- Decommissioning Otto
https://www.ottoproject.io/
- how
Microservices work with Consul
how the following components affect Consul.
Using docker
Building
Using
the consul server will wait until there are 3 peers connected before self-bootstrapping and becoming a working cluster
Building
The
Using
The
The main reason for building
As for Consul, we can use the
Nomad is a tool for managing a cluster of machines and running applications on them.
It is
By default, Nomad covers the Docker and
https://www.tutorialspoint.com/consul/consul_working_with_microservices.htm
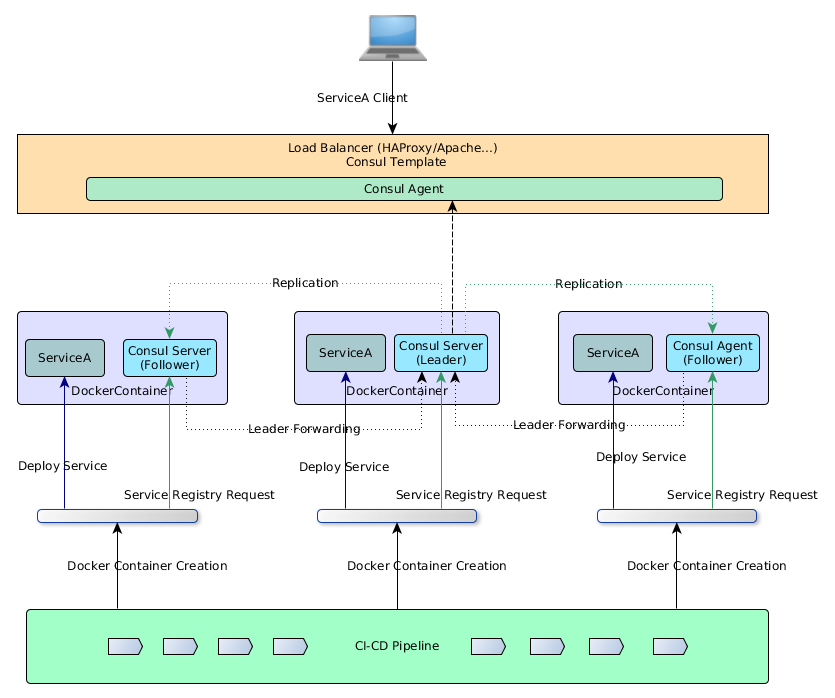

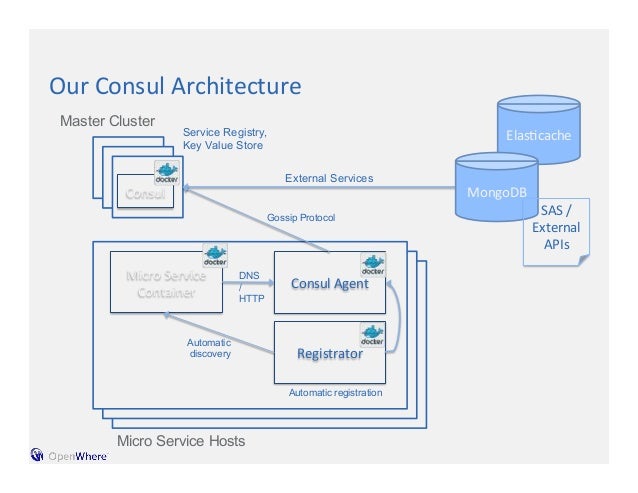




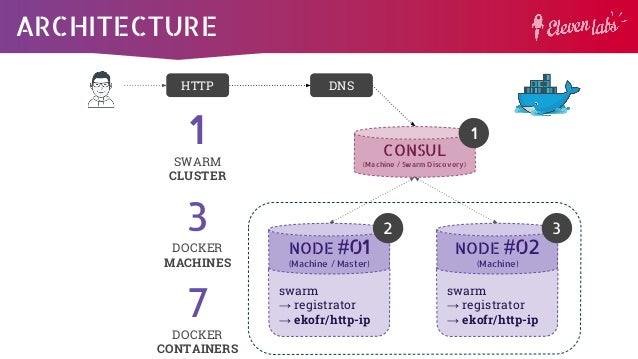
- Within each
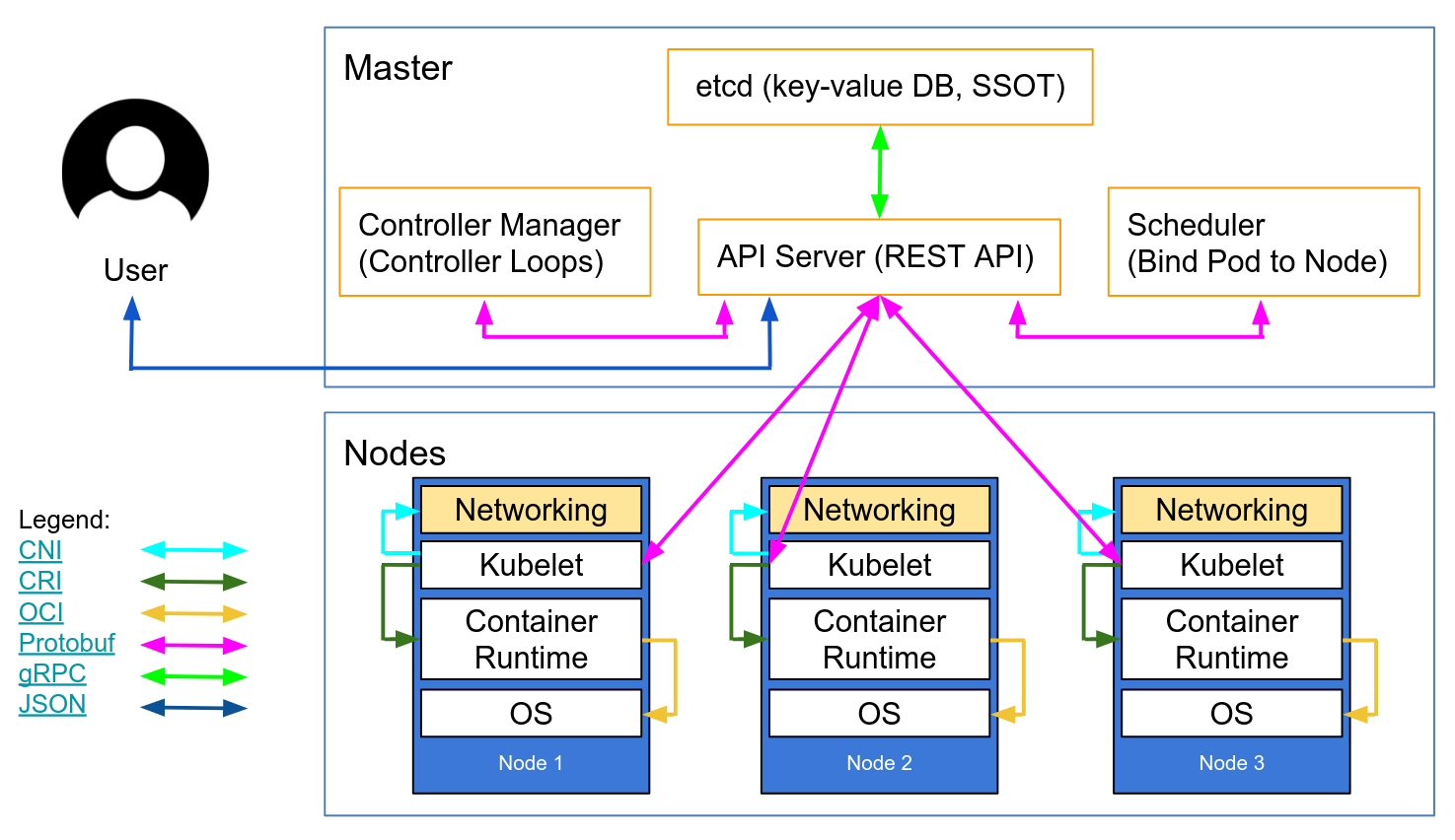
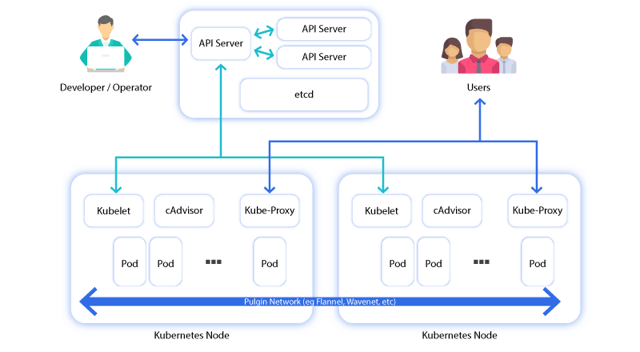
datacenter , we have a mixture of clients and servers.It is expected that there be between three to five servers. Thisstrikes a balance between availabilityin the case of failure and performance, as consensus gets progressively sloweras more machines are added . However, there is no limit to the number of clients, and they can easily scale into the thousands or tens of thousands.
