Decide whether to undertake a project or decide which of several projects to undertake.
Frame appropriate project objectives.
Develop appropriate before and after measures of project success.
Prepare estimates of the resources required to perform the project work.
Everything gets a dollar value in a cost-benefit analysis Whenever possible, express benefits and costs in monetary terms to facilitate the assessment of a project’s net value.
Consider costs for all phases of the project. Such costs may be nonrecurring (such as labor, capital investment, and certain operations and services) or recurring (such as changes in personnel, supplies, and materials or maintenance and repair). I
Cost-benefit analysis: Weighing future values today
For example, you may expect to reap benefits for years from a new computer system, but changing technology may make your new system obsolete after only one year.
http://www.dummies.com/how-to/content/performing-a-costbenefit-analysis.html
How to Do a Cost Analysis
A cost analysis (also called cost-benefit analysis, or CBA) is a detailed outline of the potential risks and gains of a projected venture.
1 Define your CBA's unit of cost benefit
CBA measures literal cost in terms of money, but, in cases where money is not an issue, CBAs can measure cost in terms of time, energy usage, and more.
2 Itemize the tangible costs of the intended project.
Costs can be one-time events or ongoing expenses
3 Itemize any and all intangible costs.
Usually, CBAs also take into account a project's intangible demands - things like the time and energy required to complete the project.
4 Itemize the projected benefits.
5 Add up and compare the project's costs and benefits
we determine whether the benefits of our project outweigh the costs
6 Calculate a payback time for the venture
7 Use your CBA to inform your decision about whether to pursue your project
if it's not clear that a project can generate additional profit in the long run or pay for itself in a reasonable amount of time, you will probably want to reconsider the project or even scrap it all together.
form factor refers to the size, shape, and packaging of a hardware device. Server computers typically come in one of three form factors:
Tower case: Most servers are housed in a traditional tower case, similar to the tower cases used for desktop computers.
Rack-mount servers are designed to save space when you need more than a few servers in a confined area. A rack-mount server is housed in a small chassis that’s designed to fit into a standard 19-inch equipment rack. The rack allows you to vertically stack servers in order to save space.
Blade servers: Blade servers are designed to save even more space than rack-mount servers A blade server is a server on a single card that can be mounted alongside other blade servers in a blade chassis, which itself fits into a standard 19-inch equipment rack. A typical blade chassis holds six or more servers, depending on the manufacturer. One of the key benefits of blade servers is that you don’t need a separate power supply for each server. the blade enclosure provides KVM switching so that you don’t have to use a separate KVM switch. With rack-mount servers, each server requires its own power cable, keyboard cable, video cable, mouse cable, and network cables. With blade servers, a single set of cables can service all the servers in a blade enclosure.v
Total Cost of Ownership (TCO) is an analysis meant to uncover all the lifetime costs that follow from owning certain kinds of assets. Ownership brings purchase costs, of course, but ownership can also bring costs for installing, deploying, operating, upgrading, and maintaining the same assets. For this reason, TCO is sometimes called life cycle cost analysis. For many kinds of acquisitions, TCO analysis finds a very large difference between purchase price and total long term cost, especially when viewed across a long ownership period.
1. Obvious costs in TCO analysis Obvious costs in TCO are the costs familiar to everyone involved during planning and vendor selection, such as:
Purchase cost: The actual price paid. Maintenance costs: warranty costs, maintenance labor, contracted maintenance services or other service contracts
2. Hidden costs in TCO analysis
The so-called hidden costs are the less obvious cost consequences that are easy to overlook or omit from acquisition decisions
Acquisition costs: the costs of identifying, selecting, ordering, receiving, inventorying, or paying for something. Upgrade / Enhancement / Refurbishing costs. Reconfiguration costs. Set up / Deployment costs: costs of configuring space, transporting, installing, setting up, integrating with other assets, outside services. Operating costs: for example, human (operator) labor, or energy/fuel costs. Change management: costs: for example, costs of user orientation, user training, workflow/process change design and implementation. Infrastructure support costs: for example, costs brought by the acquisition for heating/cooling, lighting, or IT support. Environmental impact costs: for example, costs of waste disposal/clean up, or pollution control, or the costs of environmental impact compliance reporting. Insurance costs. Security costs: Physical security, for example, security additions for a building, including new locks, secure entry doors, closed circuit television, and security guard services. Electronic security, for example, security software applications or systems, offsite data backup, disaster recovery services, etc. Financing costs: for example, loan interest and loan origination fees. Disposal / Decommission costs. Depreciation expense tax savings (a negative cost). http://www.business-case-analysis.com/total-cost-of-ownership.html
The servers themselves are 1.5U high, half again as high as the normal 1-U rack, Facebook executives said. That allows Facebook to build more space in the racks for cooling; the company used 60-mm fans to move more air with less power, they said. The racks are built on shelves, so they can be easily serviced.
Richard Fichera, an analyst at Forrester, claimed that the servers are divide into two categories: the Web tier, a high-power server that uses dual-socket, 8-core Xeon X5650 chips; and the Memcache tier, which uses less CPU, and more memory, and incorporates 8-core "Magny Cours" AMD processors, he said in a blog post. Each server can have up to 6 local disks. The power supplies are more than 93 percent efficient, almost heard of in an industry where 90 percent efficiency is considered outstanding. For backup power, they use a modular 48V DC battery backup unit that supplies up to six servers through a DC-DC converter in each server. Each battery is connected via the network, so that the Facebook IT managers can monitor the health of the system. http://www.pcmag.com/article2/0,2817,2383283,00.asp
Why Open Hardware?
By releasing Open Compute Project technologies as open hardware, our goal is to develop servers and data centers following the model traditionally associated with open source software projects. http://www.opencompute.org/
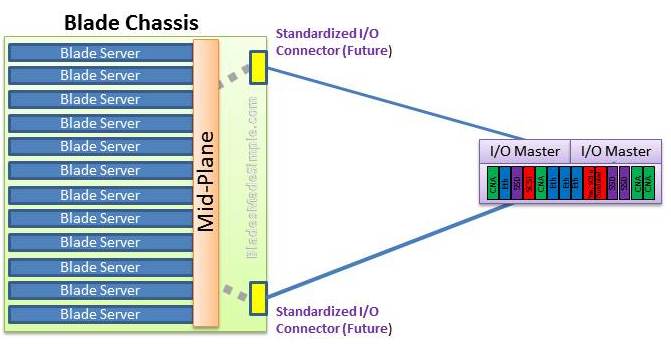
A server architecture that houses multiple server modules ("blades") in a single chassis.
It is widely used in datacenters to save space and improve system management Either self-standing or rack mounted, the chassis provides the power supply, and each blade has its own CPU, memory and hard disk
Diskless Blades With enterprise-class blade servers, disk storage is external, and the blades are diskless. This approach allows for more efficient failover because applications are not tied to specific hardware and a particular instance of the operating system. The blades are anonymous and interchangeable http://www.answers.com/topic/blade-server
The Next Evolution of the Blade Server – External I/O Expansion
Blade System Series Part-1
Chassis:- Consider this as a empty box with 8 to 10 unit in height which is the building block of the entire system. BackPlane :- This component is assembled inside the chassis to provide high speed IO (input/output) path to Blade Server via I/O Bays. Bays :- Consider this as a slot where you can install blades. Bays can be customized to allow full/Half height blades installation or Mixture of both. I/O Interconnect Bays :- These are again empty slots where you can install switches (Fiber or Ethernet) to connect Blade Servers with external Fiber or Ethernet networks. unlike rack servers which connects directly to Fiber or Ethernet network. Blade servers connects with High speed BackPlanes which further connects with I/O Bays - and the switches installed inside I/O bays would allow further connectivity. Blades:- Well, its the actual compute power which you install in bays. The reason they are called blades is because its highly dense in form factor and takes very less space
Having Management Module and I/O switches in every chassis increases Management as well as cabling that's why Cisco splits Management Module & I/O switches from the chassis This design increases efficiency by sharing I/O switches with multiple chassis , which is not possible when switches are mounted inside the chassis. so lets understand this design with examples. http://panksthought.blogspot.com.tr/2012/09/blade-system-series-part-1.html
Blade System Series Part-2
Cisco UCS (Unified Computing System) Having Management Module and I/O switches in every chassis increases Management as well as cabling that's why Cisco splits Management Module & I/O switches from the chassis
Bitcoin is a peer-to-peer payment system introduced as open source software in 2009 by developer Satoshi Nakamoto
The digital currency created and used in the system is also called bitcoin and is alternatively referred to as a virtual currency, electronic money, or cryptocurrency
Bitcoins are created as a reward for payment processing work in which users who offer their computing power verify and record payments into a public ledger
Called mining, individuals engage in this activity in exchange for transaction fees and newly minted bitcoins
Besides mining, bitcoins can be obtained in exchange for other currencies, products, and services.
Users can buy, send, and receive bitcoins electronically for a nominal fee using wallet software on a personal computer, mobile device, or a web application.
http://en.wikipedia.org/wiki/Bitcoin
Bitcoin
Bitcoin uses peer-to-peer technology to operate with no central authority or banks; managing transactions and the issuing of bitcoins is carried out collectively by the network.
Bitcoin is open-source; its design is public, nobody owns or controls Bitcoin and everyone can take part
https://bitcoin.org/en/
Bitcoin network
The Bitcoin network is a peer-to-peer payment network that operates on a cryptographic protocol. Users send bitcoins, the unit of currency, by broadcasting digitally signed messages to the network using Bitcoin wallet software.
Transactions are recorded into a distributed public database known as the block chain, with consensus achieved by a proof-of-work system called "mining".
The block chain is distributed internationally using peer-to-peer filesharing technology similar to BitTorrent
The protocol was designed in 2008 and released in 2009 as open source software by "Satoshi Nakamoto", the pseudonym of the original developer or group of developers.
The network timestamps transactions by including them in blocks that form an ongoing chain called the block chain
Such blocks cannot be changed without redoing the work that was required to create each block since the modified block.
The longest chain serves not only as proof of the sequence of events but also records that this sequence of events was verified by a majority of the Bitcoin network's computing power
Bitcoin mining
To form a distributed timestamp server as a peer-to-peer network, Bitcoin uses a proof-of-work system similar to Adam Back's Hashcash and the internet rather than newspaper or Usenet posts.
The work in this system is what is often referred to as Bitcoin mining.
The mining process involves scanning for a value that when hashed twice with SHA-256, begins with a number of zero bits. While the average work required increases exponentially with the number of leading zero bits required, a hash can always be verified by executing a single round of double SHA-256
Timestamps
The Bitcoin specification starts with the concept of a distributed timestamp server
A timestamp server works by taking a SHA256 hash function of some data and widely publishing the hash
The timestamp proves that the data must have existed at the time, in order to produce the hash
For Bitcoin, each timestamp includes the previous timestamp hash as input for its own hash
This dependency of one hash on another is what forms a chain, with each additional timestamp providing evidence that each of the previous timestamp hashes existed.
Namecoin is a cryptocurrency which also acts as an alternative, decentralized DNS, which would avoid domain name censorship by making a new top level domain outside of ICANN control, and in turn, make internet censorship much more difficult, as well as reduce outages.
http://en.wikipedia.org/wiki/Namecoin
fiat money
Fiat money is money that derives its value from government regulation or law
fiat currency
The term fiat currency is used when a fiat money is used as the main currency of the country.
The Nixon Shock of 1971 ended the convertibility of the United States dollar to gold. Since then, all reserve currencies have been fiat currencies, including the U.S. dollar and the Euro
A central bank typically introduces new money into circulation in the economy by purchasing financial assets or lending money to financial institutions
Commercial banks then multiply this base money by credit creation through fractional reserve banking, which expands the total supply of broad money (cash plus demand deposits). The amount of money in circulation is reduced by the opposite process. The value of fiat currencies is influenced by monetary policy
Fractional reserve banking
Fractional-reserve banking is the practice whereby a bank holds reserves in an amount equal to only a portion of the amount of its customers' deposits to satisfy potential demands for withdrawals. Reserves are held at the bank as currency, or as deposits reflected in the bank's accounts at the central bank.
Demand deposit
Demand deposits, bank money or scriptural money are funds held in demand deposit accounts in commercial banks.
These account balances are usually considered money and form the greater part of the narrowly defined money supply of a country
Exorbitant privilege
The term exorbitant privilege refers to the alleged benefit the United States has due to its own currency (i.e., the US dollar) being the international reserve currency.
Accordingly, the US would not face a balance of payments crisis, because it purchased imports in its own currency
Reserve currency
A reserve currency (or anchor currency) is a currency that is held in significant quantities by governments and institutions as part of their foreign exchange reserves, and that is commonly used in international transactions.
Persons who live in a country that issues a reserve currency can purchase imports and borrow across borders more cheaply than persons in other nations because they need not exchange their currency to do so.
As of 2014 the United States dollar is the world's reserve currency, and the world's need for dollars has allowed the United States government as well as Americans to borrow at lower costs, granting them an advantage in excess of $100 billion per year
hyperinflation
hyperinflation occurs when a country experiences very high and usually accelerating rates of monetary and price inflation, causing the population to minimize their holdings of money.
Hyperinflation is often associated with wars, their aftermath, sociopolitical upheavals, or other crises that make it difficult for the government to tax the population, as a sudden and sharp decrease in tax revenue coupled with a strong effort to maintain the status quo can be a direct trigger of hyperinflation.
http://en.wikipedia.org/wiki/Fiat_money
The Internet Corporation for Assigned Names and Numbers is a nonprofit organization that coordinates the Internet's global domain name system.
The Internet Assigned Numbers Authority (IANA) is a department of ICANN responsible for managing the DNS Root and the numbering system for IP addresses.
http://en.wikipedia.org/wiki/ICANN
A proof-of-work (POW) system (or protocol, or function) is an economic measure to deter denial of service attacks and other service abuses such as spam on a network by requiring some work from the service requester, usually meaning processing time by a computer
A key feature of these schemes is their asymmetry: the work must be moderately hard (but feasible) on the requester side but easy to check for the service provider. This idea is also known as a CPU cost function, client puzzle, computational puzzle or CPU pricing function. It is distinct from a CAPTCHA, which is intended for a human to solve quickly, rather than a computer
http://en.wikipedia.org/wiki/Proof-of-work
Hashcash
Hashcash is a proof-of-work system designed to limit email spam and denial-of-service attacks. Hashcash is a method of adding a textual stamp to the header of an email to prove the sender has expended a modest amount of CPU time calculating the stamp prior to sending the email In other words, as the sender has taken a certain amount of time to generate the stamp and send the email, it is unlikely that they are a spammer The receiver can, at negligible computational cost, verify that the stamp is valid
The theory is that spammers, whose business model relies on their ability to send large numbers of emails with very little cost per message, cannot afford this investment into each individual piece of spam they send. Receivers can verify whether a sender made such an investment and use the results to help filter email.
Layer 7 DDoS attacks are some of the most difficult attacks to mitigate against because they mimic human behavior as they interact with the user interface. For example, some types of Layer 7 DDoS attacks will target website elements, like your logo or a button, and repeatedly download resources hoping to exhaust the server.
