- Gemini
Relational Databases
Structure: Data is organized into tables with rows and columns.
Relationships: Tables are linked through relationships (primary and foreign keys) to establish connections between data.
Data Integrity: Strong data integrity through ACID properties (Atomicity, Consistency, Isolation, Durability).
Query Language: SQL (Structured Query Language) is used for data manipulation and retrieval.
Examples: MySQL, PostgreSQL, Oracle, SQL Serve
Non-Relational Databases (NoSQL)
Structure: Data is stored in various models like key-value, document, columnar, or graph.
Flexibility: Highly flexible schema, accommodating diverse data types.
Scalability: Designed for handling large volumes of data and high traffic.
Performance: Often optimized for specific data access patterns.
Examples: MongoDB, Cassandra, Redis, Neo4
When to Use Which
Relational Databases:
Complex relationships between data
Strong data consistency requirements
ACID compliance is essential
Predictable data access patterns
Non-Relational Databases:
Large volumes of unstructured or semi-structured data
High write throughput and scalability
Rapid development needs
Flexible data models
In conclusion, the choice between relational and non-relational databases depends on the specific requirements of the application. Many modern applications use a combination of both to handle diverse data needs effectively
ChatGPT
1. Data Model
Relational Databases:
- Structure: Data is organized into tables (relations) with rows and columns. Each table represents an entity, and columns represent attributes of that entity.
- Schema: A predefined schema defines the structure of the tables, including data types and constraints. The schema must be established before data is inserted.
Non-Relational Databases:
- Structure: Data is stored in various formats, including key-value pairs, documents, wide-columns, or graphs, depending on the type of non-relational database.
- Schema: Schemas are flexible or schema-less. Data can be stored without a fixed schema, allowing for dynamic and evolving data structures.
2. Query Language
Relational Databases:
- Language: Use SQL (Structured Query Language) for querying and managing data. SQL provides a powerful and standardized way to perform operations like querying, updating, and joining data.
Non-Relational Databases:
- Language: Use various query languages or APIs depending on the database type. For example, MongoDB uses BSON (Binary JSON) queries, while key-value stores may use simple key-based retrieval
3. Scalability
Relational Databases:
Non-Relational Databases:
4. Data Integrity and Transactions
Relational Databases:
- ACID Compliance: Generally adhere to ACID (Atomicity, Consistency, Isolation, Durability) principles to ensure data integrity and reliable transactions.
- Transactions: Support complex transactions involving multiple operations, ensuring that all operations within a transaction are completed successfully.
Non-Relational Databases:
- Eventual Consistency: Often use eventual consistency models rather than strict ACID compliance. They prioritize availability and partition tolerance, accepting that data may be temporarily inconsistent.
- Transactions: May have limited support for multi-document transactions, focusing instead on single-document operations or simple transactions.
5. Use Cases
Relational Databases:
- Use Cases: Well-suited for applications requiring complex queries, relationships between data, and strong data integrity. Examples include financial systems, CRM systems, and traditional enterprise applications.
Non-Relational Databases:
- Use Cases: Ideal for applications with rapidly changing data, high volumes of unstructured data, or requiring flexible schemas. Examples include content management systems, social media platforms, and real-time analytics.
6. Examples
Relational Databases:
Non-Relational Databases:
Summary
Relational Databases use a structured schema and SQL for managing data, excelling in scenarios requiring complex queries, strong data integrity, and consistent transactions. They typically scale vertically and are suited for traditional, well-defined data relationships.
Non-Relational Databases offer flexibility in schema design and scalability through horizontal distribution. They are designed for handling large volumes of unstructured or semi-structured data and are ideal for dynamic and rapidly changing applications where high availability is a priority.
Both types of databases have their unique advantages and are chosen based on specific application requirements and use cases.
NoSQL - What is
NoSQL
Next Generation Databases mostly addressing
The original intention has been modern web-scale databases.
Often more characteristics apply such
A NoSQL database provides a mechanism for storage and retrieval of data that use looser consistency models than traditional relational databases
NoSQL database systems are often highly optimized for retrieval and appending operations and often offer little functionality beyond record storage (e.g. key–value pairs stores)
Usage examples might be to store millions of key–value in one or a few associative arrays or
This organization is
The reduced run time flexibility compared to full SQL systems
With the rise of the real-time web, there was a need to provide information out of large volumes of data which more or less followed similar horizontal structures.
Often, NoSQL databases
Document store
The central concept of a document store is the notion of a "document".
While each document-oriented database implementation differs on the details of this definition
Graph
The
Key–value store
Key–value stores allow the application to store its data in a schema-less way.
http://en.wikipedia.org/wiki/NoSQL
- Database Transactions: ACID Atomicity
One atomic unit of work
– If one step fails, it all fails
• Consistency
– Works on a consistent set of data that
concurrently running transactions
– Data left in a clean and consistent state after completion
• Isolation• Isolation
– Allows multiple users to work concurrently with the same data
without compromising its integrity and correctness.
– A particular transaction should not be visible to other
running transactions.
• Durability
– Once completed all changes become
– Persistent changes not lost even if the system subsequently fails
Transaction Demarcation
What happens if you don’t call commit or rollback at the end of your transaction?
What happens depends on how the vendors
implement the specification.
– With Oracle JDBC drivers, for example, the call to close
the
– Most other JDBC vendors take the
pending transaction when the JDBC connection object is closed and
06-hibernate-
http://courses.coreservlets.com/Course-Materials/hibernate.html
- ACID (Atomicity, Consistency, Isolation, Durability)
- What is ACID in Database world?
- Atomicity: when a database processes a transaction, it is
In computer science, ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions
In
For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction.
Atomicity
Atomicity requires that each transaction is "all or nothing":
if one part of the transaction fails, the entire transaction fails, and
Consistency
The consistency property ensures that any transaction will bring the database from one valid state to another.
Any data written to the database must be valid according to all defined rules, including but not limited to constraints, cascades, triggers, and any combination thereof
Isolation
The isolation property ensures that the concurrent execution of transactions results in a system state that would
Durability
Durability means that once
http://en.wikipedia.org/wiki/ACID
Atomicity - "All or nothing"
Consistency -
Isolation - Multiple simultaneous transactions don't impact each other
Durability -
http://answers.yahoo.com/question/index?qid=1006050901996
Consistency
When a transaction results in invalid data, the database reverts to its previous state, which abides by all customary rules and constraints.
Isolation
Ensures that transactions are securely and independently processed at the same time without interference, but it does not ensure the order of transaction
For example, user A withdraws $100 and user B withdraws $250 from user Z’s account, which has a balance of $1000. Since both A and B draw from Z’s account,
Durability:
In the above example, user B may withdraw $100 only after user A’s transaction
If the system fails before
http://www.techopedia.com/definition/23949/atomicity-consistency-isolation-durability-acid
- Availability
- What is the CAP Theorem? The CAP theorem states that a distributed system cannot simultaneously be consistent, available, and partition tolerant
Consistency
Total partitioning, meaning failure of part of the system is rare. However, we could look at a delay, a latency, of the update between nodes, as a temporary partitioning. It will then cause a temporary decision between A and C:
On systems that allow reads before updating all the nodes, we will get high Availability
On systems that lock all the nodes before allowing reads, we will get Consistency
there's no distributed system that wants to live with "
https://dzone.com/articles/better-explaining-cap-theorem
Consistency
any read operation that begins after a write operation completes must return that value, or the result of a later write operation
Availability
every request received by a non-failing node in the system must
In an available system, if our client sends a request to a server
Partition Tolerance
The Proof
we can prove that a system cannot simultaneously have all three.
https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem
SQL vs. Hadoop: Acid vs. Base
Big Data and NoSQL (
- ACID versus BASE for database transactions
Big Data and NoSQL (
Database developers all know the ACID acronym.
Atomic: Everything in a transaction succeeds or
Consistent: A transaction cannot leave the database in an inconsistent state.
Isolated: Transactions cannot interfere with each other.
