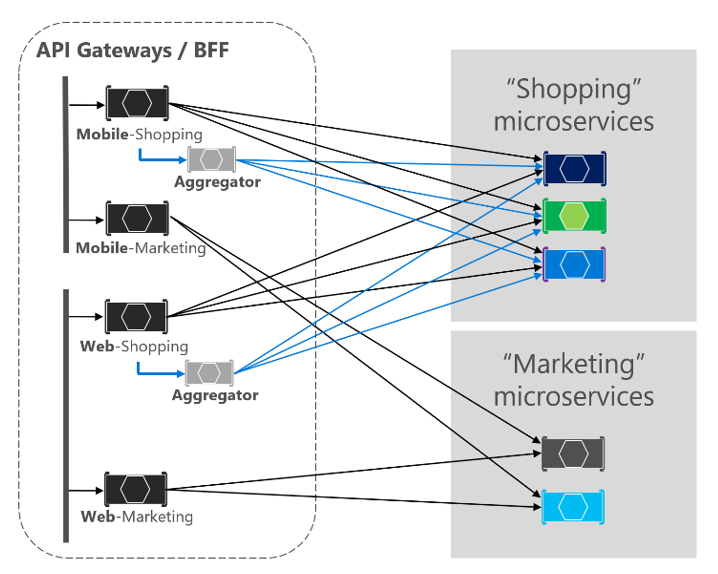
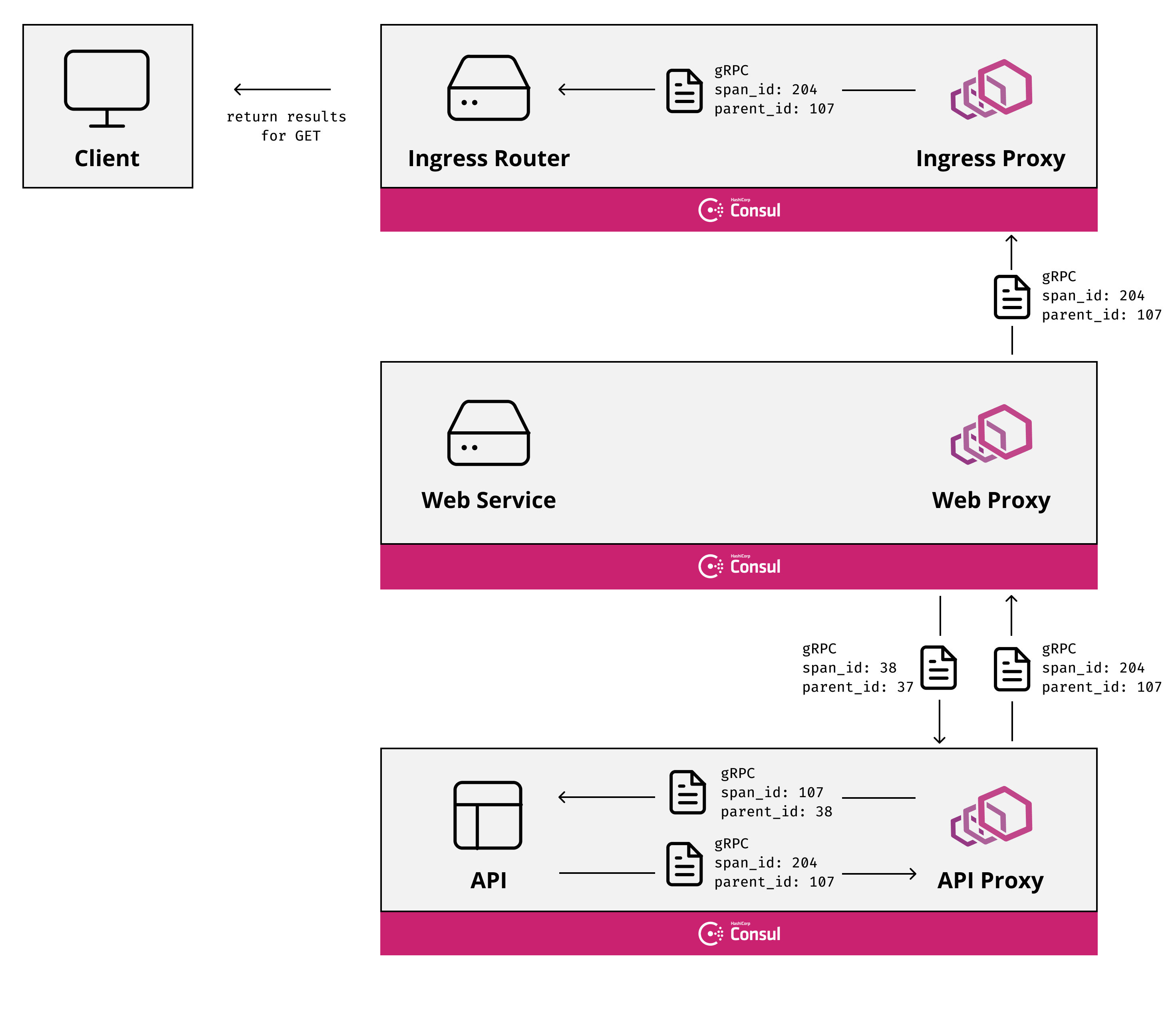
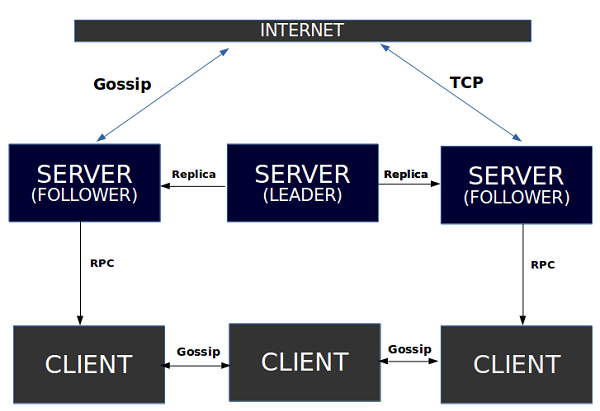
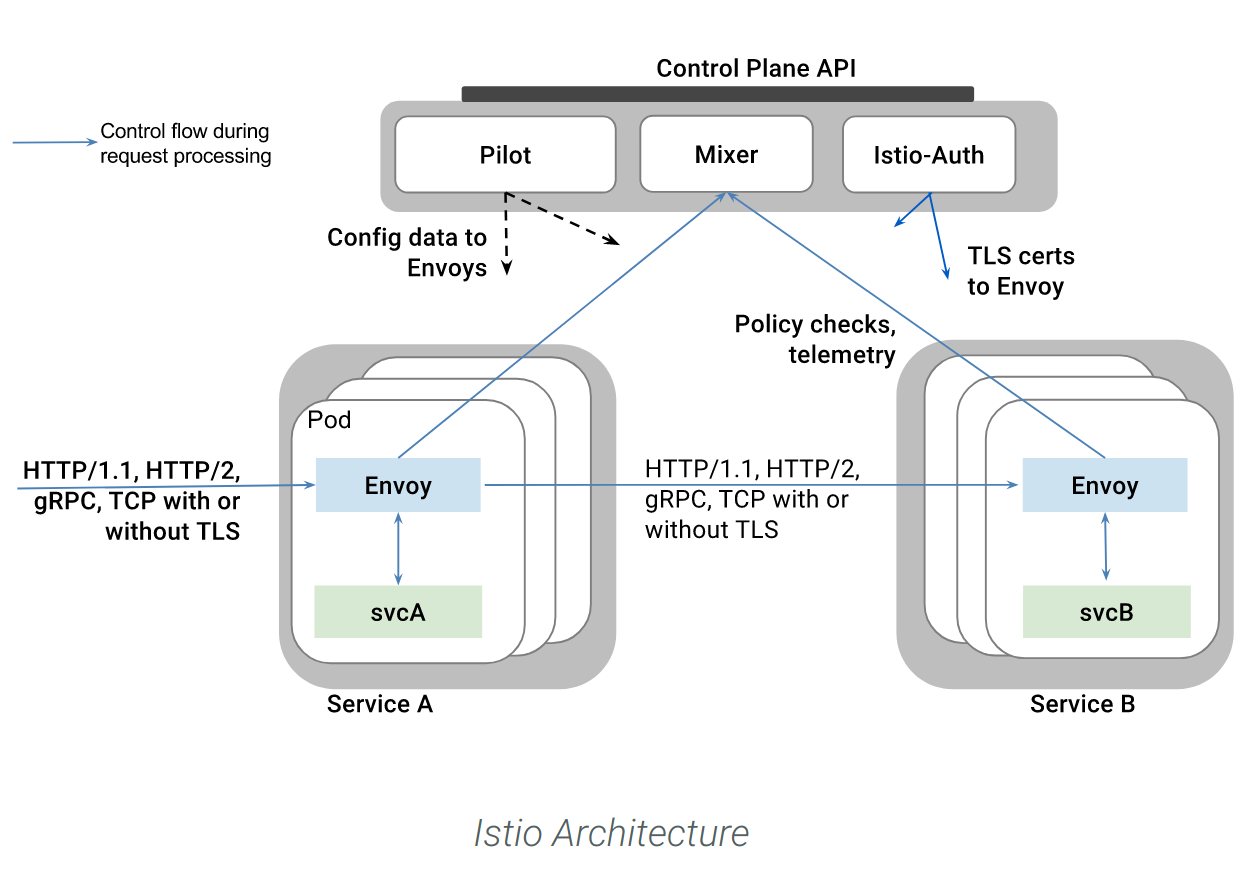
a service mesh is a dedicated infrastructure layer for handling service-to-service communication. Although this definition sounds very much like a CNI implementation on Kubernetes, there are some differences. A service mesh typically sits on top of the CNI and builds on its capabilities. It also adds several additional capabilities like service discovery and security.