Here are some of the ways to stop a DDoS attack:
Block spoofed TCP attacks before they enter your network.
Don’t let dark address packets pass your perimeter.
Block unused protocols and ports.
Limit the number of access per second per source IP.
Limit numbers of concurrent connections per source IP.
Filter foreign TCP packets.
Do not forward packets with header anomalies.
Monitor self-similarity in traffic.
Keep unwanted guests away.
Use specialized DDoS mitigation equipment.
To understand what a layer 7 DDoS attack is you must first understand what is meant by the application layer.
There are seven layers in total, each fulfilling its own purpose in a connected networking framework called the Open System Interconnection Model. The short version being referred to as the OSI Model.
http://ddosattackprotection.org/blog/wp-content/uploads/2013/12/OSI-Model.jpg
the breakdown of the function of each layer
http://ddosattackprotection.org/blog/wp-content/uploads/2013/12/OSI-Layer-Functions.jpg
There are three types of DDoS attacks
Layer 3 / 4 DDoS attacks
The majority of DDoS attacks focus on targeting the transport and network layers. These types of attacks are usually comprised of volumetric attacks that aim to overwhelm the target machine, denying or consuming resources until the server goes offline. In these types of DDoS attacks, malicious traffic (TCP / UDP) is used to flood the victim. Taking it one step further, these attacks also drive to saturate the entire network with malicious traffic until it is rendered temporarily obsolete. While these types of attacks can be a disruptive force for businesses, once the attack ceases or has been mitigated, there is no lasting damage.
http://ddosattackprotection.org/blog/layer-7-ddos-attack/
Types of DDoS Attacks
Websites are vulnerable to DDoS because of the way machines communicate online.
SYN Flood
UDP Flood
Reflected Attack
Nuke
Slowloris
Peer-to-Peer Attacks
Unintentional DDoS
Degradation of Service Attacks
Application Level Attacks
Multi-Vector Attacks
Zero Day DDoS
A Layer 7 DoS attack is often perpetrated through the use of HTTP GET. This means that the 3-way TCP handshake has been completed, thus fooling devices and solutions which are only examining layer 4 and TCP communications. The attacker looks like a legitimate connection and is therefore passed on to the web or application server. At that point, the attacker begins requesting large numbers of files/objects using HTTP GET.
When rate-limiting was used to stop this type of attack, the bad guys moved to use a distributed system of bots (zombies) to ensure that the requests (attack) was coming from myriad IP addresses and was therefore not only more difficult to detect, but more difficult to stop. The attacker uses malware and trojans to deposit a bot on servers and clients, and then remotely includes them in his attack by instructing the bots to request a list of objects from a specific site or server. The attacker might not use bots but instead might gather enough evil friends to launch an attack against a site that has annoyed them for some reason.
Layer 7 DoS attacks are more difficult to detect because the TCP connection is valid and so are the requests. The trick is to realize when there are multiple clients requesting large numbers of objects at the same time and to recognize that it is, in fact, an attack.
Defending against Layer 7 DoS attacks usually involves some sort of rate-shaping algorithm that watches clients and ensures that they request no more than a configurable number of objects per time period, usually measured in seconds or minutes. If the client requests more than the configurable number, the client's IP address is blacklisted for a specified time period and subsequent requests are denied until the address has been freed from the blacklist.
https://devcentral.f5.com/articles/layer-4-vs-layer-7-dos-attack
these types of DDoS attacks require less bandwidth to take the site down and are harder to detect and block.
To be more exact, he was getting 5,233 HTTP requests every single second. From different IP addresses around the world. The client’s website was built on WordPress. The uniqueness of the requests was bypassing the caching system, forcing the system to render and respond to every request.
here is a quick geographic distribution of the IP’s hitting the site. This is for 1 second in the attack. Yes, every second these IP’s were changing.
By default, they were not passing our anomaly check, causing the requests to get blocked at the firewall. One of the many anomalies we look for are valid user agents, and if you look carefully you see that the requests didn’t have one. Hopefully, you’ll also notice that the referrers were dynamic and the packets were the same size, another very interesting signature. This triggered one of our rules, and within minutes his site was back and the attack blocked.
After we blocked the original requests and banned the IP addresses involved, everything went quiet, at least for a day. In less than 24 hours though, the attacks resumed with a higher intensity. Remember the caching bypass discussion above? Well, it happened again, and this time it wasn’t blocked automatically as it was operating as a wolf in sheep’s skin.
What the logs show us is that the attack was doing random searches for dictionary keywords (eg: news, gov, faith, etc ). This time they were using a valid browser (Firefox, Chrome, Safari, etc), user agents, and a valid referrer.
You see, they were leveraging normal user search habits. How do you block valid search requests without blocking valid users?
we noticed another anomaly, or what we’d classify as a signature in the new DDoS pattern. The attacker was rotating IP’s within a few seconds of each other, rotating referrers and user agents, all the while performing search requests. Finally, something we could build a rule for, thanks for that. Now each time we see the same IP with a different user agent/referrer within a small period of time, we’re able to block access. Within minutes, the attack was contained.
How we’re able to do this comes down to the technology around our Website Firewall. Just in the block list created by our log correlation tool, we banned 9,673 IP Addresses in the first few hours. During the following days, the list grew to almost 40,000 different IP addresses. That’s quite a respectable botnet.
Attack Possibilities by OSI Layer
possible DDoS Traffic Types
Some DDoS Mitigation Actions and Hardware
Stateful inspection firewalls
Stateful SYN Proxy Mechanisms
Limiting the number of SYNs per second per IP
Limiting the number of SYNs per second per destination IP
Set ICMP flood SCREEN settings (thresholds) in the firewall
Set UDP flood SCREEN settings (thresholds) in the firewall
Rate limit routers adjacent to the firewall and network
https://www.us-cert.gov/sites/default/files/publications/DDoS%20Quick%20Guide.pdf
a valuable part of a DDoS attack mitigation solution. These features address a DDoS attack both by regulating the incoming traffic and by controlling the traffic as it is proxied to backend servers. It’s important not to assume that this traffic pattern always represents a DDoS attack. The use of forwarding proxies can also create this pattern because the forward proxy server’s IP address is used as the client address for requests from all the real clients it serves. However, the number of connections and requests from a forward proxy is typically much lower than in a DDoS attack
Because the traffic is generated by bots and is meant to overwhelm the server, the rate of traffic is much higher than a human user can generate.
The User‑Agent header is sometimes set to a non‑standard value.
The Referer header is sometimes set to a value you can associate with the attack.
Layer 7 HTTP/HTTPS attacks. Hoping to exhaust the server, the attackers flooded the target organization with a large number of HTTPS GET/POST requests using the following methods, amongst others:
Basic HTTP Floods: Requests for URLs with an old version of HTTP no longer used by the latest browsers or proxies
WordPress Floods: WordPress pingback attacks where the requests bypassed all caching by including a random number in the URL to make each request appear unique
Randomized HTTP Floods: Requests for random URLs that do not exist – for example, if example.com is the valid URL, the attackers were abusing this by requesting pages like www.example.com/loc id=12345, etc.
The challenge with a Layer 7 DDoS attack lies in the ability to distinguish human traffic from bot traffic. Layer 7 attacks continue to grow in complexity with ever-changing attack signatures and patterns, organizations and DDoS mitigation providers will need to have a dynamic mitigation strategy in place. Layer 7 visibility along with proactive monitoring and advanced alerting are critical to effectively defend against increasing Layer 7 threats.
a stateful firewall is a network firewall that tracks the operating state and characteristics of network connections traversing it.
The firewall is configured to distinguish legitimate packets for different types of connections. Only packets matching a known active connection are allowed to pass the firewall.
https://en.wikipedia.org/wiki/Stateful_firewall
How a Stateful Firewall Works
The stateful firewall spends most of its cycles examining packet information in Layer 4 (transport) and lower. However, it also offers more advanced inspection capabilities by targeting vital packets for Layer 7 (application) examination, such as the packet that initializes a connection. If the inspected packet matches an existing firewall rule that permits it, the packet is passed and an entry is added to the state table. From that point forward, because the packets in that particular communication session match an existing state table entry, they are allowed access without a call for further application layer inspection. Those packets only need to have their Layer 3 and 4 information (IP address and TCP/UDP port number) verified against the information stored in the state table to confirm that they are indeed part of the current exchange. This method increases overall firewall performance (versus proxy-type systems, which examine all packets) because only initiating packets need to be unencapsulated the whole way to the application layer.
Conversely, because these firewalls use such filtering techniques, they don't consider the application layer commands for the entire communications session, as a proxy firewall would. This equates to an inability to really control sessions based on application-level traffic, making it a less secure alternative to a proxy.
http://www.informit.com/articles/article.aspx?p=373120
Unlike a Denial of Service (DoS) attack, in which one computer and one internet connection is used to flood targeted resource with packets, a DDoS attack uses many computers and many Internet connections, often distributed globally in what is referred to as a botnet.
DDoS attacks can be broadly divided into three types:
Volume Based Attacks
Includes UDP floods, ICMP floods, and other spoofed-packet floods. The attack’s goal is to saturate the bandwidth of the attacked site, and magnitude is measured in bits per second (Bps).
Protocol Attacks
Includes SYN floods, fragmented packet attacks, Ping of Death, Smurf DDoS and more. This type of attack consumes actual server resources, or those of intermediate communication equipment, such as firewalls and load balancers, and is measured in Packets per second.
Application Layer Attacks
Includes Slowloris, Zero-day DDoS attacks, DDoS attacks that target Apache, Windows or OpenBSD vulnerabilities and more. Comprised ofseemingly legitimate and innocent requests, the goal of these attacks is to crash the web server, and the magnitude is measured in Requests per second.
Specific DDoS Attacks Types
Some specific and particularly popular and dangerous types of DDoS attacks include:
UDP Flood
This DDoS attack leverages the User Datagram Protocol (UDP), a sessionless networking protocol. This type of attack floods random ports on a remote host with numerous UDP packets, causing the host to repeatedly check for the application listening at that port, and (when no application is found) reply with an ICMP Destination Unreachable packet. This process saps host resources, and can ultimately lead to inaccessibility.
ICMP (Ping) Flood
Similar in principle to the UDP flood attack, an ICMP flood overwhelms the target resource with ICMP Echo Request (ping) packets, generally sending packets as fast as possible without waiting for replies. This type of attack can consume both outgoing and incoming bandwidth, since the victim’s servers will often attempt to respond with ICMP Echo Reply packets, resulting in a significant overall system slowdown.
SYN Flood
A SYN flood DDoS attack exploits a known weakness in the TCP connection sequence (the “three-way handshake”), wherein a SYN request to initiate a TCP connection with a host must be answered by a SYN-ACK response from that host, and then confirmed by an ACK response from the requester. In a SYN flood scenario, the requester sends multiple SYN requests, but either does not respond to the host’s SYN-ACK response or sends the SYN requests from a spoofed IP address. Either way, the host system continues to wait for an acknowledgment for each of the requests, binding resources until no new connections can be made, and ultimately resulting in a denial of service.
Ping of Death
A ping of death ("POD") attack involves the attacker sending multiple malformed or malicious pings to a computer. The maximum packet length of an IP packet (including header) is 65,535 bytes. However, the Data Link Layer usually poses limits to the maximum frame size - for example, 1500 bytes over an Ethernet network. In this case, a large IP packet is split across multiple IP packets (known as fragments), and the recipient host reassembles the IP fragments into the complete packet. In a Ping of Death scenario, following malicious manipulation of fragment content, the recipient ends up with an IP packet which is larger than 65,535 bytes when reassembled. This can overflow memory buffers allocated for the packet, causing a denial of service for legitimate packets. Slowloris
Slowloris is a highly-targeted attack, enabling one web server to take down another server, without affecting other services or ports on the target network. Slowloris does this by holding as many connections to the target web server open for as long as possible. It accomplishes this by creating connections to the target server but sending only a partial request. Slowloris constantly sends more HTTP headers, but never completes a request. The targeted server keeps each of these false connections open. This eventually overflows the maximum concurrent connection pool and leads to a denial of additional connections from legitimate clients.
Zero-day DDoS
“Zero-day” are simply unknown or new attacks, exploiting vulnerabilities for which no patch has yet been released. The term is well-known amongst the members of the hacker community, where the practice of trading Zero-day vulnerabilities has become a popular activity.
http://www.incapsula.com/ddos/ddos-attacks/
Denial-of-service attack
In computing, a denial-of-service attack (DoS attack) or distributed denial-of-service attack (DDoS attack) is an attempt to make a machine or network resource unavailable to its intended users.
It generally consists of the efforts of one or more people to temporarily or indefinitely interrupt or suspend services of a host connected to the Internet.
Methods of attack
There are two general forms of DoS attacks: those that crash services and those that flood services.
A DoS attack can be perpetrated in a number of ways. The five basic types of attack are:
Consumption of computational resources, such as bandwidth, disk space, or processor time.
Disruption of configuration information, such as routing information.
Disruption of state information, such as unsolicited resetting of TCP sessions.
Disruption of physical network components.
Obstructing the communication media between the intended users and the victim so that they can no longer communicate adequately.
A DoS attack may include execution of malware intended to:
Max out the processor's usage, preventing any work from occurring.
Trigger errors in the microcode of the machine.
Trigger errors in the sequencing of instructions, so as to force the computer into an unstable state or lock-up. Exploit errors in the operating system, causing resource starvation and/or thrashing, i.e. to use up all available facilities so no real work can be accomplished or it can crash the system itself
Crash the operating system itself.
Methods of attack of Denial-of-service attack
ICMP flood
A smurf attack is one particular variant of a flooding DoS attack on the public Internet Ping of death is based on sending the victim a malformed ping packet, which might lead to a system crash. Ping flood is based on sending the victim an overwhelming number of ping packets, usually using the "ping" command from unix-like hosts
(S)SYN flood A SYN flood occurs when a host sends a flood of TCP/SYN packets, often with a forged sender address
Teardrop attacks
A Teardrop attack involves sending mangled IP fragments with overlapping, over-sized payloads to the target machine.
Low-rate Denial-of-Service attacks
The Low-rate DoS (LDoS) attack exploits TCP’s slow-time-scale dynamics of retransmission time-out (RTO) mechanisms to reduce TCP throughput
Peer-to-peer attacks
Attackers have found a way to exploit a number of bugs in peer-to-peer servers to initiate DDoS attacks.
Asymmetry of resource utilization in starvation attacks
An attack which is successful in consuming resources on the victim computer
Permanent denial-of-service attacks
A permanent denial-of-service (PDoS), also known loosely as flashing, is an attack that damages a system so badly that it requires replacement or reinstallation of hardware
Application-level floods
Various DoS-causing exploits such as buffer overflow can cause server-running software to get confused and fill the disk space or consume all available memory or CPU time.