Durable: Completed transactions persist, even when servers restart
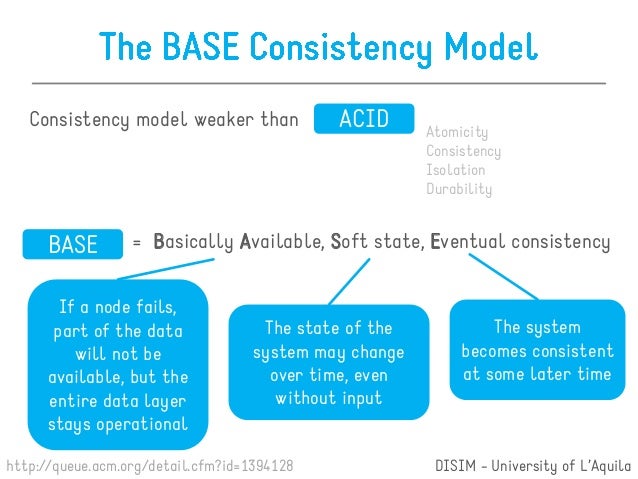
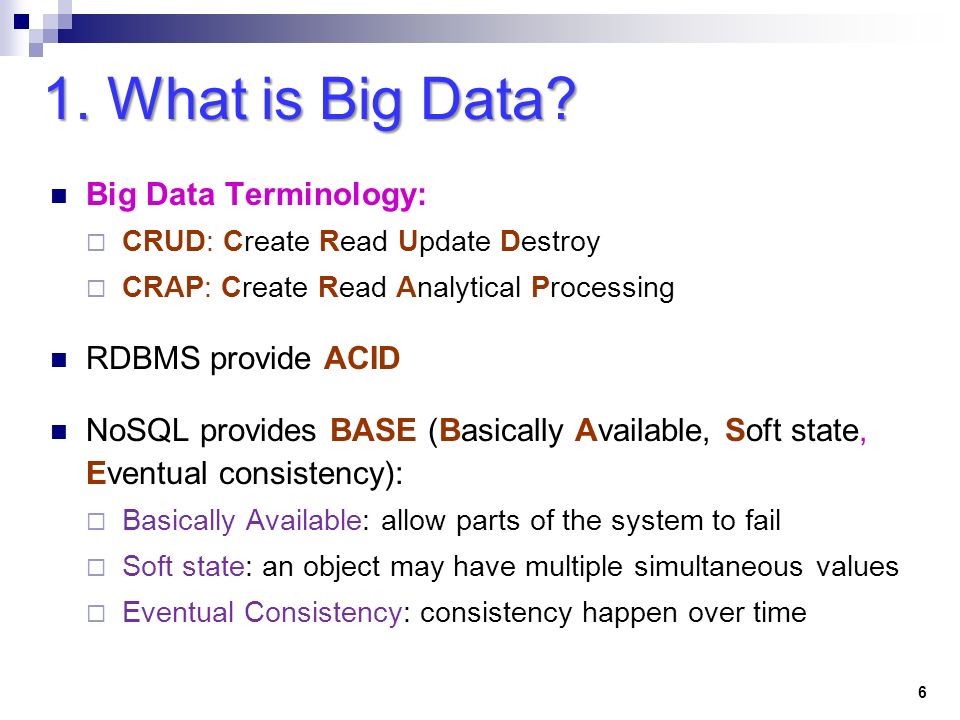
An alternative to ACID is BASE:
Basic Availability
Soft-state
Eventual consistency
ACID is incompatible with availability and performance in very large systems
For example, suppose you run an online
Every time someone is
That works well if you run The Shop Around the Corner but not if you run Amazon.com.
Rather than requiring consistency after every transaction, it is enough for the database
http://www.johndcook.com/blog/2009/07/06/brewer-cap-theorem-base/

- Myth: Eric Brewer On Why Banks Are BASE Not ACID - Availability Is Revenue
NoSQL - What is Basic Availability, Soft State and Eventual Consistency (BASE)









Myth: Money is important, so banks must use transactions to keep money safe and consistent, right?
Reality: Banking transactions are inconsistent, particularly for ATMs.
Your ATM transaction must go through so Availability is more important than consistency. If the ATM is
This is not a new problem for the financial industry.
They’ve never had consistency because historically they’ve never had perfect communication
Instead, the financial industry depends on auditing.
What accounts for the consistency of bank data is not the consistency of its databases but the fact that everything
If
ATMs are reorderable and can
http://highscalability.com/blog/2013/5/1/myth-eric-brewer-on-why-banks-are-base-not-acid-availability.html
- BASE means:
- Basic Availability
- Soft state
- Eventual consistency
- https://www.wisdomjobs.com/e-university/nosql-interview-questions.html
- In the past, when we wanted to store more data or increase our processing power, the common option was to scale vertically (get more powerful machines) or further optimize the existing code base. However, with the advances in parallel processing and distributed systems, it is more common to expand horizontally, or have more machines to do the same task in parallel
- If you ever worked with any
NoSQL NoSQL some of the - Presto is a high performance, distributed SQL query engine for big data.
We can already see a bunch of data manipulation tools in the Apache project like Spark, Hadoop, Kafka, Zookeeper and Storm. However, in order
CAP Theorem is a concept that a distributed database system can only have 2 of the 3: Consistency, Availability and Partition Tolerance.
Partition Tolerance
When dealing with modern distributed systems, Partition Tolerance is not an option. It’s a necessity. Hence, we have to trade between Consistency and Availability.
A system that is
Data records
High Consistency
performing a read operation will return the value of the most recent write operation causing all nodes to return the same data
High Availability
This condition states that every request gets a response on success/failure.
Every client gets a response, regardless of the state of any individual node in the system.
This metric is trivial to measure: either you can submit read/write commands, or you cannot
https://towardsdatascience.com/cap-theorem-and-distributed-database-management-systems-5c2be977950e
CAP stands for Consistency, Availability and Partition Tolerance.
Consistency (C
Availability (A): A guarantee that every request receives a response about whether it was successful or failed. Whether you want to read or write you will get
Partition tolerance (P): The system continues to operate despite arbitrary message loss or failure of part of the system. Irrespective of communication cut down among the nodes,
Often CAP theorem
P
https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4
The original intention has been modern web-scale databases.
Often more characteristics apply such
schema-free,
So the misleading term "
LIST OF NOSQL DATABASES
Core NoSQL Systems: [Mostly originated out of a Web 2.0 need]
Wide Column Store / Column Families
Hadoop / HBase API:
Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency:
Cassandra
massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency,
Document Store
MongoDB API:
BSON, Protocol: C, Query Method: dynamic object-based language & MapReduce, Replication: Master Slave & Auto-Sharding, Written in:
Elasticsearch API:
REST and many languages, Protocol: REST, Query Method: via JSON, Replication + Sharding: automatic and configurable, written in: Java,
JSON, Protocol: REST, Query Method:
Key Value /
Riak API:
JSON, Protocol: REST, Query Method: MapReduce term matching
Graph Databases
Java, Jini service discovery, Concurrency:
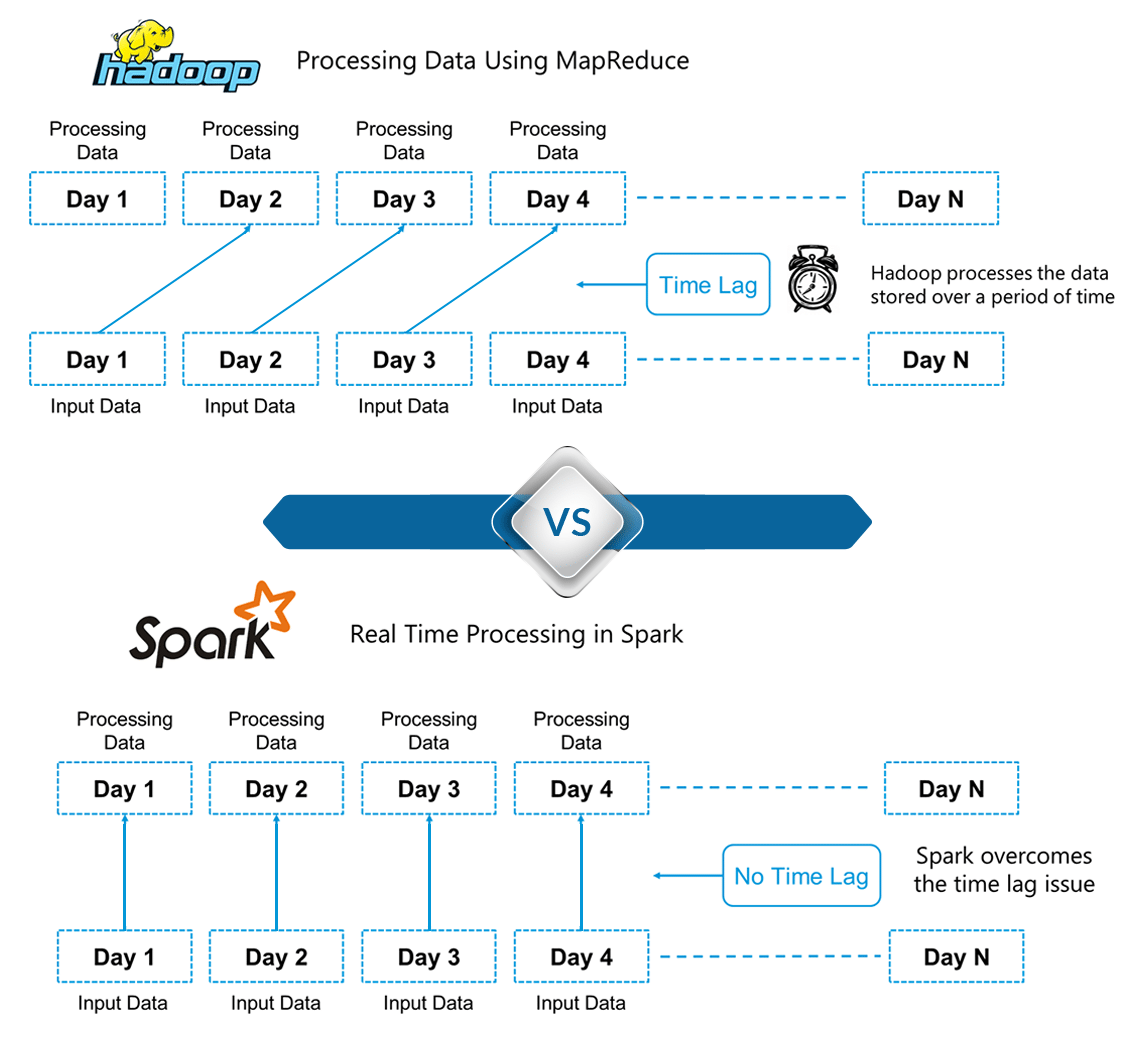


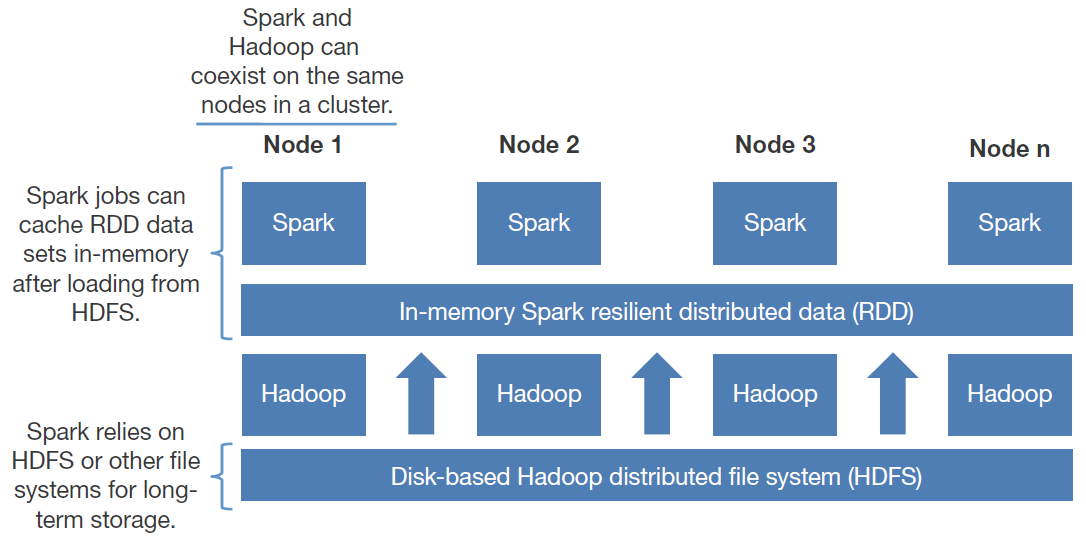


- Spark SQL is Apache Spark's module for working with structured data.
- Differences Between to Spark SQL vs Presto
- What is Database Mirroring?
- What is Database Mirroring?
- can be used to design high-availability and high-performance solutions for database redundancy.
- In database mirroring, transaction log records are sent directly from the principal database to the mirror database.
- This helps to keep the mirror database up to date with the principal database, with no loss of committed data.
- If the principal server fails, the mirror server automatically becomes the new principal server and recovers the principal database using a witness server under high-availability mode.
- Principal database is the active live database that supports all the commands, Mirror is the hot standby and witness which allows for a quorum in case of automatic switch over
- How does Database Mirroring works?
- In database mirroring, the transaction log records for a database are directly transferred from one server to another, thereby maintaining a hot standby server. As the principal server writes the database’s log buffer to disk, it simultaneously sends that block of log records to the mirror instance. The mirror server continuously applies the log records to its copy of the database. Mirroring is implemented on a per-database basis, and the scope of protection that it provides is restricted to a single-user database. Database mirroring works only with databases that use the full recovery model.
- What is a Principal server?
- Principal server is the server which serves the databases requests to the Application.
- What is a Mirror?
- This is the Hot standby server which has a copy of the database.
- What is a Witness Server?
- This is an optional server. If the Principal server goes down then Witness server controls the fail over process.
- What is Synchronous and Asynchronous mode of Database Mirroring?
