- NAND flash memory
Flash memory is an electronic (solid-state) non-volatile computer memory storage medium that can be electrically erased and reprogrammed. The two main types of flash memory are named after the NAND and NOR logic gates.
The NAND type is found primarily in memory cards, USB flash drives, solid-state drives (those produced in 2009 or later), and similar products, for general storage and transfer of data. NAND or NOR flash memory is also often used to store configuration data in numerous digital products, a task previously made possible by EEPROM or battery-powered static RAM. One key disadvantage of flash memory is that it can only endure a relatively small number of write cycles in a specific blockhttps://en.wikipedia.org/wiki/Flash_memory


- NVMe vs SSD: Speed, Storage & Mistakes to Avoid
SSD (solid-state drive) is a type of nonvolatile storage media that stores persistent data on flash memory. It has two essential parts - a NAND flash memory and a flash controller optimized to deliver high read-write performance in sequential as well as random data fetching.
SSDs offer high transfer speeds, low latency even with random data access, more durability but not for hierarchical storage use, and expectedly no sound of moving parts
For perceived and real performance gains, storage was the last bottleneck, which was eliminated with the advent of SSD and then the high-performance NVMe SSD storage solutions. The NAND flash SSDs radically improved input-output performance, access times dropped from 6-12 milliseconds to less than 1ms.
What is SATA SSD?
SATA uses the AHCI command protocol and supports the IDE, which primarily was built for the older and sluggish spinning disk drives and not for the sturdy flash-based storage.
Mistakes to avoid
Defragmentation is not for SSDs and can negatively affect its lifespan. SSDs save data in blocks and can randomly read from any location, whether contiguous or random. You will be overkilling the flash drive when you defrag.
Don’t use the SSD to its full capacity or you risk choking it. Because its performance gets affected, mainly write speeds, it is suggested to have minimal 25 percent of your storage space free for improved performance.
Modern SSDs come with an in-built Garbage Collection Mechanism. Whether the TRIM command should be enabled or not is a question based on the specific OS you are using and needs to be looked into as it can clutter unwanted data in your drive and needs to be handled properly
What is NVMe SSD?
Non-Volatile Memory Express (NVMe) is the latest industry-standard software interface for PCIe SSDs.
The NVMe SSD enables the flash memory to run directly through the PCI Express (PCIe) serial bus interface as it offers high bandwidth due to being directly attached to the CPU rather than function through the limiting SATA speeds.
It comes in two form factor, M.2 or PCIe expansion card, a 2.5-inch U.2 connector, but with both form factors, it directly connects electrically to the motherboard via the PCIe rather than SATA connection.
Mistakes to avoid
Remember, NVMe is a communication interface and storage protocol, not a storage media device.
Deploy pooled SSD storage across the data center, which places a cache of SSD storage before higher capacity drives to provide cost-efficient and enhanced performance.
Don’t judge an NVMe SSD on the base of price; it can cost you in endurance, quality of service, and most I/O consistency.
A cost-benefit analysis is recommended and the analysis of the performance requirements of application workloads to determine if you do need the transitioning.
Don’t deploy NVMe on top of the same architecture used for conventional flash, as the traditional controller can only handle low levels of I/O processing and create latency and cap performance.
https://www.promax.com/blog/nvme-vs-ssd-speed-storage-mistakes-to-avoid

- NVMe, AHCI and IDE are transfer protocols (languages). They run on top of transfer interfaces such as PCIe or SATA (spoken, written).
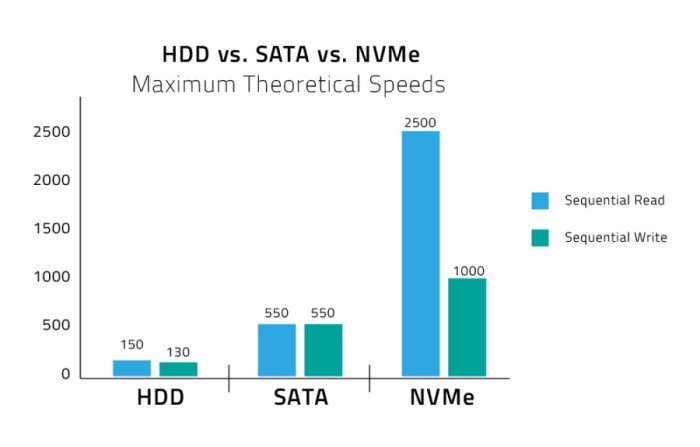
NVMe is the latest high performance and optimized protocol which supersedes AHCI and compliments PCIe technology. It offers an optimised command and completion path for use with NVMe based storage. It was developed by a consortium of manufacturers specifically for SSDs to overcome the speed bottleneck imposed by the older SATA connection. It is akin to a more efficient language between storage device and PC: one message needs to be sent for a 4GB transfer instead of two, NVMe can handle 65,000 queues of data each with 65,000 commands, instead of one queue that with the capacity for 32 commands, and it only has seven major commands (read, write, flush etc). As well as delivering better throughput NVMe offers reduced latency
https://www.userbenchmark.com/Faq/What-s-the-difference-between-SATA-PCIe-and-NVMe/105
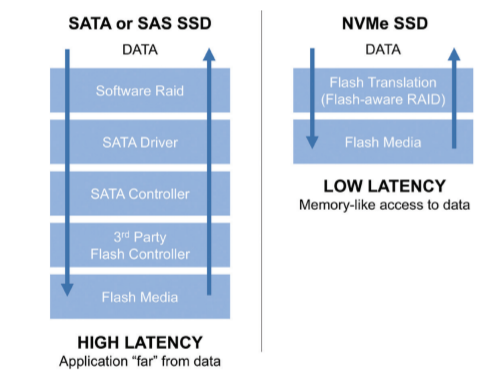
- NVMe (Non-Volatile Memory Express) is an interface protocol built especially for Solid State Drives (SSDs). NVMe works with PCI Express (PCIe) to transfer data to and from SSDs. NVMe enables rapid storage in computer SSDs and is an improvement over older Hard Disk Drive (HDD) related interfaces such as SATA and SAS. The only reason SATA and SAS are used with SSDs in computers is that until recently, only slower HDDs have been used as the large-capacity storage in computers. Flash memory has been used in mobile devices such as smartphones, tablets, USB drives and SD cards. (SSDs are flash memory.)
