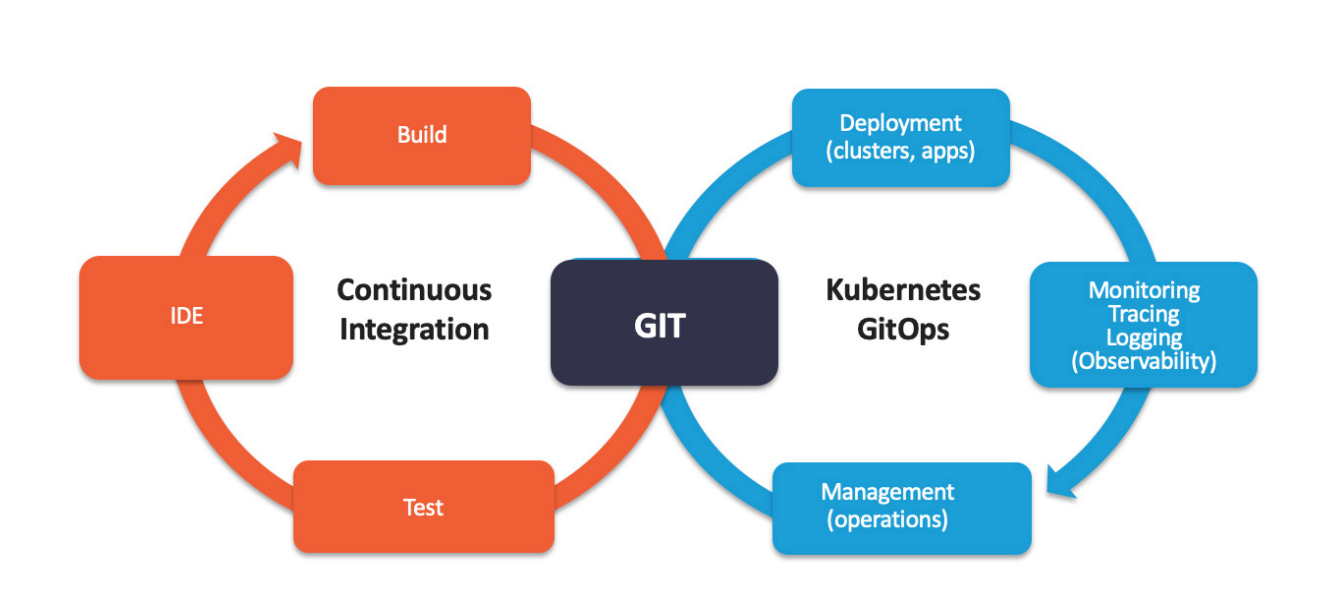
GitOps is a way of implementing Continuous Deployment for cloud native applications. It focuses on a developer-centric experience when operating infrastructure, by using tools developers are already familiar with, including Git and Continuous Deployment tools.
The core idea of GitOps is having a Git repository that always contains declarative descriptions of the infrastructure currently desired in the production environment and an automated process to make the production environment match the described state in the repository. If you want to deploy a new application or update an existing one, you only need to update the repository - the automated process handles everything else. It’s like having cruise control for managing your applications in production.
Why should I use GitOps?
Deploy Faster More Often
What is unique about GitOps is that you don’t have to switch tools for deploying your application. Everything happens in the version control system you use for developing the application anyways.
When we say “high velocity” we mean that every product team can safely ship updates many times a day — deploy instantly, observe the results in real time, and use this feedback to roll forward or back.
Easy and Fast Error Recovery
This makes error recovery as easy as issuing a git revert and watching your environment being restored.The Git record is then not just an audit log but also a transaction log. You can roll back & forth to any snapshot.
Easier Credential Management
your environment only needs access to your repository and image registry. That’s it. You don’t have to give your developers direct access to the environment.
kubectl is the new ssh. Limit access and only use it for deployments when better tooling is not available.
