- Python, an interpreted, interactive, object-oriented, extensible programming language. http://www.python.org/
- Data Science and Machine Learning
Prepare, analyze and visualize your data with
Build and train machine learning models with TensorFlow, Theano and
Get up and running in minutes whether an individual or large team
Develop web applications with frameworks like Django and Flask
Deploy to AWS or Google Cloud
Secure your applications with
Test and ensure code quality with
https://www.activestate.com/activepython
- Dask
.
Dask
Architecture
Dask
http://distributed.dask.org/en/latest/
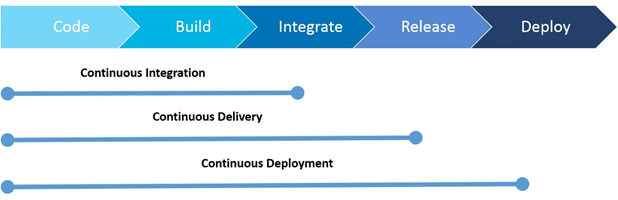
- Distributed Pandas on a Cluster with Dask
DataFrames
Summary
Dask
Introduction: Pandas is intuitive and fast, but needs Dask to scale
Read CSV and Basic operations
Read CSV
Basic Aggregations and
Joins and Correlations
Shuffles and Time Series
Parquet I/O
https://matthewrocklin.com/blog/work/2017/01/12/dask-dataframes
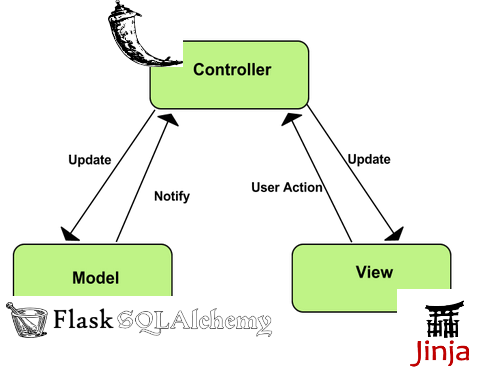
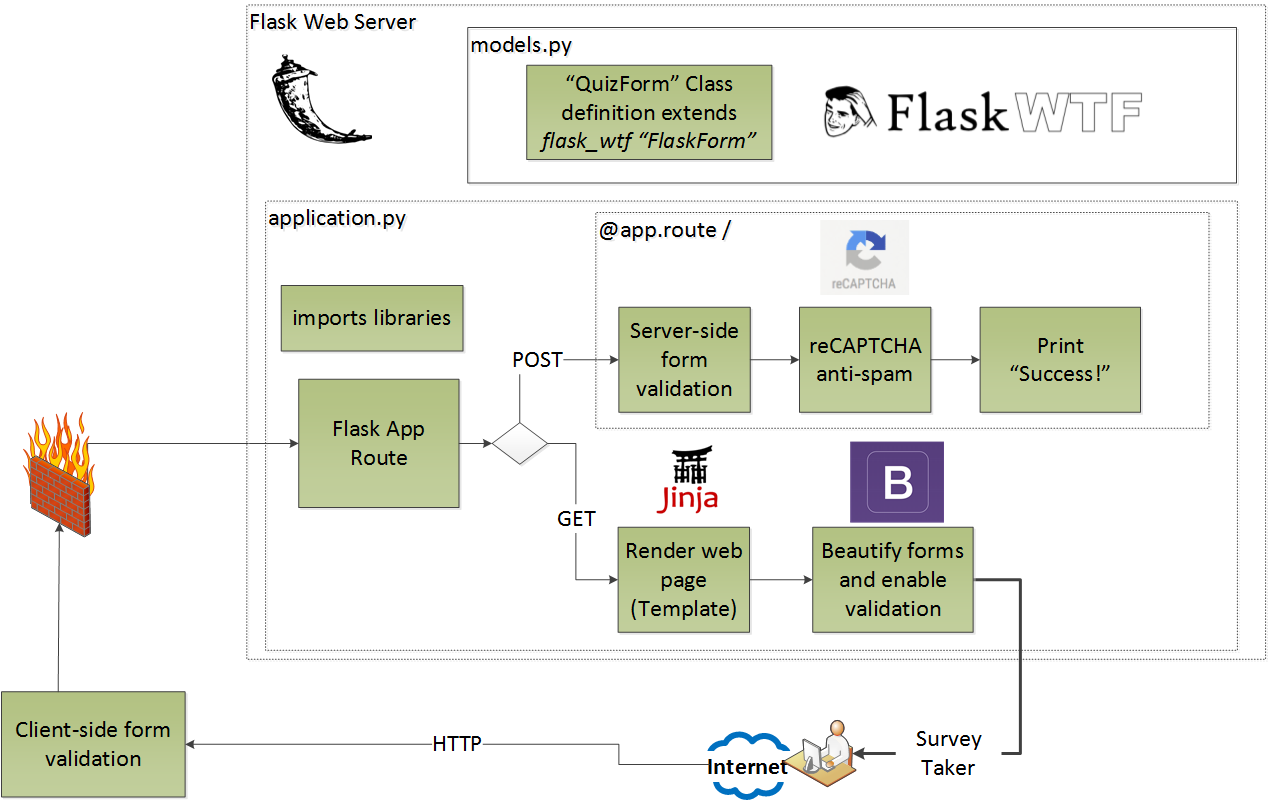
- Flask is a
microframework Werkzeug
http://flask.pocoo.org/
- The main reason
why ReactJS resides NodeJS
https://danidee10.github.io/2016/10/05/flask-by-example-5.html
Buidling SQLAlchemy
What is REST?
