- There is no JBOD in ZFS (most of the time)
ZFS uses three-tier logic to manage physical disks. Disks are combined into virtual devices (vdevs). Vdevs are then combined into a pool (or multiple pools, but I’m talking about single pool now). Vdevs can be of different types – simple (single disk), mirrors (two or more identical disks), or RAIDZ/Z2/Z3 (similar to RAID5, tolerating one, two, or three failed disks respectively). You can add vdevs to the existing pool, and the pool expands accordingly (it will be significant later).
It may seem that if we make several vdevs consisting of a single disk each, and then combine them to a pool, the result will resemble a traditional JBOD. That does not happen. Traditional JBOD will allocate space for data from start to end of the array. When one of the disks fills up, the next disk is used, and so on (this is not exactly correct, but a good approximation nonetheless). ZFS pool allocates data blocks on different vdevs in turn. If a large file is written, its blocks are put onto different vdevs. However, if you add a new disk (and thus a new vdev) to the pool which is filled to near capacity, no automatic rebalancing takes place. Whatever files you add to the pool will be mostly written to a newly added disk.
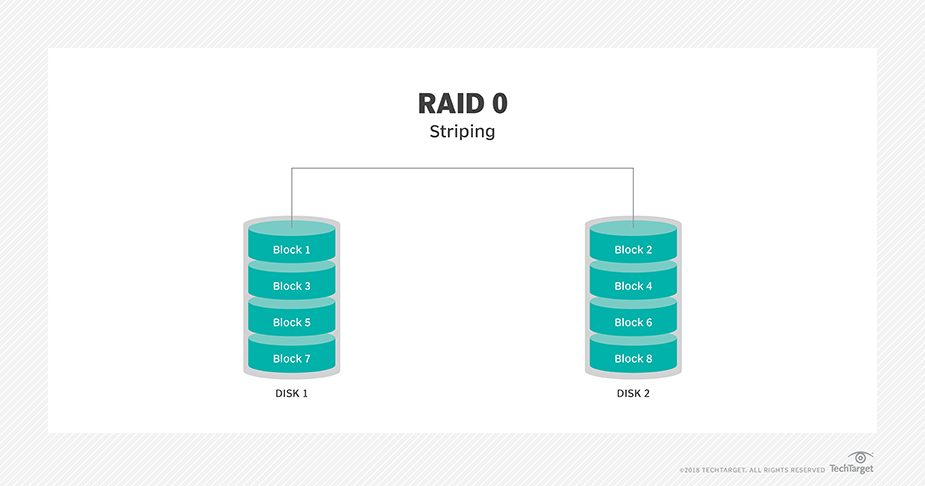
In general case, no. ZFS pool without redundancy is not like a JBOD. It behaves more like a RAID0.
https://www.klennet.com/notes/2018-12-20-no-jbod-in-zfs-mostly.aspx

- "The COW filesystem for Linux that won't eat your data
" .
Copy on write (COW) - like
Full data and metadata
Multiple devices, including replication and other types of RAID
Caching
Compression
Encryption
Snapshots
Scalable
Already working and stable, with a small community of users
https://bcachefs.org/
- For most users the
kABI -trackingkmod packages are recommendedin order to avoid needing to rebuild ZFS for every kernel update.DKMS packages are recommended for users running a non-distribution kernel or for users who wish to apply local customizations to ZFS on Linux.
- ZFS
is originally designed to work with Solaris and BSD system. Because ofthe legal and licensing issues, ZFS cannot be shipped with Linux.
In a ZFS/Linux environment, it is a bad idea to update the system automatically.
For some odd reasons, ZFS/Linux will work with server grade or gaming grade computers. Do not run ZFS/Linux on entry level computers.
https://icesquare.com/wordpress/how-to-install-zfs-on-rhel-centos-7/
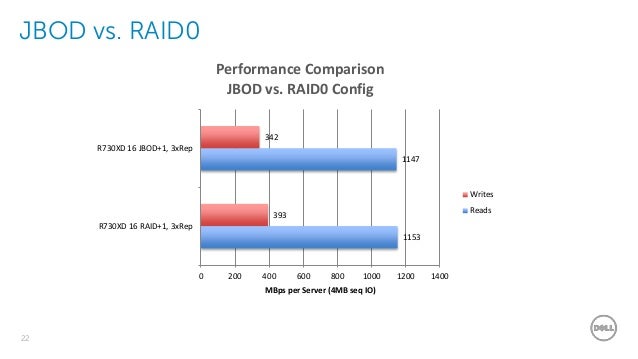
- In this post we discuss the Linux disk I/O performance using either ZFS Raidz or the
linux mdadm software RAID-0. It is important to understand that RAID-0 is not reliable for data storage, a single disk loss can easily destroy the whole RAID.On the other hand ZFS Raidz behaves similarly to RAID-5, while creating ZFS pool without specifying the Raidz1 iseffcetively RAID-o .