Nuke
A Nuke is an old denial-of-service attack against computer networks consisting of fragmented or otherwise invalid ICMP packets sent to the target, achieved by using a modified ping utility to repeatedly send this corrupt data, thus slowing down the affected computer until it comes to a complete stop.
R-U-Dead-Yet? (RUDY)
This attack is one of many web application DoS tools available to directly attack web applications by starvation of available sessions on the web server.
Slow Read attack
Slow Read attack sends legitimate application layer requests but reads responses very slowly, thus trying to exhaust server's connection pool
Distributed attack
A distributed denial of service attack (DDoS) occurs when multiple systems flood the bandwidth or resources of a targeted system, usually one or more web servers. This is the result of multiple compromised systems (for example a botnet) flooding the targeted system(s) with traffic. When a server is overloaded with connections, new connections can no longer be accepted
Reflected / Spoofed attack
A distributed reflected denial of service attack (DRDoS) involves sending forged requests of some type to a very large number of computers that will reply to the requests.
Unintentional denial of service
This describes a situation where a website ends up denied, not due to a deliberate attack by a single individual or group of individuals, but simply due to a sudden enormous spike in popularity. This can happen when an extremely popular website posts a prominent link to a second, less well-prepared site, for example, as part of a news story
Denial-of-Service Level II
In case of distributed attack or IP header modification (that depends on the kind of security behavior) it will fully block the attacked network from the Internet, but without system crash.
https://en.wikipedia.org/wiki/Denial-of-service_attack
DDoS mitigation
DDoS mitigation is a set of techniques for resisting distributed denial of service (DDoS) attacks on networks attached to the Internet by protecting the target and relay networks This is done by passing network traffic addressed to the attacked network through high-capacity networks with "traffic scrubbing" filters DDoS mitigation requires correctly identifying incoming traffic to separate human traffic from human-like bots and hijacked browsers The process is done by comparing signatures and examining different attributes of the traffic, including IP addresses, cookie variations, http headers, and Javascript footprints http://en.wikipedia.org/wiki/DDoS_mitigation
DDoS mitigation techniques
dark address prevention white/black list granular rate limiting anomaly recognition active verification dynamic filtering source rate limiting aggressive aging connection limiting syn proxy
LOIC (Low Orbit Ion Cannon)
Low Orbit Ion Cannon (LOIC) was originally developed by Praetox Technologies as an open-source network stress testing tool. It allowed developers to subject their servers to heavy network traffic loads for diagnostic purposes, but it has since been modified in the public domain through various updates and been widely used by Anonymous as a DDoS tool. The IRC-based “Hive Mind” mode enables a LOIC user to connect his or her copy of LOIC to an IRC channel in order to receive a target and other attack parameters via an IRC topic message. Using many copies of LOIC running in Hive Mind mode across many computers, a third party such as the “hacktivist” group Anonymous can take control of each copy of LOIC simultaneously. http://security.radware.com/knowledge-center/DDoSPedia/loic-low-orbit-ion-cannon/
IP Flood
IP flooding occurs when a computer hacker floods your computer with information through your network connection and IP address. This uses up your network bandwidth and disables you from your online activities. To recover from being IP flooded, request a new IP address from your Internet Service Provider and manually configure your network connection.
The above scan by nmap is highly reliable, but its drawback is that it's also easily detectable. Nearly every system admin will know that you're scanning their network as it creates a full TCP connection, and this is logged with your IP address in the log files.
Nmap can also be an excellent denial of service (DOS) tool. If several individuals all send packets from nmap at a target simultaneously at high speed (nmap "insane" speed or -T5), they're likely to overwhelm the target and it will be unable to process new website requests effectively, rendering it useless.
https://null-byte.wonderhowto.com/how-to/hack-like-pro-conduct-active-reconnaissance-and-dos-attacks-with-nmap-0146950
How do NTP reflection attacks work?
Similar to DNS amplification attacks, the attacker sends a small forged packet that requests a large amount of data be sent to the target IP Address. Monlist is a remote command in older version of NTP that sends the requester a list of the last 600 hosts who have connected to that server For attackers the monlist query is a great reconnaissance tool For a localized NTP server it can help to build a network profile. as a DDoS tool, it is even better because a small query can redirect megabytes worth of traffic Most scanning tools, such as NMAP, have a monlist module for gathering network information and many attack tools, including metasploit, have a monlist DDoS module.
Skipfish is an active web application security reconnaissance tool. It prepares an interactive sitemap for the targeted site by carrying out a recursive crawl and dictionary-based probes.
http://tools.kali.org/web-applications/skipfish
What’s a DoS attack, what’s a DDoS attack and what’s the difference?
A DoS attack is a denial of service attack where a computer is used to flood a server with TCP and UDP packets. A DDoS attack is where multiple systems target a single system with a DoS attack. The targeted network is then bombarded with packets from multiple locations.
Spring also JSR-250 based annotations which include @PostConstruct, @PreDestroy and @Resource annotations. Though these annotations are not really required because you already have other alternate http://www.tutorialspoint.com/spring/spring_jsr250_annotations.htm
JSR 250 is a Java Specification Request with the objective to develop annotations (that is, information about a software program that is not part of the program itself) for common semantic concepts in the Java SE and Java EE platforms
Suppose you are developing a course management system for a training center.
The first class you create for this system is Course. This class is called an entity class or a persistent class because it represents a real-world entity and its instances will be persisted to a database. Remember that for each entity class to be persisted by an ORM framework, a default constructor with no argument is required.
public class Course { private Long id; ... // Constructors, Getters and Setters }
For each entity class, you must define an identifier property to uniquely identify an entity. It’s a best practice to define an auto-generated identifier because this has no business meaning and thus won’t be changed under any circumstances. this identifier will be used by the ORM framework to determine an entity’s state. If the identifier value is null, this entity will be treated as a new and unsaved entity. When this entity is persisted, an insert SQL statement will be issued; otherwise, an update statement will. To allow the identifier to be null, you should choose a primitive wrapper type like java.lang.Integer and java.lang.Long for the identifier
Hibernate's own connection pooling algorithm is, however, quite rudimentary.
You should use a third party pool for best performance and stability. Just replace the hibernate.connection.pool_size property with connection pool specific settings. This will turn off Hibernate's internal pool.
C3P0 is an open source JDBC connection pool distributed along with Hibernate in the lib directory. Hibernate will use its org.hibernate.connection.C3P0ConnectionProvider for connection pooling if you set hibernate.c3p0.* properties. If you would like to use Proxool, refer to the packaged hibernate.properties
The following is an example hibernate.properties file for c3p0: hibernate.connection.driver_class = org.postgresql.Driver hibernate.connection.url = jdbc:postgresql://localhost/mydatabase hibernate.connection.username = myuser hibernate.connection.password = secret hibernate.c3p0.min_size=5 hibernate.c3p0.max_size=20 hibernate.c3p0.timeout=1800 hibernate.c3p0.max_statements=50 hibernate.dialect = org.hibernate.dialect.PostgreSQLDialect
hibernate.c3p0.min_size – Minimum number of JDBC connections in the pool. Hibernate default: 1
hibernate.c3p0.max_size – Maximum number of JDBC connections in the pool. Hibernate default: 100 hibernate.c3p0.timeout – When an idle connection is removed from the pool (in second). Hibernate default: 0, never expire. hibernate.c3p0.max_statements – Number of prepared statements will be cached. Increase performance. Hibernate default: 0 , caching is disable. hibernate.c3p0.idle_test_period – idle time in seconds before a connection is automatically validated. Hibernate default: 0
Toad test to see connections http://www.mkyong.com/hibernate/how-to-configure-the-c3p0-connection-pool-in-hibernate/
Automatically validates or exports schema DDL to the database when the SessionFactory is created. With create-drop, the database schema will be dropped when the SessionFactory is closed explicitly.
validate: validate the schema, makes no changes to the database.
update: update the schema.
create: creates the schema, destroying previous data.
create-drop: drop the schema at the end of the session.
http://stackoverflow.com/questions/438146/hibernate-hbm2ddl-auto-possible-values-and-what-they-do
Hibernate creators discourage doing so in a production environment in their book "Java Persistence with Hibernate"
excerpt: We've seen Hibernate users trying to use SchemaUpdate to update the schema of a production database automatically. This can quickly end in disaster and won't be allowed by your DBA.
Defining a custom converter in JSF is a three step process
1 Create a converter class by implementing javax.faces.convert.Converter interface. 2 Implement getAsObject() and getAsString() methods of above interface. 3 Use Annotation @FacesConvertor to assign a unique id to the custom convertor. http://www.tutorialspoint.com/jsf/jsf_customconvertor_tag.htm
Steps
1. Create a converter class by implementing javax.faces.convert.Converter interface. 2. Override both getAsObject() and getAsString() methods. 3. Assign an unique converter ID with @FacesConverter annotation. 4. Link your custom converter class to JSF component via f:converter tag. http://www.mkyong.com/jsf2/custom-converter-in-jsf-2-0/
Jetty is fully hot deployable, but does not have any native hot deployers
What this means is that Jetty contexts, servlets and filters may be added, stopped, started and reloaded dynamically, but that Jetty does not have any services that trigger these events. http://67-23-9-112.static.slicehost.net/faq?s=200-General&t=HotDeploy
How to work with Java hot-deploy
You don't really have to restart the server after you change java code,launch RJR with Debug Mode (debug-as -> Run Jetty) and you are now able to enjoy the default hot-deploy feature from JDK
RJR refers to rujettyrun https://code.google.com/p/run-jetty-run/wiki/UserGuide
Code Bubbles is a front end to Eclipse designed to simplify programming by making it easy for the programmer to define and use working sets. http://cs.brown.edu/~spr/codebubbles/
The Joint Range Extension Applications Protocol ("JREAP") extends the range of Tactical Data Link by permitting tactical data messages to be transmitted over long-distance networks, e.g. satellite links. http://en.wikipedia.org/wiki/JREAP
a communications protocol for message-oriented middleware based on XML (Extensible Markup Language) the protocol has also been used for publish-subscribe systems, signalling for VoIP, video, file transfer, gaming, Internet of Things applications such as the smart grid, and social networking services. http://en.wikipedia.org/wiki/XMPP
commands in sequence with conditionals and loops, it provides a list of production rules. Each rule has a condition and an action - simplistically you can think of it as a bunch of if-then statements.
The subtlety is that rules can be written in any order and the system can choose to evaluate them in whatever order makes sense for it. A good way of thinking of it is that the system runs through all the rules, picks the ones for which the condition is true, and then evaluates the corresponding actions.
http://martinfowler.com/bliki/RulesEngine.html
Getting Started With the Java Rule Engine API (JSR 94): Toward Rule-Based Applications
For many mission-critical applications, the process of automating business policies, procedures, and business logic is simply too dynamic to manage effectively as application source code
The Business Rules Group defines a business rule as a statement that defines or constrains some aspect of the business; a business rule is intended to assert business structure or to control or influence the business's behavior
A rule engine evaluates and executes rules, which are expressed as if-then statements. The power of business rules lies in their ability both to separate knowledge from its implementation logic and to be changed without changing source code.
Drools https://www.jboss.org/drools/ Mandarax JLisa JEOPS - The Java Embedded Object Production System OpenRules Open Lexicon SweetRules JRuleEngine http://java-source.net/open-source/rule-engines
Enterprise resource planning (ERP) is business management software—usually a suite of integrated applications—that a company can use to store and manage data from every stage of business, including:
Product planning, cost and development Manufacturing Marketing and sales Inventory management Shipping and payment http://en.wikipedia.org/wiki/Enterprise_resource_planning
Business support systems (BSS) are the components that a telephone operator or telco uses to run its business operations towards customer
Basically it deals with the taking of orders, payment issues, revenues etc. The role of business support systems in a service provider is to cover four main areas:
Product management Order management Revenue management Customer management http://en.wikipedia.org/wiki/Business_support_system
Operations support systems are computer systems used by telecommunications service providers. The term OSS most frequently describes "network systems" dealing with the telecom network itself, supporting processes such as maintaining network inventory, provisioning services, configuring network components, and managing faults
The complementary term, business support systems or BSS, is a newer term and typically refers to “business systems” dealing with customers, supporting processes such as taking orders, processing bills, and collecting payments. The two systems together are often abbreviated OSS/BSS, BSS/OSS or simply B/OSS.
OSS covers at least the application areas:
Network management systems Service delivery Service fulfillment, including the network inventory, activation and provisioning Service assurance Customer care http://en.wikipedia.org/wiki/Operations_support_system
A Decision Support System (DSS) is a computer-based information system that supports business or organizational decision-making activities. DSSs serve the management, operations, and planning levels of an organization (usually mid and higher management) and help to make decisions, which may be rapidly changing and not easily specified in advance (Unstructured and Semi-Structured decision problems). Decision support systems can be either fully computerized, human or a combination of both.
Typical information that a decision support application might gather and present includes:
inventories of information assets (including legacy and relational data sources, cubes, data warehouses, and data marts), comparative sales figures between one period and the next, projected revenue figures based on product sales assumptions
Structure: Data is organized into tables with rows and columns.
Relationships: Tables are linked through relationships (primary and foreign keys) to establish connections between data.
Data Integrity: Strong data integrity through ACID properties (Atomicity, Consistency, Isolation, Durability).
Query Language: SQL (Structured Query Language) is used for data manipulation and retrieval.
Examples: MySQL, PostgreSQL, Oracle, SQL Serve
Non-Relational Databases (NoSQL)
Structure: Data is stored in various models like key-value, document, columnar, or graph.
Flexibility: Highly flexible schema, accommodating diverse data types.
Scalability: Designed for handling large volumes of data and high traffic.
Performance: Often optimized for specific data access patterns.
Examples: MongoDB, Cassandra, Redis, Neo4
When to Use Which
Relational Databases:
Complex relationships between data
Strong data consistency requirements
ACID compliance is essential
Predictable data access patterns
Non-Relational Databases:
Large volumes of unstructured or semi-structured data
High write throughput and scalability
Rapid development needs
Flexible data models
In conclusion, the choice between relational and non-relational databases depends on the specific requirements of the application. Many modern applications use a combination of both to handle diverse data needs effectively
ChatGPT
1. Data Model
Relational Databases:
Structure: Data is organized into tables (relations) with rows and columns. Each table represents an entity, and columns represent attributes of that entity.
Schema: A predefined schema defines the structure of the tables, including data types and constraints. The schema must be established before data is inserted.
Non-Relational Databases:
Structure: Data is stored in various formats, including key-value pairs, documents, wide-columns, or graphs, depending on the type of non-relational database.
Schema: Schemas are flexible or schema-less. Data can be stored without a fixed schema, allowing for dynamic and evolving data structures.
2. Query Language
Relational Databases:
Language: Use SQL (Structured Query Language) for querying and managing data. SQL provides a powerful and standardized way to perform operations like querying, updating, and joining data.
Non-Relational Databases:
Language: Use various query languages or APIs depending on the database type. For example, MongoDB uses BSON (Binary JSON) queries, while key-value stores may use simple key-based retrieval
3. Scalability
Relational Databases:
Scalability: Typically scale vertically by adding more resources (CPU, RAM) to a single server. Horizontal scaling (scaling out across multiple servers) can be challenging due to the rigid schema and complex joins.
