- Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale
Apache Flink is a distributed system and requires
Bounded streams have a defined start and end. Bounded streams can
Run Applications at any Scale
Therefore, an application can leverage virtually unlimited amounts of
A modern container is more than just an isolation mechanism: it also includes an
image—the files that make up the application that runs inside the container.
Within Google,
Containerization transforms the data center from being machine-oriented to being application-oriented.
Containers encapsulate the application environment, abstracting away many details of machines and operating
systems from the application developer and the deployment infrastructure.
Because well-designed containers and container images
means managing applications rather than machines. This shift of management APIs from machine-oriented to
application oriented dramatically improves application deployment and introspection.
The original purpose of the
noisy, nosey, and messy neighbors. Combining these with container images created an abstraction that also isolates
applications from the (heterogeneous) operating systems on which they run.
This decoupling of image and OS makes it possible to provide the same deployment environment in
both development and production, which
reducing inconsistencies and friction.
https://flink.apache.org/flink-architecture.html

Hadoop vs Spark vs Flink – Big Data Frameworks Comparison
- Apache Flink on DC/OS (and Apache
Mesos )
For the uninitiated: Flink is a stateful stream processing framework that supports high-throughput, low-latency applications. Flink is a lightweight and fault tolerant, providing strict accuracy guarantees in case of failures, with minimal impact on performance. Flink deployments cover a range of use cases; Alibaba, for example, uses Flink to optimize search results in real-time.
Flink on DC/OS
In its Mesos user survey, Mesosphere found that 87% of new Mesos users are running DC/OS, and so Flink’s Mesos support wouldn’t be complete without DC/OS support, too. To run Flink on DC/OS, first install DC/OS from the official site.