https://www.microcontrollertips.com/why-nvme-ssds-are-faster-than-sata-ssds/
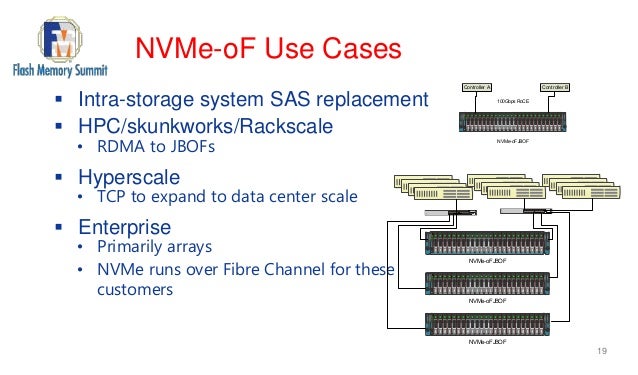
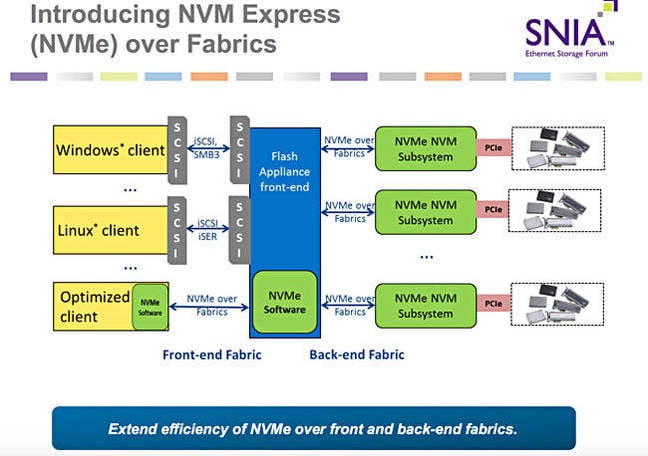
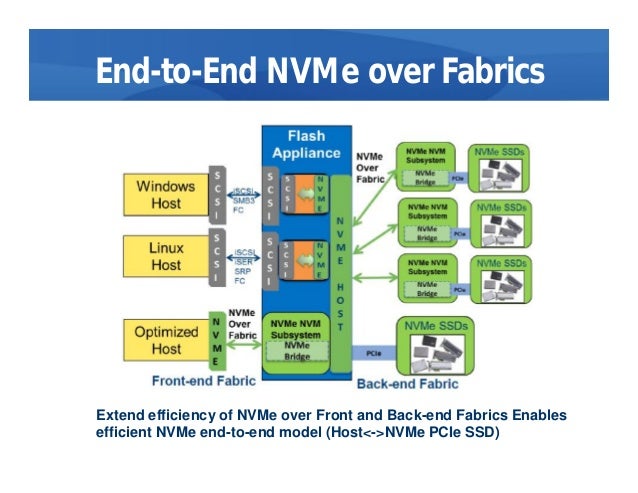
- NVMe over Fabrics, also known as NVMe-oF and non-volatile memory express over fabrics, is a protocol specification designed to connect hosts to storage across a network fabric using the NVMe protocol.
