- Software-defined data center (SDDC; also: virtual data center, VDC) is a marketing term that extends virtualization concepts such as
abstraction , pooling, and automation to all data center resources and services to achieve IT as a service (ITaaS ). In a software-defined data center," all elements of the infrastructure — networking, storage, CPU and security– are virtualized
- What is Software-defined Storage?
HARDWARE-CENTRIC STORAGE SYSTEMS
Hardware-centric storage systems, such as dedicated appliances and NAS, have hit a wall.
They can’t cope with the massive data volumes, need for elastic scalability, and dynamic workloads of Digital Business, Big Data, and the cloud.
software-defined storage (SDS)
In this
https://www.scality.com/software-defined-storage/
- SOFTWARE-DEFINED INFRASTRUCTURE
Solutions that automate IT operations and streamline management of resources, workloads, and apps by deploying and controlling data center infrastructure as
https://www.hpe.com/us/en/solutions/software-defined.html
Hyperco nvergence means more than just merging storage andcompute into a single solution.
When the entire IT
https://www.hpe.com/us/en/integrated-systems/hyper-converged.html
- Hyper-converged infrastructure (HCI) is a software-defined IT infrastructure that virtualizes
all of the elements of conventional "hardware-defined" systems. HCI includes, at a minimum, virtualized computing (ahypervisor ), avirtualised SAN (software-defined storage) and virtualized networking (software-defined networking). HCI typically runs on commercial off-the-shelf (COTS) servers.
- Hyper converged infrastructure (HCI) allows the convergence of physical storage onto industry-standard x86 servers, enabling a building block approach with scale-out capabilities. All key data center functions run as software on the
hypervisor in a tightly integrated software layer– delivering services thatwere previously provided via hardware through software.
VMware has made recently as competition in its core markets heatsup . For example, there is its partnership with parent company EMC and Cisco on VCE on converged infrastructure.
https://www.quali.com/blog/vmware-nutanix-and-whats-at-stake-in-the-sddc-market/
- Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory (memory local to another processor or memory shared between processors).
The benefits of NUMA are limited to particular workloads, notably on servers where the datais often associated strongly with certain tasks or users
- shared memory architectures
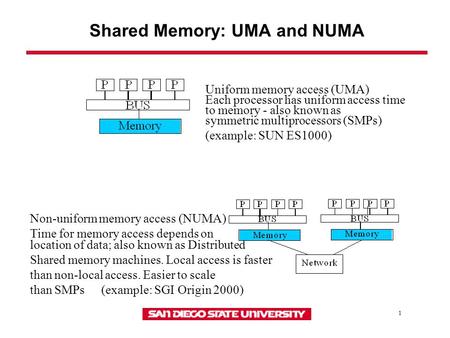

- Non-uniform memory access (NUMA) systems are server platforms with
more than one system bus. These platforms canutilize multiple processors on a single motherboard, and all processors can access all the memory on the board. When a processor accesses memory that does not lie within its own node (remote memory), data mustbe transferred over the NUMA connection at a rate that is slower than it would be when accessing local memory. Thus, memory access times are not uniform and depend on the location (proximity) of the memory and the node from whichit is accessed
https://community.mellanox.com/docs/DOC-2491
- The NUMA topology and CPU pinning features in OpenStack provide high-level control over how instances run on
hypervisor CPUs and the topology of virtualCPUs available to instances. These features help minimize latency and maximize performance.
SMP, NUMA, and SMT
Symmetric multiprocessing (SMP)SMP is a design found in many modern multi-core systems. In an SMP system, there are
Non-uniform memory access (NUMA)
NUMA is a derivative of the SMP design that
Simultaneous Multi-Threading (SMT)
SMT is a design complementary to SMP. Whereas
https://docs.openstack.org/nova/pike/admin/cpu-topologies.html
- ONAP community. As an open source project, participation in ONAP is open to all, whether you are an employee of an LF Networking (LFN) member company or just passionate about network transformation. The best way to
evaluate , learn, contribute, and influence the direction of the project is to participate. There are many ways for you to contribute to advancing thestate of the art of network orchestration andautomatio
https://www.onap.org/home/community
- What is IO Visor?
create, publish, and deploy applications in live systems without having to
https://www.iovisor.org/wp-content/uploads/sites/8/2016/09/io_visor_faq.pdf
Cgroups allow you to allocate resources — such as CPU time, system memory, network bandwidth, or combinations of these resources — among user-defined groups of tasks (processes) running on a system. You can monitor thecgroups you configure, denycgroups access to certain resources, and even reconfigure yourcgroups dynamically on a running system. Thecgconfig (control group config) service canbe configured to start up at boot time and reestablish yourpredefined cgroups , thus making them persistent across reboots.