- What is a ZFS Virtual Devices (ZFS VDEVs)?
A VDEV is nothing but a collection of a physical disk, file image, or ZFS software raid device, hot spare for ZFS raid. Examples are:
/dev/
/images/200G
/dev/sdc1
https://www.cyberciti.biz/faq/how-to-install-zfs-on-ubuntu-linux-16-04-lts/
OpenZFS is the open source implementation of ZFS which is an advanced and highly scalable storage platform. Although ZFSwas originally designed for Sun Solaris, you can use ZFS on most of major Linux distributions with the help of the ZFS on Linux project, a part of theOpenZFS project.
- A Guide to Install and Use ZFS on CentOS 7
https://linoxide.com/tools/guide-install-use-zfs-centos-7/
- The Z file system is a free and open source logical volume manager built by Sun Microsystems for
use in their Solaris operating system
ZFS is capable of
we
https://www.howtogeek.com/175159/an-introduction-to-the-z-file-system-zfs-for-linux/
- ZFS on Linux - the official
OpenZFS implementation for Linux
https://github.com/zfsonlinux/zfs/wiki/RHEL-and-CentOS
- The -
f option is to ignore disk partition labels since these are new disks
http://www.thegeekstuff.com/2015/07/zfs-on-linux-zpool/
- 2. RAID-Z pools
Minimum disk requirements for each type
Minimum disks required for each type of RAID-Z
1. raidz1
2. raidz2
3. raidz3
https://www.thegeekdiary.com/zfs-tutorials-creating-zfs-pools-and-file-systems/
- Multiple Disk (RAID 0)
RAID 10
Creating a RAID1 pool of two
RAIDz3
Exactly the same as RAIDz3 except a third drive holds parity and the minimum number of drives is 4. Your array can lose 3 drives without loss of data.
http://blog.programster.org/zfs-create-disk-pools
- What is a ZVOL?
Creating a ZVOL
To create a ZVOL, we use the "-V" switch with our "
/dev/
Virtual Device
meta-
seven types of VDEVs in ZFS:
disk (default)- The physical hard drives in your system.
file- The absolute path of pre-allocated files/images.
mirror- Standard software RAID-1 mirror.
raidz1/2/3- Non-standard distributed parity-based software RAID levels.
spare- Hard drives marked as a "hot spare" for ZFS software RAID.
cache- Device used for a level 2 adaptive read cache (L2ARC).
log- A separate log (SLOG) called the "ZFS Intent Log" or ZIL
RAID-0 is faster than RAID-1, which is faster than RAIDZ-1, which is faster than RAIDZ-2, which is faster than RAIDZ-3.
Nested VDEVs
#
Real life example
In production, the files would be physical
notice that the name of the SSDs is "
https://pthree.org/2012/12/04/zfs-administration-part-i-vdevs/
- RAIDZ-1
This still allows for one disk failure to maintain data.
Two disk failures would
The capacity of your storage will be the number of disks in your array times the storage of the smallest disk, minus one disk for parity storage
#
RAIDZ-2
RAIDZ-2 is
This still allows for two disk failures to maintain data.
Three disk failures would
The capacity of your storage will be the number of disks in your array times the storage of the smallest disk, minus two disks for parity storage
#
RAIDZ-3
https://pthree.org/2012/12/05/zfs-administration-part-ii-raidz/
RAIDZ-3 does not have a standardized RAID level to compare it to. However, it is the logical continuation of RAIDZ-1 and RAIDZ-2 in that there is a triple parity bit distributed across all the disks in the
This still allows for three disk failures to maintain data.
Four disk failures would
The capacity of your storage will be the number of disks in your array times the storage of the smallest disk, minus three disks for parity storage.
#
Hybrid RAIDZ
this setup is essentially a RAIDZ-1+0
Each RAIDZ-1 VDEV will receive 1/4 of the data sent to the pool, then each striped piece will
in terms of performance, mirrors will always outperform RAIDZ levels
in a nutshell, from fastest to slowest, your non-nested RAID levels
RAID-0 (fastest)
RAID-1
RAIDZ-1
RAIDZ-2
RAIDZ-3 (slowest)
https://pthree.org/2012/12/05/zfs-administration-part-ii-raidz/
- #
zpool create tanksde sdf sdg sdh
Consider doing something similar with LVM, RAID and ext4. You would need to do the following
https://pthree.org/2012/12/04/zfs-administration-part-i-vdevs/
- In these examples, we will assume our ZFS shared
storage is named "tank". Further, wewill assume thatthe pool is created with 4preallocated files of 1 GB in size each, in a RAIDZ-1 array. Let's createsome datasets.