Non-Relational Databases:
Scalability: Designed to scale horizontally by distributing data across multiple servers or nodes. This makes them well-suited for handling large volumes of data and high traffic loads.
4. Data Integrity and Transactions
Relational Databases:
ACID Compliance: Generally adhere to ACID (Atomicity, Consistency, Isolation, Durability) principles to ensure data integrity and reliable transactions.
Transactions: Support complex transactions involving multiple operations, ensuring that all operations within a transaction are completed successfully.
Non-Relational Databases:
Eventual Consistency: Often use eventual consistency models rather than strict ACID compliance. They prioritize availability and partition tolerance, accepting that data may be temporarily inconsistent.
Transactions: May have limited support for multi-document transactions, focusing instead on single-document operations or simple transactions.
5. Use Cases
Relational Databases:
Use Cases: Well-suited for applications requiring complex queries, relationships between data, and strong data integrity. Examples include financial systems, CRM systems, and traditional enterprise applications.
Non-Relational Databases:
Use Cases: Ideal for applications with rapidly changing data, high volumes of unstructured data, or requiring flexible schemas. Examples include content management systems, social media platforms, and real-time analytics.
6. Examples
Relational Databases:
Examples: MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server.
Relational Databases use a structured schema and SQL for managing data, excelling in scenarios requiring complex queries, strong data integrity, and consistent transactions. They typically scale vertically and are suited for traditional, well-defined data relationships.
Non-Relational Databases offer flexibility in schema design and scalability through horizontal distribution. They are designed for handling large volumes of unstructured or semi-structured data and are ideal for dynamic and rapidly changing applications where high availability is a priority.
Both types of databases have their unique advantages and are chosen based on specific application requirements and use cases.
NoSQL
Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. http://nosql-database.org/
What is NoSQL Database?
A NoSQL database provides a mechanism for storage and retrieval of data that use looser consistency models than traditional relational databases in order to achieve horizontal scaling and higher availability. Some authors refer to them as "Not only SQL" to emphasize that some NoSQL systems do allow SQL-like query language to be used.
NoSQL database systems are often highly optimized for retrieval and appending operations and often offer little functionality beyond record storage (e.g. key–value pairs stores)
In short, NoSQL database management systems are useful when working with a huge quantity of data when the data's nature does not require a relational model
Usage examples might be to store millions of key–value in one or a few associative arrays or to store millions of data records. This organization is particularly useful for statistical or real-time analysis of growing lists of elements (such as Twitter posts or the Internet server logs from a large group of users).
The reduced run time flexibility compared to full SQL systems is compensated by large gains in scalability and performance for certain data models. With the rise of the real-time web, there was a need to provide information out of large volumes of data which more or less followed similar horizontal structures. As such, NoSQL databases are often highly optimized for retrieve and append operations and often offer little functionality beyond record storage
Often, NoSQL databases are categorized according to the way they store the data:
Document store
The central concept of a document store is the notion of a "document". While each document-oriented database implementation differs on the details of this definition, in general, they all assume that documents encapsulate and encode data (or information) in some standard formats or encodings. Encodings in use include XML, YAML, and JSON as well as binary forms like BSON, PDF and Microsoft Office documents (MS Word, Excel, and so on).
Graph This kind of database is designed for data whose relations are well represented as a graph (elements interconnected with an undetermined number of relations between them). The kind of data could be social relations, public transport links, road maps or network topologies, for example.
Key–value store Key–value stores allow the application to store its data in a schema-less way. The data could be stored in a datatype of a programming language or an object. Because of this, there is no need for a fixed data model.
http://en.wikipedia.org/wiki/NoSQL
Database Transactions: ACID
Atomicity
One atomic unit of work– One atomic unit of work
– If one step fails, it all fails
• Consistency
– Works on a consistent set of data that is hidden from other
concurrently running transactions
– Data left in a clean and consistent state after completion
• Isolation• Isolation
– Allows multiple users to work concurrently with the same data
without compromising its integrity and correctness.
– A particular transaction should not be visible to other concurrentlyA particular transaction should not be visible to other concurrently
running transactions.
• Durability
– Once completed all changes become persistentOnce completed, all changes become persistent
– Persistent changes not lost even if the system subsequently fails
Transaction Demarcation
What happens if you don’t call commit or rollback at the end of your transaction?
What happens depends on how the vendors ppp
implement the specification.
– With Oracle JDBC drivers, for example, the call to close() commits
the transaction!the transaction!
– Most other JDBC vendors take the sane route and roll back any
pending transaction when the JDBC connection object is closed and the resource is returned to the pool.
In computer science, ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. In the context of databases, a single logical operation on the data is called a transaction For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction. Atomicity Atomicity requires that each transaction is "all or nothing": if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. Consistency The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including but not limited to constraints, cascades, triggers, and any combination thereof Isolation The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e. one after the other. Durability Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. http://en.wikipedia.org/wiki/ACID
What is ACID in Database world?
Atomicity - "All or nothing" .. entire transaction fails if part of a query fails Consistency - Only valid data is written to database Isolation - Multiple simultaneous transactions don't impact each other Durability - Transactions committed to database will never be lost http://answers.yahoo.com/question/index?qid=1006050901996
Atomicity:
when a database processes a transaction, it is either fully completed or not executed at all. Consistency When a transaction results in invalid data, the database reverts to its previous state, which abides by all customary rules and constraints. Isolation Ensures that transactions are securely and independently processed at the same time without interference, but it does not ensure the order of transaction For example, user A withdraws $100 and user B withdraws $250 from user Z’s account, which has a balance of $1000. Since both A and B draw from Z’s account, one of the users is required to wait until the other user transaction is completed, avoiding inconsistent data. If B is required to wait, then B must wait until A’s transaction is completed, and Z’s account balance changes to $900. Now, B can withdraw $250 from this $900 balance. Durability: In the above example, user B may withdraw $100 only after user A’s transaction is completed and is updated in the database. If the system fails before A’s transaction is logged in the database, A can not withdraw any money, and Z’s account returns to its previous consistent state. http://www.techopedia.com/definition/23949/atomicity-consistency-isolation-durability-acid
the 2 out of 3 is really 1 out of 2: It's really just A vs C!
Availability is achieved by replicating the data across different machines
Consistency is achieved by updating several nodes before allowing further reads
Total partitioning, meaning failure of part of the system is rare. However, we could look at a delay, a latency, of the update between nodes, as a temporary partitioning. It will then cause a temporary decision between A and C:
On systems that allow reads before updating all the nodes, we will get high Availability
On systems that lock all the nodes before allowing reads, we will get Consistency
there's no distributed system that wants to live with "Paritioning" - if it does, it's not distributed. That is why putting SQL in this triangle may lead to confusion https://dzone.com/articles/better-explaining-cap-theorem
What is the CAP Theorem?
The CAP theorem states that a distributed system cannot simultaneously be consistent, available, and partition tolerant
Consistency
any read operation that begins after a write operation completes must return that value, or the result of a later write operation
Availability
every request received by a non-failing node in the system must result in a response
In an available system, if our client sends a request to a server and the server has not crashed, then the server must eventually respond to the client. The server is not allowed to ignore the client's requests.
Partition Tolerance the network will be allowed to lose arbitrarily many messages sent from one node to another
The Proof
we can prove that a system cannot simultaneously have all three.
Big Data and NoSQL Databases Tutorial(BaSE)- Part 3
Big Data and NoSQL Databases Tutorial-(CAP theorem)- Part 5
ACID versus BASE for database transactions
Database developers all know the ACID acronym.
Atomic: Everything in a transaction succeeds or the entire transaction is rolled back.
Consistent: A transaction cannot leave the database in an inconsistent state.
Isolated: Transactions cannot interfere with each other.
Durable: Completed transactions persist, even when servers restart etc
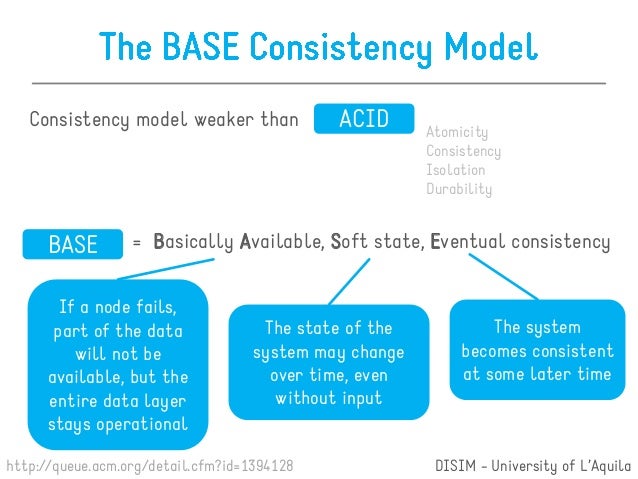
An alternative to ACID is BASE:
Basic Availability
Soft-state
Eventual consistency
ACID is incompatible with availability and performance in very large systems
For example, suppose you run an online book store and you proudly display how many of each book you have in your inventory.
Every time someone is in the process of buying a book, you lock part of the database until they finish so that all visitors around the world will see accurate inventory numbers.
That works well if you run The Shop Around the Corner but not if you run Amazon.com.
Rather than requiring consistency after every transaction, it is enough for the database to eventually be in a consistent state.
http://www.johndcook.com/blog/2009/07/06/brewer-cap-theorem-base/
Myth: Eric Brewer On Why Banks Are BASE Not ACID - Availability Is Revenue
Myth: Money is important, so banks must use transactions to keep money safe and consistent, right?
Reality: Banking transactions are inconsistent, particularly for ATMs. ATMs are designed to have a normal case behaviour and a partition mode behaviour. In partition mode Availability is chosen over Consistency.
Your ATM transaction must go through so Availability is more important than consistency. If the ATM is down then you aren’t making money.
This is not a new problem for the financial industry.
They’ve never had consistency because historically they’ve never had perfect communication
Instead, the financial industry depends on auditing.
What accounts for the consistency of bank data is not the consistency of its databases but the fact that everything is writtendown twice and sorted out later using a permanent and unalterable record that is reconciled later.
If an ATM is disconnected from the network and when the partition eventually heals, the ATM sends a list of operations to the bank and the end balance will still be correct
ATMs are reorderable and can be made consistent later
http://highscalability.com/blog/2013/5/1/myth-eric-brewer-on-why-banks-are-base-not-acid-availability.html
NoSQL provides an alternative to ACID called BASE.
What is Basic Availability, Soft State and Eventual Consistency (BASE)
1. ACID properties are to RDBMS as BASE properties are to NoSQL systems. BASE refers to Basic availability, Soft state and Eventual consistency. Basic availability implies continuous system availability despite network failures and tolerance to temporary inconsistency. Eventual consistency means that if no further updates are made to a given updated database item for long enough period of time , all users will see the same value for the updated item. Soft state refers to state change without input which is required for eventual consistency
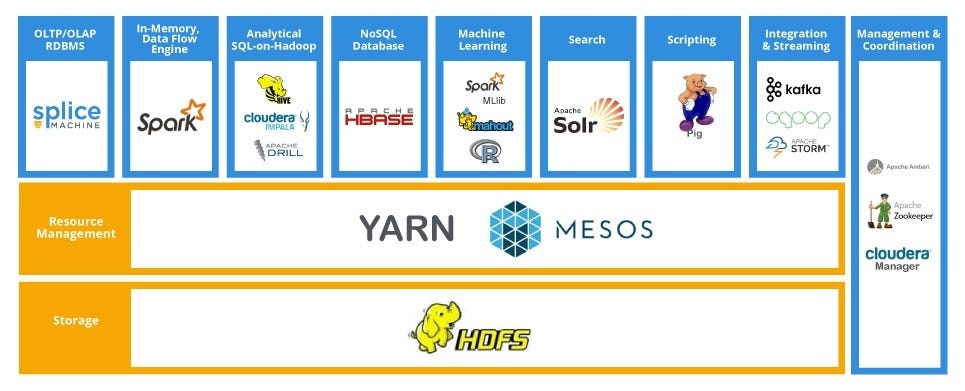
In the past, when we wanted to store more data or increase our processing power, the common option was to scale vertically (get more powerful machines) or further optimize the existing code base. However, with the advances in parallel processing and distributed systems, it is more common to expand horizontally, or have more machines to do the same task in parallel
We can already see a bunch of data manipulation tools in the Apache project like Spark, Hadoop, Kafka, Zookeeper and Storm. However, in order to effectively pick the tool of choice, a basic idea of CAP Theorem is necessary.
CAP Theorem is a concept that a distributed database system can only have 2 of the 3: Consistency, Availability and Partition Tolerance.
Partition Tolerance
When dealing with modern distributed systems, Partition Tolerance is not an option. It’s a necessity. Hence, we have to trade between Consistency and Availability.
A system that is partition-tolerant can sustain any amount of network failure that doesn’t result in a failure of the entire network.
Data records are sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
High Consistency
performing a read operation will return the value of the most recent write operation causing all nodes to return the same data
High Availability
This condition states that every request gets a response on success/failure.
Every client gets a response, regardless of the state of any individual node in the system.
This metric is trivial to measure: either you can submit read/write commands, or you cannot
If you ever worked with any NoSQL database, you must have heard about CAP theorem
CAP stands for Consistency, Availability and Partition Tolerance.
Consistency (C ): All nodes see the same data at the same time. What you write you get to read.
Availability (A): A guarantee that every request receives a response about whether it was successful or failed. Whether you want to read or write you will get some response back.
Partition tolerance (P): The system continues to operate despite arbitrary message loss or failure of part of the system. Irrespective of communication cut down among the nodes, system still works. Often CAP theorem is misunderstood. It is not any 2 out of 3. Key point here is P is not visible to your customer. It is Technology solution to enable C and A. Customer can only experience C and A. P is driven by wires, electricity, software and hardware and none of us have any control and often P may not be met. If P is existing, there is no challenge with A and C (except for latency issues).
https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4
NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable.
The original intention has been modern web-scale databases. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above.
LIST OF NOSQL DATABASES Core NoSQL Systems: [Mostly originated out of a Web 2.0 need]
Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?
Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features.
