- Apache
Mesos compute to easily be
A distributed systems kernel
kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elasticsearch) with API’s for
resource management and scheduling across entire datacenter
- Marathon is a production-grade container orchestration platform for Mesosphere’s Datacenter Operating System (DC/OS) and Apache
Mesos
https://mesosphere.github.io/marathon/ - DevOps
Kubernetes Mesos

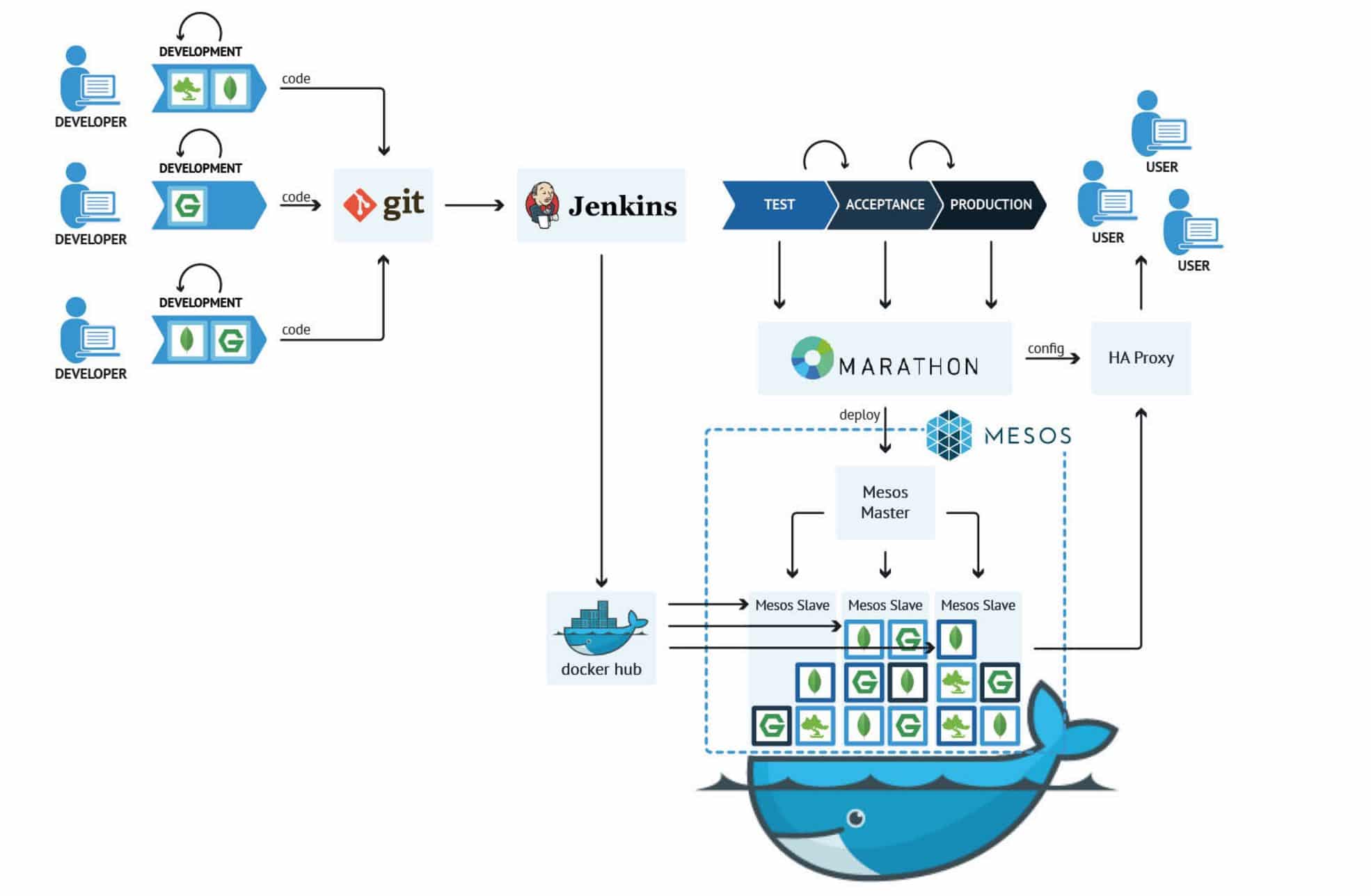

While a single master can control our complete setup, in production environments multiple masters are the norm.
Note that, because the masters expose its API trough REST,
Linux solutions like CoreOS already include
Apache
Marathon is a framework which uses
Container Deployment
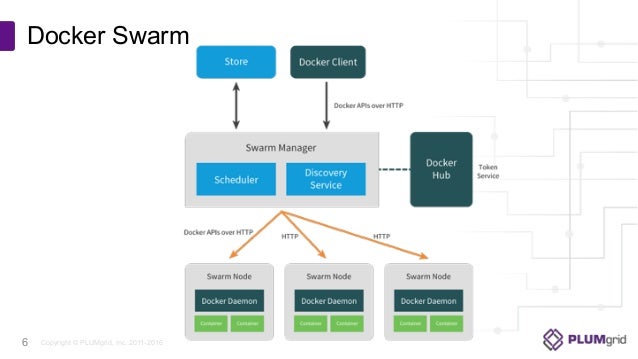
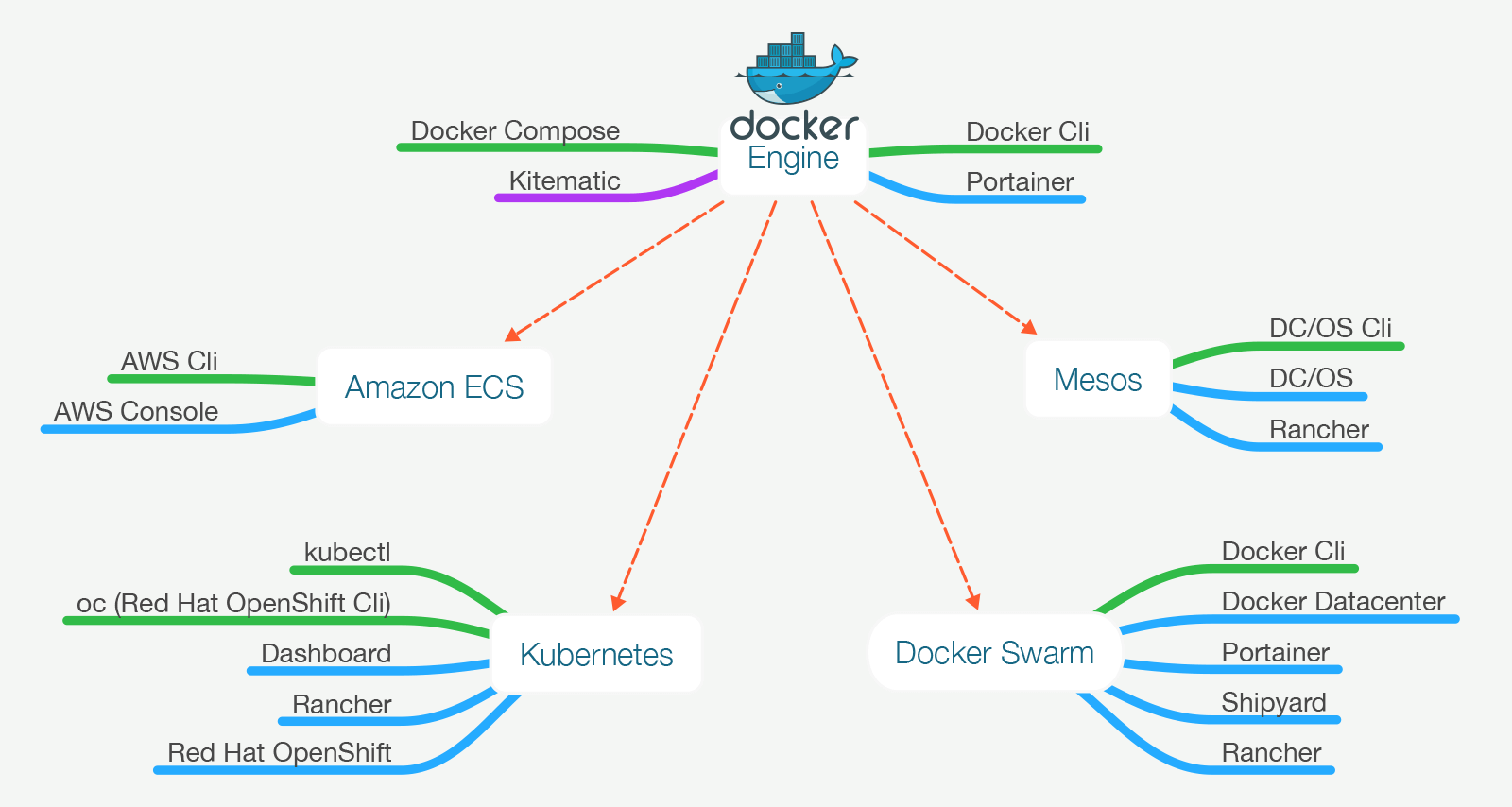
Docker Swarm: Completely Docker based and very easy
Minimum Size (Cluster)
Docker Swarm: One server running everything (for test purposes). In practical production environments, both the discovery and managers services need to be in highly available setups with at least two servers on each layer.