REST is a programming style which describes how data should be transferred
The key principles of REST are as follows
Client–server : are not concerned are not concerned
Stateless: State information is not stored client request
Layered system: To improve performance instead of an API server intermediaries like load balancers must be able to serve requests.
Uniform interface :
Code on demand (optional) : executable
It is also important to note that REST is not a standard but encourages the use of standards such as the JSON API
Flask-Restful: will be used to
Flask-SQLAlchemy be used to SQLAlchmey
Marshmallow: is used to Serailize Deserialize
Marshmallow-jsonapi modified
Psycopg2 : PostgresSQL PyMySQL
Flask-Migrate and Flask-Script: will be used
Installation
Flask-Restful: will be used to
Flask-SQLAlchemy be used to SQLAlchmey
Marshmallow: is used to Serailize Deserialize
Marshmallow-jsonapi modified
Psycopg2 : PostgresSQL
if you are using MySQL PyMySQL
Flask-Migrate and Flask-Script: will be used
Defining Database Models and Validation Schema with Flask-SQLAlchemy Marshmallow_jsonapi
Flask-SQLAlchemy's provides access to the SQLAlchemy Object Relation Mapper (ORM) .
https://techarena51.com/blog/buidling-a-database-driven-restful-json-api-in-python-3-with-flask-flask-restful-and-sqlalchemy/
Sanic
This means you can use the new shiny
https://sanic.readthedocs.io/en/latest/
- Domain and codomain simplified
Domain is a set where x values
Injection: the injection class means that each x value/element of the 2d coordinate system has a corresponding y value of the coordinate system
In order for a function to be
If a value remains without a connection in any of the sets (domain & codomain) or if there are multiple connections for example from the x values/elements from the domain to one y value from the codomain (vice versa) then the function is NOT
the surjection class means that each x value/element in the domain of the 2d coordinate system has AT LEAST ONE (but can have multiple, most often two) corresponding values/elements in the codomain.
the bijection function class represents the injection and surjection combined, both
If a function is neither
Horizontal lines
Vertical lines are test which
https://programmingcroatia.com/2016/02/11/math-functions-classes-injections-surjection-bijection/
- A function
f is called f B co-domain ofis called f f a it is written f ( f f is written f .
Terms related to functions:
Domain and co-domain
Range
Image and Pre-Image
https://www.geeksforgeeks.org/functions-properties-and-types-injective-surjective-bijective/
- (If we want to encode information without losing data, we need to make sure that no two keys map to the same value, i.e. the mapping has to be
injective -- --
https://www.southampton.ac.uk/~
- Go vs. Python
The true strength of Go is that it's succinct and minimalistic and fast
Go is much more verbose than Python. It just takes so much more lines to say the same thing.
Go doesn't have the concept of "
Go gives you
I love the little defer
Everything about Go
https://www.peterbe.com/plog/govspy
- Differences Between To Python vs Go
Python is a general-purpose programming language
Python supports multiple programming paradigms and comes up with a large standard library, paradigms included are object-oriented, imperative, functional and procedural.
the most wanted scripting language in modern software development which varies from infrastructure management to data analysis
Go supports multi-paradigm like
Most of the features about Go and its tools follow the UNIX pattern
You don’t have to compile your Go code to run it. It will
Although Go is not a scripting language like Python but people
Go can act as a
In many use cases, Go web development has proved to be more rapid than Python.
Concurrency is very different between Python and Go. Python includes lots of solid concurrency libraries but
Key Differences Between Python vs Go
Python being a scripting language has to
Python does not provide built-in concurrency mechanism whereas Go has
Python is less verbose than Go to achieve the same functionality.
Python is still a favorite language
Python
Python is great for basic programming, using it can become complicated if one wishes to build complex systems whereas, with Go, the same task can
Both Python and Go can
Python can
https://www.educba.com/python-vs-go/
- the main 5 reasons
why we choose Go over Python Django
#1 It Compiles Into Single Binary
Golang built as a compiled language
sing static linking it
#2 Static Type System
Go will let you know about this issue during compile time as a compiler error
#3 Performance
in most of the application cases Go is faster than Python (2 and 3)
For our case Go performed better because of his concurrency model and CPU scalability
Whenever we need to process some internal request we are doing it with separate
#4 You Don’t Need Web Framework For Go
For example it has http,
#5 Great IDE support and debugging
We got about 30% more performance on our Backend and API services. And now we can handle logging real time, transfer it to
https://hackernoon.com/5-reasons-why-we-switched-from-python-to-go-4414d5f42690
- A virtual environment is a way of giving each of your Python projects a separate and isolated world to run in, with its own version of Python and installed libraries.