The components of a service mesh include:
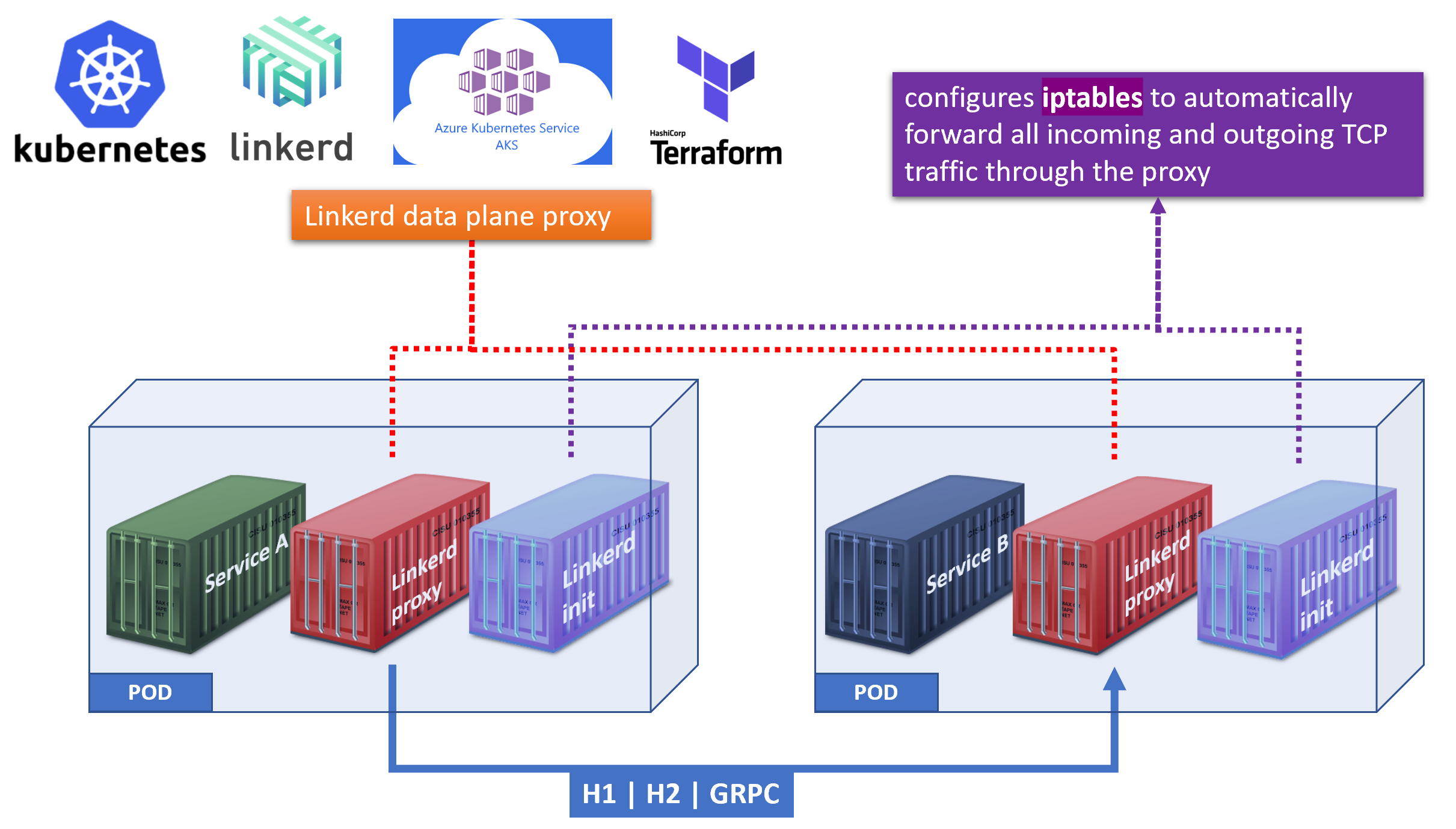
Data plane - made up of lightweight proxies that are distributed as sidecars. Proxies include NGINX, or envoy; all of these technologies can be used to build your own service mesh in Kubernetes. In Kubernetes, the proxies are run as cycles and are in every Pod next to your application.
Control plane - provides the configuration for the proxies, issues the TLS certificates authority, and contain the policy managers. It can collect telemetry and other metrics and some service mesh implementations also include the ability to perform tracing.
How is a service mesh useful?
The example shown below illustrates a Kubernetes cluster with an app composed of these services: a front-end, a backend and a database.
What a service mesh provides?
Not all of the services meshes out there have all of these capabilities, but in general, these are the features you gain:
Service Discovery (eventually consistent, distributed cache)
Load Balancing (least request, consistent hashing, zone/latency aware)
Communication Resiliency (retries, timeouts, circuit-breaking, rate limiting)
Security (end-to-end encryption, authorization policies)
Observability (Layer 7 metrics, tracing, alerting)
Routing Control (traffic shifting and mirroring)
API (programmable interface, Kubernetes Custom Resource Definitions (CRD))
Differences between service mesh implementations?
Istio
Has a Go control plane and uses Envoy as a proxy data plane. Istio is a complex system that does many things, like tracing, logging, TLS, authentication, etc. A drawback is the resource hungry control plane
The more services you have the more resources you need to run them on Istio.
AWS App Mesh
still lacks many of the features that Istio has. For example it doesn’t include mTLS or traffic policies.
Linkerd v2
Also has a Go control plane and a Linkerd proxy data plane that is written in Rust.
Linkerd has some distributed tracing capabilities and just recently implemented traffic shifting.
The current 2.4 release implements the Service Mesh Interface (SMI) traffic split API, that makes it possible to automate Canary deployments and other progressive delivery strategies with Linkerd and Flagger.
Consul Connect
Uses a Consul control plane and requires the data plane to managed inside an app. It does not implement Layer 7 traffic management nor does it support Kubernetes CRDs.
How does progressive delivery work with a service mesh?
Progressive delivery is Continuous Delivery with fine-grained control over the blast radius. This means that you can deliver new features of your app to a certain percentage of your user base.