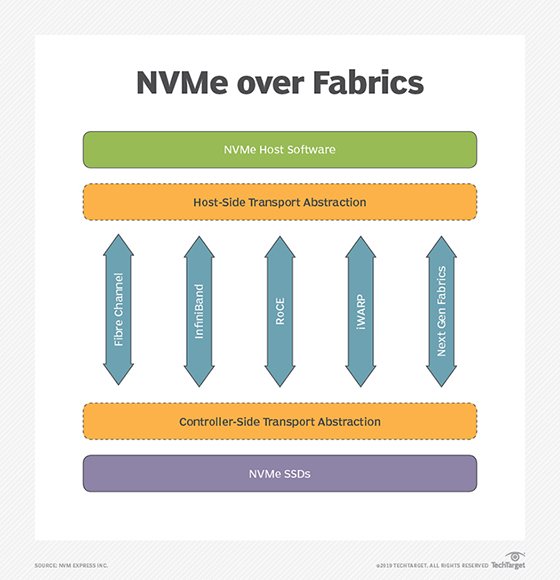
there have been multiple implementations of the protocol, such as NVMe-oF using remote direct memory access (RDMA), FC or Transmission Control Protocol/Internet Protocol (TCP/IP).
Uses of NVMe over Fabrics
Using NVMe-oF can help provide a state-of-the-art storage protocol that can take full advantage of today's SSDs. The protocol can also help in bridging the gaps between direct-attached storage (DAS) and SANs, enabling organizations to support workloads that require high throughputs and low latencies.
NVMe over Fabrics vs. NVMe: Key differences
One of the main distinctions between NVMe and NVMe over Fabrics is the transport-mapping mechanism for sending and receiving commands or responses. NVMe-oF uses a message-based model for communication between a host and a target storage device. Local NVMe will map commands and responses to shared memory in the host over the PCIe interface protocol.
While it mirrors the performance characteristics of PCIe Gen 3, NVMe lacks a native messaging layer to direct traffic between remote hosts and NVMe SSDs in an array. NVMe-oF is the industry's response to developing a messaging layer.
NVME over Fabrics using RDMA
NVME over Fabrics using RDMA
NVMe-oF use of RDMA is defined by a technical subgroup of the NVM Express organization. Mappings available include RDMA over Converged Ethernet (RoCE) and Internet Wide Area RDMA Protocol (iWARP) for Ethernet and InfiniBand.
RDMA is a memory-to-memory transport mechanism between two computers. Data is sent from one memory address space to another, without invoking the OS or the processor. Lower overhead and faster access and response time to queries are the result, with latency usually in microseconds (μs).
NVMe over Fabrics using Fibre Channel
The FC protocol supports access to shared NVMe flash, but there is a performance hit imposed to interpret and translate encapsulated SCSI commands to NVMe commands.
NVMe over Fabrics using TCP/IP
One of the newer developments regarding NVMe-oF includes the development of NVMe-oF using TCP/IP. NVMe-oF can now support TCP transport binding. NVMe over TCP makes it possible to use NVMe-oF across a standard Ethernet network.
https://searchstorage.techtarget.com/definition/NVMe-over-Fabrics-Nonvolatile-Memory-Express-over-Fabrics







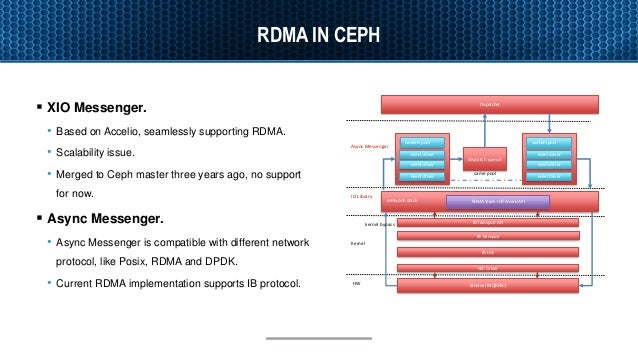
- Accelerating Ceph with RDMA and NVMe-oF
RDMA as Ceph NVMe fabrics
RDMA is a direct access from the memory of one computer into that of another without involving either one’s operating system.
RDMA supports zero-copy networking(kernel bypass)
Eliminate CPUs, memory or context switches
Reduce latency and enable fast messenger transfer.
Potential benefit for ceph
Better Resource Allocation – Bring additional disk to servers with spare CPU.
Lower latency - generated by ceph network stack.
https://www.slideshare.net/insideHPC/accelerating-ceph-with-rdma-and-nvmeof
- DRBD Fundamentals
The Distributed Replicated Block Device (DRBD) is a software-based, shared-nothing, replicated storage solution mirroring the content of block devices (hard disks, partitions, logical volumes etc.) between hosts.
DRBD mirrors data
in real time. Replication occurs continuously while applications modify the data on the device.
transparently. Applications need not be aware that the data is stored on multiple hosts.
synchronously or asynchronously. With synchronous mirroring, applications are notified of write completions after the writes have been carried out on all hosts. With asynchronous mirroring, applications are notified of write completions when the writes have completed locally, which usually is before they have propagated to the other hosts.
https://www.linbit.com/drbd-user-guide/users-guide-drbd-8-4/