Slurm and Moab
Slurm and Moab are two workload manager systems that have
been used to schedule and manage user jobs run on Livermore Computing (LC) clusters.
Currently, LC runs Slurm natively on most clusters, and provides Moab "wrappers" now that Moab has
been decommissioned. This tutorial presents the essentials for using Slurm and Moab wrappers on LC platforms
What is a Workload Manager?
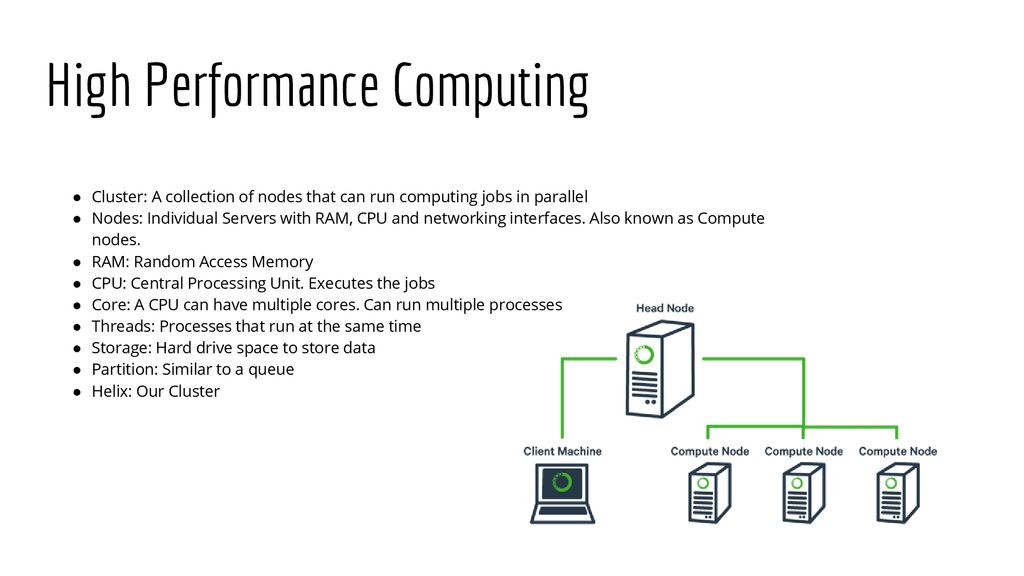
The typical LC cluster is a finite resource
that is shared by many users.
In
the process of getting work done, users compete for a cluster's nodes, cores, memory, network, etc.
In order to fairly and efficiently
utilize a cluster,
a special software system is employed to manage how work
is accomplished.
Commonly called a Workload Manager. May also
be referred to (sometimes loosely) as:
Batch system
Batch scheduler
Workload scheduler
Job scheduler
Resource manager (usually considered a component of a Workload Manager)
Tasks commonly performed by a Workload Manager:
Provide a means for users to specify and submit work as "jobs"
Evaluate, prioritize, schedule and run jobs
Provide a means for users to monitor,
modify and interact with jobs
Manage, allocate and provide access to
available machine resources
Manage pending work in job queues
Monitor and troubleshoot jobs and machine resources
Provide accounting and reporting facilities for jobs and machine resources
Efficiently balance work over machine resources; minimize wasted resources
https://computing.llnl.gov/tutorials/moab/
Deploying a
Burstable and Event-driven HPC Cluster on AWS Using SLURM, Part 1
Google Codelab for creating two federated Slurm clusters on Google Cloud Platform
OpenStack and HPC Workload Management
Increasing Cluster Performance by Combining rCUDA with Slurm
Docker vs Singularity vs Shifter in an HPC environment
Helix - HPC/SLURM Tutorial
- SchedMD® is the core company behind the Slurm workload manager software, a free open-source workload manager designed specifically to satisfy the demanding needs of high performance computing.
https://www.schedmd.com/
- Slurm vs Moab/Torque on Deepthought HPC clusters
Intro and Overview: What is a scheduler?