In order to control the progressive deployments, you need the following:
User segmentation (provided by the service mesh)
Traffic shifting Management (provided by the service mesh)
Observability and metrics (provided by the service mesh)
Automation (service mesh add-on like Flagger)
Canary
A canary is used for when you want to test some new functionality typically on the backend of your application. Traditionally you may have had two almost identical servers: one that goes to all users and another with the new features that gets rolled out to a subset of users and then compared. When no errors are reported, the new version can gradually roll out to the rest of the infrastructure.
https://www.weave.works/blog/introduction-to-service-meshes-on-kubernetes-and-progressive-delivery
- The Common Attributes of a Service Mesh
In the basic architectural diagram above,
the green boxes in the data plane represent applications,
the blue squares are service mesh proxies,
and the rectangles are application endpoints (a pod, a physical host, etc).
The control plane provides a centralized API for controlling proxy behavior in aggregate.
While interactions with the control plane can be automated (e.g. by a CI/CD pipeline), it’s typically where you–as a human–would interact with the service mesh.
Any service mesh in this guide has certain features
Resiliency features (retries, timeouts, deadlines, etc)
Cascading failure prevention (circuit breaking)
Robust load balancing algorithms
Control over request routing (useful for things like CI/CD release patterns)
The ability to introduce and manage TLS termination between communication endpoints
Rich sets of metrics to provide instrumentation at the service-to-service layer
What’s Different About a Service Mesh?
The service mesh exists to make your distributed applications behave reliably in production.
With microservices, service-to-service communication becomes the fundamental determining factor for how your applications behave at runtime.
Application functions that used to occur locally as part of the same runtime instead occur as remote procedure calls being transported over an unreliable network.
Product Comparisons
Linkerd
Built on Twitter’s Finagle library, Linkerd is written in Scala and runs on the JVM
Linkerd includes both a proxying data plane and the Namerd (“namer-dee”) control plane all in one package.
Notable features include:
All of the “table stakes” features (listed above),
Support for multiple platforms (Docker, Kubernetes, DC/OS, Amazon ECS, or any stand-alone machine),
Built-in service discovery abstractions to unite multiple systems,
Support for gRPC, HTTP/2, and HTTP/1.x requests + all TCP traffic.
Envoy
It is written as a high performance C++ application proxy designed for modern cloud-native services architectures.
Envoy is designed to be used either as a standalone proxying layer or as a “universal data plane” for service mesh architectures
Specifically on serving as a foundation for more advanced application proxies, Envoy fills the “data plane” portion of a service mesh architecture.
Envoy is a performant solution with a small resource footprint that makes it amenable to running it as either a shared-proxy or sidecar-proxy deployment mode
You can also find Envoy embedded in security frameworks, gateways, or other service mesh solutions like Istio
Notable features include:
All of the “table stakes” features (when paired with a control plane, like Istio),
Low p99 tail latencies at scale when running under load,
Acts as a L3/L4 filter at its core with many L7 filters provided out of the box,
Support for gRPC, and HTTP/2 (upstream/downstream),
API-driven, dynamic configuration, hot reloads,
Strong focus on metric collection, tracing, and overall observability.
Istio
Istio is designed to provide a universal control plane to manage a variety of underlying service proxies (it pairs with Envoy by default)
Istio initially targeted Kubernetes deployments, but was written from the ground up to be platform agnostic
The Istio control plane is meant to be extensible and is written in Go.
Its design goals mean that components are written for a number of different applications, which is part of what makes it possible to pair Istio with a different underlying data plane, like the commercially-licensed Nginx proxy. Istio must be paired with an underlying proxy.
Notable features include:
All of the table stakes features (when paired with a data plane, like Envoy),
Security features including identity, key management, and RBAC,
Fault injection,
Support for gRPC, HTTP/2, HTTP/1.x, WebSockets, and all TCP traffic,
Sophisticated policy, quota, and rate limiting,
Multi-platform, hybrid deployment.
Conduit
Conduit aims to drastically simplify the service mesh user experience for Kubernetes.
Conduit contains both a data plane (written in Rust) and a control plane (written in Go).
All of the table stakes features (some are pending roadmap items as of Apr 2018),
Extremely fast and predictable performance (sub-1ms p99 latency),
A native Kubernetes user experience (only supports Kubernetes),
Support for gRPC, HTTP/2, and HTTP/1.x requests + all TCP traffic.
https://thenewstack.io/which-service-mesh-should-i-use/
- Kubernetes Service Mesh: A Comparison of Istio, Linkerd and Consul
Cloud-native applications are often architected as a constellation of distributed microservices, which are running in Containers.
This exponential growth in microservices creates challenges around figuring out how to enforce and standardize things like routing between multiple services/versions, authentication and authorization, encryption, and load balancing within a Kubernetes cluster.
Building on Service Mesh helps resolve some of these issues, and more. As containers abstract away the operating system from the application, Service Meshes abstract away how inter-process communications are handled.
What is Service Mesh
The thing that is most crucial to understand about microservices is that they are heavily reliant on the network.
Service Mesh manages the network traffic between services.
It does that in a much more graceful and scalable way compared to what would otherwise require a lot of manual, error-prone work and operational burden that is not sustainable in the long-run.
service mesh layers on top of your Kubernetes infrastructure and is making communications between services over the network safe and reliable.
Service mesh allows you to separate the business logic of the application from observability, and network and security policies. It allows you to connect, secure, and monitor your microservices.
Connect: Service Mesh enables services to discover and talk to each other. It enables intelligent routing to control the flow of traffic and API calls between services/endpoints. These also enable advanced deployment strategies such as blue/green, canaries or rolling upgrades, and more.
Secure: Service Mesh allows you secure communication between services. It can enforce policies to allow or deny communication. E.g. you can configure a policy to deny access to production services from a client service running in development environment.