Self-documenting Deployments
With GitOps, every change to any environment must happen through the repository. You can always check out the master branch and get a complete description of what is deployed where plus the complete history of every change ever made to the system. And you get an audit trail of any changes in your system
Shared Knowledge in Teams
Using Git to store complete descriptions of your deployed infrastructure allows everybody in your team to check out its evolution over time. With great commit messages everybody can reproduce the thought process of changing infrastructure and also easily find examples of how to set up new systems.
How does GitOps work?
Environment Configurations as Git repository
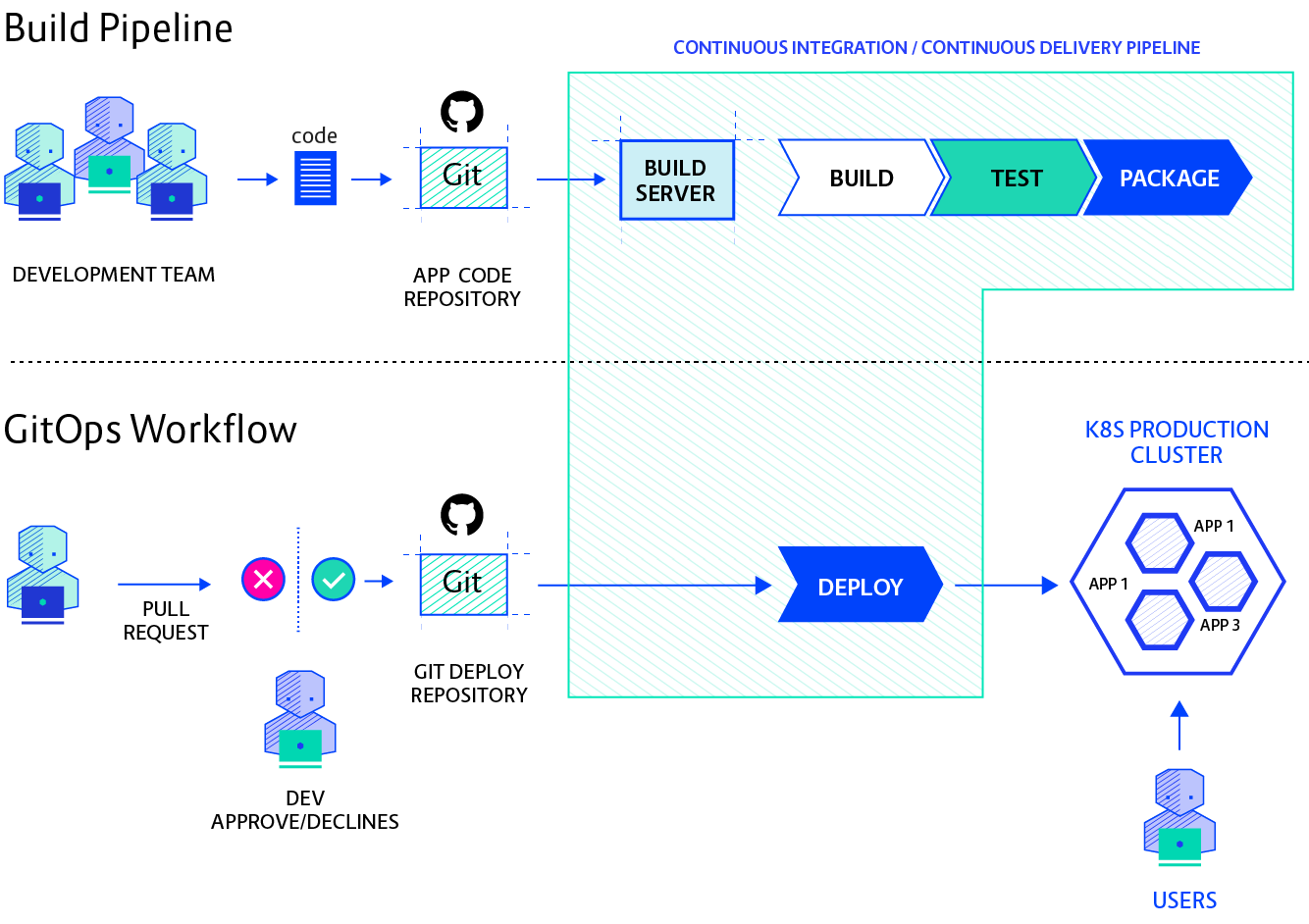
GitOps organizes the deployment process around code repositories as the central element. There are at least two repositories: the application repository and the environment configuration repository. The application repository contains the source code of the application and the deployment manifests to deploy the application. The environment configuration repository contains all deployment manifests of the currently desired infrastructure of an deployment environment.