Document Store MongoDB API: BSON, Protocol: C, Query Method: dynamic object-based language & MapReduce, Replication: Master Slave & Auto-Sharding, Written in: C++,Concurrency: Update in Place. Misc: Indexing, GridFS, Freeware + Commercial License Elasticsearch API: REST and many languages, Protocol: REST, Query Method: via JSON, Replication + Sharding: automatic and configurable, written in: Java, Misc: schema mapping, multi tenancy with arbitrary indexes, Company and Support CouchDB API: JSON, Protocol: REST, Query Method: MapReduceR of JavaScript Funcs, Replication: Master Master, Written in: Erlang, Concurrency: MVCC
Key Value / Tuple Store Riak API: JSON, Protocol: REST, Query Method: MapReduce term matching , Scaling: Multiple Masters; Written in: Erlang, Concurrency: eventually consistent (stronger then MVCC via Vector Clocks)
Graph Databases Bigdata API: Java, Jini service discovery, Concurrency: very high (MVCC), Written in: Java, Misc: GPL + commercial, Data: RDF data with inference, dynamic key-range sharding of indices, Misc
Multimodel Databases http://nosql-database.org
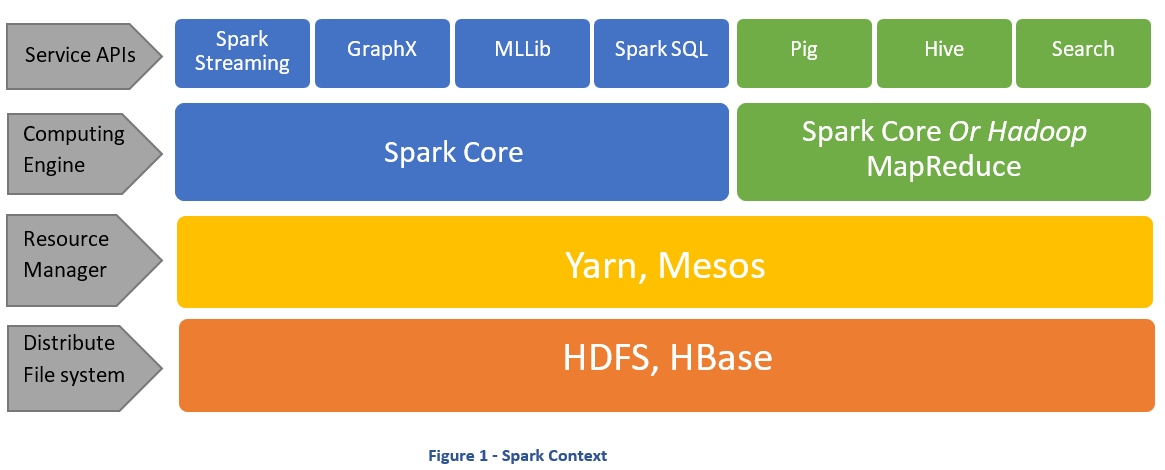
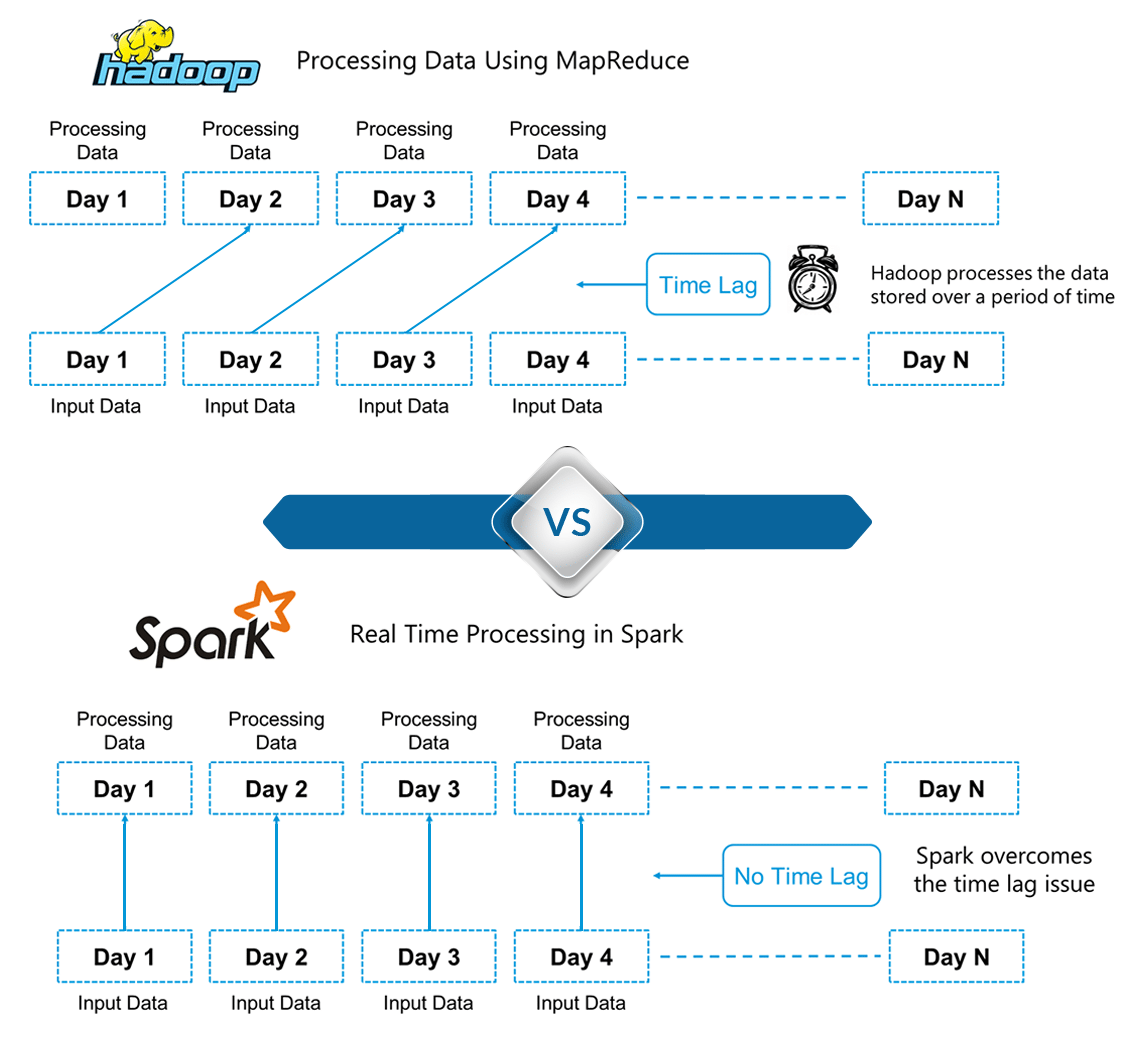
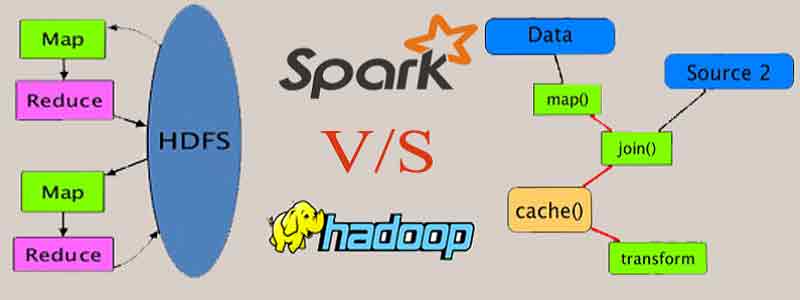
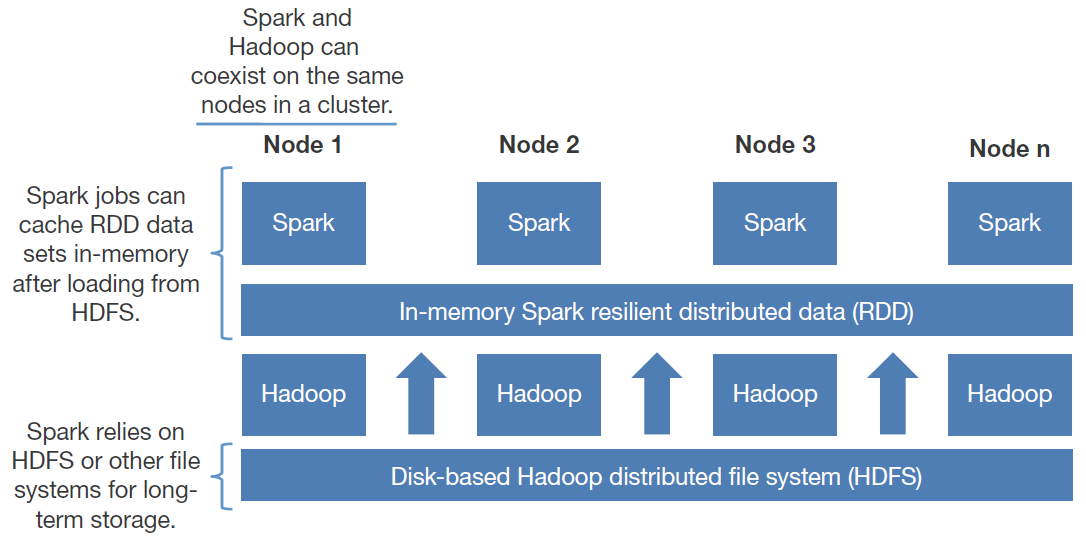
What is Apache Spark?
A n00bs guide to Apache Spark
Spark Tutorial: Real Time Cluster Computing Framework
Hadoop vs Spark – Choosing the Right Big Data Software
Spark vs. Hadoop – Who Wins?
Apache Spark vs Hadoop MapReduce – Feature Wise Comparison [Infographic]
Hadoop and Spark: Friends or Foes?
Chapter 4. In-Memory Computing with Spark
park for Big Data Analytics [Part 1]
Presto is a high performance, distributed SQL query engine for big data.
https://prestosql.io/
Spark SQL is Apache Spark's module for working with structured data.
https://spark.apache.org/sql/
Differences Between to Spark SQL vs Presto
Presto in simple terms is ‘SQL Query Engine’, initially developed for Apache Hadoop. It’s an open source distributed SQL query engine designed for running interactive analytic queries against data sets of all sizes.
Spark SQL is a distributed in-memory computation engine with a SQL layer on top of structured and semi-structured data sets. Since its in-memory processing, the processing will be fast in Spark SQL
https://www.educba.com/spark-sql-vs-presto/
What is Database Mirroring?
can be used to design high-availability and high-performance solutions for database redundancy.
In database mirroring, transaction log records are sent directly from the principal database to the mirror database.
This helps to keep the mirror database up to date with the principal database, with no loss of committed data.
If the principal server fails, the mirror server automatically becomes the new principal server and recovers the principal database using a witness server under high-availability mode.
Principal database is the active live database that supports all the commands, Mirror is the hot standby and witness which allows for a quorum in case of automatic switch over
How does Database Mirroring works?
In database mirroring, the transaction log records for a database are directly transferred from one server to another, thereby maintaining a hot standby server. As the principal server writes the database’s log buffer to disk, it simultaneously sends that block of log records to the mirror instance. The mirror server continuously applies the log records to its copy of the database. Mirroring is implemented on a per-database basis, and the scope of protection that it provides is restricted to a single-user database. Database mirroring works only with databases that use the full recovery model.
What is a Principal server?
Principal server is the server which serves the databases requests to the Application.
What is a Mirror?
This is the Hot standby server which has a copy of the database.
What is a Witness Server?
This is an optional server. If the Principal server goes down then Witness server controls the fail over process.
What is Synchronous and Asynchronous mode of Database Mirroring?
In synchronous mode, committed transactions are guaranteed to be recorded on the mirror server. Should a failure occur on the primary server, no committed transactions are lost when the mirror server takes over. Using synchronous mode provides transaction safety because the operational servers are in a synchronized state, and changes sent to the mirror must be acknowledged before the primary can proceed
In asynchronous mode, committed transactions are not guaranteed to be recorded on the mirror server. In this mode, the primary server sends transaction log pages to the mirror when a transaction is committed. It does not wait for an acknowledgement from the mirror before replying to the application that the COMMIT has completed. Should a failure occur on the primary server, it is possible that some committed transactions may be lost when the mirror server takes over.
What are the benefits of that Database Mirroring?
Database mirroring architecture is more robust and efficient than Database Log Shipping.
It can be configured to replicate the changes synchronously to minimized data loss.
It has automatic server failover mechanism.
Configuration is simpler than log shipping and replication, and has built-in network encryption support (AES algorithm)
Because propagation can be done asynchronously, it requires less bandwidth than synchronous method (e.g. host-based replication, clustering) and is not limited by geographical distance with current technology.
Database mirroring supports full-text catalogs.
Does not require special hardware (such as shared storage, heart-beat connection) and cluster ware, thus potentially has lower infrastructure cost
What are the Disadvantages of Database Mirroring?
Potential data lost is possible in asynchronous operation mode.
It only works at database level and not at server level.It only propagates changes at database level, no server level objects, such as logins and fixed server role membership, can be propagated.
Automatic server failover may not be suitable for application using multiple databases.
What are the Restrictions for Database Mirroring?
A mirrored database cannot be renamed during a database mirroring session.
Only user databases can be mirrored. You cannot mirror the master, msdb, tempdb, or model databases.
Database mirroring does not support FILESTREAM. A FILESTREAM filegroup cannot be created on the principal server. Database mirroring cannot be configured for a database that contains FILESTREAM filegroups.
On a 32-bit system, database mirroring can support a maximum of about 10 databases per server instance.
Database mirroring is not supported with either cross-database transactions or distributed transactions.
What are the minimum requirements for Database Mirroring?
Database base recovery model should be full
Database name should be same on both SQL Server instances
Server should be in the same domain name
Mirror database should be initialized with principle server
What are the operating modes of Database Mirroring?
High Availability Mode
High Protection Mode
High Performance Mode
What is High Availability operating mode?
It consists of the Principal, Witness and Mirror in synchronous communication.If Principal is lost Mirror can automatically take over.If the network does not have the bandwidth, a bottleneck could form causing performance issue in the Principal.In this mode SQL server ensures that each transaction that is committed on the Principal is also committed in the Mirror prior to continuing with next transactional operation in the principal.
What is High Protection operating mode?
It is pretty similar to High Availability mode except that Witness is not available, as a result failover is manual. It also has transactional safety FULL i.e. synchronous communication between principal and mirror. Even in this mode if the network is poor it might cause performance bottleneck.
What is High Performance operating mode?
It consists of only the Principal and the Mirror in asynchronous communication. Since the safety is OFF, automatic failover is not possible, because of possible data loss; therefore, a witness server is not recommended to be configured for this scenario. Manual failover is not enabled for the High Performance mode. The only type of failover allowed is forced service failover, which is also a manual operation.
What are Recovery models support Database Mirroring?
Database Mirroring is supported with Full Recovery model.
What is Log Hardening?
Log hardening is the process of writing the log buffer to the transaction log on disk, a process called.
What is Role-switching?
Inter changing of roles like principal and mirror are called role switching.
Database mirroring is a solution for increasing the availability of a SQL Server database. Mirroring is implemented on a per-database basis and works only with databases that use the full recovery model.
Database mirroring is the creation and maintenance of redundant copies of a database. The purpose is to ensure continuous data availability and minimize or avoid downtime that might otherwise result from data corruption or loss, or from a situation when the operation of a network is partially compromised.
It automatically sends transaction log backups from one database (Known as the primary database) to a database (Known as the Secondary database) on another server. An optional third server, known as the monitor server, records the history and status of backup and restore operations. The monitor server can raise alerts if these operations fail to occur as scheduled.
Mirroring::
Database mirroring is a primarily software solution for increasing database availability.