Monitor: Service Mesh enables observability of your distributed microservices system. Service Mesh often integrates out-of-the-box with monitoring and tracing tools (such as Prometheus and Jaeger in the case of Kubernetes) to allow you to discover and visualize dependencies between services, traffic flow, API latencies, and tracing.
Service Mesh Options for Kubernetes:
Consul
Consul is part of HashiCorp’s suite of infrastructure management products
it started as a way to manage services running on Nomad and has grown to support multiple other data center and container management platforms including Kubernetes.
Consul Connect uses an agent installed on every node as a DaemonSet which communicates with the Envoy sidecar proxies that handles routing & forwarding of traffic.
Istio
Istio has separated its data and control planes by using a sidecar loaded proxy which caches information so that it does not need to go back to the control plane for every call
The control planes are pods that also run in the Kubernetes cluster, allowing for better resilience in the event that there is a failure of a single pod in any part of the service mesh
Linkerd
its architecture mirrors Istio’s closely, with an initial focus on simplicity instead of flexibility.
This fact, along with it being a Kubernetes-only solution
While Linkerd v1.x is still supported, and it supports more container platforms than Kubernetes; new features (like blue/green deployments) are focused on v2. primarily.
Istio has the most features and flexibility of any of these three service meshes by far, but remember that flexibility means complexity, so your team needs to be ready for that.
For a minimalistic approach supporting just Kubernetes, Linkerd may be the best choice.
If you want to support a heterogeneous environment that includes both Kubernetes and VMs and do not need the complexity of Istio, then Consul would probably be your best bet.
Migrating between service mesh solutions
Note that service mesh is not as an intrusive transformation as the one from monolithic applications to microservices, or from VMs to Kubernetes-based applications.
Since most meshes use the sidecar model, most services don’t know that they run as a mesh.
Service Mesh is useful for any type of microservices architecture since it helps you control traffic, security, permissions, and observability.
