Docker is designed is properly hardened
https://www.cimcor.com/blog/the-top-5-security-risks-in-docker-container-deployment
- Docker Security ● Docker uses several mechanisms for security:
It was initially developed by the US National Security Agency
- ○ Linux kernel namespaces
- ○ Linux Control Groups (cgroups)
- ○ The Docker daemon
- ○ Linux capabilities (libcap)
- ○ Linux security mechanisms like AppArmor or SELinux
- Docker Security ● Namespaces:
- provides an isolated view of the system where processes cannot see other processes in other containers ● Each container also gets its own network stack. ● A container doesn’t get privileged access to the sockets or interfaces of another container.
- Docker Security ● Cgroups: kernel feature that limits and isolates the resource usage(CPU,memory,network) of a collection of processes.
- Docker Security ● Linux Capabilities: divides the privileges of root into distinct units and smaller groups of privileges.
- Images are extracted in a chrooted sub process, being the first-step in a wider effort toward privilege separation. ● From Docker 1.10, all images are stored and accessed by the cryptographic checksums of their contents, limiting the possibility of an attacker causing a collision with an existing image Docker Content Trust.
- Docker Content Trust ● Protects against untrusted images ● Can enable signing checks on every managed host ● Signature verification transparent to users ● Guarantee integrity of your images when pulled ● Provides trust from publisher to consumer ● export DOCKER_CONTENT_TRUST=1 ● ~/.docker/trust/trusted-certificates/
- Security Best Practices
- 14. DockerFile Security ●
- ● Do not write secrets(users and passwords).
- ● Remove unnecessary setuid, setgid permissions (Privilege escalation)
- ● Download packages securely using GPG and certificates
- ● Try to restrict an image or container to one service
- Security best practices ● To disable setuid rights, add the following to the Dockerfile of your image
- RUN find / -perm +6000 -type f -exec chmod a-s {} \;\||true
- Security best practices
- ● Don’t run containers with --privileged flag
- ● The --privileged flag gives all capabilities to the container.
- ● docker run --privileged ...
- ● docker run --cap-drop=ALL --cap-add=CAP_NET_ADMIN
- How do we add/remove capabilities?
- ● Use cap-add and cap-drop with docker run/create
- ● Drop all capabilities which are not required
- ● docker run --cap-drop ALL --cap-add $CAP
- Security best practices capabilities
- ● Manual management within the container: docker run --cap-add ALL
- ● Restricted capabilities with root: docker run --cap-drop ALL --cap-add $CAP
- ● No capabilities: docker run --user
- Security best practices ● Set a specific user. ● Don’t run your applications as root in containers.
- https://docs.docker.com/engine/security/security/
To understand DAC, let's first consider how traditional Linux file security works.
In a traditional security model, we have three entities: User, Group, and Other (
-
Now jo can change this access.
Consider another case: when a Linux process runs, it may run as the root user or another account with
With
At any one time,
Enforcing
Permissive
Disabled
In enforcing mode
Permissive mode is like a semi-enabled state.
The disabled mode is self-explanatory
https://www.digitalocean.com/community/tutorials/an-introduction-to-selinux-on-centos-7-part-1-basic-concepts
You’ll need to AppArmor
You should design a test plan that goes through the functions the program needs to perform
https://www.howtogeek.com/118328/how-to-create-apparmor-profiles-to-lock-down-programs-on-ubuntu/
The state of each profile can be switched aa aa parameter
Even though creating an AppArmor profile is rather easy, most programs do not have one. This section will show you how to create a new profile from scratch just by using the target program and letting AppArmor monitor the system call it makes and the resources it accesses.
The most important programs that need to
https://debian-handbook.info/browse/stable/sect.apparmor.html
SELinux
https://debian-handbook.info/browse/stable/sect.selinux.html
AppArmor As such it in the first place
Security policies completely define what system resources individual applications can access, and with what privileges.
Access
Every breach of policy triggers a message in the system log, and
https://wiki.archlinux.org/index.php/AppArmor
- Enforce
– enforce begins enforcing syslog auditd auditd operation will not be permitted
The following are the different
Path entries: This has information on which
Capability entries: determines the privileges
Network entries: determines the connection-type. For example: tcp. For a packet-analyzer network can be raw or packet
https://www.thegeekstuff.com/2014/03/apparmor-ubuntu
- The docker-default profile is the default for running containers. It is moderately protective while providing wide application compatibility.
The profile is generated
only users should be allowed that you can start a container where the /host directory is the / directory on your host; and the container can alter your host filesystemwithout any similar to
for example, if you instrument Docker from a web server to provision containers through an API, you should be even more careful than usual with parameter checking, to make sure that a malicious user cannot pass crafted parameters causing Docker to create arbitrary containers.
You can also expose the REST API over HTTP if you explicitly
The daemon is also potentially vulnerable to other inputs, such as image loading from either disk with
https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
- Isolate containers with a user
namespace
The best way to prevent privilege-escalation attacks from within a container is to configure your container’s applications to run as unprivileged users
For containers whose processes must run as the root user within the container, you can re-map this user to a less-privileged user on the Docker host.
The remapping
It is very important that the ranges not overlap, so that a process cannot gain access in a different
https://docs.docker.com/engine/security/userns-remap
- Secure computing mode (
seccomp seccomp ( seccomp
The default
In effect, the profile is a whitelist which denies access to system calls by default, then whitelists specific system calls.
https://docs.docker.com/engine/security/seccomp
- Kernel exploits
the host, magnifying the importance of any vulnerabilities
better: an attacker would have to route an attack through both
the VM kernel and the
host kernel.
Denial-of-service attacks
All containers share kernel resources. If one container can
monopolize access to certain resources—including memory and
more esoteric resources such as user IDs (UIDs)—it can starve
out other containers on the host, resulting in a denial-of-service
(DoS), whereby legitimate users
of the system.
Container breakouts
An attacker who gains access to a container should not be able
are not
user, often through a bug in application code that needs to run with extra privileges.
Poisoned images
If an attacker can trick you into running his image, both the host and your data are at risk
Compromising secrets
When a container accesses a database or service, it will
small numbers of long-lived VMs.
do not consider containers to offer the same level of security guarantees as VMs.
The defenses for your system should also
capabilities of containers:
Ensure that processes in containers do not run as root, so that exploiting a vulnerability present in a process does not give the
attacker root access.