Using a Virtual Environment
When working at the command line, you can put the virtual environment's "bin" directory first on your PATH, what we call "activating" the environment, and from then on, anytime you run python, you'll be running in the environment
#!/
By using the "/
Virtual environments provide a "bin/activate" script
https://www.caktusgroup.com/blog/2016/11/03/managing-multiple-python-projects-virtual-environments/
- Consider the following scenario where you have two projects: ProjectA and ProjectB, both of which have a dependency on the same library, ProjectC. The problem becomes
apparent when westart requiring different versions of ProjectC. Maybe ProjectA needs v1.0.0, while ProjectB requires the newer v2.0.0, for example.
This is a real problem for Python since it can’t differentiate between versions in the site-packages directory. So both v1.0.0 and v2.0.0 would
Since
What Is a Virtual Environment?
This means that each project can have its own dependencies, regardless of what dependencies every other project has
The great thing about this is that there are no limits to the number of environments you can have since they’re just directories containing a few scripts.
created using the
Using Virtual Environments
if you’re not using Python 3, you’ll want to install the
pip install
If you are using Python 3, then you should already have the
Start by making a new directory to work with:
$
Create a new virtual environment inside the directory:
# Python 2:
$
# Python 3
$ python3 -
By default, this will
The Python 3
More interesting are the activate scripts in the bin directory.
$ source
(
Let’s say we have
Before we test this, we need to go back to the “system” context by executing deactivate
(
$
Now your shell session is back to normal, and the python command refers to the global Python
Now, install
$ pip -
$ python -c "import
$2b$12$vWa/
if we try the same command when the virtual environment
$ source
(
In one instance, we have
let’s first check out the locations of the different python executables. With the environment “deactivated,”
$ which python
/
activate it and run the command again
$ source
(
deactivated
$ echo $PATH
activated
$ source
(
What’s the difference between these two executables
This can
How is the virtual environment’s Python executable able to use something other than the system’s site-packages?
The path
Managing Virtual Environments With
It’s just some wrapper scripts around the main
Organizes all of your virtual environments in one location
Provides methods to help you easily create, delete, and copy environments
Provides a single command to switch between environments
download the wrapper with pip
$ pip install
$ which
start a new project
$
(my-new-project) $
stop using that environment
(my-new-project) $ deactivate
$
list environments
$
my-new-project
my-
web-scraper
$
(web-scraper) $
create a new Python 3 environment
$
substitute python3 for python2 (or python if you system defaults to python2).
Using Different Versions of Python
Unlike the old
There are quite a few ways to install Python, but few of them are easy enough or flexible enough
This is where
Despite the similarity in names (
https://realpython.com/python-virtual-environments-a-primer/
- How to use Python
virtualenv
What is
A Virtual Environment is an isolated working copy of Python which
allows you to work on a specific project without worry of affecting other projects
It enables multiple side-by-side installations of Python
It doesn’t
it
packages directory
What did
Packages installed here will not affect the global Python installation.
It uses links to global environment files instead of
speed up your
Therefore, there must already have an active python environment installed on your
system.
You don't have to use
/lib/python2.7/site-packages directory
https://www.pythonforbeginners.com/basics/how-to-use-python-virtualenv/
virtualenvwrapper shouldbe installed into the same global site-packages area wherevirtualenv is installed . You may need administrative privileges to do that.
https://virtualenvwrapper.readthedocs.io/en/latest/install.html
- The headaches of dependency management are common to developers. One errant update requires hours of research to correct. Often multiple applications overlap on library dependency requirements. This could cause two applications running in the same environment to require
two version of the same library. These type of conflicts could causea number of issues both in development and production. EnterVirtualenv .Virtualenv is a tool that creates dependency silos. It allows you to deploy applications to a single environment with isolated dependencies. Dockeremploys a similar strategy at the OS level.Virtualenv segregates only at the Python and library level — that is, the environments Python executable and libraries are unique to that virtual environment. So instead of using the libraries installed at the OS environment level, you can separate Python versions and libraries intosiloed virtual environments. This allows you to deploy multiple applications in the same OS environment with different versions of the same dependencies.
https://linuxhint.com/python-virtualenv-tutorial/
- The
venv module provides support for creating lightweight “virtual environments” with their own site directories, optionally isolated from system site directories. Each virtual environment has its own Python binary (which matches the version of the binary thatwas used to create this environment) and can have its own independent set of installed Python packages in its site directories.
https://docs.python.org/3/library/venv.html
- pip
Let's dive in. pip is a tool for installing Python packages from the Python Package Index.
PHP's Packagist ,
CPAN for Perl, and
NPM for Node.js.
Python actually has another, more primitive, package manager called easy_install , which is installed automatically when you install Python itself
How does virtualenv help?
Usually pip and virtualenv are the only two packages you ever need to install globally, because once you've got both of these you can do all your work inside virtual environments.
In fact, virtualenv comes with a copy of pip which gets copied into every new environment you create, so virtualenv is really all you need
How do I use my shiny new virtual environment?
The one you care about the most is bin . This is where the local copy of the python binary and the pip installer exists
Instead of typing env /bin/python and env /bin/pip every time, we can run a script to activate the environment.