Maturity
Docker Swarm: Mature, but still evolving.
https://www.loomsystems.com/blog/single-post/2017/06/19/kubernetes-vs-docker-swarm-vs-apache-mesos-container-orchestration-comparison
Kubernetes Mesos –
Some high-level features
Container scheduling
High availability of either the application and containers or the orchestration system itself.
Parameters to determine container or application health.
Service discovery
Load Balancing requests
Attributing various types of storage to containers in a cluster.
Google itself uses Kubernetes as its own Container
Secret feature management, load balancing, auto-scaling and overall volume management are
a more distributed approach towards managing cloud resources and data centers.
Mesosphere DC/OS, a distributed
https://afourtech.com/kubernetes-vs-docker-swarm-vs-mesos/
-
Kubernetes
API Server: This component is the management hub for the Kubernetes thereby
Controller Manager: This component ensures that the cluster’s desired state matches the current state by scaling workloads up and down.
Scheduler: This component places the workload on the appropriate – be placed
The following list provides some other common terms associated with Kubernetes
Pods: Kubernetes namespaces
Deployments: These building blocks can be used to Deployments can be used
Services: Services are endpoints that can be addressed be connected Kubernetes them to be addressed by name
Labels: Labels are key-value pairs attached to objects and can be used to
Open source projects. Anyone can contribute using the Go programming language.
Logging and Monitoring add-ons. These external tools include Elasticsearch/Kibana (ELK), sysdig cAdvisor Heapster Grafana
https://platform9.com/blog/kubernetes-docker-swarm-compared/
- Orchestration Platforms in the Ring:
Kubernetes
One key advantage that Docker Swarm seems to have over
Docker Swarm also advertises itself as easy to use, especially
Docker, realizing the strength of its container technology,
https://www.nirmata.com/2018/01/15/orchestration-platforms-in-the-ring-kubernetes-vs-docker-swarm/
- Docker Clustering Tools Compared:
Kubernetes
However,
As an example, if you
We might not want to run a script but make
While some might not care about
if you prefer, for example, to use Consul you’re in a very complicated situation and would need to use one for
Kubernetes requires you to learn its CLI and configurations. You cannot use docker-compose
If you adopt Kubernetes,
Swarm team
Actually, we still cannot link them but now we have multi-host networking to help us connect containers running on different servers. It is a
Another problem was persistent volumes. Now we have persistent volumes supported by Docker natively.