A high performance computing (HPC) cluster (
hereafter abbreviated HPCC) like the
Deepthought clusters
consists of many
compute nodes, but
at the same time have many
users submitting many jobs, often very large jobs. The HPCC needs a mechanism to distribute jobs across the nodes
in a reasonable fashion; this is
the task of a program called a scheduler.
This is
a complicated tasks: the various jobs can have various requirements
( e.g. CPU, memory,
diskspace, network transportation, etc.
) as well as differing priorities. And because we want to enable large parallel jobs to run, the scheduler needs to
be able to reserve nodes for larger jobs (i.e. if an user submits a job requiring 100 nodes, and only 90 nodes are
currently free, the scheduler might need to keep other jobs off the 90 free nodes in order that the 100 node job might eventually run). The scheduler must also account for nodes
which are down, or have insufficient resources for a particular job, etc.
As such, a resource manager is also needed (which can either
be integrated with the scheduler or run as a separate program). The scheduler will also need to interface with an accounting system (which also can
be integrated into the scheduler) to handle the charging of allocations for
time used on the cluster.
The original
Deepthought HPC cluster at the University of Maryland originally used the Maui scheduler for scheduling jobs, along with the Torque Resource Manager and the Gold Allocation Manager.
In 2009, we migrated to the Moab scheduler, still keeping Torque as our resource manager and Gold for allocation management
.Moab derived from Maui, and so the user interface was mostly unchanged during this migration.