Requirements files
https://www.dabapps.com/blog/introduction-to-pip-and-virtualenv-python/
- Installing
Pipenv
Lower level:
https://docs.python-guide.org/dev/virtualenvs/
- Logically, a Requirements file is just a list of pip install arguments placed in a file.
there are 4 common uses of Requirements files:
1-Requirements files
2-Requirements files
3-Requirements files
4-Requirements files
Constraints Files
Constraints files are requirements files that only control
One way to ensure that
Constraints files offer a better way: write a single constraints file for your organisation and use that everywhere. If the thing being installed requires “
https://pip.pypa.io/en/latest/user_guide/#requirements-files
- Installing Python Modules
Alternate Installation
Often, it is necessary or desirable to install modules to a location other than the standard location for third-party Python modules. For example, on a Unix system you might not have permission to write to the standard third-party module directory.
Or you might wish to try out a module before making it a standard part of your local Python installation. This is especially true when upgrading a distribution already present: you want to make sure your existing base of scripts still works with the new version before actually upgrading.
Note that the various alternate installation schemes are mutually exclusive: you can pass -- user, or -- home, or -- prefix and -- exec-prefix, or -- install-base and -- install-platbase , but you can’t mix from these groups.
Alternate installation: the user scheme
https://docs.python.org/3/install/index.html#alternate-installation-the-user-scheme
- User Installs
With Python 2.6 came the “user scheme” for installation, which means that all Python distributions support an alternative install location that is specific to a user. The default location for each OS is explained in the python documentation for the site. USER_BASE variable. This mode of installation can be turned on by specifying the – user option to pip install.
Pinned Version Numbers
Pinning the versions of your dependencies in the requirements file protects you from bugs or incompatibilities in newly released versions:
https://pip.pypa.io/en/latest/user_guide/#requirements-files
OpenCanary is a daemon that runs several canary versions of services that alerts when a service is (ab ) used .
Prerequisites
Python 2.7
[Optional] SNMP requires the python library
[Optional] RDP requires the python library
[Optional] Samba module needs a working installation of samba
Installation on Ubuntu:
$
$
$
$ pip install
$ pip install
https://github.com/thinkst/opencanary
- JSON supports primitive types, like strings and numbers,
as well as nested lists and objects.
Python Supports JSON Natively
https://realpython.com/python-json/
JSONPlaceholder
Fake Online REST API for Testing and Prototyping
https://jsonplaceholder.typicode.com
jq is a fast, lightweight, flexible, CLI JSON processor.jq stream-processes JSON likeawk stream processes text.jq , coupled withcURL ,
http://blog.librato.com/posts/jq-json
- The
json module enables you to convert between JSON and Python Objects.
https://pythonspot.com/json-encoding-and-decoding-with-python/
- JSON stands for JavaScript Object notation and is an open standard human readable data format.
Popular alternatives to JSON are YAML and XML.
An empty JSON file
https://codingnetworker.com/2015/10/python-dictionaries-json-crash-course/
Gensim is a FREE Python library
Scalable statistical semantics
Analyze plain-text documents for semantic structure
https://radimrehurek.com/gensim/
statsmodels is a Python module that provides classes and functions for the estimation ofmany different statistical models,as well as for conducting statistical tests, and statistical data exploration
http://www.statsmodels.org/stable/index.html
Nilearn is a Python module for fast and easy statistical learning onNeuroImaging data.
https://nilearn.github.io/
- Numenta Platform for Intelligent Computing is an implementation of Hierarchical Temporal Memory (HTM), a theory of intelligence based strictly on the neuroscience of the neocortex
https://numenta.org/
PyMC is a python module that implements Bayesian statistical models and fitting algorithms, including Markov chain Monte Carlo.
https://pymc-devs.github.io/pymc/README.html
NumPy , which stands for Numerical Python, is a libraryconsisting of multidimensional array objects and a collection of routines for processing those arrays. UsingNumPy , mathematical and logicaloperations on arrays can be performed .
https://www.tutorialspoint.com/numpy/index.htm
- Using
NumPy , a developer can perform the following operations −
Mathematical and logical operations on arrays.
Fourier transforms and routines for shape manipulation.
Operations related to linear algebra.
https://www.tutorialspoint.com/numpy/numpy_introduction.htm
- Standard Python distribution doesn't come bundled with NumPy module. A lightweight alternative is to install NumPy using popular Python package installer, pip.
The best way to enable NumPy is to use an installable binary package specific to your operating system. These binaries contain full SciPy stack (inclusive of NumPy, SciPy,
https://www.tutorialspoint.com/numpy/numpy_environment.htm
NumPy ’s main object is the homogeneous multidimensional array. It is a table of elements (usually numbers),all of the same type, indexed by a tuple of positive integers. InNumPy dimensionsare called axes.
https://docs.scipy.org/doc/numpy-1.15.1/user/quickstart.html
- SymPy is a computer algebra system written in the Python programming language. Among its many features are algorithms for computing derivatives, integrals, and limits; functions for manipulating and simplifying expressions; functions for symbolically solving equations and ordinary and partial differential equations; two- and three-dimensional (2D and 3D) plotting
http://www.admin-magazine.com/HPC/Articles/Symbolic-Mathematics-with-Python-s-SymPy-Library
- Python is a great general-purpose programming language on its own, but with the help of a few popular libraries (
numpy ,scipy ,matplotlib ) it becomes a powerful environment for scientific computing.
http://cs231n.github.io/python-numpy-tutorial/
NumPy is an open source library available in Python that aids in mathematical, scientific, engineering, and data science programming
For any scientific project,
In this part, we will review the essential functions
https://www.guru99.com/numpy-tutorial.html
- SciPy, a scientific library for Python is an open source, BSD-licensed library for mathematics, science and engineering. The SciPy library depends on
NumPy , which providesconvenient and fast N-dimensional array manipulation
https://www.tutorialspoint.com/scipy/s
- Nose Testing - Framework
https://www.tutorialspoint.com/unittest_framework/nose_testing_framework.htm
- Nose’s tagline is “nose extends unit test to make testing easier
” .
http://pythontesting.net/framework/nose/nose-introduction/
- Beautiful Soup is a Python library for pulling data out of HTML and XML files.