- In synchronous mode, committed transactions are guaranteed to be recorded on the mirror server. Should a failure occur on the primary server, no committed transactions are lost when the mirror server takes over. Using synchronous mode provides transaction safety because the operational servers are in a synchronized state, and changes sent to the mirror must be acknowledged before the primary can proceed
- In asynchronous mode, committed transactions are not guaranteed to be recorded on the mirror server. In this mode, the primary server sends transaction log pages to the mirror when a transaction is committed. It does not wait for an acknowledgement from the mirror before replying to the application that the COMMIT has completed. Should a failure occur on the primary server, it is possible that some committed transactions may be lost when the mirror server takes over.
- What are the benefits of that Database Mirroring?
- Database mirroring architecture is more robust and efficient than Database Log Shipping.
- It can be configured to replicate the changes synchronously to minimized data loss.
- It has automatic server failover mechanism.
- Configuration is simpler than log shipping and replication, and has built-in network encryption support (AES algorithm)
- Because propagation can be done asynchronously, it requires less bandwidth than synchronous method (e.g. host-based replication, clustering) and is not limited by geographical distance with current technology.
- Database mirroring supports full-text catalogs.
- Does not require special hardware (such as shared storage, heart-beat connection) and cluster ware, thus potentially has lower infrastructure cost
- What are the Disadvantages of Database Mirroring?
- Potential data lost is possible in asynchronous operation mode.
- It only works at database level and not at server level.It only propagates changes at database level, no server level objects, such as logins and fixed server role membership, can be propagated.
- Automatic server failover may not be suitable for application using multiple databases.
- What are the Restrictions for Database Mirroring?
- A mirrored database cannot be renamed during a database mirroring session.
- Only user databases can be mirrored. You cannot mirror the master, msdb, tempdb, or model databases.
- Database mirroring does not support FILESTREAM. A FILESTREAM filegroup cannot be created on the principal server. Database mirroring cannot be configured for a database that contains FILESTREAM filegroups.
- On a 32-bit system, database mirroring can support a maximum of about 10 databases per server instance.
- Database mirroring is not supported with either cross-database transactions or distributed transactions.
- What are the minimum requirements for Database Mirroring?
- Database base recovery model should be full
- Database name should be same on both SQL Server instances
- Server should be in the same domain name
- Mirror database should be initialized with principle server
- What are the operating modes of Database Mirroring?
- High Availability Mode
- High Protection Mode
- High Performance Mode
- What is High Availability operating mode?
- It consists of the Principal, Witness and Mirror in synchronous communication.If Principal is lost Mirror can automatically take over.If the network does not have the bandwidth, a bottleneck could form causing performance issue in the Principal.In this mode SQL server ensures that each transaction that is committed on the Principal is also committed in the Mirror prior to continuing with next transactional operation in the principal.
- What is High Protection operating mode?
- It is pretty similar to High Availability mode except that Witness is not available, as a result failover is manual. It also has transactional safety FULL i.e. synchronous communication between principal and mirror. Even in this mode if the network is poor it might cause performance bottleneck.
- What is High Performance operating mode?
- It consists of only the Principal and the Mirror in asynchronous communication. Since the safety is OFF, automatic failover is not possible, because of possible data loss; therefore, a witness server is not recommended to be configured for this scenario. Manual failover is not enabled for the High Performance mode. The only type of failover allowed is forced service failover, which is also a manual operation.
- What are Recovery models support Database Mirroring?
- Database Mirroring is supported with Full Recovery model.
- What is Log Hardening?
- Log hardening is the process of writing the log buffer to the transaction log on disk, a process called.
- What is Role-switching?
- Inter changing of roles like principal and mirror are called role switching.
- https://www.dbamantra.com/sql-server-dba-interview-questions-answers-database-mirroring-1/
- LOG SHIPPING VS. MIRRORING VS. REPLICATION
- Master-Slave Replication in MongoDB
- adding redundancy to a database through replication
- Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
- Big Data refers to technologies and initiatives that involve data that is too diverse, fast-changing or massive for conventional technologies, skills and infra- structure to address efficiently. Said differently, the volume, velocity or variety of data is too great.
- "Big Data" caught on quickly as a blanket term for any collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.
- Big data is a popular term used to describe the exponential growth and availability of data, both structured and unstructured.
- IBM is unique in having developed an enterprise class big data and analytics platform
– in a timely fashion trust
http://www-01.ibm.com/software/data/bigdata/ - Big Data Real-time decision making is critical to business success. Yet data in your enterprise continues to grow exponentially year over
- Low latency (capital markets) Low latency is a topic within capital markets, where the proliferation of algorithmic trading requires firms to react to market events faster than the competition to increase profitability of trades. For example, when executing arbitrage strategies the opportunity to “arb” the market may only present itself for a few milliseconds before
- Low latency allows human-unnoticeable delays between an input being processed and the corresponding output providing real time characteristics
- Commodity hardware "Commodity hardware" does not imply low quality, but
- Commodity hardware, in an IT context, is a device or device component that is relatively inexpensive, widely available and more or less interchangeable with other hardware of its type.
