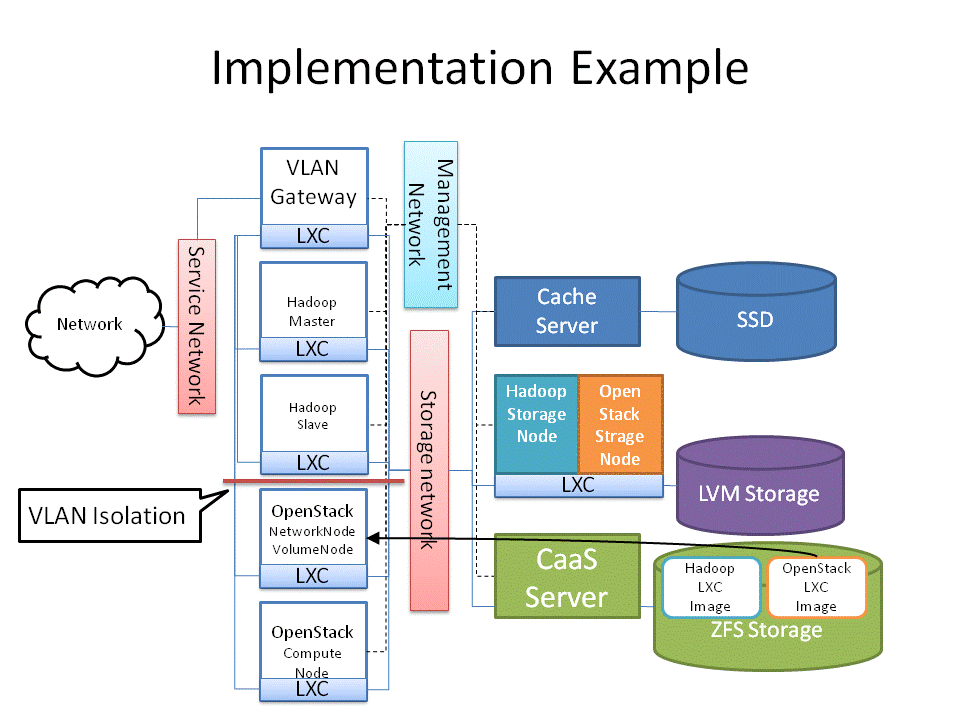
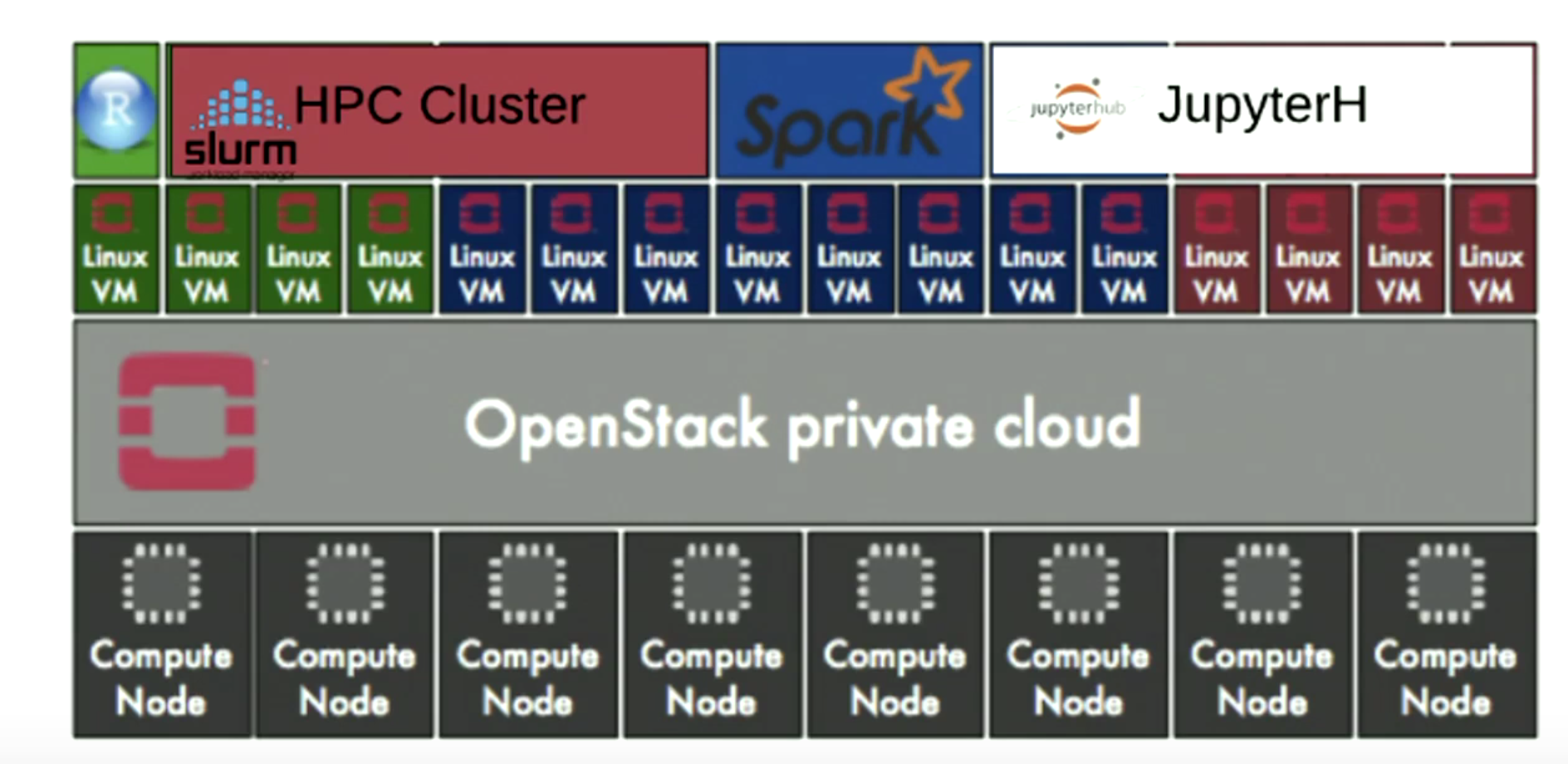
- Understanding Cloud Native Storage
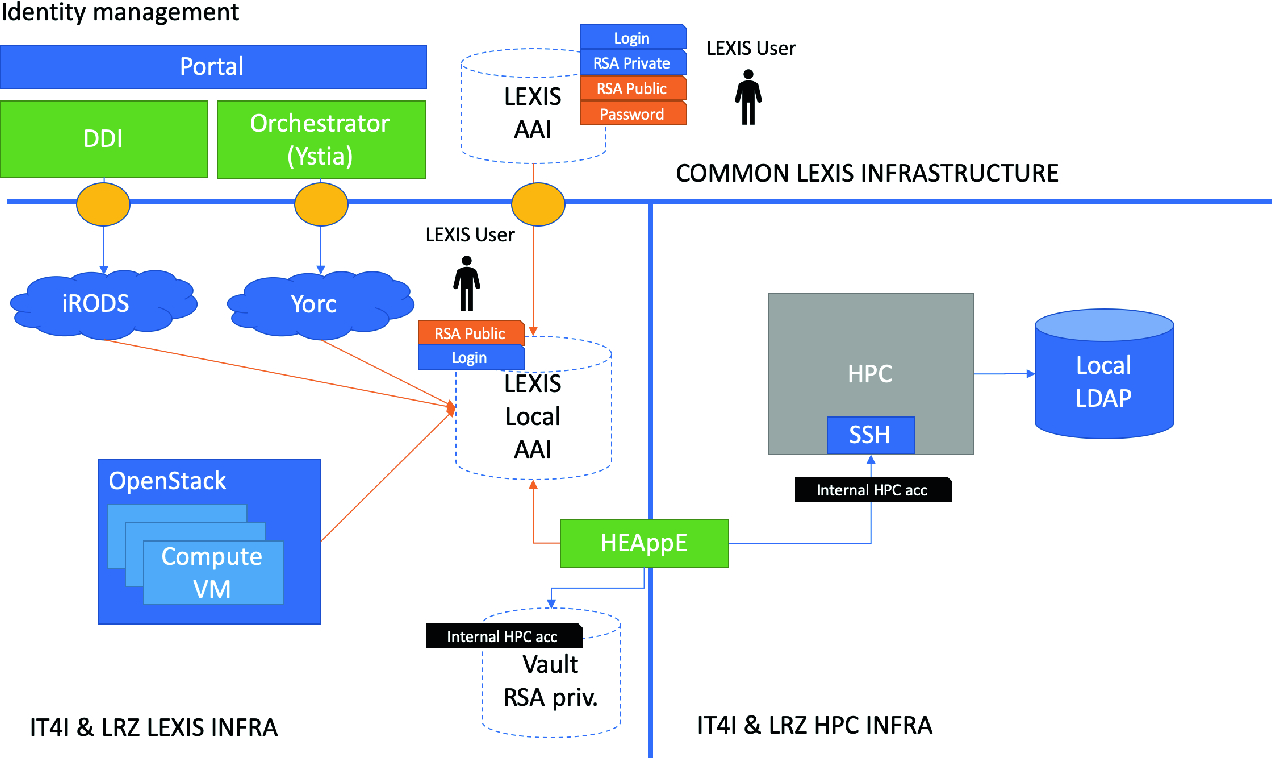
Cloud Native Storage is a solution that provides comprehensive data management for stateful applications. When you use Cloud Native Storage, you can create the containerized stateful applications capable of surviving restarts and outages. Stateful containers leverage storage exposed by vSphere while using such primitives as standard volume, persistent volume, and dynamic provisioning.