Both networking and persistent volumes problems were one
Docker Swarm took a different approach. It is a native clustering for Docker.
The best part is that it exposes standard Docker API meaning that any tool
If the API doesn’t support something, there is no way around it through Swarm API and some clever tricks need to
Setting up Docker Swarm is easy, straightforward and flexible.
All we have to do is install one of the service discovery tools and run the swarm container on all nodes. Since the distribution
We run the swarm container, expose a port and inform it about the address of the service discovery
when our usage of it becomes more serious, add
When trying to make a choice between Docker Swarm and Kubernetes, think in the following terms. Do you want to depend on Docker itself solving problems related to clustering? If you do, choose Swarm. If something
https://technologyconversations.com/2015/11/04/docker-clustering-tools-compared-kubernetes-vs-docker-swarm/
Kubernetes Mesos
Apache
Container Orchestration Tools: Compare
https://platform9.com/blog/compare-kubernetes-vs-mesos/



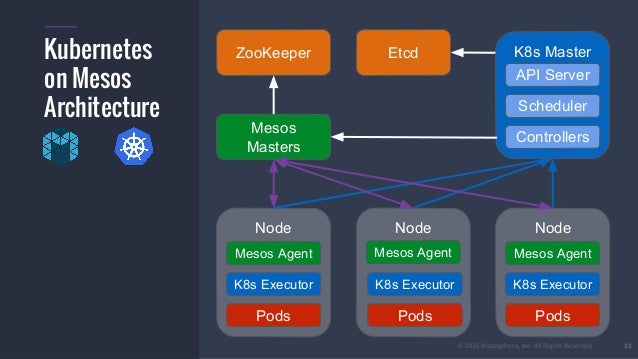

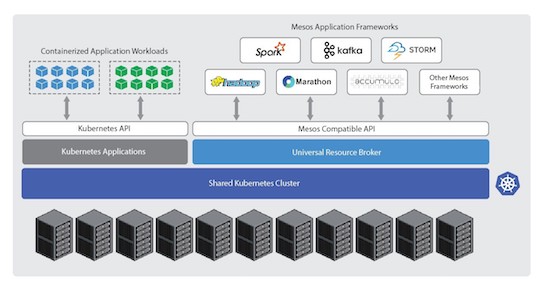

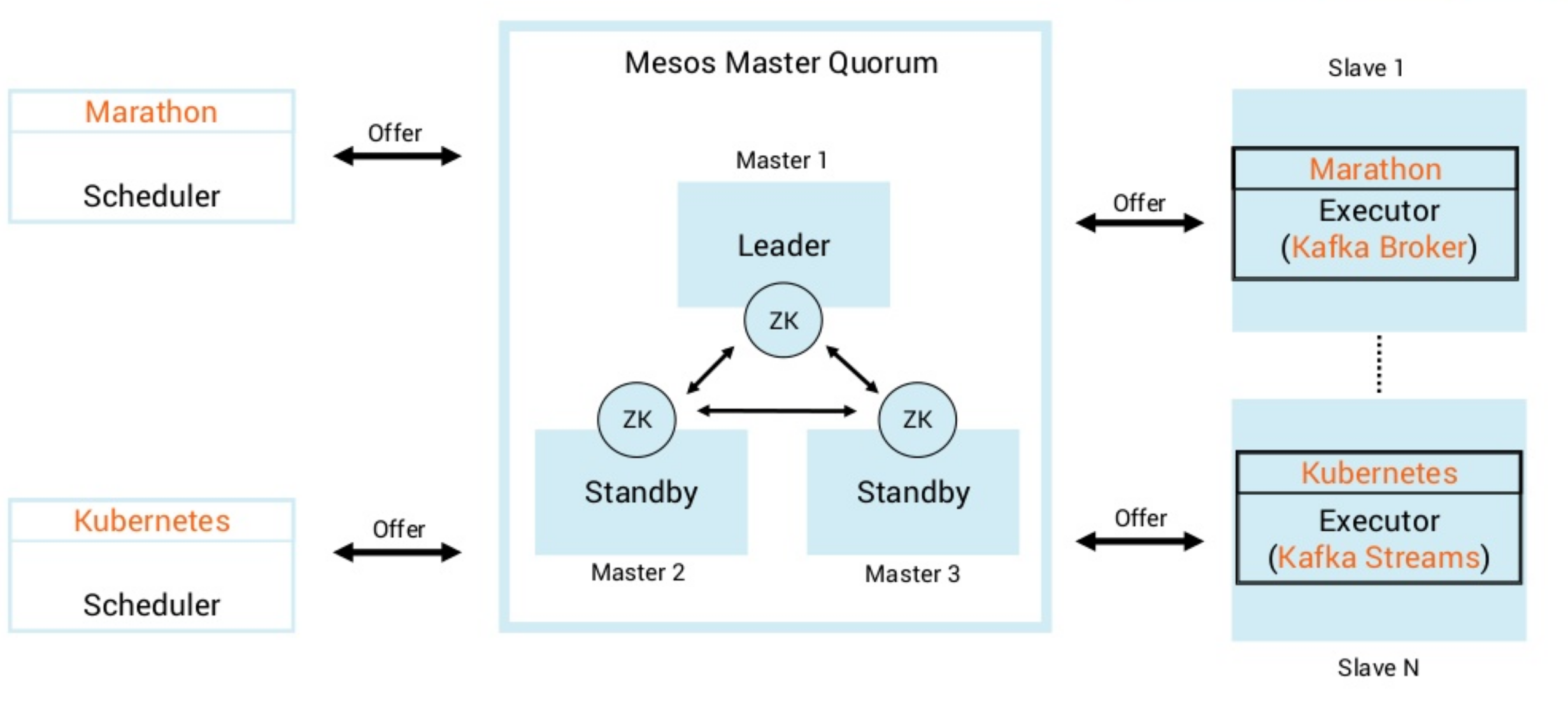


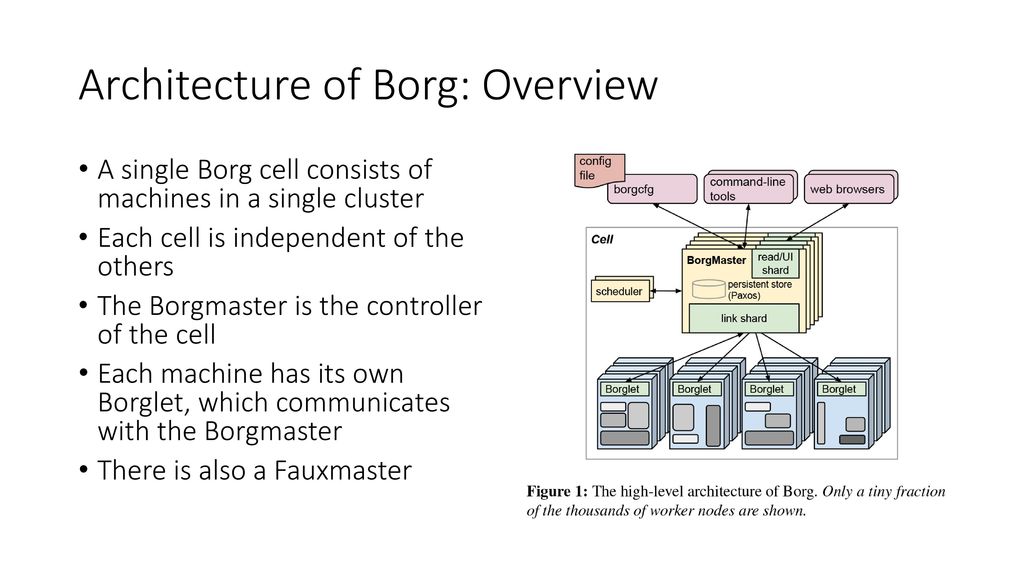
- Google's Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across
a number of
https://ai.google/research/pubs/pub43438
- At Google, we have been managing Linux containers at scale for
more than
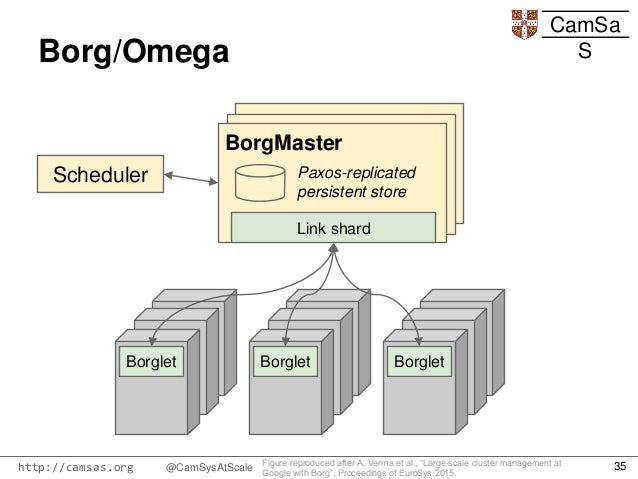
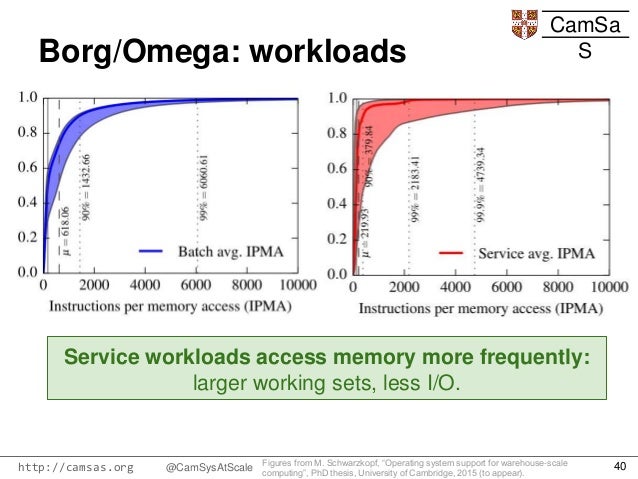
The first unified container-management system developed at Google was the system we internally call Borg
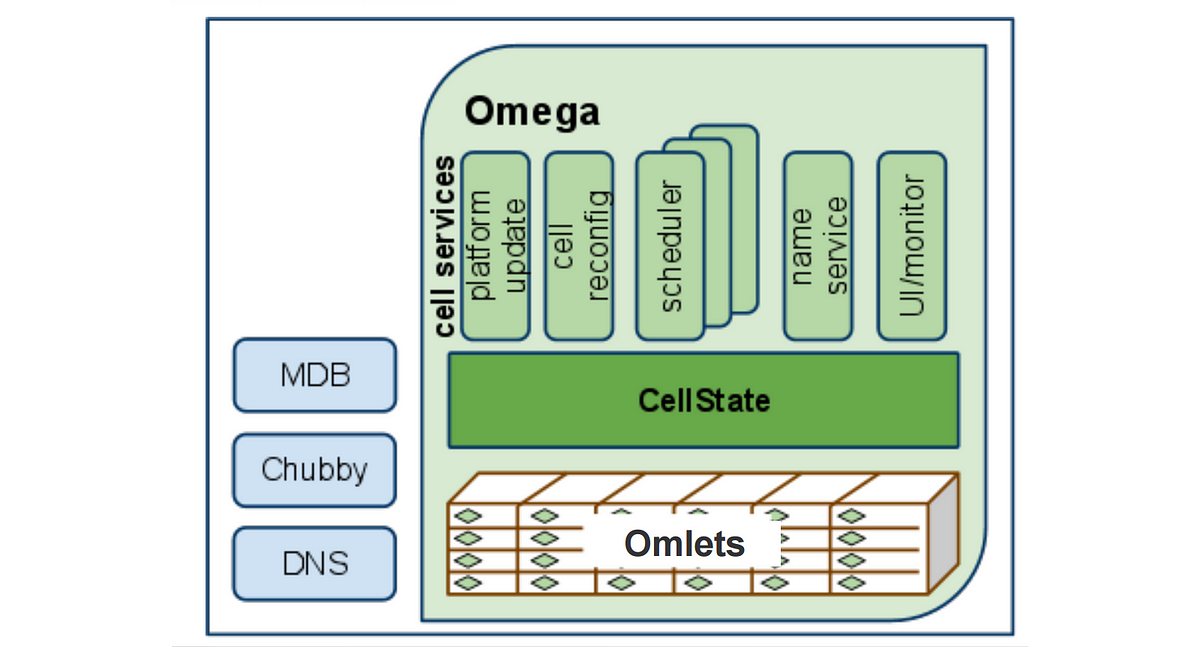
Omega,
Omega stored the state of the cluster in a centralized Paxos-based transaction-oriented store
cluster control plane (such as schedulers)
The third container-management system developed at Google was
In contrast to Omega, which exposes the store directly to
validation, semantics, and policy,
More importantly,
developers writing applications that run in a cluster: its main design goal is to make it easy to deploy and manage complex
distributed systems, while still
The key to making this abstraction work is having a hermetic container image that can encapsulate almost all of an application’s dependencies into a package that can
applications can still
socket options, /proc, and arguments to
the isolation and dependency minimization provided by containers have proved
(1) it relieves application developers and operations teams from worrying about specific details of machines and operating systems;
(2) it provides the infrastructure team flexibility to roll out new hardware and upgrade operating systems with minimal impact on running applications and their developers;