All the nodesthat are in adatacenter participate in a gossip protocol.
This means there is a gossip pool that contains all the nodes for agiven datacenter .
first, there is no need to configure clients with the addresses of servers;discovery is done automatically
Second, the work of detecting node failuresis not placed on the servers butis distributed . This makes failure detection much more scalable thannaive heartbeating schemes.Thirdly , itis used as a messaging layer to notify when important events such as leader election take place.
The servers in eachdatacenter are all part of a single Raft peer set. This meansthat they work together to elect a single leader, a selected server which has extra duties. The leaderis responsible for processing all queries and transactions. Transactions must alsobe replicated to all peers as part of the consensus protocol. Because of this requirement, when a non-leader server receives an RPC request, it forwards it to the cluster leader.
The server nodes also operate as part of a WAN gossip pool. This poolis different from the LAN pool as itis optimized for the higher latency of the internet andis expected to contain only other Consul server nodes.The purpose of this pool is to allow datacenters to discover each other in a low-touch manner.
Bringing a newdatacenter online is as easy as joining the existing WAN gossip pool.
Because the servers are all operating in this pool, it also enables cross-datacenter requests.
In general, data is not replicated between different Consuldatacenters .
When a requestis made for a resource in anotherdatacenter , the local Consulservers forward an RPC request to the remote Consulservers for that resource and return the results
There are some special situations where a limited subset of data canbe replicated , such as withConsul's built-in ACL replication capability, or external tools like consul-replicate.
https://www.consul.io/docs/internals/architecture.html
- Basic Federation with the WAN Gossip Pool
One of the key features of Consul is its support for multipledatacenters .The architecture of Consul is designed to promote a low coupling ofdatacenters so that connectivity issues or failure of anydatacenter does not impact the availability of Consul in otherdatacenters .
This means eachdatacenter runs independently, each having a dedicated group of servers and a private LAN gossip pool.
https://www.consul.io/docs/guides/datacenters.html
- Quorum - A quorum is a majority of members from a peer set: for a set of size n, quorum requires at least
( n/2) +1 members. For example, if there are 5 members in the peer set, we would need 3 nodes to form a quorum. If a quorum of nodes is unavailable for any reason, the cluster becomes unavailable andno new logs can be committed .
https://www.consul.io/docs/internals/consensus.html
- Consul uses a consensus protocol to provide Consistency (as defined by CAP).
The consensus protocol is based on"
https://www.consul.io/docs/internals/consensus.html
- Raft is a consensus algorithm that
is based on Paxos. Compared to Paxos,Raft is designed to have fewer states and a simpler, more understandable algorithm.
https://www.consul.io/docs/internals/consensus.html

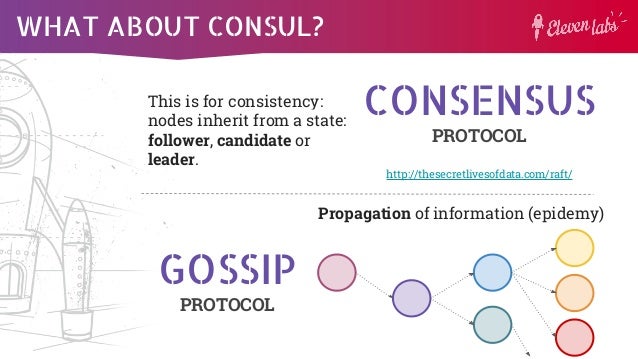
- Gossip Protocol
Serf uses a gossip protocol to broadcast messages to the cluster.
https://www.serf.io/docs/internals/gossip.html
- Serf is a decentralized solution for cluster membership, failure detection, and orchestration. Serf is in use in some huge deployments (
more than 10,000 machines in a single cluster), and powers Consul and Nomad.
