a password and types it in.
An analogy in the physical world might be a person using a key or code to unlock a safe.
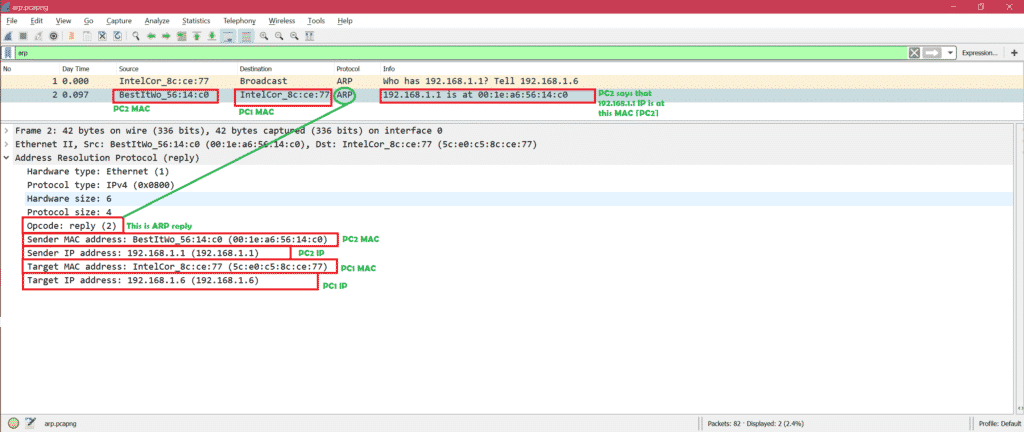
Two-Factor Authentication
It's the simplest type of multi-factor authentication.
With 2FA, users have to supply two distinct proofs of identity to gain access to the network.
Usually, this includes a password and control over a trusted cell phone.
For instance, with Twitter, users employing 2FA first enter their passwords and next, receive an SMS authentication message from Twitter with a six-digit code to input.
Multi-Factor Authentication
The term multi-factor authentication (MFA) means there are more than two factors involved.
For every factor of authentication you add, you boost security, but at the cost of making your user experience worse.
MFA systems can also be cumbersome for IT teams, who have to manage integrations with multiple applications or systems.
Adaptive Multi-Factor Authentication
Adaptive authentication means the system is flexible depending on how much risk a user presents.
For example, if an employee is working on the company premises and uses a badge to get through security to her office, Okta will recognize that she is in a trusted location, and that she has permissions to proceed.
If that same employee is working from a coffee shop, the system may prompt her for an additional security factor when she goes to log in remotely, since she’s not in a trusted location.
Or, it could present an additional MFA challenge if the user was working from a personal laptop instead of a company device.
https://www.okta.com/blog/2016/12/two-factor-authentication-vs-multi-factor-authentication-what-are-the-risks/
- What Are the Different Authentication Factors?
Whether a user is accessing his email or the corporate payroll files, he needs to verify his identity before that access is granted. There are three possible ways this user can prove he is who he claims to be:
Knowledge—the user provides information only he knows, like a password or answers to challenge questions
Possession—the user supplies an item he has, like a YubiKey or a one-time password
Inherence—the user relies on a characteristic unique to who he is, such as a fingerprint, retina scan, or voice recognition
Two-Factor Authentication vs. Multi-Factor Authentication (2FA vs. MFA)
The difference between MFA and 2FA is simple. Two-factor authentication (2FA) always utilizes two of these factors to verify the user’s identity. Multi-factor authentication (MFA) could involve two of the factors or it could involve all three. “Multi-factor” just means any number of factors greater than one.
https://www.helpsystems.com/resources/articles/whats-difference-between-two-factor-authentication-and-multi-factor
- MFA vs 2FA - What's the difference?
Knowledge (e.g. Password, PIN; meaning something you know),
Possession (e.g. Smart card, smartphone, wearable, cryptographic key etc.; Meaning something you have),
Inherence (e.g. Fingerprint, iris scan, voice print etc.; Meaning something you are),
Context (e.g. Location, what you do, how the user reacts, pattern etc.; Meaning something the user does in the context of his or her user life)
https://www.getidee.com/blog/mfa-vs-2fa
- Multi Factor authenticators (MFA)
This refers to using a single authenticator that requires a second factor to activate (MF authenticator) to achieve MFA or 2FA. For example, using a smartphone as an authenticator to access a website.The smartphone MUST be activated first using a PIN (knowledge) or a fingerprint(inherence) by the user. Then the key on the smartphone can be used to access the website.
Pros:
The user is in full control of both factors especially when an MF hardware cryptographic device is used as recommended by NIST for AAL 3.
No risk of keylogger or screen capture to harvest the user password on device, web or on mobile applications.
An attacker still needs the second factor to be able to use a stolen MF software / hardware authenticator.
MF hardware authenticator device is mostly offline – more difficult for an attacker to get.
The Verifier is only concerned with securing one factor. The second factor is controlled by the user.
Cons:
The second factor is on the same device. Where the second factor is verified locally e.g.OTP software generator on a smartphone, both the second factor and the secret key used to generate the OTP could be compromised at once.
On the fly-phishing where an attacker captures for example the password and OTP provided by the legitimate user and uses it immediately for illegitimate access to the user resources. With MF authenticators only the OTP is captured (assuming the service provider is satisfied with multi factor using a single authenticator).
Single factor authenticators (1FA)
Pros:
If one of the factors, say knowledge, is compromised it might not affect the other factor (e.g.OTP or crypto key) on the SF device. Although compromising the other factor might be trivial.
Cons:
The user is not in control of where both factors (e.g.Password and OTP) are entered.
The user password could be sniffed or captured with a keylogger, screen capture from the authentication device/application.
An attacker could use phishing to deceive users into entering their password on fake sites/login forms. Especially users that use the same password on many services – this gives an attacker automatic access to the other accounts that use the same password.
An attacker could reset the user account with just their password and email to associate a new second factor to the user account.
The SF authenticator device/software is not protected – for example, SF OTP software on a smartphone, all the attacker need is to steal the smartphone or token and then could try to get the second via phishing, brute force, keylogger, screen capture, and maybe social engineering.
On the fly-phishing: both single factors could be captured which could compromise the other user accounts.
The verifier must manage at least two different authenticators for each user.
https://www.getidee.com/blog/mfa-vs-2fa
- Multi-factor authentication (MFA; encompassing authentication, or 2FA, along with similar terms) is an electronic authentication method in which a user is granted access to a website or application only after successfully presenting two or more pieces of evidence (or factors) to an authentication mechanism: knowledge (something only the user knows), possession (something only the user has), and inherence (something only the user is)
https://en.wikipedia.org/wiki/Multi-factor_authentication