- Gemini
Understanding the Basics
Before diving into the differences and use cases, let's establish a foundation.
Block Storage: Data is stored in blocks, the smallest unit of data storage.
Object Storage: Data is stored as objects, with metadata attached to each object.
File Storage: Data is stored in files, organized in a hierarchical structure.
SAN (Storage Area Network): A network-attached storage system providing block-level access to data.
NAS (Network Attached Storage): A network-attached storage system providing file-level access to dat
Detailed Comparison and Use Cases
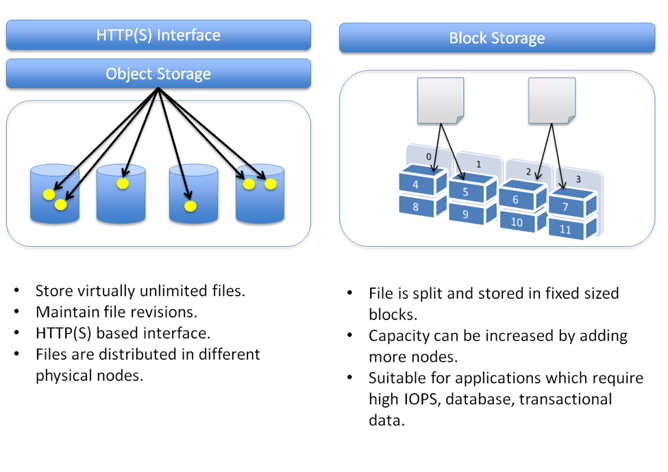
Block Storage
How it works: Data is stored in fixed-size blocks, accessed directly by the operating system.
Best for: High-performance applications like databases, virtual machines, and online transaction processing.
Example: SAN
Object Storage
How it works: Data is stored as objects with metadata, accessed via APIs.
Best for: Storing large amounts of unstructured data, backups, archives, and big data analytics.
Example: Amazon S3, Google Cloud Storage
File Storage
How it works: Data is stored in files and organized in a hierarchical structure.
Best for: File sharing, collaboration, and general data storage.
Example: NAS
SAN (Storage Area Network)
How it works: A dedicated network for storage devices, providing block-level access to data.
Best for: High-performance computing, databases, virtualized environments.
Example: Enterprise data centers
NAS (Network Attached Storage)
How it works: A file-level network storage device accessible via standard network protocols.
Best for: File sharing, home/small office storage, backup and recovery.
Example: Network-attached storage device in a home or small office
- Object Storage
Block storage is another storage option for containers. As previously mentioned, file system storage organizes data into a hierarchy of files and folders. In contrast, block storage stores chunks of data in blocks. A block
File System Storage
File system storage has been around for decades, and stores data as files. Each file
http://rancher.com/block-object-file-storage-containers/
- Storage Wars: File vs Block vs Object Storage
The standard naming convention makes them easy enough to organize while storage technologies such as NAS allow for convenient sharing at the local level
File Storage Use Cases
File sharing: If you just need a place to store and share files in the office, the simplicity of file-level storage is where it’s at.
Local archiving: The ability
Data protection: Combined with easy deployment, support for standard protocols, native replication, and various drive technologies makes file-level storage a viable data protection solution
IT pros will deploy block storage most commonly
Block Storage Use Cases
Databases: Block storage is common in databases and other mission-critical applications that demand consistently high performance.
Email servers: Block storage is the
RAID: Block storage can create an ideal foundation for RAID arrays designed to bolster data protection and performance by combining multiple disks as independent volumes.
Virtual machines: Virtualization software vendors such as
object-based storage stores data in isolated containers known as objects
You can give a single object a unique identifier and store it in a flat memory model. This is important for two reasons. You can retrieve an object from storage by
Scalability is where object-based storage does its most impressive work.
Scaling out an object architecture is as simple as adding additional nodes to the storage cluster.
Every server has its physical limitations. But thanks to location transparency and remarkable metadata
While files and blocks are
API applications such as
Object Storage Use Cases
Big data: Object storage
Web apps: You can normally access object storage through an API.
