- What is Malware Analysis?
Malware analysis is the process of understanding the behavior and purpose of a suspicious file or URL. The output of the analysis aids in the detection and mitigation of the potential threat
Pragmatically triage incidents by level of severity
Uncover hidden indicators of compromise (IOCs) that should be blocked
Improve the efficacy of IOC alerts and notifications
Enrich context when threat hunting
Types of Malware Analysis
Static Analysis
Basic static analysis does not require that the code is actually run. Instead, static analysis examines the file for signs of malicious intent. It can be useful to identify malicious infrastructure, libraries or packed files.
Technical indicators are identified such as file names, hashes, strings such as IP addresses, domains, and file header data can be used to determine whether that file is malicious.
tools like disassemblers and network analyzers can be used to observe the malware without actually running it in order to collect information on how the malware works.
since static analysis does not actually run the code, sophisticated malware can include malicious runtime behavior that can go undetected.
For example, if a file generates a string that then downloads a malicious file based upon the dynamic string, it could go undetected by a basic static analysis.
Dynamic Analysis
Dynamic malware analysis executes suspected malicious code in a safe environment called a sandbox
This closed system enables security professionals to watch the malware in action without the risk of letting it infect their system or escape into the enterprise network.
Dynamic analysis provides threat hunters and incident responders with deeper visibility, allowing them to uncover the true nature of a threat.
As a secondary benefit, automated sandboxing eliminates the time it would take to reverse engineer a file to discover the malicious code.
The challenge with dynamic analysis is that adversaries are smart, and they know sandboxes are out there, so they have become very good at detecting them. To deceive a sandbox, adversaries hide code inside them that may remain dormant until certain conditions are met. Only then does the code run.
Hybrid Analysis (includes both of the techniques above)
For example, one of the things hybrid analysis does is apply static analysis to data generated by behavioral analysis – like when a piece of malicious code runs and generates some changes in memory. Dynamic analysis would detect that, and analysts would be alerted to circle back and perform basic static analysis on that memory dump. As a result, more IOCs would be generated and zero-day exploits would be exposed.
Malware Analysis Use Cases
Malware Detection
By providing deep behavioral analysis and by identifying shared code, malicious functionality or infrastructure, threats can be more effectively detected.
In addition, an output of malware analysis is the extraction of IOCs. The IOCs may then be fed into SEIMs, threat intelligence platforms (TIPs) and security orchestration tools to aid in alerting teams to related threats in the future.
Threat Alerts and Triage
Malware analysis solutions provide higher-fidelity alerts earlier in the attack life cycle. Therefore, teams can save time by prioritizing the results of these alerts over other technologies.
Incident Response
The goal of the incident response (IR) team is to provide root cause analysis, determine impact and succeed in remediation and recovery. The malware analysis process aids in the efficiency and effectiveness of this effort.
Threat Hunting
Malware analysis can expose behavior and artifacts that threat hunters can use to find similar activity, such as access to a particular network connection, port or domain. By searching firewall and proxy logs or SIEM data, teams can use this data to find similar threats.