- The term MapReduce
actually are broken the reduce job is always performed - MapReduce is a programming model
and - MapReduce is a programming model
and - Map stage
: Generally file is stored The input file is passed
- the master-slave replication was used for failover, backup, and read scaling.
- replaced by replica sets
- Replica Set in MongoDB
- A replica set consists of a group of mongod (read as Mongo D) instances that host the same data set.
- In a replica set, the primary mongod receives all write operations and the secondary mongod replicates the operations from the primary and thus both have the same data set.
- The primary node receives write operations from clients.
- A replica set can have only one primary and therefore only one member of the replica set can receive write operations.
- A replica set provides strict consistency for all read operations from the primary.
- The primary logs any changes or updates to its data sets in its oplog(read as op log).
- The secondaries also replicate the oplog of the primary and apply all the operations to their data sets.
- When the primary becomes unavailable, the replica set nominates a secondary as the primary.
- By default, clients read data from the primary.
- Automatic Failover in MongoDB
- When the primary node of a replica set stops communicating with other members for more than 10 seconds or fails, the replica set selects another member as the new primary.
- The selection of the new primary happens through an election process and whichever secondary node gets majority of the votes becomes the primary.
- you may deploy a replica set in multiple data centers or manipulate the primary election by adjusting the priority of members
- replica sets support dedicated members for functions, such as reporting, disaster recovery, or backup.
- In addition to the primary and secondaries, a replica set can also have an arbiter.
- Unlike secondaries, arbiters do not replicate or store data.
- arbiters play a crucial role in selecting a secondary to take the place of the primary when the primary becomes unavailable.
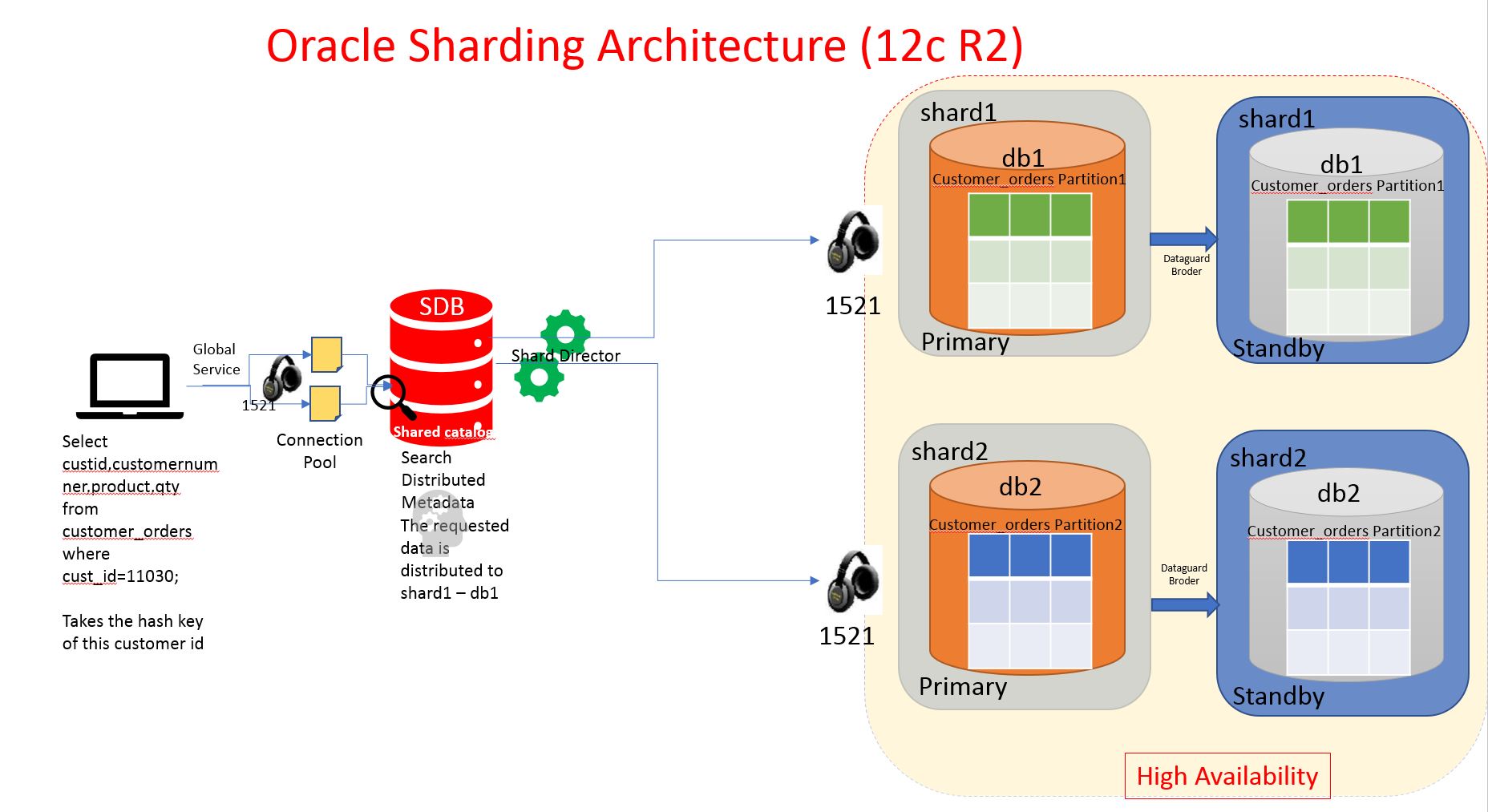
- What is Sharding in MongoDB?
- Sharding in MongoDB is the process of distributing data across multiple servers for storage.
- MongoDB uses sharding to manage massive data growth.
- With an increase in the data size, a single machine may not be able to store data or provide an acceptable read and write throughput
- MongoDB sharding supports horizontal scaling and thus is capable of distributing data across multiple machines.
- Sharding in MongoDB allows you to add more servers to your database to support data growth and automatically balances data and load across various servers.
- MongoDB sharding provides additional write capacity by distributing the write load over a number of mongod instances.
- It splits the data set and distributes them across multiple databases, or shards.
- Each shard serves as an independent database, and together, shards make a single logical database.
- MongoDB sharding reduces the number of operations each shard handles and as a cluster grows, each shard handles fewer operations and stores lesser data. As a result, a cluster can increase its capacity and input horizontally.
- For example, to insert data into a particular record, the application needs to access only the shard that holds the record.
- If a database has a 1 terabyte data set distributed amongst 4 shards, then each shard may hold only 256 Giga Byte of data.
- If the database contains 40 shards, then each shard will hold only 25 Giga Byte of data.
- When Can I Use Sharding in MongoDB?
- consider deploying a MongoDB sharded cluster when your system shows the following characteristics:
- The data set outgrows the storage capacity of a single MongoDB instance
- The size of the active working set exceeds the capacity of the maximum available RAM
- A single MongoDB instance is unable to manage write operations
- What is a MongoDB Shard?
- A shard is a replica set or a single mongod instance that holds the data subset used in a sharded cluster.
- Shards hold the entire data set for a cluster.
- Each shard is a replica set that provides redundancy and high availability for the data it holds.
- MongoDB shards data on a per collection basis and lets you access the sharded data through mongos instances.
- every database contains a “primary” shard that holds all the un-sharded collections in that database.
- https://www.simplilearn.com/replication-and-sharding-mongodb-tutorial-video
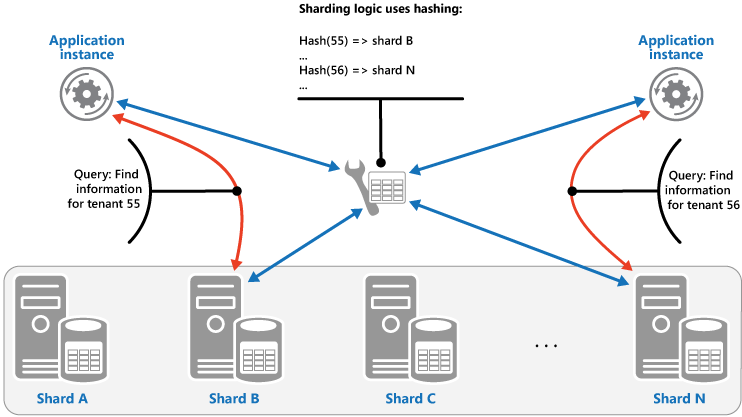
- sharding, a scalable partitioning strategy used to improve performance of a database that has to handle a large number of operations from different clients
- REPLICATION
- Replication refers to a database setup in which several copies of the same dataset are hosted on separate machines.