Note that DC/OS includes
Flink on
First things first: the Mesos documentation will walk you through initial Mesos setup. Next you should also install Marathon, since you usually want your cluster to be highly available (HA).
https://mesosphere.com/blog/apache-flink-on-dcos-and-apache-mesos/
This repository is a sample setup to run an Apache Flink job in
https://github.com/sanderploegsma/flink-k8s
Flink session cluster on
https://ci.apache.org/projects/flink/flink-docs-stable/ops/deployment/kubernetes.html
Flink Helm Chart
https://github.com/docker-flink/examples
- Apache Samza is a distributed stream processing framework. It uses Apache Kafka for messaging, and Apache Hadoop YARN to provide fault tolerance, processor isolation, security, and resource management.
http://samza.apache.org/
- Choose between Confluent Open Source or Confluent Enterprise edition.
Both are built on the world’s most popular streaming platform, Apache Kafka
Know and respond to every single event in your organization in real time.
Like a central nervous system, Confluent creates an Apache Kafka-based streaming platform to unite your organization around a single source of truth.
Confluent Platform adds administration, data management, operations tools and robust testing to your Kafka environment.
an architecture based on a highly scalable, distributed streaming platform like Confluent will grow quickly with your business and the expanding data pipelines that come with it,
https://www.confluent.io/
- Apache Spark
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk
https://spark.apache.org
- Spark runs on Hadoop, Apache
Mesos ,Kubernetes , standalone, or in the cloud. It can access diverse data sources
https://spark.apache.org/
Apache Spark is an open-source cluster-computing framework.
Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
https://en.wikipedia.org/wiki/Apache_Spark
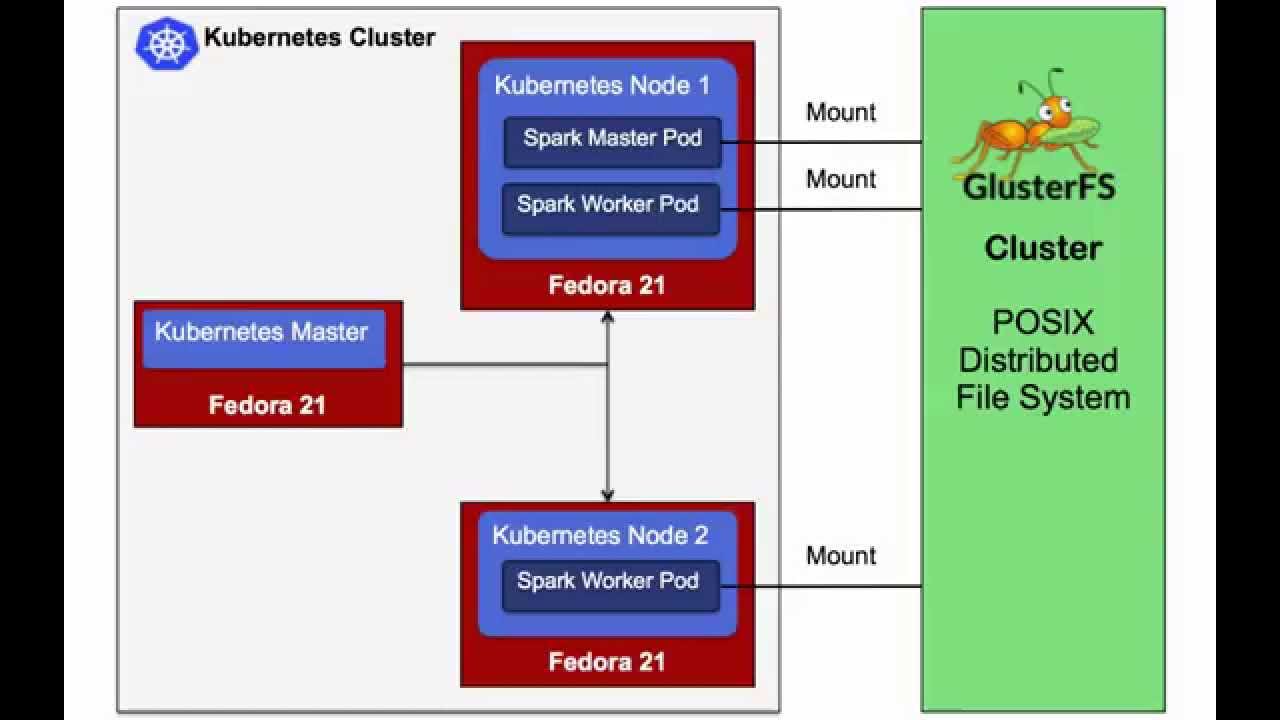
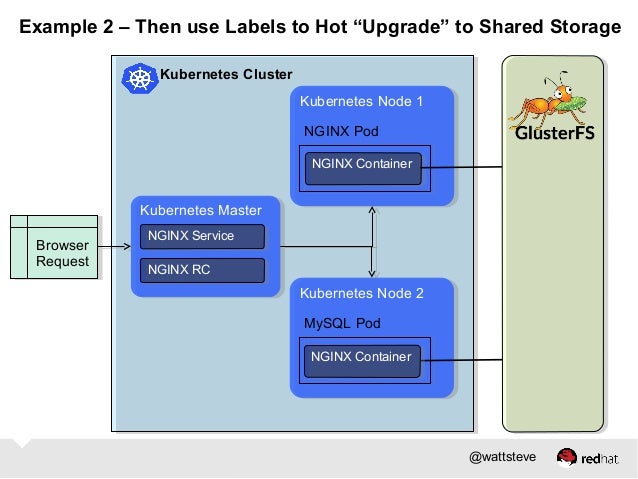
Building Clustered Applications with
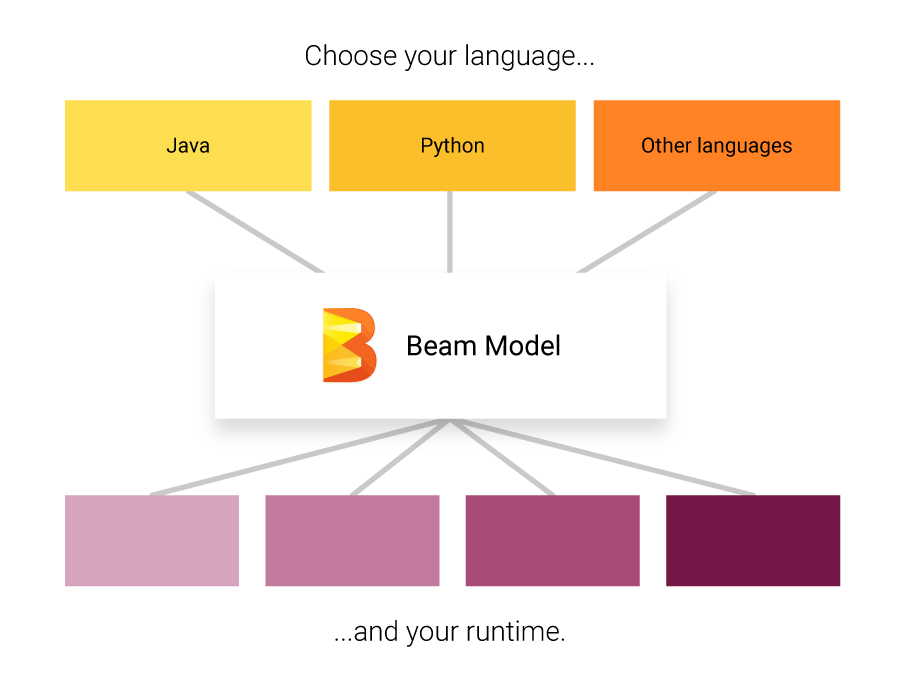
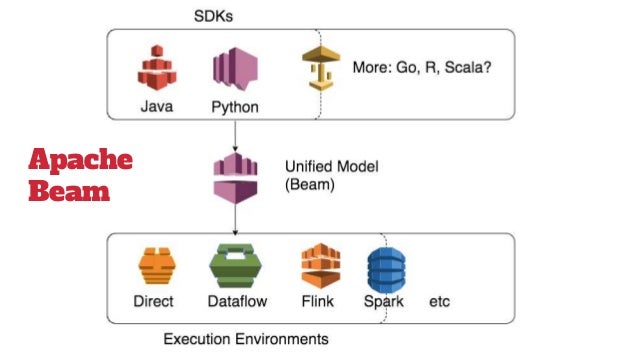
- Implement batch and streaming data processing jobs that run on any execution engine.