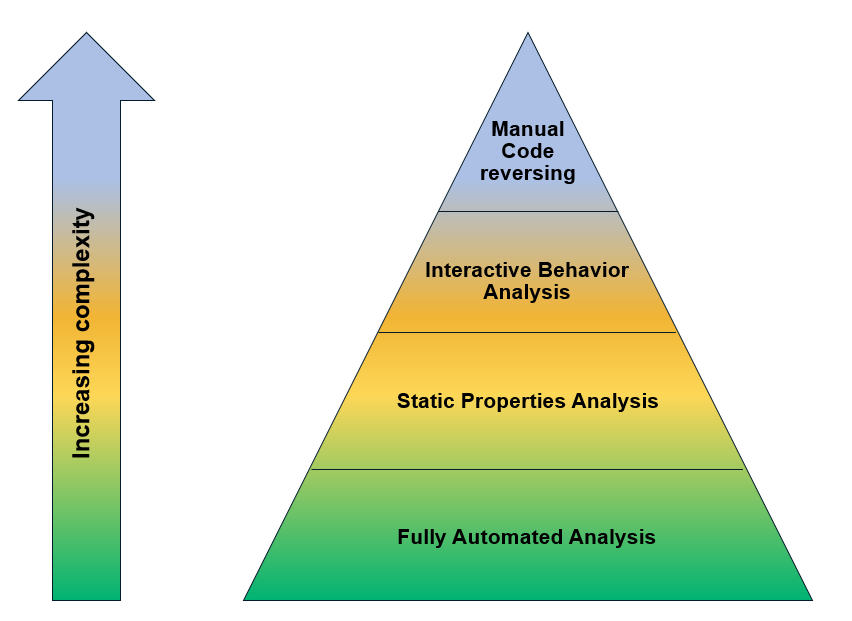
Stages of Malware Analysis
Static Properties Analysis
Static properties include strings embedded in the malware code, header details, hashes, metadata, embedded resources, etc. This type of data may be all that is needed to create IOCs, and they can be acquired very quickly because there is no need to run the program in order to see them.
Interactive Behavior Analysis
Behavioral analysis is used to observe and interact with a malware sample running in a lab. Analysts seek to understand the sample’s registry, file system, process and network activities. They may also conduct memory forensics to learn how the malware uses memory. If the analysts suspect that the malware has a certain capability, they can set up a simulation to test their theory.
Fully Automated Analysis
Manual Code Reversing
analysts reverse-engineer code using debuggers, disassemblers, compilers and specialized tools to decode encrypted data, determine the logic behind the malware algorithm and understand any hidden capabilities that the malware has not yet exhibited.
https://www.crowdstrike.com/cybersecurity-101/malware/malware-analysis/
- Understand Where You Currently Fit Into the Malware Analysis Process
Fully-Automated Analysis: Run (“detonate”) the suspicious file in an automated analysis environment (“sandbox”) to get a report on its activities, such as its interaction with the file system and network.
Static Properties Analysis: Examine metadata and other details embedded in the file (e.g., strings) without running it, so you can spot the areas you might want to examine more deeply in subsequent steps.
Interactive Behavior Analysis: Run the file in an isolated laboratory environment, which you fully control, tweaking the lab’s configuration in a series of iterative experiments to study the specimen’s behavior.
Manual Code Reversing: Examine the code that comprises the file, often with the help of a disassembler and a debugger, to understand its key capabilities and fill in the gaps left from the earlier analysis steps.
Memory, file system, and network forensics efforts (when applicable) also contribute to the understanding.
https://www.sans.org/blog/how-you-can-start-learning-malware-analysis/
- Intro to Malware Analysis: What It Is & How It Works
There are a few key reasons to perform malware analysis:
Malware detection — To better protect your organization, you need to be able to identify compromising threats and vulnerabilities.
Threat response — To help you understand how these threats work so you can react accordingly to them.
Malware research — This can help you to better understand how specific types of malware work, where they originated, and what differentiates them.
What Is Malware?
Malware is any piece of software that’s harmful to your system — worms, viruses, trojans, spyware, etc
Malware analysis can help you to determine if a suspicious file is indeed malicious, study its origin, process, capabilities, and assess its impact to facilitate detection and prevention.
The Two Types of Malware Analysis Techniques: Static vs. Dynamic
There are two ways to approach the malware analysis process — using static analysis or dynamic analysis. With static analysis, the malware sample is examined without detonating it, whereas, with dynamic analysis, the malware is actually executed in a controlled, isolated environment.
Static Malware Analysis
The malware components and properties are analyzed without running the code
Static malware analysis is signature-based — i.e., the signature of the malware binary is determined by calculating the cryptographic hash.
The malware binary can be reverse-engineered by using a disassembler.
Static malware analysis involves virus scanning, fingerprinting, memory dumping, etc.