- The main reason to have replication is redundancy.
- If a single database host machine goes down, recovery is quick since one of the other machines hosting a replica of the same database can take over
- A quick fail-over to a secondary machine minimizes downtime, and keeping an active copy of the database acts as a backup to minimize loss of data
- a Replica Set: a group of MongoDB server instances that are all maintaining the same data set
- One of those instances will be elected as the primary, and will receive all write operations from client applications
- The primary records all changes in its operation log, and the secondaries asynchronously apply those changes to their own copies of the database.
- If the machine hosting the primary goes down, a new primary is elected from the remaining instances
- By default, client applications read only from the primary.
- However, you can take advantage of replication to increase data availability by allowing clients to read data from secondaries.
- Keep in mind that since the replication of data happens asynchronously, data read from a secondary may not reflect the current state of the data on the primary.
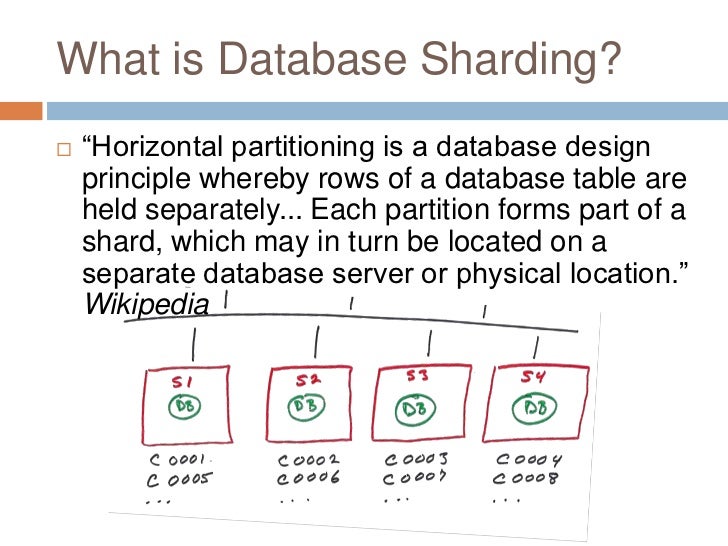
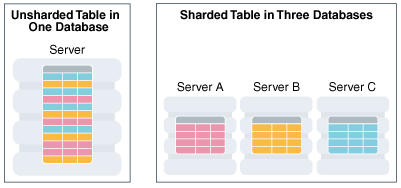
- DATABASE SHARDING
- Having a large number of clients performing high-throughput operations can really test the limits of a single database instance.
- Sharding is a strategy that can mitigate this by distributing the database data across multiple machines.
- It is essentially a way to perform load balancing by routing operations to different database servers.
- https://deadline.thinkboxsoftware.com/feature-blog/2017/5/26/advanced-database-features-replication-and-sharding
There are two methods for addressing system growth: vertical and horizontal scaling.
Vertical Scaling involves increasing the capacity of a single server, such as using a more powerful CPU, adding more RAM, or increasing the amount of storage space. Limitations in
Horizontal Scaling involves dividing the system dataset and load over multiple servers, adding additional servers to increase capacity as required. While the overall speed or capacity of a single machine may not be high, each machine handles a subset of the overall workload, potentially providing better efficiency than a single high-speed high-capacity server. Expanding the capacity of the deployment only requires adding additional servers as needed, which can be a lower overall cost than high-end hardware for a single machine.
https://docs.mongodb.com/manual/sharding/





"Big Data" describes data sets so large and complex they are impractical to manage with traditional software tools.
Big Data relates to data creation, storage, retrieval and analysis
Volume:
A typical PC might have had 10 gigabytes of storage in 2000. Today, Facebook ingests 500 terabytes of new data every day; a Boeing 737 will generate 240 terabytes of flight data during a single flight across the US
Velocity:
Variety:
Big Data data isn't just numbers, dates, and strings. Big Data is also geospatial data, 3D data, audio and video, and unstructured text, including log files and social media.
Selecting a Big Data Technology: Operational vs. Analytical
http://www.mongodb.com/big-data-explained
In a 2001 research
i.e. increasing volume (amount of data),
velocity (speed of data in and out),
variety (range of data types and sources).
http://en.wikipedia.org/wiki/Big_data
three Vs of big data: volume, velocity and variety.
Volume. Many factors contribute to the increase in data volume. Transaction-based data stored through the years. Unstructured data streaming in from social media. Increasing amounts of sensor and machine-to-machine data being collected. In the past, excessive data volume was a storage issue. But with decreasing storage costs, other issues emerge, including how to determine relevance within large data volumes and how to use analytics to create value from relevant data.
Velocity. Data is streaming in at unprecedented speed and must
Variety. Data today comes in
http://www.sas.com/en_us/insights/big-data/what-is-big-data.html
http://www.pivotal.io/big-data
http://en.wikipedia.org/wiki/Low_latency_%28capital_markets%29
http://en.wikipedia.org/wiki/Low_latency
Most commodity servers used in production Hadoop clusters have an average (again, the definition of "average" may change over time) ratio of disk space to memory, as opposed to being specialized servers with massively high memory or CPU.
Examples of Commodity Hardware in Hadoop
An example of suggested hardware specifications for a production Hadoop cluster is:
four 1TB hard disks in a JBOD (Just a Bunch Of Disks) configuration
two quad core
16-24GBs of RAM (24-32GBs if you're considering HBase)
1 Gigabit Ethernet
(Source: Cloudera)
http://www.revelytix.com/?
Other examples of commodity hardware in IT:
RAID (redundant array of independent
A commodity server is a commodity computer that
http://whatis.techtarget.com/definition/commodity-hardware
https://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
https://en.wikipedia.org/wiki/MapReduce
implementation for processing and generating large
data sets. Users specify a map function that processes a
key/value pair to generate a set of intermediate key/value
pairs, and a reduce function that merges all intermediate
values associated with the same intermediate key.
https://static.googleusercontent.com/media/research.google.com/en//archive/
Reduce stage
http://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
- Yet Another Resource Negotiator (YARN) Various applications can run on YARN
MapReduce is just one choice (the main choice at this point)
Scalability issues (max ~4,000 machines)
Inflexible Resource Management
MapReduce1 had slot based model
http://wiki.apache.org/hadoop/PoweredByYarn
- CSA Releases the Expanded Top Ten Big Data Security & Privacy Challenges
Bigtable
Bigtable is a distributed storage system for managing structured data that BigTable - Google File System Google File System (GFS or
- The Apache™ Hadoop® project develops
open
- The CSA’s Big Data Working Group followed a three-step process to arrive at top security and privacy challenges presented by Big Data:
- 1. Interviewed CSA members and surveyed security-practitioner oriented trade journals to draft an initial list of high priority security and privacy problems
- 2. Studied published solutions.
- 3. Characterized a problem as a challenge if the proposed solution does not cover the problem scenarios.
- Top 10 challenges
- Secure computations in distributed programming frameworks
- Security best practices for non-relational data stores
- Secure data storage and transactions logs
- End-point input validation/filtering
- Real-Time Security Monitoring
- Scalable and composable privacy-preserving data mining and analytics
- Cryptographically enforced data centric security
- Granular access control
- Granular audits
- Data Provenance The Expanded Top 10 Big Data challenges has evolved from the initial list of challenges presented at CSA Congress to an expanded version that addresses three new distinct issues:
- Modeling: formalizing a threat model that covers most of the
- Analysis: finding tractable solutions based on the threat model
- Implementation: implanting the solution in existing infrastructures The full report explores each one of these challenges in depth, including an overview of the various use
- https://cloudsecurityalliance.org/articles/csa-releases-the-expanded-top-ten-big-data-security-privacy-challenges/
http://research.google.com/archive/bigtable.html
http://en.wikipedia.org/wiki/BigTable
http://en.wikipedia.org/wiki/Google_File_System
The project includes these modules:
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Other Hadoop-related projects at Apache:
Cassandra: A scalable multi-master database with no single points of failure.
Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying.
ZooKeeper: A high-performance coordination service for distributed applications.
http://hadoop.apache.org/
- Hue is a Web interface for analyzing data with Apache Hadoop
- Two options that
are backed
• org
• http://wiki.apache.org/hadoop/AmazonS3
– org
• Backed by
• http://code.google.com/p/kosmosfs
- Apache
HBase
Use Apache
Google File System, Apache
http://hbase.apache.org/
- what is
HBase
Column-Oriented data store, known as “Hadoop Database”
Type of “
– Does not provide
5
HDFS won't do well on anything under 5
particularly with a block replication of 3
•
When to Use
Two well-known use cases
– Lots and lots of data (already mentioned)
– Large amount of clients/requests
data)
Great for
Great for variable schema
– Rows may drastically differ
– If your schema has many columns and most of them are null
When NOT to Use
Bad for traditional RDBMs retrieval
– Transactional applications
– Relational Analytics
• 'group by', 'join', and 'where column like', etc....