It maintains two copies of a single database that must reside on different server instances of SQL Server Database Engine.
Replication::
It is a set of technologies for copying and distributing data and database objects from one database to another and then synchronizing between databases to maintain consistency. Using replication, you can distribute data to different locations and to remote or mobile users over local and wide area networks, dial-up connections, wireless connections, and the Internet.
the master-slave replication was used for failover, backup, and read scaling.
replaced by replica sets
Replica Set in MongoDB
A replica set consists of a group of mongod (read as Mongo D) instances that host the same data set.
In a replica set, the primary mongod receives all write operations and the secondary mongod replicates the operations from the primary and thus both have the same data set.
The primary node receives write operations from clients.
A replica set can have only one primary and therefore only one member of the replica set can receive write operations.
A replica set provides strict consistency for all read operations from the primary.
The primary logs any changes or updates to its data sets in its oplog(read as op log).
The secondaries also replicate the oplog of the primary and apply all the operations to their data sets.
When the primary becomes unavailable, the replica set nominates a secondary as the primary.
By default, clients read data from the primary.
Automatic Failover in MongoDB
When the primary node of a replica set stops communicating with other members for more than 10 seconds or fails, the replica set selects another member as the new primary.
The selection of the new primary happens through an election process and whichever secondary node gets majority of the votes becomes the primary.
you may deploy a replica set in multiple data centers or manipulate the primary election by adjusting the priority of members
replica sets support dedicated members for functions, such as reporting, disaster recovery, or backup.
In addition to the primary and secondaries, a replica set can also have an arbiter.
Unlike secondaries, arbiters do not replicate or store data.
arbiters play a crucial role in selecting a secondary to take the place of the primary when the primary becomes unavailable.
What is Sharding in MongoDB?
Sharding in MongoDB is the process of distributing data across multiple servers for storage.
MongoDB uses sharding to manage massive data growth.
With an increase in the data size, a single machine may not be able to store data or provide an acceptable read and write throughput
MongoDB sharding supports horizontal scaling and thus is capable of distributing data across multiple machines.
Sharding in MongoDB allows you to add more servers to your database to support data growth and automatically balances data and load across various servers.
MongoDB sharding provides additional write capacity by distributing the write load over a number of mongod instances.
It splits the data set and distributes them across multiple databases, or shards.
Each shard serves as an independent database, and together, shards make a single logical database.
MongoDB sharding reduces the number of operations each shard handles and as a cluster grows, each shard handles fewer operations and stores lesser data. As a result, a cluster can increase its capacity and input horizontally.
For example, to insert data into a particular record, the application needs to access only the shard that holds the record.
If a database has a 1 terabyte data set distributed amongst 4 shards, then each shard may hold only 256 Giga Byte of data.
If the database contains 40 shards, then each shard will hold only 25 Giga Byte of data.
When Can I Use Sharding in MongoDB?
consider deploying a MongoDB sharded cluster when your system shows the following characteristics:
The data set outgrows the storage capacity of a single MongoDB instance
The size of the active working set exceeds the capacity of the maximum available RAM
A single MongoDB instance is unable to manage write operations
What is a MongoDB Shard?
A shard is a replica set or a single mongod instance that holds the data subset used in a sharded cluster.
Shards hold the entire data set for a cluster.
Each shard is a replica set that provides redundancy and high availability for the data it holds.
MongoDB shards data on a per collection basis and lets you access the sharded data through mongos instances.
every database contains a “primary” shard that holds all the un-sharded collections in that database.
adding redundancy to a database through replication
sharding, a scalable partitioning strategy used to improve performance of a database that has to handle a large number of operations from different clients
REPLICATION
Replication refers to a database setup in which several copies of the same dataset are hosted on separate machines.
The main reason to have replication is redundancy.
If a single database host machine goes down, recovery is quick since one of the other machines hosting a replica of the same database can take over
A quick fail-over to a secondary machine minimizes downtime, and keeping an active copy of the database acts as a backup to minimize loss of data
a Replica Set: a group of MongoDB server instances that are all maintaining the same data set
One of those instances will be elected as the primary, and will receive all write operations from client applications
The primary records all changes in its operation log, and the secondaries asynchronously apply those changes to their own copies of the database.
If the machine hosting the primary goes down, a new primary is elected from the remaining instances
By default, client applications read only from the primary.
However, you can take advantage of replication to increase data availability by allowing clients to read data from secondaries.
Keep in mind that since the replication of data happens asynchronously, data read from a secondary may not reflect the current state of the data on the primary.
DATABASE SHARDING
Having a large number of clients performing high-throughput operations can really test the limits of a single database instance.
Sharding is a strategy that can mitigate this by distributing the database data across multiple machines.
It is essentially a way to perform load balancing by routing operations to different database servers.
Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
There are two methods for addressing system growth: vertical and horizontal scaling.
Vertical Scaling involves increasing the capacity of a single server, such as using a more powerful CPU, adding more RAM, or increasing the amount of storage space. Limitations in available technology may restrict a single machine from being sufficiently powerful for a given workload. Additionally, Cloud-based providers have hard ceilings based on available hardware configurations. As a result, there is a practical maximum for vertical scaling.
Horizontal Scaling involves dividing the system dataset and load over multiple servers, adding additional servers to increase capacity as required. While the overall speed or capacity of a single machine may not be high, each machine handles a subset of the overall workload, potentially providing better efficiency than a single high-speed high-capacity server. Expanding the capacity of the deployment only requires adding additional servers as needed, which can be a lower overall cost than high-end hardware for a single machine. The trade off is increased complexity in infrastructure and maintenance for the deployment. https://docs.mongodb.com/manual/sharding/
Divide a data store into a set of horizontal partitions or shards. This can improve scalability when storing and accessing large volumes of data.
For example, a customer might only have one billing address, yet I might choose to put the billing address information into a separate table with a CustomerId reference so that I have the flexibility to move that information into a separate database
For example, I might shard my customer database using CustomerId as a shard key - I'd store ranges 0-10000 in one shard and 10001-20000 in a different shard. When choosing a shard key, the DBA will typically look at data-access patterns and space issues to ensure that they are distributing load and space across shards evenly.
Big Data refers to technologies and initiatives that involve data that is too diverse, fast-changing or massive for conventional technologies, skills and infra- structure to address efficiently.
Said differently, the volume, velocity or variety of data is too great. "Big Data" describes data sets so large and complex they are impractical to manage with traditional software tools.
Big Data relates to data creation, storage, retrieval and analysis that is remarkable in terms of volume, velocity, and variety:
Volume: A typical PC might have had 10 gigabytes of storage in 2000. Today, Facebook ingests 500 terabytes of new data every day; a Boeing 737 will generate 240 terabytes of flight data during a single flight across the US
Velocity: Clickstreams and ad impressions capture user behavior at millions of events per second; high-frequency stock trading algorithms reflect market changes within microseconds;
Variety: Big Data data isn't just numbers, dates, and strings. Big Data is also geospatial data, 3D data, audio and video, and unstructured text, including log files and social media. Traditional database systems were designed to address smaller volumes of structured data, fewer updates or a predictable, consistent data structure. Traditional database systems are also designed to operate on a single server, making increased capacity expensive and finite. As applications have evolved to serve large volumes of users, and as application development practices have become agile, the traditional use of the relational database has become a liability for many companies rather than an enabling factor in their business
Selecting a Big Data Technology: Operational vs. Analytical The Big Data landscape is dominated by two classes of technology: systems that provide operational capabilities for real-time, interactive workloads where data is primarily captured and stored; and systems that provide analytical capabilities for retrospective, complex analysis that may touch most or all of the data. These classes of technology are complementary and frequently deployed together.
http://www.mongodb.com/big-data-explained
"Big Data" caught on quickly as a blanket term for any collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.
In a 2001 research reportand related lectures, META Group (now Gartner) analyst Doug Laney defined data growth challenges and opportunities as being three-dimensional,
i.e. increasing volume (amount of data), velocity (speed of data in and out), variety (range of data types and sources).
http://en.wikipedia.org/wiki/Big_data
Big data is a popular term used to describe the exponential growth and availability of data, both structured and unstructured.
three Vs of big data: volume, velocity and variety.
Volume. Many factors contribute to the increase in data volume. Transaction-based data stored through the years. Unstructured data streaming in from social media. Increasing amounts of sensor and machine-to-machine data being collected. In the past, excessive data volume was a storage issue. But with decreasing storage costs, other issues emerge, including how to determine relevance within large data volumes and how to use analytics to create value from relevant data.
Velocity. Data is streaming in at unprecedented speed and must be dealt with in a timely manner. RFID tags, sensors and smart metering are driving the need to deal with torrents of data in near-real time. Reacting quickly enough to deal with data velocity is a challenge for most organizations.
Variety. Data today comes in all types of formats. Structured, numeric data in traditional databases. Information created from line-of-business applications. Unstructured text documents, email, video, audio, stock ticker data and financial transactions. Managing, merging and governing different varieties of data is something many organizations still grapple with.
IBM is unique in having developed an enterprise class big data and analytics platform – Watson Foundations - that allows you to address the full spectrum of big data business challenges. Information management is key to that platform helping organizations discover fresh insights, operate in a timely fashion and establish trust to act with confidence.
http://www-01.ibm.com/software/data/bigdata/
Big Data
Real-time decision making is critical to business success. Yet data in your enterprise continues to grow exponentially year over year, making analysis more difficult. To turn structured and unstructured data into actionable intelligence, your business needs an effective, smart way to harness Big Data. http://www.pivotal.io/big-data
Low latency (capital markets)
Low latency is a topic within capital markets, where the proliferation of algorithmic trading requires firms to react to market events faster than the competition to increase profitability of trades. For example, when executing arbitrage strategies the opportunity to “arb” the market may only present itself for a few milliseconds before parity is achieved. To demonstrate the value that clients put on latency, a large global investment bank has stated that every millisecond lost results in $100m per annum in lost opportunity. http://en.wikipedia.org/wiki/Low_latency_%28capital_markets%29
Low latency allows human-unnoticeable delays between an input being processed and the corresponding output providing real time characteristics
http://en.wikipedia.org/wiki/Low_latency
Commodity hardware
"Commodity hardware" does not imply low quality, but rather, affordability. Most commodity servers used in production Hadoop clusters have an average (again, the definition of "average" may change over time) ratio of disk space to memory, as opposed to being specialized servers with massively high memory or CPU.
Examples of Commodity Hardware in Hadoop An example of suggested hardware specifications for a production Hadoop cluster is: four 1TB hard disks in a JBOD (Just a Bunch Of Disks) configuration two quad core CPUs, running at least 2-2.5GHz 16-24GBs of RAM (24-32GBs if you're considering HBase) 1 Gigabit Ethernet
Commodity hardware, in an IT context, is a device or device component that is relatively inexpensive, widely available and more or less interchangeable with other hardware of its type.
Other examples of commodity hardware in IT: RAID (redundant array of independent -- originally inexpensive -- disks) performance typically relies upon an array of commodity hard disks to enable improvements in mean time between failures (MTBF), fault tolerance and failover. A commodity server is a commodity computer that is dedicated to running server programs and carrying out associated tasks. In many environments, multiple low-end servers share the workload. Commodity servers are often considered disposable and, as such,are replaced rather than repaired. http://whatis.techtarget.com/definition/commodity-hardware
The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster
https://en.wikipedia.org/wiki/MapReduce
MapReduce is a programming model and an associated
implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key. https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
Map stage : The map or mapper’s job is to process the input data. Generally the input data is in the form of file or directory and is stored in the Hadoop file system (HDFS). The input file is passed to the mapper function line by line. The mapper processes the data and creates several small chunks of data.
Reduce stage : This stage is the combination of the Shuffle stage and the Reduce stage. The Reducer’s job is to process the data that comes from the mapper. After processing, it produces a new set of output, which will be stored in the HDFS. http://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
Yet Another Resource Negotiator (YARN)
Various applications can run on YARN MapReduce is just one choice (the main choice at this point) YARN was designed to address issues with MapReduce1 Scalability issues (max ~4,000 machines) Inflexible Resource Management MapReduce1 had slot based model
http://wiki.apache.org/hadoop/PoweredByYarn
CSA Releases the Expanded Top Ten Big Data Security & Privacy Challenges
Security and privacy issues are magnified by the three V’s of big data: Velocity, Volume, and Variety.
The CSA’s Big Data Working Group followed a three-step process to arrive at top security and privacy challenges presented by Big Data:
1. Interviewed CSA members and surveyed security-practitioner oriented trade journals to draft an initial list of high priority security and privacy problems
2. Studied published solutions.
3. Characterized a problem as a challenge if the proposed solution does not cover the problem scenarios.
Top 10 challenges
Secure computations in distributed programming frameworks
Security best practices for non-relational data stores
Secure data storage and transactions logs
End-point input validation/filtering
Real-Time Security Monitoring
Scalable and composable privacy-preserving data mining and analytics
Cryptographically enforced data centric security
Granular access control
Granular audits
Data Provenance The Expanded Top 10 Big Data challenges has evolved from the initial list of challenges presented at CSA Congress to an expanded version that addresses three new distinct issues:
Modeling: formalizing a threat model that covers most of the cyber-attack or data-leakage scenarios
Analysis: finding tractable solutions based on the threat model
Implementation: implanting the solution in existing infrastructures The full report explores each one of these challenges in depth, including an overview of the various use casesfor each challenge. The challenges themselves can be organized into four distinct aspects of the Big Data ecosystem as follows:
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers. Many projects at Google store data in Bigtable, including web indexing, Google Earth, and Google Finance. These applications place very different demands on Bigtable, both in terms of data size (from URLs to web pages to satellite imagery) and latency requirements (from backend bulk processing to real-time data serving). Despite these varied demands, Bigtable has successfully provided a flexible, high-performance solution for all of these Google products. In this paper we describe the simple data model provided by Bigtable, which gives clients dynamic control over data layout and format, and we describe the design and implementation of Bigtable. http://research.google.com/archive/bigtable.html
BigTable
BigTable is a compressed, high performance, and proprietary data storage system built on Google File System, Chubby Lock Service, SSTable (log-structured storage like LevelDB) and a few other Google technologies. It is not distributed outside Google, although Google offers access to it as part of its Google App Engine. http://en.wikipedia.org/wiki/BigTable
Google File System
Google File System (GFS or GoogleFS) is a proprietary distributed file system developed by Google for its own use.[1] It is designed to provide efficient, reliable access to data using large clusters of commodity hardware. A new version of the Google File System is codenamed Colossus http://en.wikipedia.org/wiki/Google_File_System
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
The project includes these modules:
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Other Hadoop-related projects at Apache:
Cassandra: A scalable multi-master database with no single points of failure. HBase: A scalable, distributed database that supports structured data storage for large tables.
Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying.
ZooKeeper: A high-performance coordination service for distributed applications.
http://hadoop.apache.org/
Hue is a Web interface for analyzing data with Apache Hadoop
Apache HBase is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the
Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
http://hbase.apache.org/
what is HBase?