Dynamic Malware Analysis
The malware is executed within a virtual environment, and its behavior is observed.
Dynamic malware analysis takes a behavior-based approach to malware detection and analysis.
The malware binary can be reverse-engineered using disassemblers and debuggers to understand and control certain aspects of the program when executing.
Dynamic malware analysis involves registry changes, API calls, memory writes, etc.
It is more effective and provides a higher detection rate than static analysis
The Four Stages of Malware Analysis
Stage One: Fully Automated Analysis
Automated malware analysis refers to relying on detection models formed by analyzing previously discovered malware samples
Fully automated analysis can be done using tools like Cuckoo Sandbox, an open-source automated malware analysis platform that can be tweaked to run custom scripts and generate comprehensive reports.
Stage Two: Static Properties Analysis
Static properties analysis involves looking at a file’s metadata without executing the malware
One of the free tools that you may find useful for this purpose is PeStudio. This tool flags suspicious artifacts within executable files and is designed for automated static properties analysis. PeStudio presents the file hashes that can be used to search VirusTotal, TotalHash, or other malware repositories to see if the file has previously been analyzed.
Stage Three: Interactive Behavior Analysis
the malware sample is executed in isolation as the analyst observes how it interacts with the system and the changes it makes.
Often, a piece of malware might refuse to execute if it detects a virtual environment or might be designed to avoid execution without manual interaction (i.e., in an automated environment)
There are several types of actions that should immediately raise a red flag, including:
Adding or modifying new or existing files,
Installing new services or processes, and
Modifying the registry or changing system settings.
Some types of malware might try to connect to suspicious host IPs that don’t belong to the environments. Others might also try to create mutex objects to avoid infecting the same host multiple times (to preserve operational stability). These findings are relevant indicators of compromise.
Some of the tools that you can use include:
Wireshark for observing network packets,
Process Hacker to observe the processes that are executing in memory,
Process Monitor to observe real-time file system, registry, process activity for Windows, and
ProcDot to provide an interactive and graphical representative of all recorded activities.
Stage Four: Manual Code Reversing
This process can:
Shed some light on the logic and algorithms the malware uses,
Expose hidden capabilities and exploitation techniques the malware uses, and
Provide insights about the communication protocol between the client and the server on the command and control side.
Typically, to manually reverse the code, analysts make use of debuggers and disassemblers.
How to Prevent Malware Infection
Keep your systems and applications up to date.
Stay wary of social engineering attacks that can compromise your data
Perform regular scans on your systems using antivirus, anti-malware solutions
Employ security best practices like using a secure connection, blocking ads, etc.
Create backups for all your business-critical data
https://sectigostore.com/blog/malware-analysis-what-it-is-how-it-works/
- Free Automated Malware Analysis Sandboxes and Services
Automated malware analysis tools, such as analysis sandboxes, save time and help with triage during incident response and forensic investigations
https://zeltser.com/automated-malware-analysis/
- Free Blocklists of Suspected Malicious IPs and URLs
Several organizations maintain and publish free blocklists of IP addresses and URLs of systems and networks suspected in malicious activities on-line
https://zeltser.com/malicious-ip-blocklists/
- Free Online Tools for Looking up Potentially Malicious Websites
Several organizations offer free online tools for looking up a potentially malicious website. Some of these tools provide historical information; others examine the URL in real time to identify threats
https://zeltser.com/lookup-malicious-websites/
What about malware variations that have not yet been seen? Signature-based detection methods will not work. To detect these types of threats, vendors created Sandboxing products, which take a suspect file and place it in an environment where its behaviors can be closely analyzed. If the file does something malicious while in the sandbox, it is flagged as malware. This is known as Heuristic detection, and it looks for anomaly behavior that is out of the ordinary. In fact, vendors create proprietary heuristic algorithms that can detect never before seen polymorphic samples of malware
https://training.fortinet.com/pluginfile.php/1624915/mod_scorm/content/1/story_content/external_files/NSE%202%20TIS%20Script_EN.pdf