One common task is extracting all the URLs found within a page’s 'a' tags
Another common task is extracting all the text from a page
let's grab all the links from Reddit
https://www.pythonforbeginners.com/beautifulsoup/beautifulsoup-4-python
Scrapy is an application framework for crawling web sites and extracting structured datawhich can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Even though
https://scrapy.readthedocs.io/en/latest/intro/overview.html
- Django
Django is a high-level Python Web framework that encourages rapid development and clean, pragmatic design.
https://www.djangoproject.com/
- web2py
Free open source full-stack framework for rapid development of fast, scalable, secure and portable database-driven web-based applications.
Written and programmable in Python.
http://www.web2py.com/
- The Python SQL Toolkit and Object Relational Mapper
It provides a full suite of well known enterprise-level persistence patterns, designed for efficient and high-performing database access, adapted into a simple and
https://www.sqlalchemy.org/
- Distributed Evolutionary Algorithms in Python
DEAP is a novel evolutionary computation framework for rapid prototyping and testing
ideas. It seeks to make algorithms explicit and data structures transparent.
https://pypi.org/project/deap/
Gunicorn
http://gunicorn.org/
- Asynchronous HTTP Client/Server for
asyncio and Python.
https://aiohttp.readthedocs.io/en/stable/
- Why do I need Anaconda Distribution?
of Python to run, and it's difficult to keep them from interacting with each other. It is even
harder to keep them updated. Anaconda Distribution makes getting and maintaining
these packages quick and easy
What is
Anaconda Distribution?
It is an open source, easy-to-install high performance Python and R distribution, with the
with free community support.
what is Miniconda
It’s Anaconda Distribution without the collection of 1,000+ open source packages.
With
Example:
http://docs.anaconda.com/_downloads/Anaconda-Starter-Guide-Cheat-Sheet.pdf
- There are two variants of the installer: Miniconda is Python 2 based and Miniconda3 is Python 3 based. Note that the choice of which
Miniconda is installed only affects the root environment. Regardless of which version of Miniconda you install, you can still install both Python 2. x and Python 3. x environments.
- Choose Anaconda if you:
Are new to
Like the convenience of having Python and over 150 scientific packages automatically installed at once.
Have the time and disk space—a few minutes and 300 MB.
Do not want
Choose
Do not mind installing each of the packages you want to use individually.
Do not have time or disk space to install over 150 packages at once.
Want fast access to Python and the
GUI versus command line installer
Both GUI and command line installers are available for Windows,
If you do not wish to enter commands in a Terminal window, choose the GUI installer.
If GUIs slow you down, choose the
Choosing a version of Python
The last version of Python 2 is 2.7,
The newest stable version of Python is 3.6,
You can easily set up additional versions of Python such as 3.5 by downloading any version and creating a new environment with just a few clicks
https://conda.io/docs/user-guide/install/download.html#choosing-a-version-of-python
- Anaconda Distribution
With over 6 million users, the open source Anaconda Distribution is the fastest and easiest way to do Python and R data science and machine learning on Linux, Windows, and Mac OS X. It's the industry standard for developing, testing, and training on a single machine.
https://www.anaconda.com/what-is-anaconda/
- Easily install 1,400+ data science packages for Python/R and manage your packages, dependencies, and
environments—all with the single click of a button. Free and open source
https://www.anaconda.com/distribution/
- Anaconda is an open-source package manager, environment manager, and distribution of the Python and R programming languages.
Anaconda offers a collection of over 720 open-source
Installing Anaconda
The best way to install Anaconda is to download the latest Anaconda installer bash script, verify it, and then run it.
Setting Up Anaconda Environments
Anaconda virtual environments allow you to keep projects organized by Python versions and packages needed.
For each Anaconda environment you set up, you can specify which version of Python to use and can keep all of your related programming files together within that directory.
Since we are using the Anaconda with Python 3 in this tutorial, you will have access only to the Python 3 versions of packages.
copy the hash from the site
echo "HASH GOES HERE" >
sha256sum Anaconda3-5.0.1-Linux-x86_64.
[optional] less
cat
Comments:
1 -
2 - this creates
3 - this runs the checksum, but then pipes (passes) that result to the
4 - [optional] this just displays the contents of the file so you can give it the eye test.
5 - if you don't trust your eyes with those long hash strings, even when mashed together in the file, run this command. this passes the contents of the file to check uniqueness, by line. The output is thus: 1 == they match, 2 == they do not match, and
https://www.digitalocean.com/community/tutorials/how-to-install-the-anaconda-python-distribution-on-ubuntu-16-04
- Package, dependency and environment management for any language—Python, R, Ruby, Lua, Scala, Java, JavaScript, C/ C++, FORTRAN
Conda is an open source package management system and environment management system that runs on Windows,
Conda quickly installs, runs and updates packages and their dependencies.