you can start standardizing on Service Mesh in your system design to lay the building blocks and the critical components for large-scale operations
Improving observability into distributed services: For example, If one service in the architecture becomes a bottleneck, the common way to handle it is through re-tries, but that can worsen the bottleneck due to timeouts. With service mesh, you can easily break the circuit to failed services to disable non-functioning replicas and keep the API responsive.
Blue/green deployments: Service mesh allows you to implement Blue/Green deployments to safely rollout new upgrades of the applications without risking service interruption.
First, you expose only a small subset of users to the new version, validate it, then proceed to release it to all instances in Production.
Chaos monkey/ testing in production scenarios: with the ability to inject delays, faults to improve the robustness of deployments
‘Bridge’ / enabler for modernizing legacy applications:If you’re in the throes of modernizing your existing applications to Kubernetes-based microservices, you can use service mesh as a ‘bridge’ while you’re de-composing your apps.
you can use service mesh as a ‘bridge’ while you’re de-composing your apps. You can register your existing applications as ‘services’ in the Istio service catalog and then start migrating them gradually to Kubernetes without changing the mode of communication between services – like a DNS router. This use case is similar to using Service Directory.
API Gateway:If you’re bought into the vision of service mesh and want to start the rollout,you can already have your Operations team start learning the ropes of using service mesh by deploying it simply to measure your API usage.
Service mesh becomes the dashboard for microservices architecture. It’s the place for troubleshooting issues, enforcing traffic policies, rate limits, and testing new code. It’s your hub for monitoring, tracing and controlling the interactions between all services – how they are connected, perform and secured.
https://platform9.com/blog/kubernetes-service-mesh-a-comparison-of-istio-linkerd-and-consul/
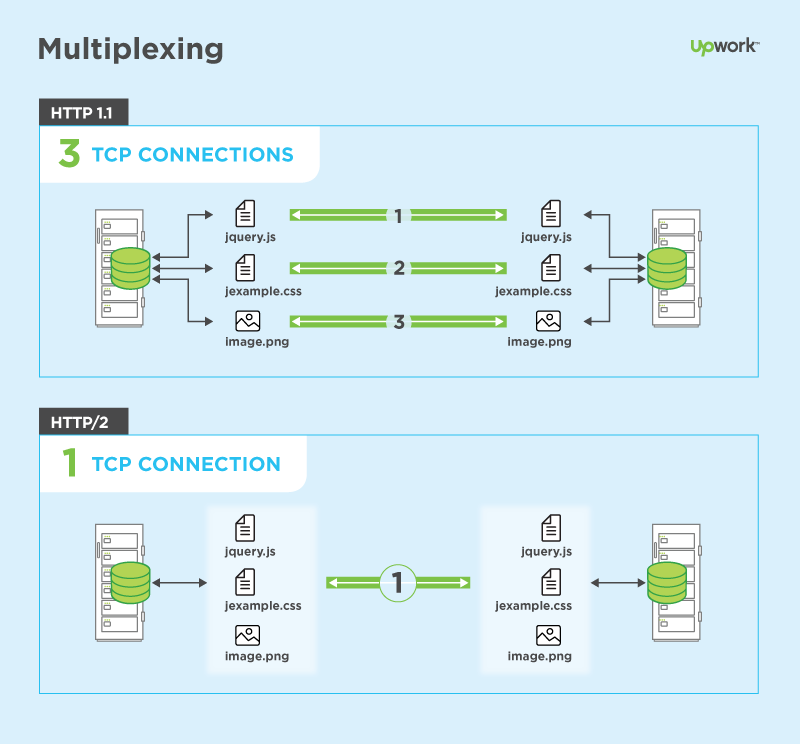
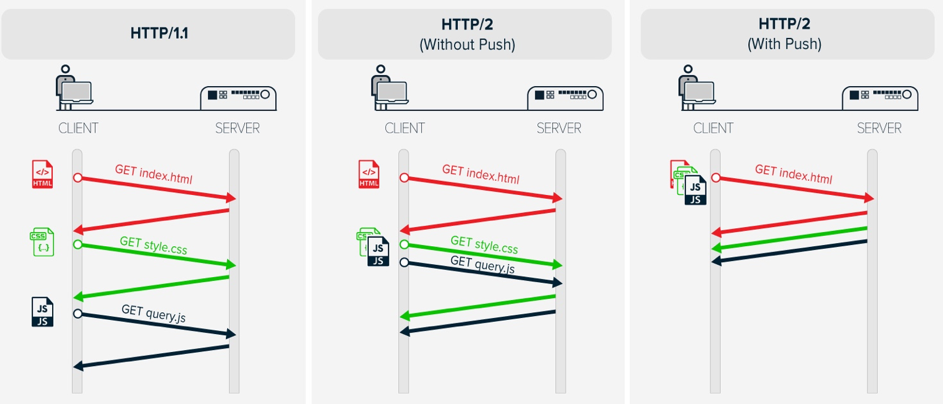
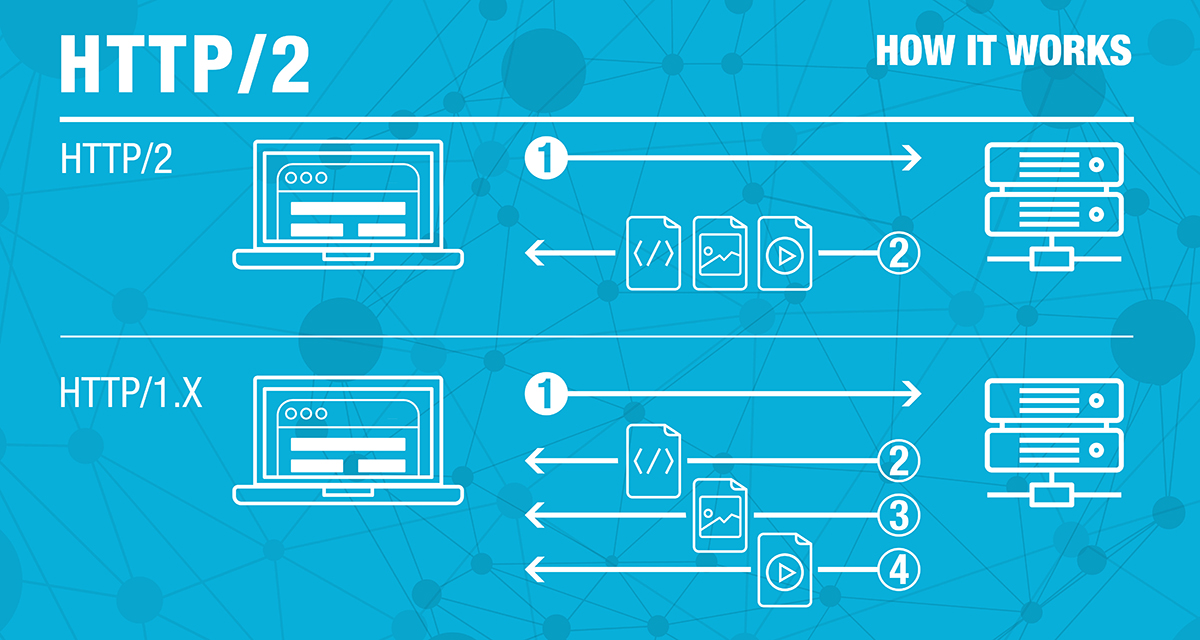
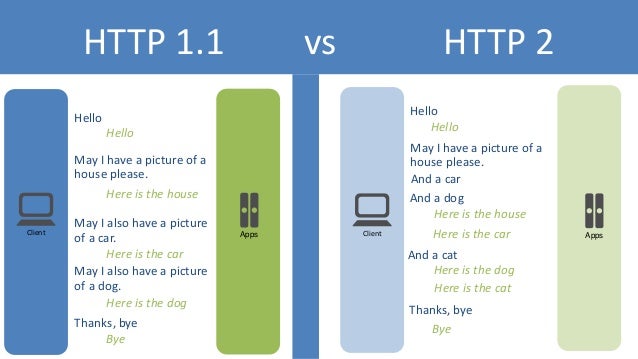
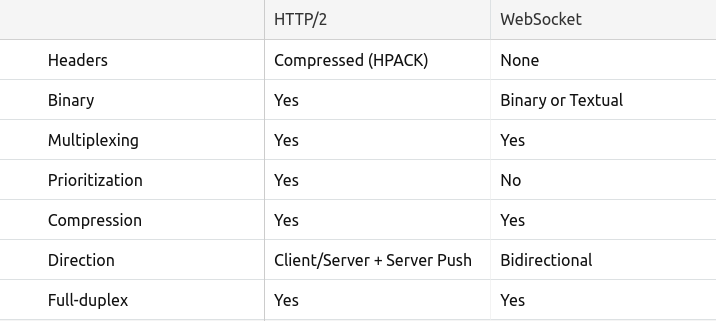
- HTTP/2 (originally named HTTP/2.0) is a major revision of the HTTP network protocol used by the World Wide Web.