Run filesystems as read-only so that attackers cannot overwrite data or save malicious scripts to file
Cut down on the kernel calls that a container can make to reduce the potential attack surface
Limit the resources that a container can use to avoid DoS attacks whereby a compromised container or application consumes enough resources (such as memory or CPU) to bring the
host to a halt.
Similarly, if you have containers that process or store sensitive information, keep them on a
containers processing credit-card details should
security of VMs.
Applying Updates
Identify images that require updating.
For each dependent image, run docker build with the
On each Docker host, run docker pull to ensure that it has up-to-date images
Once you’ve
remove them from your registry.
If you use Docker Hub to build your images, note
In the past,
access to the
To safely use images, you need to have guarantees about their provenance: where they came from and who created them.
What’
metadata file describing the constituent parts of a Docker image.
This is Docker’s mechanism for allowing
When a user pulls an image from a repository, she receives a certificate that includes the publisher’s public
key, allowing her to verify that the image came from the publisher.
When content trust
whose signatures or digests do not match.
By running both a registry and a
Notary server, organizations can provide trusted images to users.
https://theswissbay.ch/pdf/_to_sort/O%27Reilly/docker-security.pdf
- The Update Framework (TUF) helps developers maintain the security of a software update system, even against attackers that compromise the repository or signing keys. TUF provides a flexible framework and specification that developers can adopt into any software update system.
https://github.com/theupdateframework/tuf
- Notary aims to make the internet more secure by making it easy for people to publish and verify content. We often rely on TLS to secure our communications with a web server, which is inherently flawed, as any compromise of the server enables malicious content to
be substituted
https://github.com/theupdateframework/notary
- This document describes basic use of the Notary CLI as a tool supporting Docker Content Trust. For more advanced use cases, you must run your own Notary service. Read the use the Notary client for advanced users documentation.
What is Notary
Notary is a tool for publishing and managing trusted collections of content. Publishers can digitally sign collections and consumers can verify integrity and origin of content.
With Notary anyone can provide
https://docs.docker.com/notary/getting_started/
- Use Case Examples of Notary:
Docker uses Notary to implement Docker Content Trust and
Quay is using Notary as a library, wrapping it and extending it to suit their needs. For Quay, Notary is flexible rather than single-purpose.
CloudFlare’s PAL tool uses Notary for container identity, allowing one to associate metadata such as secrets to running containers
https://www.cncf.io/announcement/2017/10/24/cncf-host-two-security-projects-notary-tuf-specification/
- The Docker Bench for Security is a script that checks for dozens of common best-practices around deploying Docker containers in production. The tests are all
automated, are inspired
https://github.com/docker/docker-bench-security
- Clair is an open source project for the static analysis of vulnerabilities in
appc docker
https://coreos.com/clair/docs/latest/
- A service that analyzes docker images and applies user-defined acceptance policies to allow automated container image validation and certification. The Anchore Engine is an open source project that provides a centralized service for inspection, analysis, and certification of container images. The Anchore engine
is provided be run is provided Kubernetes
- a tool to perform static analysis of known vulnerabilities,
trojans , viruses, malware & other malicious threats in docker images/containers and to monitor the docker daemon and runningdocker
https://github.com/eliasgranderubio/dagda
- An open artifact metadata API to audit and govern your software supply chain
Developers can use
https://grafeas.io/
- Falco is a behavioral activity monitor designed to detect anomalous activity in your applications. Powered by
sysdig
Falco
https://github.com/falcosecurity/falco
- Build rules specific to your
Kubernetes microservices
Runtime Security built for containers.
https://sysdig.com/opensource/falco
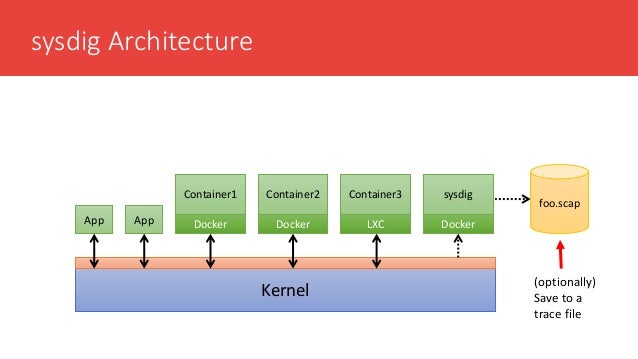
Banyan Collector: A framework to peek inside containers
A framework for Static Analysis of Docker container images
Have you wondered what your container images really contain? If they have the
https://github.com/banyanops/collector
- Scan Docker installations for security issues and vulnerabilities.
plugin based system for discovery, audit and reporting
able to scan local and remote docker installations
plugins are easy to write
https://github.com/kost/dockscan
- hub-detect-
ws iScan
https://github.com/blackducksoftware/hub-detect-ws
- batten is an auditing framework that contains some tools to help audit and harden your Docker deployments.
Identify potential security
https://github.com/dockersecuritytools/batten
InSpec
https://github.com/inspec/inspec
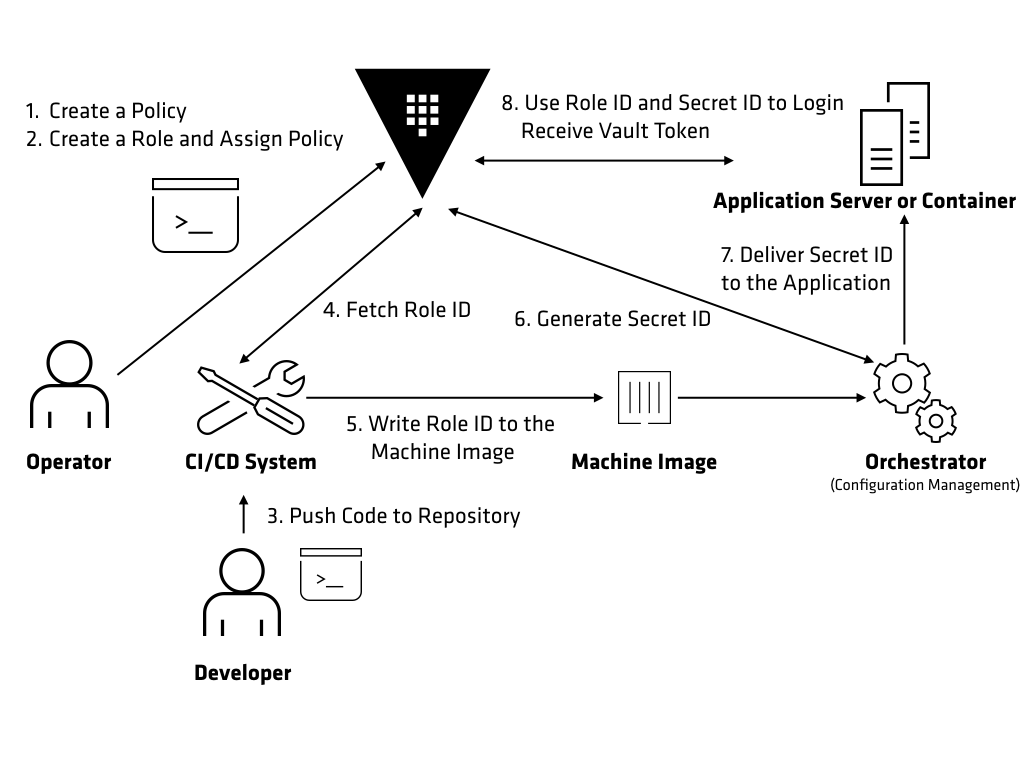
- In a containerized deployment, how do you safely pass secrets—passwords, certificates, etc.—between containers in a cluster without compromising their safety? HashiCorp Vault
to securely manage
- HashiCorp Vault and Terraform on Google Cloud — Security Best Practices
Vault is not always an ideal solution for secrets management. If only
Vault Security Best Practices
Isolate the installation with
Use a bastion host for Admin Access. Vault must be accessible by humans via API, but never by SSH or RDP
Restrict storage access. Vault encrypts all data at rest, regardless of which storage backend you use
https://medium.com/@jryancanty/hashicorp-vault-and-terraform-on-google-cloud-security-best-practices-3d94de86a3e9
- Security Model
The overall goal of Vault's security model is to provide confidentiality, integrity, availability, accountability, authentication.