This release brings improvements in Serf's gossip protocol which provide better robustness for applications that rely on Serf to detect the health of nodes in a cluster
https://www.hashicorp.com/blog/serf-0-8
- Thanos - a Scalable Prometheus with Unlimited Storage
Thanos' architecture introduces a central query layer across all the servers via a sidecar component which sits alongside each Prometheus server, and a central Querier component that
https://www.infoq.com/news/2018/06/thanos-scalable-prometheus
- Highly available Prometheus setup with
long term storage capabilities.
Thanos is a set of components that can
https://github.com/improbable-eng/thanos
- Consul is an important service discovery tool in the world of
Devops .
https://www.tutorialspoint.com/consul/index.htm
Consul is a
It
One of the core reasons to build Consul was to maintain the services present in the distributed systems
https://www.tutorialspoint.com/consul/index.htm
Service Discovery − Using either DNS or HTTP, applications can easily find the services they depend upon.
Health Check Status It
Key/Value Store −dynamic configuration, feature flagging, coordination, leader election, etc
Multi Datacenter Deployment − Consul supports multiple
Service Discovery
It
The usage of service discovery comes in as a boon for distributed systems.
This is one of the main problems, which
Comparison with
https://www.tutorialspoint.com/consul/consul_introduction.htm
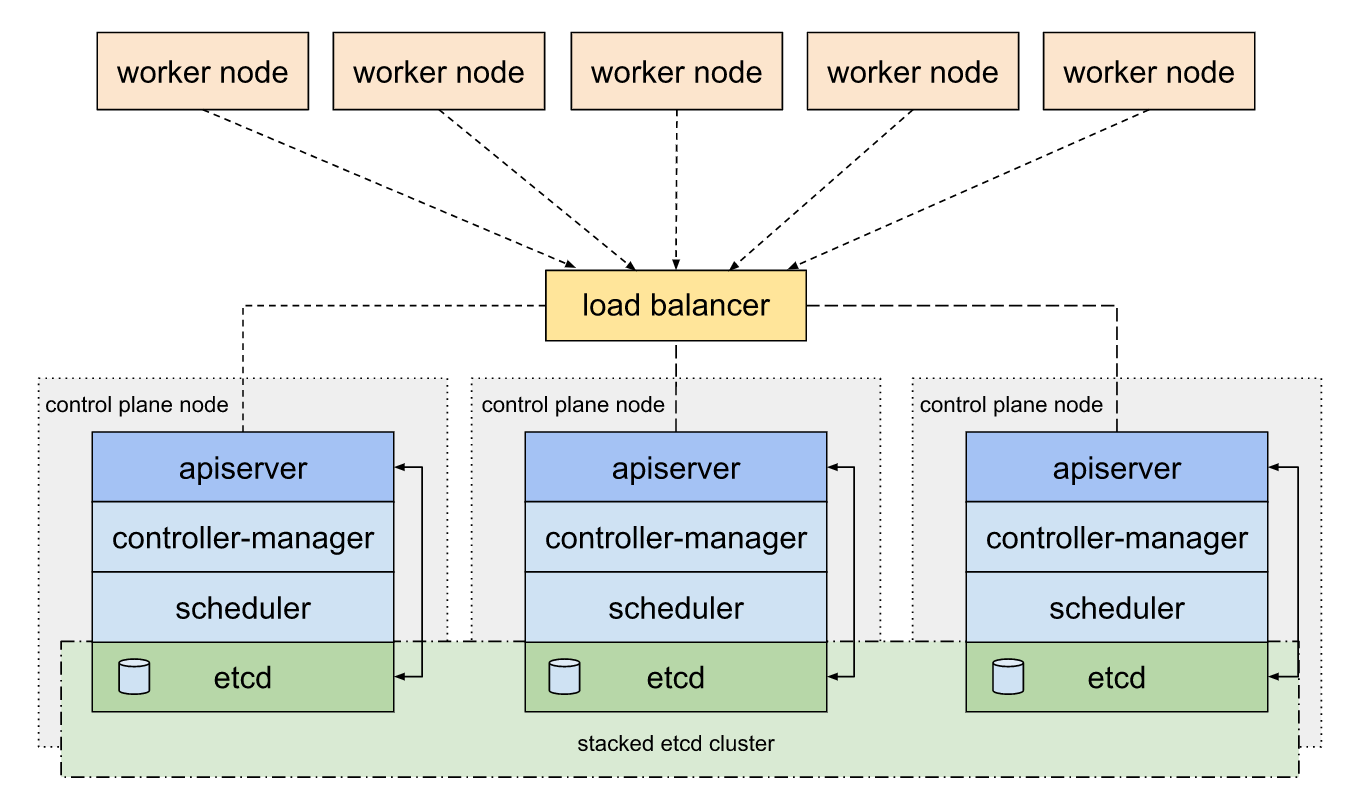
there are three different servers, which
Each server interacts with its own client using the concept of RPC. The Communication between the Clients is
Raft Algorithm
Raft is a consensus algorithm for managing a replicated log. It relies on the principle of CAP Theorem, which states that in the presence of a network partition, one has to choose between consistency and availability.