https://beam.apache.org/


- The Grizzly NIO framework
Writing scalable server applications in the Java™ programming language has always been difficult. Before
https://javaee.github.io/grizzly/
- Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients
. Netty isa NIO client server framework which enablesquick and easy development of network applications such as protocol servers and clients. Itgreatly simplifies and streamlines network programming such as TCP and UDP socket server.
https://netty.io/
- How
WebSockets Work
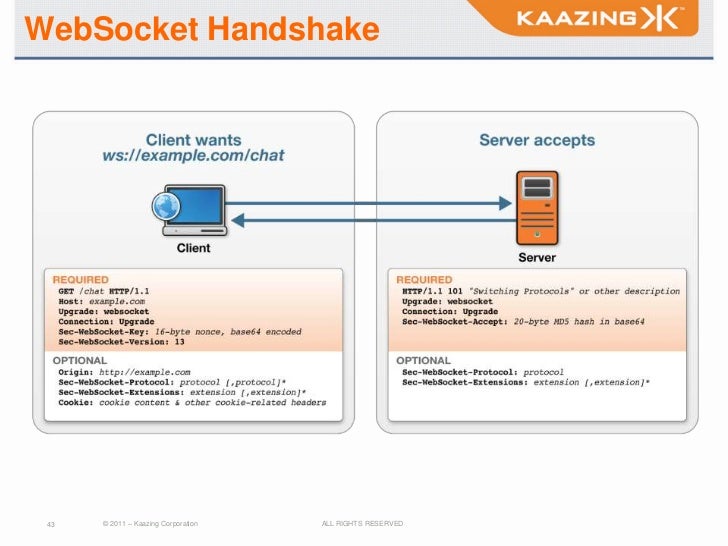
The client establishes a WebSocket connection through a process known as the WebSocket handshake. This process starts with the client sending a regular HTTP request to the server.
Now that the handshake is complete the initial HTTP connection
At this point either party can
With
having the ability to open bidirectional, low latency connections enables a whole new generation of real-time web applications.
https://blog.teamtreehouse.com/an-introduction-to-websockets






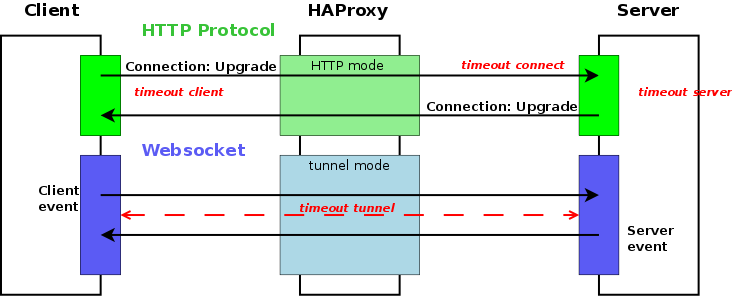
- HTTP protocol is connection-less
only the client can request information from a server
HTTP is purely half-duplex
a server can answer only one time to a client request
Some websites or web applications require the server to update client from time to time
There were a few ways to do so
the client
the client
those methods have many drawbacks
So
allows a 2 ways communication (full duplex) between a client and a server, over a single TCP connection
uses the standard TCP port
How does
The most important part is the “Connection: Upgrade” header which let the client know to the server it wants to change to
the TCP connection used for the HTTP request/response challenge
The socket finishes as soon as one peer decides it or the TCP connection is closed
https://www.haproxy.com/blog/websockets-load-balancing-with-haproxy/
- HTML5
WebSocket
defines a full-duplex communication channel that operates through a single socket over the Web
especially for real-time, event-driven web applications
how HTML5 Web Sockets can offer such
Normally when a browser visits a web page, an HTTP request
If you want to get the most up-to-date "real-time" information, you can constantly refresh that page manually
Current attempts to provide real-time web applications largely revolve around polling and other server-side push technologies
HTML5 Web Sockets represents the next evolution of web communications—a full-duplex, bidirectional communications channel that operates through a single socket over the Web
HTML5 Web Sockets provides a true standard
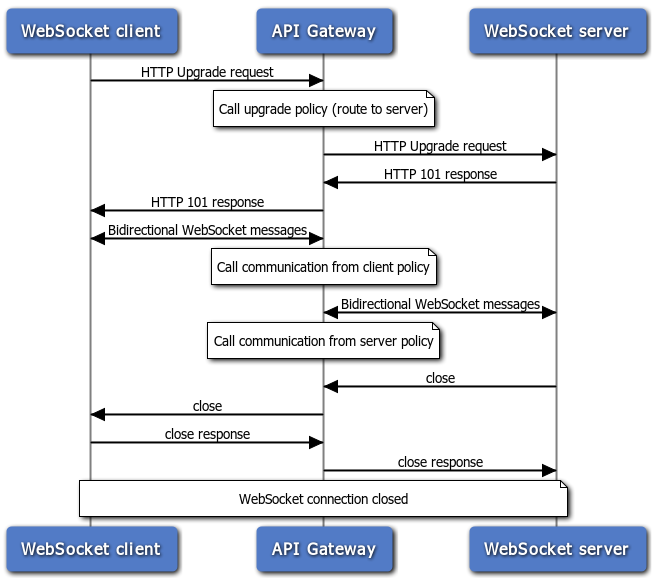
To establish a WebSocket connection, the client and server upgrade from the HTTP protocol to the WebSocket protocol during their initial handshake
Once established,
The data
it cannot deliver raw binary data to JavaScript because JavaScript does not support a
Today, only Google's Chrome browser supports HTML5 Web Sockets natively
To leverage the full power of HTML5 Web Sockets,
http://www.websocket.org/quantum.html

SIMPLEX, HALF-DUPLEX, FULL-DUPLEX




- Who said REST can’t be
realtime polling your REST APIs and haveKaazing dynamically deliver updates from them the moment they are available to any client, anywhere
A distributed cloud-based service ensures the highest reliability and performance.
using Server Sent Events (SSE) it streams these messages to either browsers or mobile apps
SSE is a HTML5 standard
Advanced security capabilities include end-to-end encryption and access control (a set which app users receive which data) while performance innovations ensure that no matter what, users will receive, the right data, at the right time in the right form