This means that data at rest and in transit must be secure from eavesdropping or tampering.
Threat Model
Eavesdropping
Client communication with Vault should be secure from eavesdropping
Tampering with data at rest or in transit.
Any tampering should be detectable
Access to data or controls without authentication or authorization
Access to data or controls without accountability.
If audit logging
Confidentiality of stored secrets.
Availability of secret material in the face of failure.
running in a highly available configuration to avoid loss of availability.
The following are not parts of the Vault threat model
Protecting against arbitrary control of the storage backend.
As an example, an attacker could delete or corrupt all the contents of the storage backend causing total data loss for Vault. The ability to control reads would allow an attacker to snapshot in a well-known state and rollback state changes if that would be beneficial to them.
Protecting against the leakage of the existence of secret material. An attacker that can read from the storage backend may observe that secret material exists and
Protecting against memory analysis of a running Vault. If an attacker
External Threat Overview
there are 3 distinct systems
the
Vault or the server more accurately, which is providing an API and serving requests.
the storage backend, which the server is
There is no mutual trust between the Vault client and server.
Clients use TLS to verify the identity of the server and to establish a secure communication channel.
Servers require that a client provides a client token for every request which is used to identify the client.
The storage
Vault uses a security barrier for all requests made to the backend.
The security barrier automatically encrypts all data leaving Vault using a 256-bit Advanced Encryption Standard (AES) cipher in the Galois Counter Mode (GCM) with 96-bit nonces.
When data
Internal Threat Overview
Within the Vault system, a critical security concern is an attacker attempting to gain access to secret material
For example, GitHub users in the "engineering" team may
Vault then generates a client token which is a randomly generated, serialized value and maps it to the policy list.
On each request a client provides this token.
Vault then uses it to check that the token is valid and has not
Vault uses a strict default deny or whitelist enforcement.
Each policy specifies a level of access granted to a path in Vault.
Although clients could
As part of a policy,
When Vault
This means that the encryption key needed to read and write from the storage backend
The risk of distributing the master key is that a single malicious actor with access to it can decrypt the entire Vault.
Instead, Shamir's technique allows us to split the master key into multiple shares or parts.
The number of shares and the threshold needed is configurable, but by default Vault generates 5 shares, any 3 of which must
By using a secret sharing technique, we avoid the need to place absolute trust in the
The master key is only retrievable by reconstructing the shares.
The shares are not useful for making any requests to Vault, and can only
Once unsealed
Opening the bank vault requires two-factors: the key and the combination.
Similarly, Vault requires multiple shares
Once unsealed, each security deposit boxes still requires the owner provide a key, and similarly the Vault ACL system protects all the secrets stored.
https://www.vaultproject.io/docs/internals/security.html
- Two-man rule
The two-man rule is a control mechanism designed to achieve a high level of security for especially critical material or operations. Under this rule all access and actions require
No-lone zone
A no-lone zone is an area that must
https://en.wikipedia.org/wiki/Two-man_rule
- Shamir's Secret Sharing
Shamir's Secret Sharing is an algorithm in cryptography created by Adi Shamir. It is
To reconstruct the original secret,
https://en.wikipedia.org/wiki/Shamir's_Secret_Sharing
- How our security team handle secrets
We were distributing our secrets using
It gives the secrets to applications running on our servers as a file.
At Monzo, only a handful of engineers have access to Vault, and they tightly control who else can use it.
These were
1. Having two mechanisms created confusion, but neither one was perfect
2. The way we were using
The secrets were readable to anyone with access to our
Creating secrets and adding them to your service requires messing around with
Reading them into your service is a little fiddly, and we were lacking libraries to standardise it.
3. The way we were using Vault also had issues
It was impossible to configure or even inspect without a key ceremony (where a few engineers who have access to Vault get together and configure it). A key ceremony takes about three hours of work.