Column-Oriented data store, known as “Hadoop Database”
Type of “NoSQL” DB
– Does not provide a SQL based access
5 – Does not adhere to Relational Model for storage
HDFS won't do well on anything under 5 nodes anyway;
particularly with a block replication of 3
• HBase is memory and CPU intensive
When to Use HBase
Two well-known use cases
– Lots and lots of data (already mentioned)
– Large amount of clients/requests (usually cause a lot of
data)
Great for single random selects and range scans by key
Great for variable schema
– Rows may drastically differ
– If your schema has many columns and most of them are null
When NOT to Use HBase
Bad for traditional RDBMs retrieval
– Transactional applications
– Relational Analytics
• 'group by', 'join', and 'where column like', etc....
Currently bad for text-based search access
– There is work being done in this arena
• HBasene: https://github.com/akkumar/hbasene/wiki
• HBASE-3529: 100% integration of HBase and Lucene
based on HBase' coprocessors
– Some projects provide solution that use HBase
• Lily=HBase+Solr http://www.lilyproject.org
HBase Access HBase Shell
Native Java API
Avro Server
http://avro.apache.org HBql
http://www.hbql.com PyHBase
https://github.com/hammer/pyhbase AsyncHBase
https://github.com/stumbleupon/asynchbase
JPA/JPO access to HBase via DataNucleous
http://www.datanucleus.org HBase-DSL
https://github.com/nearinfinity/hbase-dsl
Native API is not the only option
REST Server
Complete client and admin APIs
Requires a REST gateway server
Supports many formats: text, xml, json, protocol buffers,raw binary
Thrift
Apache Thrift is a cross-language schema compiler
http://thrift.apache.org
Requires running Thrift Server
Local (Standalone) Mode
Comes Out-of-the-Box, easy to get started
Uses local filesystem (not HDFS), NOT for production
Runs HBase & Zookeeper in the same JVM
Pseudo-Distributed Mode
Requires HDFS
Mimics Fully-Distributed but runs on just one host
Good for testing, debugging and prototyping
Not for production use or performance benchmarking!
Development mode used in class Fully-Distributed Mode
Run HBase on many machines
Great for production and development clusters
Two options: Tall-Narrow OR Flat-Wide Tall Narrow is generally recommended
Store parts of cell data in the row id
Faster data retrieval HBase splits on row boundaries
Flat-Wide vs. Tall-Narrow
Tall Narrow has superior query granularity
query by rowid will skip rows, store files!
Flat-Wide has to query by column name which won’t skip rows or storefiles
Tall Narrow scales better HBase splits at row boundaries meaning it will shard at blog boundary
Flat-Wide solution only works if all the blogs for a single user can fit into a single row
Flat-Wide provides atomic operations
atomic on per-row-basis
There is no built in concept of a transaction for multiple rows or tables
http://courses.coreservlets.com/Course-Materials/pdf/hadoop/03-HBase_6-KeyDesign.pdf
Hadoop vs MPP
The Hadoop Distributed File System (HDFS)
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject.
http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
Thrift Framework
Thrift is a software framework for scalable cross-language services development. It combines a software stack with a code generation engine to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml.
Originally developed at Facebook, Thrift was open sourced in April 2007 and entered the Apache Incubator in May, 2008.
The Apache Thrift software framework, for scalable cross-language services development, combines a software stack with a code generation engine to build services that work efficiently and seamlessly between C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml and Delphi and other languages
http://thrift.apache.org/
Apache Ambari
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
http://ambari.apache.org/
Apache Ambari A completely open source management platform for provisioning, managing, monitoring and securing Apache Hadoop clusters
http://hortonworks.com/apache/ambari/
Apache Avro
Apache Avro™ is a data serialization system.
Avro provides:
Rich data structures.
A compact, fast, binary data format.
A container file, to store persistent data.
Remote procedure call (RPC).
Simple integration with dynamic languages
http://avro.apache.org/
Cascading
Cascading is the proven application development platform for building data applications on Hadoop.
http://www.cascading.org/
Fully-featured data processing and querying library for Clojure or Java.
http://cascalog.org/
Cloudera Impala
Open Source, Interactive SQL for Hadoop
Cloudera Impala is massively parallel processing (MPP) SQL query engine that runs natively in Apache Hadoop
http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/impala.html
PigPen
PigPen is an eclipse plugin that helps users create pig-scripts, test them using the example generator and then submit them to a hadoop cluster as well.
https://wiki.apache.org/pig/PigPen
Apache Crunch
The Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines.
Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run.
https://crunch.apache.org
Apache Giraph
Apache Giraph is an iterative graph processing system built for high scalability. For example, it is currently used at Facebook to analyze the social graph formed by users and their connections. Giraph originated as the open-source counterpart to Pregel, the graph processing architecture developed at Google and described in a 2010
http://giraph.apache.org/
Apache Accumulo
The Apache Accumulo™ sorted, distributed key/value store is a robust, scalable, high-performance data storage and retrieval system. Apache Accumulo is based on Google's BigTable design and is built on top of Apache Hadoop, Zookeeper, and Thrift.
https://accumulo.apache.org/
Apache Chukwa is an open source data collection system for monitoring large distributed systems. Apache Chukwa is built on top of the Hadoop Distributed File System (HDFS) and Map/Reduce framework and inherits Hadoop’s scalability and robustness. Apache Chukwa also includes a flexible and powerful toolkit for displaying, monitoring and analyzing results to make the best use of the collected data
http://chukwa.apache.org/
Apache Bigtop
Bigtop is a project for the development of packaging and tests of the Apache Hadoop ecosystem.
http://bigtop.apache.org/
Hortonworks Data Platform 2.1
100% Open Source Enterprise Apache Hadoop
http://hortonworks.com/
Why use Storm?
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!
http://storm.apache.org
Apache Kafka is publish-subscribe messaging rethought as a distributed commit log.
http://kafka.apache.org
Apache Spark Components – Spark Streaming
Spark Streaming: What Is It and Who’s Using It?
Performance Tuning of an Apache Kafka/Spark Streaming System - Telecom Case Study
The Tools of API Management — The Full Stack
The Latest in API Orchestration, Mediation, and Integration
OpenLogic stacks | Rogue Wave
What is Couchbase Server? The Scalability of NoSQL + The Flexibility of JSON + The Power of SQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
https://graphql.org/
COUCHBASE IS THE NOSQL DATABASE FOR BUSINESS-CRITICAL APPLICATIONS
https://www.couchbase.com/
Apache Kafka GraphQL Couchbase PostgreSQL
Hadoop Distributions
Cloudera
Cloudera offers CDH, which is 100% open source, as a free download as well as a free edition of their Cloudera Manager console for administering and managing Hadoop clusters of up to 50 nodes.
The enterprise version on the other hand combines CDH and a more sophisticated Manager plus an enterprise support package
Hortonworks
The major difference from Cloudera and MapR is that HDP uses Apache Ambari for cluster management and monitoring.
MapR
The major differences to CDH and HDP is that MapR uses their proprietary file system MapR-FS instead of HDFS.
The reason for their Unix-based file system is that MapR considers HDFS as a single point of failure.
Neo4j Community Edition is an open source product licensed under GPLv3.Neo4j is the world’s leading Graph Database. It is a high performance graph store with all the features expected of a mature and robust database, like a friendly query language and ACID transactions.
https://github.com/neo4j/neo4j
Apache Cassandra
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
http://cassandra.apache.org/
Redis
Redis is an open source, BSD licensed, advanced key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
http://redis.io/
RocksDB is an embeddable persistent key-value store for fast storage.
https://rocksdb.org/
mongoDB
MongoDB (from "humongous") is a scalable, high-performance, open source, document-oriented database.
http://www.mongodb.org/
GridFS is a specification for storing and retrieving files that exceed the BSON-document size limit of 16 MB.
When to Use GridFS
In MongoDB, use GridFS for storing files larger than 16 MB.
In some situations, storing large files may be more efficient in a MongoDB database than on a system-level filesystem.
If your filesystem limits the number of files in a directory, you can use GridFS to store as many files as needed.
When you want to access information from portions of large files without having to load whole files into memory, you can use GridFS to recall sections of files without reading the entire file into memory.
When you want to keep your files and metadata automatically synced and deployed across a number of systems and facilities, you can use GridFS. When using geographically distributed replica sets, MongoDB can distribute files and their metadata automatically to a number ofmongod instances and facilities.
https://docs.mongodb.com/manual/core/gridfs/
Riak
Riak is an open source, distributed database
http://basho.com/riak/
CouchDB
Apache CouchDB is a database that uses JSON for documents, JavaScript for MapReduce queries, and regular HTTP for an API
https://couchdb.apache.org/
Pivotal Greenplum Database (Pivotal GPDB) manages, stores and analyzes terabytes to petabytes of data in large-scale analytic data warehouses
Pivotal GPDB extracts the data you need to determine which modern applications will best serve customers in context, at the right location, and during the right activities using a shared-nothing, massively parallel processing (MPP) architecture and flexible column- and row-oriented storage
http://www.pivotal.io/big-data/pivotal-greenplum-database
Commercial Hadoop Distributions
Amazon Web Services Elastic MapReduce
EMR is Hadoop in the cloud leveraging Amazon EC2 for compute, Amazon S3 for storage and other services.
Cloudera
Enterprise customers wanted a management and monitoring tool for Hadoop, so Cloudera built Cloudera Manager,
Enterprise customers wanted a faster SQL engine for Hadoop, so Cloudera built Impala using a massively parallel processing (MPP) architecture
IBM InfoSphereBigInsights
IBM has advanced analytics tools, a global presence and implementation services, so it can offer a complete big data solution that will be attractive to many customers
MapR
MapR Technologies has added some unique innovations to its Hadoop distribution, including support for Network File System (NFS), running arbitrary code in the cluster, performance enhancements for HBase, as well as high-availability and disaster recovery features
Pivotal Greenplum Database In addition to the columnar Greenplum Database technology it brought from EMC, Pivotal's Hadoop distribution has an MPP Hadoop SQL engine called HAWQ that provides MPP-like SQL performance on Hado
Teradata
The Teradata distribution for Hadoop includes integration with Teradata's management tool and SQL-H, a federated SQL engine that lets customers query data from its data warehouse and Hadoop
Intel Delivers Hardware-Enhanced Performance, Security for Hadoop
Microsoft Windows Azure HDInsight
Microsoft Windows Azure HDInsight Service is designed specifically for the Windows Azure cloud. HDInsight and Hadoop for Windows (a version of Hortonworks Data Platform) comprise the only Hadoop distributions that run in a Windows environment.
MapR is a complete distribution for Apache Hadoop that packages more than a dozen projects from the Hadoop ecosystem to provide a broad set of Big Data capabilities for the user. Projects such as Apache HBase, Hive, Pig, Mahout, Flume, Avro, Sqoop, Oozie and Whirr are included along with non-Apache projects such as Cascading and Impala.
https://www.mapr.com/why-hadoop/why-mapr
Amazon EMR
Amazon Elastic MapReduce (Amazon EMR) is a web service that makes it easy to quickly and cost-effectively process vast amounts of data.
Amazon EMR uses Hadoop, an open source framework, to distribute your data and processing across a resizable cluster of Amazon EC2 instances. Amazon EMR is used in a variety of applications, including log analysis, web indexing, data warehousing, machine learning, financial analysis, scientific simulation, and bioinformatics
http://aws.amazon.com/elasticmapreduce/
InfoSphereBigInsights
IBM makes it simpler to use Hadoop to get value out of big data and build big data applications. It enhances open source technology to withstand the demands of your enterprise, adding administrative, discovery, development, provisioning, security, and support, along with best-in-class analytical capabilities
http://www-01.ibm.com/software/data/infosphere/biginsights/
oracle golden gate
Oracle GoldenGate is a comprehensive software package for real-time data integration and replication in heterogeneous IT environments.
http://www.oracle.com/technetwork/middleware/goldengate/overview/index.html
The GridGain® in-memory computing platform includes an In-Memory Compute Grid which enables parallel processing of CPU or otherwise resource intensive tasks including traditional High Performance Computing (HPC) and Massively Parallel Processing (MPP). Queries are broken down into sub-queries which are sent to the relevant nodes in the compute grid of the GridGain cluster and processed on the local CPUs where the data resides.
In-memory computing solutions deliver real-time application performance and massive scalability by creating a copy of your data stored in disk-based databases in RAM. When data is stored in RAM, applications run 1,000x faster because data does not need tobe retrieved from disk and moved into RAM prior to processing. Performance is further increased across the distributed in-memory computing cluster by using massive parallel processing to distribute processing across the cluster nodes, leveraging the computing power of all of the nodes in the cluster. In-memory computing platforms provide massive application scalability by allowing users to expand the size of their in-memory CPU pool by adding more nodes to the cluster. In-memory computing platforms can scale up by upgrading existing nodes with more powerful servers which have more cores, RAM and/or computing power.
In in-memory computation, the data is kept in random access memory(RAM) instead of some slow disk drives and is processed in parallel. Using this we can detect a pattern, analyze large data. This has become popular because it reduces the cost of memory. So, in-memory processing is economic for applications. The two main columns of in-memory computation are-
RAM storage
Parallel distributed processing.
https://data-flair.training/blogs/spark-in-memory-computing/
Why In-Memory Computing Is Cheaper And Changes Everything
What is in-memory computing?
All forms of flash today are used like disk drives. Even though we may remove the controller as a bottleneck, the applications are still doing I/O to a flash drive or a flash board. It is getting much more reliable and cheaper, so it is going to become a persistence mechanism replacing disk
Today, the reliability of flash is longer than that of disk drives. If you replace your hardware every three to four years, and you have flash SSD and disk, you will probably not see a failure on the flash at all in that period of time, but I guarantee you that you will change disk drives.
When we talk about in-memory, we are talking about the physical database being in-memory rather than as it is “traditionally” done: on disk.
In-Memory Database Computing – A Smarter Way of Analyzing Data
Querying data from physical disks was traditional approach, In-memory database computing (IMDBC) replaced this approach, as in IMDBC data is queried through the computer’s random access memory i.e. RAM. Upon querying data from RAM results in shorter query response time and allows analytics applications to support faster business decisions
In-Data Computing vs In-Memory Computing vs Traditional Model(Storage based)
In-Data Computing (also known as In-Place Computing) is an abstract model in which all data is kept in an infinite and persistent memory space for both storage and computing. In-data computing is a data-centric approach, where data is computed in the same space it is stored. Instead of moving data to the code, code is moved to the data space for processing. With today’s 64-bit architecture and virtualization technology, BigObject® depicts a persistent and nearly infinite memory space for data
http://www.bigobject.io/technology.html
SAP HANA is an in-memory database: • - It is a combination of hardware and software made to process massive real time data using In-Memory computing.
• - It combines row-based, column-based database technology.
• - Data now resides in main-memory (RAM) and no longer on a hard disk.
• - It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
An in-memory database (IMDB); also main memory database system or MMDB or memory resident database) is a database management system that primarily relies on main memory for computer data storage.