(3) it ties telemetry collected by the management system (e.g., metrics such as CPU and memory usage) to applications rather than machines, which dramatically improves
application monitoring and introspection, especially when scale-up, machine failures, or maintenance cause application instances to move.
For example, the /
(
For example, Borg applications can provide a simple text status message that can
provides key-value annotations stored in each object’s metadata that can
This is simpler, more robust, and permits finer-grained reporting and control of metrics and logs. Compare
The application-oriented shift has ripple effects throughout the management infrastructure. Our load balancers don’t balance traffic
Logs
pollution from multiple applications or system operations.
In reality, we use nested containers that are co-scheduled on the same machine: the outermost
one provides a pool of resources; the inner ones provide deployment isolation
In Borg, the outermost container
The original Borg system made it possible to run disparate workloads on shared machines to improve resource utilization.
For example, the pod API is usable by people, internal
To further this consistency,
A good example of this is the separation between the
A replication controller ensures the existence of the desired number of pods for a
how those pods
Decoupling ensures that multiple related but different components share a similar look and feel.
The design of
of control through choreography
autonomous entities that collaborate.
We present some of them here
Don’t make the container system
Don’t just number containers give them labels
Be careful with ownership
Don’t expose raw state
if one of these pods
one or more of the labels that cause it to be targeted by the
serving traffic, but it will remain up and can
the pods that implements the service automatically creates a replacement pod for the misbehaving one.
SOME OPEN HARD PROBLEMS
Configuration; managing configurations
Dependency management; instantiating the dependencies is rarely as simple as just starting a new copy
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/44843.pdf




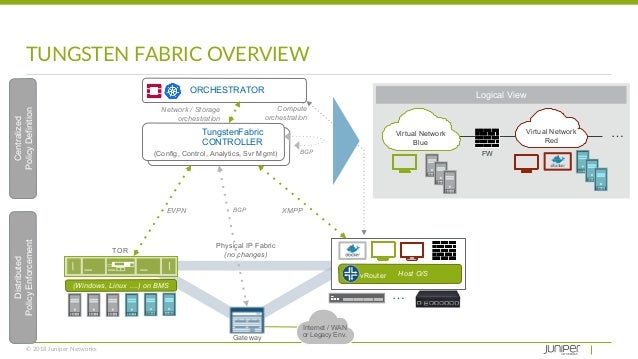
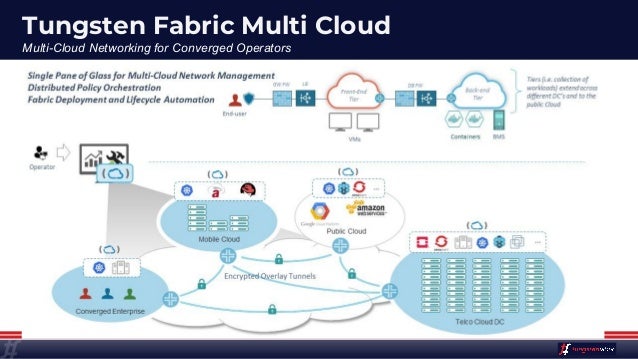
- Solve your tooling complexity and overload with the simplicity of only one networking and security tool. Save time and swivel-chair fatigue from context switches as you
consolidate - Connecting multiple orchestration stacks like
Kubernetes Mesos VMware - Choosing an SDN plug-in for CNI, Neutron, or
vSphere - Networking and security across legacy, virtualized and containerized applications.