Differences from HTTP 1.1
The proposed changes do not require any changes to how existing web applications work, but new applications can take advantage of new features for increased speed
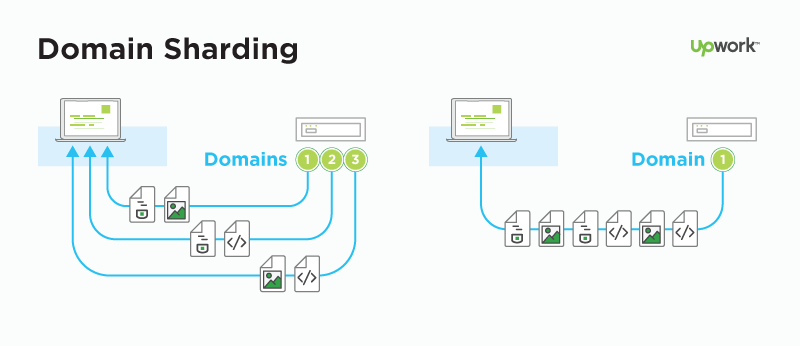
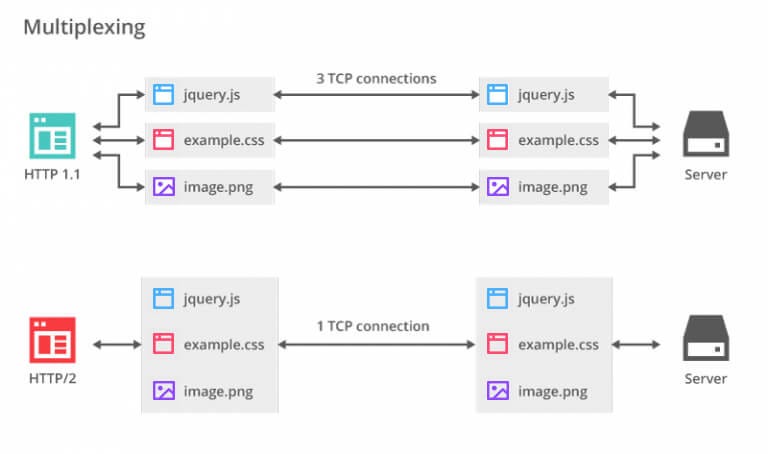
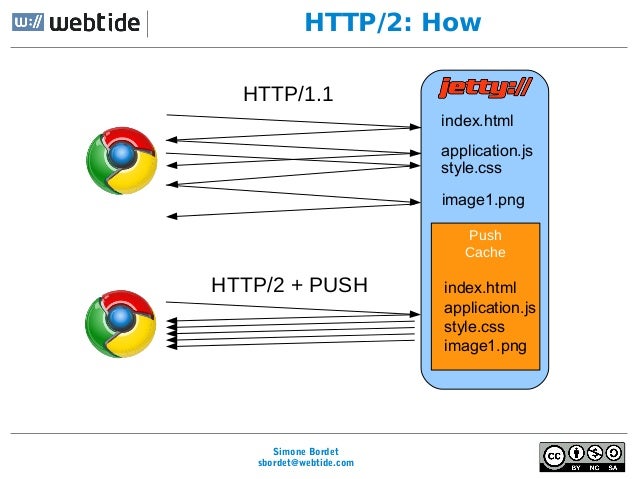
What is new is how the data is framed and transported between the client and the server.Websites that are efficient minimize the number of requests required to render an entire page by minifying (reducing the amount of code and packing smaller pieces of code into bundles, without reducing its ability to function) resources such as images and scripts. However, minification is not necessarily convenient nor efficient and may still require separate HTTP connections to get the page and the minified resources. HTTP/2 allows the server to "push" content, that is, to respond with data for more queries than the client requested. This allows the server to supply data it knows a web browser will need to render a web page, without waiting for the browser to examine the first response, and without the overhead of an additional request cycle.
https://en.wikipedia.org/wiki/HTTP/2
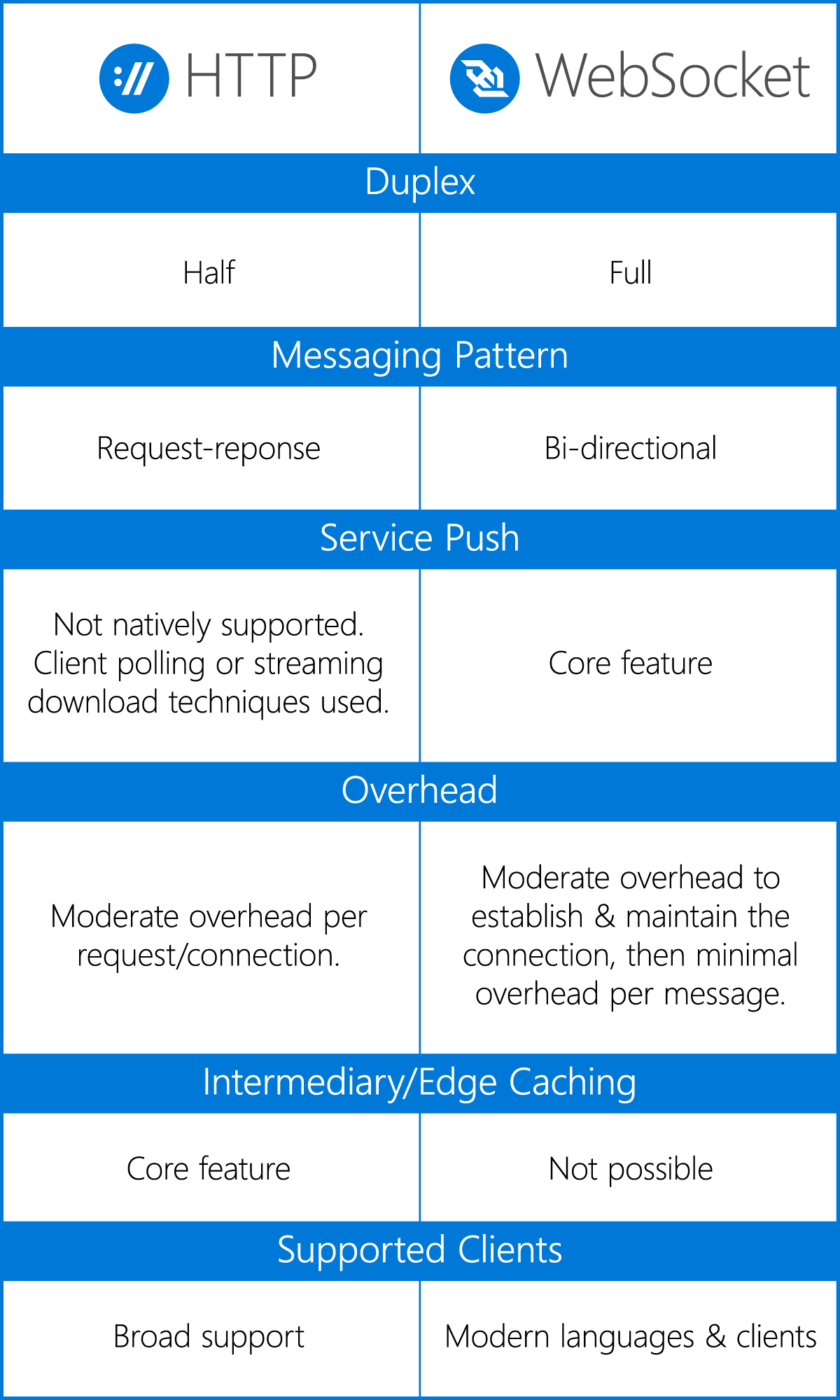
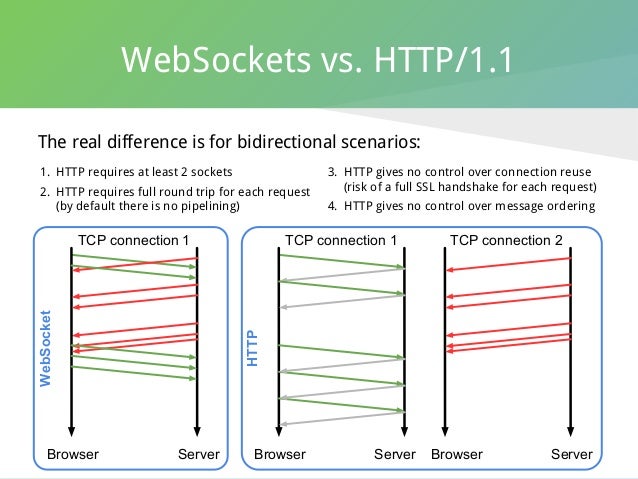