Push-based vs. Pull-based Deployments
There are two ways to implement the deployment strategy for GitOps: Push-based and Pull-based deployments.
The difference between the two deployment types is how it is ensured, that the deployment environment actually resembles the desired infrastructure.
When possible, the Pull-based approach should be preferred as it is considered the more secure and thus better practice to implement GitOps.
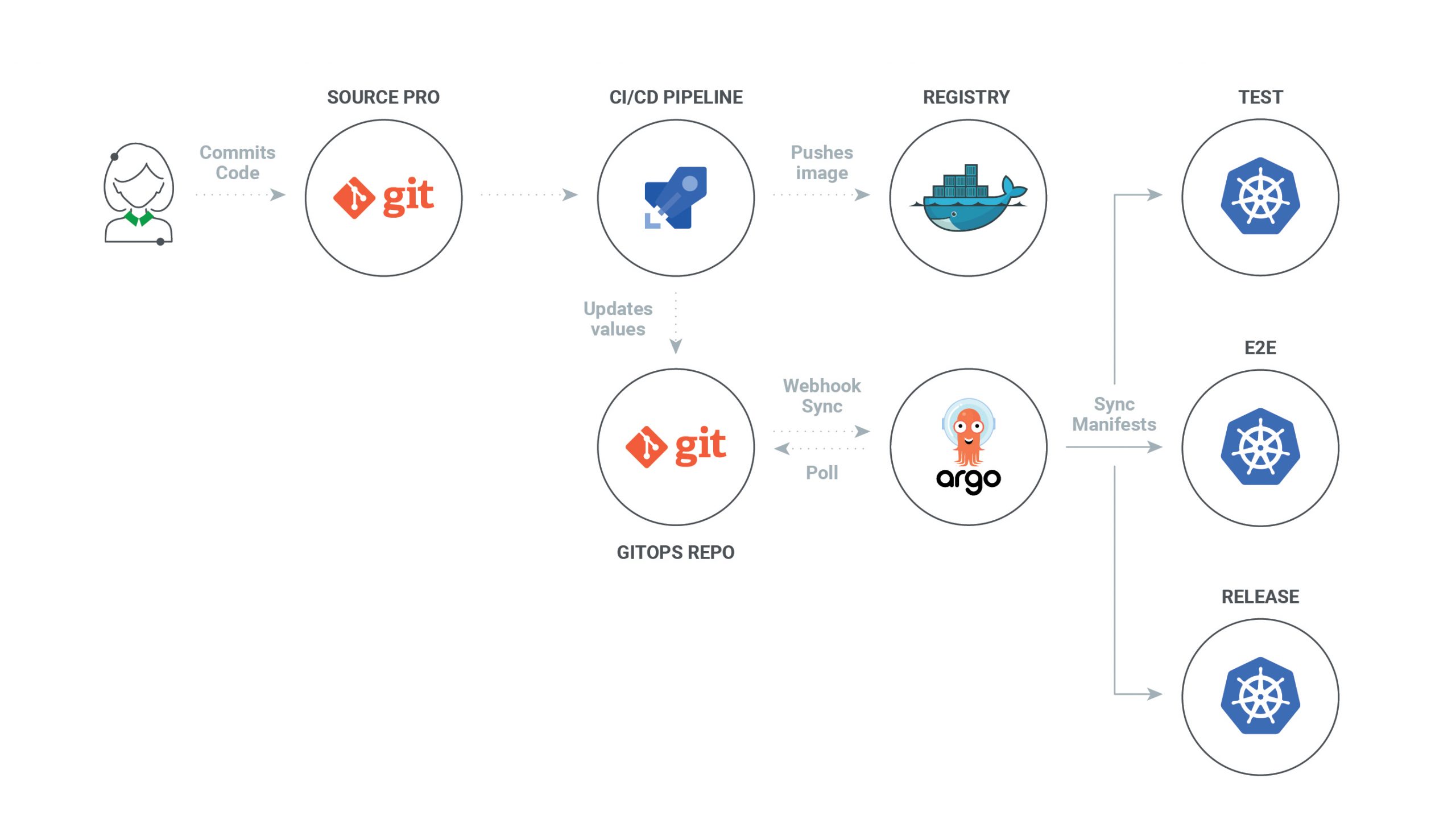
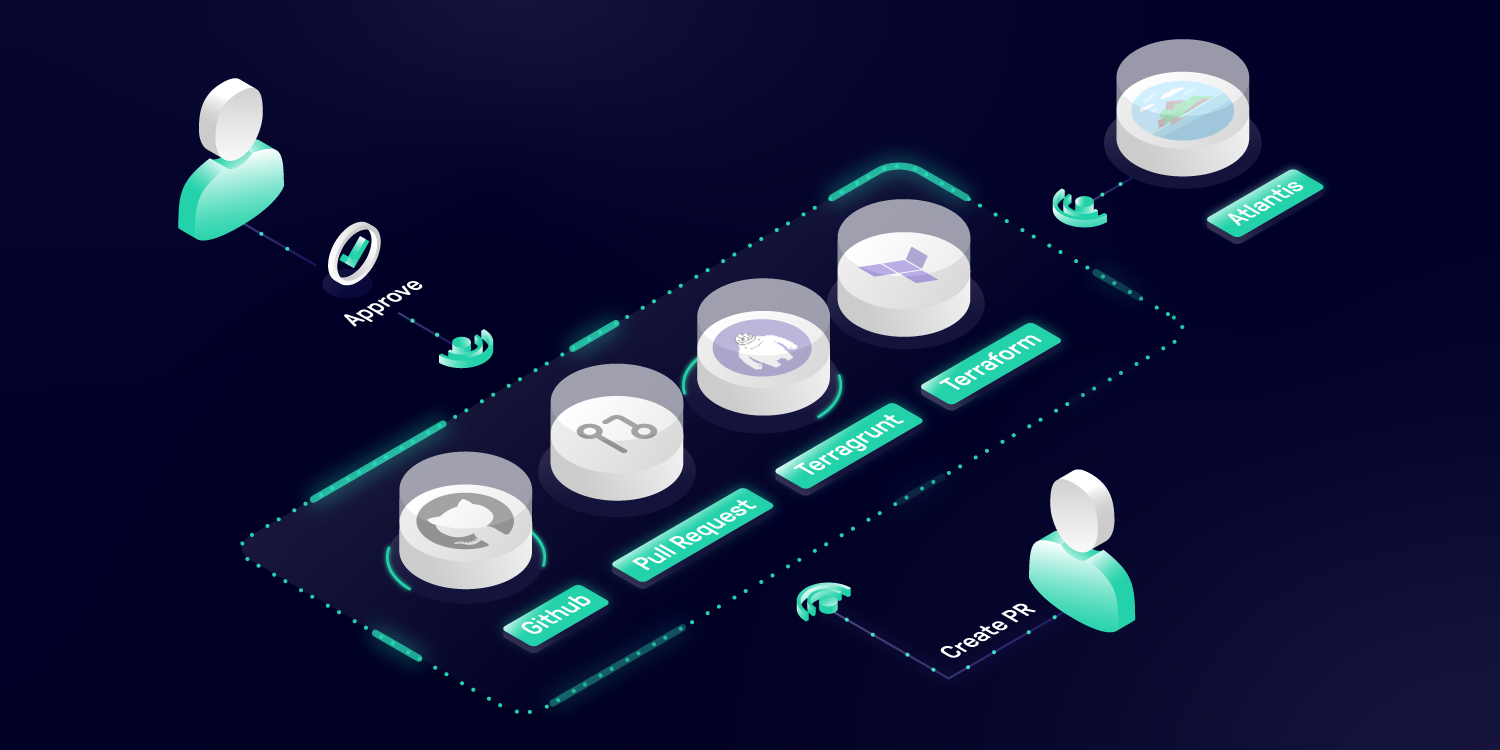
Push-based Deployments
The Push-based deployment strategy is implemented by popular CI/CD tools such as Jenkins, CircleCI, or Travis CI. The source code of the application lives inside the application repository along with the Kubernetes YAMLs needed to deploy the app. Whenever the application code is updated, the build pipeline is triggered, which builds the container images and finally the environment configuration repository is updated with new deployment descriptors.
With this approach it is indispensable to provide credentials to the deployment environment.
In some use cases a Push-based deployment is inevitable when running an automated provisioning of cloud infrastructure. In such cases it is strongly recommended to utilize the fine-granular configurable authorization system of the cloud provider for more restrictive deployment permissions.