Slurm includes its own resource management and accounting system, so Torque and Gold are no longer used.
http://hpcc.umd.edu/hpcc/help/slurm-vs-moab.html
Intelligent HPC Workload Management Across Infrastructure and Organizational Complexity
Running computations on the Torque cluster
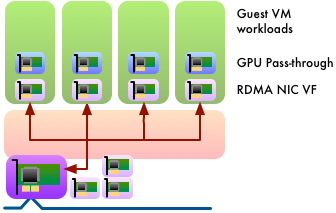
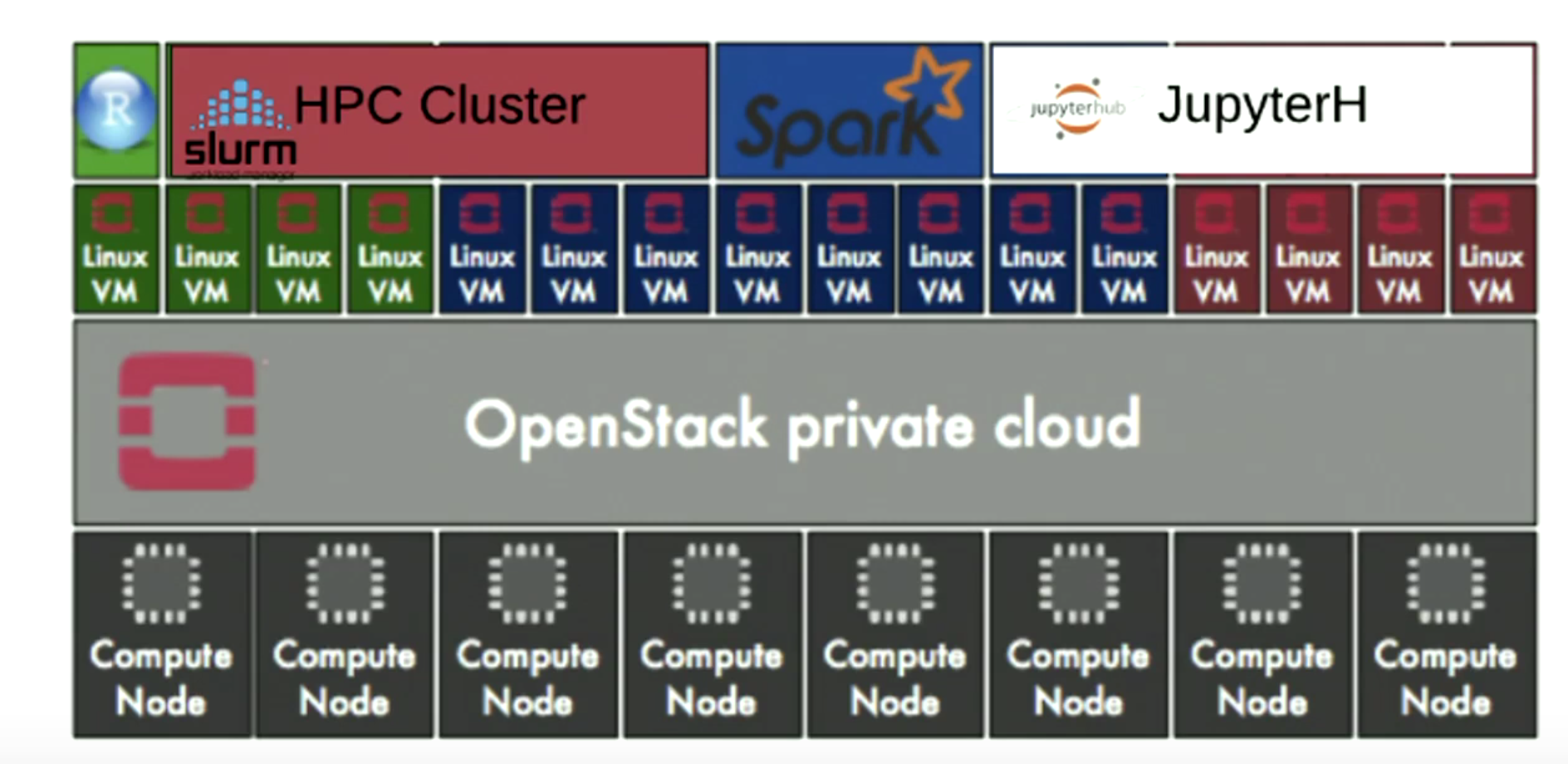
Workload Management in HPC and Cloud
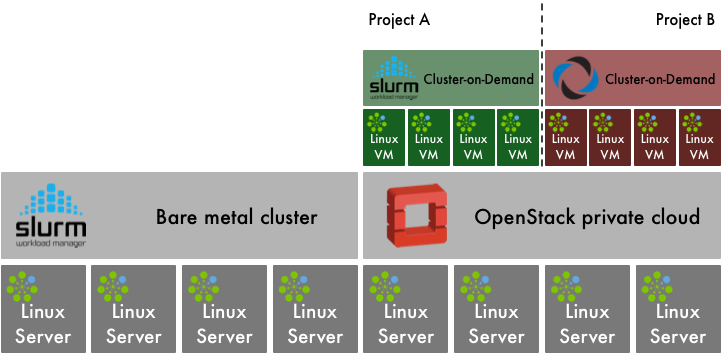
Cluster as a Service: Managing multiple clusters for
openstack clouds and other diverse frameworks
Overview of the UL HPC Viridis cluster, with its OpenStack-based private Cloud setup.