- WebSocket is a computer communications protocol, providing full-duplex communication channels over a single TCP connection. The WebSocket protocol was standardized by the IETF as RFC 6455 in 2011, and the WebSocket API in Web IDL is being standardized by the W3C.WebSocket is distinct from HTTP. Both protocols are located at layer 7 in the OSI model and depend on TCP at layer 4
Although they are different, RFC 6455 states that WebSocket "is designed to work over HTTP ports 80 and 443 as well as to support HTTP proxies and intermediaries," thus making it compatible with the HTTP protocol. To achieve compatibility, the WebSocket handshake uses the HTTP Upgrade header[1] to change from the HTTP protocol to the WebSocket protocol.
The WebSocket protocol enables interaction between a web browser (or other client application) and a web server with lower overhead than half-duplex alternatives such as HTTP polling, facilitating real-time data transfer from and to the server.
https://en.wikipedia.org/wiki/WebSocket
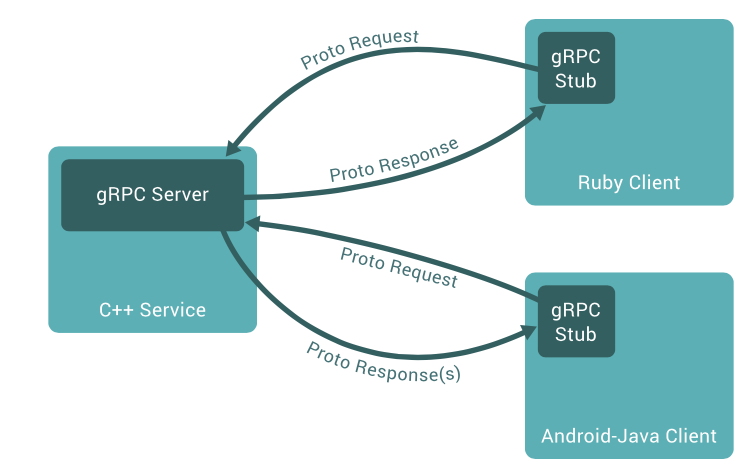
gRPC is a modern open source high performance RPC framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication.
Bi-directional streaming and integrated auth
Bi-directional streaming and fully integrated pluggable authentication with HTTP/2-based transport
https://grpc.io/