Another important thing to keep in mind when using this approach is that the deployment pipeline only is triggered when the environment repository changes. It can not automatically notice any deviations of the environment and its desired state. This means, it needs some way of monitoring in place, so that one can intervene if the environment doesn’t match what is described in the environment repository
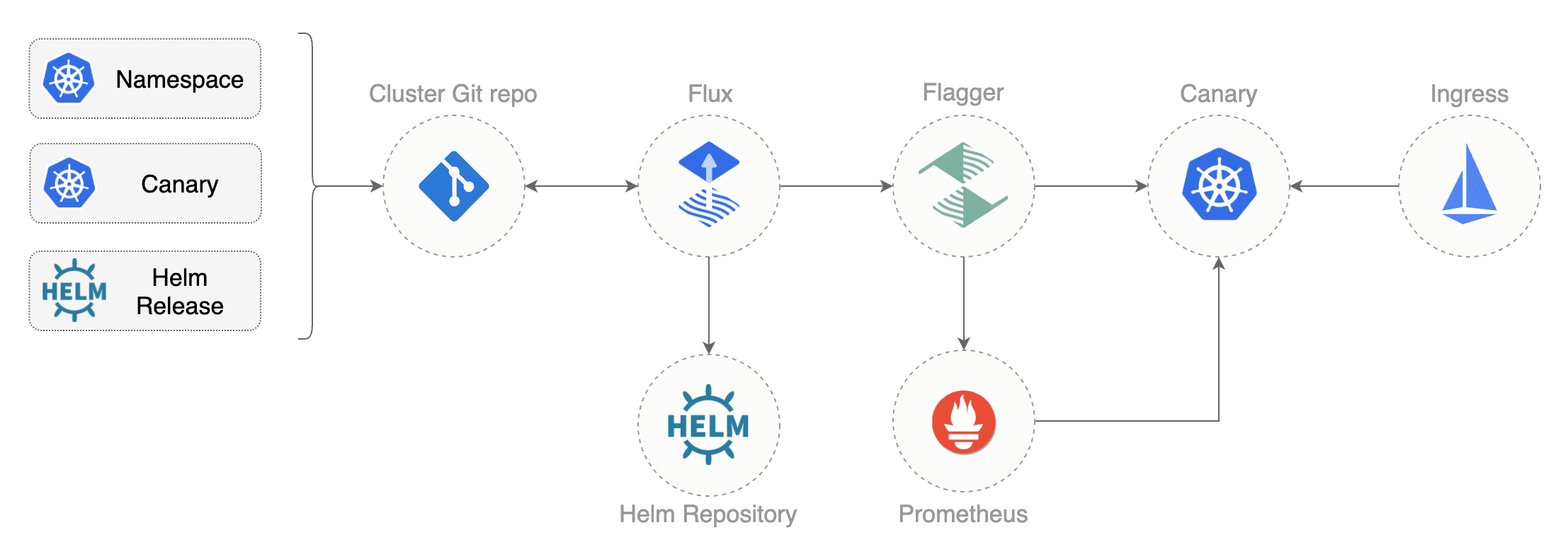
Pull-based Deployments
The Pull-based deployment strategy uses the same concepts as the push-based variant but differs in how the deployment pipeline works. Traditional CI/CD pipelines are triggered by an external event, for example when new code is pushed to an application repository. With the pull-based deployment approach, the operator is introduced. It takes over the role of the pipeline by continuously comparing the desired state in the environment repository with the actual state in the deployed infrastructure. Whenever differences are noticed, the operator updates the infrastructure to match the environment repository. Additionally the image registry can be monitored to find new versions of images to deploy.
Just like the push-based deployment, this variant updates the environment whenever the environment repository changes. However, with the operator, changes can also be noticed in the other direction. Whenever the deployed infrastructure changes in any way not described in the environment repository, these changes are reverted. This ensures that all changes are made traceable in the Git log, by making all direct changes to the cluster impossible.
This change in direction solves the problem of push-based deployments, where the environment is only updated when the environment repository is updated.