https://kaazing.com/
- Once established, a
websocket
Although most often used in the context of HTTP, Representational State Transfer (REST) is an architectural design pattern and not a transport protocol. The HTTP protocol is just one implementation of the REST architecture.
https://blog.feathersjs.com/http-vs-websockets-a-performance-comparison-da2533f13a77
- CLOUD SCALABILITY: SCALE UP VS SCALE OUT
IT Managers run into scalability challenges on a regular basis . It is difficult to predict growth rates of applications, storage capacity usage, and bandwidth.
When a workload reaches capacity limits the question is how is performance maintained while preserving efficiency to scale?
Scale-up vs Scale-out
Infrastructure scalability handles the changing needs of an application by statically adding or removing resources to meet changing application demands as needed. In most cases, this is handled by scaling up (vertical scaling) and/or scaling out (horizontal scaling).
Scale-up or Vertical Scaling
Scale-up is done by adding more resources to an existing system to reach a desired state of performance. For example, a database or web server needs additional resources to continue performance at a certain level to meet SLAs. More compute , memory, storage, or network can be added to that system to keep the performance at desired levels. When this is done in the cloud, applications often get moved onto more powerful instances and may even migrate to a different host and retire the server it was on. These types of scale-up operations have been happening on-premises in datacenters for decades. However, the time it takes to procure additional recourses to scale-up a given system could take weeks or months in a traditional on-premises environment while scaling-up in the cloud can take only minutes
Scale-out or Horizontal Scaling
Scale-out is usually associated with distributed architectures. There are two basic forms of scaling out:
Adding additional infrastructure capacity in pre-packaged blocks of infrastructure or nodes (i.e. hyper-converged)
use a distributed service that can retrieve customer information but be independent of applications or services. Horizontal scaling makes it easy for service providers to offer “pay-as-you-grow” infrastructure and services. Hyper-converged infrastructure has become increasingly popular for use in private cloud and even tier 2 service providers. This approach is not quite as loosely coupled as other forms of distributed architectures but, it does help IT managers that are used to traditional architectures make the transition to horizontal scaling and realize the associated cost benefits.
Loosely coupled distributed architecture allows for scaling of each part of the architecture independently. This means a group of software products can be created and deployed as independent pieces, even though they work together to manage a complete workflow. Each application is made up of a collection of abstracted services that can function and operate independently. This allows for horizontal scaling at the product level as well as the service level. Even more granular scaling capabilities can be delineated by SLA or customer type ( e.g. bronze, silver, or gold) or even by API type if there are different levels of demand for certain APIs. This can promote an efficient use of scaling within a given infrastructure.
https://blog.turbonomic.com/blog/on-technology/cloud-scalability-scale-vs-scale
No comments:
Post a Comment