With Cloud Native Storage, you can create persistent container volumes independent of virtual machine and container life cycle.
https://docs.vmware.com/en/VMware-vSphere/6.7/Cloud-Native-Storage/GUID-CF1D7196-E49C-4430-8C50-F8E35CAAE060.html
- Cloud Native Storage Concepts and Terminology
Kubernetes Cluster
A cluster of VMs where Kubernetes control plane and worker services are running. On top of the Kubernetes cluster, you deploy your containerized applications. Applications can be stateful and stateless.
Pod
A pod is a group of one or more containers that share such resources as storage and network. Containers inside a pod are started, stopped, and replicated as a group.
Container Orchestrator
Open-source platforms, such as Kubernetes, for deployment, scaling, and management of containerized applications across clusters of hosts
Stateful Application
As containerized applications evolve from stateless to stateful, they require persistent storage. Unlike stateless applications that do not save data between sessions, stateful applications save data to persistent storage. The retained data is called the application's state. You can later retrieve the data and use it in the next session. Most applications are stateful. A database is as an example of a stateful application
PersistentVolume
Stateful applications use PersistentVolumes to store their data. A PersistentVolume is a Kubernetes volume capable of retaining its state and data. It is independent of a pod and can continue to exist even when the pod is deleted or reconfigured. In the vSphere environment, the PersistentVolume objects use virtual disks (VMDKs) as their backing storage.
StorageClass
Kubernetes uses a StorageClass to define different tiers of storage and to describe different types of requirements for storage backing the PersistentVolume. In the vSphere environment, a storage class can be linked to a storage policy.
PersistentVolumeClaim
Typically, applications or pods can request persistent storage through a PersistentVolumeClaim
StatefulSet
A StatefulSet manages the deployment and scaling of your stateful applications. The StatefulSet is valuable for applications that require stable identifiers or stable persistent storage.
https://docs.vmware.com/en/VMware-vSphere/6.7/Cloud-Native-Storage/GUID-6B4A87B4-F435-4410-85AD-B0B976133D62.html

- Cloud Native Storage (CNS) provides comprehensive data management for stateful, containerized apps, enabling apps to survive restarts and outages. Stateful containers can use vSphere storage primitives such as standard volume, persistent volume, and dynamic provisioning, independent of VM and container lifecycle.
https://docs.pivotal.io/tkgi/1-9/vsphere-cns.html
- Cloud Volumes Service is now software-defined
The new software-defined Cloud Volumes Service is the first enterprise storage system delivered in GKE to offer ONTAP’s application data management capabilities plus Kubernetes’ cloud-native agility and flexibility. This service was made possible through a deep collaborative engineering effort by both NetApp and Google Cloud, which is grounded in the companies’ joint commitment to modernizing enterprise infrastructure. Both emerging cloud-native and traditional enterprise applications can now enjoy cloud-native storage with enterprise-grade features such as rapid scaling, and higher availability
https://morioh.com/p/b680f947e85c

- Storage is one of the most critical components of a Containers-as-a-Service platform. Container-native storage exposes the underlying storage services to containers and microservices. Like software-defined storage, it aggregates and pools storage resources from disparate mediums.
Container-native storage enables stateful workloads to run within containers by providing persistent volumes. Combined with Kubernetes primitives such as StatefulSets, it delivers the reliability and stability to run mission-critical workloads in production environments.