We didn't have any ways to configure Vault using code, so
To let a service read from Vault, you'd have to generate a secret key for that service, which we'd then manually store as Kubernetes secret. Every time you create a Vault secret for a new service, you also have to create a Kubernetes secret
To address these issues
1. Secrets
2. It's impossible to read all the secrets at once, but easy to let services read specific secrets
3. It's easy to add brand new secrets, and hard to overwrite existing ones.
5. It's auditable.
6. It's inspectable.
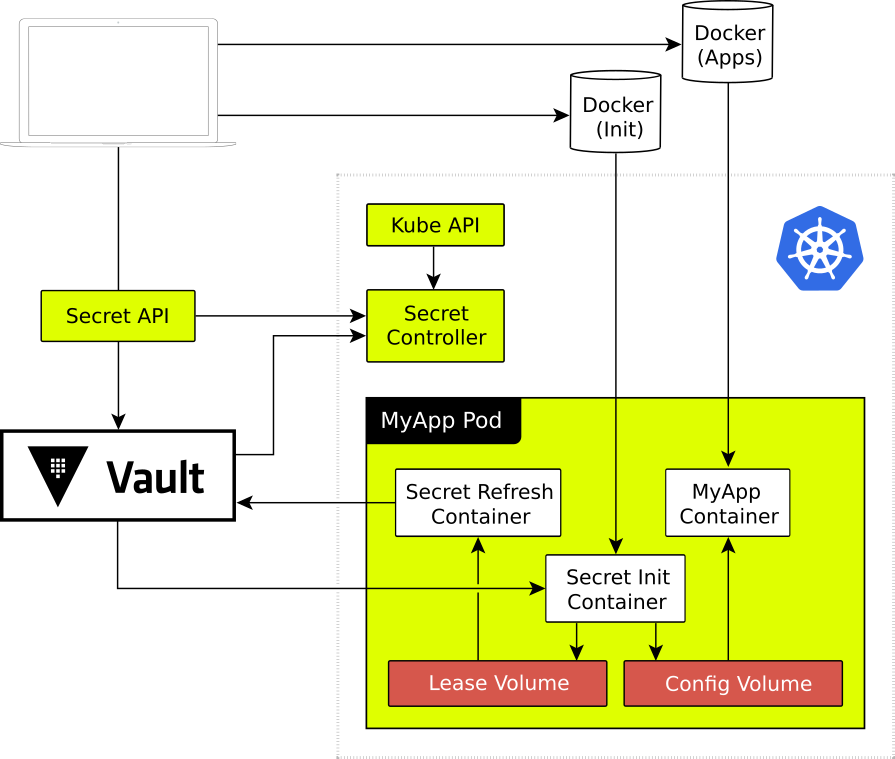
Authenticating to Vault
To make sure we can access secret information securely, but without having to create new secrets that add unnecessary complexity, we
This lets Kubernetes applications present their service account token (like a password, attached by default to all applications in Kubernetes) to Vault. Vault will then issue its own token with permissions that
In our case, we
We called this policy
Service account tokens are
This means they're still not as secure as we'd like, because they're stored
But, given that the Kubernetes secret is just a token which allows access to Vault, this reduces how dangerous it is to access Kubernetes secrets; you'd now need to talk to Vault
We also decided that we could improve the security of Kubernetes secrets by encrypting them at rest using an experimental Kubernetes feature. We generated an AES key (a very strong key for encrypting data fast), stored inside Vault, which we
We wanted to avoid
Human interactions with Vault
We have an internal authentication mechanism which allow staff members to prove their identity, and perform various actions,
We soon intend to do this via a custom Vault auth plugin, which is a little safer and easier to work with, but to save time during this project, we instead used a web service in front of Vault which intercepts its requests.
Computer interactions with Vault
We designed the default
Libraries
We wrote some new library code to make it super easy for engineers to read secrets into their services. Our tooling encourages engineers to only have one key in their Vault secrets (which are actually each a key-value store), named data.
We'd like to get Vault to issue short lived credentials for our services which further restrict their access to Cassandra, our database, so we have more guarantees that an attacker couldn't write to the database.
It would also be great to issue AWS credentials out of
https://monzo.com/blog/2019/10/11/how-our-security-team-handle-secrets?source=hashibits&utm_source=hc-newsletter&utm_medium=email&utm_campaign=november2019newsletter&utm_section=community&mkt_tok=eyJpIjoiTURCbVpqRTJOVEUzWVRabSIsInQiOiJSK1E3T0JcL2RzSUZ0R296alBXMjIzdHVUa0lnb1pTMXB1a1RNelVPME41a1wvKzVlbU16cUcyQWNIeWV5bWtcLzRcL0FQMDFcLzhuQWFCM005WmxcL2pFZFFzWkNiR0RpTkRZOVA1dDFmR2N6QUd1aGE1U0VHdTdMckd5OVBFQVZTbkdwNCJ9
- use HashiCorp Consul for service discovery, service registration, and service mesh for Kubernetes and non-Kubernetes environments.
At
Consul supports both standalone Kubernetes and managed Kubernetes (Microsoft AKS, AWS EKS, Google Cloud GKE, and
This makes it easier for organizations to
Upon installation,
Through integrations with popular network middleware solutions like F5 BIG-IP and
Envoy Proxy and Ambassador API Gateway
Proxies are very beneficial to managing
https://www.hashicorp.com/blog/exploring-the-hashicorp-consul-ecosystem-for-kubernetes/?
- Production Hardening
best practices for a production hardened deployment of Vault.
Recommendations
End-to-End TLS.
If intermediate load balancers or reverse proxies are used to front Vault, they should not
Single Tenancy.
Vault should be the only main process running on a machine.
This reduces the risk that another process running on the same machine
Similarly, running on bare metal should
This reduces the surface area introduced by additional layers of abstraction and other tenants of the hardware.
Firewall traffic.
Vault listens on
Disable SSH / Remote Desktop.
When running a Vault as a single tenant application, users should never access the machine directly. Instead, they should access Vault through its API over the network.
Disable Swap.
Vault encrypts data in transit and at rest, however it must still have sensitive data in memory to function.
Vault attempts to "memory lock" to physical memory automatically, but disabling swap adds another layer of defense.
Don't Run as Root.
Turn Off Core Dumps.
A user or administrator that can force a core dump and has access to the resulting file
Immutable Upgrades.
Avoid Root Tokens.
Vault provides a root token when it is first initialized.
We recommend treating Vault configuration as
Once setup, the root token should
Root tokens can
Enable Auditing.
Enabling auditing provides a history of all operations performed by Vault and provides a forensics trail
Audit logs securely
Upgrade Frequently.
Configure SELinux / AppArmor
Using additional mechanisms like
Restrict Storage Access
Vault encrypts all data at rest, regardless of
Although the data
Disable Shell Command History.
vault command itself to not appear in history at all.
Tweak
Consider
Docker Containers.
To leverage the "memory lock" feature inside the Vault container you will
https://www.vaultproject.io/guides/operations/production
- HashiCorp Vault secures, stores, and tightly controls access to tokens, passwords, certificates, API keys, and other secrets in modern computing. Vault handles leasing, key revocation, key rolling, and auditing. Through a unified API, users can access an encrypted Key/Value store and network encryption-as-a-service, or generate AWS IAM/STS credentials, SQL/
NoSQL
https://www.vaultproject.io/

- Security Best Practices for Building Docker Images
Installation of external software components
Copying files
When adding files into the image,
To ensure proper usage of the cache, separate COPY statements (opposed to package installation activities). This helps in performance, by invalidating just some parts of the cache.