Backup archives: Object storage has native support for large data sets and near infinite scaling capabilities.
https://blog.storagecraft.com/storage-wars-file-block-object-storage/
- In the Cloud: Block Storage vs. Object Storage
Object Storage Systems
Enterprises use object storage for different use cases, such as static content storage and distribution, backup and archiving, and disaster recovery. Object storage works very well for unstructured data sets where data
The data or content of the object
A unique identifier associated with the
Metadata - each object has
For object-based storage systems, there is no hierarchy of relations between files.
The Block Storage System
We use block storage systems to host our databases, support random read/write operations, and keep system files of the running virtual machines.
Why Object-based Storage and Not Block?
The primary advantage of the object-based storage is that you can easily distribute objects across various nodes on the storage backend. As
Why Block-based Storage and Not Object?
With block-based storage, it is easier to
In object-based storage,
https://cloud.netapp.com/blog/block-storage-vs-object-storage-cloud
- Object Storage versus Block Storage: Understanding the Technology Differences
Every object contains three things:
The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for assembling an aircraft.
An expandable amount of metadata. The metadata
A globally unique identifier. The identifier is an address given to the object in order for the object to
With block storage,
Object storage
However, object storage
Another key difference is
Items such as static Web content, data backup, and archives are fantastic use cases. Object-based storage architectures can
Objects remain protected by storing multiple copies of data over a distributed system
Object storage systems are eventually consistent while block storage systems are strongly consistent.
Eventual consistency can provide virtually unlimited scalability. It ensures high availability for data that needs to
Geographically distributed back-end storage is another great use case for object storage. The object storages applications present as network storage and support extendable metadata for efficient distribution and parallel access to objects. That makes it ideal for moving your back-end storage clusters across multiple data centers.
We don’t recommend you use object storage for transactional data, especially because of the eventual consistency model outlined previously. In addition, it’s very important to recognize that object storage
storage-versus-block-storage-understanding-technology-differences/
- FILE STORAGE
File storage exists in two forms: File Servers and Networked Attached Storage (NAS).
NAS is a file server appliance.
File storage provides standard network file sharing protocols to exchange file content between systems.
Standard file sharing protocols include NFS and SMB (
Index tables include:
Standard file system metadata, stored separately from the file itself, record basic file attributes such as the
BLOCK STORAGE
Which manages data as blocks within sectors and tracks, and file storage, which manages files organized into hierarchical file systems.
In computing, a block, sometimes called a physical record, is a sequence of bytes or bits, usually containing some whole number of records, having a maximum length, a block size
Block storage
OBJECT STORAGE
Object storage organizes information into containers of flexible sizes, referred to as objects.
Each object includes the data itself
https://www.scality.com/topics/what-is-object-storage/
- DISTRIBUTED FILE SYSTEM
A distributed file system
METADATA
EXAMPLES OF DFS
NFS
CIFS/SMB
Hadoop
NetWare
https://www.scality.com/topics/what-is-a-distributed-file-system/
- OBJECT STORAGE VS. NAS
WHAT IS NAS?
NAS, or Network Attached Storage, is the main and primary shared storage architecture for file storage, which has been the ubiquitous and familiar way to store data for a long time, based on a traditional file system comprising files organized in hierarchical directories.
WHAT IS OBJECT STORAGE?
By design, it overcomes the limitations of NAS and other traditional storage architectures that would not fit the bill for such cloud-scale environments.
In an Object Storage solution,
These objects can
Objects may be local or geographically separated, but
Most object
https://www.scality.com/topics/object-storage-vs-nas/
Ded uplication
Snapshots and clones
Make and save snapshots of the entire file system on demand or schedule the process to save effort. In case of malware attack or user error, administrators can roll the system back to an uninfected state. Recovery takes seconds, not days.
https://www.ixsystems.com/freenas-mini/
- Compression Vs. Deduplication
Thin Provisioning
Compression
Compression works by identifying redundancy “within a file” and then removing those redundancies.