Even though Kubernetes can use traditional, distributed file systems such as network file system (NFS) and GlusterFS, we recommend using a container-aware storage fabric that is designed to address the requirements of stateful workloads running in production.
Container-Native Storage Solutions
The cloud native ecosystem has defined specifications for storage through the Container Storage Interface (CSI) which encourages a standard, portable approach to implementing and consuming storage services by containerized workloads.
Ceph, Longhorn, OpenEBS and Rook are some container-native storage open source projects
https://thenewstack.io/the-most-popular-cloud-native-storage-solutions/
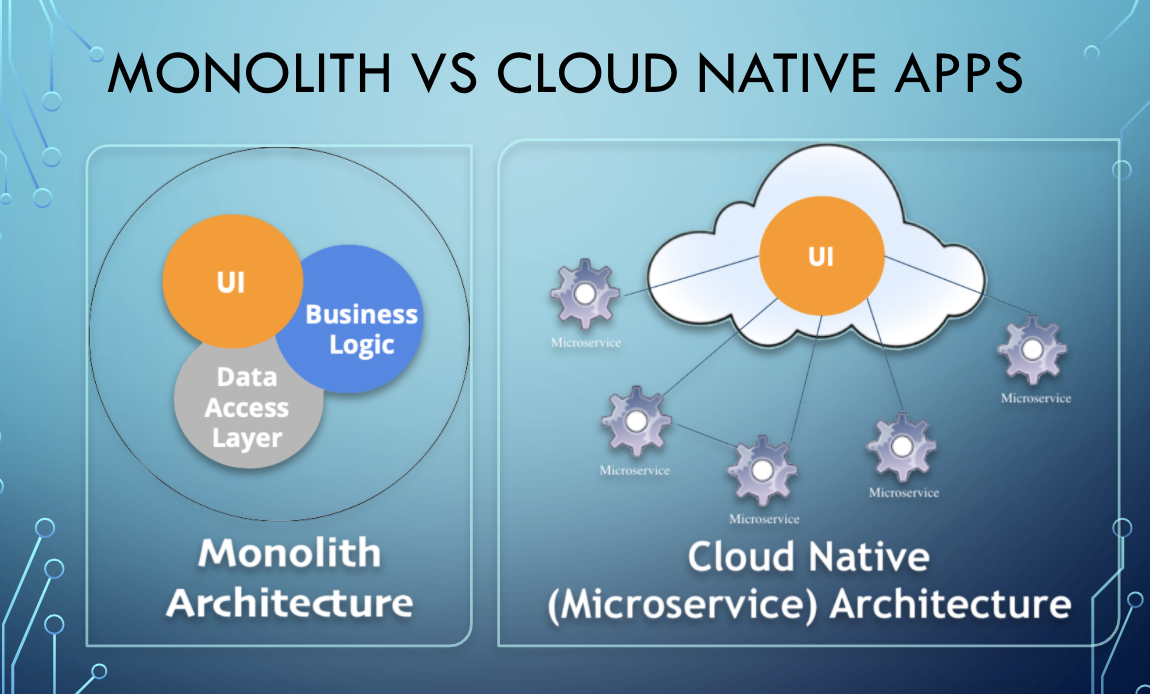
- What is cloud native?
Cloud native refers less to where an application resides and more to how it is built and deployed.
A cloud native application consists of discrete, reusable components known as microservices that are designed to integrate into any cloud environment
These microservices act as building blocks and are often packaged in containers.
Microservices work together as a whole to comprise an application, yet each can be independently scaled, continuously improved, and quickly iterated through automation and orchestration processes.
Advantages and disadvantages
Advantages
Compared to traditional monolithic apps, cloud native applications can be easier to manage as iterative improvements occur using Agile and DevOps processes.
Comprised of individual microservices, cloud native applications can be improved incrementally and automatically to continuously add new and improved application features
Improvements can be made non-intrusively, causing no downtime or disruption of the end-user experience.
Disadvantages
Although microservices enable an iterative approach to application improvement, they also create the necessity of managing more elements. Rather than one large application, it becomes necessary to manage far more small, discrete services.
Cloud native apps demand additional toolsets to manage the DevOps pipeline, replace traditional monitoring structures, and control microservices architecture.