– There is work being done in this arena
•
• HBASE-3529: 100% integration of
based on
– Some projects provide
•
Native Java API
Avro Server
http://avro.apache.org
http://www.hbql.com
https://github.com/hammer/pyhbase
https://github.com/stumbleupon/asynchbase
JPA/JPO access to
http://www.datanucleus.org
https://github.com/nearinfinity/hbase-dsl
Native API is not the only option
REST Server
Complete client and admin APIs
Requires a REST gateway server
Supports many formats: text, xml,
Thrift
Apache Thrift is a cross-language schema compiler
http://thrift.apache.org
Requires running Thrift Server
http://courses.coreservlets.com/Course-Materials/pdf/hadoop/03-HBase_1-Overview.pdf
- Runtime Modes
Local (Standalone) Mode
Comes Out-of-the-Box, easy to get started
Uses local filesystem (not HDFS), NOT for production
Runs
Pseudo-Distributed Mode
Requires HDFS
Mimics
Good for testing, debugging and prototyping
Not for production use or performance benchmarking!
Development mode used in class
Run
Great for production and development clusters
http://courses.coreservlets.com/Course-Materials/pdf/hadoop/03-HBase_2-InstallationAndShell.pdf
- Designing to Store Data in Tables
Store parts of cell data in the row id
Faster data retrieval
Flat-Wide vs. Tall-Narrow
Tall Narrow has superior query granularity
query by
Flat-Wide has to
Tall Narrow scales better
Flat-Wide solution only works if all the blogs for a single user can fit into a single row
Flat-Wide provides atomic operations
atomic on per-row-basis
There is no built in
http://courses.coreservlets.com/Course-Materials/pdf/hadoop/03-HBase_6-KeyDesign.pdf
Hadoop vs MPP
- The Hadoop Distributed File System (HDFS)
http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
- Thrift Framework
Originally developed at Facebook, Thrift was open sourced in April 2007 and entered the Apache Incubator in
The Apache Thrift software framework, for scalable cross-language services development, combines a software stack with a code generation engine to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js,
http://thrift.apache.org/
- Apache Ambari
http://ambari.apache.org/
Apache Ambari
http://hortonworks.com/apache/ambari/
- Apache Avro
Avro provides:
Rich data structures.
A compact, fast, binary data format.
A container file, to store persistent data.
Remote procedure call (RPC).
Simple integration with dynamic languages
http://avro.apache.org/
- Cascading
http://www.cascading.org/
Fully-featured data processing and querying library forClojure or Java.
- Cloudera Impala
Cloudera Impala is
http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/impala.html
- PigPen
https://wiki.apache.org/pig/PigPen
- Apache Crunch
Its goal is to make pipelines that
https://crunch.apache.org
- Apache Giraph
http://giraph.apache.org/
- Apache Accumulo
https://accumulo.apache.org/
- Apache Chukwa is an open source data collection system for monitoring large distributed systems.
Apache Chukwa is built on top of the Hadoop Distributed File System (HDFS) and Map/Reduce framework and inherits Hadoop’s scalability and robustness. Apache Chukwa also includes aflexible and powerful toolkit for displaying, monitoring and analyzing results to make the best use of the collected data
- Apache
Bigtop
http://bigtop.apache.org/
- Hortonworks Data Platform 2.1
http://hortonworks.com/
- Why use Storm?
http://storm.apache.org
- Apache Kafka is
publish -subscribe messaging rethought as a distributed commit log.






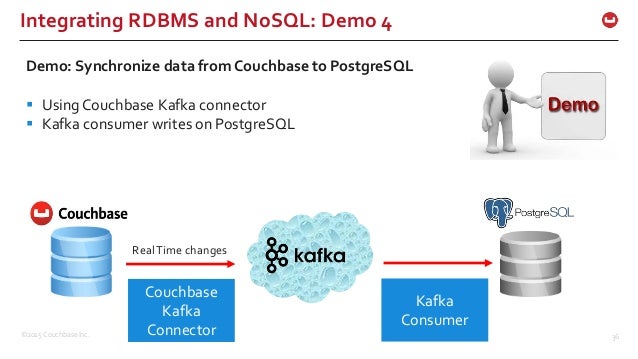
- What is Couchbase Server? The Scalability of
NoSQL + The Flexibility of JSON + The Power of SQL
https://www.slideshare.net/BigDataSpain/migration-and-coexistence-between-relational-and-nosql-databases-by-manuel-hurtado
- A query language for your API
https://graphql.org/
- COUCHBASE IS THE NOSQL DATABASE FOR BUSINESS-CRITICAL APPLICATIONS
https://www.couchbase.com/
- Hadoop Distributions
Cloudera
Cloudera offers CDH, which is 100% open source, as a free download
The enterprise version
Hortonworks
The major difference from Cloudera and MapR is that HDP uses Apache Ambari for cluster management and monitoring.
MapR
The major differences to CDH and HDP is that MapR uses their proprietary file system MapR-FS instead of HDFS.
The reason for their Unix-based file system is that MapR considers HDFS as a single point of failure.
http://www.ymc.ch/en/hadoop-overview-of-top-3-distributions
- Neo4j Community Edition is an open source product licensed under GPLv3
. Neo4j is the world’s leading Graph Database. It is a high performance graph store with all the features expected of a mature and robust database, like a friendly query language and ACID transactions.
- Apache Cassandra
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or
http://cassandra.apache.org/
- Redis
http://redis.io/
Roc ksDB
https://rocksdb.org/
mongoDB
http://www.mongodb.org/
GridFS is a specification for storing and retrieving files that exceed the BSON-document size limit of 16 MB.
When to Use
In MongoDB, use
In some situations, storing large files may be more efficient in a MongoDB database than on a system-level filesystem.
If your filesystem limits the number of files in a directory, you can use
When you want to access information from portions of large files without having to load whole files into memory, you can use
When you want to keep your files and metadata automatically synced and deployed across
https://docs.mongodb.com/manual/core/gridfs/
- Riak
http://basho.com/riak/
CouchDB
https://couchdb.apache.org/
- Pivotal Greenplum Database (Pivotal GPDB) manages, stores and analyzes terabytes to
petabytes of data in large-scale analytic data warehouses
http://www.pivotal.io/big-data/pivotal-greenplum-database
- Commercial Hadoop Distributions
Amazon Web Services Elastic MapReduce
EMR is Hadoop in the cloud leveraging Amazon EC2 for
Cloudera
Enterprise customers wanted a management and monitoring tool for Hadoop, so Cloudera built Cloudera Manager,
Enterprise customers wanted a faster SQL engine for Hadoop, so Cloudera built Impala using a massively parallel processing (MPP) architecture
IBM
IBM has advanced analytics tools, a global presence and implementation services, so it can offer a complete big data solution that will be attractive
MapR
MapR Technologies has added some unique innovations to its Hadoop distribution, including support for Network File System (NFS), running arbitrary code in the cluster, performance enhancements for
Pivotal Greenplum Database
Teradata
The Teradata distribution for Hadoop includes integration with Teradata's management tool and SQL-H, a federated SQL engine that lets customers query data from its data warehouse and Hadoop
Intel Delivers Hardware-Enhanced Performance, Security for Hadoop
Microsoft Windows Azure
Microsoft Windows Azure
http://www.cio.com/article/2368763/big-data/146238-How-the-9-Leading-Commercial-Hadoop-Distributions-Stack-Up.html
- MapR
https://www.mapr.com/why-hadoop/why-mapr
- Amazon EMR
Amazon EMR uses Hadoop, an open source framework, to distribute your data and processing across a resizable cluster of Amazon EC2 instances.
http://aws.amazon.com/elasticmapreduce/
InfoSphere BigInsights
http://www-01.ibm.com/software/data/infosphere/biginsights/
- oracle golden gate
http://www.oracle.com/technetwork/middleware/goldengate/overview/index.html
- The GridGain® in-memory computing platform includes an In-Memory Compute Grid which enables parallel processing of CPU or otherwise resource intensive tasks including traditional High Performance Computing (HPC) and Massively Parallel Processing (MPP).
Queries are broken down into sub-queries whichare sent to the relevant nodes in thecompute grid of the GridGain cluster and processed on the localCPUs where the dataresides .
https://www.gridgain.com/technology/in-memory-computing-platform/compute-grid
- In-Memory Speed and Massive Scalability
In-memory computing solutions deliver real-time application performance and massive scalability by creating a copy of your data stored in disk-based databases in RAM. When data
https://www.gridgain.com/technology/in-memory-computing-platform
- What is Spark In-memory Computing?
In in-memory computation, the data
RAM storage
Parallel distributed processing.
https://data-flair.training/blogs/spark-in-memory-computing/


- Why In-Memory Computing Is Cheaper And Changes Everything

- In-Memory Database Computing
– A Smarter Way of Analyzing Data
- In-Data Computing vs In-Memory Computing vs Traditional Model
( Storage based)
In-Data Computing (also known as In-Place Computing) is an abstract model in which
http://www.bigobject.io/technology.html
- SAP HANA is an in-memory database: • - It is a combination of hardware and software made to process massive
real time data using In-Memory computing.