It is contrasted with database management systems that employ a disk storage mechanism. Main memory databases are faster than disk-optimized databases since the internal optimization algorithms are simpler and execute fewer CPU instructions. Accessing data in memory eliminates seek time when querying the data, which provides faster and more predictable performance than disk.
http://en.wikipedia.org/wiki/In-memory_database
The in-memory database defined
An in-memory database is a type of nonrelational database that relies primarily on memory for data storage, in contrast to databases that store data on disk or SSDs. In-memory databases are designed to attain minimal response time by eliminating the need to access disks.
Because all data is stored and managed exclusively in main memory, it is at risk of being lost upon a process or server failure.
In-memory databases can persist data on disks by storing each operation in a log or by taking snapshots.
In-memory databases are ideal for applications that require microsecond response times and can have large spikes in traffic coming at any time such as gaming leaderboards, session stores, and real-time analytics.
Use cases
Real-time bidding
In-memory databases are ideal choices for ingesting, processing, and analyzing real-time data with submillisecond latency.
Caching
A cache is a high-speed data storage layer which stores a subset of data, typically transient in nature, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to efficiently reuse previously retrieved or computed data. The data in a cache is generally stored in fast access hardware such as RAM (Random-access memory) and may also be used in correlation with a software component. A cache's primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer.
Popular in-memory databases
Amazon Elasticache for Redis
in-memory data store that provides submillisecond latency to power internet-scale, real-time applications.
Developers can use ElastiCache for Redis as an in-memory nonrelational database. ElastiCache for Redis also provides the ability to add and remove shards from a running cluster.
The ElastiCache for Redis cluster configuration supports up to 15 shards and enables customers to run Redis workloads with up to 6.1 TB of in-memory capacity in a single cluster. ElastiCache for Redis also provides the ability to add and remove shards from a running cluster.
Amazon ElastiCache for Memcached
Memcached-compatible in-memory key-value store service
can be used as a cache or a data store
for use cases where frequently accessed data must be in-memory.
Aerospike
in-memory database solution for real-time operational applications
This high-performance nonrelational database can be installed as a persistent in-memory service with a RAM cluster
or greater data sizes using local SSD instances
https://aws.amazon.com/nosql/in-memory/
Difference between In-Memory cache and In-Memory Database
the differences between In-Memory cache(redis, memcached), In-Memory data grids (gemfire) and In-Memory database (VoltDB)
Cache - By definition means it is stored in memory. Any data stored in memory (RAM) for faster access is calledcache. Examples: Ehcache, Memcache Typically you put an object in cache with String as Key and access the cache using the Key. It is very straight forward. It depends on the application when to access the cahce vs database and no complex processing happens in the Cache. If the cache spans multiple machines, then it is called distributed cache. For example, Netflix uses EVCAche which is built on top of Memcache to store the users movie recommendations that you see on the home screen.
In Memory Database - It has all the features of a Cache plus come processing/querying capabilities. Redis falls under this category. Redis supports multiple data structures and you can query the data in the Redis ( examples like get last 10 accessed items, get the most used item etc). It can span multiple machine and is usually very high performant and also support persistence to disk if needed. For example, Twitter uses Redis database to store the timeline information.
https://stackoverflow.com/questions/37015827/difference-between-in-memory-cache-and-in-memory-database
Redis vs. Memcached: In-Memory Data Storage Systems
Redis and Memcached are both in-memory data storage systems
Memcached is a high-performance distributed memory cache service
Redis is an open-source key-value store
Similar to Memcached, Redis stores most of the data in the memory
In Memcached, you usually need to copy the data to the client end for similar changes and then set the data back.
The result is that this greatly increases network IO counts and data sizes.
In Redis, these complicated operations are as efficient as the general GET/SET operations.Therefore, if you need the cache to support more complicated structures and operations, Redis is a good choice.
Different memory management scheme
In Redis, not all data storage occurs in memory. This is a major difference between Redis and Memcached. When the physical memory is full, Redis may swap values not used for a long time to the disks
Difference in Cluster Management
Memcached is a full-memory data buffering system. Although Redis supports data persistence, the full-memory is the essence of its high performance. For a memory-based store, the size of the memory of the physical machine is the maximum data storing capacity of the system. If the data size you want to handle surpasses the physical memory size of a single machine, you need to build distributed clusters to expand the storage capacity.
Compared with Memcached which can only achieve distributed storage on the client side, Redis prefers to build distributed storage on the server side.
Amazon ElastiCache offers fully managed Redis and Memcached. Seamlessly deploy, run, and scale popular open source compatible in-memory data stores.
Build data-intensive apps or improve the performance of your existing apps by retrieving data from high throughput and low latency in-memory data stores
https://aws.amazon.com/elasticache/
Distributed cache
In computing, a distributed cache is an extension of the traditional concept of cache used in a single locale.
A distributed cache may span multiple servers so that it can grow in size and in transactional capacity It is mainly used to store application data residing in database and web session data The idea of distributed caching has become feasible now because main memory has become very cheap and network cards have become very fast, with 1Gbit now standard everywhere and 10Gbit gaining traction.
Also, a distributed cache works well on lower cost machines usually employed for web servers as opposed to database servers which require expensive hardware.
https://en.wikipedia.org/wiki/Distributed_cache
Infinispan
Infinispan is a distributed in-memory key/value data store with optional schema Available as an embedded Java library or as a language-independent service accessed remotely over a variety of protocols (Hot Rod, REST, Memcached and WebSockets) Use it as a cache or a data grid. Advanced functionality such as transactions, events, querying, distributed processing, off-heap and geographical failover http://infinispan.org/
In-Memory Distributed Caching
The primary use case for caching is to keep frequently accessed data in process memory to avoid constantly fetching this data from disk, which leads to the High Availability (HA) of that data to the application running in that process space (hence, “in-memory” caching) Most of the caches were built as distributed in-memory key/value stores that supported a simple set of ‘put’ and ‘get’ operations and optionally some sort of read-through and write-through behavior for writing and reading values to and from underlying disk-based storage such as an RDBMS. Depending on the product, additional features like ACID transactions, eviction policies, replication vs. partitioning, active backups, etc. also became available as the products matured. In-Memory Data Grid The feature of data grids that distinguishes them from distributed caches the most was their ability to support co-location of computations with data in a distributed context and consequently provided the ability to move computation to data.This capability was the key innovation that addressed the demands of rapidly growing data sets that made moving data to the application layer increasing impractical. Most of the data grids provide some basic capabilities to move the computations to the data.Another uniquely new characteristic of in-memory data grids is the addition of distributed MPP processing based on standard SQL and/or MapReduce, that allows to effectively compute over data stored in-memory across the cluster.Just as distributed caches were developed in response to a growing need for data HA, in-memory data grids were developed to respond to the growing complexities of data processing.Adding distributed SQL and/or MapReduce type processing required a complete re-thinking of distributed caches, as focus has shifted from pure data management to hybrid data and compute management.This new and very disruptive capability of in-memory data grids also marked the start of the in-memory computing revolution. https://www.gridgain.com/resources/blog/cache-data-grid-database
From distributed caches to in-memory data grids
What do high-load applications need from cache?
Low latency
Linear horizontal scalability
Distributed cache
Cache access patterns: Client Cache Aside For reading data:
Cache access patterns: Client Read Through For reading data
Cache access patterns: Client Write Through For writing data
Cache access patterns: Client Write Behind For writing data
https://www.slideshare.net/MaxAlexejev/from-distributed-caches-to-inmemory-data-grids
the difference between two major categories in in-memory computing: In-Memory Database and In-Memory Data Grid
In-Memory Data Grids (IMDGs) are sometimes (but not very frequently) called In-Memory NoSQL/NewSQL Databases there are also In-Memory Compute Grids and In-Memory Computing Platforms that include or augment many of the features of In-Memory Data Grids and In-Memory Databases. Tiered Storage what we mean by “In-Memory”. Surprisingly - there’s a lot of confusion here as well as some vendors refer to SSDs, Flash-on-PCI, Memory Channel Storage, and, of course, DRAM as “In-Memory” https://www.gridgain.com/resources/blog/in-memory-database-vs-in-memory-data-grid-revisited
Cache < Data Grid < Database
In-Memory Distributed Cache
In-Memory Data Grid
In-Memory Database
In-Memory Distributed Caching
The primary use case for caching is to keep frequently accessed data in process memory to avoid constantly fetching this data from disk, which leads to the High Availability (HA) of that data to the application running in that process space (hence, “in-memory” caching).
In-Memory Data Grid
The feature of data grids that distinguishes them from distributed caches was their ability to support co-location of computations with data in a distributed context and consequently provided the ability to move computation to data.
In-Memory Database
The feature that distinguishes in-memory databases over data grids is the addition of distributed MPP processing based on standard SQL and/or MapReduce, that allows to compute over data stored in-memory across the cluster.
What’s the Difference Between an In-Memory Data Grid and In-Memory Database?
The differences between IMDGs and IMDBs are more technical in nature, but both offer ways to accelerate development and deployment of data-driven applications.
What’s an In-Memory Data Grid (IMDG)? IMDGs are designed to provide high availability and scalability by distributing data across multiple machines. The rise of cloud, social media, and the Internet of Things (IoT) has created demand for applications that need to be extremely fast and capable of processing millions of transactions per second.
So, What’s an In-Memory Database (IMDB)?
An IMDB is a database management system that primarily relies on main memory for computer data storage. It contrasts with database management systems that employ a disk-storage mechanism. An IMDB eliminates the latency and overhead of hard-disk storage and reduces the instruction set that’s required to access data.
How To Choose An In-Memory NoSQL Solution: Performance Measuring
The main purpose of this work is to show results of benchmarking some of the leading in-memory NoSQL databases with a tool named YCSB
We selected three popular in-memory database management systems:
Redis (standalone and in-cloud named Azure Redis Cache), Tarantool and CouchBase and one cache system Memcached.
Memcached is not a database management system and does not have persistence. But we decided to take it, because it is also widely used as a fast storage system
In-memory NoSQL database management system is a database management system that stores all the data in the main memory and persists each update on disk. Persistency is provided by saving each data modification request in a binary log. Since the log is written in append-only mode, it is rarely a bottleneck. Both read and write workloads are processed without significant disk head movement
Memcached is a general-purpose distributed memory caching system Tarantool is an open-source NoSQL database management system and Lua application server developed in my.com.
Couchbase Server, originally known as Membase, is an open-source, distributed NoSQL document-oriented database.
Yahoo! Cloud Serving Benchmark
Yahoo! Cloud Serving Benchmark, or YCSB is a powerful utility for performance measuring of a wide range of NoSQL databases including in-memory and on-disk solutions
What is No SQL?
A No-SQL (often interpreted as Not Only SQL) database provides a mechanism for storage and retrieval of data that is modelled in means other than the tabular relations used in relational databases. Motivations for this approach include simplicity of design, horizontal scaling and finer control over availability.
What is In Memory Database?
An in-memory database (IMDB; also main memory database system or MMDB or memory resident database) is a database management system that primarily relies on main memory for computer data storage. It is contrasted with database management systems that employ a disk storage mechanism. Main memory databases are faster than disk-optimized databases since the internal optimization algorithms are simpler and execute fewer CPU instructions. Accessing data in memory eliminates seek time when querying the data, which provides faster and more predictable performance than disk.
Why In Memory NoSQL ? Application developers have been frustrated with the impedance mismatch between the relational data structures and the in-memory data structures of the application. Using NoSQL databases allows developers to develop without having to convert in-memory structures to relational structures.
The NoSQL realm already has in-memory DBMS options such as Aerospike
In-memory DBMS vendors MemSQL and VoltDB are taking the trend in the other direction, recently adding flash- and disk-based storage options to products that previously did all their processing entirely in memory. The goal here is to add capacity for historical data for long-term analysis.
Ehcache is an open source, standards-based cache for boosting performance, offloading your database, and simplifying scalability. It's the most widely-used Java-based cache because it's robust, proven, and full-featured
http://ehcache.org/
Memcached
Free & open source, high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load.
http://memcached.org/
OSCache
OSCache is a widely used, high performance J2EE caching framework. In addition toit'sservlet-specific features, OSCache can be used as a generic caching solution for any Java application. A few of its generic features include:
* Caching of Arbitrary Objects - You are not restricted to caching portions of JSP pages or HTTP requests. Any Java object can be cached.
* Comprehensive API - The OSCache API gives you full programmatic control over all of OSCache's features.
* Persistent Caching - The cache can optionally be disk-based, thereby allowing expensive-to-create data to remain cached even across application restarts.
* Clustering - Support for clustering of cached data can be enabled with a single configuration parameter. No code changes required.
* Expiry of Cache Entries - You have a huge amount of control over how cached objects expire, including pluggable RefreshPolicies if the default functionality does not meet your requirements.
http://www.opensymphony.com/oscache/
ShiftOne
ShiftOne Java Object Cache is a Java library that implements several strict object caching policies, decorators that add behavior, and a light framework for configuring them for an application.
http://jocache.sourceforge.net/
SwarmCache
SwarmCache is a simple but effective distributed cache. It uses IP multicastto efficiently communicate with any number of hosts on a LAN. It is specifically designed for use by clustered, database-driven web applications
http://swarmcache.sourceforge.net/
Whirlycache
Whirlycache is a fast, configurable in-memory object cache for Java. It can be used, for example, to speed up a website or an application by caching objects that would otherwise have to be created by querying a database or by another expensive procedure
http://java.net/projects/whirlycache
cache4j
cache4j is a cache for Java objects with a simple API and fast implementation.
It features in-memory caching, a design for a multi-threaded environment, both synchronized and blocking implementations, a choice of eviction algorithms (LFU, LRU, FIFO), and the choice of either hard or soft references for object storage.
http://cache4j.sourceforge.net/
JCS
JCS is a distributed caching system written in java. It is intended to speed up applications by providing a means to manage cached data of various dynamic natures. Like any caching system, JCS is most useful for high read, low put applications. Latency times drop sharply and bottlenecks move away from the database in an effectively cached system.
https://commons.apache.org/proper/commons-jcs//
Solr
Solr is the popular, blazing fast open source enterprise search platform from the Apache Lucene project. Its major features include powerful full-text search, hit highlighting, faceted search, dynamic clustering, database integration, rich document (e.g., Word, PDF) handling, and geospatial search.
http://lucene.apache.org/solr/
Tapestry
Component oriented framework for creating dynamic, robust, highly scalable web applications in Java.
http://tapestry.apache.org/
Apache Lucene
Apache Lucene(TM) is a high-performance, full-featured text search engine library written entirely in Java
http://lucene.apache.org/java/docs/index.html
JiBX
JiBX is a tool for binding XML data to Java objects. It's extremely flexible, allowing you to start from existing Java code and generate an XML schema, start from an XML schema and generate Java code, or bridge your existing code to a schema that represents the same data. It also provides very high performance, outperforming all other Java data binding tools across a wide variety of tests.
http://jibx.sourceforge.net/
Hazelcast
Open source clustering and highly scalable data distribution platform for Java
http://www.hazelcast.com