Most operators support sending mails or Slack notifications if it can not bring the environment to the desired state for any reason, for example if it can not pull a container image.
Additionally, you probably should set up monitoring for the operator itself, as there is no longer any automated deployment process without it.
The operator should always live in the same environment or cluster as the application to deploy
seen with the push-based approach, where credentials for doing deployments are known by the CI/CD pipeline.
When the actual deploying instance lives inside the very same environment, no credentials need to be known by external services.
The Authorization mechanism of the deployment platform in use can be utilized to restrict the permissions on performing deployments.
When using Kubernetes, RBAC configurations and service accounts can be utilized.
Working with Multiple Applications and Environments
When you are using a microservices architecture, you probably want to keep each service in its own repository.
GitOps can also handle such a use case. You can always just set up multiple build pipelines that update the environment repository. From there on the regular automated GitOps workflow kicks in and deploys all parts of your application.
Managing multiple environments with GitOps can be done by just using separate branches in the environment repository.
You can set up the operator or the deployment pipeline to react to changes on one branch by deploying to the production environment and another to deploy to staging.
FAQ
Is my project ready for GitOps?
All you need to get started is infrastructure that can be managed with declarative Infrastructure as Code tools.
I don’t use Kubernetes. Can I still use GitOps?
In principle, you can use any infrastructure that can be observed and described declaratively, and has Infrastructure as Code tools available
However, currently most operators for pull-based GitOps are implemented with Kubernetes in mind.
Is GitOps just versioned Infrastructure as Code?
Declarative Infrastructure as Code plays a huge role for implementing GitOps,
GitOps takes the whole ecosystem and tooling around Git and applies it to infrastructure.
Continuous Deployment systems guarantee that the currently desired state of the infrastructure is deployed in the production environment.
Apart from that you gain all the benefits of code reviews, pull requests, and comments on changes for your infrastructure.
How to get secrets into the environment without storing them in git?
you have have secrets created within the environment which never leave the environment
For example, you provision a database within the environment and give the secret to the applications interacting with the database only.
Another approach is to add a private key once to the environment (probably by someone from a dedicated ops team) and from that point you can add secrets encrypted by the public key to the environment repository.
How does GitOps Handle DEV to PROD Propagation?