Multistack
https://tungsten.io/



- fabric8 is an end to end development platform spanning ideation to production for the creation of cloud native applications and
microservices ChatOps
http://fabric8.io/

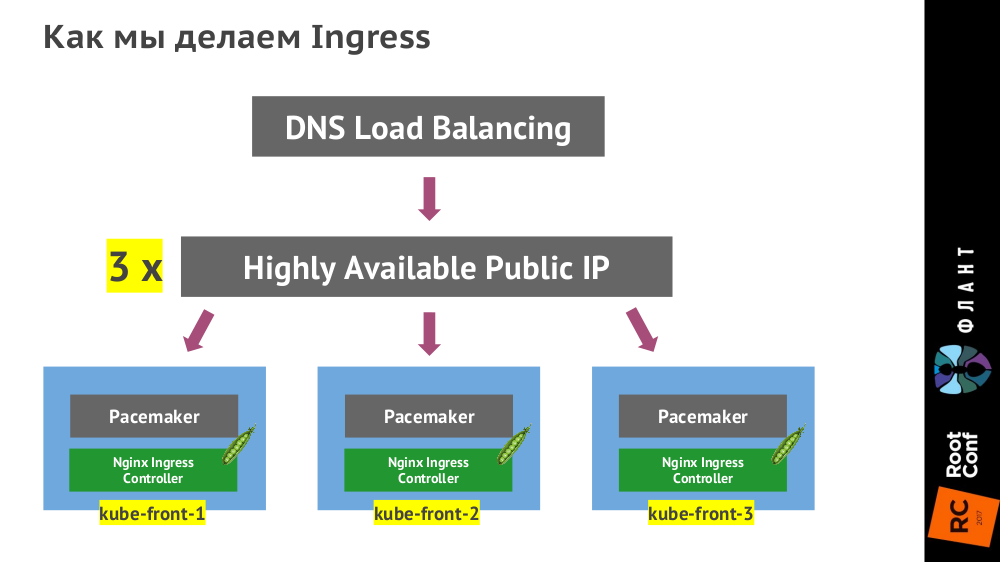
- Pacemaker is a high-availability cluster resource manager.
It achieves maximum availability for your cluster services (a. .
https://wiki.clusterlabs.org/wiki/Pacemaker
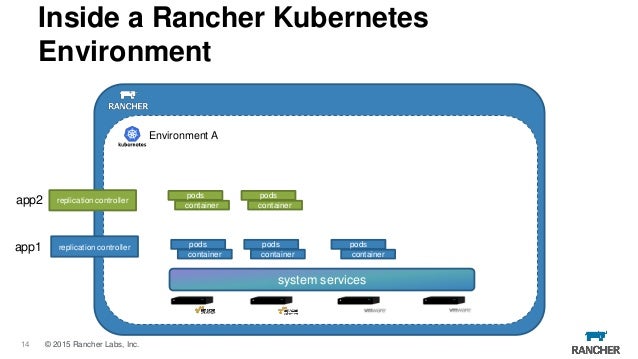
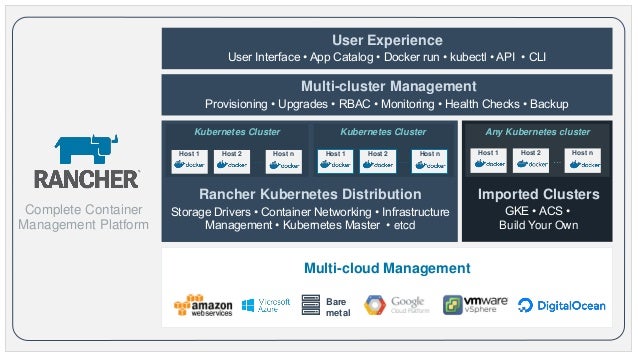
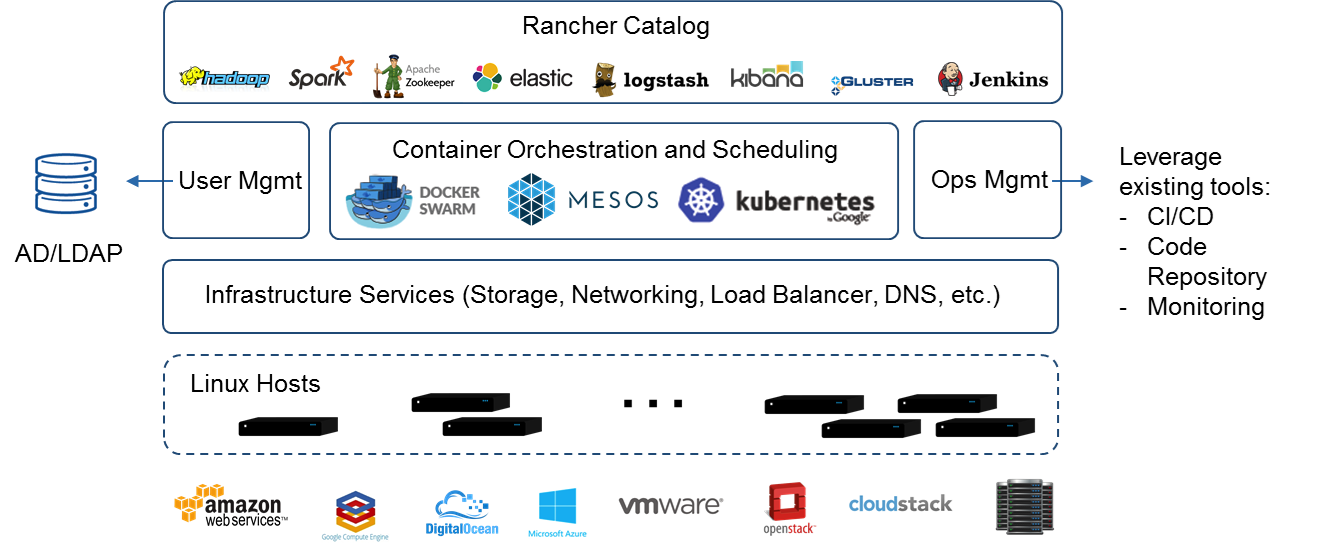
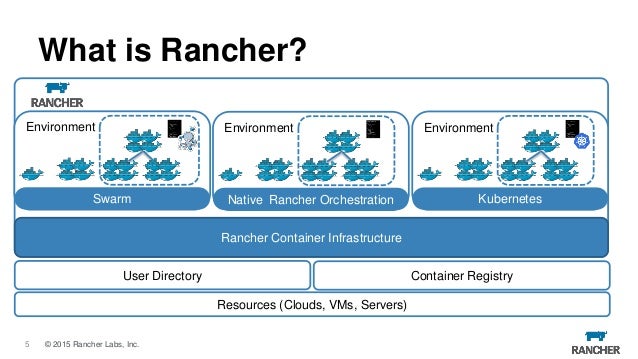
- Rancher is an open source project that provides a complete platform for operating Docker in production. It provides infrastructure services such as multi-host networking, global and local load balancing, and volume snapshots. It integrates native Docker management capabilities such as Docker Machine and Docker Swarm. It offers a rich user experience that enables
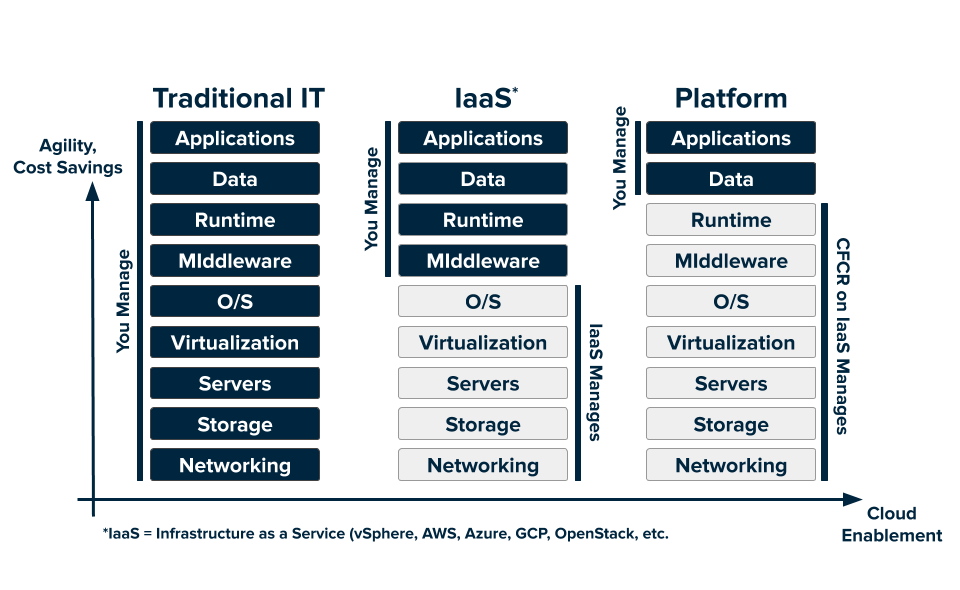
devops - As the global industry standard for
PaaS . .