Architecture
Cloud native applications rely on microservices architecture. This distinctive architectural approach to software development focuses on the creation of discrete, single-function services. These single-function services—or microservices—can be deployed, upgraded, improved, and automated independent of any other microservice
Cloud native microservices
A microservice is a small application with a small footprint that performs a specific function. Microservices enable an architectural approach where a much larger application is composed of discrete, independently deployed components. The microservices approach to software development can be used in multiple ways but has become closely associated with cloud native application development.
Development principles
Whether creating a new cloud native application or modernizing an existing application, developers adhere to a consistent set of principles:
Follow the microservices architectural approach
Rely on containers for maximum flexibility and scalability:
Adopt Agile methods
Storage
Cloud native applications frequently rely on containers. The appeal of containers is that they are flexible, lightweight, and portable. Early use of containers tended to focus on stateless applications that had no need to save user data from one user session to the next
as more core business functions move to the cloud, the issue of persistent storage must be addressed in a cloud native environment.
Cloud native vs. Cloud enabled
A cloud enabled application is an application that was developed for deployment in a traditional data center but was later changed so that it also could run in a cloud environment. Cloud native applications, however, are built to operate only in the cloud.
Cloud native vs. Cloud ready
In the short history of cloud computing, the meaning of "cloud ready" has shifted several times. Initially, the term applied to services or software designed to work over the internet. Today, the term is used more often to describe an application that works in a cloud environment or a traditional app that has been reconfigured for a cloud environment
Cloud native vs. Cloud based
A cloud based service or application is delivered over the internet. It’s a general term applied liberally to any number of cloud offerings. Cloud native is a more specific term. Cloud native describes applications designed to work in cloud environments. The term denotes applications that rely on microservices, continuous integration and continuous delivery (CI/CD) and can be used via any cloud platform.
Cloud native vs. Cloud first
Cloud first describes a business strategy in which organizations commit to using cloud resources first when launching new IT services, refreshing existing services, or replacing legacy technology.
https://www.ibm.com/cloud/learn/cloud-native
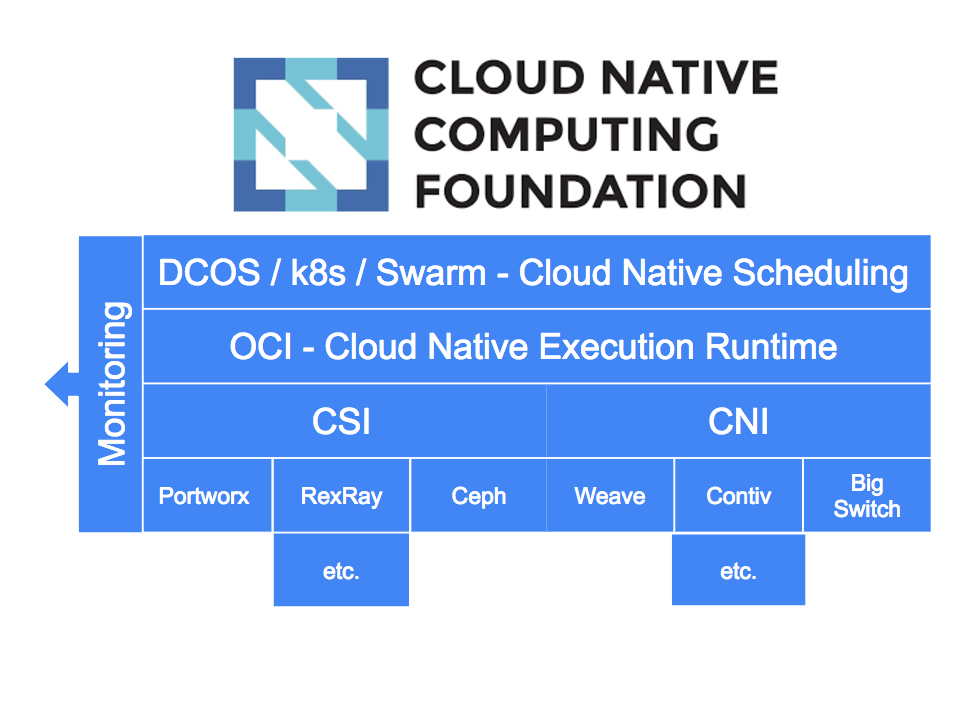
- Oracle® Linux Cloud Native Environment Concepts
Oracle Linux Cloud Native Environment is a curated set of open source projects that are based on open standards, specifications and APIs defined by the Open Container Initiative (OCI) and Cloud Native Computing Foundation (CNCF) that can be easily deployed, have been tested for interoperability and for which enterprise-grade support is offered.