GitOps doesn’t provide a solution to propagating changes from one stage to the next one. We recommend using only a single environment and avoid stage propagation altogether. But if you need multiple stages (e.g., DEV, QA, PROD, etc.) with an environment for each, you need to handle the propagation outside of the GitOps scope, for example by some CI/CD pipeline.
We are already doing DevOps. What’s the difference to GitOps?
GitOps is a technique to implement Continuous Delivery. While DevOps and GitOps share principles like automation and self-serviced infrastructure, these shared principles certainly make it easier to adopt a GitOps workflow when you are already actively employing DevOps techniques.
So, is GitOps basically NoOps?
You can use GitOps to implement NoOps,
If you are using cloud resources anyway, GitOps can be used to automate those.
Typically, however, some part of the infrastructure like the network configuration or the Kubernetes cluster you use isn’t managed by yourself decentrally but rather managed centrally by some operations team.
So operations never really goes away.
Is there also SVNOps?
If you prefer SVN over Git,you may need to put more effort into finding tools that work for you or even write your own.
All available operators only work with Git repository
https://www.gitops.tech/
- ArgoCD: A GitOps operator for Kubernetes with a web interface
- Flux: The GitOps Kubernetes operator by the creators of GitOps — Weaveworks
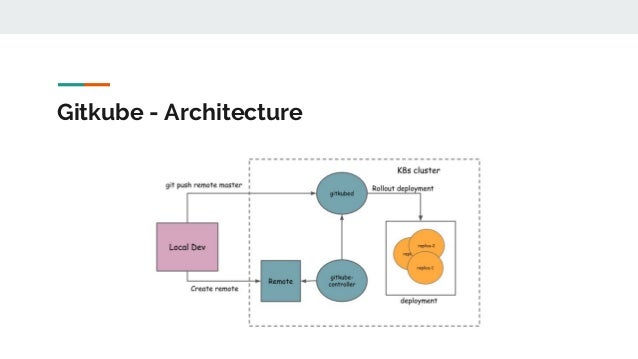
- Gitkube: A tool for building and deploying docker images on Kubernetes using git push
- JenkinsX: Continuous Delivery on Kubernetes with built-in GitOps
- Terragrunt: A wrapper for Terraform for keeping configurations DRY, and managing remote state
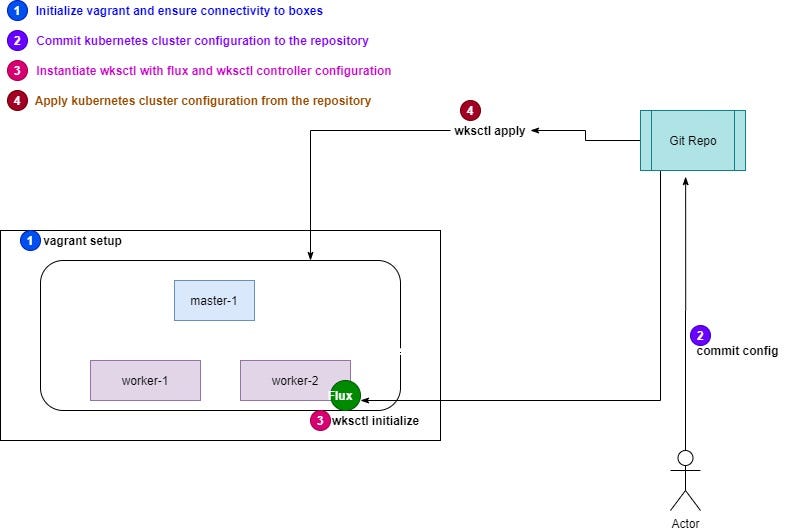
- WKSctl: A tool for Kubernetes cluster configuration management based on GitOps principles
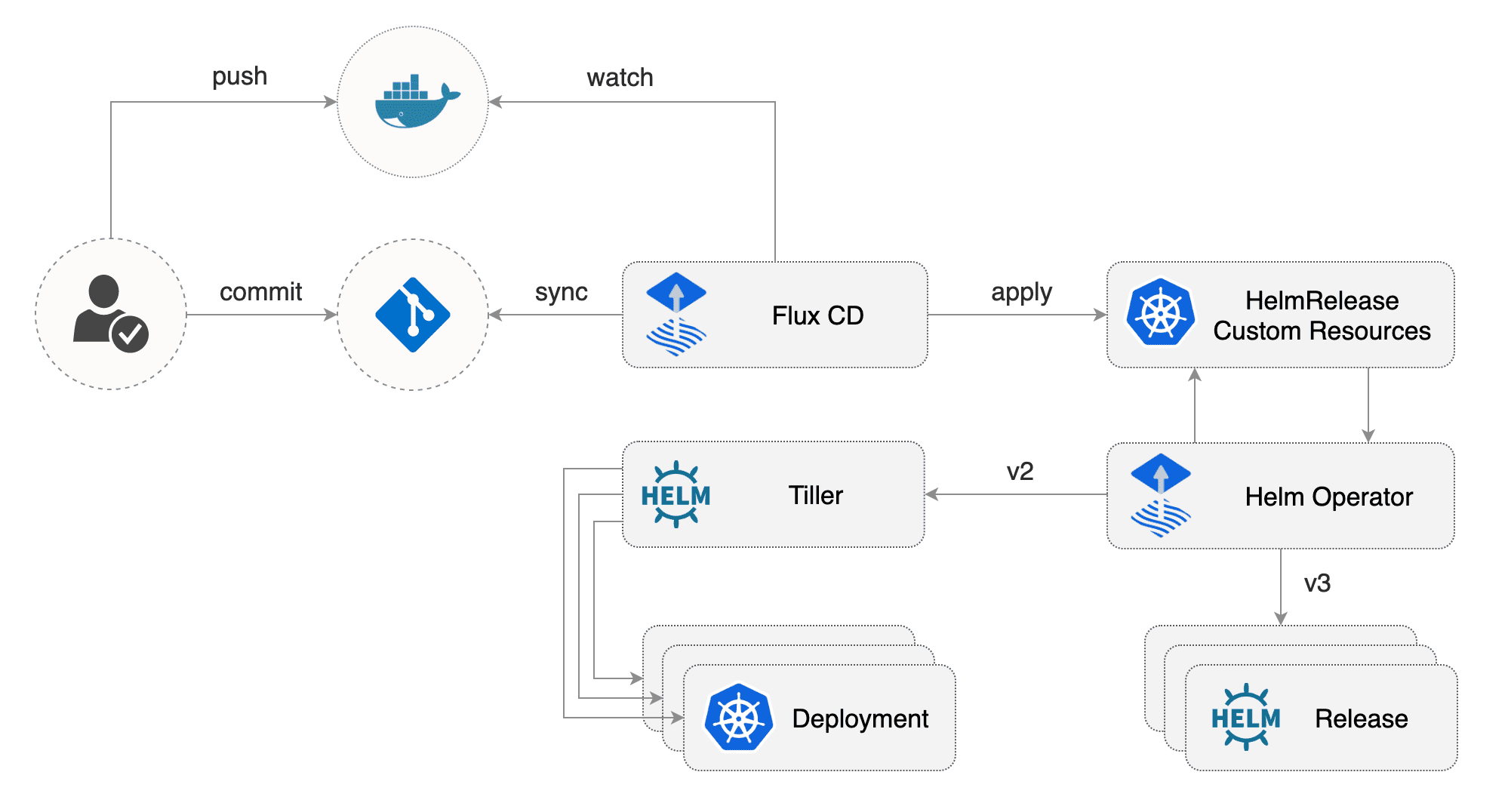
- Helm Operator: An operator for using GitOps on K8s with Helm
- werf: A CLI tool to build images and deploy them to Kubernetes via push-based approach