Downloading files
Use
To limit the size of an image, the usage of
Disk, Directories and Mounts
The Docker build file allows defining storage areas for your application with the help of the VOLUME statement
Working directory
Instead of using the combination of “cd /data &&
Running Processes
CMD [
Environment settings
ENV PATH /
Active User
With the USER statement,
Auditing tool for Docker
https://linux-audit.com/security-best-practices-for-building-docker-images/
- Open-AudIT is an application to tell you exactly what is on your network, how it
is configured be queried Data about the network is inserted VBScript The entire application is written php vbscript
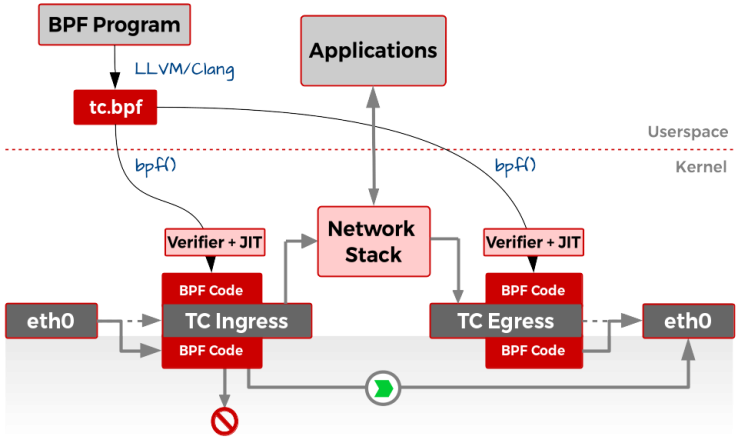
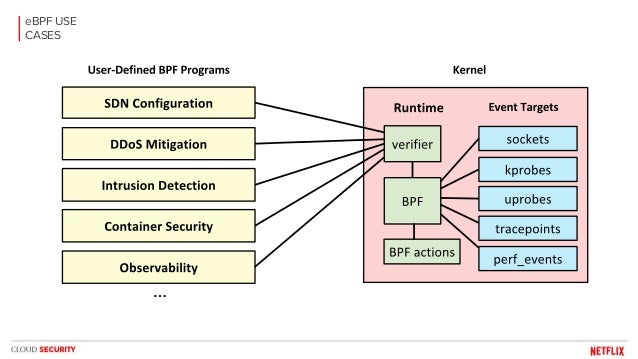
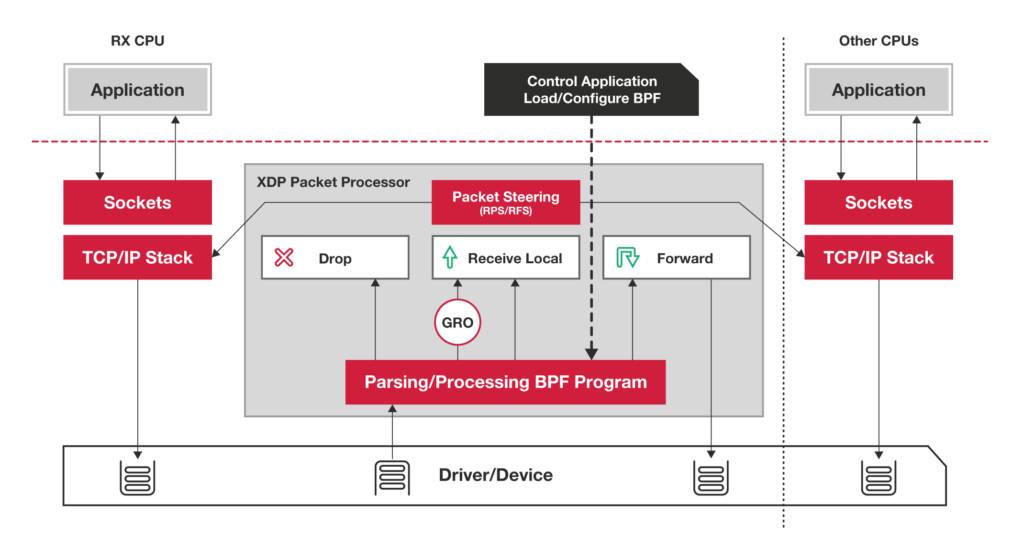
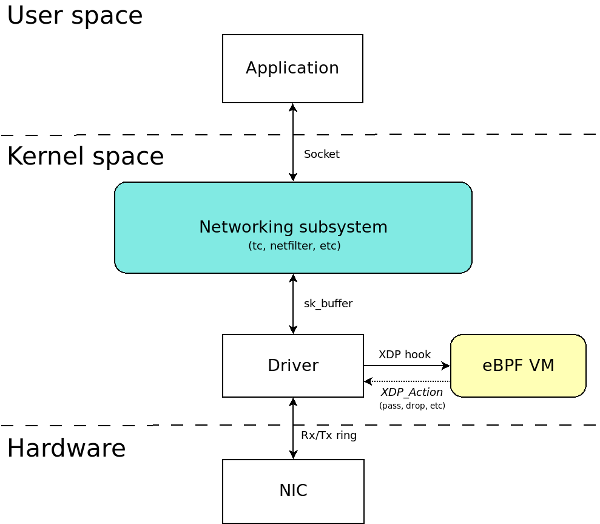
- purely in-kernel solutions for some packet-processing intensive workloads still lag
behind
the kernel community never sleeps (almost literally) and the holy grail of kernel-based networking performance has
This technology allows you to implement new networking features (and/or re-implement existing ones) via custom extended BPF (
XDP
XDP allows you to attach an
Such a hook
XDP is not a programming language,
https://developers.redhat.com/blog/2018/12/06/achieving-high-performance-low-latency-networking-with-xdp-part-1/




- Docker Trusted Registry
You install it behind your firewall so that
Image management
DTR can be installed
You can use DTR as part of your continuous integration, and continuous delivery processes to build, ship, and run your applications.