- Prototyping kernel development
https://github.com/netoptimizer/prototype-kernel
- The basic idea is to compile modules outside the kernel tree, but use the kernels
kbuild infrastructure. Thus, thisdoes require that you have a kernel source tree avail on your system. Most distributions offer a kernel-devel package, that only install what you need for this to work
- I/O Virtualization Goals
I/O Virtualization (IOV) involves sharing a single I/O resource between multiple virtual machines. Approaches for IOV include models where
Software-Based Sharing
https://www.intel.com/content/dam/doc/application-note/pci-sig-sr-iov-primer-sr-iov-technology-paper.pdf
- Layer 3: Software-Defined Data Center (SDDC)
Resource pooling, usage tracking, and governance on top of the Hypervisor layer give rise to the Software-Defined Data Center (SDDC). The notion of “infrastructure as code” becomes possible at this layer through the use of REST APIs. Users at this layer are typically agnostic to Infrastructure and Hypervisor specifics below them and have grow accustomed to thinking of
An OSI Model for Cloud
Layer 1: Infrastructure
Layer 2:
Layer 3: Software-Defined Data Center (SDDC)
Layer 4: Image
Layer 5: Services
Layer 6: Applications
https://blogs.cisco.com/cloud/an-osi-model-for-cloud
- Converged vs. Hyper-Converged Infrastructure Solutions
Today's virtual environments can
Generally
The hardware-focused, building-block approach of VCE (a joint venture of EMC, Cisco, and
The software defined approach of Nutanix,
The most important difference between the two technologies is that in a converged infrastructure, each of the components in the building block is a discrete component that can
In a non-converged architecture, physical servers run a virtualization
In a converged architecture,
The hyper-converged infrastructure has the storage
Using Nutanix as an example, the storage logic controller, which normally is part of SAN hardware, becomes a software service attached to each VM at the
Hyper-Converged Infrastructure Costs
Like traditional infrastructures, the cost of a hyper-converged infrastructure can vary dramatically depending on the underlying
Niel Miles, software defined data center solutions manager at Hewlett-Packard, described "software defined" as programmatic controls of the corporate infrastructure as a company moves forward, while speaking at the HP Discover 2014 conference in Las Vegas earlier this year. He said this approach adds "business agility," noting that it increases the company's ability to address automation, orchestration, and control more quickly and effectively. Existing technology cannot keep up with these changes, requiring the additional software layer to respond more quickly than was possible in the past.
For those looking to reuse their existing hardware to take advantage of a hyper-converged infrastructure, several companies offer approaches more
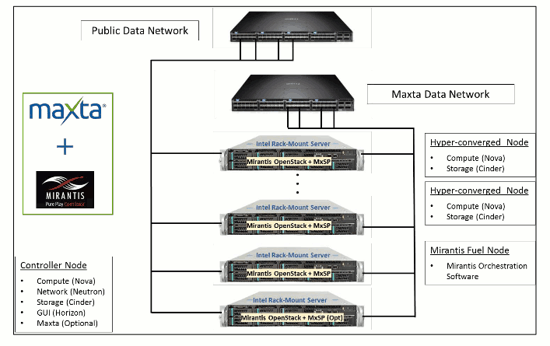
Maxta's VM-centric offering simplified IT management and reduces storage administration by enabling customers to manage VMs and not storage.
Converged Infrastructure: Main Differentiators
There are two approaches to building a converged infrastructure.
The first is using the building-block approach, such as that used in the VCE
While one of the main arguments in favor of a converged infrastructure is that it comes pre-configured and
The same holds true for the components themselves. Because each component
It is possible to build a converged infrastructure without using the building block approach.
The second approach is using a reference architecture, such as the one dubbed VSPEX by EMC, which allows the company to use existing hardware, such as a conforming router, storage array or server, to build the equivalent of a pre-configured
https://www.