Oracle Linux Cloud Native Environment uses Kubernetes to deploy and manage containers. When you create an environment, in addition to Kubernetes nodes, the Oracle Linux Cloud Native Environment Platform API Server must be installed on a server, and is needed to perform a deployment and manage modules. The term module refers to a packaged software component that can be deployed to provide both core and optional cluster-wide functionality. The Kubernetes module for Oracle Linux Cloud Native Environment is the core module, and automatically installs and configures Kubernetes, CRI-O, runC and Kata Containers on the Kubernetes nodes and brings up a Kubernetes cluster.
The Oracle Linux Cloud Native Environment Platform Command-Line Interface performs the validation and deployment of modules to the nodes, enabling easy deployment of modules such as the Kubernetes module. The required software for modules is configured by the Platform CLI, such as Kubernetes, CRI-O, runC, Kata Containers, CoreDNS and Flannel.
An optional module is the Istio module for Oracle Linux Cloud Native Environment which is used to deploy a service mesh on top of the Kubernetes cluster. The Istio module requires Helm, Prometheus and Grafana, and these are also deployed along with Istio.
https://docs.oracle.com/en/operating-systems/olcne/concepts/intro.html





- What are cloud-native applications?
Cloud-native applications are a collection of small, independent, and loosely coupled services.
If an app is "cloud-native," it’s specifically designed to provide a consistent development and automated management experience across private, public, and hybrid clouds.
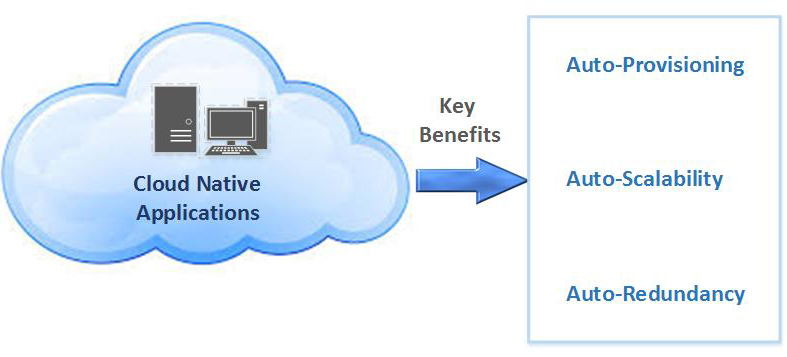
Organizations adopt cloud computing to increase the scalability and availability of apps.
These benefits are achieved through self-service and on-demand provisioning of resources, as well as automating the application life cycle from development to production.
Cloud-native development is just that—an approach to building and updating apps quickly, while improving quality and reducing risk. More specifically, it’s a way to build and run responsive, scalable, and fault-tolerant apps anywhere—be it in public, private, or hybrid cloud
https://www.redhat.com/en/topics/cloud-native-apps
- What Is a Cloud-native App?
Cloud-native apps are loosely coupled to the underlying infrastructure needed to support them. These days that means deploying microservices via containers that can be dynamically provisioned resources based on user demand. Each microservice can communicate independently via APIs managed through a service layer. While microservices aren’t required for an app to be considered cloud-native, the perks of modularity, portability, and granular control over resources make them a natural fit for running applications in the cloud.
The Benefits of Cloud-native Development
Common benefits of going cloud-native include:
On-demand provisioning of compute and storage resources
Reusable modular software components, services, and APIs
DevOps-friendly—microservices architectures are also great for setting up continuous integration and delivery (CI/CD) pipelines
Cross-platform portability across public and private clouds or across on-premises and hybrid clouds
Highly agile, scalable, and extensible software architecture that can grow with your business
https://www.purestorage.com/knowledge/what-is-cloud-native.html
- 10 Key Attributes of Cloud-Native Applications
Packaged as lightweight containers:
Developed with best-of-breed languages and frameworks:
Designed as loosely coupled microservices:
Centered around APIs for interaction and collaboration:
Architected with a clean separation of stateless and stateful services:
Isolated from server and operating system dependencies:
Deployed on self-service, elastic, cloud infrastructure:
Managed through agile DevOps processes:
Automated capabilities:
Defined, policy-driven resource allocation:
https://thenewstack.io/10-key-attributes-of-cloud-native-applications/