It even allows you to see what dockerfile were used to produce the image and, if security scanning is enabled all of the
Security scanning
DTR has a built in security scanner that can be used to are used Most importantly, it is kept
Image signing
DTR ships with Notary built in so that
https://docs.docker.com/v17.12/datacenter/dtr/2.4/guides/
- 10 Docker Image Security Best Practices
1. Prefer minimal base images
By preferring minimal images that bundle only the necessary
2. Least privileged user
When a Dockerfile a USER . namespace is then mapped
To minimize exposure, opt-in to create a dedicated user and a dedicated group in the Docker image for the application; use the USER directive in the Dockerfile
A specific user might not exist in the image; create that user using the instructions in the Dockerfile
3. Sign and verify images to mitigate MITM attacks
Verify docker images
Make it a best practice that you always verify images before pulling them in, regardless of policy
To experiment with verification, temporarily enable Docker Content Trust with the following command
export DOCKER_CONTENT_TRUST=1
Now attempt to pull an image that is not signed is denied and the image is not pulled
Sign docker images
To sign images, use Docker Notary. Notary verifies the image signature for you, and blocks you from running an image if the signature of the image is invalid.
When Docker Content Trust is enabled
When the image is signed This private key is then used to sign any additional images as they are built
4. Find, fix and monitor for open source vulnerabilities
5. Don’t leak sensitive information to Docker images
Using multi-stage builds
By leveraging Docker support for multi-stage builds, fetch and manage secrets in an intermediate image layer that is later disposed
Use code to add secrets to said
Using Docker secret commands
Use an alpha feature in Docker for managing secrets to mount sensitive files without caching them
Beware of recursive copy
the following command copies the entire build context folder, recursively, to the Docker image, which could end up copying sensitive files as wel
If you have sensitive files in your folder, either remove them or use . dockerignore
6. Use fixed tags for immutability
The most common tag is latest, which represents the latest version of the image. Image tags are not immutable, and the author of the images can publish the same tag multiple times
Instead of pulling a tag, pull an image using the specific SHA256 reference of the Docker image, which guarantees you get the same image for every pull. However notice that using a SHA256 reference can be risky, if the image changes that hash might not exist anymore
7. Use COPY instead of ADD
Space and image layer considerations
using COPY allows separating the addition of an archive from remote locations and unpacking it as different layers, which optimizes the image cache.
If remote files are needed , combining all of them into one RUN command that downloads, extracts, and cleans-up afterwards optimizes a single layer operation over several layers that would be required if ADD were used .
zip bombs and Zip Slip vulnerabilities
When local archives are used , ADD automatically extracts them to the destination directory. While this may be acceptable, it adds the risk of zip bombs and Zip Slip vulnerabilities that could then be triggered automatically.
When using COPY the source for the files to be downloaded from remote URLs should be declared over a secure TLS connection and their origins need to be validated as well .
8. Use metadata labels
The most common label is “ maintainer”, which specifies the email address and the name of the person maintaining this image.
This metadata could contain: a commit hash, a link to the relevant build, quality status (did all tests pass?), source code, a reference to your SECURITY. TXT file location
It is good practice to adopt a SECURITY. TXT (RFC5785) file that points to your responsible disclosure policy for your Docker label schema when adding labels
9. Use multi-stage build for small and secure images
This is a good reason why Docker has the multi-stage build capability. This feature allows you to use multiple temporary images in the build process, keeping only the latest image along with the information you copied into it.
First image—a very big image size, bundled with many dependencies that are used in order to build your app and run tests.
Second image—a very thin image in terms of size and number of libraries, with only a copy of the artifacts required to run the app in production.
10. Use a linter
Adopt the use of a linter to avoid common mistakes and establish best practice guidelines that engineers can follow in an automated way.
https://snyk.io/blog/10-docker-image-security-best-practices/
- Docker Bench for Security
The Docker Bench for Security is a script that checks for dozens of common best-practices around deploying Docker containers in production. The tests are all automated, and are inspired by the CIS Docker Community Edition Benchmark v1.1.0.
https://github.com/docker/docker-bench-security
- Docker Security Best Practices
1. Image Authenticity
Use Private or Trusted Repositories
Docker Cloud and Docker Hub can scan images in private repositories to verify that they are free from known security vulnerabilities or exposures, and report the results of the scan for each image tag.
Use Docker Content Trust
This is a new feature introduced in Docker Engine 1.8, which allows you to verify Docker image publishers.
the service protects against image forgery, replay attacks, and key compromises.
2. Excess Privileges
Drop Unnecessary Privileges and Capabilities
The best practice for users would be to remove all capabilities except those explicitly required for their processes.
3. System Security
make use of other Linux security options, such as AppArmor , SELinux , grsecurity and Seccomp.
a Linux kernel security module that allows the system administrator to restrict programs’ capabilities with per-program profiles.
Profiles can allow capabilities like network access, raw socket access, and the permission to read, write, or execute files on matching paths.
Security-Enhanced Linux (SELinux ) is a Linux kernel security module that provides a mechanism for supporting access control security policies, including…( MAC)
A set of patches for the Linux kernel which emphasize security enhancements.
a computer security facility in the Linux kernel.
Should it attempt any other system calls, the kernel will terminate the process with SIGKILL.
4. Limit Available Resource Consumption
-m / -- memory: Set a memory limit
https://blog.sqreen.com/docker-security/
- Docker containers are a wrapper around Linux control groups (
cgroups ) andnamespaces .
For example, the PID namespace restricts which processes can be seen within a container.
Securing the host OS
One can also develop custom security modules using Linux Security Modules (LSMs).
Type enforcement revolves around defining a type and assigning privileges to those types
Users can specify a file path to a binary and the permissions they have
Seccomp
Seccomp (short for ‘Secure Computing’) is another security module included in many Linux distributions that allows users to restrict system calls.
Seccomp can be used to sandbox applications that handle untrusted user inputs to a subset of system calls.
The first step in using seccomp is to determine all the system calls an application makes when it runs. This can be a difficult and error-prone exercise that should be conducted when the application is written .
Users can use tools like audit to profile all the system calls that it makes by exercising it in different ways.
The drawback with seccomp is that the profile has to be applied during the launch of the application. The granularity of restricting system calls is too narrow and requires extensive working knowledge of Linux to come up with good profiles.
Capabilities
Linux capabilities are groups of permissions that can be given to child processes.
Container Runtime Security Practices
Unix socket (/var/run/docker. sock )
By default, the Docker client communicates with the Docker daemon using the unix socket.
Once mounted, it is very easy to spin up any container, create new images, or shut down existing containers.
Solution:
Set up appropriate SELinux /AppArmor profiles to limit containers mounting this socket
Volume mounts
Docker allows mounting to sensitive host directories. Also, the contents of the host file system can be changed directly from the container. For application containers with direct Internet exposure, it is important to be extra careful when mounting sensitive host directories (/etc/, /usr /)
Solution:
Mount host-sensitive directories as read-only.