Conda easily creates, saves, loads and switches between environments on your local computer.
It was created for Python programs, but it can package and distribute software for any language
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because conda is also an environment manager. With just a few commands, you can set up a totally separate environment to run that different version of Python, while continuing to run your usual version of Python in your normal environment.
Conda can be combined with continuous integration systems such as Travis CI and AppVeyor to provide frequent, automated testing of your code.
Conda is also available on PyPI
s
https://conda.io/docs/index.html
- Package, dependency and environment management for any language—Python, R, Ruby, Lua, Scala, Java, JavaScript, C/ C++, FORTRAN
Conda easily creates, saves, loads and switches between environments on your local computer
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because conda is also an environment manager.
https://conda.io/docs/
- The
Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more
http://jupyter.org/
- IntelliJ IDEA Community Edition is the open source version of IntelliJ IDEA, an IDE (Integrated Development Environment) for Java, Groovy and other programming languages such as Scala or Clojure. It is made by JetBrains, maker of PyCharm Python IDE.
http://docs.anaconda.com/anaconda/user-guide/tasks/integration/intellij/
- Eclipse and PyDev
After you have Eclipse, PyDev, and Anaconda installed, set Anaconda Python as your default:
http://docs.anaconda.com/anaconda/user-guide/tasks/integration/eclipse-pydev/
- Python for Visual Studio Code
If you’ve installed Anaconda as your default Python installation and installed Python for Visual Studio Code, your VSC installation is already set to use Anaconda’s Python interpreter.
http://docs.anaconda.com/anaconda/user-guide/tasks/integration/python-vsc/
- Spyder, the Scientific PYthon Development EnviRonment, is a free integrated development environment (IDE) that is included with Anaconda. It includes editing, interactive testing, debugging and introspection features.
- R is one of the most popular languages in the world for data science. Built specifically for working with data, R provides an intuitive interface to the most advanced statistical methods available today. Here are a few highlights of the language:
- Installation of Python, Spyder, Numpy, Sympy, Scipy, Pytest, Matplotlib via Anaconda (2016)
we suggest to use the Anaconda Python distribution.
numpy (NUMeric Python): matrices and linear algebra
scipy (SCIentific Python): many numerical routines
matplotlib: (PLOTting LIBrary) creating plots of data
sympy (SYMbolic Python): symbolic computation
pytest (Python TESTing): a code testing framework
The packages numpy, scipy and matplotlib are building stones of computational work with Python and extremely widely spread.
Sympy has a special role as it allows SYMbolic computation rather than numerical computation.
The pytest package and tool supports regression testing and test driven development -- this is generally important, and particularly so in best practice software engineering for computational studies and research.
Spyder (home page) is s a powerful interactive development environment for the Python language with advanced editing, interactive testing, debugging and introspection features.
The name SPYDER derives from "Scientific PYthon Development EnviRonment" (SPYDER).
Useful features include
provision of the IPython (Qt) console as an interactive prompt, which can display plots inline
ability to execute snippets of code from the editor in the console
continuous parsing of files in editor, and provision of visual warnings about potential errors
step-by-step execution
variable explorer
Anaconda is one of several Python distributions. Python distributions provide the Python interpreter, together with a list of Python packages and sometimes other related tools, such as editors.
Running the tests with Spyder
http://www.southampton.ac.uk/~fangohr/blog/installation-of-python-spyder-numpy-sympy-scipy-pytest-matplotlib-via-anaconda.html
How to Install sklearn, numpy, & scipy with Anaconda on Windows 10 64-bit
Jupyter Notebook Tutorial: Introduction, Setup, and Walkthrough
- What Is A Jupyter Notebook?
In this case, "notebook" or "notebook documents" denote documents that contain both code and rich text elements, such as figures, links, equations,
the ideal place to bring together an analysis description and its results as well as they can be executed perform the data analysis in real time.
"Jupyter" is a loose acronym meaning Julia, Python, and R. These programming languages were the first target languages of the Jupyter application
What Is The Jupyter Notebook App?
As a server-client application, the Jupyter Notebook App allows you to edit and run your notebooks via a web browse
Its two main components are the kernels and a dashboard.
A kernel is a program that runs and introspects the user’s code. The Jupyter Notebook App has a kernel for Python code, but there are also kernels available for other programming languages.
Project Jupyter started as a spin-off project from IPython. IPython is now the name of the Python backend, which is also known as the kernel.
How To Install Jupyter Notebook
Running Jupyter Notebooks With The Anaconda Python Distribution
Running Jupyter Notebook The Pythonic Way: Pip
Running Jupyter Notebooks in Docker Containers
To run the official Jupyter Notebook image in your Docker container, give in the following command in your Docker Quickstart Terminal:
docker run --rm -it -p 8888:8888 -v "$(pwd):/notebooks" jupyter/notebook
The "Files" tab is where all your files are kept, the "Running" tab keeps track of all your processes and the third tab, "Clusters", is provided by IPython parallel, IPython's parallel computing framework. It allows you to control many individual engines, which are an extended version of the IPython kernel.