Deduplication
While deduplication takes potentially the same amount of processing power, it by comparison can be more memory intensive than compression because the comparable range is now “across all the files” (in fact segments of those files) in the environment.
http://www.storage-switzerland.com/Articles/Entries/2012/9/26_Compression_Vs._Deduplication.html
- ChatGPT
Compression, deduplication, and encryption are distinct data management techniques used to optimize storage, enhance security, and manage data more efficiently. Here’s a detailed explanation of each, including their differences and best use cases:
1. Compression
Definition: Compression reduces the size of data by encoding it more efficiently, which can save storage space and improve data transfer speeds.
Characteristics:
Reduces Data Size: Compresses data to occupy less space, either by removing redundancy (lossless) or discarding some data (lossy).
Improves Efficiency: Helps in reducing storage costs and speeding up data transmission.
Decompression Required: Data needs to be decompressed before use, which requires additional processing.
Types:
Lossless Compression: No data is lost during compression. Examples include ZIP files and PNG images.
Lossy Compression: Some data is discarded to achieve higher compression rates. Examples include JPEG images and MP3 audio.
Best Use Cases:
File Storage: Reducing the size of files to save disk space.
Data Transfer: Compressing data for faster transmission over networks.
Backup: Compressing backup files to save storage space and improve backup speed.
Example: Gzip - A popular tool for compressing files in UNIX-based systems.
2. Deduplication
Definition: Deduplication eliminates duplicate copies of data to reduce storage usage and increase efficiency.
Characteristics:
Eliminates Redundancy: Identifies and removes duplicate data blocks, keeping only one copy.
Efficiency: Reduces storage requirements and can improve backup performance by minimizing the amount of data written.
Single Instance Storage: Stores only a single instance of identical data.
Types:
File-Level Deduplication: Removes duplicate files across the storage system.
Block-Level Deduplication: Identifies and removes duplicate blocks of data within files.
Best Use Cases:
Backup and Archiving: Reducing storage requirements for backups and archives by eliminating duplicate data.
Virtualization: Optimizing storage for virtual machines by eliminating redundant virtual disk data.
Data Storage: Reducing the size of data stored on disk by eliminating redundant blocks.
Example: Dell EMC Data Domain - A deduplication appliance that optimizes backup storage.
3. Encryption
Definition: Encryption transforms data into a secure format that can only be read or decrypted by authorized users with the correct decryption key.
Characteristics:
Data Security: Protects data from unauthorized access and ensures confidentiality.
Two Types:
Symmetric Encryption: Uses the same key for encryption and decryption (e.g., AES).
Asymmetric Encryption: Uses a pair of keys (public and private) for encryption and decryption (e.g., RSA).
Performance Impact: Can affect system performance due to the computational overhead of encryption and decryption.
Best Use Cases:
Data at Rest: Encrypting stored data to protect it from unauthorized access if storage devices are compromised.
Data in Transit: Encrypting data transmitted over networks to prevent eavesdropping or tampering.
Compliance: Meeting regulatory requirements for data protection and privacy.
Example: BitLocker - A disk encryption feature in Windows that encrypts entire drives to protect data.
Summary of Differences:
Compression:
Purpose: Reduces the size of data to save space and improve transfer speeds.
Impact: Saves storage space and speeds up data transfer.
Use Cases: File storage, data transfer, backup.
Deduplication:
Purpose: Eliminates duplicate data to reduce storage usage.
Impact: Reduces storage requirements by keeping only one copy of duplicated data.
Use Cases: Backup and archiving, virtualization, data storage.
Encryption:
Purpose: Secures data by converting it into a format only accessible by authorized users.
Impact: Protects data from unauthorized access, ensuring confidentiality.
Use Cases: Data at rest, data in transit, compliance.
Each technique addresses different aspects of data management and security. Compression and deduplication focus on optimizing storage efficiency, while encryption is concerned with protecting data confidentiality and security. Depending on your needs, you might use one or a combination of these techniques to manage your data effectively.
- Compression, deduplication and encryption: What's the difference?