Privileged containers
Privileged containers can do almost anything a host can do
Solution:
Use capabilities to grant fine-grained privileges instead
SSH within container
Running ssh service within containers makes managing ssh keys/ access policies difficult
Solution:
Do not run ssh services inside a container.
Instead, run ssh on the host and use `docker exec` or `docker attach` to interact with the container.
Binding privileged ports
By default, Docker allows binding privileged ports (<1024) to a container.
Solution:
List all containers and their port mappings using the code below to ensure that the container's ports are not mapped to host ports below port 1024.
Exposing ports
Ensure that there are no unnecessary ports exposed
Running without default AppArmor / SELinux or seccomp
Docker runs containers with default AppArmor /SELinux and seccomp profiles. They can be disabled with the -- unconfined option
Solution:
Do not disable the default profiles that Docker supplies.
Sharing host namespaces
These allow containers to see and kill PIDs running on the host or even connect to privileged ports
Solution:
Avoid sharing host namespaces with containers
Enabling TLS
If the Docker daemon is running on a TCP endpoint, it is advised to run with TLS enabled
Do not set mount propagation mode to shared
Mount propagation mode allows mounting volumes in shared, slave or private mode on a container
Mounting a volume in shared mode does not restrict any other container to mount and make changes to that volume.
Solution:
Run the following command to list the propagation mode for mounted volumes:
`docker ps -- quiet -- all | xargs docker inspect -- format '{{ . Id }}: Propagation={{range $mnt : = . Mounts}} {{json $mnt . Propagation}} {{end}}'`
Restrict a container from acquiring new privileges
A process can set the no_new_priv bit in the kernel
The no_new_priv bit ensures that the process or its children processes do not gain any additional privileges via setuid or sgid bits.
Solution:
List the security options for all the containers using the following command:
`docker ps -- quiet -- all | xargs docker inspect -- format '{{ . Id }}: SecurityOpt ={{. HostConfig . SecurityOpt }}'`
One can start a container with `no_new_privileges ` as below:
`docker run-- security-opt=no -new-privileges`
https://www.stackrox.com/post/2017/08/hardening-docker-containers-and-hosts-against-vulnerabilities-a-security-toolkit/
- Linux Security Modules (LSM) is a framework that allows the Linux kernel to support a variety of computer security models while avoiding favoritism toward any single security implementation.
since Linux 2.6. AppArmor , SELinux , Smack, and TOMOYO Linux are the currently accepted modules in the official kernel.
TOMOYO Linux is a Mandatory Access Control (MAC) implementation for Linux that can be used to increase the security of a system, while also being useful purely as a system analysis tool.
TOMOYO Linux allows each process to declare behaviours and resources needed to achieve their purpose. When protection is enabled , TOMOYO Linux acts like an operation watchdog, restricting each process to only the behaviours and resources allowed by the administrator.
The main features of TOMOYO Linux include:
System analysis
Increased security through Mandatory Access Control
Tools to aid in policy generation
Simple syntax
Easy to use
Requires no modification of existing binaries
http://tomoyo.osdn.jp/
- The most complete implementation of a Smack based system is
Tizen .
The Automotive Grade Linux project uses Smack. This uses the Yocto Project build tools.
Smack (full name: Simplified Mandatory Access Control Kernel) is a Linux kernel security module that protects data and process interaction from malicious manipulation using a set of custom mandatory access control (MAC) rules, with simplicity as its main design goal
http://schaufler-ca.com/
- Protect the Docker daemon socket
By default, Docker runs via a non-networked Unix socket.
It can also optionally communicate using an HTTP socket.
If you need Docker to be reachable via the network
In the daemon mode, it only allows connections from clients authenticated by a certificate signed by that CA. In the client mode, it only connects to servers with a certificate signed by that CA
https://docs.docker.com/v17.12/engine/security/https/
Cgroups andNamespaces
This feature also allows for better accounting of the usage, such as when teams need to report the usage for billing
The
It is also a good security feature because processes running in containers can not easily consume all the resources on a system - for example, a denial of service attack by starving other processes of required resources
Container processes can only see processes running in the same
In a lot of ways, this can make a container process seem like it is a virtual machine, but the process still executes system calls on the main kernel.
These processes see a filesystem which is a small subset of the real filesystem.
(you could make the user root have user id 0 inside the container but
A good example is running a web server that needs to listen on a privileged port, such as 80.
Ports under 1024
If you wanted to run an Apache server (
Your intent was to give the process the ability to open a privileged port, but now the process
The limitations imposed by the
To avoid this issue, it is possible to map a non-privileged port outside the container to a privileged port inside the container. For example, you map port 8080 on the host to port 80 inside the container. This will allow you to run processes that normally require privileged ports without
Seccomp Profiles
The default
The issue with these
Capabilities
Capabilities are another way of specifying privileges that need to be available to a process running in a container. The advantage of capabilities is that groups of permissions
Using capabilities is much more secure than
A lot of the security concerns for processes running in containers apply to processes on a host in general
It also combines capabilities and defining access to resources by
https://rancher.com/blog/2018/2018-09-12-introduction-to-container-security-1/
Making sense Of Linux
They are a combination of Linux kernel technologies. Specifically,
To get a better understanding of how
seven types of
IPC controls the System V IPC and POSIX message queues a process can see.
Network controls the network resources a process can see.
Mount controls the set of file systems and mounts a process can see.
PID controls the process IDs a process can see.
User controls the user information (e.g.,
UTS controls the hostname and domain information a process can see.
The first is via one or more CLONE_NEWXXXX flags passed to the clone system call
The second way is through the
Each
Let’s
When the
Now what makes this interesting is the way the
This helped me visualize the
Each container has its own
The pause container and application container share the net and
If you are using docker and your container needs access to a
https://prefetch.net/blog/2018/02/22/making-sense-of-linux-namespaces/
- To understand the current state of Kernel Audit, it’s important to understand its relationship with
namespaces , which are kernel-enforced user space views.Currently, there are sevennamespaces : peernamespaces which include the Mountnamespace ; the UTSnamespace (hostname and domain information); the IPCnamespace (no one really knows what this one does); NETnamespaces which are peer systems, peernamespaces so the system comes up in the initial NETnamespace andall of the physical devices appear in thatnamespace ; and, three hierarchynamespaces – PID, User, andCgroups – so thatthe permissions are inherited from one to another.