• - Data now
• - It’s best suited for performing real-time
http://saphanatutorial.com/sap-hana-database-introduction/
in-memory database
- An in-memory database (IMDB); also main memory database system or MMDB or memory resident database
) is a database management system that primarily relies on main memory for computer data storage.
http://en.wikipedia.org/wiki/In-memory_database
- The in-memory database defined
An in-memory database is a
Because all data
In-memory databases can persist data on disks by storing each operation in a log or by taking snapshots.
In-memory databases are ideal for applications that require microsecond response times and can have large spikes in traffic coming
Use cases
Real-time bidding
In-memory databases are ideal choices for ingesting, processing, and analyzing real-time data with
Caching
A cache is a high-speed data storage layer which stores a subset of data, typically transient
Popular in-memory databases
Amazon
in-memory data store that provides
Developers can use
The
Amazon
Memcached-compatible in-memory key-value store service
can
for use cases where frequently accessed data must be
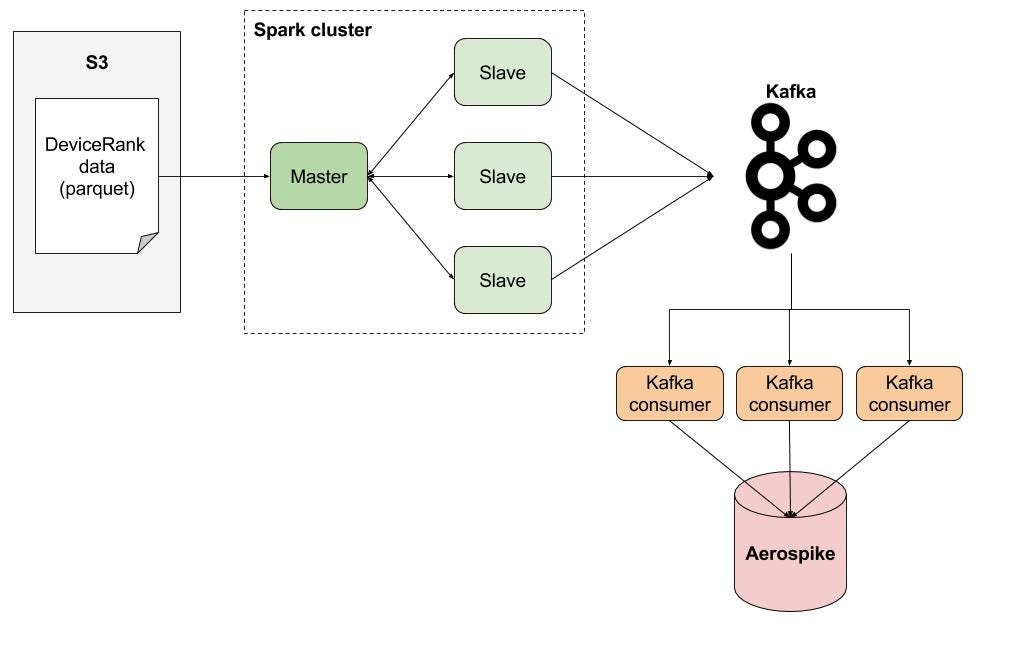
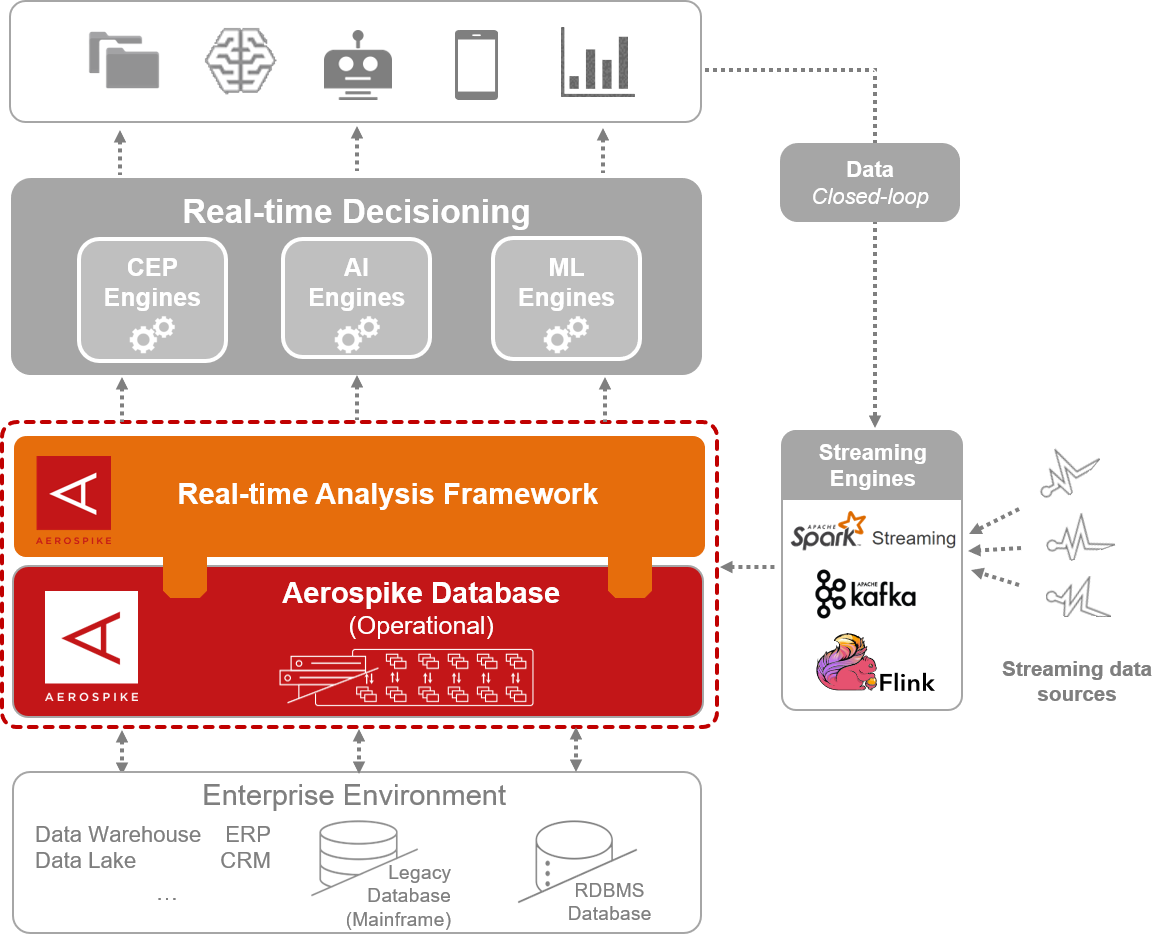
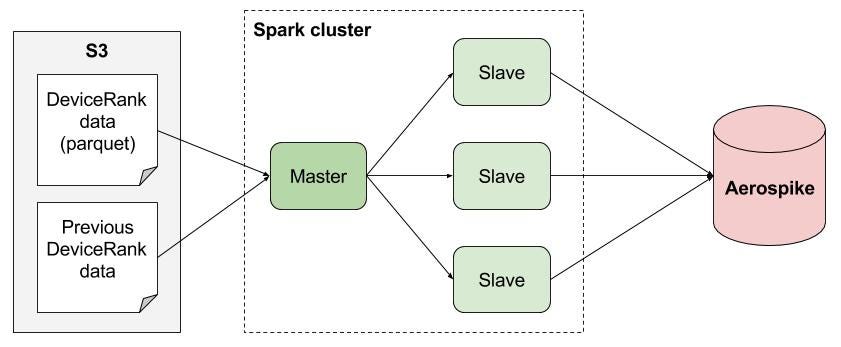
Aerospike
in-memory database solution for real-time operational applications
This high-performance nonrelational database can
or greater data sizes using local SSD instances
https://aws.amazon.com/nosql/in-memory/



- Difference between In-Memory cache and In-Memory Database
the differences between In-Memory cache
Cache - By definition means
https://stackoverflow.com/questions/37015827/difference-between-in-memory-cache-and-in-memory-database
- Redis vs. Memcached: In-Memory Data Storage Systems
Redis and Memcached are both in-memory data storage systems
Memcached is a high-performance distributed memory cache service
Redis is an open-source key-value store
Similar to Memcached, Redis stores most of the data in the memory
In Memcached, you usually need to copy the data to the client end for similar changes and then set the data back.
The result is that this
In Redis, these complicated operations are as efficient as the general GET/SET operations
Different memory management scheme
In Redis, not all data storage occurs in memory. This is a major difference between Redis and Memcached. When the physical memory is full, Redis may swap values not used for a long time to the disks
Difference in Cluster Management
Memcached is a full-memory data buffering system. Although Redis supports data persistence, the full-memory is the essence of its high performance. For a memory-based store, the size of the memory of the physical machine is the maximum data storing capacity of the system. If the data size you want to handle surpasses the physical memory size of a single machine, you need to build distributed clusters to expand the storage capacity.