Data compression
Compression is actually
Data deduplication
File deduplication (sometimes called data reduction or commonality factoring) is another space-saving technology intended to eliminate redundant (duplicate) files on a storage system
http://searchdatabackup.techtarget.com/tip/Compression-deduplication-and-encryption-Whats-the-difference
- Understanding data deduplication ratios in backup systems
Data backup policies: the greater the frequency of "full" backups (versus "incremental" or "differential" backups), the higher the deduplication potential since data will be redundant from day to day.
Data retention settings:
Data type: some data is inherently more prone to duplicates than others. It's more reasonable to expect higher deduplication ratios if the environment contains primarily Windows servers with similar files, or
http://searchdatabackup.techtarget.com/tip/Understanding-data-deduplication-ratios-in-backup-systems
- In computing, data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. Related and somewhat synonymous terms are intelligent (data) compression and single-instance (data) storage. This technique
is used to improve storage utilization and can alsobe applied to be sent
https://en.wikipedia.org/wiki/Data_deduplication
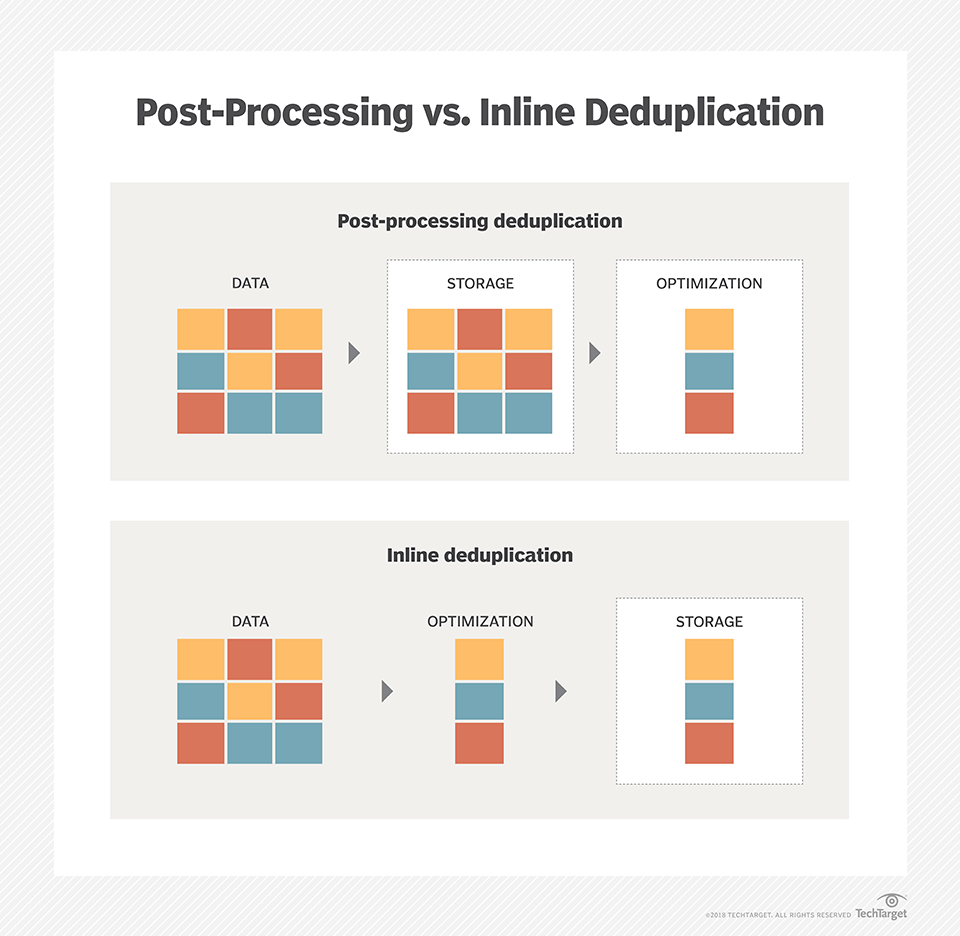
- Inline deduplication is the removal of redundancies from data before or as it is being written to a backup device. Inline deduplication reduces the amount of redundant data in an application and the capacity needed for the backup disk targets,
in comparison to post-process deduplication.