- A ZVOL is a "ZFS volume" that has
been exported to the system as a block device.
A ZVOL is a ZFS block device that
This means that the single block device gets to take advantage of your underlying RAID array, such as mirrors or RAID-Z. It gets to take advantage of the copy-on-write benefits, such as snapshots. It gets to take advantage of online scrubbing, compression and data
Creating a ZVOL
To create a ZVOL, we use the "-V" switch with our "
Ext4 on a ZVOL
you could put another filesystem, and mount
ZVOL storage for VMs
you can use these block devices as the backend storage for VMs.
It's not uncommon to create logical volume block devices as the backend for VM storage.
After having the block device available for
depending on the setup.
https://pthree.org/2012/12/21/zfs-administration-part-xiv-zvols/
- “Preview” file system. SUSE continues to support
Btrfs in only RAID 10 equivalent configurations, and only time will tell ifbcachefs proves to be a compelling alternative toOpenZFS
- The ZFS file system provides data integrity features for storage drives using its Copy On Write (CoW) technology and improved RAID, but these features have
been limited to storage drives previously. If you have a drive failure,utilizing RAID or mirroring will protect your volumes, but what happens if your boot drive fails? In the past, if you usedFreeNAS , you had no option other than having your storage go offline and remain unusable untilit was repaired , and the ability to mirror was only available inTrueNAS , whichutilized the underlyingFreeBSD code.
https://www.ixsystems.com/blog/root-on-zfs/
- Red Hat deprecates BTRFS, is Stratis the new ZFS-like hope?
Red Hat introduced BTRFS as a technology preview in RHEL 6 and has been over the years one of the major contributors.
Stratis vs BTRFS/ZFS
Just like the other two competitors, the newly born Stratis aims to fill the gap on Linux, but there’s much difference. Aside from the brave decision to use the Rust programming language, Stratis aims to provide
https://www.marksei.com/red-hat-deprecates-btrfs-stratis/
- A daemon that manages a pool of block devices to create flexible filesystems.
- Open ZFS vs.
Btrfs | and other file systems
SUSE continues to support
It is an honor to work with the OpenZFS community and
https://www.ixsystems.com/blog/open-zfs-vs-btrfs/
Btrfs has been deprecated
The
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/7.4_release_notes/chap-red_hat_enterprise_linux-7.4_release_notes-deprecated_functionality
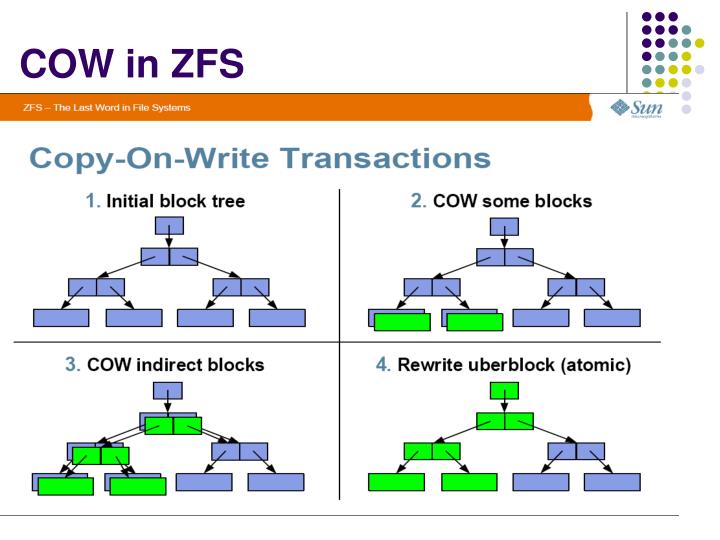
- Copy-on-write (CoW or COW), sometimes referred to as implicit sharing or shadowing, is a resource-management technique used in computer programming
to efficiently implement a "duplicate" or "copy" operation on modifiable resources. If a resourceis duplicated but notmodified , it isnot necessary to create a new resource;the resource can be shared between the copy and the original. Modifications must still create a copy, hence the technique:the copy operation is deferred to the first write. By sharing resources in this way, it is possibleto significantly reduce the resource consumption of unmodified copies, while adding a small overhead to resource-modifying operations.
https://en.wikipedia.org/wiki/Copy-on-write
- The principle
that you can efficiently share asmany read -only copies of an object as you want until you need tomodify it. Then you need to have your own copy.
http://wiki.c2.com/?
- Copy-on-write
All blocks within the ZFS filesystem contain a checksum of the target block,
https://www.ixsystems.com/freenas-mini