The User
There Can Be Only One
As to containers, there is no hard definition
https://www.
- The Curious Case of Pid
Namespaces And How Containers Can Share Them
they give each application its own unique view of the system
Because of
Processes in
The kernel generates a new pid for the child and returns the identifier to the calling process, but it is up to the parent to keep track of this pid manually.
The first process started by the kernel has pid 1
The parent pid of init is pid 0, signifying that its parent is the kernel.
Pid 1 is the root of the user-space process tree
It is possible to reach pid 1 on a
If pid 1 dies, the kernel will panic and you have to reboot the machine.
A Quick Overview of
Linux
In most cases,
For example, as soon as a process creates a network
when you
Instead, it
a pid
Pid 1 in a
Inside a
1) It does not automatically get default signal handers, so
2) If another process in the
3) If it dies, every other process in the pid
The Docker “Mistake”
Docker (
This can lead to some unexpected behavior for an application processes because it usually
It is possible to run a special init process in your container and have it fork-exec into the application process, and many containers do this to avoid these problems. One unfortunate
The
It assumes that the process you are starting is not an init process, so it creates an init process for you (
A Simpler Alternative
It is possible to pass the
Multiple Containers in a Pod
it is preferable to bundle these processes separately so that
To achieve this,
A pod is a set of related containers that share some
that means processes in the same pod cannot signal each other
In addition, each container in the pod has the aforementioned init problem: every container process will run as pid 1
The
Adding
With the container runtime interface,
It then communicates with the pod’s
in this model the init process has additional privileges and introduces a new attack vector.
The
has access to the host’s filesystem
has to maintain full privileges because it doesn’t know in advance the set of privileges each new app will need.
is visible to
Sandboxes and Pid
1
3
2
4
5
https://hackernoon.com/the-curious-case-of-pid-namespaces-1ce86b6bc900
But consider what happens if a process
It's because
The action of calling
Suppose the parent process
And this is where the init process kicks in. The init process
Why zombie processes are harmful
Why are zombie processes a bad thing, even though they're
You're right,
But doesn't
You may
A "full init system" as we may call it, is neither necessary nor desirable.
The init system
https://blog.phusion.nl/2015/01/20/docker-and-the-pid-1-zombie-reaping-problem/
- Containers as everyone knows them are normal processes that
are executed using two features of the Linux kernel callednamespaces andcgroups .
Process IDs
File System
Network interfaces
Inter-Process Communication (IPC)
While I said above that processes running in a
Linux has a feature called
The thing I wanted to point out here was that
You can also think of other types of abstractions you could use. Service meshes like
You can also use multiple sidecars. There's nothing stopping you from using both the
https://www.ianlewis.org/en/what-are-kubernetes-pods-anyway
- Kubernetes provides a clean abstraction called pods for just this use case. It hides the complexity of Docker flags and the need to babysit the containers, shared volumes
, and the like . It also hides differences between container runtimes. For example,rkt supports pods natively so there is less work for Kubernetes to do but you as the user of Kubernetes don't have to worry about it.
In
The pause container has two core responsibilities. First, it serves as the basis of Linux
Sharing
In Linux, when you run a new process, the process inherits its
Once the process is running, you can add other processes to the process'
Containers in a pod share
In both cases we specify the pause container as the container whose
Reaping Zombies
In Linux, processes in a PID
Processes can start other processes using the fork and exec
Processes can start other processes using the fork and exec
Longer lived zombie processes occur when parent processes don't call the wait
In containers, one process must be the init process for each PID
on
It's useful to note that there has been a lot of back-and-forth on PID
https://www.ianlewis.org/en/almighty-pause-container
- init container -
kubernetes
A
Init containers are exactly like regular containers, except:
Init containers always run to completion.
Each init container must complete successfully before the next one starts.
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/
- Introduction to Container Security
We will begin by talking about two of the Linux kernel features that helped make containers as we know them today possible
This feature also allows for better accounting of the usage, such as when teams need to report the usage for billing purposes
The cgroups feature of containers allows them to scale in a controllable way and have a predictable capacity.
It is also a good security feature because processes running in containers can not easily consume all the resources on a system - for example, a denial of service attack by starving other processes of required resources.
https://rancher.com/blog/2018/2018-09-12-introduction-to-container-security-1/
- The underlying technology
Docker uses a technology called namespaces to provide the isolated workspace called the container. When you run a container, Docker creates a set of namespaces for that container.
These namespaces provide a layer of isolation
Each aspect of a container runs in a separate namespace and its access is limited to that namespace .
Docker Engine uses namespaces such as the following on Linux:
The pid namespace : Process isolation (PID: Process ID).
The net namespace : Managing network interfaces (NET: Networking).
The ipc namespace : Managing access to IPC resources (IPC: InterProcess Communication).
The mnt namespace : Managing filesystem mount points (MNT: Mount).
The uts namespace : Isolating kernel and version identifiers. (UTS: Unix Timesharing System).
Control groups
Docker Engine on Linux also relies on another technology called control groups (cgroups ). A cgroup limits an application to a specific set of resources. Control groups allow Docker Engine to share available hardware resources to containers and optionally enforce limits and constraints. For example, you can limit the memory available to a specific container.
Union file systems
Union file systems, or UnionFS, are file systems that operate by creating layers, making them very lightweight and fast. Docker Engine uses UnionFS to provide the building blocks for containers. Docker Engine can use multiple UnionFS variants, including AUFS, btrfs , vfs , and DeviceMapper .
Container format
Docker Engine combines the namespaces , control groups, and UnionFS into a wrapper called a container format. The default container format is libcontainer . In the future , Docker may support other container formats by integrating with technologies such as BSD Jails or Solaris Zones.
https://docs.docker.com/engine/docker-overview/#the-underlying-technology
Unionfs : A Stackable Unification File System
This project builds a stackable unification file system, which can appear to merge the contents of several directories (branches), while keeping their physical content separate.
http://unionfs.filesystems.org/
- Kernel Korner -
Unionfs : Bringing Filesystems Together
In this situation, unioning allows administrators to keep such files separate physically, but to merge them logically into a single view. A collection of merged directories is called a union, and each physical directory is called a branch
https://www.linuxjournal.com/article/7714
- Harbor
Harbor is an open source cloud native registry that stores, signs, and scans container images for vulnerabilities.
It fills a gap for organizations and applications that cannot use a public or cloud-based registry, or want a consistent experience across clouds.
https://goharbor.io/