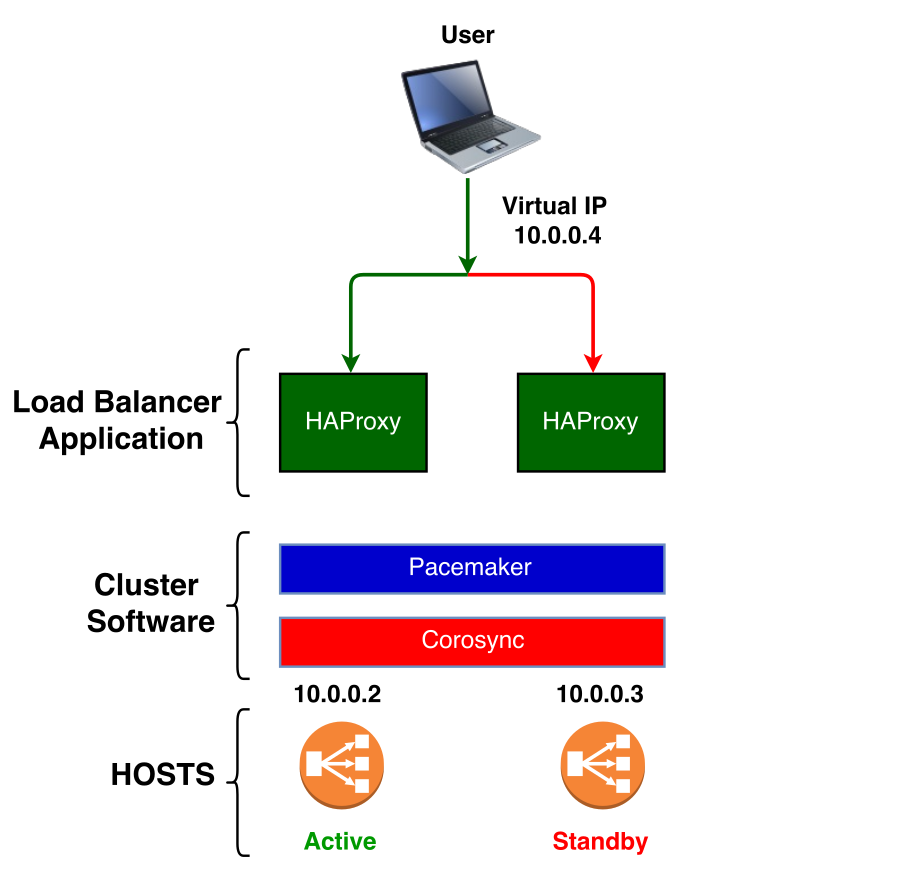
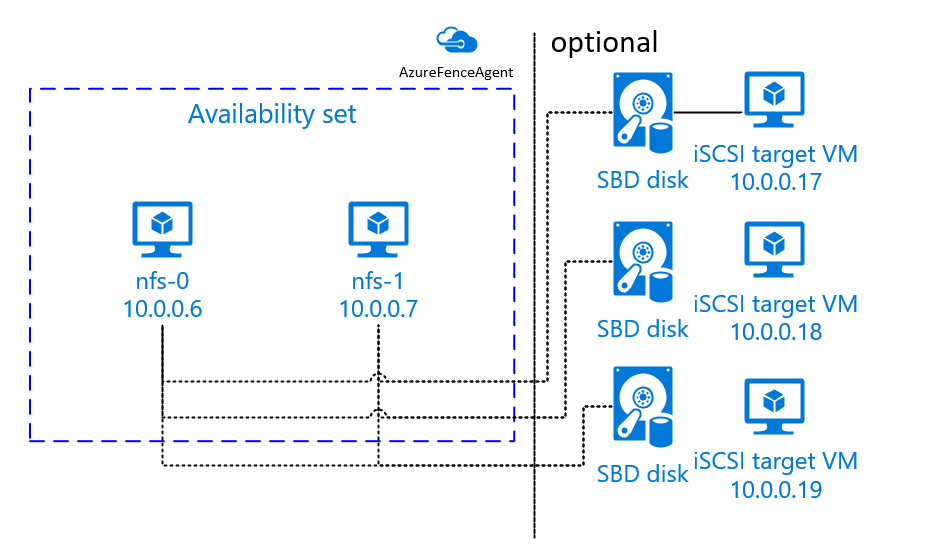


Fencing Devices
The fencing device is a hardware/software device which helps to disconnect the problem node by resetting node / disconnecting shared storage from accessing it
https://www.itzgeek.com/how-tos/linux/centos-how-tos/configure-high-avaliablity-cluster-on-centos-7-rhel-7.html
https://rancher.com/what-is-rancher/open-source/

https://www.cloudfoundry.org/
Docker Compose is used to run multiple containers as a single service- What is Docker Compose?
- For instance, as a developer,
- Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration.
- Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration
- The main function of Docker Compose is the creation of
microservice architecture, meaning the containers and the links between them. - You can use Docker Machine to:
- What is Docker Machine?
For example, suppose you had an application which required NGNIX and MySQL, you could create one file which would start both the containers as a service without the need to start each one separately.
All Docker Compose files are YAML files.
https://www.tutorialspoint.com/docker/docker_compose.htm
If your Docker application includes more than one container (for example, a webserver and database running in separate containers), building, running, and connecting the containers from separate Dockerfiles is cumbersome and time-consuming. Docker Compose solves this problem by allowing you to use a YAML file to define multi-container apps. You can configure as many containers as you want, how they should be built and connected, and where data should be stored . When the YAML file is complete, you can run a single command to build, run, and configure all of the containers.
https://www.linode.com/docs/applications/containers/how-to-use-docker-compose
how can I easily recreate a microservice architecture on my development machine?
And how can I be sure that it remains unchanged as it propagates through a Continuous Delivery process?
And finally, how can I be sure that a complex build & test environment can be reproduced easily?
For multi-host deployment, you should use more advanced solutions, like Apache Mesos or a complete Google Kubernetes architecture.