https://searchdatabackup.techtarget.com/definition/inline-deduplication


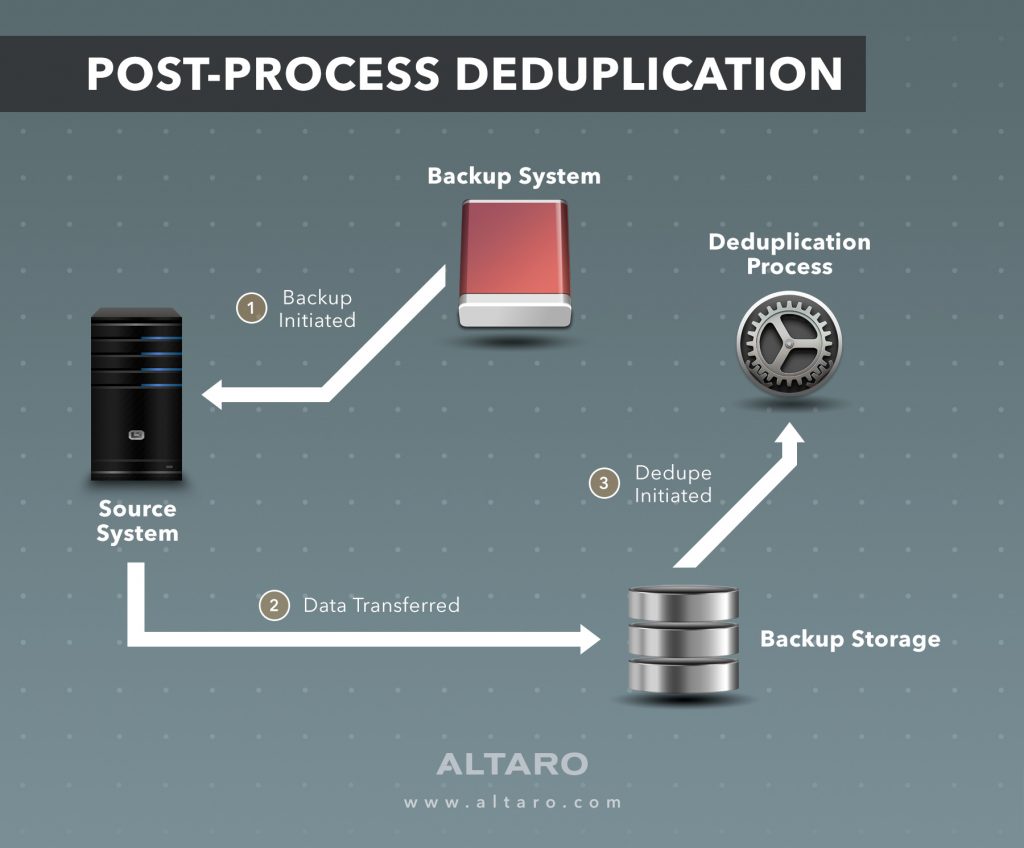
- Post-Processing Deduplication (PPD)
Post-process deduplication (PPD) refers to a system where software processes filter redundant data from a data set after
https://www.techopedia.com/definition/14776/post-processing-deduplication-ppd
- Post-processing backs up data faster and reduces the backup window, but requires more
disk because backup datais temporarily stored to speed the process.
However, inline deduplication can cause a performance issue during the data backup process because the
In addition, erasure coding, compression and deduplication can work together in data protection and conserving storage capacity, but they have stark differences. Erasure coding enables data that becomes corrupted to
https://searchdatabackup.techtarget.com/tutorial/Inline-deduplication-vs-post-processing-Data-dedupe-best-practices

- The term raw disk refers to the accessing of the data on a hard disk drive (HDD) or other disk storage device or media directly at the individual byte level instead of through its filesystem as
is usually done
http://www.linfo.org/raw_disk.html
- Block And File—The Long-Time Storage Champions
The most common enterprise data storage models are ‘block storage’ and ‘file storage’. Block storage became increasingly popular in the mid-1990s, as computers in the data center moved from each using its own
While both block and file storage have many advantages, they both face challenges with the changing nature and explosive growth of data. More and more data created today is ‘unstructured’—individual items of information.