OpenStack and
Virtualised HPC
How the Vienna
Biocenter powers HPC with OpenStack
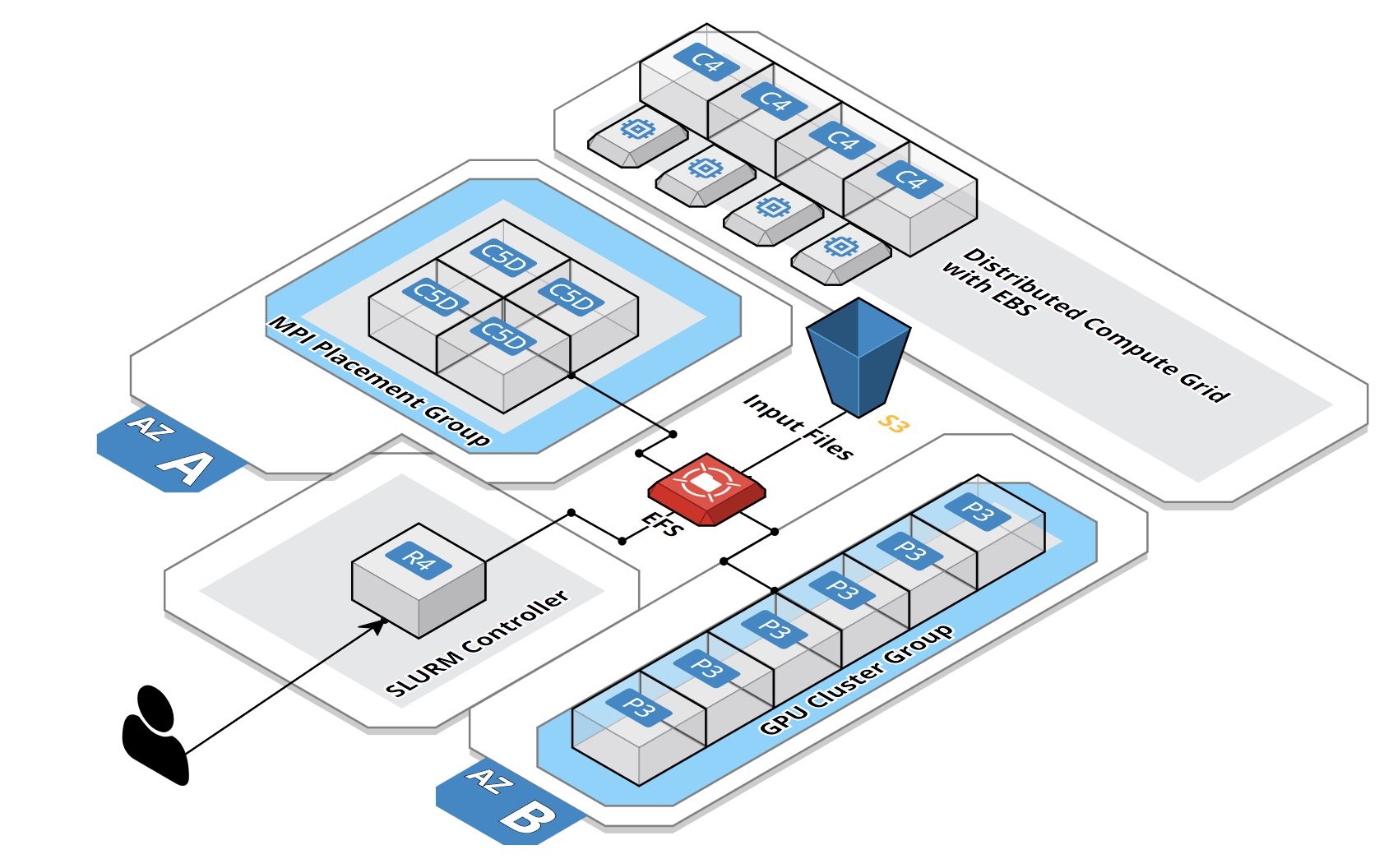

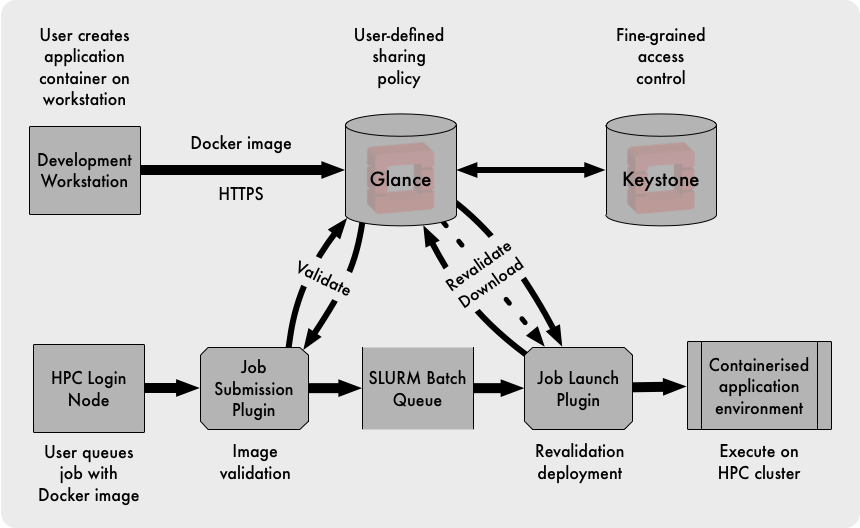

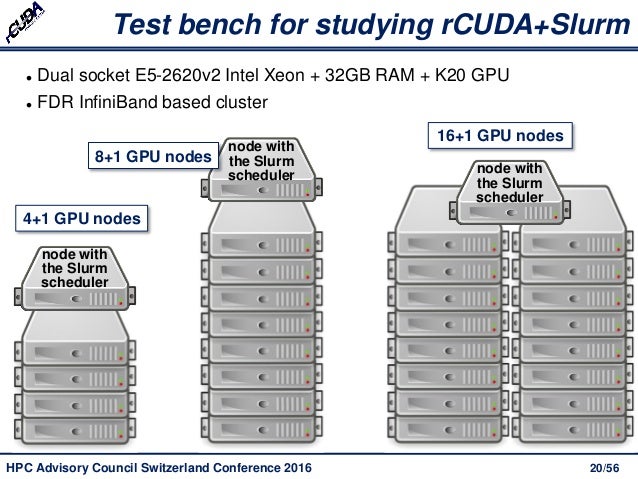

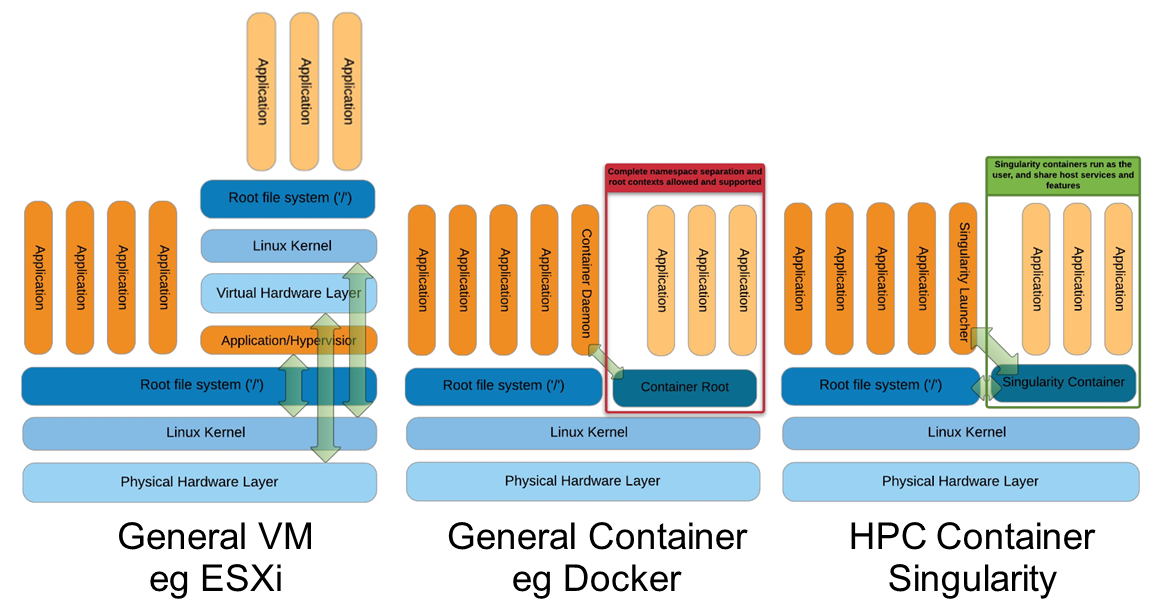



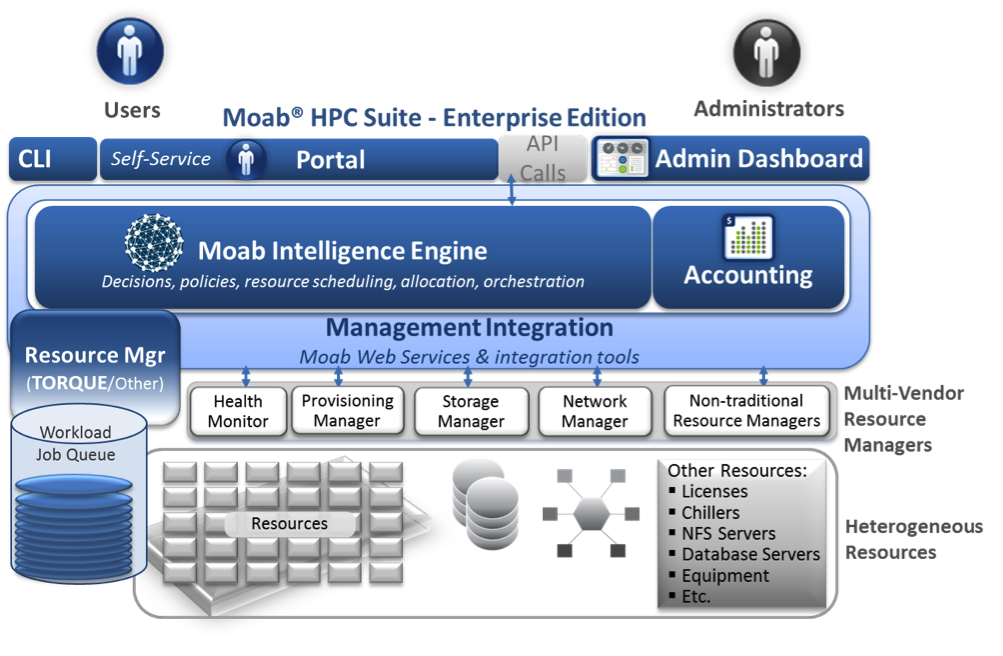

 Workload Management in HPC and Cloud
Workload Management in HPC and Cloud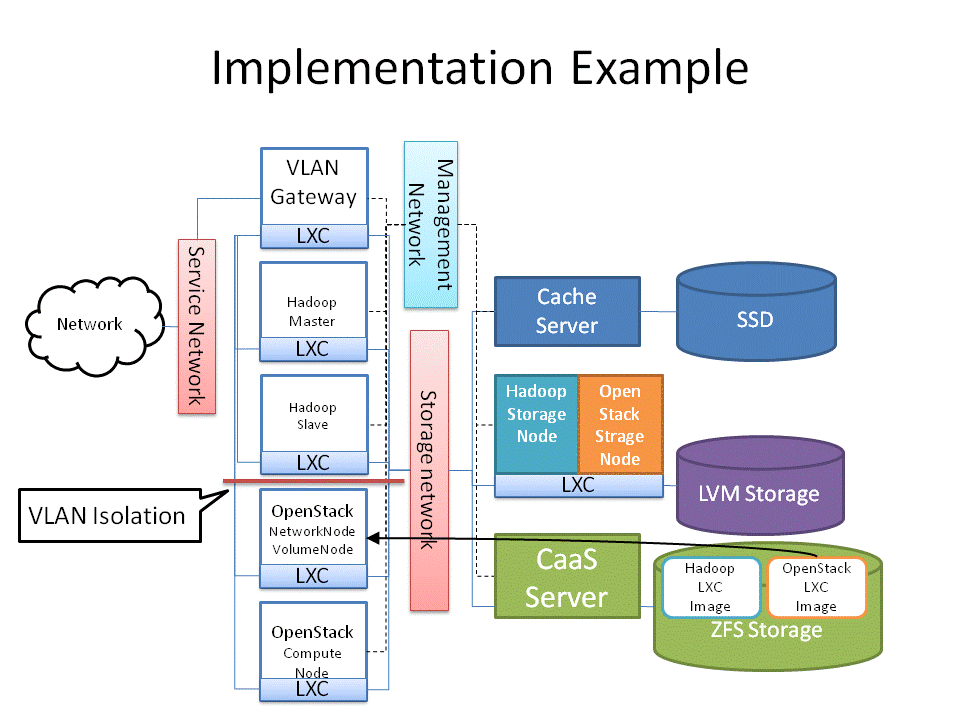 Cluster as a Service: Managing multiple clusters for
Cluster as a Service: Managing multiple clusters for 
No comments:
Post a Comment