The main function of Docker Compose is the creation of microservice architecture, meaning the containers and the links between them.
https://blog.codeship.com/orchestrate-containers-for-development-with-docker-compose
https://docs.docker.com/compose/overview/
Common use cases
Development environments
When you’re developing software, the ability to run an application in an isolated environment and interact with it is crucial
Automated testing environments
An important part of any Continuous Deployment or Continuous Integration process is the automated test suite. Automated end-to-end testing requires an environment in which to run tests. Compose provides a convenient way to create and destroy isolated testing environments for your test suite. By defining the full environment in a Compose file, you can create and destroy these environments in just a few commands
Single host deployments
You can use Compose to deploy to a remote Docker Engine. The Docker Engine may be a single instance provisioned with Docker Machine or an entire Docker Swarm cluster
https://docs.docker.com/compose/overview/#automated-testing-environments
Docker Compose Workflow
There are three steps to using Docker Compose:
Define each service in a Dockerfile .
Define the services and their relation to each other in the docker-compose. yml file.
Use docker-compose up to start the system.
https://blog.codeship.com/orchestrate-containers-for-development-with-docker-compose/
Install and run Docker on Mac or Windows
Provision and manage multiple remote Docker hosts
Provision Swarm clusters
What is Docker Machine?
Docker Machine is a tool that lets you install Docker Engine on virtual hosts, and manage the hosts with docker-machine commands. You can use Machine to create Docker hosts on your local Mac or Windows box, on your company network, in your data center, or on cloud providers like Azure, AWS, or Digital Ocean.
https://docs.docker.com/machine/overview/


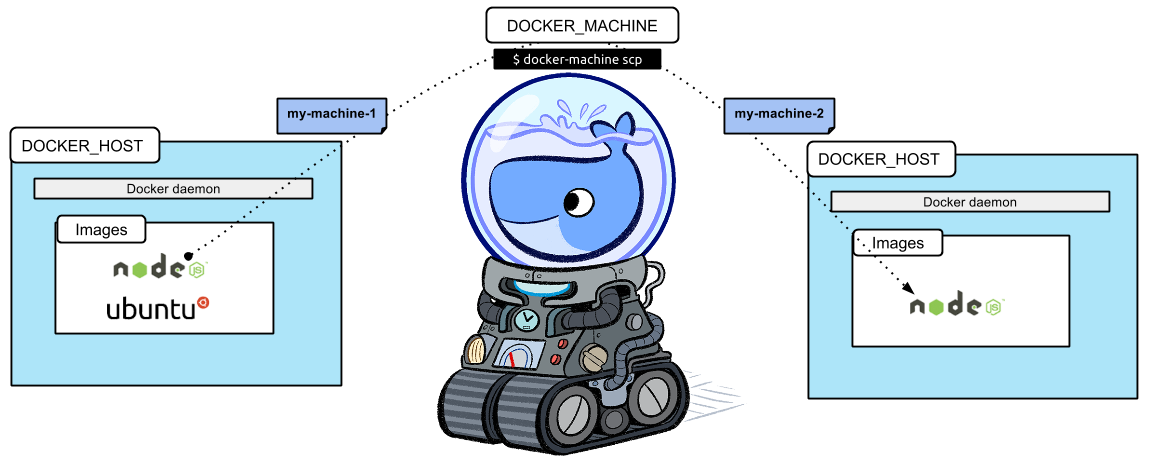
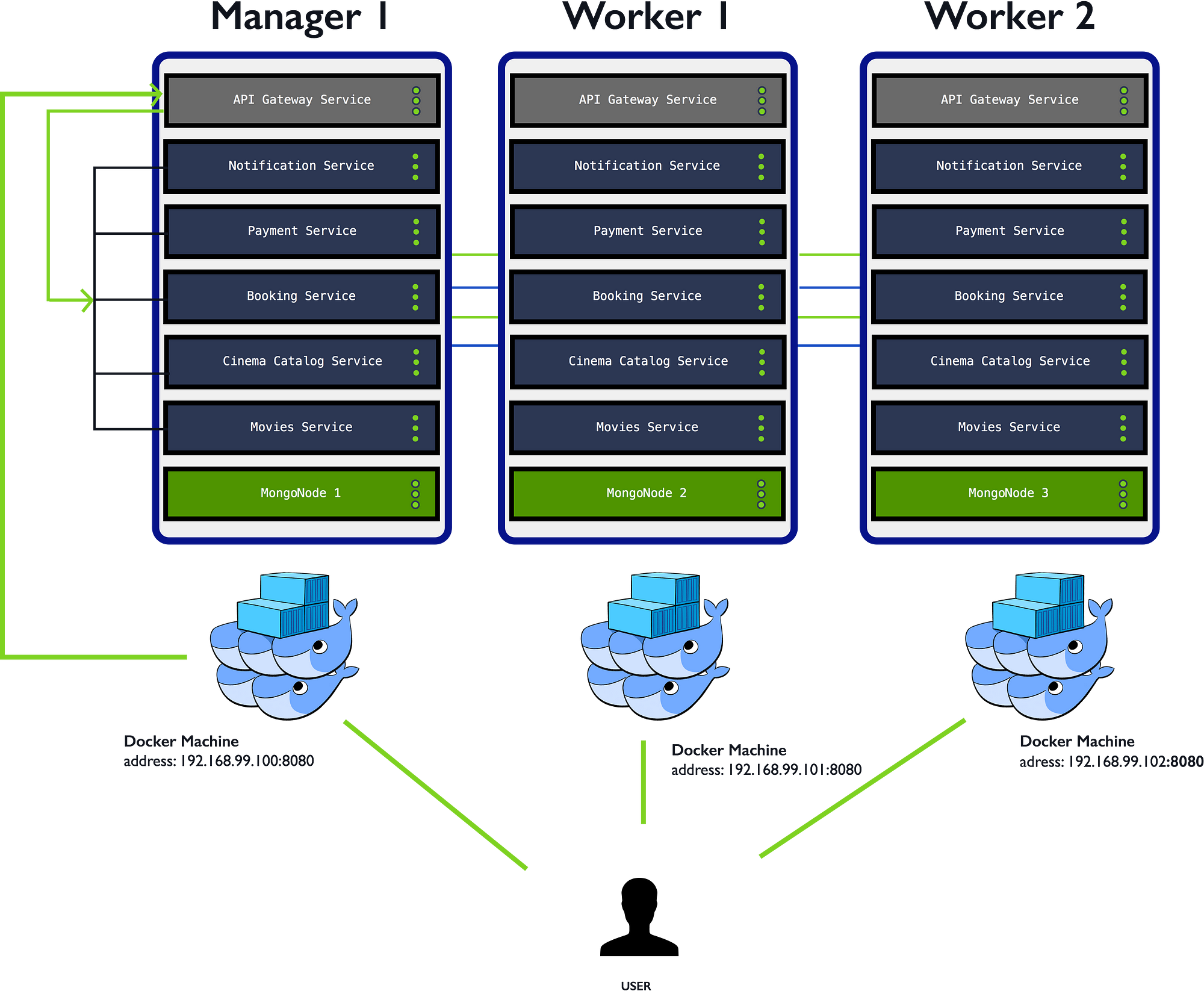
Docker Machine is a tool that lets you install Docker Engine on virtual hosts, and manage the hosts with docker-machine commands. You can use Machine to create Docker hosts on your local Mac or Windows box, on your company network, in your data center, or on cloud providers like Azure, AWS, or Digital Ocean.
Why should I use it?
Docker Machine enables you to provision multiple remote Docker hosts on various flavors of Linux.