Object Storage—Valet Parking For Your Data
To illustrate how object storage works, computer experts often use a car parking analogy. Imagine your car is an item of unstructured data. You want to 'store' or park it in a parking lot. You have three options.
Object Metadata Powers Big Data, Analytics and Data Science
Another powerful feature of object storage is its use of ‘metadata’—or ‘data about data’.
This attached metadata enables much more sophisticated searching of data in object storage than in file storage—where the filename is often the only clue to a file’s contents. In a supermarket analogy, file storage is like the ‘value’ or ‘white label’ shelf, where items
Another powerful aspect of object storage is that the nature of this metadata can
Organizations can use the latest on-premise systems like EMC
https://turkey.emc.com/storage/elastic-cloud-storage/articles/what-is-object-storage-cloud-ecs.htm
- Object storage offers substantially better scalability, resilience, and durability than today’s parallel file systems, and for certain workloads, it can deliver staggering amounts of bandwidth to and from
compute as well GET
Key Features of Object Storage
PUT creates a new object and fills it with data.
There is no way to
When a new object
GET retrieves the contents of an object based on its object ID
Editing an object means creating a
This gross simplicity has
Because data is
Because the only reference to an object is its unique object ID, a simple hash of the object
The Limitations of Object Storage
Objects’ immutability restricts them to write-once, read-many workloads. This means object stores cannot
Objects
Both