- Tips on choosing the best architecture for your business
Each unit must
Each component
Sometimes, each unit comes from a different vendor, therefore support and warranty
Use case: Traditional infrastructures are still a good fit for companies with a stable environment that handle very large deployments. Tens of
Application servers, storage, and networking switches
the entire product stack
as
every appliance in the converged stack needs to
Use case: Converged infrastructures are ideal for companies that need a lot of control over each element in their IT infrastructure, as each element can be “fine-tuned” individually. They may also be a good fit for large enterprises who are replacing their entire infrastructure, as they
storage, networking and
the software layer gives you flexibility in using hardware resources and makes the deployment and management of VMs easy
Use case: Small and medium enterprises which require a cost-effective, flexible and agile infrastructure
If you have a
If you need the performance and control of a traditional infrastructure but are deploying from scratch, choose a converged infrastructure to avoid the costs and troubles of hunting for many pieces of infrastructure from different vendors.
If your business needs fast deployment, quick access to resources and a low foot print while keeping your overall IT budget low, then a hyper-converged infrastructure is the best for you.
https://syneto.eu/2016/10/03/hyper-converged-vs-traditional-infrastructures/
- What is
Hyperconverged Infrastructure?
Combine
Three-tier architecture is expensive to build complex to operate, and difficult to scale. Don't wait for IT infrastructure to support your application demands. Adopt HCI without losing control, increasing costs, or compromising security.
https://www.vmware.com/tr/products/hyper-converged-infrastructure.html
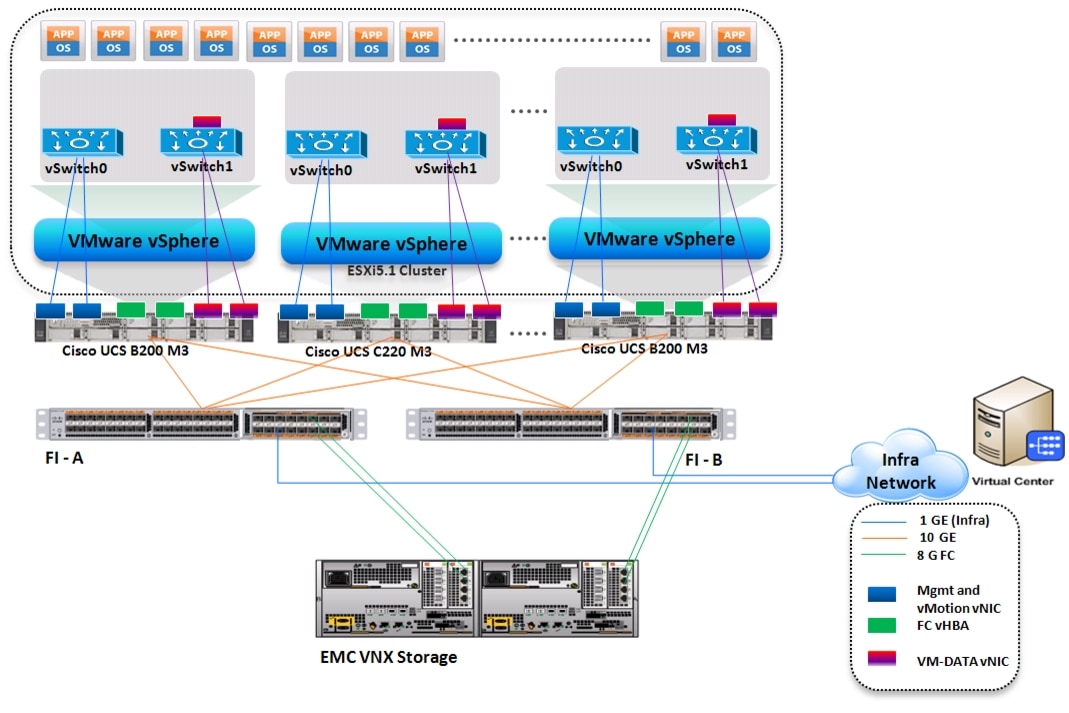
Cisco Virtualization Solution for EMC VSPEX with VMware vSphere 5.1 for 100-125 Virtual Machines











.jpg)