Docker Engine runs natively on Linux systems. If you have a Linux box as your primary system, and want to run docker commands, all you need to do is download and install Docker Engine. However, if you want an efficient way to provision multiple Docker hosts on a network, in the cloud or even locally, you need Docker Machine.
What’s the difference between Docker Engine and Docker Machine?
When people say “Docker” they typically mean Docker Engine, the client-server application made up of the Docker daemon, a REST API that specifies interfaces for interacting with the daemon, and a command line interface (CLI) client that talks to the daemon (through the REST API wrapper). Docker Engine accepts docker commands from the CLI, such as docker run <image>, docker ps to list running containers, docker image ls to list images, and so on.
Docker Machine is a tool for provisioning and managing your Dockerized hosts (hosts with Docker Engine on them). Typically, you install Docker Machine on your local system. Docker Machine has its own command line client docker-machine and the Docker Engine client, docker. You can use Machine to install Docker Engine on one or more virtual systems. These virtual systems can be local (as when you use Machine to install and run Docker Engine in VirtualBox on Mac or Windows) or remote (as when you use Machine to provision Dockerized hosts on cloud providers). The Dockerized hosts themselves can be thought of, and are sometimes referred to as, managed “machines”.
https://docs.docker.com/machine/overview/#what-is-docker-machine
Define and run multiple containers on a swarm cluster.
Just like docker-compose helps you define and run multi-container applications on a single host, docker-stack helps you define and run multi-container applications on a swarm cluster.
Docker:
Build, ship, publish, download, and run docker images.
Docker Compose:
Define and run multiple containers linkedtogether on a single host.
Useful for setting up development and testing workflows.
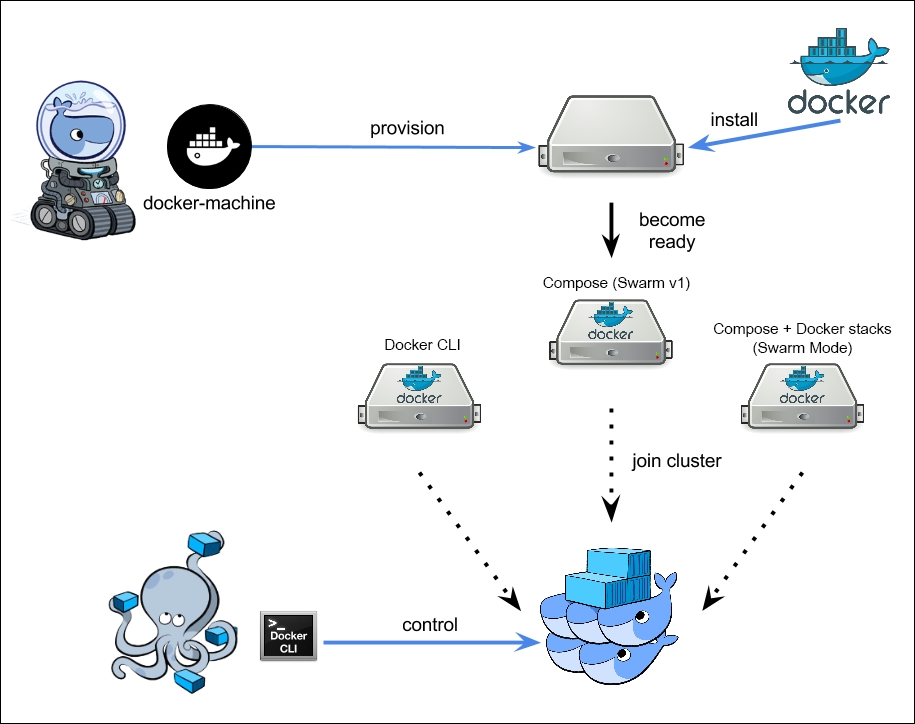
Docker Machine:
Tool for provisioning and managing docker hosts (virtual hosts running docker engine).
It automatically creates hosts, installs Docker Engine on them, then configures the docker clients.
You can use Machine to create Docker hosts on your local machine using a virtualization software likeVirtualBox or VMWare Fusion.
Docker machine also supports various cloud providers like AWS, Azure, Digital Ocean, Google Compute Engine, OpenStack,RackSpace etc .
Docker Swarm:
A swarm is a group of docker hosts linkedtogether into a cluster.
The swarm clusterconsists of a swarm manager and a set of workers.
You interact with the cluster by executing commands on theswarm manager.
Withswarm , you can deploy and scale your applications to multiple hosts.
Swarm helps with managing, scaling, networking, service discovery, and load balancing between the nodes in the cluster.
Docker Stack:
Define and run multiple containers on a swarm cluster.
https://www.callicoder.com/docker-machine-swarm-stack-golang-example/
Just like docker-compose helps you define and run multi-container applications on a single host, docker-stack helps you define and run multi-container applications on a swarm cluster.
Docker:
Build, ship, publish, download, and run docker images.
Docker Compose:
Define and run multiple containers linked
Useful for setting up development and testing workflows.
Docker Machine:
Tool for provisioning and managing docker hosts (virtual hosts running docker engine).
It automatically creates hosts, installs Docker Engine on them, then configures the docker clients.
You can use Machine to create Docker hosts on your local machine using a virtualization software like
Docker machine also supports various cloud providers like AWS, Azure, Digital Ocean, Google Compute Engine, OpenStack,
Docker Swarm:
A swarm is a group of docker hosts linked
The swarm cluster
You interact with the cluster by executing commands on the
With
Swarm helps with managing, scaling, networking, service discovery, and load balancing between the nodes in the cluster.
Docker Stack:
Define and run multiple containers on a swarm cluster.
https://www.callicoder.com/docker-machine-swarm-stack-golang-example/
- Titus is a container management platform that provides
scalable and reliable container execution and cloud-native integration with Amazon AWS
To deliver the consistent experience for developers and IT ops, teams began using Docker for Containers as a Service (CaaS ).
Containers as a Service is a model where IT organizations and developers can work together to build, ship and run their applications anywhere.
CaaS enables an IT secured and managed application environment consisting of content and infrastructure, from which developers are able build and deploy applications in a self service manner.
https://blog.docker.com/2016/02/containers-as-a-service-caas
Containers as a Service is a model where IT organizations and developers can work together to build, ship and run their applications anywhere.
https://blog.docker.com/2016/02/containers-as-a-service-caas

Titus is a framework on top of Apache Mesos , a cluster-management system that brokers available resources across a fleet of machines. Titus consists of a replicated, leader-elected scheduler called Titus Master, which handles the placement of containers onto a large pool of EC2 virtual machines called Titus Agents, which manage each container's life cycle. Zookeeper manages leader election, and Cassandra persists the master's data. The Titus architecture is shown below.
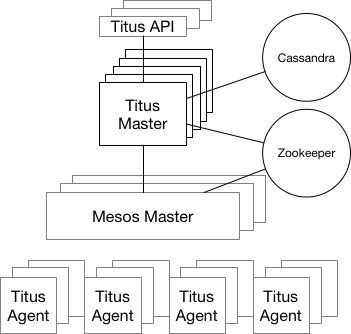
https://netflix.github.io/titus/overview/
It is so nice article thank you for sharing this valuable content
ReplyDeleteDocker Training in Hyderabad
Kubernetes Training in Hyderabad
Docker and Kubernetes Training
Docker and Kubernetes Online Training