Compared with Memcached which can only achieve distributed storage on the client side, Redis prefers to build distributed storage on the server side.
https://medium.com/@Alibaba_Cloud/redis-vs-memcached-in-memory-data-storage-systems-3395279b0941
- Amazon
Elasti Cache
Build data-intensive apps or improve the performance of your existing apps by retrieving data from high throughput and low latency in-memory data stores
https://aws.amazon.com/elasticache/
- Distributed cache
In computing, a distributed cache
A distributed cache may span multiple servers so
Also, a distributed cache works well on
https://en.wikipedia.org/wiki/Distributed_cache
Infinispan
Use it as a cache or a data grid.
Advanced functionality such as transactions, events, querying, distributed processing, off-heap and geographical failover
http://infinispan.org/
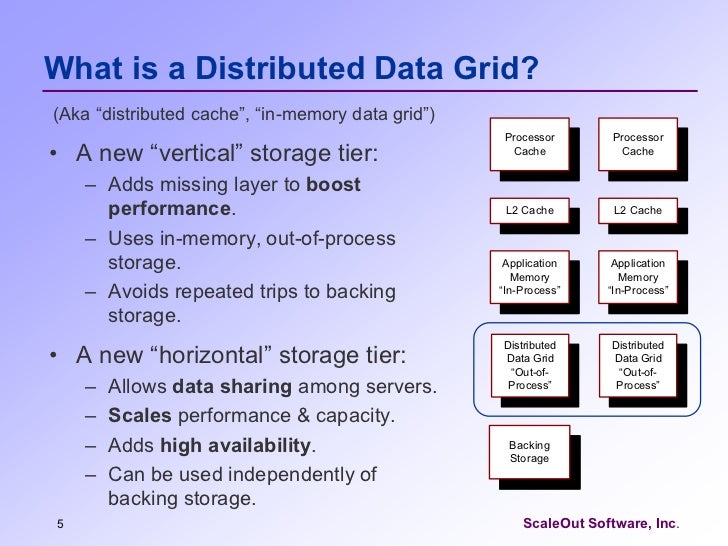
- In-Memory Distributed Caching
The primary use case for caching is to keep frequently accessed data in process memory to avoid constantly fetching this data from disk, which leads to the High Availability (HA) of that data to the application running in that process space (hence, “in-memory” caching)
Most of the caches
In-Memory Data Grid
The feature of data grids that distinguishes them from distributed caches the most was their ability to support co-location of computations with data in a distributed context and consequently provided the ability to move computation to data
https://www.gridgain.com/resources/blog/cache-data-grid-database
- From distributed caches to in-memory data grids
What do high-load applications need from cache?
Low latency
Linear horizontal scalability
Distributed cache
Cache access patterns: Client Cache Aside For reading data:
Cache access patterns: Client Read Through For reading data
Cache access patterns: Client Write Through For writing data
Cache access patterns: Client Write Behind For writing data
https://www.slideshare.net/MaxAlexejev/from-distributed-caches-to-inmemory-data-grids
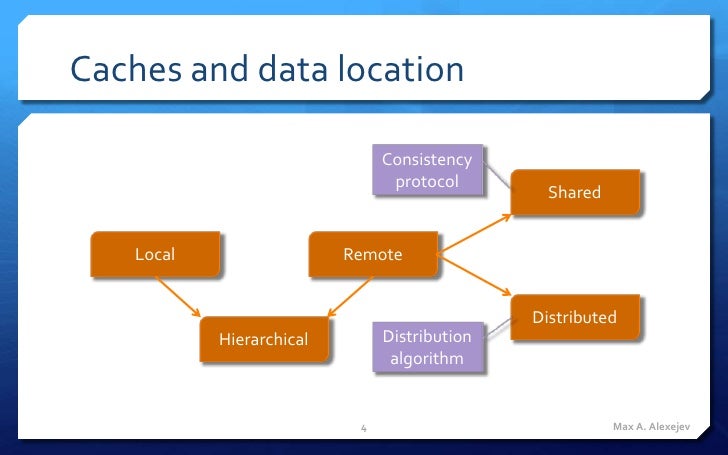
- the difference between two major categories in
in -memory computing: In-Memory Database and In-Memory Data Grid
In-Memory Data Grids (IMDGs) are sometimes (but not
there are also In-Memory Compute Grids and In-Memory Computing Platforms that include or augment many of the features of In-Memory Data Grids and In-Memory Databases.
Tiered Storage
what we mean by “In-Memory”.
https://www.gridgain.com/resources/blog/in-memory-database-vs-in-memory-data-grid-revisited
- Cache < Data Grid < Database
In-Memory Distributed Cache
In-Memory Data Grid
In-Memory Database
In-Memory Distributed Caching
The primary use case for caching is to keep frequently accessed data in process memory to avoid constantly fetching this data from disk, which leads to the High Availability (HA) of that data to the application running in that process space (hence, “in-memory” caching).
In-Memory Data Grid
The feature of data grids that distinguishes them from distributed caches was their ability to support co-location of computations with data in a distributed context and consequently provided the ability to move computation to data.
In-Memory Database
The feature that distinguishes in-memory databases over data grids is the addition of distributed MPP processing based on standard SQL and/or MapReduce, that allows to compute over data stored in-memory across the cluster.
https://dzone.com/articles/cache-data-grid-database
- What’s the Difference Between an In-Memory Data Grid and In-Memory Database?
The differences between IMDGs and IMDBs are more technical
What’s an In-Memory Data Grid (IMDG)?
So, What’s an In-Memory Database (IMDB)?
An IMDB is a database management system that primarily relies on main memory for computer data storage. It contrasts with database management systems that
https://www.electronicdesign.com/embedded-revolution/what-s-difference-between-memory-data-grid-and-memory-database


- How To Choose An In-Memory
NoSQL Solution: Performance Measuring
The main purpose of this work is to show results of benchmarking
We selected three popular in-memory database management systems:
Redis (standalone and in-cloud named Azure Redis Cache),
Memcached is not a database management system and does not have persistence. But we
In-memory
Memcached is a general-purpose distributed memory caching system
Couchbase Server, originally known as
Yahoo! Cloud Serving Benchmark
Yahoo! Cloud Serving Benchmark, or YCSB is a powerful utility for performance measuring of a wide range of
http://highscalability.com/blog/2015/12/30/how-to-choose-an-in-memory-nosql-solution-performance-measur.html
- Potential of in memory NO SQL database
What is No SQL?
A No-SQL (often interpreted as Not Only SQL) database provides a mechanism for storage and retrieval of data that
What is
An in-memory database (IMDB; also main memory database system or MMDB or memory resident database) is a database management system that primarily relies on main memory for computer data storage.
Why In Memory
The
In-memory DBMS vendors MemSQL and VoltDB are taking the trend in the other direction, recently adding flash- and disk-based storage options to products that previously did all their processing entirely in memory. The goal here is to add capacity for historical data for long-term analysis.
https://www.rebaca.com/potentiality-of-in-memory-no-sql-database/
Ehcache
http://ehcache.org/
- Memcached
Free & open source, high-performance, distributed memory object caching system, generic
http://memcached.org/
OSCache
* Caching of Arbitrary Objects -
* Comprehensive API - The OSCache API gives you full programmatic control over all of OSCache's features.
* Persistent Caching - The cache can optionally be disk-based,
* Clustering - Support for clustering of cached data can
* Expiry of Cache Entries - You have a huge amount of control over how cached objects expire, including pluggable
http://www.opensymphony.com/oscache/
ShiftOne
http://jocache.sourceforge.net/
SwarmCache
http://swarmcache.sourceforge.net/
Whirlycache
http://java.net/projects/whirlycache
- cache4j
cache4j is a cache for Java objects with a simple API and fast implementation.
It features in-memory caching, a design for a multi-threaded environment, both synchronized and blocking implementations, a choice of eviction algorithms (LFU, LRU, FIFO), and the choice of either hard or soft references for object storage.
http://cache4j.sourceforge.net/
- JCS
JCS is a distributed caching system written in java.
https://commons.apache.org/proper/commons-jcs//
- Solr
http://lucene.apache.org/solr/
- Tapestry
http://tapestry.apache.org/
- Apache Lucene
http://lucene.apache.org/java/docs/index.html
JiBX
http://jibx.sourceforge.net/
- Hazelcast
http://www.hazelcast.com
Great article,thank you for sharing such an great info with us,
ReplyDeletebig data and hadoop online training
Hey, thanks for the blog article.Really thank you! Great.
ReplyDeleteMySql Admin training
MYSQL online training
MYSQL training
OBIEE online training
OBIEE training
Oracle 11g rac online training
Oracle 11g rac training
Oracle Access Manager online training