A Raft Cluster contains several servers, usually in the odd number count.
For example, if we have five servers, it will allow the system to tolerate two failures.
In a normal operation, there is exactly one leader and
There are two types of protocol in Consul, which
Consensus Protocol and
Gossip Protocol
Consensus Protocol
Consensus protocol
Gossip Protocol
In consul, the usage of gossip protocol occurs in two ways, WAN (Wireless Area Network) and LAN (Local Area Network).
There are three known libraries, which can implement a Gossip Algorithm to discover nodes in a peer-to-peer network −
gossip-python − It
Smudge −
Remote Procedure Calls
a protocol that one program uses to request a service from another program
Before RPC, Consul used to have only TCP and UDP based connections, which were good with most systems, but not
In this area, GRPC by Google is a great tool to look forward in case one wishes to observe benchmarks and compare performance.
https://www.tutorialspoint.com/consul/consul_architecture.htm
- A high performance, open-source universal RPC framework
Install runtime and dev environments with a single line and also scale to millions of RPCs per second with the framework
https://grpc.io/
- ZooKeeper
http://zookeeper.apache.org/
etcd is a distributed key-value store that provides a reliable way to store data across a cluster of machines. It’s open-source and available on GitHub.etcd gracefully handles leader elections during network partitions and will tolerate machine failure, including the leader.
https://coreos.com/etcd/
- Setup
Etcd Cluster on CentOS 7/8 / Ubuntu 18.04/16.04 /Debian 10/9
Simple: well-defined, user-facing API (
Secure: automatic TLS with optional client
Fast: benchmarked 10,000 writes/sec
Reliable: properly distributed using Raft
https://computingforgeeks.com/setup-etcd-cluster-on-centos-debian-ubuntu/

- Gossip protocol
a procedure or process of computer–computer communication that
It is a communication protocol.
Modern distributed systems often use gossip protocols to solve problems that might be difficult to solve in other ways,
https://en.wikipedia.org/wiki/Gossip_protocol
- Gossip Protocols
are executed that is, in cycles. That's what the word cycle in the simulator means. It will rotate in every cycle.
- In large distributed systems, knowing the state of the whole system is a difficult task that becomes harder
as you increment the number of nodes.
Since the underlying network is a problem, you can’t rely on hardware solutions, such as
https://conferences.oreilly.com/velocity/vl-eu/public/schedule/detail/71020
- The Gossip Protocol is a method to resolve this communication chaos. In Cassandra, when one node talks to another, the node which
is expected to respond, not only provides information about itsstatus,but also provides information about the nodesthat it had communicated with before. Through this process, there is a reduction in network log, more informationis kept and efficiency of information gathering increases. The main feature of the protocol is to provide the latest information of any noderespectively .
An important feature of Gossip Protocol is Failure Detection. Basically, when two nodes communicate with one another; for instance, Node A to Node B, then Node A sends a message ‘
https://www.edureka.co/blog/gossip-protocol-in-cassandra/
Hello, an amazing Information dude. Thanks for sharing this nice information with us. Docker Avanzado
ReplyDelete