Toggling Between Python 2 and 3 in Jupyter Notebooks
# Python 2.7
conda create -n py27 python=2.7 ipykernel
# Python 3.5
conda create -n py35 python=3.5 ipykernel
source activate py27
source deactivate
https://www.datacamp.com/community/tutorials/tutorial-jupyter-notebook
- One of the most common question people ask is which IDE / environment / tool to use, while working on your data science projects
there is no dearth of options available – from language specific IDEs like R Studio, PyCharm to editors like Sublime Text or Atom
Jupyter Notebooks (previously known as iPython notebooks as well)
Jupyter Notebooks allow data scientists to create and share their documents, from codes to full blown reports.
Jupyter Notebook is an open-source web application that allows us to create and share codes and documents.
It provides an environment, where you can document your code, run it, look at the outcome, visualize data and see the results without leaving the environment
This makes it a handy tool for performing end to end data science workflows – data cleaning, statistical modeling, building and training machine learning models, visualizing data
Jupyter Notebooks really shine when you are still in the prototyping phase. This is because your code is written in indepedent cells, which are executed individually. This allows the user to test a specific block of code in a project without having to execute the code from the start of the scrip
allow you to run other languages besides Python, like R, SQL, etc
How to install Jupyter Notebook
you need to have Python installed on your machine first. Either Python 2.7 or Python 3.3 (or greater)
For new users, the general consensus is that you should use the Anaconda distribution to install both Python and the Jupyter notebook.
Anaconda installs both these tools and includes quite a lot of packages commonly used in the data science and machine learning community.
The pip method
you decide not to use Anaconda, then you need to ensure that your machine is running the latest pip version.
Jupyter notebook will open up in your default web browser with the below URL
http://localhost:8888/tree
You can even use other languages in your Notebook, like R, Julia, JavaScript, etc
JupyterLab enables you to arrange your work area with notebooks, terminals, text files and outputs – all in one window
https://www.analyticsvidhya.com/blog/2018/05/starters-guide-jupyter-notebook/
- IPython notebooks (more recently known as Jupyter notebooks) for the programming assignments. An IPython notebook lets you write and execute Python code in your web browser. IPython notebooks make it very easy to tinker with code and execute it in bits and pieces; for this reason IPython notebooks are widely used in scientific computing.
http://cs231n.github.io/ipython-tutorial/
- Start IPython by issuing the ipython command from your shell, you should be greeted by the following:
Unlike the Python REPL, you will see that the input prompt is In [N]: instead of >>>.
https://ipython.readthedocs.io/en/stable/interactive/tutorial.html
- The R Notebook Versus The Jupyter Notebook
Notebook Sharing
The source code for an R Markdown notebook is an .Rmd file.
when you save a notebook, an .nb.html file is created alongside it.
This HTML file is an associated file that includes a copy of the R Markdown source code and the generated output.
You can publish your R Markdown notebook on any web server, GitHub or as an email attachment.
To share the notebooks you make in the Jupyter application, you can export the notebooks as slideshows, blogs, dashboards, etc
Code Execution
when you’re working with R because the R Markdown Notebook allows all R code pieces to share the same environment. However, this can prove to be a huge disadvantage if you’re working with non-R code pieces, as these don’t share environments.
in the Jupyter application,The code environment is shared between code cells.
Version control
The R Markdown notebooks seem to make this issue a bit easier to handle, as they have associated HTML files that save the output of your code and the fact that the notebook files are essentially plain text files, version control will be much easier. You can choose to only put your .Rmd file on GitHub or your other versioning system, or you can also include the .nb.html file.
Project Management
the Jupyter project is not native to any development kit: in that sense, it will cost some effort to integrate this notebook seamlessly with your projects.
https://www.datacamp.com/community/blog/jupyter-notebook-r#compare
- R includes a powerful and flexible system (Sweave) for creating dynamic reports and reproducible research using LaTeX. Sweave enables the embedding of R code within LaTeX documents to generate a PDF file that includes narrative and analysis, graphics, code, and the results of computations.
knitr is an R package that adds many new capabilities to Sweave and is also fully supported by RStudio.
To use Sweave and knitr to create PDF reports, you will need to have LaTeX installed on your system. LaTeX can be installed following the directions on the LaTeX project page.
https://support.rstudio.com/hc/en-us/articles/200552056-Using-Sweave-and-knitr
- Use R Markdown to publish a group of related data visualizations as a dashboard.
https://rmarkdown.rstudio.com/flexdashboard/
- Write HTML, PDF, ePub, and Kindle books with R Markdown
https://bookdown.org/
- A dashboard has three parts: a header, a sidebar, and a body. Here’s the most minimal possible UI for a dashboard page.
https://rstudio.github.io/shinydashboard/get_started.html
- Python(x,y) is a free scientific and engineering development software for numerical computations, data analysis and data visualization based on Python programming language, Qt graphical user interfaces and Spyder interactive scientific development environment.
https://python-xy.github.io/
- Anaconda: A free distribution of Python with scientific packages. Supports Linux, Windows and Mac.
Enthought Canopy: The free and commercial versions include the core scientific packages. Supports Linux, Windows and Mac.