This separation of the object store from the user-facing access interface brings some powerful features with it. For example, an object store may have a gateway that provides an S3-compatible interface with user accounting, fine-grained access controls, and user-defined object tags for applications that natively speak the S3 REST API.
Because object storage does not
Much more sophisticated interfaces can be
Object Storage Implementations
DDN WOS
how object stores
-separates back-end object storage servers and front-end gateways, and the API providing access to the back-end is dead simple and accessible via C++, Python, Java, and raw REST
-objects
-
-
-active data scrubbing occurs on the backend; most other object stores assume that data integrity
-
-NFS gateways scale out to eight servers, each with
OpenStack Swift
-stores objects in block file systems like ext3, and it relies heavily on file system features (specifically,
-
-container and account servers store a subset of
-container and account servers store a subset of
https://www.glennklockwood.com/data-intensive/storage/object-storage.html
- What is
iRODS
The Integrated Rule-Oriented Data System (
Open Source Data Management Software
The plugin architecture supports
https://irods.org
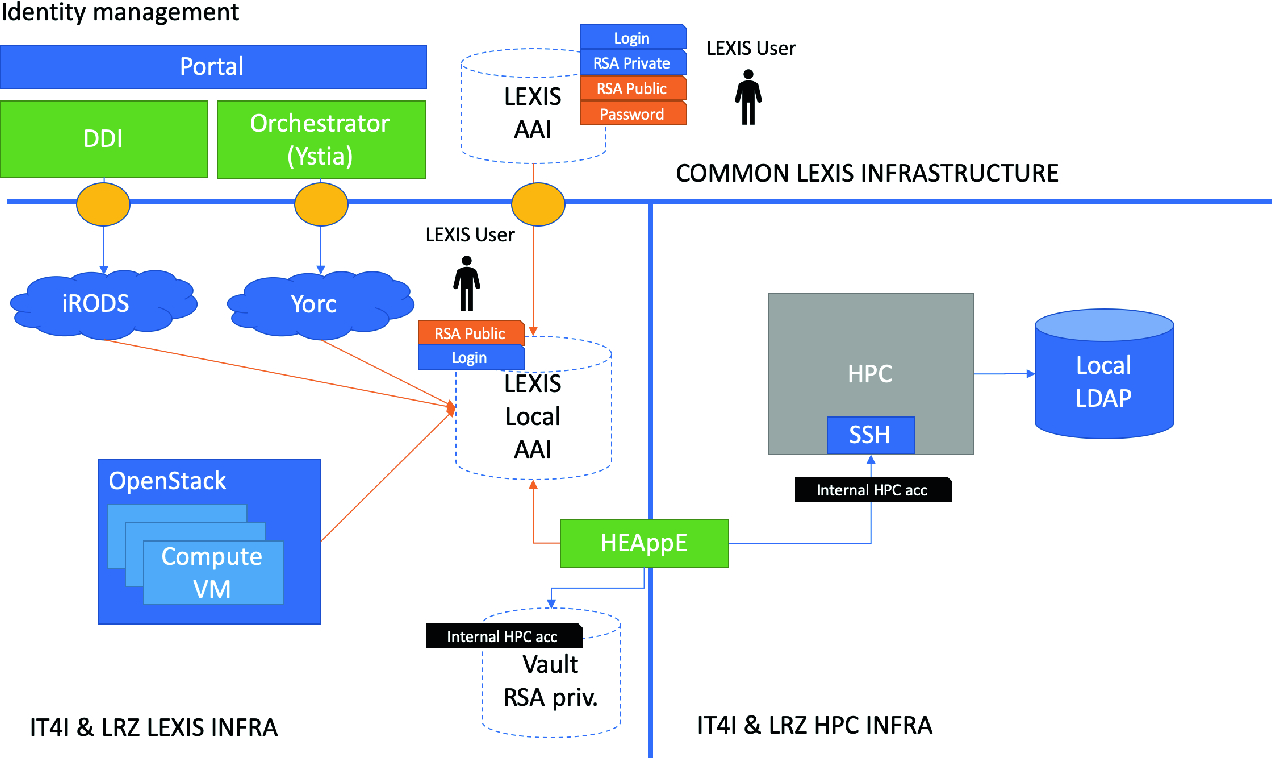
HPC, Cloud and Big-Data Convergent Architectures: The LEXIS Approach
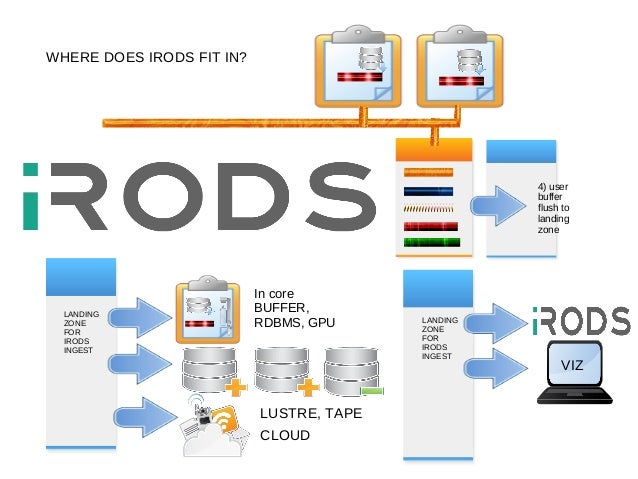
A Fast, Scale-able HPC Engine for Data Ingest

Managing Next Generation Sequencing Data with iRODS
MarFS
Our default implementation uses GPFS file systems as the metadata component and Scality object stores as the data component.
https://github.com/mar-file-system/marfs
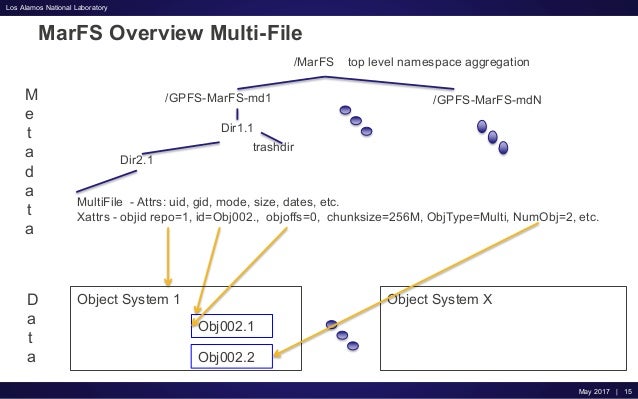
An Update on MarFS