Python(x,y): A free distribution including scientific packages, based around the Spyder IDE. Windows and Ubuntu; Py2 only.
WinPython: Another free distribution including scientific packages and the Spyder IDE. Windows only, but more actively maintained and supports the latest Python 3 versions.
Pyzo: A free distribution based on Anaconda and the IEP interactive development environment. Supports Linux, Windows and Mac.
https://scipy.org/install.html
- Spyder is an Integrated Development Environment (IDE) for scientific computing, written in and for the Python programming language. It comes with an Editor to write code, a Console to evaluate it and view the results at any time, a Variable Explorer to examine the variables defined during evaluation
http://www.southampton.ac.uk/~fangohr/blog/spyder-the-scientific-python-development-environment.html
- Anaconda, Jupyter Notebook, TensorFlow and Keras for Deep Learning
There are different ways of installing TensorFlow:
“native” pip or install from source
install in a virtual environment with Virtualenv, Anaconda, or Docker.
Anaconda will enable you to create virtual environments and install packages needed for data science and deep learning. With virtual environments you can install specific package versions for a particular project or a tutorial without worrying about version conflicts.
Conda is a package manager to manage virtual environment and install packages.
Conda vs Pip install
You can use either conda or pip for installation in an virtual environment created with conda.
https://medium.com/@margaretmz/anaconda-jupyter-notebook-tensorflow-and-keras-b91f381405f8
- IronPython is an open-source implementation of the Python programming language which is tightly integrated with the .NET Framework. IronPython can use the .NET Framework and Python libraries, and other .NET languages can use Python code just as easily.
http://ironpython.net/
- Jython: Python for the Java Platform
How to use Java from Jython?
Using Java from Jython is as simple as importing the Java package that you'd like to use.
There are a variety of ways to use Jython from within Java. Perhaps the most widely used solution is to create an object factory in Java that coerces the Jython object into Java code. There are a multitude of ways create such a factory. Object factories can be created one-to-one with Jython classes, or they can be more loosely-coupled such that one factory implementation would work for any Jython object
http://www.jython.org
- PyPy is a fast, compliant alternative implementation of the Python language (2.7.13 and 3.5.3). It has several advantages and distinct features:
http://pypy.org/
- tox aims to automate and standardize testing in Python. It is part of a larger vision of easing the packaging, testing and release process of Python software.
automatic customizable (re)creation of virtualenv test environments
installs your setup.py based project into each virtual environment
test-tool agnostic: runs pytest, nose or unittests in a uniform manner
Basic example
First, install tox with pip install tox. Then put basic information about your project and the test environments you want your project to run in into a tox.ini file residing right next to your setup.py file:
You can also try generating a tox.ini file automatically, by running tox-quickstart and then answering a few simple questions.
Invoke is a general-purpose task execution library, similar to Make. Invoke is far more general-purpose than tox but it does not contain the Python testing-specific features that tox specializes in.
Nox is a project similar in spirit to tox but different in approach. Nox’s key difference is that it uses Python scripts instead of a configuration file. Nox might be useful if you find tox’s configuration too limiting but aren’t looking to move to something as general-purpose as Invoke or Make.
https://tox.readthedocs.io/en/latest/
- tox is a generic virtualenv management and test command line tool you can use for:
- checking your package installs correctly with different Python versions and interpreters
- running your tests in each of the environments, configuring your test tool of choice
- acting as a frontend to Continuous Integration servers, greatly reducing boilerplate and merging CI and shell-based testing.
This is a really simple example, envlist in the tox section specifies that we want to run the commands of the testenv section against two versions of python, in the example, our targets are 2.7 and 3.5. Tox will work by creating a separate virtualenv for each version and installing our package in both of them.
https://medium.com/@alejandrodnm/testing-against-multiple-python-versions-with-tox-9c68799c7880
- However, it repeats a section (the list of available environments) from my tox.ini file, which is sad. I could get around this by giving up having individual build jobs, or by just saying that I’ll fix the file when I add an environment to tox to test.
https://www.dominicrodger.com/2013/07/26/tox-and-travis/
- setup.py is the build script for setuptools.
https://packaging.python.org/tutorials/packaging-projects/#setup-py
- Avoiding expensive sdist
Some projects are large enough that running an sdist, followed by an install every time can be prohibitively costly. To solve this, there are two different options you can add to the tox section. First, you can simply ask tox to please not make an sdist:
https://tox.readthedocs.io/en/latest/example/general.html#avoiding-expensive-sdist
- envlist(comma separated values)
Determining the environment list that tox is to operate on happens in this order (if any is found, no further lookups are made):
command line option -eENVLIST
environment variable TOXENV
tox.ini file’s envlist
https://tox.readthedocs.io/en/latest/config.html
- KNIME makes understanding data and designing data science workflows and reusable components accessible to everyone.
KNIME Analytics Platform is the open source software for creating data science applications and services.
Build end to end data science workflows
Open and combine simple text formats (CSV, PDF, XLS, JSON, XML, etc), unstructured data types (images, documents, networks, molecules, etc), or time series data
Leverage Machine Learning and AI
Build machine learning models for classification, regression, dimension reduction, or clustering, using advanced algorithms including deep learning, tree-based methods, and logistic regression.
https://www.knime.com/knime-software/knime-analytics-platform